
- 19、yolov5s.yaml文件解读_yolov5 yolov5s6.yaml
- 2Linux 基础(七)常用命令 - 磁盘分区命令_linux磁盘分区命令
- 3C# 1.消息队列MQ使用场景--图文解析
- 4ChatGLM相关内容链接,供参考_chatglm官网
- 5Unity 百度SDK 之 在线语音合成 TTS WebAPI 功能的实现_unity 百度在线语音合成怎么使用
- 6Elasticsearch-集群架构详解
- 7TabNine代码补全工具使用体验
- 8Nature | 机器学习在药物研发中的应用_机器学习及自动化技术在医药研发领域的应用
- 9Pywinauto常用02--pywin32(Python调用win api)_pywin32怎么用
- 10(15)点云数据处理学习——单目深度估计获得RGBD图再重建点云_深度图像和rgb图像生成点云数据
FHIR 生态_forge fhir
赞
踩
原文在这里
2023年6月底,世卫组织(WHO)和HL7签署了合作协议,利用HL7 FHIR提供互操作性,来支撑WHO的SMART指南(SMART Guideline)愿景 - 使用数智化的方式推动并加速一致化的健康干预措施建议,让世界上每个人都能立即从临床、公卫和数据使用建议中充分受益。
作为WHO的《2020-2025 年全球数字卫生战略》的一部分,SMART 指南使用 FHIR 、HL7的临床质量语言 (CQL) 和ICD标准以表达 WHO 的各种健康和临床指南,实现数据互操作、决策支持与指标、术语的一致性。这些标准被进一步利用来为各国及其合作伙伴开发一个由软件库、服务和工具组成的支持生态系统,并作为数字公共产品服务全球卫生健康事业。

为什么世卫组织会采用FHIR作为卫生信息互操作的标准在全球推广其一致化的健康干预措施建议?因为FHIR不仅标准成熟适用,而且还具有一个极具生命力的生态。
一个有生命力的标准会吸引生态的构建,而完善的生态将促进标准的成熟和演进。HL7 FHIR作为新一代的卫生信息互操作标准,其生态已经初具规模并蓬勃发展。
HL7 FHIR的知识产权类型
HL7 FHIR的知识产权是CC0,也就是知识共享。任何机构、组织和个人都可以无需向HL7申请而免费使用、扩展FHIR的标准。其知识产权类型配合FHIR标准的丰满程度,极大地鼓励和促进了基于FHIR的生态建设,应该也是WHO采用FHIR的原因之一。
FHIR的标准发布和标准的推广
标准应该是方便可及的 - 不仅有用户可阅读、可理解的文字说明,更需要要可以直接下载让计算机可用、可理解的电子结构化标准。
HL7 FHIR官网详细说明了每个版本、每个FHIR资源的结构与关系、使用范围、用例和示例。在下载页面提供了各种版本的标准、值集、profile和工具的免费下载。
对于用户的扩展、再约束和实施指南,有专门的实施指南注册和发布网站。这里可以免费注册自己的实施指南、也可以访问、查阅和下载别人的实施指南,从而让基于FHIR标准的自定义扩展可以无障碍地被分享、使用、理解,甚至进一步扩展。
下图是发布在注册网站的按用例类型统计的FHIR实施指南:
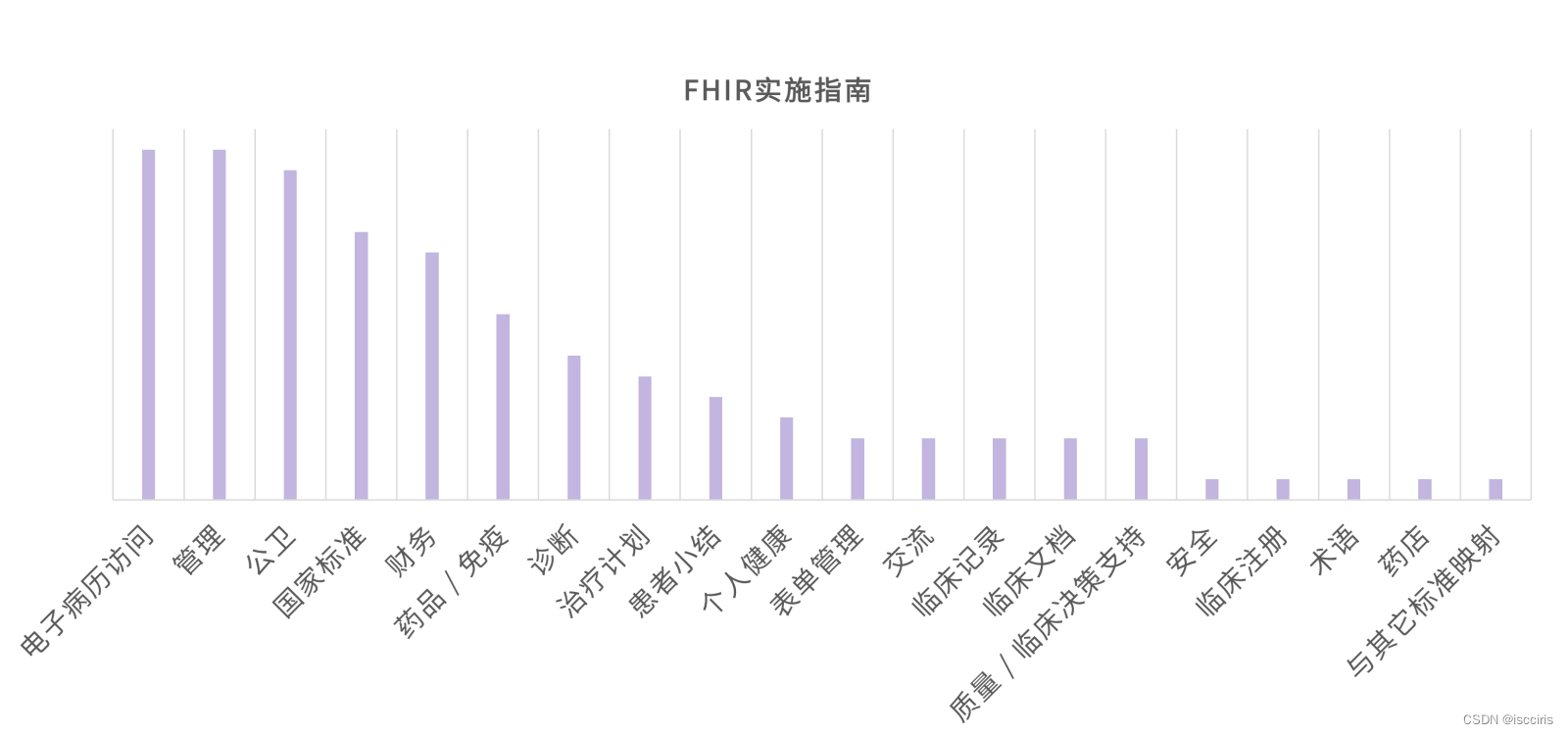
这众多方向的实施指南也是FHIR横跨交叉领域建立起成熟生态的体现。FHIR有什么快速建立生态的秘诀?
成熟的卫生信息标准要能应对各种行业互操作挑战,FHIR有一个四层机制用于制定标准并用各种互操作挑战来测试、验证和推进FHIR落地:
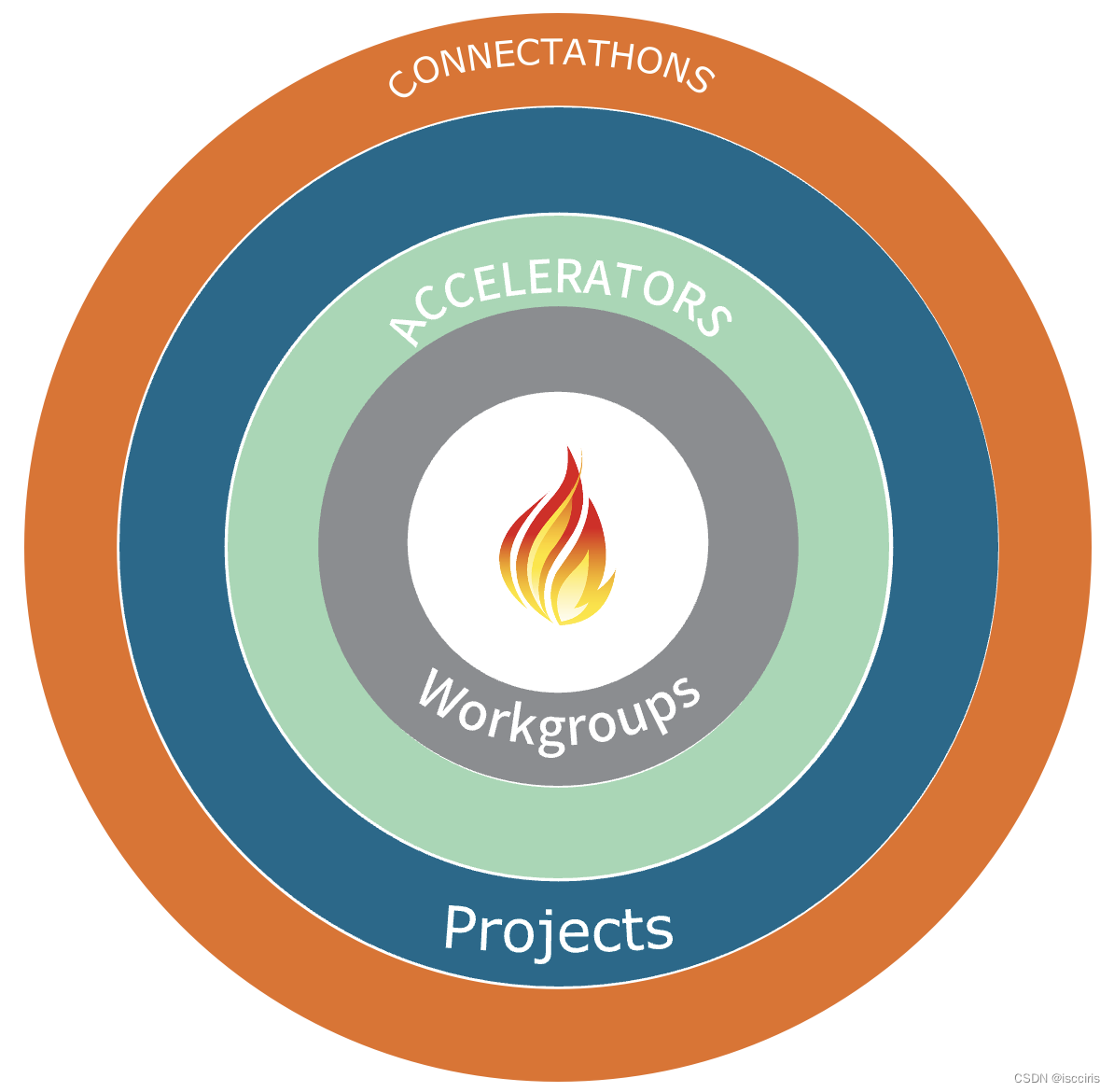
工作组(workgroups):FHIR有40多个工作组,专注不同的领域的需求,并制定和改进相关FHIR资源和用例标准。例如FHIR基础架构、基因组学、电子健康档案、财务管理、设备…
加速器计划(accelerators):为了推进在主要互操作领域的成熟和落地,FHIR建立加速器计划让每个领域的各个利益相关方参与进来,通过研究各方的需求、凝聚各方的智慧来推动FHIR。如今已经有8个不同领域的加速器计划:

例如Vulcan是专注连接临床研究、转化研究和医疗保健的加速器,它的成员不仅有HL7这样的标准开发组织,还有学会 - 例如约翰霍普金斯医学院,行业协会 - 例如全球医疗数据科学社区PHUSE,政府机构 - 例如FDA,技术厂商 - 例如InterSystems,药厂 - 例如GSK,甚至意见领袖。

课题(projects):FHIR通过课题,研究具体的需求、实现具体的目标,让FHIR扎实、可用。例如Vulcan加速器有以下课题:
| 课题 | 目标 |
|---|---|
| Schedule of Activities (SoA)活动安排 | 用FHIR表示电子表格中的活动时间表。 使得研究中的每项活动的描述、时间和标识都能保持一致 |
| Real World Data (RWD) 真实世界数据 | 以标准化的格式从EHR中提取数据,以支持临床研究,特别是向监管机构提交数据 |
| Phenotypic Data 表型数据 | 为基因组研究和基因组医学提供更多高质量的标准化表型信息 |
| Electronic Product Information (ePI) 电子产品信息 | 为产品信息(各论)定义一个共同的结构,支持患者对产品数据的跨边界交换 |
| Adverse Events (AE)不良事件 | 支持对不良事件的报告和格式进行标准化。 提高相关FHIR资源的成熟度 |
| FHIR to OMOP映射 | 支持开发FHIR到OMOP的数据传输,以便更好地分析临床数据,用于研究 |
连接测试马拉松(connectathons):这是一个针对技术厂商的FHIR互操作系列化的一致性认证。每年3次的连接测试马拉松会确定众多的具体互操作用例,厂商选择并参与这些用例,用FHIR进行跨厂商的互操作测试。它不仅是技术厂商验证自己的FHIR互操作一致性的试验场,更是通过测试和反馈来发现标准的问题、确定标准适用性的大型沟通会。
FHIR confluence上公布有历次的连接测试马拉松的用例说明、实施指南、学习资料等详尽的资料。
除了这些手段,HL7还有FHIR认证,建立FHIR标准的智力资源池、确保FHIR在全球的正确采纳。
FHIR标准的适应性
FHIR的适应性核心在于其标准的设计 - 通过profile,在资源模型层面已经考虑到如何让用户进行不破坏标准的扩展和再约束;在标准成熟上,设计了成熟度模型,让标准基于实际使用和反馈逐步成熟。
Profile可以让用户裁剪、扩展FHIR标准,以适用于自己的术语体系和用例场景,实现基于统一标准的千人千面。
在标准的理解与反馈上,FHIR官方沟通提供了开放的交流和反馈的渠道。
FHIR生态的工具
成熟的生态工具是FHIR的一大亮点。这些工具是整个生态贡献的,好的工具得到广泛认同和采纳,既促进了标准的理解与使用、也避免了低水平的重复建设。
1. 标准学习工具:
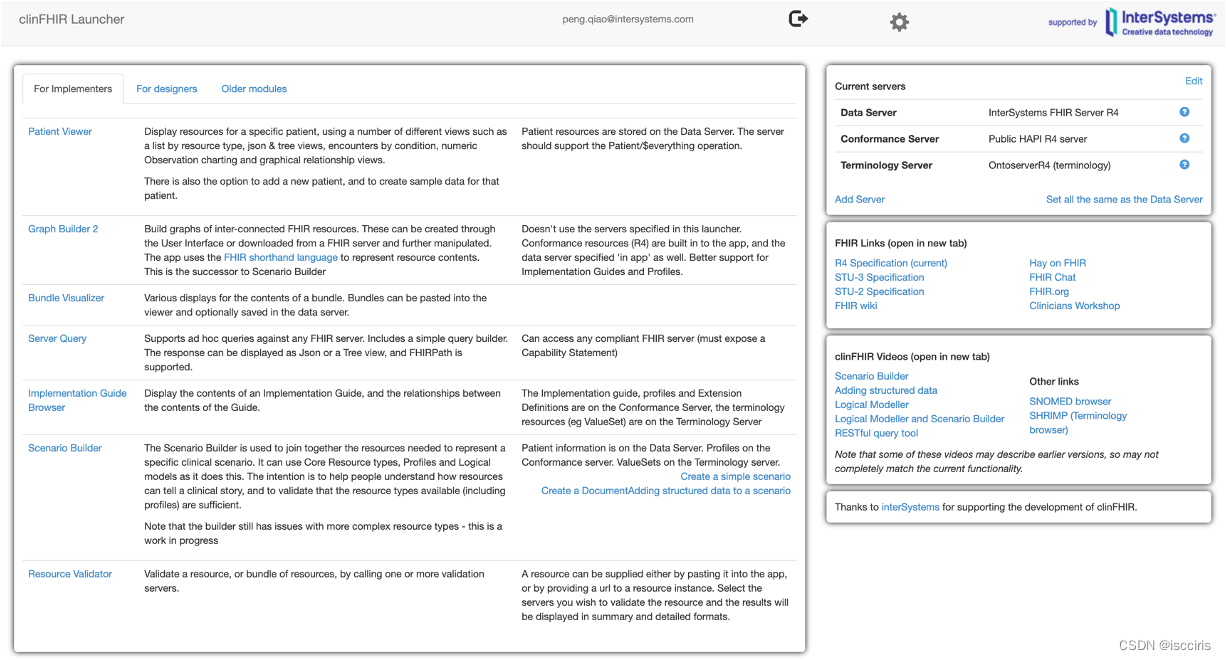
理解和学习是标准推行的第一要务。除了汗牛充栋的学习材料和视频,FHIR还有不错的学习网站,例如Clinfhir ,最初设计是方便医生理解如何用FHIR构建和解决自己的用例的,但实际上也被广大卫生信息从业者用于理解FHIR标准。
2. 测试数据生成工具:
想学习标准?没有什么比直观的数据更能说明问题了。FHIR生态下有名的Synthea是一个基于马塞诸塞州的患者真实数据经过统计、混淆后的FHIR测试数据生成工具,可以按用户要求生成指定数量的、符合真实数据分布的FHIR资源,会为每个生成的虚拟患者生成一个FHIR boundle文件,并生成对应的医院、医生等FHIR资源。大家可以免费下载Synthea使用它产生测试数据。
另外,国内也广泛使用的MIMIC - 麻省理工贝斯以色列迪康医学中心的有5万多患者真实完整的高质量重症医疗数据集,如今也有了FHIR版本。
3. FHIR服务器:
还没有FHIR服务器,怎么测试FHIR?
FHIR生态下有大量的免费沙箱,用户可以选择它们进行标准的学习和测试。例如官网提供的沙箱和各个厂商提供的沙箱。通过各种API工具,例如postman,学习者无需注册即可以了解FHIR标准的方方面面,甚至将自己的测试数据加载进去并测试自己的解决方案。
4. 标准扩展和再约束构建工具:
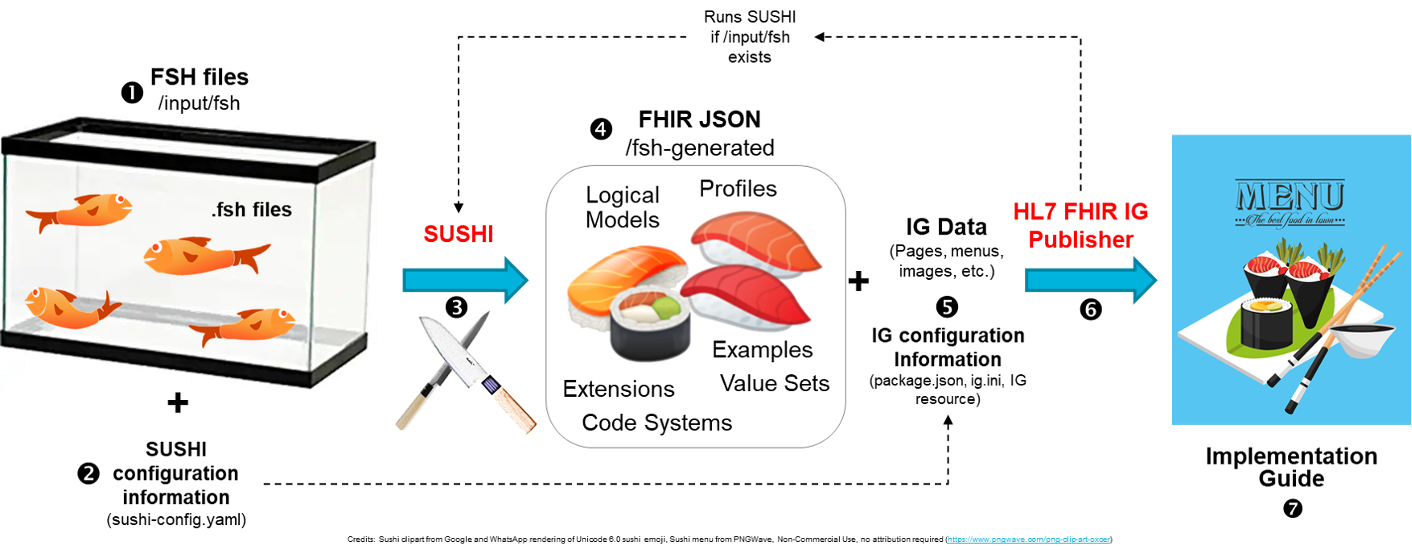
如何方便、直观地构建自己的术语、扩展和再约束(Profile)和用例?FHIR生态下有众多公司提供的免费工具可用 - 随君取用。例如术语扩展可以用Snapper和FSH、进行小规模profile开发可以用可视化的Forge或Trifolia-on-FHIR、进行大规模的profile和实施指南开发可以用FSH。
5. 标准验证工具:
需要基于profile对FHIR资源进行校验?资源更多了,不仅有FHIR官网提供的FHIR资源校验网页,还有各种开发语言版本的校验工具代码:
FHIR生态下百花齐放的各种应用架构、应用方向
更令人眼前一亮的是FHIR生态下各种应用架构、应用方向和众多其它生态对FHIR的采纳。
应用开发架构:
FHIR提供了标准卫生信息模型和相应的API,为行业应用的快速开发提供了坚实的基础。FHIR生态下最有名的SMART on FHIR,实现即插即用和可复用的应用开发架构。在国际卫生信息互操作标准发展简史中有简要介绍。
SMART on FHIR市场已经有大量的应用可以直接下载部署。
决策支持架构:
决策支持已经是卫生信息数字化转型的核心需求之一。卫生信息化已经建设了各种基于知识库和基于机器学习的决策支持系统,涵盖了临床、业务管理、费用、组学与科研、公卫、健康管理等全部业务,但仍面临众多挑战。
任何知识库系统和决策支持系统面临的一个关键挑战是决策支持的可移植性!如果决策支持厂商都按自己的数据、术语和服务标准构建解决方案,用户在使用多个决策支持产品时,将面临大量数据转换和映射及服务集成带来的非常高的实施成本和潜在决策错误风险。
FHIR通过Clinical Reasoning模块和CDS Hooks分别提供了本地决策支持架构和外部决策支持架构,通过标准化降低成本和风险、提高决策效率和范围。这里是对CDS Hooks的介绍。

其它标准对FHIR的采纳:
相较于之前流行的互操作标准,FHIR在标准化、灵活性、可用性 三方面取得了很好的平衡。FHIR资源模型比大多数的行业通用数据模型(CDM)都简化,方便使用。曾经各自为战的众多标准都发现FHIR无处不在,且FHIR资源和API可以作为自己的数据和访问数据的基石,而融入FHIR生态可以更方便获得数据、获得更多的推广、发挥更大的价值,因此一系列的XX on FHIR项目应运而生 - 或者直接采纳FHIR、或者与FHIR相兼容。除了上面提到的SMART on FHIR,这里简单汇总一下主要的已完成和进行中的on FHIR项目和标准。
1. IHE
IHE(Integrating the Healthcare Enterprise)是国际上比较流行且成功的卫生信息交换服务规范。它一直采用流行和稳定的互操作基础标准来开发自己的服务规范,最初使用DICOM + HL7 V2消息,后来用到HL7 V3 和CDA。IHE发现新的FHIR互操作标准有助于应对新的用例、并更好解决老的用例,认为FHIR会成为最流行的互操作基础标准,因此已经发布了很多基于FHIR的IHE服务,尤其是那些和移动业务相关的服务,例如移动患者人口统计查询 (PDQm)。
2. OMOP on FHIR
OMOP(Observational Medical Outcomes Partnership)是包括国内在内全球科研人员进行真实世界研究的重要工具,它开发了通用数据模型CDM和分析工具库。
HL7国际和OHDSI宣布合作提供单一的通用数据模型,用于共享临床护理和观察研究信息 - 这就是OMOP on FHIR项目。
OMOP-on-FHIR 是构建在 OMOP CDM 数据库之上的 FHIR 服务器,它提供中间映射层,实现OMOP CDM和FHIR资源之前的双向转换,从而打通两大生态,使临床医生和研究人员能够从多个来源提取数据并以相同的结构进行分析处理与共享交换而不会降低数据质量,可以同时使用两个生态下丰富的应用与工具,利用各自的生态优势。例如OMOP让FHIR生态可以利用其丰富的预测模型,而FHIR让OMOP的研究分析可以集成到临床工作流程中,推动精准医学的落地。
3. FHIR to CDISC Joint Mapping
CDISC 是一个标准开发组织,开发了生物制药行业使用的诸多数据标准,常用于提交临床试验数据以进行分析和监管审批。
通过与HL7合作,FHIR to CDISC Joint Mapping实施指南定义了FHIR 与三个特定 CDISC 标准之间的映射:
- 研究数据列表模型实施指南 (SDTMIG) 3.2
- 临床数据采集标准协调实施指南 (CDASH) 2.1
- 实验室1.0.1
通过简化 HL7 FHIR和 CDISC 标准之间的数据转换,消除使用临床信息支持科研的障碍。用途包括:
- 捕获“真实世界证据”(RWE),让那些不是为临床试验目的采集的数据可以用于研究监管
- 利用FHIR 的SMART等技术,直接在临床系统内部捕获试验驱动的数据,而不是建立单独的临床试验管理解决方案
- 在回顾性研究中更容易利用临床数据
- 创建病例报告表单 (CRF),链接到使用 FHIR 资源和Profile定义的数据元素
- 使两个标准社区的专家能够理解彼此的术语,并随着两套规范的不断发展更好地协调它们
4. 通用数据模型协调 Common Data Models Harmonization(CDMH)
在卫生信息领域,有众多的通用数据模型(Common Data Models)服务于不同的或相同的业务领域。虽然都是“通用”数据模型,但数据在彼此之间并不通用。
FHIR的细颗粒度统一语义资源模型可以作为众多通用数据模型间的桥梁。通用数据模型协调(CDMH)目标就是借助FHIR打通各个通用数据模型,让它们的数据可以相互转换。
CDMH 项目由美国FDA 领导,与其他联邦政府机构合作。已发布的通用数据模型协调 (CDMH) FHIR 实施指南 (IG) 将重点放在以患者为中心的结果研究 (PCOR) 和其它目的提取的观察数据的映射和转换为 FHIR 格式。该项目重点关注以下四种通用数据模型 (CDM) 到 FHIR 的映射:
- 以患者为中心的结果研究网络 (PCORNet)
- 整合生物学和床边 (Informatics for Integrating Biology& the Bedside - i2b2) 临床试验 (ACT) 信息学,也称为 i2b2/ACT
- 观察性医疗结果合作伙伴 (OMOP)
- 美国食品和药物管理局的哨兵(Sentinel)
5. Arden Syntax on FHIR
和HL7的临床质量语言(Clinical Quality Language - CQL)类似,Arden Syntax 是一种结构化、可执行的医学知识表示和处理语言,将医学知识表达为独立的单元 - 医学逻辑模块(Medical Logical Modules),常用于设计CDS系统,构建临床指南规则和临床决策规则。
新版本 Arden Syntax 3.0 版采用FHIR进行扩展,重新定义了基于FHIR的标准化的数据模型和数据访问方式。作为经过审计、基于共识的迭代 HL7 标准开发流程的一部分,3.0版已成功通过投票。
6. HL7 V2 to FHIR
HL7 V2在全球依然有很高的采纳度,但其局限性和FHIR的成熟度都在推动从V2到FHIR的迁移。HL7 V2 to FHIR 项目建立实施指南,将HL7 V2的组件映射到FHIR组件:V2的消息、消息段、数据类型和词汇分别映射到 FHIR 的Bundle、FHIR资源、数据类型和编码系统,并对FHIR进行相应扩展以弥补二者间的差距。
7. C-CDA on FHIR
C-CDA是最广泛实施的 HL7 CDA 实施指南之一,涵盖了临床护理的文档范围。CDA 和 FHIR 之间的互操作能力是推动临床文档进化的重要渠道。
C-CDA on FHIR 实施指南 (IG) 定义了一系列 FHIR 配置文件,以表示 C-CDA 中的各种文档类型,并弥补二者设计上的差异。C-CDA on FHIR 利用FHIR使文档标准更为精简。
还有更多的on FHIR项目没有介绍到,例如SNOMED on FHIR、PDMP on FHIR… 同时可以预期还会有越来越多的on FHIR项目会不断涌现。
不仅是这些on FHIR 项目,越来越多的机构发现FHIR的价值,将自己原来的数据模型改为FHIR。例如美国互操作核心数据集USCDI(U.S. Core Data for Interoperability) 起初采用通用临床数据集CCDS作为模型, 如今已经完全采纳FHIR,并且成为美国国家FHIR标准US Core的一部分。FHIR也得到了很多国家采纳作为国家级卫生信息互操作的标准。
大规模数据统计与分析:
一个好的标准应该有助于解决完整的行业需求。FHIR作为行业互操作标准已经超越了传统互操作的能力范围,除了互操作的数据模型、消息、文档、服务和API,FHIR服务器加上FHIR资源仓库为大规模的卫生信息持久化和访问提供了方案。
FHIR的完整蓝图目前尚缺一块拼图 - 基于FHIR的大规模数据统计与分析。
1. 大规模数据检索
FHIR API提供检索类型的API,通过查询参数(Search Parameter)对资源进行检索。
例如: 想要获取所有检验项目为loinc 1234-1,且检验结果小于9.2的Observation资源,可以用这样的查询参数:
GET http://fhirsvr.com/Observation? code-value-quantity=loinc|1234-1$lt9.2
- 1
除了FHIR Core发布的查询参数,用户还可以扩展自己的查询参数,满足检索需求。
FHIR标准里的FHIR Path为FHIR资源模型提供了类似于XPath的资源路径导航和获取语言,可以方便地筛选、过滤层次化的FHIR数据。
但FHIR查询API和FHIR Path都仅适合于单资源类型的检索,对于需要多类型资源联合分析、汇聚、统计等分析需求无能为力。
2. 大规模的数据统计分析
HL7为临床质量指标与决策支持提出了临床质量语言(Clinical Quality Language - CQL) ,CQL如今基于FHIR,使用FHIR资源模型来构建标准化的指标体系,以支持决策和基于指标的管理。
对于科研数据分析,借助上面介绍的OMOP on FHIR和其它项目,用户可以用自己熟悉的科研工具并利用FHIR数据支持自己的科研工作,本质上是将FHIR数据转换并导入自己的科研工具。
对于通用大规模数据统计分析,虽然FHIR提供了API、FHIR资源数据序列化的JSON、XML可以作为文档进行分析,但市面上的统计分析工具和机器学习工具大都支持SQL,SQL也是最流行的数据统计分析语言。
FHIR的深层次化模型是立体的、对象化的,而SQL是扁平的、表格化的。这个差异让FHIR对主流分析工具和机器学习工具不友好。这对基于FHIR原生的大规模数据分析利用造成了障碍,是FHIR最需要完善的那一块。
FHIR和生态已经创立了很多项目,努力补上这一环。
SQL on FHIR
SQL on FHIR项目的思路是为SQL用户提供FHIR的SQL表示层。SQL表示层提供一个机制:让用户根据自己的需要基于FHIR Path定义视图。这里的视图不是SQL视图,而是一个SQL模型的逻辑表达,由一个新的FHIR工件ViewDefinition定义。各个技术厂商负责物理实现它并展现为SQL表。
例如下面的视图定义:
{ "resourceType": "http://hl7.org/fhir/uv/sql-on-fhir/StructureDefinition/ViewDefinition", "select": [ { "column": [ { "path": "getResourceKey()", "alias": "id" }, { "path": "gender" } ] }, { "column": [ { "path": "given.join(' ')", "alias": "given_name", "description": "A single given name field with all names joined together." }, { "path": "family", "alias": "family_name" } ], "forEach": "name.where(use = 'official').first()" } ], "name": "patient_demographics", "status": "draft", "resource": "Patient" }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
它定义一张这样的SQL表:

考虑到FHIR资源模型的复杂,SQL on FHIR目前尚待成熟。当前是版本2,尚未发布,且有很多限制,例如不能在视图里定义跨资源的字段。
技术厂商的FHIR资源SQL实现
除了SQL on FHIR项目,很多技术厂商也在借助自身技术上的优势为FHIR提供SQL访问层。
例如InterSystems IRIS是一个多模型数据平台技术,它可以同时支持对FHIR资源逻辑模型使用对象建模、对FHIR序列化的JSON/XML使用文档建模,并将这些模型投射为SQL模型。InterSystems IRIS正是借助于这个特性,提供一个名为FHIR SQL构建器(FHIR SQL Builder)的工具,用户通过图形化方式拖拽建立需要的SQL模型,而无需拷贝和转换数据。
FHIR生态正展现出蓬勃的生命力,如今已经是百花齐放。FHIR展现的统一行业语义能力和强大的生态,不仅帮助WHO发布数字公共产品服务,也可以赋能卫生信息数字化转型。

