
opencv人脸检测总结_opencv人脸识别实验报告
赞
踩
主要参考了很多大神的总结,做了自己的整理,还没有完成,后续不断完善补充
opencv人脸检测总结
一.人脸检测介绍
1. 人脸检测分类

基于知识方法主要利用先验知识将人脸看作器官特征的组合,根据眼睛、眉毛、嘴巴、鼻子等器官的特征以及相互之间的几何位置关系来检测人脸。
基于统计的方法则将人脸看作一个整体的模式——二维像素矩阵,从统计的观点通过大量人脸图像样本构造人脸模式空间,根据相似度量来判断人脸是否存在。在这两种框架之下,发展了许多方法。
目前随着各种方法的不断提出和应用条件的变化,将知识模型与统计模型相结合。
在实际工程应用中,用得广泛的人脸检测算法还是基于Adaboost的这些算法,主要是其计算量小,特别适合在嵌入式端实现,或者是基于浅层的神经网络检测算法。随着芯片技术的发展,带有深度学习网络的芯片将会越来越普遍,这样基于深度学习的人脸检测算法将会成为主流。
2. 人脸检测原理
人脸检测属于目标检测(object detection) 的一部分,主要涉及两个方面。

1.先对要检测的目标对象进行概率统计,从而知道待检测对象的一些特征,建立起目标检测模型。
2.用得到的模型来匹配输入的图像,如果有匹配则输出匹配的区域,否则什么也不做。
以下主要介绍一个opencv人脸检测。Opencv人脸检测主要用的是Adaboost算法。
二.Opencv人脸检测
在OpenCV中主要使用了两种特征(即两种方法)进行人脸检测,Haar特征和LBP特征,下面详细介绍一下Haar特征。
OpenCV在人脸检测上使用的是haar特征的级联表,这个级联表中包含的是boost的分类器。
Haar分类器算法的要点如下:
① 使用Haar-like特征做检测。
② 使用积分图(Integral Image)对Haar-like特征求值进行加速。
③ 使用AdaBoost算法训练区分人脸和非人脸的强分类器。
④ 使用筛选式级联把强分类器级联到一起,提高准确率。
1. Haar-like特征

- 边界特征,包含四种
- 线性特征,包含8种
- 中心围绕特征,包含两种
通俗来说,将上面的任意一个矩形放到人脸区域上,然后,将白色区域的像素和减去黑色区域的像素和,得到的值暂且称之为人脸特征值,如果你把这个矩形放到一个非人脸区域,那么计算出的特征值应该和人脸特征值是不一样的,而且越不一样越好,所以这些方块的目的就是把人脸特征量化,以区分人脸和非人脸
那么什么样的矩形特征怎么样的组合到一块可以更好的区分出人脸和非人脸呢,这就是AdaBoost算法要做的事了。
2. AdaBost算法
AdaBoost是Freund 和Schapire在1995年提出的算法,是对传统Boosting算法的一大提升。AdaBoost是自适应Boosting算法。
Boosting算法的核心思想,是将弱学习方法提升成强学习算法,也就是“三个臭皮匠顶一个诸葛亮”,它的理论基础来自于Kearns 和Valiant的相关证明。Boosting算法涉及到两个重要的概念就是弱学习和强学习,所谓的弱学习,就是指一个学习算法对一组概念的识别率只比随机识别好一点,所谓强学习,就是指一个学习算法对一组概率的识别率很高。
利用AdaBoost算法可以选择更好的矩阵特征组合,即分类器,分类器将矩阵组合以二叉决策树的形式存储起来。
2.1弱分类器的孵化
最初的弱分类器可能只是一个最基本的Haar-like特征,计算输入图像的Haar-like特征值,和最初的弱分类器的特征值比较,以此来判断输入图像是不是人脸,然而这个弱分类器太简陋了,可能并不比随机判断的效果好,对弱分类器的孵化就是训练弱分类器成为最优弱分类器,注意这里的最优不是指强分类器,只是一个误差相对稍低的弱分类器,训练弱分类器实际上是为分类器进行设置的过程。至于如何设置分类器,设置什么,我们首先分别看下弱分类器的数学结构和代码结构。

一个弱分类器![]() 由子窗口图像x,一个特征f,指示不等号方向的p和阈值
由子窗口图像x,一个特征f,指示不等号方向的p和阈值![]() 组成。P的作用是控制不等式的方向,使得不等式都是<号,形式方便。
组成。P的作用是控制不等式的方向,使得不等式都是<号,形式方便。
- 代码结构
- /*
- * CART classifier
- */
- typedef struct CvCARTHaarClassifier
- {
- CV_INT_HAAR_CLASSIFIER_FIELDS()
- int count; ;//这个弱分类器需要的Haar-like特征数目,如果上传调用时nsplits为1这个count值即为1,也就是说一般理解的弱分类器
- int* compidx; //选择出的这个弱分类器的Haar-like特征的序号
- CvTHaarFeature* feature; //选择出的这个弱分类器的Haar-like特征
- CvFastHaarFeature* fastfeature;
- float* threshold; //选择出的这个弱分类器的Haar-like特征的threshold
- int* left; ;//跟CART树有关,应该是Node的序号
- int* right; //跟CART树有关,应该是Node的序号
- float* val; //跟上面的threshold比较后的output值,其实是code里面的 //Curleft和curright
- } CvCARTHaarClassifier;
代码结构中的threshold即代表数学结构中的![]() 阈值。
阈值。
这个阈值究竟是干什么的?我们先了解下CvCARTHaarClassifier这个结构,注意CART这个词,它是一种二叉决策树,它的提出者Leo Breiman等牛称其为“分类和回归树(CART)”。什么是决策树?我如果细讲起来又得另起一章,我只简略介绍它。
“机器学习中,决策树是一个预测模型;他代表的是对象属性与对象值之间的一种映射关系。树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每个叶结点则对应从根节点到该叶节点所经历的路径所表示的对象的值。决策树仅有单一输出,若欲有复数输出,可以建立独立的决策树以处理不同输出。从数据产生决策树的机器学习技术叫做决策树学习, 通俗说就是决策树。”(来自《维基百科》)
决策树包含:分类树,回归树,分类和回归树(CART),CHAID 。
分类和回归的区别是,分类是当预计结果可能为两种类型(例如男女,输赢等)使用的概念。 回归是当局域结果可能为实数(例如房价,患者住院时间等)使用的概念。
决策树用途很广可以分析因素对事件结果的影响(详见维基百科),同时也是很常用的分类方法,我举个最简单的决策树例子,假设我们使用三个Haar-like特征f1,f2,f3来判断输入数据是否为人脸,可以建立如下决策树:
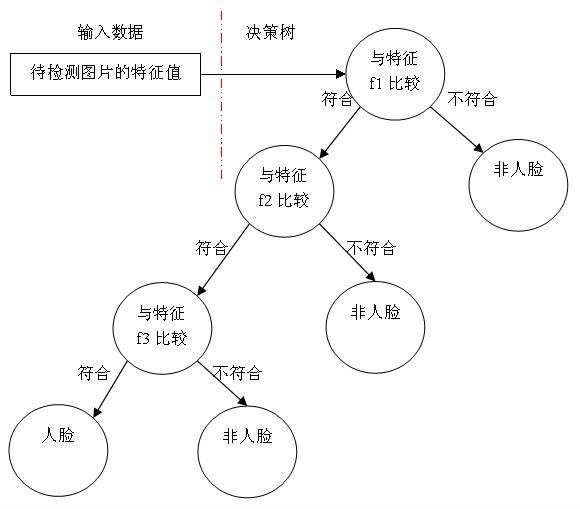
可以看出,在分类的应用中,每个非叶子节点都表示一种判断,每个路径代表一种判断的输出,每个叶子节点代表一种类别,并作为最终判断的结果。
一个弱分类器就是一个基本和上图类似的决策树,最基本的弱分类器只包含一个Haar-like特征,也就是它的决策树只有一层,被称为树桩(stump)。
最重要的就是如何决定每个结点判断的输出,要比较输入图片的特征值和弱分类器中特征,一定需要一个阈值,当输入图片的特征值大于该阈值时才判定其为人脸。训练最优弱分类器的过程实际上就是在寻找合适的分类器阈值,使该分类器对所有样本的判读误差最低。
具体操作过程如下:
1)对于每个特征 f,计算所有训练样本的特征值,并将其排序。
扫描一遍排好序的特征值,对排好序的表中的每个元素,计算下面四个值:
全部人脸样本的权重的和t1;
全部非人脸样本的权重的和t0;
在此元素之前的人脸样本的权重的和s1;
在此元素之前的非人脸样本的权重的和s0;
2)最终求得每个元素的分类误差![]()
在表中寻找r值最小的元素,则该元素作为最优阈值。有了该阈值,我们的第一个最优弱分类器就诞生了。
在这漫长的煎熬中,我们见证了一个弱分类器孵化成长的过程,并回答了如何得到弱分类器以及二叉决策树是什么。最后的问题是强分类器是如何得到的。
2.2弱分类器的化蝶飞
首先看一下强分类器的代码结构:
- /* internal stage classifier */
- typedef struct CvStageHaarClassifier
- {
- CV_INT_HAAR_CLASSIFIER_FIELDS()
- int count;
- float threshold;
- CvIntHaarClassifier** classifier;
- }CvStageHaarClassifier;
- /* internal weak classifier*/
- typedef struct CvIntHaarClassifier
- {
- CV_INT_HAAR_CLASSIFIER_FIELDS()
- } CvIntHaarClassifier;
这里要提到的是CvIntHaarClassifier结构: 它就相当于一个接口类,当然是用C语言模拟的面向对象思想,利用CV_INT_HAAR_CLASSIFIER_FIELDS()这个宏让弱分类CvCARTHaarClassifier强分类器和CvStageHaarClassifier继承于CvIntHaarClassifier。
强分类器的诞生需要T轮的迭代,具体操作如下:
1. 给定训练样本集S,共N个样本,其中X和Y分别对应于正样本和负样本; T为训练的最大循环次数;
2. 初始化样本权重为1/N ,即为训练样本的初始概率分布;
3. 第一次迭代训练N个样本,得到第一个最优弱分类器,步骤见2.2.2节
4. 提高上一轮中被误判的样本的权重;
5. 将新的样本和上次本分错的样本放在一起进行新一轮的训练。
6. 循环执行4-5步骤,T轮后得到T个最优弱分类器。
7.组合T个最优弱分类器得到强分类器,组合方式如下:
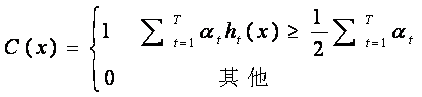
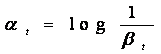
相当于让所有弱分类器投票,再对投票结果按照弱分类器的错误率加权求和,将投票加权求和的结果与平均投票结果比较得出最终的结果。
至此,我们看到其实我的题目起的漂亮却并不贴切,强分类器的脱颖而出更像是民主的投票制度,众人拾材火焰高,强分类器不是个人英雄主义的的产物,而是团结的力量。但从宏观的局外的角度看,整个AdaBoost算法就是一个弱分类器从孵化到化蝶的过程。小人物的奋斗永远是理想主义者们津津乐道的话题。但暂时让我们放下AdaBoost继续探讨Haar分类器的其他特性吧。
2.3强分类器的强强联手
至今为止我们好像一直在讲分类器的训练,实际上Haar分类器是有两个体系的,训练的体系,和检测的体系。训练的部分大致都提到了,还剩下最后一部分就是对筛选式级联分类器的训练。我们看到了通过AdaBoost算法辛苦的训练出了强分类器,然而在现实的人脸检测中,只靠一个强分类器还是难以保证检测的正确率,这个时候,需要一个豪华的阵容,训练出多个强分类器将它们强强联手,最终形成正确率很高的级联分类器这就是我们最终的目标Haar分类器。
那么训练级联分类器的目的就是为了检测的时候,更加准确,这涉及到Haar分类器的另一个体系,检测体系,检测体系是以现实中的一幅大图片作为输入,然后对图片中进行多区域,多尺度的检测,所谓多区域,是要对图片划分多块,对每个块进行检测,由于训练的时候用的照片一般都是20*20左右的小图片,所以对于大的人脸,还需要进行多尺度的检测,多尺度检测机制一般有两种策略,一种是不改变搜索窗口的大小,而不断缩放图片,这种方法显然需要对每个缩放后的图片进行区域特征值的运算,效率不高,而另一种方法,是不断初始化搜索窗口size为训练时的图片大小,不断扩大搜索窗口,进行搜索,解决了第一种方法的弱势。在区域放大的过程中会出现同一个人脸被多次检测,这需要进行区域的合并,这里不作探讨。
无论哪一种搜索方法,都会为输入图片输出大量的子窗口图像,这些子窗口图像经过筛选式级联分类器会不断地被每一个节点筛选,抛弃或通过。
结构如图:
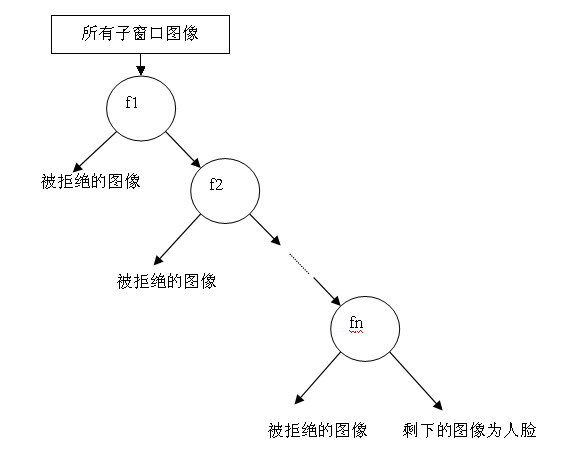
我想你一定觉得很熟悉,这个结构不是很像一个简单的决策树么。
在代码中,它的结构如下:
- /* internal tree cascade classifier node */
- typedef struct CvTreeCascadeNode
- {
- CvStageHaarClassifier* stage;
- struct CvTreeCascadeNode* next;
- struct CvTreeCascadeNode* child;
- struct CvTreeCascadeNode* parent;
- struct CvTreeCascadeNode* next_same_level;
- struct CvTreeCascadeNode* child_eval;
- int idx;
- int leaf;
- } CvTreeCascadeNode;
- /* internal tree cascade classifier */
- typedef struct CvTreeCascadeClassifier
- {
- CV_INT_HAAR_CLASSIFIER_FIELDS()
- CvTreeCascadeNode* root; /* root of the tree */
- CvTreeCascadeNode* root_eval; /* root node for the filtering */
- int next_idx;
- } CvTreeCascadeClassifier;
级联强分类器的策略是,将若干个强分类器由简单到复杂排列,希望经过训练使每个强分类器都有较高检测率,而误识率可以放低,比如几乎99%的人脸可以通过,但50%的非人脸也可以通过,这样如果有20个强分类器级联,那么他们的总识别率为0.99^20 ![]() 98%,错误接受率也仅为0.5^20
98%,错误接受率也仅为0.5^20 ![]() 0.0001%。这样的效果就可以满足现实的需要了,但是如何使每个强分类器都具有较高检测率呢,为什么单个的强分类器不可以同时具有较高检测率和较高误识率呢?
0.0001%。这样的效果就可以满足现实的需要了,但是如何使每个强分类器都具有较高检测率呢,为什么单个的强分类器不可以同时具有较高检测率和较高误识率呢?
下面我们讲讲级联分类器的训练。(主要参考了论文《基于Adaboost的人脸检测方法及眼睛定位算法研究》)
设K是一个级联检测器的层数,D是该级联分类器的检测率,F是该级联分类器的误识率,di是第i层强分类器的检测率,fi是第i层强分类器的误识率。如果要训练一个级联分类器达到给定的F值和D值,只需要训练出每层的d值和f值,这样:
d^K = D,f^K = F
级联分类器的要点就是如何训练每层强分类器的d值和f值达到指定要求。
AdaBoost训练出来的强分类器一般具有较小的误识率,但检测率并不很高,一般情况下,高检测率会导致高误识率,这是强分类阈值的划分导致的,要提高强分类器的检测率既要降低阈值,要降低强分类器的误识率就要提高阈值,这是个矛盾的事情。据参考论文的实验结果,增加分类器个数可以在提高强分类器检测率的同时降低误识率,所以级联分类器在训练时要考虑如下平衡,一是弱分类器的个数和计算时间的平衡,二是强分类器检测率和误识率之间的平衡。
具体训练方法如下,我用伪码的形式给出:
1)设定每层最小要达到的检测率d,最大误识率f,最终级联分类器的误识率Ft;
2)P=人脸训练样本,N=非人脸训练样本,D0=1.0,F0=1.0;
3)i=0;
4)for : Fi>Ft
++i;
ni=0;Fi=Fi-1;
for : Fi>f*Fi-1
++ni;
利用AdaBoost算法在P和N上训练具有ni个弱分类器的强分类器;
衡量当前级联分类器的检测率Di和误识率Fi;
for : di<d*Di-1;
降低第i层的强分类器阈值;
衡量当前级联分类器的检测率Di和误识率Fi;
N = Φ;
利用当前的级联分类器检测非人脸图像,将误识的图像放入N;
3.积分图
之所以放到最后讲积分图(Integral image),不是因为它不重要,正相反,它是Haar分类器能够实时检测人脸的保证。当我把Haar分类器的主脉络都介绍完后,其实在这里引出积分图的概念恰到好处。
在前面的章节中,我们熟悉了Haar-like分类器的训练和检测过程,你会看到无论是训练还是检测,每遇到一个图片样本,每遇到一个子窗口图像,我们都面临着如何计算当前子图像特征值的问题,一个Haar-like特征在一个窗口中怎样排列能够更好的体现人脸的特征,这是未知的,所以才要训练,而训练之前我们只能通过排列组合穷举所有这样的特征,仅以Viola牛提出的最基本四个特征为例,在一个24×24size的窗口中任意排列至少可以产生数以10万计的特征,对这些特征求值的计算量是非常大的。
而积分图就是只遍历一次图像就可以求出图像中所有区域像素和的快速算法,大大的提高了图像特征值计算的效率。
我们来看看它是怎么做到的。
积分图是一种能够描述全局信息的矩阵表示方法。积分图的构造方式是位置(i,j)处的值ii(i,j)是原图像(i,j)左上角方向所有像素的和:
![]()
积分图构建算法:
1)用s(i,j)表示行方向的累加和,初始化s(i,-1)=0;
2)用ii(i,j)表示一个积分图像,初始化ii(-1,i)=0;
3)逐行扫描图像,递归计算每个像素(i,j)行方向的累加和s(i,j)和积分图像ii(i,j)的值
s(i,j)=s(i,j-1)+f(i,j)
ii(i,j)=ii(i-1,j)+s(i,j)
4)扫描图像一遍,当到达图像右下角像素时,积分图像ii就构造好了。
积分图构造好之后,图像中任何矩阵区域的像素累加和都可以通过简单运算得到如图所示。
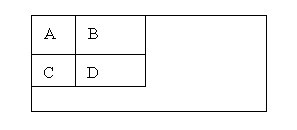
设D的四个顶点分别为α、β、γ、δ,则D的像素和可以表示为
Dsum = ii( α )+ii( β)-(ii( γ)+ii( δ ));
而Haar-like特征值无非就是两个矩阵像素和的差,同样可以在常数时间内完成。
4. Opencv人脸检测
人脸的Haar特征分类器是什么?
人脸的Haar特征分类器就是一个XML文件,该文件中会描述人脸的Haar特征值。当然Haar特征的用途可不止可以用来描述人脸这一种,用来描述眼睛,嘴唇或是其它物体也是可以的。
首先,采用样本的haar特征进行分类器的训练,从而得到一个级联的boost分类器。训练的方式包含两方面:
1. 正例样本,即待检测目标样本
2. 反例样本,其他任意的图片
首先将这些图片统一成相同的尺寸,这个过程被称为归一化,然后进行统计。一旦分类器建立完成,就可以用来检测输入图片中的感兴趣区域的检测了,一般来说,输入的图片会大于样本,那样,需要移动搜索窗口,为了检索出不同大小的目标,分类器可以按比例的改变自己的尺寸,这样可能要对输入图片进行多次的扫描。
什么是级联的分类器呢?级联分类器是由若干个简单分类器级联成的一个大的分类器,被检测的窗口依次通过每一个分类器,可以通过所有分类器的窗口即可判定为目标区域
三.Opencv 人脸检测步骤
- 读入图片
- 彩色图片转化为灰度图片,因为harr特征从灰度图中提取。
- 进行灰度图直方图均衡化操作
- 检测人脸
Opencv人脸检测弱点:
Viola and Jones提出了开创性算法,他们通过Haar-Like特征和AdaBoost去训练级联分类器获得实时效果很好的人脸检测器,然而研究指出当人脸在非约束环境下,该算法检测效果极差。这里说的非约束环境是对比于约束情况下人脸数单一、背景简单、直立正脸等相对理想的条件而言的,随着人脸识别、人脸跟踪等的大规模应用,人脸检测面临的要求越来越高(如上图):人脸尺度多变、数量冗大、姿势多样包括俯拍人脸、戴帽子口罩等的遮挡、表情夸张、化妆伪装、光照条件恶劣、分辨率低甚至连肉眼都较难区分等。
- 人脸检测难点
人脸检测是个复杂的极具挑战性的模式识别问题,主要难点如下:
1)姿态。人脸与摄像机镜头的相对位置决定了人脸姿态的多样性,上下俯仰角、左右偏角、竖直面旋转角都不一样。
2)遮挡。人脸在图像里可能会被其它人脸遮挡或者被背景等遮挡,这样只漏出局部的人脸。另外,人脸附属物也会导致遮挡,如眼镜、口罩、长发、胡须等。
3)光照。不同光谱、光源位置、光照强度等都会对人脸外观产生影响,如背光环境下,人脸一般偏暗甚至细节都看不清;而在单一强光源下,人脸则会呈现出“阴阳脸”。
五.小知识补充

BP是一种按照误差逆向传播算法训练的多层前馈神经网络。
神经网络包括了多层神经网络(可以当做普通的神经网络)和卷积神经网络等,而卷积神经网络又属于深度学习中最为重要的算法。我们这所谓的层指的神经网络的层数,但是也并不是层数多了就是深度学习,深度学习一定是层数多最起码3层以上吧!
1.“深度学习”和”多层神经网络”的区别?
关于“深度学习”和“多层神经网络”的区别? 借用知乎上比较理性和感性的认识 分析一下。从广义上说深度学习的网络结构也是多层神经网络的一种。
传统意义上的多层神经网络是只有输入层、隐藏层、输出层。其中隐藏层的层数根据需要而定,没有明确的理论推导来说明到底多少层合适。
而深度学习中最著名的卷积神经网络CNN,在原来多层神经网络的基础上,加入了特征学习部分,这部分是模仿人脑对信号处理上的分级的。具体操作就是在原来的全连接的层前面加入了部分连接的卷积层与降维层,而且加入的是一个层级。 输入层 - 卷积层 -降维层 -卷积层 - 降维层 – …. – 隐藏层 -输出层。
简单来说,多层神经网络做的步骤是:特征映射到值,特征是人工挑选。
深度学习步骤是: 信号->特征->值,特征是由网络自己选择。
两种网络被设计出来,所要解决的问题和目的不同。
作者:杨延生 来源:知乎链接:https://www.zhihu.com/question/26017374/answer/31868340
作者:Bipolar Bear来源:知乎链接:https://www.zhihu.com/question/26017374/answer/127924427
2. 多层神经网络
多层神经网络与universal approximation theorem [1] (泛逼近性原理,不知这样翻译可对?)相伴而生。
该理论指出,单隐藏层(hidden layer)非线性前馈神经网络,可以在实数空间近似任何连续函数。上世纪80 90年代,Backpropagation 刚刚开始大行其道,利用这一算法,只需知道输入和输出便可训练网络参数,从而得到一个神经网络“黑箱”。之所以称为黑箱,是因为无需知道y=f(x) 中f的表达式是什么,也能轻易做函数计算,因为f(objective function)就是网络本身。多层神经网络的座右铭是:“函数是什么我不管,反正我能算!“。
当然多层神经网络并非天下无敌,它有三个主要限制:
- 在面对大数据时,需要人为提取原始数据的特征作为输入。必须忽略不相关的变量,同时保留有用的信息。这个尺度很难掌握,多层神经网络会把蹲在屋顶的Kitty和骑在猫奴头上的Kitty识别为不同的猫咪,又会把二哈和狼归类为同一种动物。前者是对不相关变量过于敏感,后者则因无法提取有实际意义的特征。
- 想要更精确的近似复杂的函数,必须增加隐藏层的层数,这就产生了梯度扩散问题
- 无法处理时间序列数据(比如音频),因为多层神经网络不含时间参数。随着人工智能需求的提升,我们想要做复杂的图像识别,做自然语言处理,做语义分析翻译,等等。多层神经网络显然力不从心。
3.深度学习
那么深度模型是如何解决以上三个问题的?
- 深度学习自动选择原始数据的特征。举一个图像的例子,将像素值矩阵输入深度网络(这里指常用于图像识别的卷积神经网络CNN),网络第一层表征物体的位置、边缘、亮度等初级视觉信息。第二层将边缘整合表征物体的轮廓……之后的层会表征更加抽象的信息,如猫或狗这样的抽象概念。所有特征完全在网络中自动呈现,并非出自人工设计。更重要的一点是这种随着层的深入,从具象到抽象的层级式表征跟大脑的工作原理吻合,视网膜接收图像从LGN到视皮层、颞叶皮层再到海马走的是同样的路数[2]!
- 深度网络的学习算法。一种方法是改变网络的组织结构,比如用卷积神经网络代替全连接(full connectivity)网络,训练算法仍依据Backpropagating gradients的基本原理。另一种则是彻底改变训练算法,我尝试过的算法有Hessian-free optimization[3],recursive least-squares(RLS) 等。
- 使用带反馈和时间参数的Recurrent neural network 处理时间序列数据。从某种意义上讲,Recurrent neural network可以在时间维度上展开成深度网络,可以有效处理音频信息(语音识别和自然语言处理等),或者用来模拟动力系统。

