
- 1jenkins自动化部署_jenkins打包,发布,部署
- 2vuecli3直接在本地打开dist文件中的index.html出现白屏的问题_vue dist 不能直接访问
- 3自然语言处理实验—用隐马尔可夫模型在分词中的应用计算概率矩阵(含python代码和详细例子解释)_发射概率矩阵
- 4【Kotlin基础系列】第6章 包与导入_kotlin import
- 5华为系统鸿蒙流畅度,鸿蒙系统流畅度怎么样 华为鸿蒙系统流畅度评测详解
- 6微信小程序--Taro框架实际开发中的问题汇总_taro 小程序 报错 exports.usecontext (vendors.js? [sm]:1
- 7python学生管理器_完成数据模型类studentmodel
- 8当微信小程序邂逅知识问答,订单就按耐不住了!_mini订单内容
- 9从关键新闻和最新技术看AI行业发展(2023.12.4-12.17第十二期) |【WeThinkIn老实人报】_phi-2 开源地址
- 10鸿蒙OS基于安卓11,华为鸿蒙OS 2.0、EMUI 11对比:安卓底层没了
一文详解深度树检索技术(TDM)三部曲(与Deep Retrieval)
赞
踩

©作者 | wdmad
来源 | 数据科学の杂谈
推荐系统的主要目的是从海量物品库中高效检索用户最感兴趣的物品,既然是“海量”,意味着用户基本不可能浏览完所有的物品,所以才需要推荐系统来辅助用户高效获取感兴趣的信息。同样也正是因为“海量”,由于算力的限制,复杂模型也是很难直接遍历每个物品算出分数来排序。如今的推荐系统通常大致分为召回(retrieval)和排序(ranking)两个阶段,召回是从全量物品库中快速得到一个候选集合,通常是几百到几千,后面的排序模块则使用更复杂的模型对候选集排序得到 top-k 物品推荐给用户。
召回需要在速度和准确性上作平衡,其结果很大程度上决定了推荐的上限。如果其返回的候选集中没有包含用户感兴趣的物品,那么后面的排序模型能力再强也没用。但是受速度的限制,长期以来的主流做法是使用简单模型如物品协同过滤,或者获取 embedding 后转换成向量最近邻搜索问题。
这种方案在模型表达能力上有一定的局限,而且近邻搜索与实际的目标(如提升点击率)在优化方向上不一定一致。想要在召回中直接使用复杂模型特别是近几年涌现出来的各种深度学习模型作推理,在这个领域很长一段时间来都没什么大的进展。
不过局面终有一天会被打破,本篇介绍的这些近几年公开的算法皆是致力于探索在大规模召回问题中直接使用复杂模型。标题中的 TDM 三部曲指的是以 TDM 为首的三篇围绕树结构的论文:
Learning Tree-based Deep Model for Recommender Systems [1] (TDM, 2018)
Joint Optimization of Tree-based Index and Deep Model for Recommender Systems [2] (JTM, 2019)
Learning Optimal Tree Models under Beam Search [3] (OTM, 2020)
Deep Retrieval 指的是论文:
Deep Retrieval: Learning A Retrievable Structure for Large-Scale Recommendations [4] (2020)
这里需要指出的是虽然从论文发表时间来看是 TDM -> JTM -> OTM,但 OTM 严格意义上不能算是 JTM 的改进版本。因为 TDM 的训练大致分为两步:树的学习和模型的学习,JTM 改进的是前者,而 OTM 改进的是后者,因而 JTM 和 OTM 看上去更像是同父异母的姐妹。
现在回到最开始的问题,是什么制约了召回中复杂模型的使用?复杂模型不可避免地使得线上单个样本的计算时间增大,那么遍历全量物品库显然不可承受。如果把召回看作是一个检索的过程,即从全量库中检索符合条件的物品,那么可以产生一些新的思路。
我们知道在传统数据库中可以通过添加索引来极大增加查询效率,那么在召回中是否也可以迁移这种思想?TDM 和 Deep Retrieval 论文的核心就是立足于如何构建这样一套高效的索引结构来增加检索效率,从而使得在召回中直接使用复杂模型成为可能。
下面逐一说明这些算法的内部原理,另外从应用的角度也会讲一些实现细节,完整代码见:
https://github.com/massquantity/dismember
TDM 有官方的开源实现 [5],而我的 TDM 实现在原版基础上未做过多修改,相当于将原版的 Python2 和 C++ 代码用 Scala 重写了一遍。是的,我诧异地发现原版用的貌似是 Python2。而 JTM、OTM 和 Deep Retrieval 甚至没找到什么开源的实现(不排除以后有),因此也就自由发挥了。

TDM
如上文所述,TDM 通过树这种数据结构来构建索引。照原论文里的说法是可以使用多叉树,但无论是论文还是官方实现使用的都是二叉树,所以这里仅讨论二叉树的情况。
考虑下图的这棵树,每一个物品对应着树上的一个叶节点(图中 id 为 7 到 14),我们的目标是得到用户可能偏好最大的 K 个物品,即最底层的 K 个叶节点。用户的偏好可用 来表示,意为用户 对于节点 感兴趣的概率。这实际上就是个二分类问题,将用户特征和节点 id 输入某个模型如深度神经网络就可以得到这个概率,按概率排序后进而得到 top-K 个物品。现在的问题是如何高效地得到这些叶节点的概率?
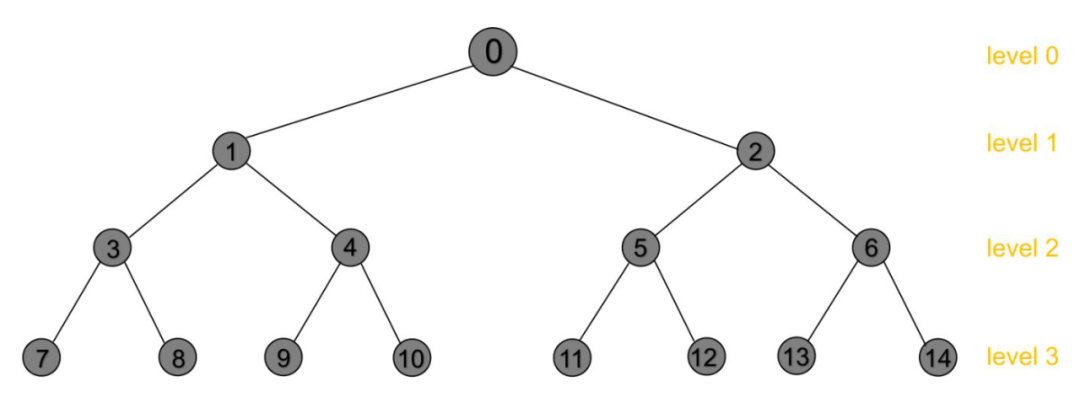
虽然图中最底层只有 8 个叶节点,但实际场景中可能会有百万到上亿个物品,所以直接用复杂模型遍历叶节点检索是不大可行的。论文中采用的是 beam search 的方法从根节点(root node)开始逐层挑选 top-K 节点,而挑选的依据正是用户对每个节点的偏好 ,然后将这些 top-K 节点的子节点作为下一层的候选节点,一直到最后一层。
二叉树有一个很好的性质,如果一个节点 id 是 n,那么其叶子结点是 和 ,一次遍历就能取得当前层节点的所有叶子结点。这相当于每个选中的节点有两个候选子节点,那么整体的计算次数是 ,其中 是所有物品集的数量。若物品总量为 1 亿,k 为 10,那么推理一次需要计算 次,对比原来的 1 亿次下降了不止一个数量级,时间复杂度从 下降到 ,这样复杂模型就可以使用了。
不过上述流程很容易会给人带来一个疑惑,这样层层检索下来,如何保证最终得到的叶节点一定是 最大的 K 个?为了解答这个问题论文里引入了一个兴趣最大堆树的概念,直接衍生自传统数据结构中的堆(heap):
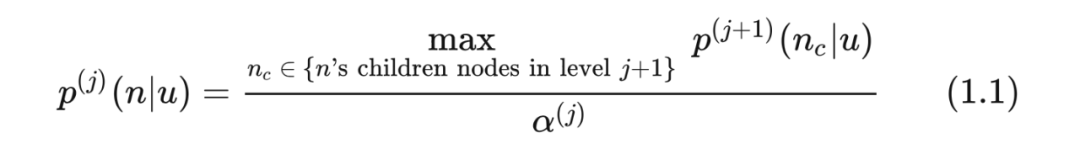
这个公式意为每个节点的 都等于其所有子节点 的最大值, 代表树的第 层, 是一个归一化参数可以被忽略。由于 beam search 在每一层都会搜索到 最大的 K 个节点,那么满足了这个性质之后,这 K 个节点的子节点也一定包含了下一层的 top-K,这样一直检索到最后一层就能得到 top-K 的叶节点了。可以看到树的结构充当着索引的作用,让检索过程中能直接跳过众多不相干的节点。
以上更多地是 TDM 训练完后的推理(检索)过程,那么接下来的问题是 TDM 的训练。TDM 整个体系大致分为两个部分 —— 模型和树,那么训练也是分别要学习这两样东西。这里的模型作用是计算用户 对于某个节点 的偏好 ,如前文所述(几乎)可以是任意复杂模型,所以论文里果然上了一个带有时序特征和 attention 的复杂深度学习模型,具体模型结构这里就不细述了,因为不是 TDM 的重点,仅谈如何在树结构确定的情况下训练这个模型。
通常模型的训练离不开样本,所以这里的关键是先要构造样本,而后用 TensorFlow 之类的框架搭个神经网络训练就比较常规了。将用户交互过的物品(叶节点)设为正样本,由于树结构已预先确定,那么每个叶节点的祖先节点也就确定了,而根据上面的最大堆性质,正样本叶节点的祖先节点也同样为正样本,同时在各层随机采样一些除正样本以外的节点作为负样本。对于一棵二叉树,根节点 id 为 0,于是参考上图第 层的节点 id 范围为左闭右开的 ,那么每一层在这个范围内采样就可以了。
模型训练完后,接下来看树结构的学习。所谓的树结构,说地直白一点就是物品 id 和树叶节点 id 的一一对应关系。对于二叉树节点 ,其父节点是 ,那么依次上溯就可得到节点 所有的祖先节点。所以这里我们只需要关心物品和叶节点的对应关系,这层关系确定后上面的祖先节点也都确定了。
关于树结构学习的具体方法,论文里说的是将所有物品的 embedding 向量递归地使用 k-means 聚类来确定最终的叶节点分布,而物品的 embedding 则来自于前面模型的 embedding 层。不过说实话光看论文里的描述很难搞得明白 TDM 的这棵树究竟是怎么聚类得到的,所以下面我们来看具体实现。
不得不说论文里只是给了个模糊的框架,而真正写代码的时候又牵扯出了诸多细节,主要体现在树的构建和操作上。首先来看上文中的树聚类学习,我觉得这个过程可以这么解释:目标是将所有物品分配到各个叶节点,但是直接分配不可行,所以先将所有物品分配到根节点 0,然后通过聚类将所有物品分成两类,分别分配给根节点的子节点,也就是一半的物品分配到节点 1,另一半分配到节点 2。然后再对属于节点 1 和 2 的物品分别聚类,继续将物品往下分配到各自的子节点,这是一个递归的过程,最后在叶节点只分配到一个物品的时候终止。
为了保证树的平衡性,每次聚类的时候都要进行再平衡,即保证聚类出来两个子类的物品数量一样,具体方法是计算每个物品到聚类质心的距离,距离最远的几个会被调整到另外一个子类。如果你熟悉后面的 JTM,会发现这整个层层分配 + 再平衡的操作和 JTM 的步骤如出一辙,不同之处在于 TDM 中分成两类的依据是聚类,而 JTM 中是目标函数,这一点后文再述。
基于以上流程,在各个节点上聚类是可以并行的,原版实现 [6] 用的是 Python 多进程,通过队列(Queue)和管道(Pipe)进行进程间通信。不过对于这样一种将一个大任务递归地层层拆分成多个子任务的并行计算,Java 7 中增加的 ForkJoinPool [7] 看来是更适合的选择,而在 Scala 实现中则可以直接使用 Java 的类库。
另外值得一提的是论文中提到聚类的原始方案是谱聚类(spectral clustering),但因为计算复杂度太高所以改成了 K-means,在我的数据集上试验下来谱聚类的效果确实比 K-means 好一点,当然耗时也长得多。
接下来考虑一下在树上检索的流程。因为论文里讨论的是一般情况,所以给的算法流程里是从根节点开始检索,但实际上并不需要。假设要获取 top-3 的物品,每一层 beam search 的候选节点数是 6,那么完全可以跳过前几层而直接从 level 3 开始检索,因为上方的比如 level 2 只包含 4 个节点,beam search 的时候肯定会全包括进去而不需要按偏好排序。
召回中一般需要取几百到几千的物品,这样可以跳过开始的很多层,从而节省计算资源和加速推理。同样代码里有一个参数 start_sample_level ,表示开始进行负采样的层,如果推理的时候前几层的节点不需要包括,那么这几层也同样不需要采样和训练了。
最后再来看一个细节,论文在描述的时候给出了一棵树的图例:

这是一颗满二叉树,即每一层的节点数都达到了最大值。然而我相信大部分第一次看论文的人都不会注意到的一点是,物品的数量不会正好是 2 的 n 次幂,那么就不会覆盖完树的最后一层,也就是极有可能会出现下面这种情况:
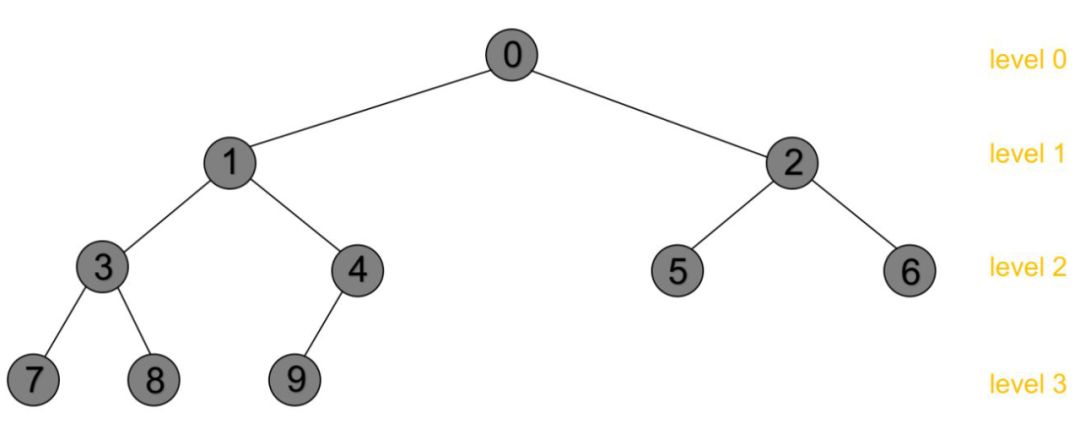
这是一颗完全二叉树,也满足论文里的描述,然而这种叶节点不是在同一层的树在实现上并不是很友好,比如在向上采样时没法规定一个统一的起始采样层,以及检索的时候如果指定了最大高度则容易跳过倒数第二层的叶节点。那么原版实现是怎么处理这个问题的呢?就是强行把所有叶节点都拉平到最下面同一层,见代码 [8],对应到我的代码 [9]。

JTM
前文提到在 TDM 中树的学习采用的是一种层次化聚类的方式,并没什么理论依据,论文里也说这只是一个直觉性(intuitively)的方法。这种层次化聚类方法的问题"直觉上"与常用的向量最近邻方法类似,即模型和最近邻搜索的优化方向不一致。前者优化的是用户 对节点的偏好 ,而后者优化的是向量相似度。所以从这个角度上来说 TDM 中的层层聚类也是在向量相似度上作文章。
显然作者认为这样拍脑袋出来的方法是不大合理的,所以才有了 JTM 的出现。其核心思路还是比较直接的,就是让模型和树优化同一个目标。模型优化部分和 TDM 中的差不多,变化的仅是树的学习这一部分。
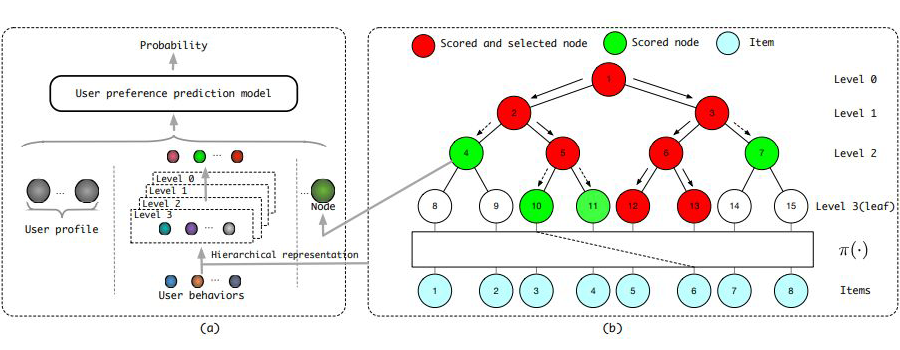
对比 JTM 论文中的这张图与前面 TDM 中的树的图,最显著的不同是右图最下方出现了一个物品和叶节点的映射函数 。前面讲 TDM 的时候提到过树结构取决于物品 id 和叶节点 id 的一一对应关系,这一点实际上是在 JTM 论文中被明确提出来的。有了这个之后统一优化目标为:

对于第 i 个正样本 , 为用户, 为其感兴趣的物品,那么 通过 映射到某一个叶节点即 , 为某一节点到树的第 层祖先节点的映射。于是上式的意思是最大化正样本中用户与节点偏好的概率,而这里的节点包括物品对应的叶节点和相应的祖先节点,由于损失函数一般为最小化,所以上面采用的是 。
(2.1)式代表的是所有物品的目标函数,而对于单个物品 来说并不需要囊括所有的样本,而只需要计算其为目标物品(target item)的样本。于是设 为目标物品是 的所有样本,则 的目标函数为:
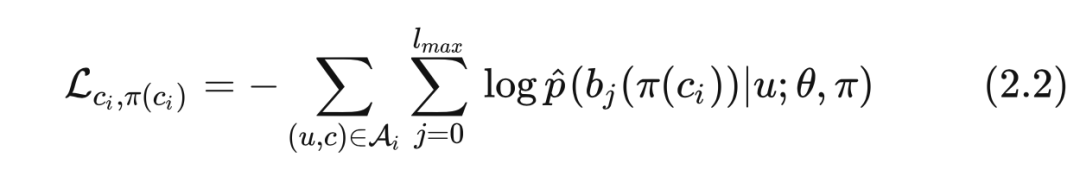
TDM 中训练模型来优化(2.1)式的方法是叶节点上溯得到所有祖先节点作为正样本,同时在每一层随机采样另外的节点作为负样本。而在 JTM 中这部分可变可不变,放到后面讲实现的时候再说明。这里先假设解决了模型优化的问题后,树如何学习来同样满足(2.1)式就成为了 JTM 的核心。
JTM 中树的学习简单来说就是贪心 + 试错法,上面的映射函数 在具体的实现中就是一个 map(或者是 Python 里的 dict),将物品 c 映射到叶节点 。那么所谓的试错法就是把一个物品映射到每一个可能的节点,分别计算(2.2)式,最后将物品映射到值最大的那个节点。然而直接使用这种方法过于简单粗暴,计算量非常大。
注意(2.1)式中的两个加和涉及到所有的样本和所有的层,假设有 1 百万样本,1 万种物品,那么可能的叶节点位置也为 1 万,而树的层数为 。对于所有物品,就需要计算 次才能得到最佳的 。一般推荐系统里肯定远远不止 1 百万样本和 1 万物品,所以总体计算量会快速增长到不可承受。
可以看到上面对于 JTM 的计算可分为三个部分 —— 总样本数、树的层数以及候选节点数。论文中提出的贪心法主要是通过减少后两者来降低整体计算量。先将所有物品都映射到树的根节点即 ,再每隔 d 层将物品分配到对应层的子节点,一直到最后一层每一个物品都分配到一个叶节点。下式代表从 s 层到 d 层的目标函数:
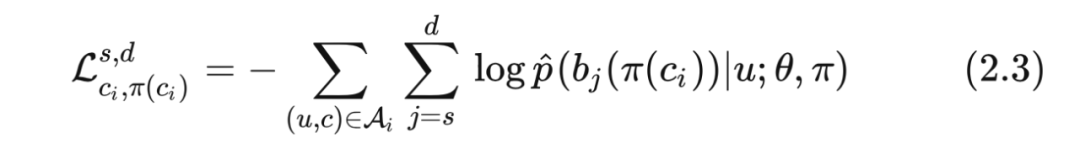
我们来看下这个方法是怎么降低计算量的。依然以上面的例子,原来的方案需要计算所有层 14,加上所有的叶节点位置 1 万。贪心法需要计算 层, 是一个超参数,理论上 越大越精确,但相应的计算量也越大,当 时就和原来的一样了。而利用二叉树本身的特点,一个节点往下 层的子节点数是 个,论文中给的例子是 ,相比于原来的 1 万就小了很多。
前文提到过树的平衡对于检索效率很重要,因此每分配完 层后,论文中还加了一个再平衡(rebalance)操作。如果仅仅是通过计算(2.2)式来分配物品到节点,很可能出现的情况是某个节点分配了超多的物品,那么学习出来的树会变得非常不平衡,而再平衡的目的就是使得一个节点可分配的物品数不超过 个。
这个再平衡操作使得实现的复杂度上了一个台阶,想要分配一个物品,并不是每个节点计算一遍(2.2)式取值最大的分配就好了,而是需要把所有计算值保存下来并排序,再通过 rebalance 将超过数量的物品分配到别的空闲节点上,具体实现见代码 。
在 JTM 的具体实现中还有几个点值得讨论。首先,JTM 中的模型优化和 TDM 中的是否是一样的?如果严格按照论文里的那应该是不一样的,因为 TDM 用的是二分类而 JTM 用的是多分类,然而使用多分类至少可能产生两个问题,都和 softmax 的计算有关。
一是 softmax 的分母计算应该包含哪些类别?这在论文中没有明确说明,如果使用当前层的所有节点作为类别,那么每一层使用的模型就变得不一样了,因为每一层的节点数是不一样的,这样无论训练还是推理都会带来更大的复杂性。另一个是为了缓解 softmax 训练计算量大的问题,论文中明确提到了使用常见的 NCE 来采样训练,然而这类采样方法通常只适用于训练,实际的推理过程中仍然需要计算全量 softmax,这样利用树结构来加速检索的效果会大打折扣。
基于以上考虑,我的 JTM 实现中仍然沿用了 TDM 的二分类模型训练,那么相应的树学习中计算(2.2)式也就是二分类模型输出的概率。而实际上并不需要计算概率,我们需要的是相对大小并排序,那么只需要计算模型的标量输出 logit 就可以了。
这里我不负责任地猜测一下作者为什么要在论文里强行上这么个不好实现的多分类目标函数,最可能的原因是这样写能让提出的理论更加“优雅”。JTM 的核心是模型和树优化同一个目标函数,如果使用二分类那么这个公式可能就没法写得非常统一了,至少不那么一目了然,读者倒回去看一下 TDM 论文中的公式(4)就明白了。
其次 JTM 论文的 3.2 节末尾简略提了一句,“Furthermore, each sub-task can run in parallel to further improve the efficiency”。虽然只有一句话,但实现中这一点其实挺重要的,因为 JTM 的贪心法虽然降低了很多计算量,但如果想算得精确一些 就不能取得太小,而 越大计算量也越大,所以利用并行计算来加速树的学习是有必要的。然而论文里也没说具体的 sub-task 究竟是什么,只能我自己猜了。

在树学习(Tree Learning)这个算法(论文中的 Algorithm 2)中大致有两个可以并行的地方,即节点内并行和节点间并行。前者指的是同一个节点内的所有 item 在往下 层分配子节点时并行;后者指的是同一层的节点之间并行。假设设置的最大并行度为 16,那么对于靠近根节点的几层可以使用节点内并行,因为 0-3 层的节点数都小于 16,如果使用节点间并行则无法达到最大并行度,而 4 层以下则可以使用节点间并行。
另外我发现节点间并行还有另外一种实现思路,那就是异步学习。上面的方法其实是一种同步学习,也就是每一层都要等待该层所有的节点都分配好了,再继续往下 d 层分配,如下图 level 2 的 4 个节点就需要相互等待:
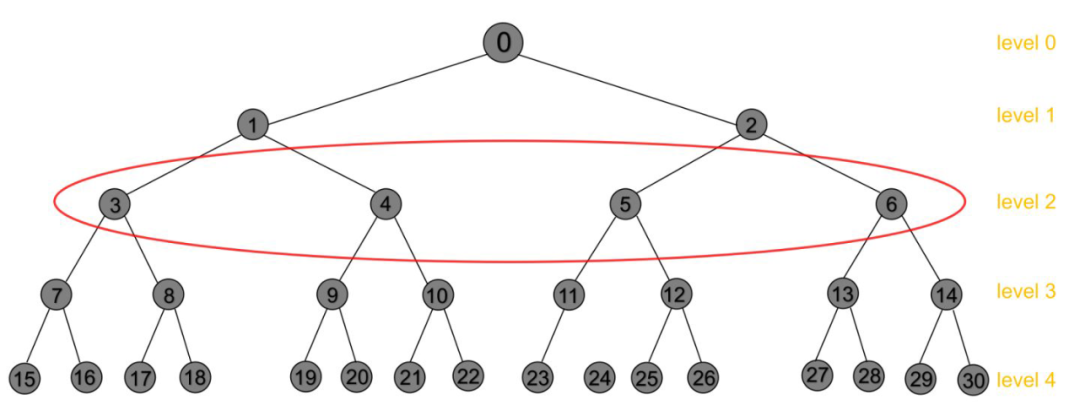
但实际上每层节点往下 d 层分配一直到最后一层,这个过程的每个节点之间是相互独立互不影响的,那么每个节点一路分配到最后一层的过程可视为一个 sub-task,同一层的节点之间就不需要相互等待了,如下图中每一个框内就是一个 sub-task,4 个可以并行计算,对应代码为 JTMAsync [10]。


OTM
OTM 这篇论文,乍看上去比较理论化不大好懂(与其他几篇比起来),但核心 idea 却很简洁明了,即解决训练和测试数据分布不一致的问题。回忆一下 TDM 中的模型训练数据来自于正样本叶节点及其祖先节点,以及每一层采样的负样本节点。然而实际推理过程中用的是自顶而下的 beam search,每一层保留 top-K 节点,这样推理中经过的节点和训练过程中使用的样本节点可能分布截然不同,致使最终召回效果下降。
因而 OTM 在模型训练时舍弃了 TDM 的这套构造样本的方式,而是直接使用当前模型在树上作 beam search,得到的每一层 top-K 节点作为训练样本。那么接下来的问题是得到的这些样本,哪些是正样本哪些是负样本呢?
如果想要偷懒点,可以直接采用类似 TDM 的模式,将 beam search 得到的节点中属于正样本祖先节点的设为正样本,其余的则设为负样本。然而作者认为这样并不能保证最后得到的叶节点一定是用户偏好 最大的 K 个。为了证明这一点(以及其他相关的)论文里洋洋洒洒上了一大坨,甚至很多证明还都放到了另外的补充材料中(supplemental material)中。最后得出来的结论是节点的标签 满足下式才是最优的:
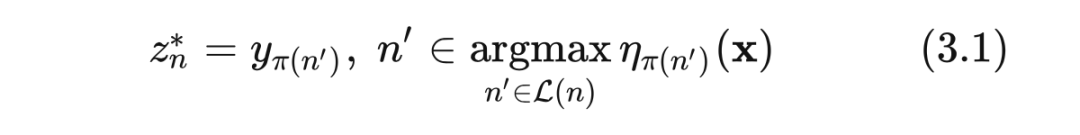
其中 为上文 JTM 中提到的物品到节点的映射, 为节点 n 对应的所有叶节点, 为模型节点 的预测概率。那么(3.1)式的意思是节点 的标签取决于模型对于其所有叶节点中预测概率最大的那个。论文中称 为 pseudo target ,并配合下图对提出的核心 idea 作了说明。
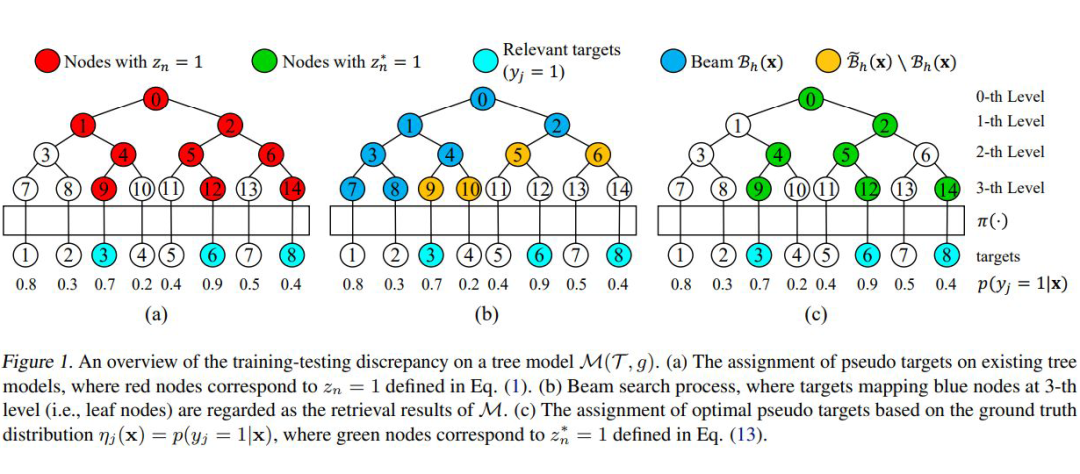
最底下的一层标号 1-8 的为物品,跨过映射函数 映射到了树的根节点 7-14。图(a)中的红色节点为 TDM 中采用的正样本上溯得到的训练节点,对照图(b)中的蓝色节点为实际 beam search 中的每层 top-K 节点,不同的流程导致二者的节点分布可能差别很大。
而图(c)则显示了 pseudo target 的生成过程,与 TDM 不同,OTM 中并不是每个正样本的祖先节点也都是设为正样本,比如节点 6 在图(a)中是正样本,而在图(c)中则是负样本,因为其叶节点为 13 和 14,而 ,所以根据(3.1)式节点 6 的 pseudo target 应和节点 13 相同,即为 0。
然而直接根据(3.1)式算出所有节点的 pseudo target 是不现实的, 因为计算一个节点需要遍历该节点的所有叶节点得出最大值,而像上层的一些节点几乎牵涉到了树的所有叶节点。因此论文中提出的方案是每一层节点的 pseudo target 取决于其子节点的预测概率较大的那个:
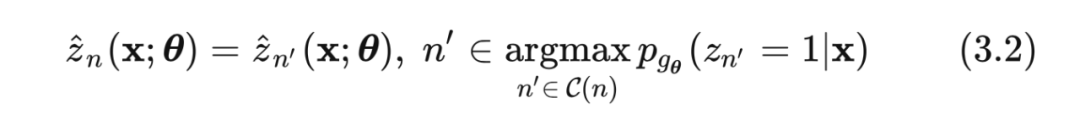
其中 表示节点 n 的子节点。对于二叉树来说,一个节点的子节点只有两个,计算量就小了很多。叶节点因为没有子节点,所以其 pseudo target 取决于数据本身 ,即正样本对应的叶节点为 1,负样本为 0,那么从叶节点自底而上计算(3.2)式就能得到树上任意节点的 pseudo target。
本篇开头提到过,OTM 改进的是 TDM 中模型学习这一部分,那么树的学习这一部分论文中是直接沿用 JTM 的方法。OTM 的核心 idea 虽然简洁明了,但其真正的实现还是比较复杂的,其复杂性主要来源于样本的构造,因为已经不是 TDM 那样简单的节点上溯和负采样了。首先看一下论文中给出的 Algorithm 1:

说实话论文中的这个算法流程我看着是有点奇怪的。注意第 4 和第 5 步使用的都是 ,即模型上一轮的固定参数,而 下标是 也就是树的第 层,那么这个流程的意思是 beam search 过程中每一层都计算 和 然后更新模型参数(第 6 步)?这样岂不是 beam search 进行下一层计算的时候模型参数就不是上一轮的固定参数了?抑或是论文里说的固定参数范围仅限定于 beam search 中的一层而不是整个 beam search 过程?
而且如果严格按照论文中的算法流程,beam search 得到的每一层节点都单独计算 势必会产生很多重复计算,因为每次计算 pseudo target 都要从叶节点开始上溯。所以我在实现中每次真正更新模型参数前先将一批数据中所有层的 pseudo target 和 beam search 节点都计算好。这样既能使用上一轮的固定参数模型,又能一次性不重复地计算完所有的 pseudo target。
根据论文的补充材料(supplementary material)显示,第 5 步中只需要为满足 的节点计算 pseudo target,而对于 节的 可直接设为 0。 代表正样本节点在 h 层的祖先节点,那么这里的意思是每一层 beam search 得到的节点,只有与正样本的祖先节点有重合的才需要计算 pseudo target。
综上所述,我认为效率最高的训练流程是先从树的叶节点自底而上计算每一层正样本祖先节点的 pseudo target ,再从根节点自顶而下进行 beam search 获取训练节点,最后在训练节点中搜索是否存在正样本祖先节点,如果存在则把节点 label 设为相应的 pseudo target,若不存在则 label 为 0 。训练节点的 label 都确定后就可以使用这些节点正式更新模型参数。
论文中还有一点值得注意,TDM 中一个样本只需要单个 label,在 OTM 中扩增到了一个样本多 label 的情况,若用论文中的符号表示则分别对应 和 。之前在看 TDM 论文的时候就有这个疑惑:一个用户可能对多个物品感兴趣,如果把这多个物品分散到不同的样本中,再像 TDM 中那样直接每一层负采样,极有可能会把一个正样本当成了另外样本的负样本来训练。
而如果是一个样本有多个 label 的话则可以避免这种情况,比如 OTM 中每一层 beam search 得到的训练节点,可以有多个正样本,只要这些正样本分别对应于多个 label 的祖先节点。
然而多 label 带来的问题是一个样本不同的 target 节点可能有同一个父节点,那么这个父节点的 pseudo target 应该取决于哪一个 target 节点呢?这一点在论文中没有明确说明,不过参照论文中的(1)式对于 target 的正式定义(这里记为(3.3)式),可以将有相同父节点的 target 节点进行聚合,即先将一组 target 节点按父节点分组,属于同一组的再进行加和。
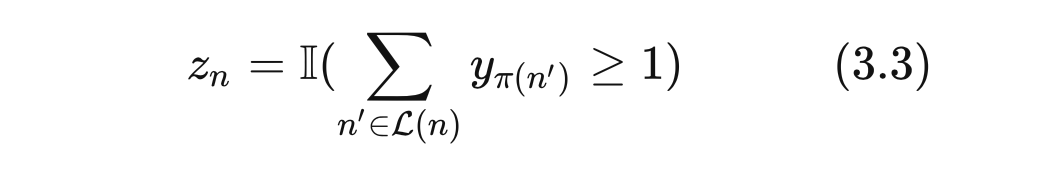
Scala 2.13 在集合库中新增了 groupMapReduce [11] 方法,非常适合这个需求,假设已经得到了一组节点组成的列表 nodes,每个节点用元组(id, score)表示,那么想要将其中相同父节点的 target 分组聚合得到一个新的列表,只需要一行代码 nodes.groupMapReduce(n => (n._1 - 1) / 2)(_._2)(_ + _) 。

Deep Retrieval
Deep Retrieval 的核心卖点和 TDM 系列差不多,即在大规模召回中直接使用复杂模型,因而两者总免不了被拿来作比较。TDM 系列为了能快速检索引入了树作为索引结构,而 DR 中的索引结构是一个 的矩阵,总共有 层,每层 个节点,见论文中的图(a):

在检索的时候同样使用了 beam search,从最左侧的一层开始使用 user embed 作为输入,每一层选择 top-B 的节点,最后得到 top-B 的 path,再通过映射函数找到 path 对应的物品。path 指的是每一层选出的节点组成的序列,论文中用 表示,每条 path 可以看作是一个 cluster。
这个步骤得到的 path 以及物品之间的顺序并不重要,因为论文中还同时训练了一个重排序(rerank)模型,对得到的物品作进一步排序最后输出召回结果。从论文里看这个 rerank 模型是属于 Deep Retrieval 的一部分,而不是一般意义上跟在召回模块后的粗排或精排。
与 TDM 一样,Deep Retrieval 的整个体系也需要训练两个部分 —— 模型和索引结构,不过这里的索引结构被具象化为了一个映射函数 。这一点和 JTM 类似,不同之处在于 JTM 中仅仅是物品到叶节点的映射,而 DR 中是物品到多条 path 的映射。
上图(b)为 DR 的模型结构,第一层的输入为 user embed,而后的每一层输入为 user embed 和之前层的节点 embed 的拼接,每一层的输出为 个节点的 softmax。由于 DR 中每个物品可以映射到 条 path,那么总的目标函数为:

上文讲 JTM 的时候提到过模型使用二分类还是多分类的选择,使用多分类的问题是会使树每层的模型不同,且推理的时候计算量大。从上面的图(b)看 DR 使用的正是多分类 softmax 输出概率,而每一层的输入输出都不相同,所以 DR 中每一层 MLP 本质上是不同的模型,仅在 user embed 层面是共享的,这一点和 TDM 所有节点共享同一个模型不一样。
另一方面,由于 DR 模型中每一层的类别比较少(论文中 K=100),也就不需要 NCE 这样的近似计算了,可直接通过原始 softmax 更新模型。所以综合来看虽然每层模型不同致使参数量变大,但类别设定的少的话训练和推理在这方面应该不构成什么问题。
论文里将需要训练的两部分,即模型和索引结构,分为了类似于 EM 算法的 E-step 和 M-step,E-step 为固定 优化模型参数 ,M-step 为固定模型参数 优化 ,二者优化的是同一个目标函数:
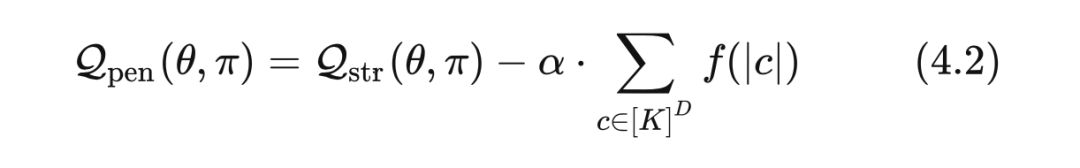
(4.2)式和(4.1)式的不同点在于引入了一个惩罚函数 ,用于防止一条 path 被分配到了太多的物品。不过仔细看的话可以发现加的这个惩罚函数只会影响 M-step,而 E-step 只优化模型参数,所以 E-step 训练的时候可以忽略这个 。
E-step 的训练完成后,接下来是 M-step 的优化。如果之前没有写 JTM,我大概对这部分也不会有什么特别的感觉,然而现在我越看越觉得 DR 的这个 M-step 与 JTM 很像。当然不是说具体的算法步骤,而是背后的核心思想相似。M-step 中比较重要的是理解论文中定义的打分函数 score function :
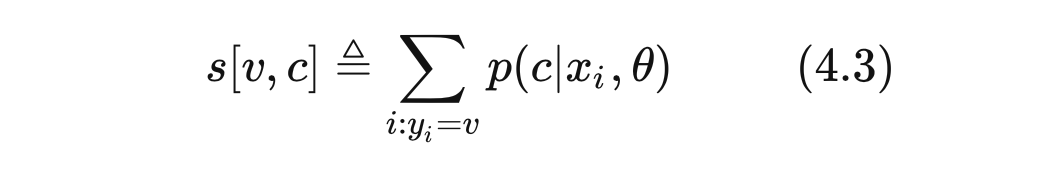
表示物品 v 分配到 path c 的累计重要度,使用的是所有目标物品为 v 的样本加和,表示为 。抛开符号的差异,(4.3)式所表示的意思其实和 JTM 中的(2.2)式如出一辙, 就约等于(2.2)式的 。二者流程的内在含义都是想要获得物品的最佳映射,那么就把所有可能的映射对应物都计算一遍目标函数。不同点在于 JTM 中一个物品只映射到一个叶节点,所以取目标函数最大的那个节点;而 DR 中一个物品可以对应多条 path,因而取分数最大的 条候选 path, 是一个超参数。
在得到了所有的 后就意味着得到了每个物品 的 条候选 path,接下来的标是从 条中选出最终的 条。之所以在之前的计算中不直接选择 条出来,是因为之前 的计算没有考虑(4.2)式里的惩罚函数。DR 中加入惩罚函数 是为了防止一条 path 被分配太多的物品导致不均衡,而这与 JTM 中的 rebalance 操作异曲同工,因为 rebalance 也是为了防止一个节点被分配太多的物品,所以到这里我确信 DR 的 M-step 绝对借鉴了 JTM 里的思想。
经过一系列推导,论文中提到了依据 incremental gain 的大小来选择最终的 条 path,如下算法流程:
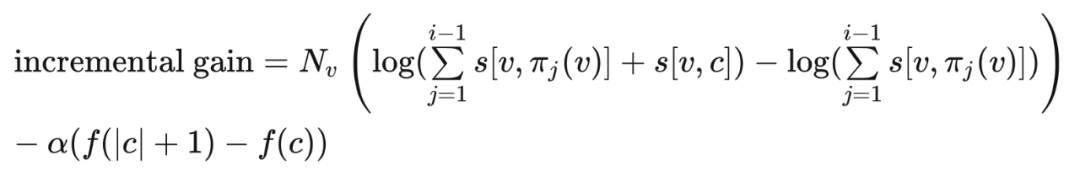

注意这个算法流程的输入是 ,也就是默认(4.3)式的 已经提前计算好了。不过这一步实际上是挺耗时的,因为需要所有的样本都推理一遍。 可以通过流式训练(streaming training),细节就不细述了,论文里这一块写地比较详细。
在实现中由于我用的是固定数据集,所以无论是直接计算(4.3)式训练还是使用流式训练都可以,在代码 [12] 中前者用 “batch” 表示,后者用 “streaming” 表示。这里的直接计算(4.3)式指的是先将所有数据都扔进模型计算出所有样本的
θ,再对各个物品与 path 分组(groupby)加和,最后排序得到每个物品分数最大的 条 path。
最后关于 beam search 后的重排序(rerank)模型,在论文 2.3 节说这个 rerank 模型用的是 softmax ,然而后面的实验部分又说这只是在公开数据集上使用的,实际生产环境用的是 logistic regression,原因是 softmax 的效果不大好。这个操作就有点迷了,合着这个 softmax 就是用来在公开数据集上刷榜的? 反正我的实现就是按照论文里的原始提法,用 sampled_softmax 近似 softmax 以解决物品数过多的问题。
Deep Retrieval 论文中还有一个槽点,如果我之前没看过 OTM 论文大概率也不会察觉,那就是 DR 的实验为什么没和 OTM 作比较?一开始我以为是因为两者都首发表于 2020 年,所以互相不知道对方的工作。然而重看论文的时候发现 DR 论文的 Related Works 里赫然写着 TDM,JTM,OTM 。所以又回头看了一下 OTM 论文就明白了,因为在实验的数据集上 OTM 的指标远高于 Deep Retrieval,不可能在论文里拿一个效果更好的模型作对比。当然仅凭这点并不能盖棺定论 OTM 一定优于 Deep Retrieval 。

参考文献
[1] https://arxiv.org/pdf/1801.02294.pdf
[2] https://arxiv.org/pdf/1902.07565.pdf
[3] https://arxiv.org/pdf/2006.15408.pdf
[4] https://arxiv.org/abs/2007.07203
[5] https://github.com/alibaba/x-deeplearning/tree/master/xdl-algorithm-solution/TDM
[6] https://github.com/alibaba/x-deeplearning/blob/master/xdl-algorithm-solution/TDM/script/tdm_ub_att_ubuntu/cluster/cluster.py
[7] https://docs.oracle.com/en/java/javase/11/docs/api/java.base/java/util/concurrent/ForkJoinPool.html
[8] https://github.com/alibaba/x-deeplearning/blob/master/xdl-algorithm-solution/TDM/script/tdm_ub_att_ubuntu/cluster/tree_builder.py#L53
[9] https://github.com/massquantity/dismember/blob/main/tdm/src/main/scala/com/mass/tdm/tree/TreeBuilder.scala#L131
[10] https://github.com/massquantity/dismember/blob/main/jtm/src/main/scala/com/mass/jtm/optim/JTMAsync.scala
[11] https://superruzafa.github.io/visual-scala-reference/groupMapReduce/
[12] https://github.com/massquantity/dismember/blob/main/deep-retrieval/src/main/scala/com/mass/dr/optim/CoordinateDescent.scala#L29
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

