
- 1gtm900常用指令集_睿比洋短信指令
- 2Android studio——百度地图_android studio 百度地图
- 3java之Synchronized(锁住对象和锁住代码)_synchronized 项目锁住get set代码
- 4随机扰动
- 5python机器学习手册——学习代码(导入、处理、时间、图像、降维、sklearn模型、神经网络)_python resample sklearn
- 6如何不残留地卸载jupyter/lab_卸载jupyter lab
- 7----uni-app之修改头像----
- 8CSS实现单行或者多行文本溢出隐藏并且显示省略号_css一行显示不下显示省略号
- 9Linux学习之firewallD_firewall: 未找到命令
- 10电磁波的分类_电磁波分类
自然语言处理从零到入门 词干提取与词形还原_词干提取的目的
赞
踩
自然语言处理从零到入门 词干提取 Stemming 与 词形还原 – Lemmatisation
词干提取和词形还原是英语语料预处理中的重要环节。虽然他们的目的一致,但是两者还是存在一些差异。
本文将介绍他们的概念、异同、实现算法等。
一、词干提取和词形还原在 NLP 中在什么位置?
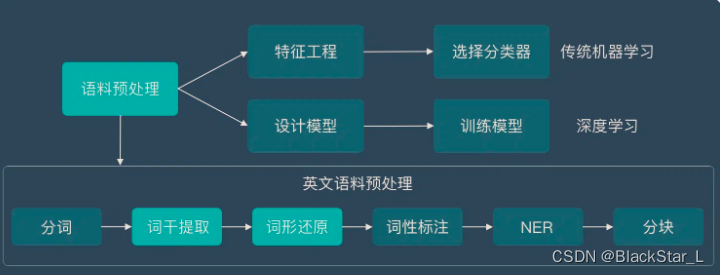
词干提取是英文语料预处理的一个步骤(中文并不需要),而语料预处理是NLP的第一步,下面这张图将让大家知道词干提取在这个知识结构中的位置。
二、什么是词干提取和词形还原?
词干提取:
词干提取(百度百科)
在词法学和信息检索里,词干提取是去除词缀得到词根的过程(得到单词最一般的写法)。对于一个词的形态词根,词干并不需要完全相同;相关的词映射到同一个词干一般能得到满意的结果,即使该词干不是词的有效根。从1968年开始在计算机科学领域出现了词干提取的相应算法。很多搜索引擎在处理词汇时,对同义词采用相同的词干作为查询拓展,该过程叫做归并。词干提取项目一般涉及到词干提取算法或词干提取器。
词干提取(维基百科)
在语言形态学和信息检索中,词干化是将变形(或有时衍生)词语减少到词干,词根或词形的过程 – 通常是书面形式。茎不必与该词的形态根相同; 通常,相关的单词映射到同一个词干就足够了,即使这个词干本身并不是一个有效的词根。自20世纪60年代以来,已经在计算机科学中研究了词干化的算法。许多搜索引擎将具有相同词干的单词视为同义词作为一种查询扩展,一个叫做混淆的过程。
词形还原:
词形还原(维基百科)
语言学中的Lemmatisation(或 词形还原)是将单词的变形形式组合在一起的过程,因此它们可以作为单个项目进行分析,由单词的引理或字典形式标识。
在计算语言学中,lemmatisation是基于其预期含义确定单词的引理的算法过程。与词干化不同,词汇化取决于正确识别句子中的预期词性和词语的含义,以及围绕该句子的较大语境,例如邻近句子甚至整个文档。因此,开发有效的lemmatisation算法是一个开放的研究领域。
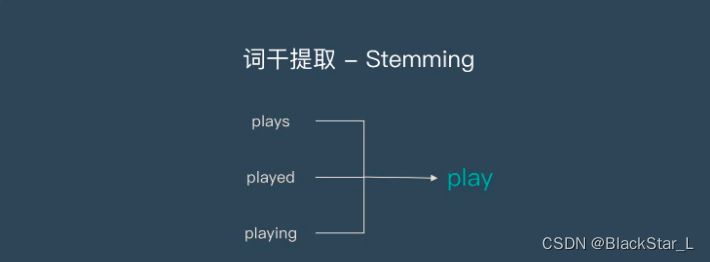
2.1、词干提取 - Stemming
词干提取是去除单词的前后缀得到词根的过程。
大家常见的前后缀有:名词的复数,单词的不同时态变形等等。
2.2、词形还原 - Lemmatisation
词形还原是基于词典,将单词的复杂形态转变成最基础的形态。
词形还原不是简单的将前后缀去掉,而是会根据词典将单词进行转换。比如drove会转换为drive。

为什么要做词干提取和词形还原?
比如当我搜索 play baskball 时,Bob is playing basketball 也符合我的要求,但是 play 和 playing对于计算机来说是两种完全不同的东西,所以我们需要将playing转换成play。
词干提取和词形还原的目的就是将长相不同,但是含义相同的词统一起来,这样方便后续的处理和分析。
三、词干提取和词形还原的 4 个相似点

- 目标一致。词干提取和词形还原的目标均为将词的派生形态等变化为词干(stem)或原型的基础形式,都是一种对词的不同形态的统一归并的过程。
- 结果部分交叉。词干提取和词形还原不是互斥关系,其结果是有部分交叉的。一部分词利用这两类方法都能达到相同的词形转换效果。如"dogs"的词干为"dog",其原型也为"dog"。
- 主流实现方法类似。目前实现词干提取和词形还原的主流实现方法均是利用语言中存在的规则或利用词典映射提取词干或获得词的原形。
- 应用领域相似。主要应用于信息检索和文本、自然语言处理等方面,二者均是这些应用的基本步骤。
四、词干提取和词形还原的 5 个不同点

- 在原理上,词干提取主要是采用"缩减"的方法,将词转换为词干,如将"cats"处理为"cat",将"effective"处理为"effect"。而词形还原主要采用"转变的方法",将词转变为其原型,如将"drove"处理为"drive",将"driving"处理为"drive"。
- 在复杂性上,词干提取方法相对简单,词形还原则需要返回词的原形,需要对词形进行分析,不仅要进行词缀的转化,还要进行词性识别,区分相同词形但原形不同的词的差别。词性标注的准确率也直接影响词形还原的准确率,因此,词形还原更为复杂。
- 实现方法上,虽然词干提取和词形还原实现的主流方法类似,但二者在具体实现上各有侧重。词干提取的实现方法主要利用规则变化进行词缀的去除和缩减,从而达到词的简化效果。词形还原则相对较复杂,有复杂的形态变化,单纯依据规则无法很好地完成。其更依赖于词典,进行词形变化和原形的映射,生成词典中的有效词。
- 在结果上,词干提取和词形还原也有部分区别。词干提取的结果可能并不是完整的、具有意义的词,而只是词的一部分,如"revival"词干提取的结果为"reviv",“ailiner"词干提取的结果为"airlin”。而经过词形还原处理后获得的结果是具有一定意义的、完整的词,一般为词典中的有效词。
- 在应用领域上,同样各有侧重点。虽然二者均被应用于信息检索和文本处理中,但侧重点不同。词干提取更多被应用于信息检索领域,如Solr、Lucene等,用于扩展检索,粒度较粗。词形还原更主要被应用于文本挖掘、自然语言处理,用于更细力度、更为准确的文本分析和表达。
五、3 种主流的词干提取算法

1. Porter
这种词干算法比较旧。它是从20世纪80年代开始的,其主要关注点是删除单词的共同结尾,以便将它们解析为通用形式。它不是太复杂,它的开发停止了。
通常情况下,它是一个很好的起始基本词干分析器,但并不建议将它用于复杂的应用。相反,它在研究中作为一种很好的基本词干算法,可以保证重复性。与其他算法相比,它也是一种非常温和的词干算法。
2. Snowball (推荐)
种算法也称为 Porter2 词干算法。它几乎被普遍认为比 Porter 更好,甚至发明 Porter 的开发者也这么认为。Snowball 在 Porter 的基础上加了很多优化。Snowball 与 Porter 相比差异约为5%。
3. Lancaster
Lancaster 的算法比较激进,有时候会处理成一些比较奇怪的单词。如果在 NLTK 中使用词干分析器,则可以非常轻松地将自己的自定义规则添加到此算法中。
六、词形还原的实践方法
词形还原是基于词典的,每种语言都需要经过语义分析、词性标注来建立完整的词库,目前英文词库是很完善的。
Python 中的 NLTK 库包含英语单词的词汇数据库。这些单词基于它们的语义关系链接在一起。链接取决于单词的含义。特别是,我们可以利用 WordNet。
import nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize("blogs"))
#Returns blog
import nltk
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
print(lemmatizer.lemmatize("blogs"))
#Returns blog
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
总结
词干提取和词形还原都是将长相不同,但是含义相同的词统一起来,这样方便后续的处理和分析。
他们是英文语料预处理中的一个环节。
词干提取和词形还原的 4 个相似点:
- 目标一致
- 部分结果一致
- 主流实现方式类似
- 应用领域相似
词干提取和词形还原的 5 个不同点:
- 原理上不同
- 词形还原更加复杂
- 具体实现方式的侧重点不同
- 呈现结果有区别
- 应用领域上,侧重点不完全一致
3种词干提取的主流算法:
- Porter
- Snowball
- Lancaster
英文的词形还原可以直接使用 Python 中的 NLTK 库,它包含英语单词的词汇数据库。
参考
词干提取(百度百科)
词干提取(维基百科)
词形还原(维基百科)
词干提取 – Stemming | 词形还原 – Lemmatisation (easyai)

