
- 1Android App开发基础(2)—— App的工程结构
- 2"新年快乐"的多语言版本
- 3mac上安装docker并运行kubernetes_mac docker 运行 kubernetesui/dashboard 默认端口
- 4音频格式之AAC:(2)AAC封装格式ADIF,ADTS,LATM,extradata及AAC ES存储格式
- 5windows docker desktop配置国内镜像仓库_docker desktop 国内镜像
- 6Java面试——缓存_什么是缓存区间
- 7nohup 执行mysql命令_Linux nohup命令:后台命令脱离终端运行
- 8【QueryWrappery用法】_new querrywrapper<>().ne
- 9用python制作简单节日贺卡_生日贺卡python
- 10C语言总结(第2章算法——程序的灵魂 第3章最简单的C程序设计——顺序程序设计 第4章选择结构程序设计)_一个物体从 100m的高空自由落下,编写程序计算并输出它到达地面所需的时间和它
Hadoop-生产调优
赞
踩
第1章 HDFS-核心参数
1.1 NameNode内存生产配置
1)NameNode 内存计算
- 每个文件块大概占用 150 byte,一台服务器 128G 内存为例,能存储多少文件块呢?
- 128 * 1024 * 1024 * 1024 / 150byte ≈ 9.1 亿
- G MB KB Byte
2)Hadoop2.x系列,配置 NameNode 内存
-
NameNode 内存默认 2000m,如果内存服务器内存 4G,NameNode 内存可以配置 3g。在 hadoop-env.sh 文件中配置如下
-
HADOOP_NAMENODE_OPTS=-Xmx3072m- 1
3)Hadoop3.x系列,配置 NameNode 内存
(1)hadoop-env.sh 中描述 Hadoop 的内存是动态分配的
# The maximum amount of heap to use (Java -Xmx). If no unit
# is provided, it will be converted to MB. Daemons will
# prefer any Xmx setting in their respective _OPT variable.
# There is no default; the JVM will autoscale based upon machine
# memory size.
# export HADOOP_HEAPSIZE_MAX=
# The minimum amount of heap to use (Java -Xms). If no unit
# is provided, it will be converted to MB. Daemons will
# prefer any Xms setting in their respective _OPT variable.
# There is no default; the JVM will autoscale based upon machine
# memory size.
# export HADOOP_HEAPSIZE_MIN=
HADOOP_NAMENODE_OPTS=-Xmx102400m
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
(2)查看 NameNode 占用内存
[root@node1 ~]# jps 1990 NameNode 2135 DataNode 2553 ResourceManager 1771 QuorumPeerMain 3069 Jps 2703 NodeManager [root@node1 ~]# jmap -heap 1990 Attaching to process ID 1990, please wait... Debugger attached successfully. Server compiler detected. JVM version is 25.241-b07 using thread-local object allocation. Parallel GC with 2 thread(s) Heap Configuration: MinHeapFreeRatio = 0 MaxHeapFreeRatio = 100 MaxHeapSize = 2046820352 (1952.0MB) ☆ NewSize = 42467328 (40.5MB) MaxNewSize = 682098688 (650.5MB) OldSize = 85458944 (81.5MB) NewRatio = 2 SurvivorRatio = 8 MetaspaceSize = 21807104 (20.796875MB) CompressedClassSpaceSize = 1073741824 (1024.0MB) MaxMetaspaceSize = 17592186044415 MB G1HeapRegionSize = 0 (0.0MB) Heap Usage: PS Young Generation Eden Space: capacity = 127926272 (122.0MB) used = 114224304 (108.93278503417969MB) free = 13701968 (13.067214965820312MB) 89.28916806080302% used From Space: capacity = 5242880 (5.0MB) used = 0 (0.0MB) free = 5242880 (5.0MB) 0.0% used To Space: capacity = 18874368 (18.0MB) used = 0 (0.0MB) free = 18874368 (18.0MB) 0.0% used PS Old Generation capacity = 122683392 (117.0MB) used = 42217192 (40.261451721191406MB) free = 80466200 (76.7385482788086MB) 34.411497197599495% used 15419 interned Strings occupying 1436248 bytes.

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
(3)查看 DataNode 占用内存
[root@node1 ~]# jmap -heap 2135 Attaching to process ID 2135, please wait... Debugger attached successfully. Server compiler detected. JVM version is 25.241-b07 using thread-local object allocation. Parallel GC with 2 thread(s) Heap Configuration: MinHeapFreeRatio = 0 MaxHeapFreeRatio = 100 MaxHeapSize = 2046820352 (1952.0MB) ☆ NewSize = 42467328 (40.5MB) MaxNewSize = 682098688 (650.5MB) OldSize = 85458944 (81.5MB) NewRatio = 2 SurvivorRatio = 8 MetaspaceSize = 21807104 (20.796875MB) CompressedClassSpaceSize = 1073741824 (1024.0MB) MaxMetaspaceSize = 17592186044415 MB G1HeapRegionSize = 0 (0.0MB) Heap Usage: PS Young Generation Eden Space: capacity = 127926272 (122.0MB) used = 18529608 (17.67121124267578MB) free = 109396664 (104.32878875732422MB) 14.484599379242443% used From Space: capacity = 5242880 (5.0MB) used = 0 (0.0MB) free = 5242880 (5.0MB) 0.0% used To Space: capacity = 12058624 (11.5MB) used = 0 (0.0MB) free = 12058624 (11.5MB) 0.0% used PS Old Generation capacity = 78118912 (74.5MB) used = 15015288 (14.319694519042969MB) free = 63103624 (60.18030548095703MB) 19.221066468514053% used 15063 interned Strings occupying 1353568 bytes.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
查看发现主节点上的 NameNode 和 DataNode 占用内存都是自动分配的,且相等。不是很合理。
可以参考 CDH 官方说明配置
Hardware Requirements | 6.x | Cloudera Documentation


具体修改:hadoop-env.sh
export HDFS_NAMENODE_OPTS="-Dhadoop.security.logger=INFO,RFAS -Xmx1024m"
export HDFS_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS -Xmx1024m"
- 1
- 2
1.2 NameNode 心跳并发配置
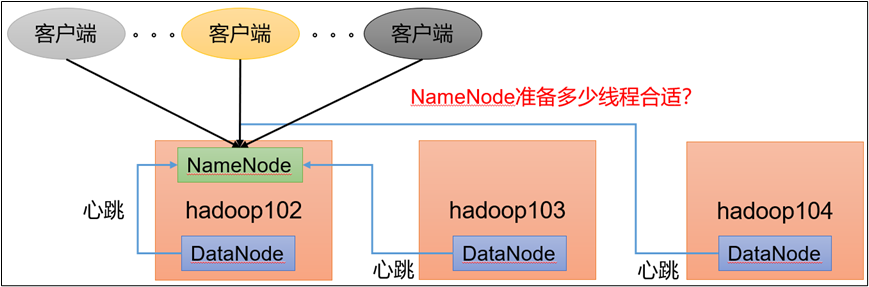
1)hdfs-site.xml
The number of Namenode RPC server threads that listen to requests from clients. If dfs.namenode.servicerpc-address is not configured then Namenode RPC server threads listen to requests from all nodes.
NameNode有一个工作线程池,用来处理不同DataNode的并发心跳以及客户端并发的元数据操作。
对于大集群或者有大量客户端的集群来说,通常需要增大该参数。默认值是10。
<property>
<name>dfs.namenode.handler.count</name>
<value>21</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
企业经验:
d
f
s
.
n
a
m
e
n
o
d
e
.
h
a
n
d
l
e
r
.
c
o
u
n
t
=
20
∗
〖
l
o
g
〗
e
(
C
l
u
s
t
e
r
S
i
z
e
)
dfs.namenode.handler.count = 20 *〖log〗_e^(Cluster Size)
dfs.namenode.handler.count=20∗〖log〗e(ClusterSize)
,比如集群规模 (DataNode 台数)为3台时,此参数设置为21.可通过简单的python代码计算该值,代码如下:
[root@node1 ~]# python
Python 2.7.5 (default, Aug 7 2019, 00:51:29)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-39)] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import math
>>> print int(20*math.log(3))
21
- 1
- 2
- 3
- 4
- 5
- 6
- 7
1.3 开启回收站配置
开启回收站功能,可以将删除的文件在不超时的情况下,回复原数据,起到防止误删除、备份等作用
1)回收站机制
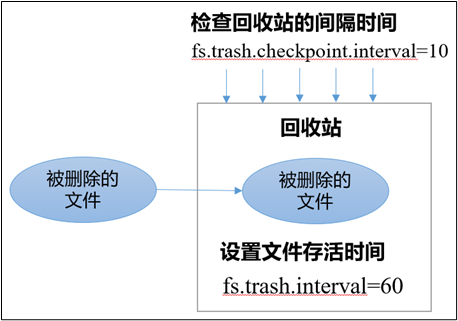
2)开启回收站功能参数说明
(1)默认值fs.trash.interval = 0,0表示禁用回收站;其他值表示设置文件的存活时间。
(2)默认值fs.trash.checkpoint.interval = 0,检查回收站的间隔时间。如果该值为0,则该值设置和fs.trash.interval的参数值相等。
(3)要求fs.trash.checkpoint.interval <= fs.trash.interval。
3)启用回收站
修改 core-site.xml,配置垃圾回收时间为1分钟
<property>
<name>fs.trash.interval</name>
<value>1</value>
</property>
- 1
- 2
- 3
- 4
4)查看回收站
- 回收站目录在HDFS集群中的路径:/user/root《随用户而变》/.Trash
5)注意:通过web的9870端口删除的文件不会走回收站
6)通过程序删除的文件不会经过回收站,需要调用 moveToTrash()才进入回收站
Trash trash = New Trash(conf);
trash.moveToTrash(path);
- 1
- 2
7)在命令行利用hadoop fs -rm命令删除的文件才会走回收站。
[root@node1 hadoop]# hadoop fs -rm /tmp/lj_tmp/202312/10/input/new_node1_2023-12-10_14_56_54.log
2024-01-28 18:43:21,365 INFO fs.TrashPolicyDefault: Moved: 'hdfs://node1:8020/tmp/lj_tmp/202312/10/input/new_node1_2023-12-10_14_56_54.log' to trash at: hdfs://node1:8020/user/root/.Trash/Current/tmp/lj_tmp/202312/10/input/new_node1_2023-12-10_14_56_54.log
- 1
- 2
8)恢复回收站数据
hadoop fs -mv hdfs://node1:8020/user/root/.Trash/Current/tmp/lj_tmp/202312/10/input/new_node1_2023-12-10_14_56_54.log hdfs://node1:8020/tmp/lj_tmp/202312/10/input
- 1
第2章 HDFS-集群压测
在企业中非常关心每天从Java后台拉取过来的数据,需要多久能上传到集群?消费者关心多久能从HDFS上拉取需要的数据?
为了搞清楚HDFS的读写性能,生产环境上非常需要对集群进行压测。
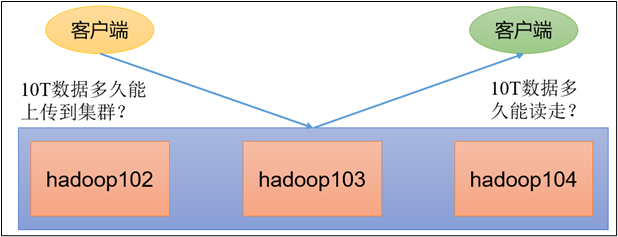
HDFS的读写性能主要受网络和磁盘影响比较大。为了方便测试,将hadoop102、hadoop103、hadoop104虚拟机网络都设置为100mbps。
100Mbps单位是bit;10M/s单位是byte ; 1byte=8bit,100Mbps/8=12.5M/s。
测试网速:来到node2的/opt/module目录,创建一个
[root@node1 hadoop]# python -m SimpleHTTPServer
- 1
2.1 测试 HDFS 写性能
1)写测试底层原理
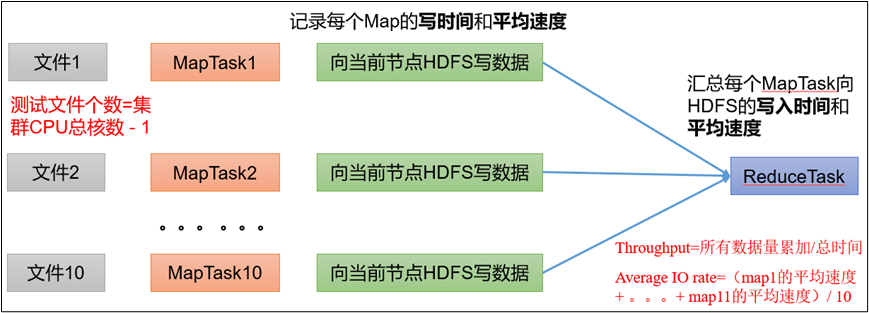
2)测试内容:向HDFS集群写10个128M的文件
[root@node1 hadoop]# hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -write -nrFiles 10 -fileSize 128MB
2021-02-09 10:43:16,853 INFO fs.TestDFSIO: ----- TestDFSIO ----- : write
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Date & time: Tue Feb 09 10:43:16 CST 2021
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Number of files: 10
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Total MBytes processed: 1280
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Throughput mb/sec: 1.61
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Average IO rate mb/sec: 1.9
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: IO rate std deviation: 0.76
2021-02-09 10:43:16,854 INFO fs.TestDFSIO: Test exec time sec: 133.05
2021-02-09 10:43:16,854 INFO fs.TestDFSIO:
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
注意:nrFiles n为生成mapTask的数量,生产环境一般可通过hadoop103:8088查看CPU核数,设置为(CPU核数 - 1)
-
Number of files:生成mapTask数量,一般是集群中(CPU核数-1),我们测试虚拟机就按照实际的物理内存-1分配即可
-
Total MBytes processed:单个map处理的文件大小
-
Throughput mb/sec:单个mapTak的吞吐量
-
计算方式:处理的总文件大小/每一个mapTask写数据的时间累加
-
集群整体吞吐量:生成mapTask数量*单个mapTak的吞吐量
-
-
Average IO rate mb/sec::平均mapTak的吞吐量
-
计算方式:每个mapTask处理文件大小/每一个mapTask写数据的时间
-
全部相加除以task数量
-
-
IO rate std deviation:方差、反映各个mapTask处理的差值,越小越均衡
3)注意:如果测试过程中,出现异常
(1)可以在 yarn-site.xml 中设置虚拟内存检测为 false
<!--是否启动一个线程检查每个任务正使用的虚拟内存量,如果任务超出分配值,则直接将其杀掉,默认是true -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
- 1
- 2
- 3
- 4
- 5
(2)分发配置并重启 Yarn 集群
4)测试结果分析
(1)由于副本1就在本地,所以该副本不参与测试
一共参与测试的文件:10个文件 * 2个副本 = 20个
压测后的速度:1.61
实测速度:1.61M/s * 20个文件 ≈ 32M/s
三台服务器的带宽:12.5 + 12.5 + 12.5 ≈ 30m/s
所有网络资源都已经用满。
如果实测速度远远小于网络,并且实测速度不能满足工作需求,可以考虑采用固态硬盘或者增加磁盘个数。
(2)如果客户端不在集群节点,那就三个副本都参与计算
2.2 测试 HDFS 读性能
1)测试内容:读取HDFS集群10个128M的文件
[root@node1 hadoop]# hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -read -nrFiles 10 -fileSize 128MB
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: ----- TestDFSIO ----- : read
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: Date & time: Tue Feb 09 11:34:15 CST 2021
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: Number of files: 10
2021-02-09 11:34:15,847 INFO fs.TestDFSIO: Total MBytes processed: 1280
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: Throughput mb/sec: 200.28
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: Average IO rate mb/sec: 266.74
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: IO rate std deviation: 143.12
2021-02-09 11:34:15,848 INFO fs.TestDFSIO: Test exec time sec: 20.83
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2)删除测试生成数据
[root@node1 hadoop]# hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO -clean
- 1
3)测试结果分析:为什么读取文件速度大于网络带宽?由于目前只有三台服务器,且有三个副本,数据读取就近原则,相当于都是读取的本地磁盘数据,没有走网络。
第3章 HDFS 多目录
3.1 NameNode 多目录配置
1)NameNode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性

2)具体配置如下
(1)在 hdfs-site.xml 文件中添加如下内容
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name1,file://${hadoop.tmp.dir}/dfs/name2</value>
</property>
- 1
- 2
- 3
- 4
注意:因为每台服务器节点的磁盘情况不同,所以这个配置配完之后,可以选择不分发
(2)停止集群,删除三台节点的data和logs中所有数据。
[root@node1 hadoop]# rm -rf data/ logs/
[root@node1 hadoop]# rm -rf data/ logs/
[root@node1 hadoop]# rm -rf data/ logs/
- 1
- 2
- 3
(3)格式化集群并启动
[root@node1 hadoop]# bin/hdfs namenode -format
[root@node1 hadoop]# sbin/start-dfs.sh
- 1
- 2
3)查看结果
[root@node1 dfs]# ls
data name1 name2
- 1
- 2
检查 name1 和 name2 里面的内容,发现一模一样。
3.2 DataNode 多目录配置
1)DataNode 可以配置成多个目录,每个目录存储的数据不一样(数据不是副本)

2)具体配置如下
在 hdfs-site.xml 文件中添加如下内容
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data1,file://${hadoop.tmp.dir}/dfs/data2</value>
</property>
- 1
- 2
- 3
- 4
3)查看结果
[root@node1 hadoop]# ls
data1 data2 name1 name2
- 1
- 2
4)向集群上传一个文件,再次观察两个文件夹里面的内容发现不一致(一个有数一个没有)
3.3 集群数据均衡之磁盘间数据均衡
生产环境,由于硬盘空间不足,往往需要增加一块硬盘。刚加载的硬盘没有数据时,可以执行磁盘数据均衡命令。(Hadoop3.x新特性)

(1)生成均衡计划(我们只有一块磁盘,不会生成计划)
hdfs diskbalancer -plan hadoop103
- 1
(2)执行均衡计划
hdfs diskbalancer -execute hadoop103.plan.json
- 1
(3)查看当前均衡任务的执行情况
hdfs diskbalancer -query hadoop103
- 1
(4)取消均衡任务
hdfs diskbalancer -cancel hadoop103.plan.json
- 1
第4章 HDFS–集群扩容及缩容
4.1 添加白名单
白名单:表示在白名单的主机IP地址可以,用来存储数据
企业中:配置白名单,可以尽量防止黑客恶意访问攻击
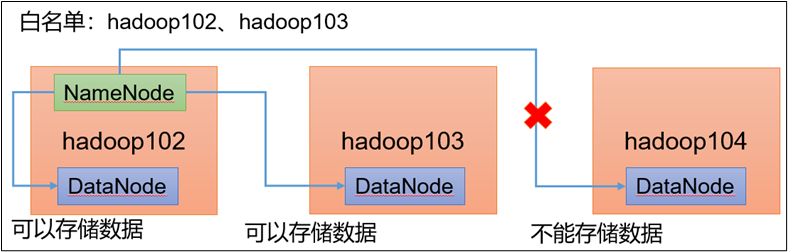
配置白名单步骤如下:
1)在 NameNode 节点的 ./hadoop/etc/hadoop 目录下分别创建 whitelist 和blacklist 文件
(1)创建白名单
vim whitelist
- 1
在 whitelist 中添加如下主机名称,假如集群正常工作节点为 102 103
hadoop102
hadoop103
- 1
- 2
(2)创建黑名单
# 保持空的就可以
touch blacklist
- 1
- 2
2)在 hdfs-site.xml 配置文件中增加 dfs.hosts 配置参数
<!-- 白名单 -->
<property>
<name>dfs.hosts</name>
<value>/export/server/hadoop/etc/hadoop/whitelist</value>
</property>
<!-- 黑名单 -->
<property>
<name>dfs.hosts.exclude</name>
<value>/export/server/hadoop/etc/hadoop/blacklist</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3)分发配置文件 whitelist,hdfs-site.xml
xsync whitelist hdfs-site.xml
- 1
4)第一次添加白名单必须重启集群,不是第一次,只需刷新 NameNode 节点即可
5)在 web 浏览器上查看 DN,http://hadoop102:9870/dfshealth.html#tab-datanode
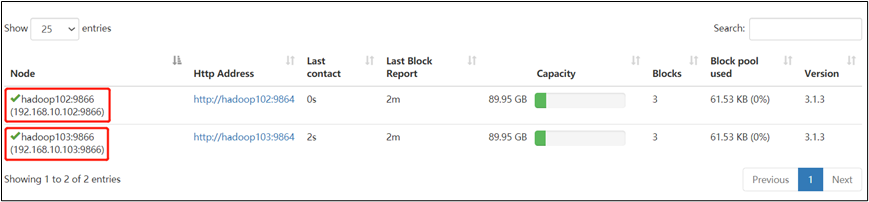
6)在 hadoop104 上执行上传数据失败
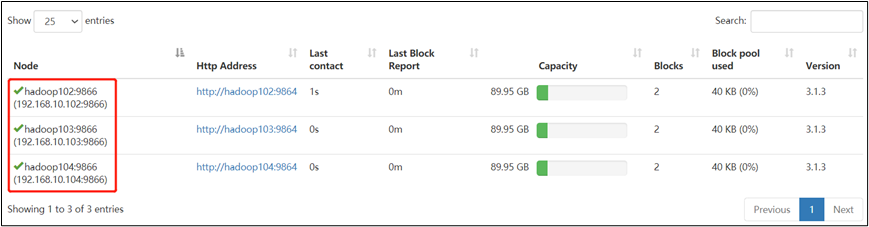
7)二次修改白名单,增加 hadoop104
vim whitelist
hadoop102
hadoop103
hadoop104
- 1
- 2
- 3
- 4
8)刷新 NameNode
hdfs dfsadmin -refreshNodes
- 1
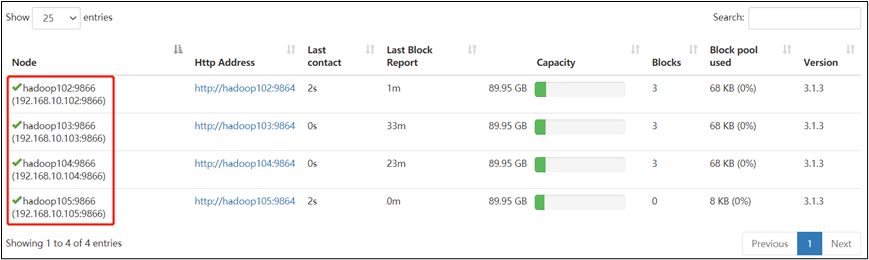
9)在 web 浏览器上查看 DN,http://hadoop102:9870/dfshealth.html#tab-datanode
4.2 服役新服务器
1)需求
随着公司业务的增长,数据量越来越大,原有的数据节点的容量已经不能满足存储数据的需求,需要在原有集群基础上动态添加新的数据节点。
2)环境准备
(1)在hadoop100主机上再克隆一台hadoop105主机
(2)修改IP地址和主机名称
vim /etc/sysconfig/network-scripts/ifcfg-ens33
vim /etc/hostname
- 1
- 2
(3)拷贝hadoop102的 /export/server 目录和 /etc/profile.d/my_env.sh 到 hadoop105
scp -r /export/server/* root@hadoop105:/export/server
scp /etc/profile.d/my_env.sh root@hadoop105:/etc/profile.d/my_env.sh
source /etc/profile
- 1
- 2
- 3
(4)删除 hadoop105 上 Hadoop 的历史数据,data 和 log 数据
rm -rf data/ logs/
- 1
(5)配置 hadoop102 和 hadoop103 到 hadoop105 的ssh 免密登陆
# 在 hadoop102 上执行
ssh-copy-id hadoop105
# 在 hadoop103 上执行
ssh-copy-id hadoop105
- 1
- 2
- 3
- 4
3)服役新节点具体步骤
(1)直接启动 DataNode,即可关联到集群
hdfs --daemon start datanode
yarn --daemon start nodemanager
- 1
- 2
4)白名单中增加新服役的服务器
(1)在白名单whitelist中增加hadoop105
vim whitelist
修改为如下内容
hadoop102
hadoop103
hadoop104
hadoop105
- 1
- 2
- 3
- 4
- 5
- 6
(2)分发
xsync whitelist
- 1
(3)刷新 NameNode
dfs dfsadmin -refreshNodes
- 1
5)在 hadoop105 上上传文件
hadoop dfs -put ./test.txt /tmp
- 1
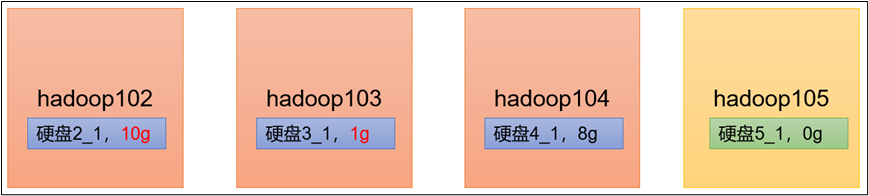
4.3 服务器间数据均衡
1)企业经验:在企业开发中,如果经常在hadoop102和hadoop104上提交任务,且副本数为2,由于数据本地性原则,就会导致hadoop102和hadoop104数据过多,hadoop103存储的数据量小。
另一种情况,就是新服役的服务器数据量比较少,需要执行集群均衡命令。
2)开启数据均衡命令
sbin/start-balancer.sh -threshold 10
- 1
对于参数10,代表的是集群中各个节点的磁盘空间利用率相差不超过10%,可根据实际情况进行调整。
3)停止数据均衡命令
sbin/stop-balancer.sh
- 1
注意:由于 HDFS 需要启动单独的 Rebalance Server 来执行 Rebalance 操作,所以尽量不要在 NameNode 上执行 start-balancer.sh,而是找一台比较空闲的机器。
4.4 黑名单退役服务器
黑名单:表示在黑名单的主机IP地址不可用,用来存储数据
企业中:配置黑名单,用来退役服务器。
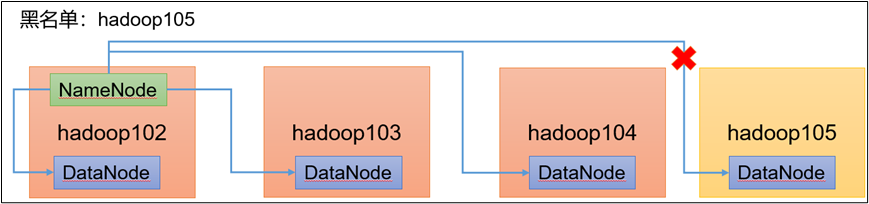
黑名单配置步骤如下:
1)编辑 blacklist 文件
vim blacklist
- 1
添加如下主机名称(要退役的节点)
hadoop105
- 1
注意:如果白名单中没有配置,需要在 hdfs-site.xml 配置文件中增加 dfs.host 配置参数
<!-- 黑名单 -->
<property>
<name>dfs.hosts.exclude</name>
<value>/export/server/hadoop-3.1.3/etc/hadoop/blacklist</value>
</property>
- 1
- 2
- 3
- 4
- 5
2)分发配置文件 blacklist 和 hdfs-site.xml
xsync hdfs-site.xml blacklist
- 1
3)第一次添加黑名单必须重启集群,不是第一次,只需要刷新 NameNode 节点即可
hdfs dfsadmin -refreshNodes
- 1
4)检查 web 浏览器,退役节点的状态为 decommission in progress(退役中),说明数据节点正在复制块到其他节点


5)等待退役节点状态为 decommissioned(所有块以复制完成),停止该节点及节点资源管理器。
注意:如果副本数是 3,退役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役

hdfs --daemon stop datanode
yarn --daemon stop nodemanager
- 1
- 2
6)如果数据不均衡,可以用命令实现集群的再平衡
sbin/start-balancer.sh -threshold 10
- 1
第5章 HDFS-存储优化
注:演示纠删码和异构存储需要一共5台虚拟机。尽量拿另外一套集群。提前准备5台服务器的集群。
5.1 纠删码
5.1.1 纠删码原理
HDFS默认情况下,一个文件有3个副本,这样提高了数据的可靠性,但也带来了2倍的冗余开销。Hadoop3.x引入了纠删码,采用计算的方式,可以节省约50%左右的存储空间。
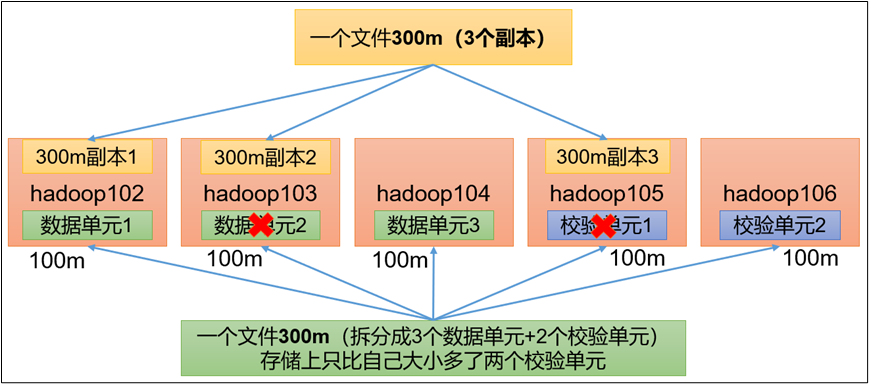
1)纠删码操作相关的命令
hdfs ec
- 1
2)查看当前支持的纠删码策略
hdfs ec -listPolicies
- 1
3)纠删码策略解释
RS-3-2-1024k:使用RS编码,每3个数据单元,生成2个校验单元,共5个单元,也就是说:这5个单元中,只要有任意的3个单元存在(不管是数据单元还是校验单元,只要总数=3),就可以得到原始数据。每个单元的大小是1024k=1024*1024=1048576。
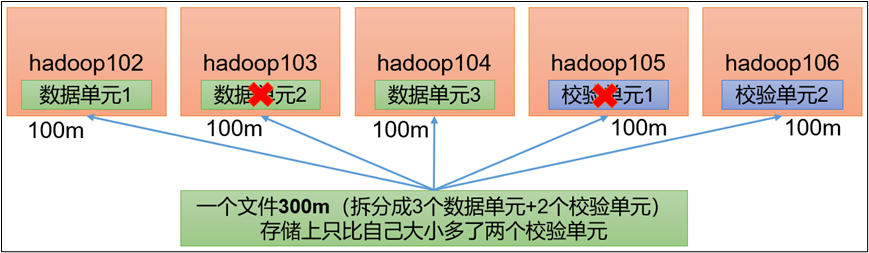
RS-10-4-1024k:使用RS编码,每10个数据单元(cell),生成4个校验单元,共14个单元,也就是说:这14个单元中,只要有任意的10个单元存在(不管是数据单元还是校验单元,只要总数=10),就可以得到原始数据。每个单元的大小是1024k=1024*1024=1048576。
RS-6-3-1024k:使用RS编码,每6个数据单元,生成3个校验单元,共9个单元,也就是说:这9个单元中,只要有任意的6个单元存在(不管是数据单元还是校验单元,只要总数=6),就可以得到原始数据。每个单元的大小是1024k=1024*1024=1048576。
RS-LEGACY-6-3-1024k:策略和上面的RS-6-3-1024k一样,只是编码的算法用的是rs-legacy。
XOR-2-1-1024k:使用XOR编码(速度比RS编码快),每2个数据单元,生成1个校验单元,共3个单元,也就是说:这3个单元中,只要有任意的2个单元存在(不管是数据单元还是校验单元,只要总数= 2),就可以得到原始数据。每个单元的大小是1024k=1024*1024=1048576。
5.1.2 纠删码案例实操

纠删码策略是给具体一个路径设置。所有往此路径下存储的文件,都会执行此策略。
默认只开启对RS-6-3-1024k策略的支持,如要使用别的策略需要提前启用。
1)需求:将/input 目录设置为 RS-3-2-1024k 策略
2)具体步骤
(1)开启对RS-3-2-1024k策略的支持
hdfs ec -enablePolicy -policy RS-3-2-1024k
- 1
(2)在 HDFS 创建目录,并设置 RS-3-2-1024k 策略
hdfs dfs -mkdir /input
hdfs ec -setPolicy -path /input -policy RS-3-2-1024k
- 1
- 2
(3)上传文件,并查看文件编码后的存储情况
hdfs dfs -put test.txt /input
- 1
注:你所上传的文件需要大于2M才能看出效果。(低于2M,只有一个数据单元和两个校验单元)
(4)查看存储路径的数据单元和校验单元,并作破坏实验
5.2 异构存储(冷热数据分离)
异构存储主要解决,不同的数据,存储在不同类型的硬盘中,达到最佳性能的问题。
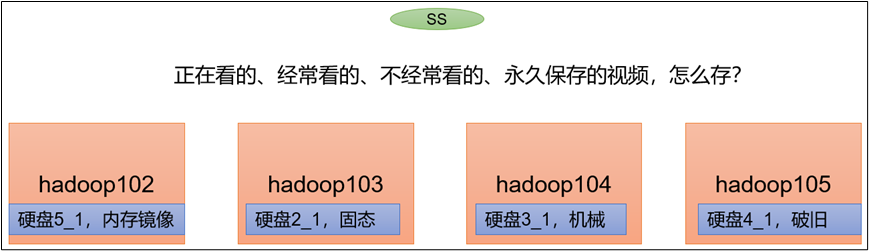
1)关于存储类型
RAM_DISK:内存镜像文件系统
SSD:SSD固态硬盘
DISK:普通硬盘,在 HDFS 中,如果没有主动声明数据目录存储类型默认都是 DISK
ARCHIVE:没有特指哪种存储介质,主要的指的是计算能力比较弱而存储密度比较高的存储介质,用来解决数据量的容量扩增的问题,一般用于归档
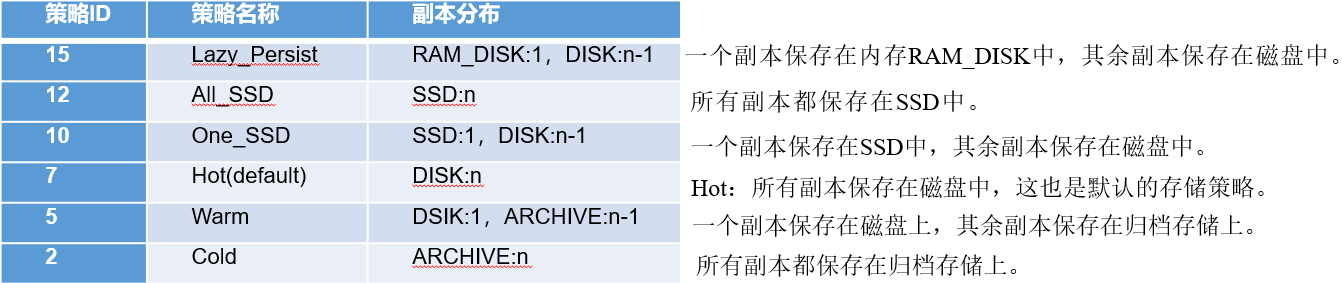
2)关于存储策略
说明:从 Lazy_Persist 到 Cold,分别代表了设备的访问速度从快到慢
5.2.1 异构存储 Shell 操作
(1)查看当前有哪些存储策略可以用
hdfs storagepolicies -listPolicies
- 1
(2)为指定路径(数据存储目录)设置指定的存储策略
hdfs storagepolicies -setStoragePolicy -path xxx -policy xxx
- 1
(3)获取指定路径(数据存储目录或文件)的存储策略
hdfs storagepolicies -getStoragePolicy -path xxx
- 1
(4)取消存储策略;执行改命令之后该目录或者文件,以其上级的目录为准,如果是根目录,那么就是HOT
hdfs storagepolicies -unsetStoragePolicy -path xxx
- 1
(5)查看文件块的分布
hdfs fsck xxx -files -blocks -locations
- 1
(5)查看集群节点
hadoop dfsadmin -report
- 1
5.2.2 测试环境准备
1)测试环境描述
服务器规模:5台
集群配置:副本数为2,创建好带有存储类型的目录(提前创建)
集群规划:
| 节点 | 存储类型分配 |
|---|---|
| hadoop102 | RAM_DISK,SSD |
| hadoop103 | SSD,DISK |
| hadoop104 | DISK,RAM_DISK |
| hadoop105 | ARCHIVE |
| hadoop106 | ARCHIVE |
2)配置文件信息
(1)为 hadoop102 节点的 hdfs-site.xml 添加如下信息
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[SSD]file:///export/server/hadoop-3.1.3/hdfsdata/ssd,[RAM_DISK]file:///export/server/hadoop-3.1.3/hdfsdata/ram_disk</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
(2)为 hadoop103 节点的 hdfs-site.xml 添加如下信息
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[SSD]file:///export/server/hadoop-3.1.3/hdfsdata/ssd,[DISK]file:///export/server/hadoop-3.1.3/hdfsdata/disk</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
(3)为 hadoop104 节点的 hdfs-site.xml 添加如下信息
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[RAM_DISK]file:///export/server/hdfsdata/ram_disk,[DISK]file:///export/server/hadoop-3.1.3/hdfsdata/disk</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
(4)为 hadoop105 节点的 hdfs-site.xml 添加如下信息
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[ARCHIVE]file:///export/server/hadoop-3.1.3/hdfsdata/archive</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
(5)为 hadoop106 节点的 hdfs-site.xml 添加如下信息
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.storage.policy.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>[ARCHIVE]file:///export/server/hadoop-3.1.3/hdfsdata/archive</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3)数据准备
(1)启动集群
start-all.sh
- 1
(2)在 HDFS 上创建文件目录
hdfs fs -mkdir /testdir
- 1
(3)并将文件资料上传
hdfs dfs -put ./text.txt /testdir
- 1
5.2.3 HOT 存储策略案例
(1)最开始我们未设置存储策略的情况下,我们获取该目录的存储策略
hdfs storagepolicies -getStoragePolicy -path /testdir
- 1
(2)我们查看上传的文件块分布
hdfs fsck /testdir -files -blocks -locations
[DatanodeInfoWithStorage[192.168.10.104:9866,DS-0b133854-7f9e-48df-939b-5ca6482c5afb,DISK], DatanodeInfoWithStorage[192.168.10.103:9866,DS-ca1bd3b9-d9a5-4101-9f92-3da5f1baa28b,DISK]]
- 1
- 2
- 3
未设置存储策略,所有文件块都存储在 DISK 下。所以,默认存储策略为 HOT。
5.2.4 WARM存储策略测试
(1)接下来我们为数据降温
hdfs storagepolicies -setStoragePolicy -path /testdir -policy WARM
- 1
(2)再次查看文件块分布,我们可以看到文件块依然放在原处。
hdfs fsck /testdir -files -blocks -locations
- 1
(3)我们需要让他 HDFS 按照存储策略自行移动文件块
hdfs mover /testdir
- 1
(4)再次查看文件块分布
hdfs fsck /testdir -files -blocks -locations
[DatanodeInfoWithStorage[192.168.10.105:9866,DS-d46d08e1-80c6-4fca-b0a2-4a3dd7ec7459,ARCHIVE], DatanodeInfoWithStorage[192.168.10.103:9866,DS-ca1bd3b9-d9a5-4101-9f92-3da5f1baa28b,DISK]]
- 1
- 2
- 3
文件块一半在 DISK,一半在 ARCHIVE,符合我们设置的WARM策略
5.2.5 COLD 策略测试
(1)我们继续将数据降温为cold
hdfs storagepolicies -setStoragePolicy -path /testdir -policy COLD
- 1
注意:当我们将目录设置为 COLD 并且我们未配置 ARCHIVE 存储目录的情况下,不可以向该目录直接上传文件,会报出异常。
(2)手动转移
hdfs mover /testdir
- 1
(3)检查文件块的分布
hdfs fsck /testdir -files -blocks -locations
[DatanodeInfoWithStorage[192.168.10.105:9866,DS-d46d08e1-80c6-4fca-b0a2-4a3dd7ec7459,ARCHIVE], DatanodeInfoWithStorage[192.168.10.106:9866,DS-827b3f8b-84d7-47c6-8a14-0166096f919d,ARCHIVE]]
- 1
- 2
- 3
所有文件块都在 ARCHIVE,符合 COLD 存储策略。
5.2.6 ONE_SSD策略测试
(1)接下来我们将存储策略从默认的 HOT 更改为 ONE_SSD
hdfs storagepolicies -setStoragePolicy -path /testdir -policy One_SSD
- 1
(2)手动转移
hdfs mover /testdir
- 1
(3)检查文件块的分布
hdfs fsck /testdir -files -blocks -locations
[DatanodeInfoWithStorage[192.168.10.104:9866,DS-0b133854-7f9e-48df-939b-5ca6482c5afb,DISK], DatanodeInfoWithStorage[192.168.10.103:9866,DS-2481a204-59dd-46c0-9f87-ec4647ad429a,SSD]]
- 1
- 2
- 3
文件块分布为一半在SSD,一半在DISK,符合One_SSD存储策略。
5.2.7 ALL_SSD策略测试
(1)接下来,我们再将存储策略更改为 All_SSD
hdfs storagepolicies -setStoragePolicy -path /testdir -policy All_SSD
- 1
(2)手动转移
hdfs mover /testdir
- 1
(3)检查文件块的分布
hdfs fsck /testdir -files -blocks -locations
[DatanodeInfoWithStorage[192.168.10.102:9866,DS-c997cfb4-16dc-4e69-a0c4-9411a1b0c1eb,SSD], DatanodeInfoWithStorage[192.168.10.103:9866,DS-2481a204-59dd-46c0-9f87-ec4647ad429a,SSD]]
- 1
- 2
- 3
所有的文件块都存储在SSD,符合All_SSD存储策略。
5.2.8 LAZY_PERSIST策略测试
(1)将存储策略改为lazy_persist
hdfs storagepolicies -setStoragePolicy -path /testdir -policy lazy_persist
- 1
(2)手动转移
hdfs mover /testdir
- 1
(3)检查文件块的分布
hdfs fsck /testdir -files -blocks -locations
[DatanodeInfoWithStorage[192.168.10.104:9866,DS-0b133854-7f9e-48df-939b-5ca6482c5afb,DISK], DatanodeInfoWithStorage[192.168.10.103:9866,DS-ca1bd3b9-d9a5-4101-9f92-3da5f1baa28b,DISK]]
- 1
- 2
- 3
所有的文件块都存储在SSD,符合All_SSD存储策略。
这里我们发现所有的文件块都是存储在DISK,按照理论一个副本存储在RAM_DISK,其他副本存储在DISK中,这是因为,我们还需要配置“dfs.datanode.max.locked.memory”,“dfs.block.size”参数。
那么出现存储策略为LAZY_PERSIST时,文件块副本都存储在DISK上的原因有如下两点:
(1)当客户端所在的DataNode节点没有RAM_DISK时,则会写入客户端所在的DataNode节点的DISK磁盘,其余副本会写入其他节点的DISK磁盘。
(2)当客户端所在的DataNode有RAM_DISK,但“dfs.datanode.max.locked.memory”参数值未设置或者设置过小(小于“dfs.block.size”参数值)时,则会写入客户端所在的DataNode节点的DISK磁盘,其余副本会写入其他节点的DISK磁盘。
但是由于虚拟机的“max locked memory”为64KB,所以,如果参数配置过大,还会报出错误:
ERROR org.apache.hadoop.hdfs.server.datanode.DataNode: Exception in secureMain
java.lang.RuntimeException: Cannot start datanode because the configured max locked memory size (dfs.datanode.max.locked.memory) of 209715200 bytes is more than the datanode's available RLIMIT_MEMLOCK ulimit of 65536 bytes.
- 1
- 2
我们可以通过该命令查询此参数的内存
ulimit -a
- 1
第6章 HDFS-故障排除
注意:采用三台服务器即可,恢复到Yarn开始的服务器快照。
6.1 NameNode 故障处理
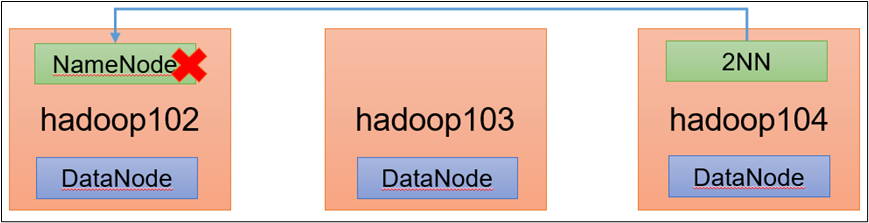
1)需求:
NameNode进程挂了并且存储的数据也丢失了,如何恢复NameNode
2)故障模拟
(1)kill -9 NameNode 进程
kill -9 2078
- 1
(2)删除 NameNode 存储的数据(/export/server/hadoop-3.1.3/data/tmp/dfs/name)
rm -rf /export/server/hadoop-3.1.3/data/tmp/dfs/name/*
- 1
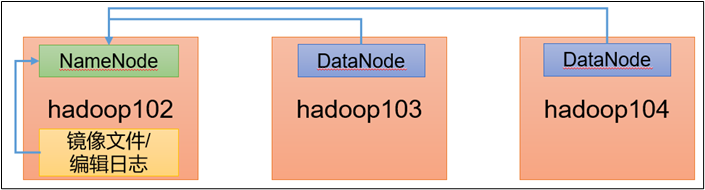
(3)问题解决
(1)拷贝 SecondaryNameNode 中数据到原 NameNode 存储数据目录
scp -r root@hadoop104:/export/server/hadoop-3.1.3/data/tmp/dfs/name /export/server/hadoop-3.1.3/data/tmp/dfs/name
- 1
(2)重新启动 NameNode
hdfs --daemon start namenode
- 1
(3)向集群上传一个文件
hdfs dfs ./test.txt /tmp
- 1
6.2 集群安全模式&磁盘修复
1)安全模式:文件系统只接受读数据请求,而不接受删除、修改等变更请求
2)进入安全模式场景
- NameNode 在加载镜像文件和编辑日志期间处于安全模式;
- NameNode 再接收 DataNode 注册时,处于安全模式
3)退出安全模式条件
dfs.namenode.safemode.min.datanodes:最小可用datanode数量,默认0
dfs.namenode.safemode.threshold-pct:副本数达到最小要求的block占系统总block数的百分比,默认0.999f。(只允许丢一个块)
dfs.namenode.safemode.extension:稳定时间,默认值30000毫秒,即30秒
4)基本语法
集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。
hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态)
- 1
- 2
- 3
- 4
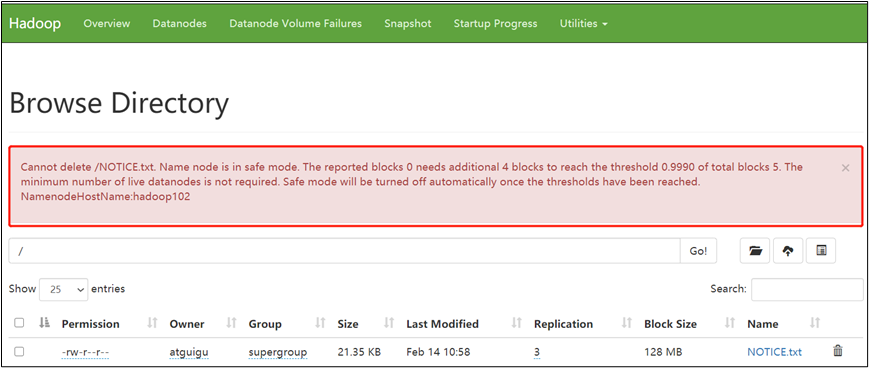
5)案例1:启动集群进入安全模式
(1)重新启动集群
stop-all.sh
start-all.sh
- 1
- 2
(2)集群启动后,立即来到集群式伤处数据,提示集群处于安全模式
6)案例2:磁盘修复
需求:数据块损坏,进入安全模式,如何处理
(1)分别进入hadoop102、hadoop103、hadoop104的/export/server/hadoop-3.1.3/data/dfs/data/current/BP-1015489500-192.168.10.102-1611909480872/current/finalized/subdir0/subdir0目录,统一删除某2个块信息
cd /export/server/hadoop-3.1.3/data/dfs/data/current/BP-1015489500-192.168.10.102-1611909480872/current/finalized/subdir0/subdir0
rm -rf blk_1073741847 blk_1073741847_1023.meta
rm -rf blk_1073741865 blk_1073741865_1042.meta
- 1
- 2
- 3
说明:hadoop103/hadoop104重复执行以上命令
(2)重新启动集群
start-all.sh
- 1
(3)观察http://hadoop102:9870/dfshealth.html#tab-overview

说明:安全模式已经打开,块的数量没有达到要求。
(4)离开安全模式
hdfs dfsadmin -safemode get
hdfs dfsadmin -safemode leave
- 1
- 2
(5)观察http://hadoop102:9870/dfshealth.html#tab-overview
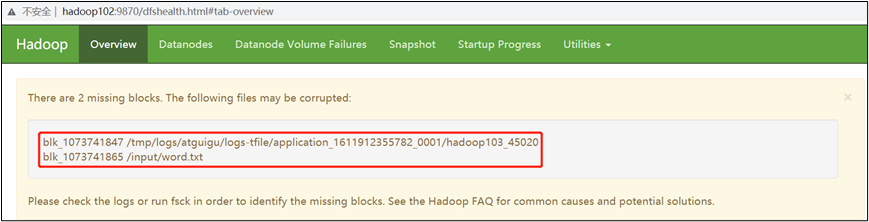
(6)将元数据删除
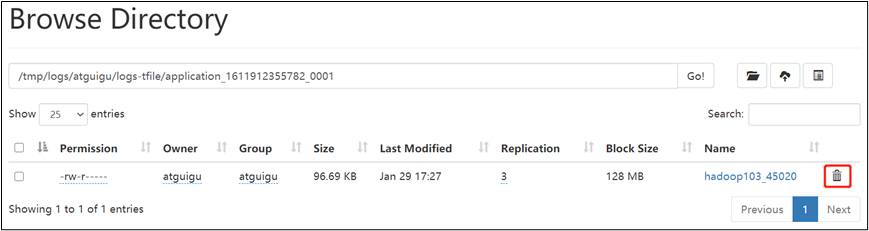
(7)观察http://hadoop102:9870/dfshealth.html#tab-overview,集群已经正常
7)案例3:
需求:模拟等待安全模式
(1)查看当前模式
hdfs dfsadmin -safemode get
- 1
(2)先进入安全模式
hdfs dfsadmin -safemode enter
- 1
(3)创建并执行下面的脚本
在/export/server/hadoop-3.1.3路径上,编辑一个脚本safemode.sh
vim safemode.sh
#!/bin/bash
hdfs dfsadmin -safemode wait
hdfs dfs -put /opt/module/hadoop-3.1.3/README.txt /
sh safemode.sh
- 1
- 2
- 3
- 4
- 5
- 6
- 7
(4)再打开一个窗口,执行
hdfs dfsadmin -safemode leave
- 1
(5)再观察上一个窗口
Safe mode is OFF
- 1
(6)HDFS 集群上已经有上传的数据了

6.3 慢磁盘监控
“慢磁盘”指的时写入数据非常慢的一类磁盘。其实慢性磁盘并不少见,当机器运行时间长了,上面跑的任务多了,磁盘的读写性能自然会退化,严重时就会出现写入数据延时的问题。
如何发现慢磁盘?
正常在HDFS上创建一个目录,只需要不到1s的时间。如果你发现创建目录超过1分钟及以上,而且这个现象并不是每次都有。只是偶尔慢了一下,就很有可能存在慢磁盘。
可以采用如下方法找出是哪块磁盘慢:
1)通过心跳未联系时间。
一般出现慢磁盘现象,会影响到DataNode与NameNode之间的心跳。正常情况心跳时间间隔是3s。超过3s说明有异常。

2)fio命令,测试磁盘的读写性能
(1)顺序读测试
yum install -y fio
fio -filename=/home/atguigu/test.log -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_r
Run status group 0 (all jobs):
READ: bw=360MiB/s (378MB/s), 360MiB/s-360MiB/s (378MB/s-378MB/s), io=20.0GiB (21.5GB), run=56885-56885msec
- 1
- 2
- 3
- 4
- 5
结果显示,磁盘的总体顺序读速度为360MiB/s。
(2)顺序写测试
fio -filename=/home/atguigu/test.log -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_w
Run status group 0 (all jobs):
WRITE: bw=341MiB/s (357MB/s), 341MiB/s-341MiB/s (357MB/s-357MB/s), io=19.0GiB (21.4GB), run=60001-60001msec
- 1
- 2
- 3
- 4
结果显示,磁盘的总体顺序写速度为341MiB/s。
(3)随机写测试
fio -filename=/home/atguigu/test.log -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_randw
Run status group 0 (all jobs):
WRITE: bw=309MiB/s (324MB/s), 309MiB/s-309MiB/s (324MB/s-324MB/s), io=18.1GiB (19.4GB), run=60001-60001msec
- 1
- 2
- 3
- 4
结果显示,磁盘的总体随机写速度为309MiB/s。
(4)混合随机读写
fio -filename=/home/atguigu/test.log -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=test_r_w -ioscheduler=noop
Run status group 0 (all jobs):
READ: bw=220MiB/s (231MB/s), 220MiB/s-220MiB/s (231MB/s-231MB/s), io=12.9GiB (13.9GB), run=60001-60001msec
WRITE: bw=94.6MiB/s (99.2MB/s), 94.6MiB/s-94.6MiB/s (99.2MB/s-99.2MB/s), io=5674MiB (5950MB), run=60001-60001msec
- 1
- 2
- 3
- 4
- 5
结果显示,磁盘的总体混合随机读写,读速度为220MiB/s,写速度94.6MiB/s****。
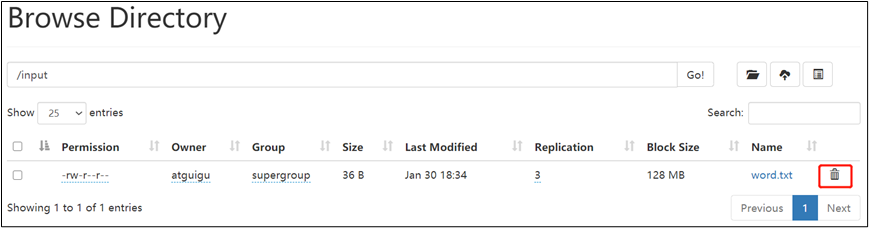
6.4 小文件归档
1)HDFS存储小文件弊端
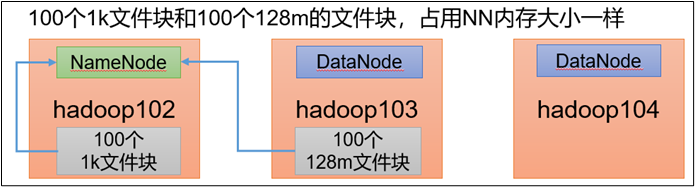
每个文件均按块存储,每个块的元数据存储在NameNode的内存中,因此HDFS存储小文件会非常低效。因为大量的小文件会耗尽NameNode中的大部分内存。但注意,存储小文件所需要的磁盘容量和数据块的大小无关。例如,一个1MB的文件设置为128MB的块存储,实际使用的是1MB的磁盘空间,而不是128MB。
2)解决存储小文件办法之一
HDFS存档文件或HAR文件,是一个更高效的文件存档工具,它将文件存入HDFS块,在减少NameNode内存使用的同时,允许对文件进行透明的访问。具体说来,HDFS存档文件对内还是一个一个独立文件,对NameNode而言却是一个整体,减少了NameNode的内存。

3)实例操作
(1)需要启动 YARN 进程
start-yarn.sh
- 1
(2)归档文件
把 /input 目录里面的所有文件归档成一个叫 input.har 的归档文件,并把归档后文件存储到 /output 路径下。
hadoop archive -archiveName input.har -p /input /output
- 1
(3)查看归档
hadoop fs -ls /output/input.har
- 1
(4)解归档文件
hadoop fs -cp har:///output/input.har/* /
- 1
第7章 HDFS-集群迁移
7.1 Apache 和 Apache 集群间数据拷贝
1)scp 实现两个远程主机之间的文件复制
# 推 push
scp -r hello.txt root@hadoop103:/root/tmp/hello.txt
# 拉 pull
scp -r root@hadoop103:/root/tmp/hello.txt hello.txt
# 是通过本地主机中转实现两个远程主机的文件复制;如果在两个远程主机之间 ssh 没有配置的情况下可以使用该方式。
scp -r root@hadoop103:/root/tmp/hello.txt root@hadoop104:/root/tmp
- 1
- 2
- 3
- 4
- 5
- 6
2)采用 distcp 命令实现两个 Hadoop 集群之间的递归数据复制
hadoop distcp hdfs://hadoop102:8020/user/atguigu/hello.txt hdfs://hadoop105:8020/user/atguigu/hello.txt
- 1
7.2 Apache 和 CDH 集群间拷贝数据
迁移数据
1)准备两套集群,我这使用apache集群和CDH集群。
2)启动集群
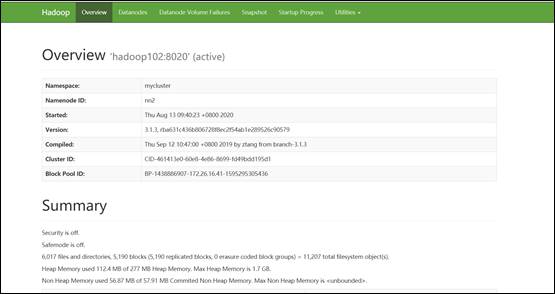
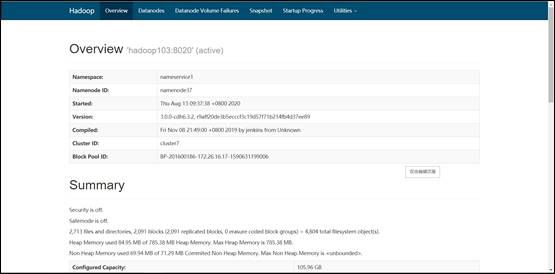
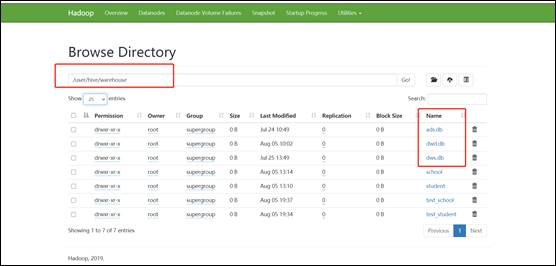
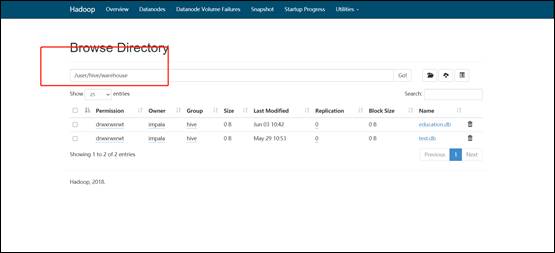
3)启动完毕后,将apache集群中,hive库里dwd,dws,ads三个库的数据迁移到CDH集群
4)在 apache 集群里 hosts 加上 CDH Namenode 对应域名并分发给各机器
vim /etc/hosts
- 1
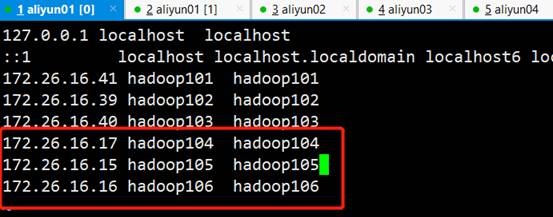
# 分发数据
xsync /etc/hosts
- 1
- 2
5)因为集群都是 HA(高可用)模式,所以需要在 apache 集群上配置 CDH 集群,让 distcp 能识别出 CDH 的 nameservice
修改 hdfs-site.xml
<!--配置nameservice--> <property> <name>dfs.nameservices</name> <value>mycluster,nameservice1</value> </property> <!--指定本地服务--> <property> <name>dfs.internal.nameservices</name> <value>mycluster,nameservice1</value> </property> <!--配置多NamenNode--> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2,nn3</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>hadoop101:8020</value> </property> <property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>hadoop102:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn3</name> <value>hadoop103:8020</value> </property> <!--配置nameservice1的namenode服务--> <property> <name>dfs.ha.namenodes.nameservice1</name> <value>namenode30,namenode37</value> </property> <property> <name>dfs.namenode.rpc-address.nameservice1.namenode30</name> <value>hadoop104:8020</value> </property> <property> <name>dfs.namenode.rpc-address.nameservice1.namenode37</name> <value>hadoop106:8020</value> </property> <property> <name>dfs.namenode.http-address.nameservice1.namenode30</name> <value>hadoop104:9870</value> </property> <property> <name>dfs.namenode.http-address.nameservice1.namenode37</name> <value>hadoop106:9870</value> </property> <property> <name>dfs.client.failover.proxy.provider.nameservice1</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <!--为NamneNode设置HTTP服务监听--> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>hadoop101:9870</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>hadoop102:9870</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn3</name> <value>hadoop103:9870</value> </property> <!--配置HDFS客户端联系Active NameNode节点的Java类--> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
6)修改 CDH host
vim /etc/hosts
- 1
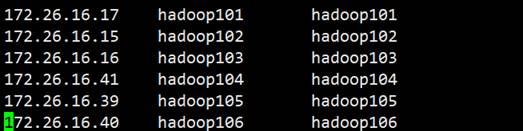
7)进行分发,这里的hadoop104,hadoop105,hadoop106分别对应apache的hadoop101,hadoop102,hadoop103
xsync /etc/hosts
- 1
8)同样修改 CDH 集群配置,在所有 hdfs-site.xml 文件里修改配置
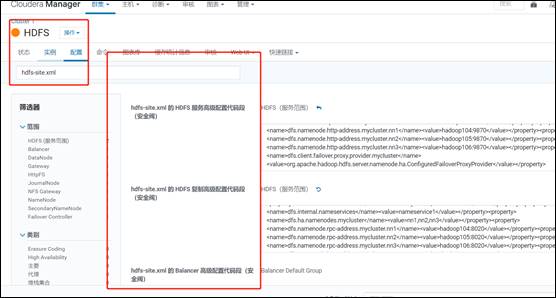
<property> <name>dfs.nameservices</name> <value>mycluster,nameservice1</value> </property> <property> <name>dfs.internal.nameservices</name> <value>nameservice1</value> </property> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2,nn3</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name> <value>hadoop104:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name> <value>hadoop105:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn3</name> <value>hadoop106:8020</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>hadoop104:9870</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>hadoop105:9870</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn3</name> <value>hadoop106:9870</value> </property> <property> <name>dfs.client.failover.proxy.provider.mycluster</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
9)最后注意:重点由于我的 Apahce 集群和 CDH 集群3台集群都是 hadoop101,hadoop102,hadoop103所以要关闭域名访问,使用IP访问
CDH把钩去了
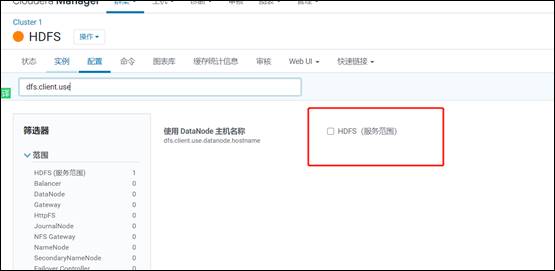
10)Apache 设置为 false
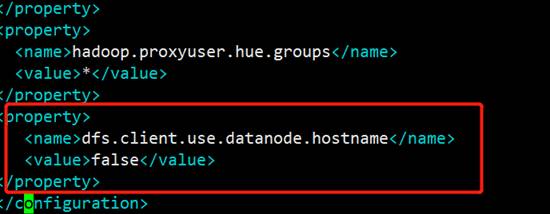
11)再使用 hadoop distcp 命令进行迁移,-Dmapred.job.queue.name 指定队列,默认是 default 队列。上面配置集群都配了的话,那么在 CDH 和 apache 集群下都可以执行这个命令
hadoop distcp -Dmapred.job.queue.name=hive webhdfs://mycluster:9070/user/hive/warehouse/dwd.db/ hdfs://nameservice1/user/hive/warehouse
- 1
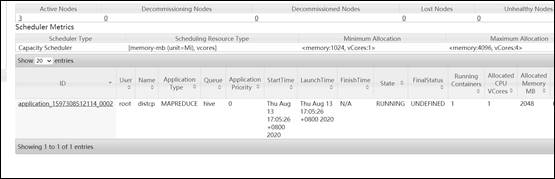
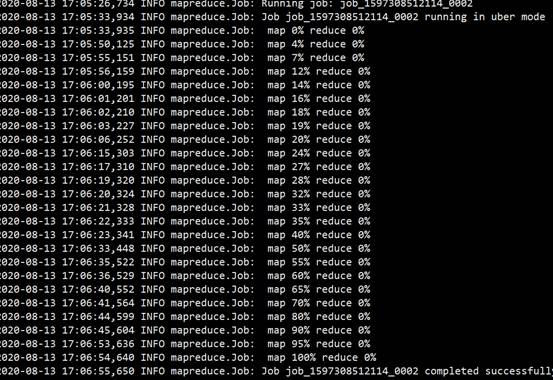
12)会启动一个 MR 任务,正在迁移
13)查看 cdh 9870 http 地址
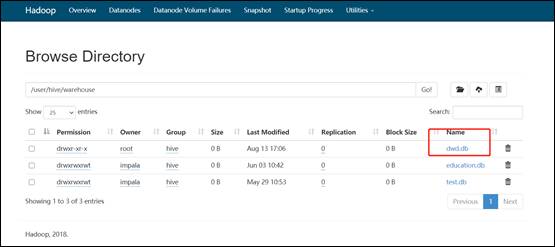
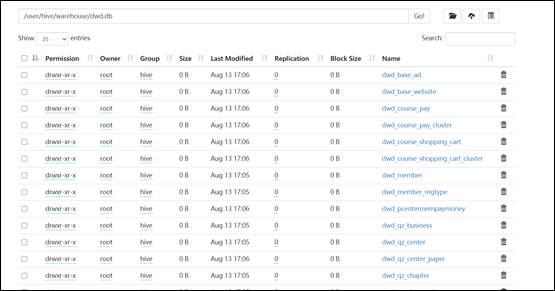
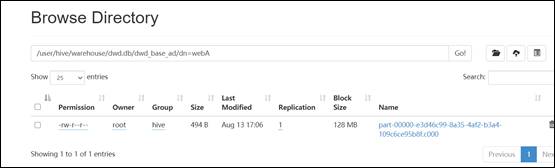
14)数据已经成功迁移。数据迁移成功之后,接下来迁移 hive 表结构,编写 shell 脚本
#!/bin/bash
hive -e "use dwd;show tables">tables.txt
cat tables.txt |while read eachline
do
hive -e "use dwd;show create table $eachline">>tablesDDL.txt
echo ";" >> tablesDDL.txt
done
- 1
- 2
- 3
- 4
- 5
- 6
- 7
15)执行脚本后将 tablesDDL.txt 文件分发到 CDH 集群下
xsync tablesDDL.txt
- 1
16)然后 CDH 下导入此表结构,先进到 CDH 的 hive 里创建 dwd 库
hive
hive> create database dwd;
- 1
- 2
17)创建数据库后,边界 tablesDDL.txt 在最上方加上 use dwd;
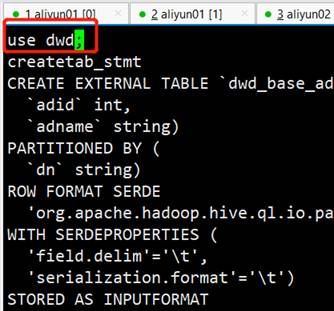
18)并且将 createtab_stmt 都替换成空格
sed -i "s#createtab_stmt# #g" tablesDDL.txt
- 1
19)最后执行 hive -f 命令将表结构导入
hive -f tablesDDL.txt
- 1
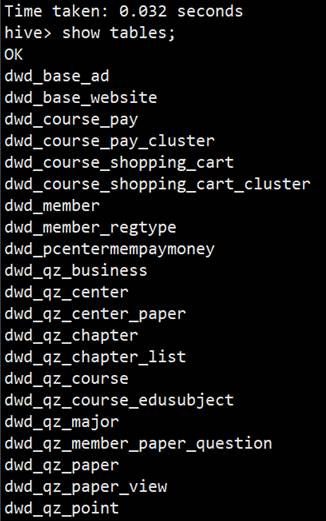
20)最后将表的分区重新刷新下,只有刷新分区才能把数据读出来,编写脚本
vim msckPartition.sh
#!/bin/bash
hive -e "use dwd;show tables">tables.txt
cat tables.txt |while read eachline
do
hive -e "use dwd;MSCK REPAIR TABLE $eachline"
done
[root@hadoop101 module]# chmod +777 msckPartition.sh
[root@hadoop101 module]# ./msckPartition.sh
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
21)刷新完分区后,查询表数据
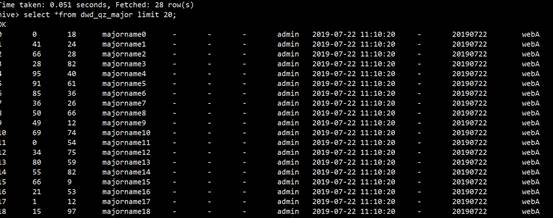
第8章 MapReduce 生产经验
8.1 MapReduce 跑得慢的原因
MapReduce程序效率的瓶颈在于两点:
1)计算机性能
CPU、内存、磁盘、网络
2)I/O操作优化
(1)数据倾斜
(2)Map运行时间太长,导致Reduce等待过久
(3)小文件过多
8.2 MapReduce 常用调优参数
MapReduce 优化 1
1)自定义分区,减少数据倾斜
定义类,继承 Partitioner 接口,重写 getPartition 方法
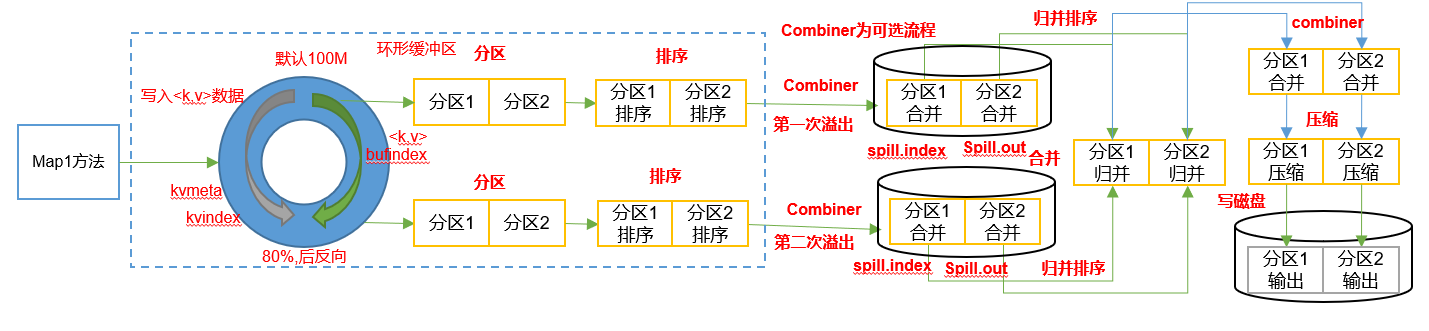
2)减少溢写次数
mapreduce.task.io.sort.mb
Shuffle的环形缓冲区大小,默认100m,可以提高到200m
mapreduce.map.sort.spill.percent
环形缓冲区溢出的阈值,默认80% ,可以提高到90%
3)增加每次 Merge 合并次数
mapreduce.task.io.sort.factor默认10,可以提高到20
4)在不影响业务结果的前提条件下可以提前采用Combiner
job.setCombinerClass(xxxReducer.class);
5)为了减少磁盘 IO,可以采用 Snappy 或者 LZO 压缩
conf.setBoolean(“mapreduce.map.output.compress”, true);
conf.setClass(“mapreduce.map.output.compress.codec”, SnappyCodec.class,CompressionCodec.class);
6)mapreduce.map.memory.mb 默认 MapTask 内存上限1024MB。
可以根据128m 数据对应1G内存原则提高该内存。
7)mapreduce.map.java.opts:控制MapTask堆内存大小。(如果内存不够,报:java.lang.OutOfMemoryError)
8)mapreduce.map.cpu.vcores 默认 MapTask 的 CPU 核数 1。计算密集型任务可以增加 CPU 核数
9)异常重试
mapreduce.map.maxattempts每个Map Task最大重试次数,一旦重试次数超过该值,则认为Map Task运行失败,默认值:4。根据机器性能适当提高。
MapReduce 优化 2
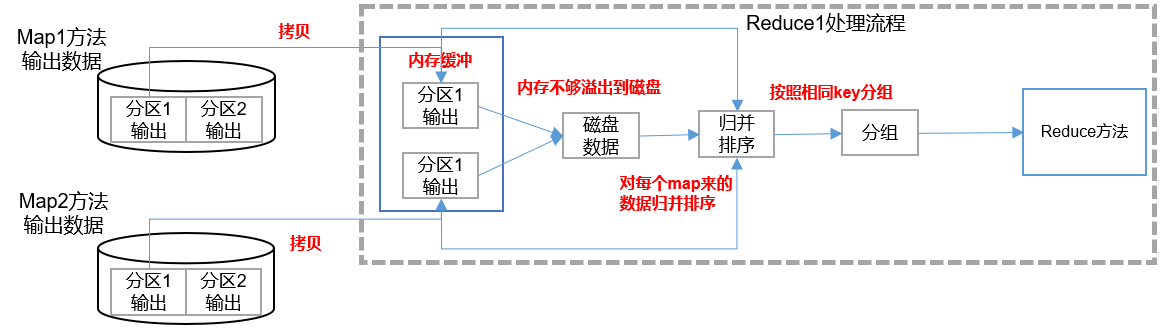
1)mapreduce.reduce.shuffle.parallelcopies 每个 Reduce 去 Map 中拉取数据的并行数,默认值是5。可以提高到10。
2)mapreduce.reduce.shuffle.input.buffer.percent Buffer 大小占 Reduce 可用内存的比例,默认值0.7。可以提高到0.8
3)mapreduce.reduce.shuffle.merge.percent Buffer中的数据达到多少比例开始写入磁盘,默认值0.66。可以提高到0.75
4)mapreduce.reduce.memory.mb 默认ReduceTask内存上限1024MB,根据128m数据对应1G内存原则,适当提高内存到4-6G
5)mapreduce.reduce.java.opts:控制ReduceTask堆内存大小。(如果内存不够,报:java.lang.OutOfMemoryError)
6)mapreduce.reduce.cpu.vcores 默认 ReduceTask 的 CPU 核数1个。可以提高到 2-4 个
7)mapreduce.reduce.maxattempts 每个Reduce Task 最大重试次数,一旦重试次数超过该值,则认为Map Task运行失败,默认值:4。
8)mapreduce.job.reduce.slowstart.completedmaps 当 MapTask 完成的比例达到该值后才会为 ReduceTask 申请资源。默认是0.05。
9)mapreduce.task.timeout 如果一个Task在一定时间内没有任何进入,即不会读取新的数据,也没有输出数据,则认为该Task处于Block状态,可能是卡住了,也许永远会卡住,为了防止因为用户程序永远Block住不退出,则强制设置了一个该超时时间(单位毫秒),默认是600000(10分钟)。如果你的程序对每条输入数据的处理时间过长,建议将该参数调大。
10)如果可以不用Reduce,尽可能不用
8.3 MapReduce 数据倾斜问题
1)数据倾斜现象
数据频率倾斜——某一个区域的数据量要远远大于其他区域。
数据大小倾斜——部分记录的大小远远大于平均值。
2)减少数据倾斜的方法
(1)首先检查是否空值过多造成的数据倾斜
生产环境,可以直接过滤掉空值;如果想保留空值,就自定义分区,将空值加随机数打散。最后再二次聚合。
(2)能在map阶段提前处理,最好先在Map阶段处理。如:Combiner、MapJoin
(3)设置多个reduce个数
第9章 Hadoop-YARN 生产经验
9.1 常用的调优参数
1)调优参数列表
(1)Resourcemanager 相关
# 处理调度器请求的线程数量
yarn.resourcemanager.scheduler.client.thread-count ResourceManager
# 配置调度器
yarn.resourcemanager.scheduler.class
- 1
- 2
- 3
- 4
(2)Nodemanager 相关
# NodeManager使用内存数 yarn.nodemanager.resource.memory-mb # NodeManager为系统保留多少内存,和上一个参数二者取一即可 yarn.nodemanager.resource.system-reserved-memory-mb # NodeManager使用CPU核数 yarn.nodemanager.resource.cpu-vcores # 是否将虚拟核数当作CPU核数 yarn.nodemanager.resource.count-logical-processors-as-cores # 虚拟核数和物理核数乘数,例如:4核8线程,该参数就应设为2 yarn.nodemanager.resource.pcores-vcores-multiplier # 是否让yarn自己检测硬件进行配置 yarn.nodemanager.resource.detect-hardware-capabilities # 是否开启物理内存检查限制container yarn.nodemanager.pmem-check-enabled # 是否开启虚拟内存检查限制container yarn.nodemanager.vmem-check-enabled # 虚拟内存物理内存比例 yarn.nodemanager.vmem-pmem-ratio
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
(3)Container 容器相关
# 容器最小内存
yarn.scheduler.minimum-allocation-mb
# 容器最大内存
yarn.scheduler.maximum-allocation-mb
# 容器最小核数
yarn.scheduler.minimum-allocation-vcores
# 容器最大核数
yarn.scheduler.maximum-allocation-vcores
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
第10章 Hadoop 综合调优
10.1 Hadoop 小文件优化方法
10.1.1 Hadoop 小文件弊端
HDFS上 每个文件都要在 NameNode 上创建对应的元数据,这个元数据的大小约为 150byte,这样当小文件比较多的时候,就会产生很多的元数据文件,一方面会大量占用 NameNode 的内存空间,另一方面就是元数据文件过多,使得寻址索引速度变慢。
小文件过多,在进行MR计算时,会生成过多切片,需要启动过多的 MapTask。每个 MapTask 处理的数据量小,导致 MapTask 的处理时间比启动时间还小,白白消耗资源。
10.1.2 Hadoop小文件解决方案
1)在数据采集的时候,就将小文件或小批数据合成大文件再上传 HDFS(数据源头)
2)Hadoop Archive(存储方向)
是一个高效的将小文件放入HDFS块中的文件存档工具,能够将多个小文件打包成一个HAR文件,从而达到减少NameNode的内存使用
3)CombineTextInputFormat(计算方向)
CombineTextInputFormat用于将多个小文件在切片过程中生成一个单独的切片或者少量的切片。
4)开启uber模式,实现JVM重用(计算方向)
默认情况下,每个Task任务都需要启动一个JVM来运行,如果Task任务计算的数据量很小,我们可以让同一个Job的多个Task运行在一个JVM中,不必为每个Task都开启一个JVM。
(1)未开启uber模式,在 /input 路径上上传多个小文件并执行 wordcount 程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output2
- 1
(2)观察控制台
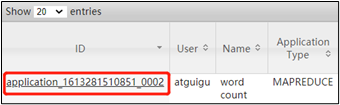
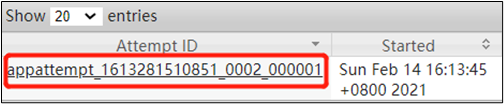
2021-02-14 16:13:50,607 INFO mapreduce.Job: Job job_1613281510851_0002 running in uber mode : false
- 1
(3)观察 http://hadoop103:8088/cluster

(4)开启uber模式,在 mapred-site.xml 中添加如下配置
<!-- 开启uber模式,默认关闭 --> <property> <name>mapreduce.job.ubertask.enable</name> <value>true</value> </property> <!-- uber模式中最大的mapTask数量,可向下修改 --> <property> <name>mapreduce.job.ubertask.maxmaps</name> <value>9</value> </property> <!-- uber模式中最大的reduce数量,可向下修改 --> <property> <name>mapreduce.job.ubertask.maxreduces</name> <value>1</value> </property> <!-- uber模式中最大的输入数据量,默认使用dfs.blocksize 的值,可向下修改 --> <property> <name>mapreduce.job.ubertask.maxbytes</name> <value></value> </property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
(5)分发配置
xsync mapred-site.xml
- 1
(6)再次执行 wordcount 程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output2
- 1
(7)观察控制台
2021-02-14 16:28:36,198 INFO mapreduce.Job: Job job_1613281510851_0003 running in uber mode : true
- 1
(8)观察 http://hadoop103:8088/cluster

10.2 测试MapReduce计算性能
使用Sort程序评测MapReduce
注:一个虚拟机不超过 150G 磁盘尽量不要执行这段代码
(1)使用 RandomWriter 来产生随机数,每个节点运行10个 Map 任务,每个 Map 产生大约 1G 大小的二进制随机数
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar randomwriter random-data
- 1
(2)执行Sort程序
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar sort random-data sorted-data
- 1
(3)验证数据是否真正排好序了
hadoop jar /opt/module/hadoop-3.1.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar testmapredsort -sortInput random-data -sortOutput sorted-data
- 1
10.3 企业开发场景案例
10.3.1 需求
(1)需求:从1G数据中,统计每个单词出现次数。服务器3台,每台配置4G内存,4核CPU,4线程。
(2)需求分析:
1G / 128m = 8个MapTask;1个ReduceTask;1个mrAppMaster
平均每个节点运行10个 / 3台 ≈ 3个任务(4 3 3)
10.3.2 HDFS 参数调优
(1)修改:hadoop-env.sh
export HDFS_NAMENODE_OPTS="-Dhadoop.security.logger=INFO,RFAS -Xmx1024m"
export HDFS_DATANODE_OPTS="-Dhadoop.security.logger=ERROR,RFAS -Xmx1024m"
- 1
- 2
- 3
(2)修改 hdfs-site.xml
<!-- NameNode有一个工作线程池,默认值是10 -->
<property>
<name>dfs.namenode.handler.count</name>
<value>21</value>
</property>
- 1
- 2
- 3
- 4
- 5
(3)修改 core-site.xml
<!-- 配置垃圾回收时间为60分钟 -->
<property>
<name>fs.trash.interval</name>
<value>60</value>
</property>
- 1
- 2
- 3
- 4
- 5
(4)分发配置
xsync hadoop-env.sh hdfs-site.xml core-site.xml
- 1
10.3.3 MapReduce参数调优
(1)修改 mapred-site.xml
<!-- 环形缓冲区大小,默认100m --> <property> <name>mapreduce.task.io.sort.mb</name> <value>100</value> </property> <!-- 环形缓冲区溢写阈值,默认0.8 --> <property> <name>mapreduce.map.sort.spill.percent</name> <value>0.80</value> </property> <!-- merge合并次数,默认10个 --> <property> <name>mapreduce.task.io.sort.factor</name> <value>10</value> </property> <!-- maptask内存,默认1g; maptask堆内存大小默认和该值大小一致mapreduce.map.java.opts --> <property> <name>mapreduce.map.memory.mb</name> <value>-1</value> <description>The amount of memory to request from the scheduler for each map task. If this is not specified or is non-positive, it is inferred from mapreduce.map.java.opts and mapreduce.job.heap.memory-mb.ratio. If java-opts are also not specified, we set it to 1024. </description> </property> <!-- matask的CPU核数,默认1个 --> <property> <name>mapreduce.map.cpu.vcores</name> <value>1</value> </property> <!-- matask异常重试次数,默认4次 --> <property> <name>mapreduce.map.maxattempts</name> <value>4</value> </property> <!-- 每个Reduce去Map中拉取数据的并行数。默认值是5 --> <property> <name>mapreduce.reduce.shuffle.parallelcopies</name> <value>5</value> </property> <!-- Buffer大小占Reduce可用内存的比例,默认值0.7 --> <property> <name>mapreduce.reduce.shuffle.input.buffer.percent</name> <value>0.70</value> </property> <!-- Buffer中的数据达到多少比例开始写入磁盘,默认值0.66。 --> <property> <name>mapreduce.reduce.shuffle.merge.percent</name> <value>0.66</value> </property> <!-- reducetask内存,默认1g;reducetask堆内存大小默认和该值大小一致mapreduce.reduce.java.opts --> <property> <name>mapreduce.reduce.memory.mb</name> <value>-1</value> <description>The amount of memory to request from the scheduler for each reduce task. If this is not specified or is non-positive, it is inferred from mapreduce.reduce.java.opts and mapreduce.job.heap.memory-mb.ratio. If java-opts are also not specified, we set it to 1024. </description> </property> <!-- reducetask的CPU核数,默认1个 --> <property> <name>mapreduce.reduce.cpu.vcores</name> <value>2</value> </property> <!-- reducetask失败重试次数,默认4次 --> <property> <name>mapreduce.reduce.maxattempts</name> <value>4</value> </property> <!-- 当MapTask完成的比例达到该值后才会为ReduceTask申请资源。默认是0.05 --> <property> <name>mapreduce.job.reduce.slowstart.completedmaps</name> <value>0.05</value> </property> <!-- 如果程序在规定的默认10分钟内没有读到数据,将强制超时退出 --> <property> <name>mapreduce.task.timeout</name> <value>600000</value> </property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
(2)分发配置
xsync mapred-site.xml
- 1
10.3.4 Yarn 参数调优
(1)修改 yarn-site.xml 配置参数如下:
<!-- 选择调度器,默认容量 --> <property> <description>The class to use as the resource scheduler.</description> <name>yarn.resourcemanager.scheduler.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value> </property> <!-- ResourceManager处理调度器请求的线程数量,默认50;如果提交的任务数大于50,可以增加该值,但是不能超过3台 * 4线程 = 12线程(去除其他应用程序实际不能超过8) --> <property> <description>Number of threads to handle scheduler interface.</description> <name>yarn.resourcemanager.scheduler.client.thread-count</name> <value>8</value> </property> <!-- 是否让yarn自动检测硬件进行配置,默认是false,如果该节点有很多其他应用程序,建议手动配置。如果该节点没有其他应用程序,可以采用自动 --> <property> <description>Enable auto-detection of node capabilities such as memory and CPU. </description> <name>yarn.nodemanager.resource.detect-hardware-capabilities</name> <value>false</value> </property> <!-- 是否将虚拟核数当作CPU核数,默认是false,采用物理CPU核数 --> <property> <description>Flag to determine if logical processors(such as hyperthreads) should be counted as cores. Only applicable on Linux when yarn.nodemanager.resource.cpu-vcores is set to -1 and yarn.nodemanager.resource.detect-hardware-capabilities is true. </description> <name>yarn.nodemanager.resource.count-logical-processors-as-cores</name> <value>false</value> </property> <!-- 虚拟核数和物理核数乘数,默认是1.0 --> <property> <description>Multiplier to determine how to convert phyiscal cores to vcores. This value is used if yarn.nodemanager.resource.cpu-vcores is set to -1(which implies auto-calculate vcores) and yarn.nodemanager.resource.detect-hardware-capabilities is set to true. The number of vcores will be calculated as number of CPUs * multiplier. </description> <name>yarn.nodemanager.resource.pcores-vcores-multiplier</name> <value>1.0</value> </property> <!-- NodeManager使用内存数,默认8G,修改为4G内存 --> <property> <description>Amount of physical memory, in MB, that can be allocated for containers. If set to -1 and yarn.nodemanager.resource.detect-hardware-capabilities is true, it is automatically calculated(in case of Windows and Linux). In other cases, the default is 8192MB. </description> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property> <!-- nodemanager的CPU核数,不按照硬件环境自动设定时默认是8个,修改为4个 --> <property> <description>Number of vcores that can be allocated for containers. This is used by the RM scheduler when allocating resources for containers. This is not used to limit the number of CPUs used by YARN containers. If it is set to -1 and yarn.nodemanager.resource.detect-hardware-capabilities is true, it is automatically determined from the hardware in case of Windows and Linux. In other cases, number of vcores is 8 by default.</description> <name>yarn.nodemanager.resource.cpu-vcores</name> <value>4</value> </property> <!-- 容器最小内存,默认1G --> <property> <description>The minimum allocation for every container request at the RM in MBs. Memory requests lower than this will be set to the value of this property. Additionally, a node manager that is configured to have less memory than this value will be shut down by the resource manager. </description> <name>yarn.scheduler.minimum-allocation-mb</name> <value>1024</value> </property> <!-- 容器最大内存,默认8G,修改为2G --> <property> <description>The maximum allocation for every container request at the RM in MBs. Memory requests higher than this will throw an InvalidResourceRequestException. </description> <name>yarn.scheduler.maximum-allocation-mb</name> <value>2048</value> </property> <!-- 容器最小CPU核数,默认1个 --> <property> <description>The minimum allocation for every container request at the RM in terms of virtual CPU cores. Requests lower than this will be set to the value of this property. Additionally, a node manager that is configured to have fewer virtual cores than this value will be shut down by the resource manager. </description> <name>yarn.scheduler.minimum-allocation-vcores</name> <value>1</value> </property> <!-- 容器最大CPU核数,默认4个,修改为2个 --> <property> <description>The maximum allocation for every container request at the RM in terms of virtual CPU cores. Requests higher than this will throw an InvalidResourceRequestException.</description> <name>yarn.scheduler.maximum-allocation-vcores</name> <value>2</value> </property> <!-- 虚拟内存检查,默认打开,修改为关闭 --> <property> <description>Whether virtual memory limits will be enforced for containers.</description> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property> <!-- 虚拟内存和物理内存设置比例,默认2.1 --> <property> <description>Ratio between virtual memory to physical memory when setting memory limits for containers. Container allocations are expressed in terms of physical memory, and virtual memory usage is allowed to exceed this allocation by this ratio. </description> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>2.1</value> </property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
(2)分发配置
xsync yarn-site.xml
- 1
10.3.5 执行程序
(1)重启集群
stop-yarn.sh
start-yarn.sh
- 1
- 2
(2)执行 WordCount 程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /input /output
- 1
(3)观察Yarn任务执行页面 http://hadoop103:8088/cluster/apps


