- 1textrank算法提取文本摘要_textrank 摘要
- 2移动平台质量跟踪系统对比-crashlytics、网易云捕、友盟、bugly_android bugly同类产品
- 3【VMWare linux ubuntu共享文件夹设置】_vmware给linux共享的文件夹在哪里
- 4Elasticsearch-7.8.0安装最全(mac、Linux、window、centos7.5集群、docker)_mac arm docker elasticsearch7.8
- 5Android 抽屉模型实现(Drawer),AndroidX and NavigationView_android drawer
- 6【Qt 学习之路】Jetson Orin Nx CLB 开发套件上的 Qt 部署安装_orin安装qgc
- 7【网络学习笔记】之【eNSP实验6——ACL】_在甲、丙公司所属网络内选择两台代表性主机ensp
- 8【并发编程】CAS到底是什么
- 9Docker部署jar 项目容器及配置文件_dockerfile指定jar配置文件
- 10Java遍历HashMap的两种方式_java 遍历2个hashmap找位置
计算机体系结构·指令级并行_数据旁路
赞
踩
作为复习笔记使用
一、流水线概述
定义
流水线技术(pineline)是指在程序执行的时候多条指令重叠进行操作的一种准并行(parallelism)处理实现技术,也就是在同一个时间使用不同的资源,也就是说不同的程序在同一个时间独占互不相同的某种资源,是对CPU资源的高效使用
流水线技术的本质是:在上一条指令结束之前进行下一条指令的执行
比方说在工厂的生产线上,我们不是等待一辆汽车生产组装完才去从头开始准备生产另一辆汽车,而是把一辆汽车的生产分成若干个步骤,然后汽车A的第1个步骤完成,相应的工人们空闲下来之后,开始汽车B的第一个步骤,A进入第2个步骤……
⚠️要注意的是,流水线技术不会减少单个任务所花费的时间,流水线技术能够提高生产效率在于提高了单位时间内执行的任务数量,也就是增加了吞吐量从而使得CPU性能提高
流水线性能
我们默认流水线的理想状况是CPI = 1
而使用流水线技术的理想加速比等于流水线上的流水线级数,如果流水线上有3个阶段,那么它的理想加速比就是3X(注意是理想加速比)
但是由于流水线上的每个阶段长度可能不同,流水线会被最慢的阶段限制,而且最开始的时候和结束的时候只会使用到一个资源,再加上阶段和阶段之间有前驱后继的依赖关系,实际生活中的流水线实现完全充分流水是小概率的,实际的流水线加速比是达不到理想加速比的,实际的加速比只能无限趋近于理想加速比,计算公式如下:
Non-PineLined Time:顺序执行的时间,如果题目中说一个流水线有5个stage,这5个stage需要M cycles才能完成,现有1000条指令,不考虑其他复杂因素,那么Non-PineLined Time = 5000M cycles
PipeLined Time: 如果有1000条指令,流水线同样有5个stage,不考虑其他的复杂因素,那么PipeLined Time = 1000 + (5-1) cycles = 1004 cycles
流水线的性能衡量就是流水线上每条指令完成使用的平均时间:
这个公式也可以看成:流水线性能 = 实际加速比/理想加速比
上面例子中的流水线性能就是5000M/5 = 1000M
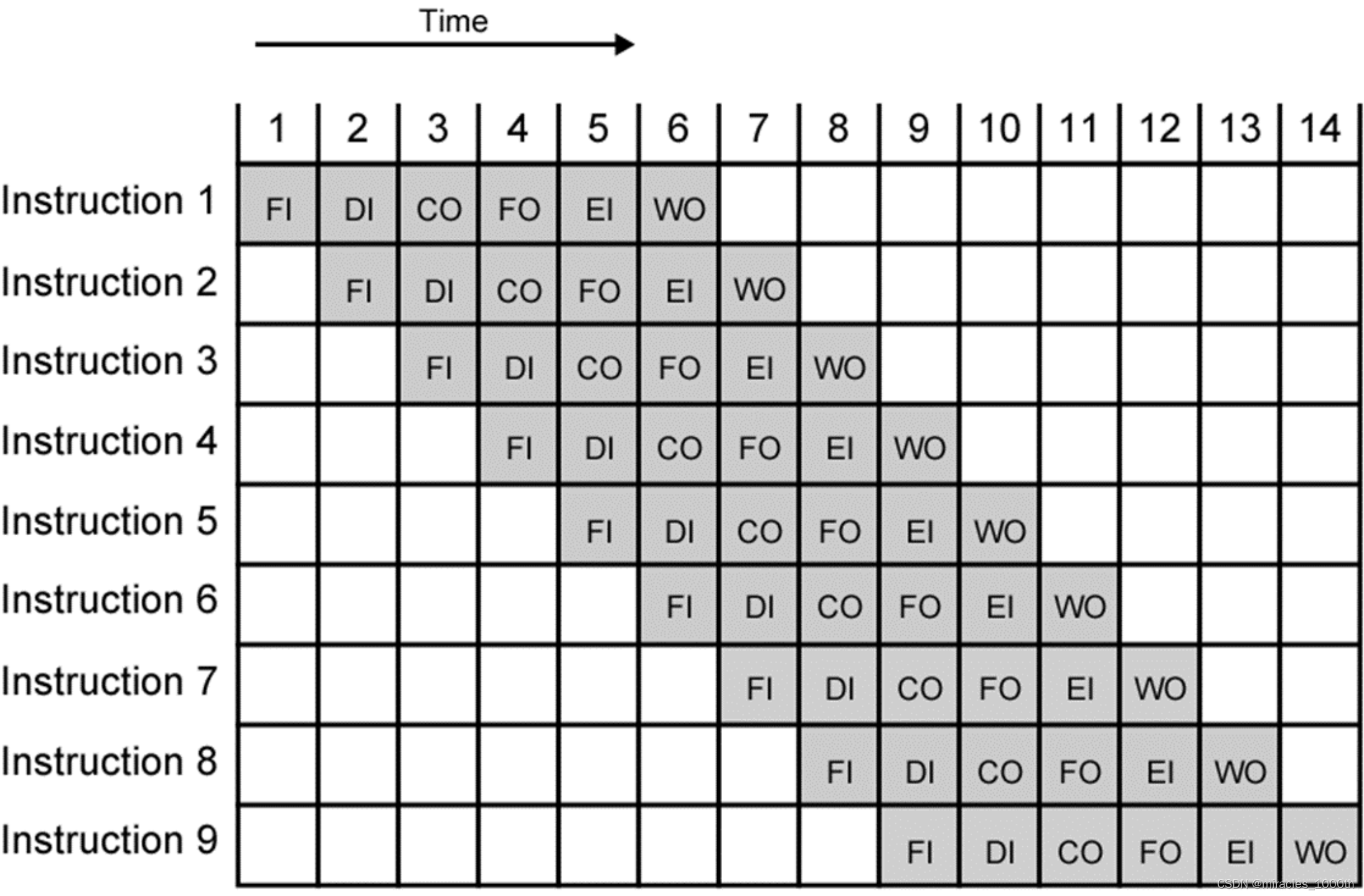
二、指令执行过程
上面的图中是一个经典的五级流水线,我们假设每个指令都会经过这5个过程(实际上有的指令可能不会有全部的5个过程,或者是少于5个过程或者是多于5个过程),而且这个流水线是平衡的(balanced),也就是说每个stage的执行时间差不多长
各流水线级
1. IF(Instruction Fetch):
取指令阶段,在这个阶段流水线主要进行取指令,将PC中的指令拿出的同时进行PC+4的操作,确定下一条指令
- send the program counter(PC) to memory and fetch the current instruction from memory
- update the PC to the next sequential PC by adding 4 to PC
2.ID/Reg(Instruction Decode/Register Fetch):
如果是R型指令(ADD R1,R2,R3),翻译指令同时去对应的寄存器中拿取数据
如果是I型指令中的分支语句,还可以完成相等检测(Beq R1, R2,5)
对指令的翻译和读取寄存器中数据是同时进行的
- decode the instruction and read the registers corresponding to register source specifiers from the register file
- do the equality test on the registers as they read, for a possible branch
- decoding is done in parallel with reading registers
3.EX(Execution/Effective Address): 执行和计算地址阶段
如果是Register-Register 类型的指令(ADD R4,R1,R5),那么EX阶段会在ALU上进行数值计算
如果是Register- Immediate类型的指令(ADDI R4,R1,15),那么ALU就会用第一个从寄存器上读取的数据和一个符号扩展的立即数进行指定的运算
如果是memory寻址类型的指令(LW R1, 10(R2)),那么ALU就会进行地址计算,也就是用R2里面的基地址 + 偏移量10
- Memory reference : the ALU adds the base register and the offset to form the effective address
- Register-Register ALU instruction: the ALU performs the operation specified by the ALU opcode on the values read from the register file
- Register-Immediate ALU instruction: the ALU performs the operation specified by the ALU opcode on the first value read from the register file and the sign-extended immediate
4. MEM(Memory Access): 仅仅在对内存有读写操作的时候进行的stage
如果指令是load,那么就通过计算出来的地址从memory里面读取数据[ LW R1, 0(R2)],这里就是将(0+R2)里面的数据拿进R1
如果指令是store,那么就将寄存器中的数据拿进计算出的地址对应的memory unit里面[SW R4,12(R1)], 这里就是将R4中的数据拿进(12+R1)
- If the instruction is a load, memory does a read using the effective address computed in the previous cycle
- If the instruction is a store, then the memory writes the data from the second register read from the register file using the effective address
5. WB(Write Back)
如果是Register- Register类型的ALU计算,那么WB阶段就是将计算结果从ALU写回对应的寄存器
如果是Load指令,那么就将数据从memory拿进寄存器
写回操作是写回寄存器而不是memory,写回的源头可能是ALU也可能是memory
- Register- Register : write the result into the register file from ALU
- Load Instruction : write the result into the register file from the memory system
数据通路
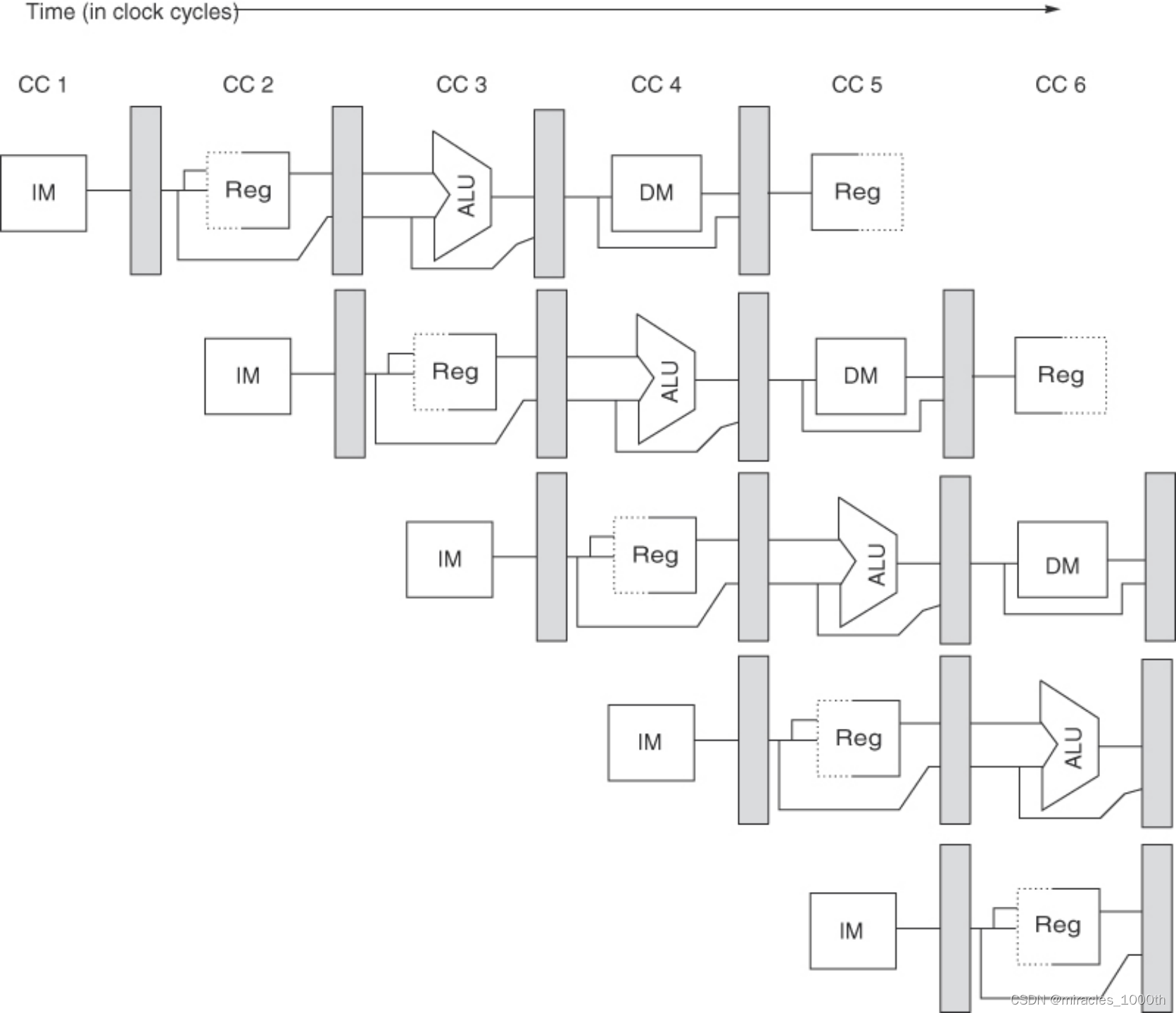
流水线寄存器 : 在每个流水线级结束之后,流水线会进入一个缓存寄存器,这个缓存寄存器用于存储本流水线级的执行结果,保证各个流水线级的独立,也就是说,流水线寄存器用于在相邻的两个流水线级之间传送数据,提供后面的流水线级所需要的数据,同时进行隔离
如果流水线级A的结果不会在流水线级A+1用到,那么A的流水线寄存器就会把这个没有用到的数据传给A+1的流水线寄存器,直到用到为止,也就是说,不一定只有紧挨着的阶段能使用上一阶段的结果
三、流水线冲突
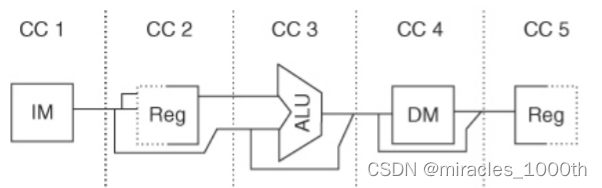
结构冲突(structural hazard)
1.定义:因为缺乏硬件的支持而导致指令不能在预定的时钟周期内执行,也就是有两条指令在同一个时钟周期内要使用同一个资源
在上面的图中我们可以看到,在Cycle5的时候,出现了需要同时使用memory的两条指令,这就是发生了结构冲突
2.解决方法:
- 最简单的方法就是停止等待,先让上一条指令执行完毕,然后下一条指令才开始执行,但是这样会造成流水线性能的下降
- 第二种方法是设置备用的硬件资源,因为上一条指令此时是要访问存储器中的数据,下一条指令是要访问存储器中的指令,所以我们,我们可以将数据和指令分开存储,也就是同时使用数据存储器DM和指令存储器IM
数据冲突(data hazard)
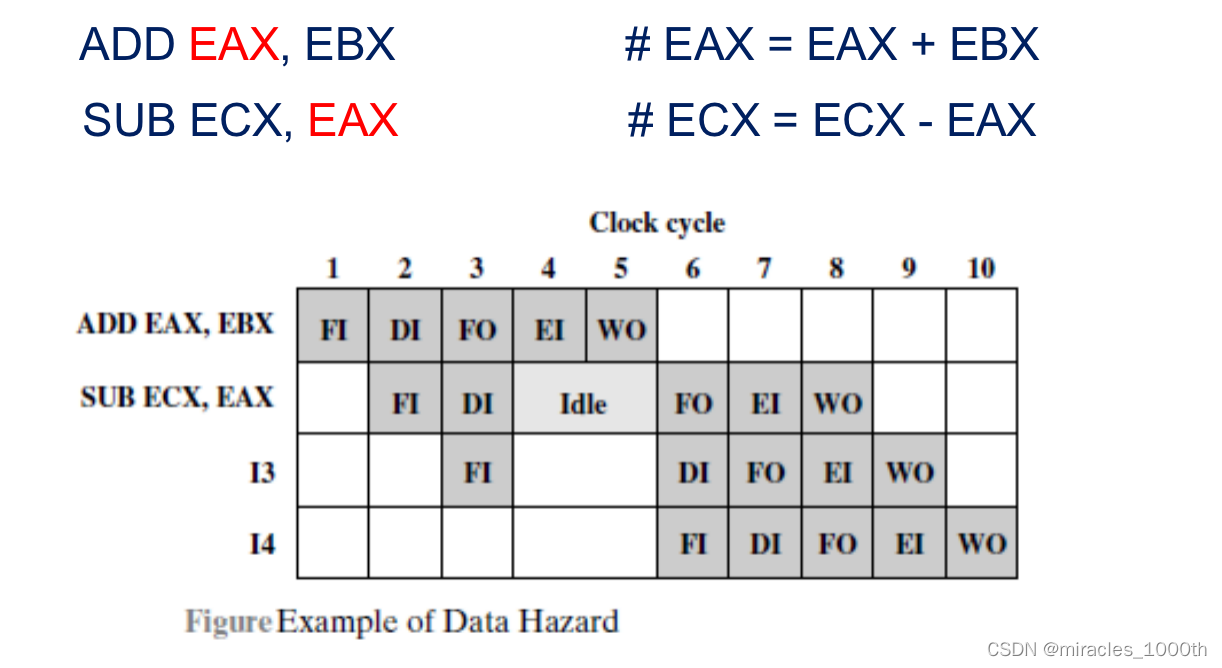
1.定义:当指令在流水线中重叠进行的时候,后面的指令需要用到前面的指令的执行结果,但是前面的指令尚未更新数据,后面的指令没有办法拿到正确的数据,也就是说,一条指令的执行必须等待前面某条指令执行完毕才能执行
2.类型:
- 先写后读(Read After Wirte/RAW): 指令1先进行写操作,想要进行R1 = R2 + R3,指令2进行读操作,要从寄存器读取R1的值作运算,但是这个时候指令1没有更新R1的数据,就产生了RAW冲突

- 先读后写(Write After Read/WAR) : 指令1先进行read操作,紧接着指令2要进行write操作,如果这个时候指令2在指令1读取之前就更新了数据,那么就发生了WAR冲突,但是这种冲突不会发生在MIPS里面,因为在MIPS中read永远在stage2,write永远在stage5

- 先写后写(Write After Write/WAW): 指令1先进行write操作,指令2紧接着进行write操作,如果指令2先于指令1更新了数据,那么指令2的结果会被指令1覆盖掉,造成返回值错误,形成WAW的冲突,这种冲突仅仅发生在write操作占用多个流水线级的情况,在MIPS里面同样不会发生

3. 解决方法:
- 暂停等待:如果出现下一条指令依赖于上一条指令的运行结果,那么就暂停下一条指令的执行,直到上一条指令WB执行结束之后我们再继续它的执行,但是这样同样会造成性能损耗
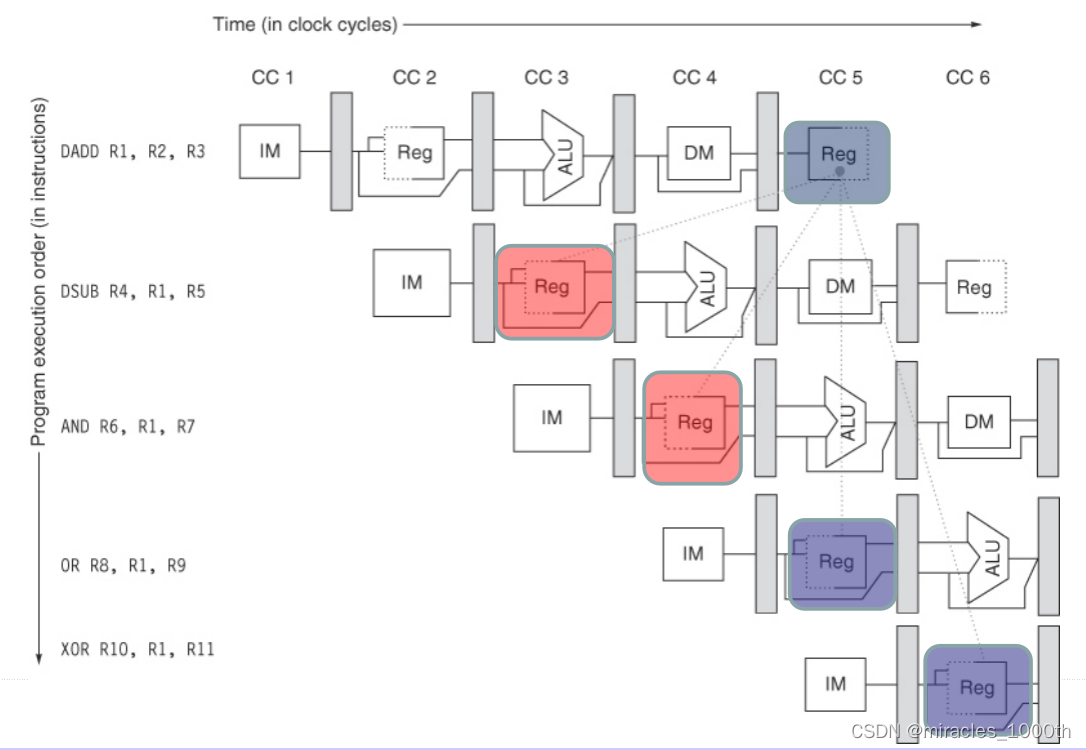
- 分时访问:我们可以看到在上面的流水线的图中,Reg的前半部分是虚线,后半部分是实线,这就是分时访问的效果,由于寄存器的访问时间很短,我们可以分成两个部分,前半部分进行write操作,后半部分进行read操作,这样一来,如果真的发生了RAW的冲突,我们可以将受到影响的后续指令数目从3缩小到2
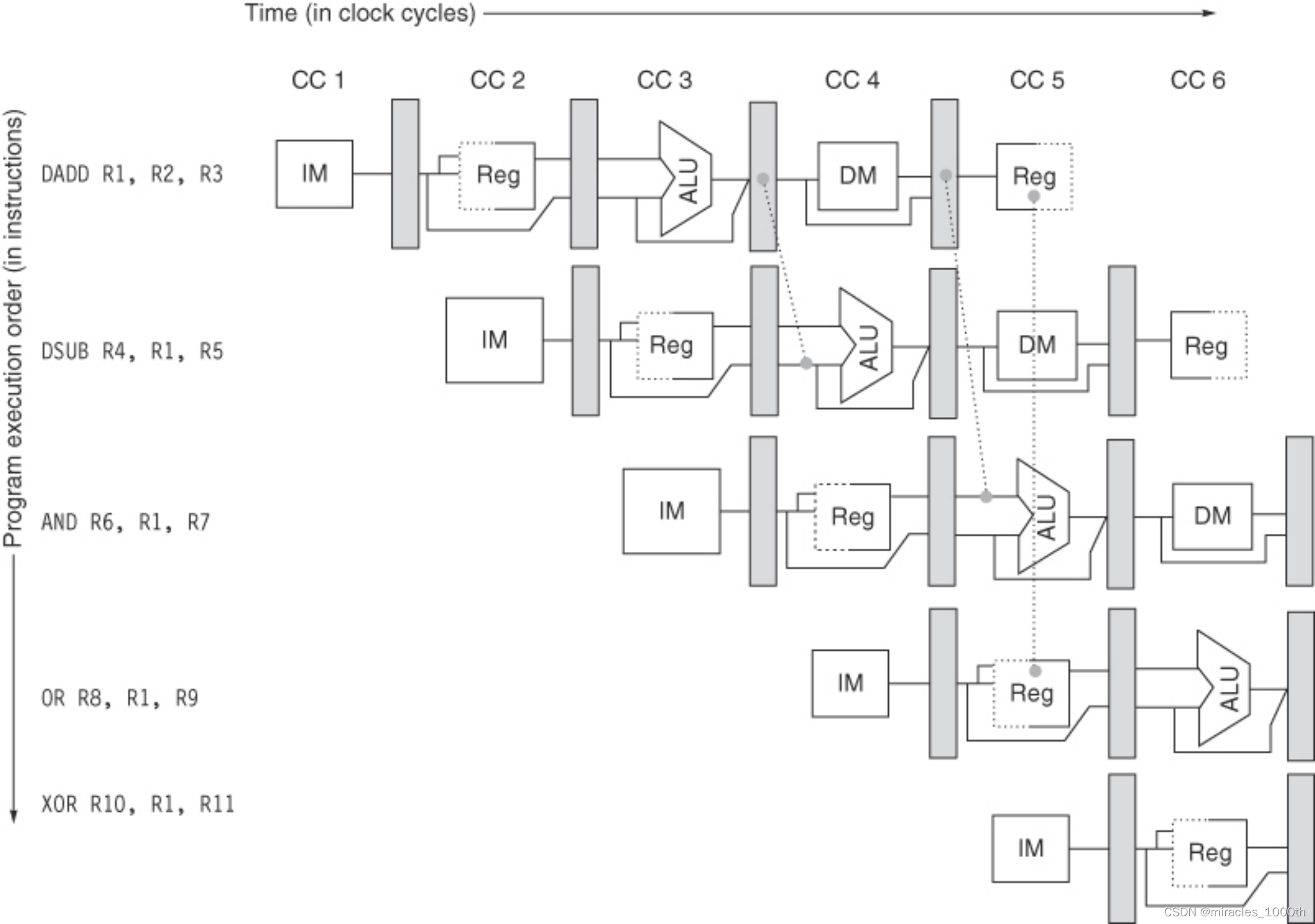
- 数据旁路(forwarding/bypassing) :将所需要的数据直接从一个流水线级传到较早阶段的流水线级的技术,主要的思想是:不是所有的指令得出结果都需要完整的5个stage,有可能结果已经被计算出来存储在流水线寄存器里面,只不过没有写回寄存器,此时我们只需要提供通路,将中间的结果放到ALU/EX阶段或者MEM阶段(MEM阶段也是可以使用Forwarding的)就可以了
也就说,我们拿数据的地方从一个变成了多个,使用forwarding之后,我们不仅可以像原来一样,从通用寄存器中拿到数据,还可以从EX之后和MEM之后的流水线寄存器拿到数据
- 互锁机制:互锁机制更像是Forwarding的一种补充,Forwarding是不能够解决所有的冲突的,Forwarding适合于指令1在ALU,也就是EX阶段就产生新的数据的情况,但是不是所有的指令都可以在EX就产生新数据,就比如说指令1是Load指令,指令2是R型指令,这个时候指令1的数据只能在MEM之后产生,指令2只能等待
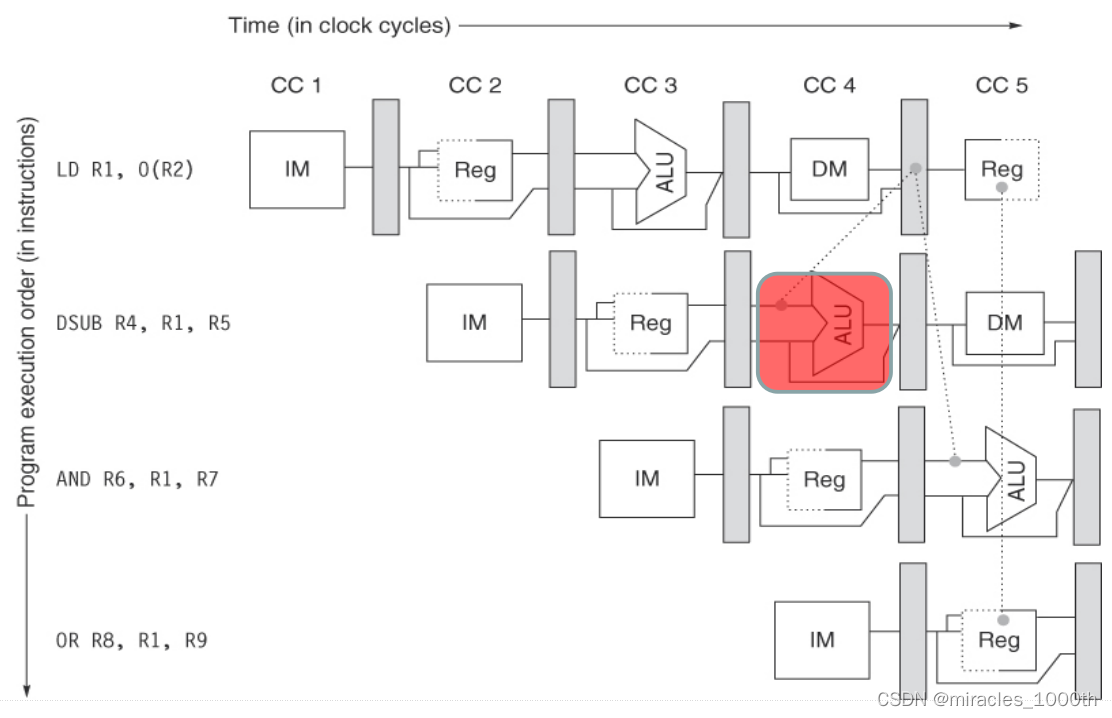
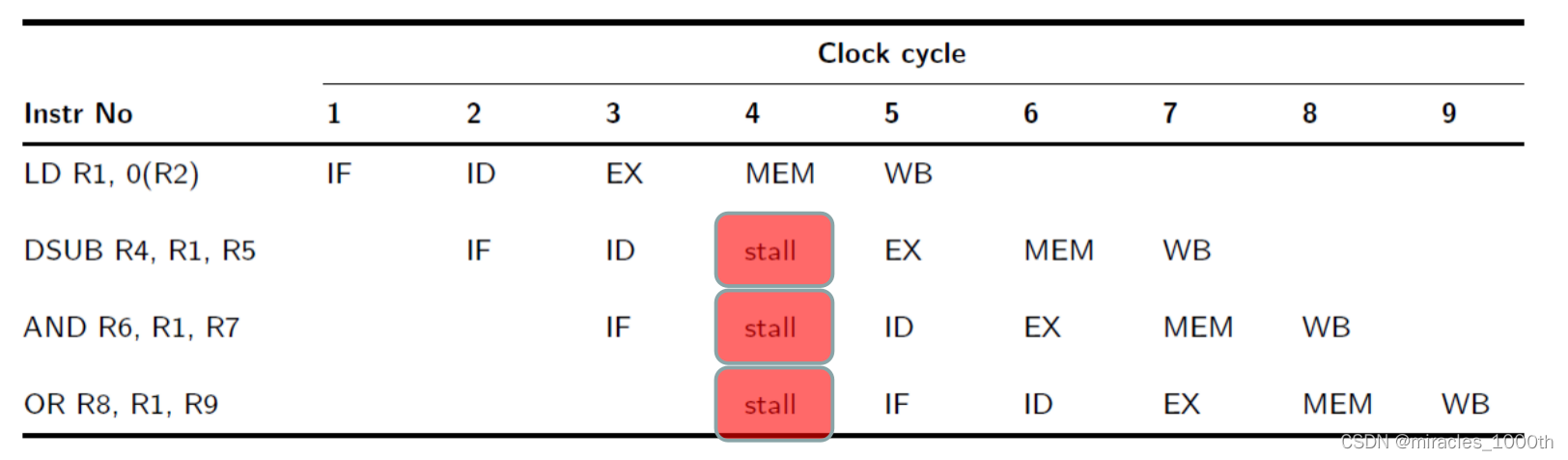
这个时候我们只能暂停流水线,等待指令1执行完毕,冲突消失之后再进行指令2,相当于插入了一个空的气泡
控制冲突(control hazard)
1. 这种冲突发生在分支跳转指令之中,在流水线中,指令是并行处理的,也就是说,在其中一条指令在执行EX的时候,后面的很多条指令已经完成了IF和ID/Reg的阶段,这个时候,如果在这一条指令中要发生跳转,那么后面的所有指令就都不能进行,造成严重的性能损失
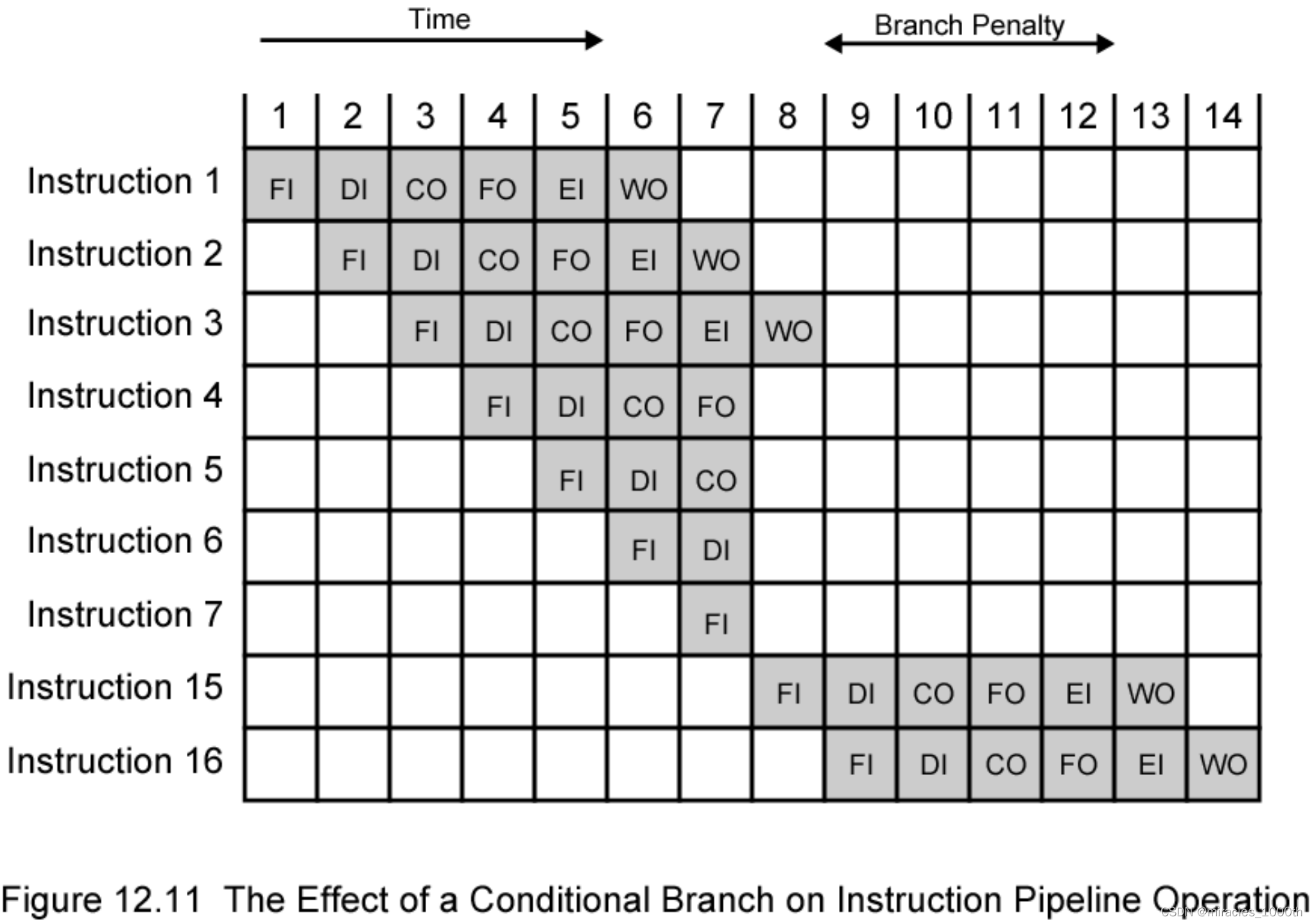
2. 解决方法:
- 排空流水线:暂停,等待分支指令计算出跳转的地址之后再重启流水线,但是会造成很大的延迟
- 延迟分支 :在分支指令之后插入一个无论分支跳不跳转都要执行的一条指令,这样的话,我们不用去预测分支是否跳转,也能保证流水线不会停止
- 分支预测:在ID/Reg阶段进行
1⃣️静态分支预测:是最简单的一种分支预测技术,无论分支的结果是跳转还是不跳转,我们永远认为指令会顺序执行,如果预测出错,丢弃流水线中的指令
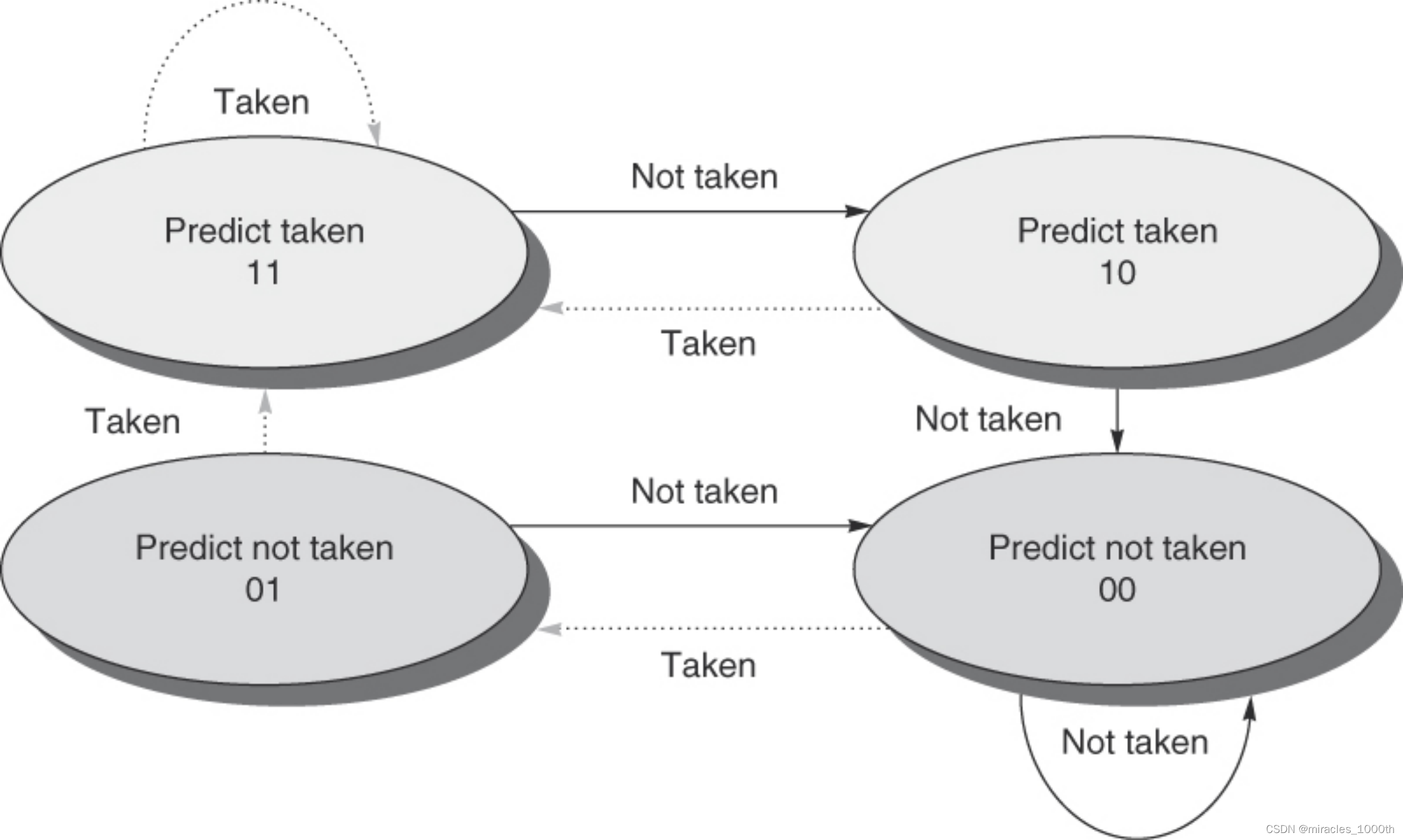
2⃣️动态分支预测:
1)一比特饱和计数:首先假设分支会跳转,一旦出现一次分支不跳转,那么我们之后就假设分支永远不跳转,直到再次出现分支跳转
2)二比特饱和计数:首先假设分支会进行跳转,出现第一次分支不跳转的时候,仍然假设分支会跳转,直到出现连续两次分支不跳转,才将我们的预测变为分支不跳转