
- 1国产系统软件网站_国产app网站
- 2安装docker时,遇到Loaded plugins...怎么办
- 3解决Could not install packages due to an EnvironmentError: [WinError 5] 拒绝访问。: ‘f:\program files\p
- 4Docker本地部署Drupal内容管理框架并实现公网远程访问_本地管理框架
- 5OSI与TCP/IP各层的结构与功能及协议_tcp/ip和osi分层模型每层对应的协议
- 6SpringBoot全局异常处理 | Java
- 7产品经理之Axure的元件库使用&详细案例_axure 移动端元件库
- 8【干货分享】前端面试知识点锦集01(HTML篇)——附答案_从下列选中中选出不同的一个?a
- 9Python自动操作 GUI 神器——PyAutoGUI_python判断鼠标在主屏还是副屏
- 10行人重识别(4)——行人重识别(基于视频)综述
(SQL学习随笔3)SQL语法——SELECT语句_sql select 等于
赞
踩
基本认识
SELECT 'test'; -- 查询单个值
SELECT 1, 2.3, 'test', true; -- 查询多个值
SELECT 1 AS 整数, 2.1 AS 浮点数, '测试' AS 字符串, true AS 布尔型; -- 针对每个查询到的值,在其后配合AS关键字设置别名
SELECT 1 + 2, 5 * 10, version() AS 版本信息; -- 查询函数或算式运算结果
- 1
- 2
- 3
- 4
FROM关键字
-- 创建示例数据表 CREATE TABLE tips ( total_bill FLOAT, tip FLOAT, sex CHAR(6), smoker CHAR(3), day CHAR(3), time TEXT, size INT ); -- 插入示例数据 INSERT INTO tips VALUES (16.99, 1.01, 'Female', 'No', 'Sun', 'Dinner', 2), (10.34, 1.66, 'Male', 'No', 'Sun', 'Dinner', 3), (21.01, 3.5, 'Male', 'No', 'Sun', 'Dinner', 3), (23.68, 3.31, 'Male', 'No', 'Sun', 'Dinner', 2), (24.59, 3.61, 'Female', 'No', 'Sun', 'Dinner', 4), (25.29, 4.71, 'Male', 'No', 'Sun', 'Dinner', 4), (8.77, 2.0, 'Male', 'No', 'Sun', 'Dinner', 2), (26.88, 3.12, 'Male', 'No', 'Sun', 'Dinner', 4), (15.04, 1.96, 'Male', 'No', 'Sun', 'Dinner', 2), (14.78, 3.23, 'Male', 'No', 'Sun', 'Dinner', 2);

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
SELECT * FROM tips;
SELECT tip, sex FROM tips;
SELECT tip AS 小费 FROM tips;
- 1
- 2
- 3
LIMIT与OFFSET
SELECT * FROM tips LIMIT 3; -- 查询前三行
SELECT * FROM tips LIMIT 3 OFFSET 8; -- 从第9行(包含)开始查询三行
- 1
- 2
ORDER BY
SELECT * FROM tips ORDER BY total_bill DESC; -- 单字段降序(默认升序)
SELECT * FROM tips ORDER BY size ASC, total_bill DESC; -- 多字段排序
- 1
- 2
- 3
WHERE条件查询
-- 示例数据 CREATE TABLE funds ( fund_code VARCHAR(10) PRIMARY KEY, fund_name TEXT, fund_type TEXT, within_a_week FLOAT, within_a_month FLOAT, within_three_month FLOAT, within_this_year FLOAT, within_six_month FLOAT, within_one_year FLOAT ); INSERT INTO funds VALUES ('5669', '前海开源公用事业股票', '股票型', 0.0714, 0.2844, 0.6162, 0.3708, 0.3582, 1.263), ('828', '泰达转型机遇', '股票型', 0.0328, 0.1904, 0.5942, 0.2832, 0.2827, 1.0693), ('689', '前海开源新经济混合', '混合型', 0.0769, 0.2797, 0.5918, 0.3768, 0.3504, 0.9222),
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
单值比较
= 等于
<> 不等于
<、<= 小于、小于等于
>、>= 大于、大于等于
SELECT * FROM funds WHERE fund_type <> '混合型';
- 1
多条件组合
SELECT * FROM funds
WHERE fund_type <> '混合型' AND within_three_month > 0.5; -- AND
SELECT * FROM funds
WHERE fund_type = '股票型' OR fund_type = '债券型'; -- OR
SELECT * FROM funds
WHERE fund_type IN ('股票型', '债券型'); -- IN
SELECT * FROM funds
WHERE NOT fund_type IN ('股票型', '债券型'); -- NOT(加在完整条件之前)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
范围筛选
SELECT * FROM funds
WHERE within_three_month BETWEEN 0.4 AND 0.5; -- BETWEEN ... AND ...
- 1
- 2
空值匹配
SELECT * FROM funds WHERE within_one_year = NULL; -- 这样不行
SELECT * FROM funds WHERE within_one_year IS NULL; -- 正确
- 1
- 2
- 3
LIKE通配
- 主要有两种通配符——
'%'与'_',其中'%'代表任意多个字符,'_'代表单个任意字符
SELECT * FROM funds WHERE fund_name LIKE '%新能源%';
SELECT * FROM funds WHERE fund_name LIKE '%a';
SELECT * FROM funds WHERE fund_name LIKE '%A'; -- 在MySQL中,与上面返回一致(不区分大小写)
SELECT * FROM funds WHERE BINARY fund_name LIKE '%A'; -- 强制当成二进制格式后通配
- 1
- 2
- 3
- 4
- 5
- 6
条件分组
SELECT * FROM funds
WHERE (fund_name LIKE '%医药%' AND within_three_month > 0.4)
OR (fund_name LIKE '%车%' AND within_three_month > 0.45);
- 1
- 2
- 3
运算符和函数
数据变换
- 文本处理
MySQL
/* concat(字段1, 字段2, ... ,字段n)用于将传入的若干个【字段】或单个值信息拼接为新的单个字段 left(字段, 截取字符数量)用于从【字段】每条记录最左端开始提取【截取字符数量】个的字符 right(字段, 截取字符数量)用于从【字段】每条记录最右端开始提取【截取字符数量】个的字符 char_length(字段)用于计算传入【字段】每条记录的字符数量(单个汉字亦算作1个字符) substr(字段, 开始位置, 截取长度)用于提取【字段】从【开始位置】往后最多【截取数量】个字符 regexp_like(字段, 正则表达式)用于判断【字段】中是否存在满足【正则表达式】模式子串,返回1表示存在,0表示不存在 replace(字段, 目标字符串, 替换字符串)用于将【字段】中所有【目标字符串】替换为【替换字符串】 repeat(字段, 重复次数)用于将【字段】复制【重复次数】后进行拼接 reverse(字段)用于将【字段】中每条字符记录进行翻转 */ SELECT concat(fund_name, ' ', fund_type, ' ', within_a_month) AS 'concat()', left(fund_name, 2) AS 'left()', right(fund_name, 3) AS 'right()', char_length(fund_name) AS 'char_length()', substr(fund_name, 3, 4) AS 'substr()', regexp_like(fund_name, '医药') AS 'regexp_like()', replace(fund_name, '医药', 'medicine') AS 'replace()', repeat(fund_name, 3) AS 'repeat()', reverse(fund_name) AS 'reverse()' FROM funds;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
/* concat(字段1, 字段2, ... ,字段n)用于将传入的若干个【字段】或单个值信息拼接为新的单个字段 left(字段, 截取字符数量)用于从【字段】每条记录最左端开始提取【截取字符数量】个的字符 right(字段, 截取字符数量)用于从【字段】每条记录最右端开始提取【截取字符数量】个的字符 char_length(字段)用于计算传入【字段】每条记录的字符数量(单个汉字亦算作1个字符) substr(字段, 开始位置, 截取长度)用于提取【字段】从【开始位置】往后最多【截取数量】个字符 字段 ~ 正则表达式 用于判断【字段】中是否存在满足【正则表达式】模式子串,直接返回返回boolean型判断结果 replace(字段, 目标字符串, 替换字符串)用于将【字段】中所有【目标字符串】替换为【替换字符串】 repeat(字段, 重复次数)用于将【字段】复制【重复次数】后进行拼接 reverse(字段)用于将【字段】中每条字符记录进行翻转 */ SELECT concat(fund_name, ' ', fund_type, ' ', within_a_month) AS "concat()", left(fund_name, 2) AS "left()", right(fund_name, 3) AS "right()", char_length(fund_name) AS "char_length()", substr(fund_name, 3, 4) AS "substr()", fund_name ~ '医药' AS "~", replace(fund_name, '医药', 'medicine') AS "replace()", repeat(fund_name, 3) AS "repeat()", reverse(fund_name) AS "reverse()" FROM funds;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
在PostgreSQL中还可以使用
||来拼接若干个字符型字段:
SELECT fund_name || ' - ' || fund_type FROM funds;
- 数值计算
PostgreSQL
SELECT 1 + 1 AS 加,
1 - 2 AS 减,
2 * 5 AS 乘,
4 / 3 AS 整数除法,
4 / 3. AS 浮点数除法,
2 ^ 2 AS 平方,
|/ 25 AS 平方根,
5 % 2.2 AS 取余,
||/ 27 AS 立方根,
3! AS 阶乘,
@ -5.5 AS 绝对值;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
MySQL
SELECT 1 + 1 AS 加,
1 - 2 AS 减,
2 * 5 AS 乘,
4 / 3 AS 整数除法,
4 / 3. AS 浮点数除法,
5 % 2.2 AS 取余,
sqrt(9) AS 平方根,
abs(-5.5) AS 绝对值;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 聚合函数
SELECT min(within_three_month) AS 最小值,
max(within_three_month) AS 最大值,
avg(within_three_month) AS 平均值,
count(fund_type) AS 计算行数,
sum(within_three_month) AS 求和
FROM funds;
SELECT DISTINCT fund_type FROM funds; -- 去重
SELECT count(DISTINCT fund_type) FROM funds; -- 统计不重复字段的数量
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
分组运算
SELECT fund_type, count(*) AS 基金数量, avg(within_a_month) AS 最近一个月平均涨幅 -- 这些字段运算后必须是和分组字段等长的,即对非分组字段进行的运算操作一定是聚合压缩操作
FROM funds
GROUP BY fund_type
ORDER BY 最近一个月平均涨幅 DESC
LIMIT 3;
- 1
- 2
- 3
- 4
- 5
- 分组后过滤(HAVING)
SELECT fund_type, count(*) AS 基金数量, avg(within_a_month) AS 最近一个月平均涨幅
FROM funds
GROUP BY fund_type
HAVING count(*) >= 5; -- having筛选条件中只能对分组依据字段进行筛选,或对其他字段进行聚合后筛选
- 1
- 2
- 3
- 4
执行顺序
第一步: FROM <left_table>
第二步: ON <join_condition>
第三步: <join_type> JOIN <right_table>
第四步: WHERE <where_condition>
第五步: GROUP BY <group_by_list>
第六步: HAVING <having_condition>
第七步: SELECT
第八步: DISTINCT <select_list>
第九步: ORDER BY <order_by_condition>
第十步: LIMIT <limit_number>
因此在select中定义的别名不能在where或having中使用
表连接
-- 创建商品信息表 CREATE TABLE product_info ( product_id VARCHAR PRIMARY KEY, product_category VARCHAR, product_name VARCHAR, product_price FLOAT ); -- 创建销售记录表 CREATE TABLE sale_records ( sold_product_id VARCHAR, amount INT, discount FLOAT ); -- 插入示例数据 INSERT INTO product_info VALUES ('ca4ef73a-dd6d-11eb-894e-287fcf8fcac7', '生活用品', '花王蒸汽眼罩12片装', 48.8), ('ca4ef73b-dd6d-11eb-922a-287fcf8fcac7', '鞋类', '安踏EDGE跑鞋', 429.0), ('ca4ef73c-dd6d-11eb-b7ee-287fcf8fcac7', '鞋类', '匹克态极3.0跑步鞋', 499.0), ('ca4ef73d-dd6d-11eb-9fc4-287fcf8fcac7', '办公用品', 'Salli马鞍椅', 2255.0), ('ca4ef73e-dd6d-11eb-851b-287fcf8fcac7', '办公用品', 'GAVEE人体工学椅', 3888.0), ('ca4ef73f-dd6d-11eb-ba5f-287fcf8fcac7', '办公用品', '赫曼米勒Aeron人体工学椅', 16310.0), ('e2d3o9ed-dccb-11eb-we7u-287fcf8fcac7', '数码产品', '华为Mate X2折叠手机', 17799.0); INSERT INTO sale_records VALUES ('ca4ef73a-dd6d-11eb-894e-287fcf8fcac7', 2, 0.9), ('ca4ef73b-dd6d-11eb-922a-287fcf8fcac7', 6, 0.8), ('ca4ef73d-dd6d-11eb-9fc4-287fcf8fcac7', 3, 0.9), ('ca4ef73b-dd6d-11eb-922a-287fcf8fcac7', 1, 0.9), ('ca4ef73e-dd6d-11eb-851b-287fcf8fcac7', 2, 0.8), ('ca4ef73c-dd6d-11eb-b7ee-287fcf8fcac7', 9, 0.7),
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
内连接
-- 内连接
SELECT DISTINCT product_name FROM sale_records AS a
INNER JOIN product_info AS b
ON a.sold_product_id = b.product_id;
-- 两表中的字段不存在重复,可以省略别名
SELECT DISTINCT product_name FROM sale_records
INNER JOIN product_info
ON sold_product_id = product_id;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
左(右)外连接
-- 左外连接
SELECT * FROM product_info
LEFT JOIN sale_records
ON sold_product_id = product_id
WHERE product_name = '华为Mate X2折叠手机';
- 1
- 2
- 3
- 4
- 5
全外连接
SELECT DISTINCT product_name FROM sale_records
FULL JOIN product_info -- 或 FULL OUTER JOIN (MySQL中没有全外连接)
ON sold_product_id = product_id;
- 1
- 2
- 3
外键约束
-- 创建销售记录表
CREATE TABLE sale_records
(
sold_product_id VARCHAR REFERENCES product_info(product_id),
amount INT,
discount FLOAT DEFAULT 1
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
在本例中,即希望sale_records中的sold_prodect_id都能在product_info中找到对应的product_id
INSERT INTO sale_records VALUES ('not_int_product_info', 1, 1); -- 报错,因为product_info表中并不存在product_id为'not_int_product_info'的数据
- 1
窗口函数
针对每一条数据单独开一个窗,在窗内执行不同的操作(通常用于既要明细又要聚合的场景)
示例数据:
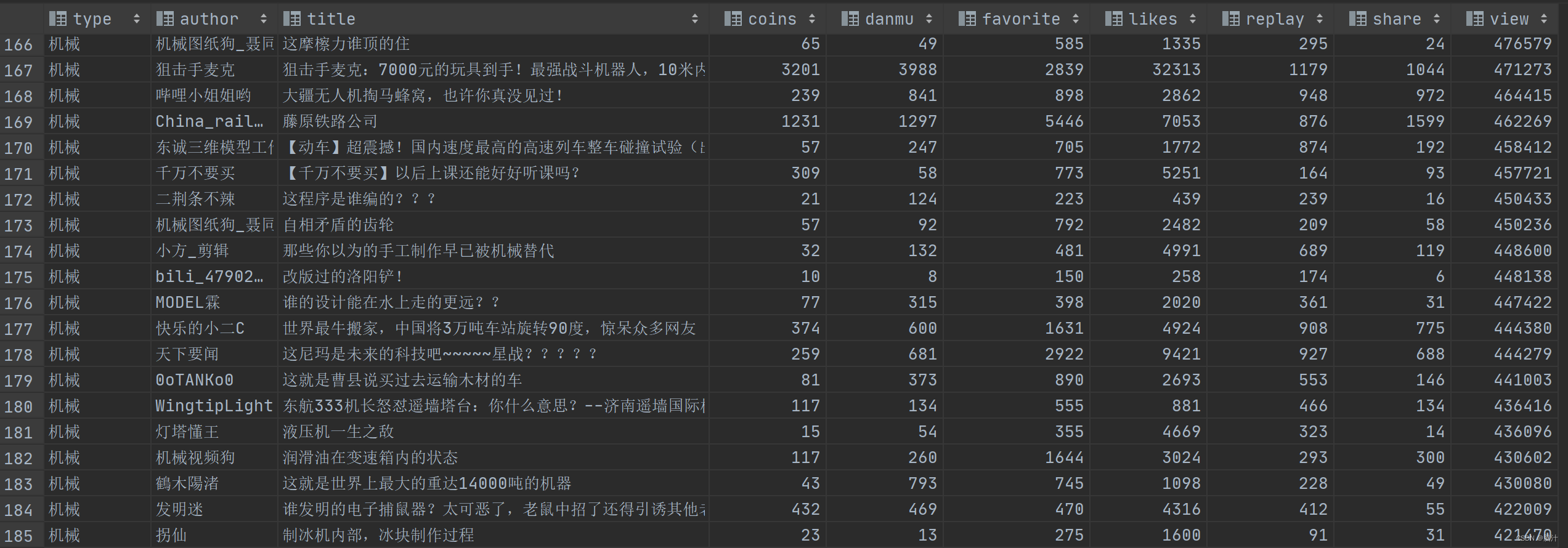
- 需求一:获得每个type下播放量前三名对应的记录
SELECT *
FROM (
SELECT type, author, title, dense_rank() OVER (PARTITION BY type ORDER BY view DESC) AS top3
FROM bilibili
) AS temp
WHERE top3 <= 3;
- 1
- 2
- 3
- 4
- 5
- 6
注意:窗口函数的执行实在WHERE之后的,因此要获取前三名不能在内层直接用WHERE,而是用嵌套查询在外层使用WHERE
- 需求二:查询每个type中,在coins降序排名下,每个视频与其下一名之间播放量的差值
select *, view - diff as diff_view
from (
select type, author, title, view, coins, lead(view, 1) over (partition by type order by coins desc) as diff
from bilibili
) as _; -- FROM 中的子查询必须有一个别名
- 1
- 2
- 3
- 4
- 5
注意:over子句中起的别名不能在同级select中使用,因此还是要用嵌套查询
更多窗口函数:
- MySQL
https://dev.mysql.com/doc/refman/8.0/en/window-function-descriptions.html- PostgreSQL
http://www.postgres.cn/docs/12/functions-window.html
UNION:表上下拼接
SELECT * FROM t1
UNION
SELECT * FROM t2
UNION
SELECT * FROM t3
- 1
- 2
- 3
- 4
- 5
-- 要求:两表具有相同的字段数量,且字段数据类型相互兼容
-- 最终查询到的表头字段与第一张表t1一致
-- UNION 会自动去重,使用UNION ALL不去重
子查询
SELECT *
FROM (
SELECT * FROM t1
) as _; -- 子查询必须要给予别名
GROUP BY ...
- 1
- 2
- 3
- 4
- 5
条件判断
- PostgreSQL示例数据
-- 懂车帝部分车辆评分及价格信息表
CREATE TABLE car_info
(
brand VARCHAR,
score FLOAT,
price VARCHAR
);
INSERT INTO car_info
VALUES ('轩逸', 3.65, '8.48-15.59万'),
('雅阁', 3.94, '15.18-24.18万'),
('思域', 3.83, '9.49-15.89万'),
('朗逸', 3.62, '6.79-15.89万'),
('哈弗H6', 3.81, '9.19-15.49万'),
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- MySQL示例数据
-- 懂车帝部分车辆评分及价格信息表
CREATE TABLE car_info
(
brand TEXT,
score FLOAT,
price TEXT
);
INSERT INTO car_info
VALUES ('轩逸', 3.65, '8.48-15.59万'),
('雅阁', 3.94, '15.18-24.18万'),
('思域', 3.83, '9.49-15.89万'),
('朗逸', 3.62, '6.79-15.89万'),
('哈弗H6', 3.81, '9.19-15.49万')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
PostgreSQL
- 对值进行匹配
CASE 输入值 WHEN 匹配值1 THEN 结果1 WHEN 匹配值2 THEN 结果2 … ELSE 备选值 END
-- 为奥迪、宝马、五菱开头的品牌单独匹配,其他情况返回other
SELECT CASE left(brand, 2) -- 从左取brand两个字符
WHEN '奥迪' THEN 'Audi'
WHEN '宝马' THEN 'BMW'
WHEN '五菱' THEN 'SGMW'
ELSE 'other'
END,
brand
FROM car_info;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 对条件进行匹配
CASE WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2 ELSE 备选结果 END
-- 以4为阈值区分高评分与非高评分
SELECT CASE WHEN score > 4 THEN '高评分' ELSE '非高评分' END,
brand,
score
FROM car_info;
- 1
- 2
- 3
- 4
- 5
MySQL
CASE-WHEN-THEN-END结构语法与PostgreSQL一致
IF(条件, 满足条件时返回的值, 不满足条件时返回的值)
-- 以4为阈值区分高评分与非高评分
SELECT if(score > 4, '高评分', '非高评分'),
brand,
score
FROM car_info;
- 1
- 2
- 3
- 4
- 5
IFNULL(a, b),当a为NULL时,返回b;当a不为null时,返回a
SELECT IFNULL(null, '是null'), IFNULL('非null', '不返回这个');
- 1

