
- 1最全的 Vue 面试题+详解答案_vue原理面试题
- 2solidity语言语法总结
- 3【时间序列】多变量时间序列异常检测数据集整理及标准化处理代码合集
- 4HarmonyOS 鸿蒙驱动消息机制管理
- 5HCIP-AI EI Developer V2.0 模拟试卷_hcia-harmonyos application developer v2.0 模拟考试
- 6蔚来,还有几张底牌可打?
- 7您所应了解的Python四大主流网络编程框架_esafenet python
- 8【c++】获取电脑硬件信息(操作系统,CPU,内存,GPU,显卡驱动,显示设备分辨率)_c++ 获取硬件信息
- 9克鲁斯卡尔算法-------最小生成树图解_克鲁斯卡尔算法求最小生成树
- 10hnu云计算个人实验报告——实验七
结合创新!11种多尺度特征融合方法,附论文和代码
赞
踩
随着深度学习和计算机视觉技术的快速发展,多尺度特征融合已经成为一个备受关注的、不断探索的研究方向,它通过捕捉不同尺度和层次上的特征信息,提高对图像和视频内容的理解能力,为图像处理、计算机视觉和深度学习等领域的应用提供了坚实的基础。
今天就整理了11种多尺度特征融合方法分享给大家,这些方法采用了不同的策略和技术,能够有效地改进图像的识别、检测、分类和分割等任务!
1、MSGNet: Learning Multi-Scale Inter-Series Correlations for Multivariate Time Series Forecasting(AAAI2024)
MSGNet:学习多变量时间序列预测的多尺度序列间相关性
简述:本文提出了一种深度学习模型MSGNet,利用频域分析和自适应图卷积来捕捉多个时间尺度上的系列间相关性。MSGNet通过自注意力机制处理系列内依赖,并引入自适应混合跳跃图卷积层学习每个时间尺度的系列间关系。实验证明,MSGNet在多个真实数据集上有效,并能自动学习可解释的多尺度系列间相关性,展现出良好的泛化能力。
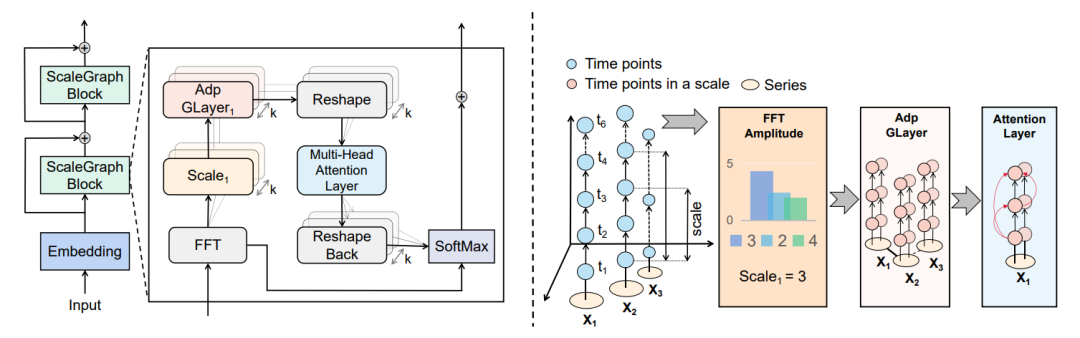
2、CEDNet: A Cascade Encoder-Decoder Network for Dense Prediction(ICLR 2024)
CEDNet:用于密集预测的级联编码器-解码器网络
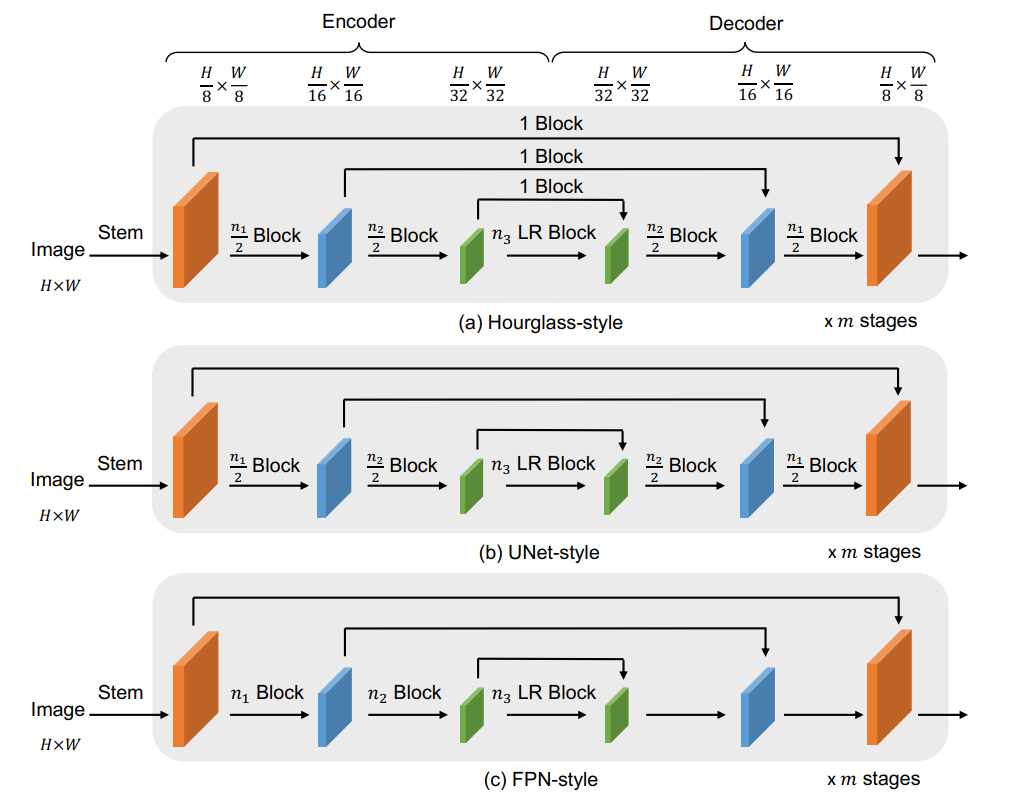
简述:本文提出了一种名为CEDNet的简化级联编码器-解码器网络,它专为密集预测任务设计,并在解码器中执行多尺度特征融合。CEDNet的特点是能够从早期阶段整合高级特征来指导低级特征学习,增强多尺度特征融合。研究人员还研究了Hourglass、UNet和FPN三种编码器-解码器结构,并将它们集成到CEDNet中,提升了性能。在目标检测、实例分割和语义分割的实验中验证了该方法的有效性。
3、Dual Attention U-Net with Feature Infusion:Pushing the Boundaries of Multiclass Defect Segmentation
具有特征注入的双注意力 U-Net:突破多类缺陷分割的界限
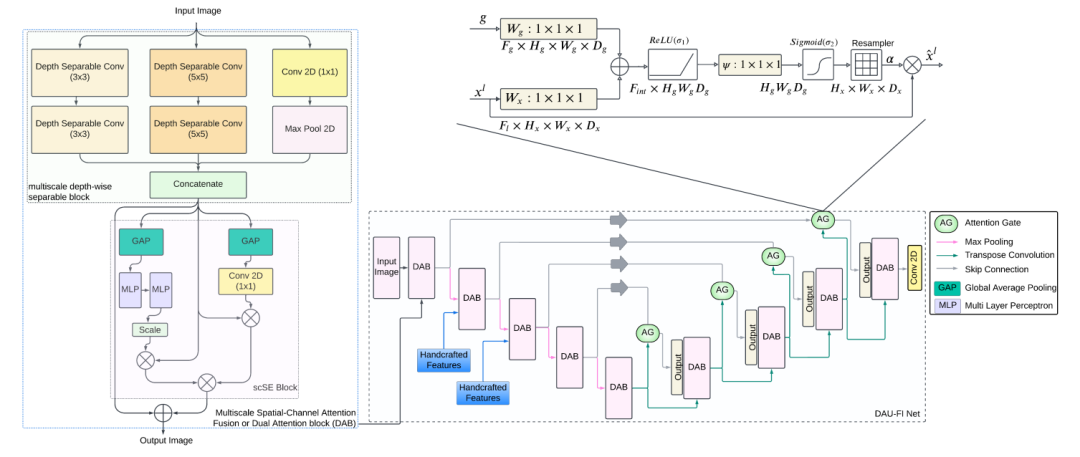
简述:本文提出了DAU-FI Net架构,主要针对多类不平衡数据集的语义分割,通过集成多尺度空间通道注意力机制和特征注入提升精度。核心是多尺度深度可分离卷积块和空间通道压缩与激励(scSE)注意力单元,模拟特征图中的通道和空间区域依赖关系。DAU-FI Net利用加法注意力门优化分割,并扩展特征空间。实验表明,该架构在下水道管道和涵洞缺陷数据集及基准数据集上实现了最先进的平均并集交(IoU),比之前方法高出8.9%和12.6%。
4、DilateFormer: Multi-Scale Dilated Transformer for Visual Recognition(TMM2023)
DilateFormer:用于视觉识别的多尺度扩张变压器
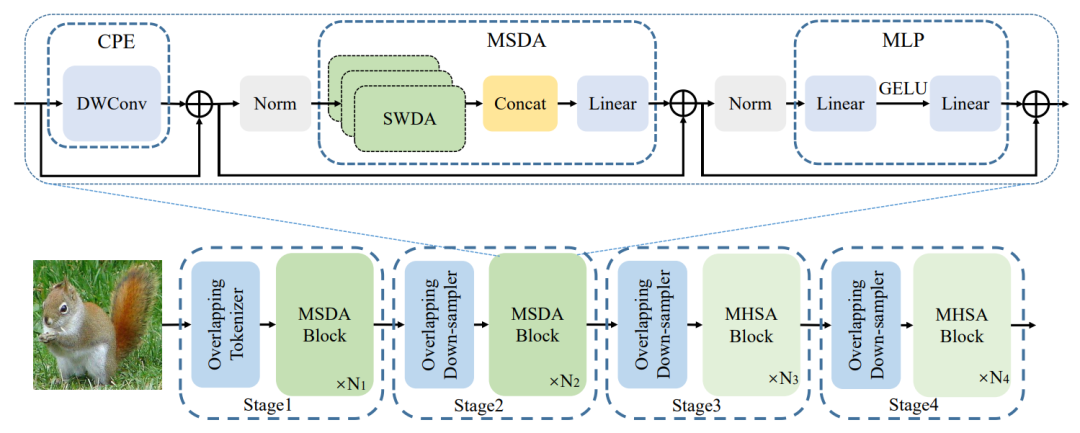
简述:本文提出了多尺度扩张注意力(MSDA)模块来模拟局部和稀疏斑块的相互作用,并构建了多尺度膨胀变压器(DilateFormer)。DilateFormer在视觉任务中表现出色,ImageNet-1 K分类任务上与先进模型相当,但FLOP减少了70%。DilateFormer-Base在ImageNet上达到85.6%的前1准确率,在COCO任务上分别达到53.5%的盒式mAP和46.1%的掩码mAP,在ADE20 K语义分割上达到51.1%的MS mIoU。
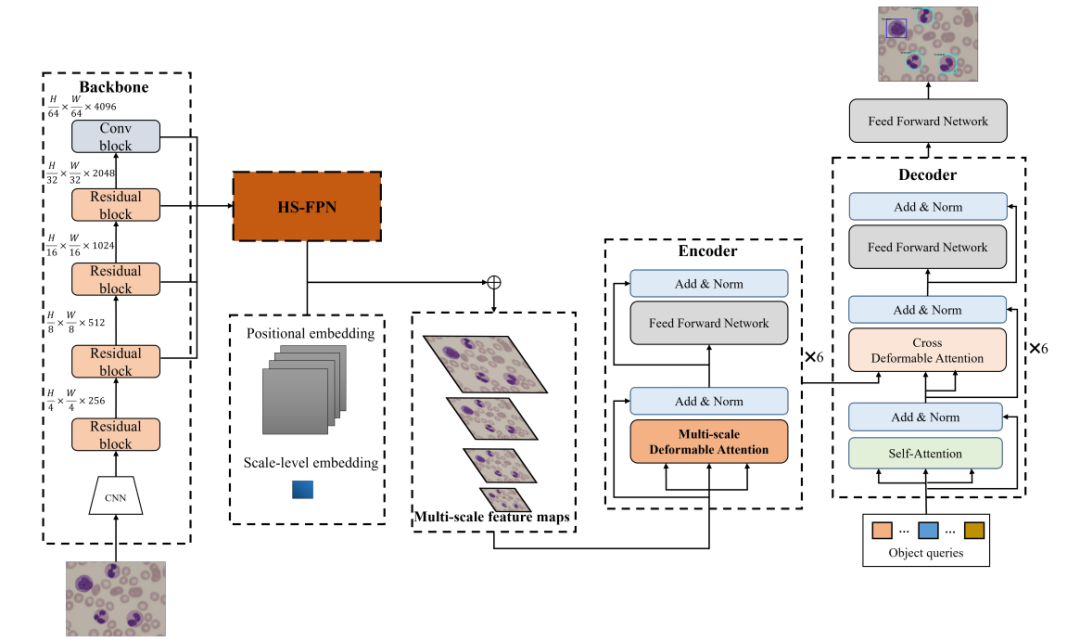
5、Accurate Leukocyte Detection Based on Deformable-DETR and Multi-Level Feature Fusion for Aiding Diagnosis of Blood Diseases
基于可变形DETR和多级特征融合的精准白细胞检测辅助血液病诊断
简述:本文提出了MFDS-DETR方法,使用多层次特征融合和可变自注意力机制来增强白细胞检测性能。通过在编码器中集成多尺度可变自注意力模块,在解码器中使用自注意力和交叉可变形注意力机制提取白细胞特征图的全球特征。实验证明,该方法在WBCDD、LISC和BCCD数据集上优于其他先进模型,有效性和通用性得到验证。
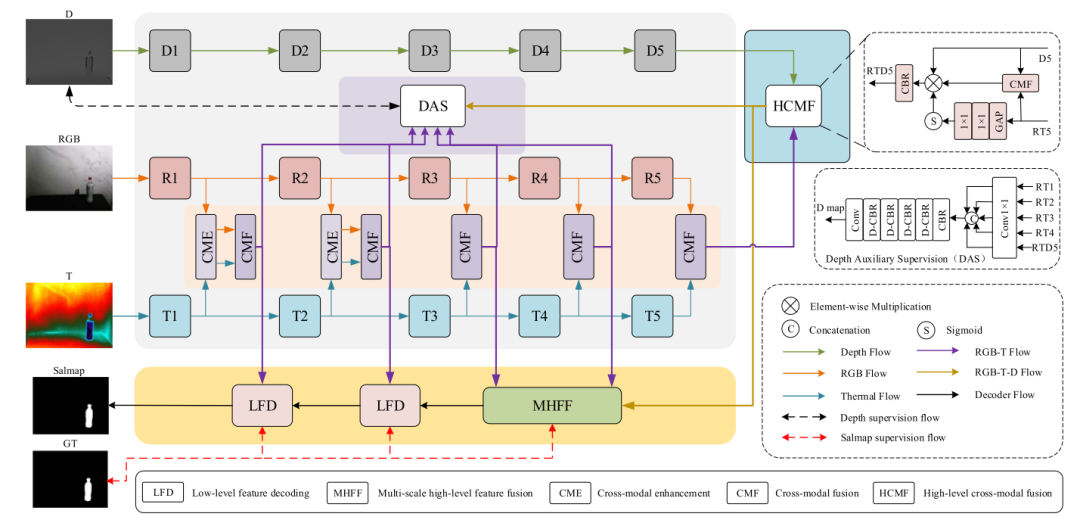
6、Lightweight multi-level feature difference fusion network for RGB-D-T salient object detection
用于RGB-D-T显著目标检测的轻量级多级特征差异融合网络
简述:本文提出了MFDF网络,用于实时RGB-D-T显著目标检测,这是首个此类网络。由于深度模态信息较少,研究人员采用基于MobileNetV2的非对称三流编码器,为减少冗余参数,还设计了低级特征解码模块和多尺度高级特征融合模块。MFDF在17种最先进方法中表现优异,速度快(320 × 320图像尺寸下124 FPS),参数少(8.9 M),实验证明其有效性。
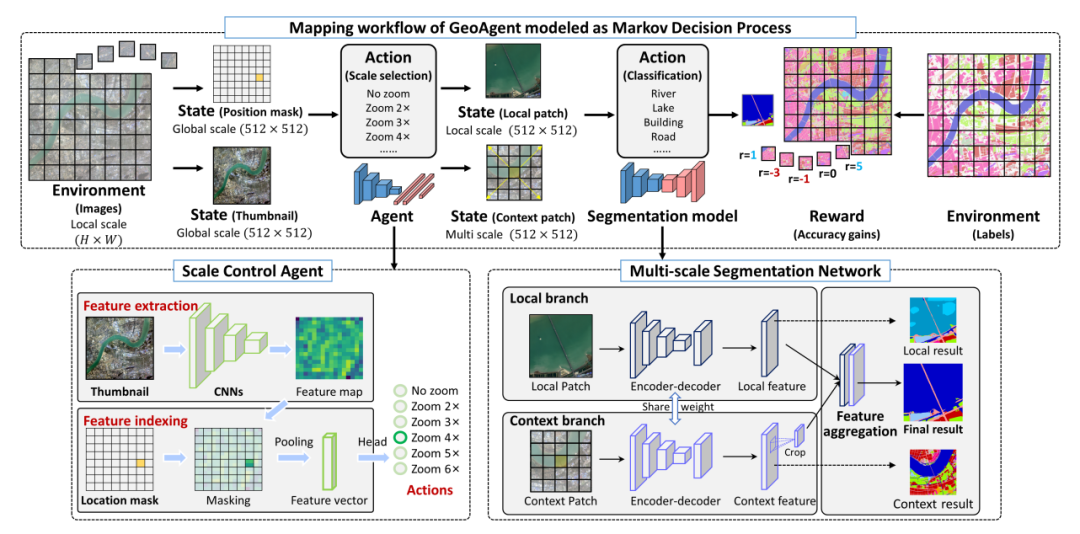
7、Seeing Beyond the Patch: Scale-Adaptive Semantic Segmentation of High-resolution Remote Sensing Imagery based on Reinforcement Learning(ICCV2023)
超越斑块:基于强化学习的超分辨率遥感图像的尺度自适应语义分割
简述:本文提出了GeoAgent,一个自适应的动态尺度感知框架,用于高分辨率遥感影像的语义分割。GeoAgent利用全局缩略图和位置蒙版为每个图像补丁提供上下文信息,并通过比例控制代理选择适当的尺度。特征索引模块增强了智能体对补丁位置的区分能力,双分支分割网络提取并融合多尺度特征。实验结果表明,GeoAgent在公开数据集和新构建的WUSU数据集上都优于其他分割方法,特别是在大规模测绘应用中。
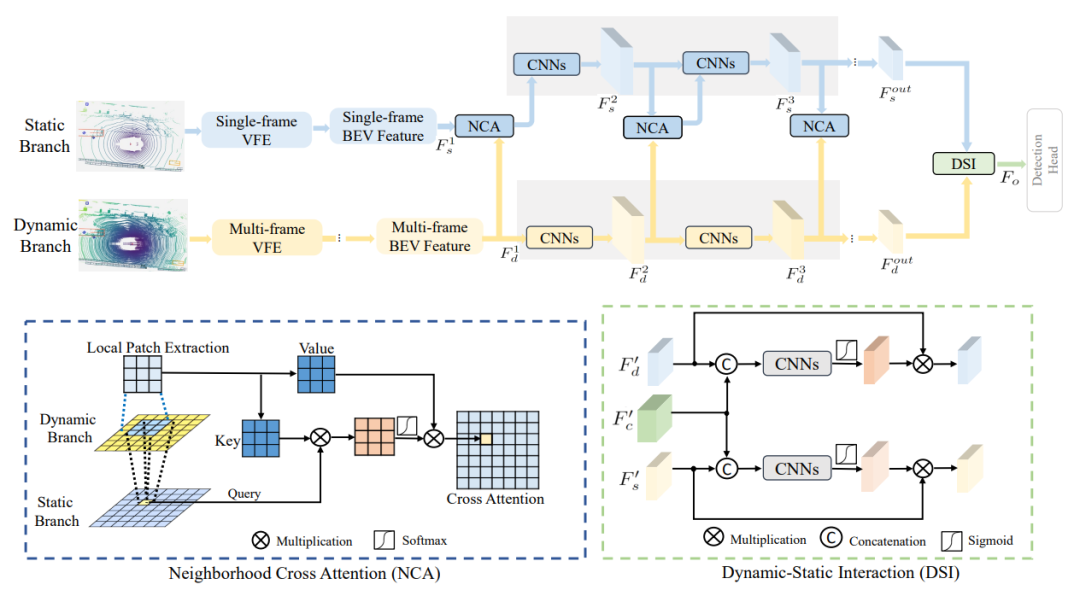
8、DynStatF: An Effcient Feature Fusion Strategy for LiDAR 3D Object Detection(CVPR2023)
DynStatF:一种用于LiDAR 3D目标检测的高效特征融合策略
简述:本文提出了一种新的特征融合策略DynStaF,通过当前单帧的精确位置信息增强多帧提供的丰富语义信息。DynStaF包含邻域交叉注意力(NCA)和动态-静态交互(DSI)模块,通过双路径架构运行,NCA模块将静态分支要素作为查询,动态分支要素作为键值,解决点云稀疏性,只考虑邻域位置。实验表明,DynStaF在nuScenes数据集上显著提升PointPillars性能至61.6%,与CenterPoint结合使用时,达到61.0%的mAP和67.7%的NDS,为最先进性能。
9、Lite DETR : An Interleaved Multi-Scale Encoder for Efficient DETR(CVPR2023)
Lite DETR:用于高效 DETR 的交错式多标度编码器
简述:本文提出了Lite DETR,一个简单高效的端到端目标检测框架,可将检测头的GFLOP降低60%,同时保持99%原始性能。通过交错更新高级和低级特征,研究人员设计高效编码器模块,为更好融合跨尺度特征,还开发键感知可变形注意力来预测更可靠权重。实验验证了Lite DETR的有效性和效率,且高效编码器策略适用于现有DETR模型。
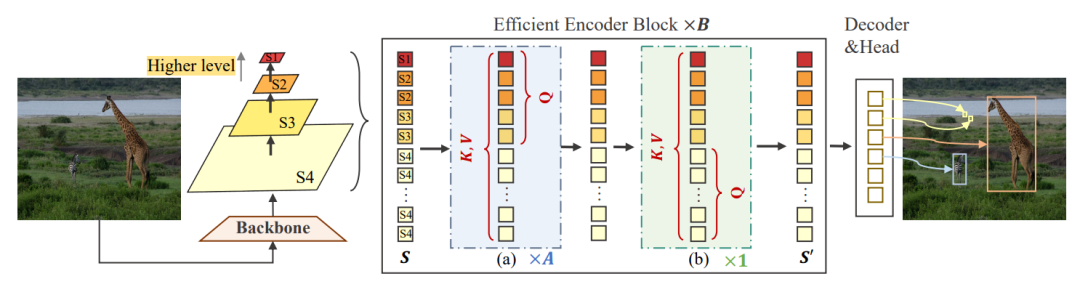
10、CDDFuse: Correlation-Driven Dual-Branch Feature Decomposition(CVPR2023)
CDDFuse:面向多模态图像融合的相关驱动双分支特征分解
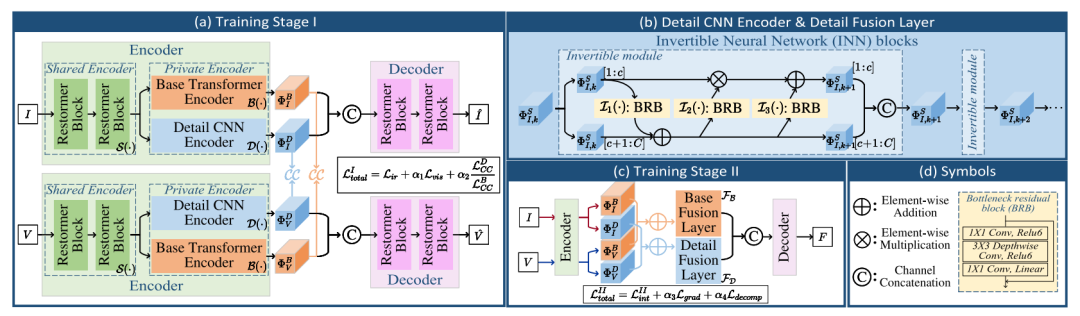
简述:本文提出了CDDFuse网络,这是一个新的多模态特征融合方法。它首先利用Restormer模块提取跨模态的浅层特征,然后通过一个双分支Transformer-CNN结构处理全局和局部特征,结合可逆神经网络(INN)来提取高频信息。CDDFuse使用相关驱动损失来优化特征融合,并结合全局和局部融合层生成最终图像。实验证明,CDDFuse在多种图像融合任务中表现优异,并提升了红外-可见光图像的语义分割和目标检测性能。
11、Centralized Feature Pyramid for Object Detection
用于目标检测的集中式特征金字塔
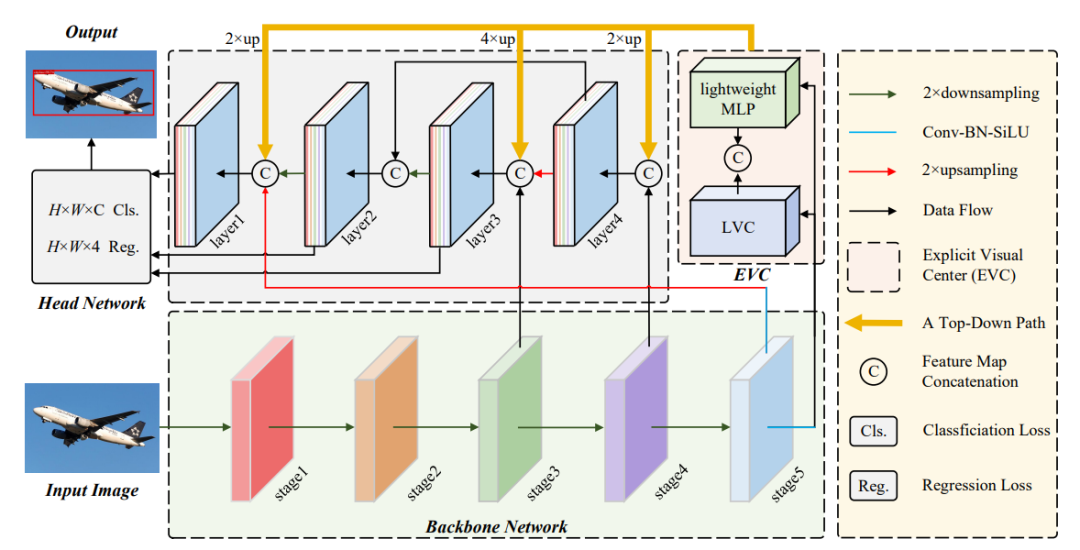
简述:本文提出了一种新的目标检测网络,称为集中式特征金字塔(CFP),它通过全局显式监管来优化特征。CFP使用轻量级MLP捕获全局依赖,并通过可学习的视觉中心机制关注图像的角落区域。这种方法通过从深层次特征中提取的信息来调节浅层次特征,实现了更全面和具有区分性的特征表示。在MS-COCO数据集上的实验表明,CFP能够提升YOLOv5和YOLOX目标检测基线的性能。
码字不易,欢迎大家点赞评论收藏!
关注下方《享享学AI》
回复【多尺度特征融合】获取完整论文
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

