
- 1从信息到知识到智能——理解和改变世界:Part 1 对世界的认知论视角
- 2django缓存机制_避免重复查询: 可以使用django提供的缓存机制,将查询结果缓存起来,避免重复查询。
- 3java实现layui分页_layui如何实现数据分页功能
- 4Springboot + netty + rabbitmq + myBatis系列(二) Netty 及心跳机制的 引入_springboot 设置rabbitmq心跳检测
- 5推荐一些视觉SLAM的深度学习方法(下)_gan slam
- 6奥比中光 Astra Pro 一代(MX400)RGBD 摄像头 彩色RGB及深度采集_python 奥比中光astra 摄像头采集深度图和rgb图像
- 7【C++】【二叉树】【红黑树】构建RB tree、红黑树 类_c++二叉树和红黑树
- 83D Gaussian Splatting Linux端部署指南(含Linux可视化)_gaussion-splatting在linux服务器上配置环境
- 9CnetSDK .NET PDF Library SDK Crack_cnetsdk .net pdf barcode reader sdk 库 dll
- 10鸿蒙系统是造假的,集体失声?鸿蒙系统官宣后,鸿蒙系统的真实现状显现
(五)CelebA && CelebA-HQ
赞
踩
文中部分内容转自两位大神,本人根据前人工作自行进行总结,将celeba数据集在windows上的生成做了进一步解释。
https://blog.csdn.net/weixin_39881922/article/details/81877005
https://blog.csdn.net/yunyi4367/article/details/80784205
CeleA是香港中文大学的开放数据,包含202599张人脸数据。
下载地址:
官网链接
百度网盘
下载好数据集之后可看到如下目录,其中Img里面的数据便是可用于深度学习训练的人脸数据。

打开Img可看到如下目录,其中 img_celeba.7z文件夹下面有14个压缩包,解压后可得到作者从网上爬虫得到的数据原图,这个数据大小不一,未经裁剪。 img_align_celeba_png.7z文件夹中有16个压缩包,是将原图裁剪后得到的
178*218大小的png数据,比较大。 img_align_celeba.zip 压缩包内是202599张剪切为178*218的jpg格式数据,可直接解压使用。

解压后可得到这样的一些jpg数据。

在深度学习中,我们往往需要方形的数据、高清数据集,或由于cpu/gpu计算能力不足而需要将人脸resize。这就需要我们生成高清人脸数据集CelebA-HQ。
1.解压得到原图
已经下载好img_celeba.7z 需要将其中的14个压缩包解压,得到202599张从原图。
原来的压缩包是这样的,无法直接解压。

windows:copy /B img_celeba.7z.0** img_celeba.7z
linux: cat img_celeba.7z.0** > img_celeba.7z
就可以合并压缩包,得到这个压缩包就可以直接解压得到202599张图片了。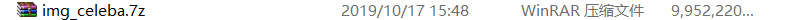
2.下载deltas文件
https://drive.google.com/drive/folders/0B4qLcYyJmiz0TXY1NG02bzZVRGs
文件夹内有30个zip文件,不需要解压缩。注意里面的 image_list.txt 不能丢掉。
3.下载github上这位仁兄的h5tool.py,他的才能直接得到jpg文件,另外一个大兄弟的得到的是hdf5文件
https://github.com/willylulu/celeba-hq-modified
4.创建图片保存目录:
当前文件夹下创建目录celeba-hq,在此目录下创建如下目录。
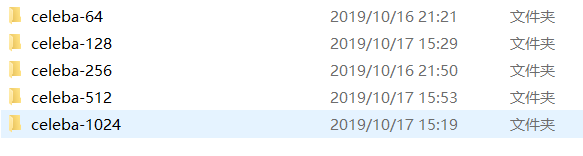
4.的到最终目录如下:

python2.7环境下执行命令:
python h5tool.py create_celeba_hq 123456.h5 ./ ./delta/
便可以生成30000张64,128,256,512,1024的高清celeba人脸图片。

- 相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

