
- 1使用 pandas 读取 excel 表格之读取指定的子表 sheet_pandas读取excel指定sheet
- 2Java条件语句_代码 如果年龄大于15,这种行为可以
- 3wps计算机里wps云盘图标,使用注册表删除我的电脑中的WPS网盘、百度网盘、微盘云等图标...
- 4前端学习(271):网格布局grid-template_grid-template: 1px 1px 1px 1px /1px ??
- 5Microsoft Edge功能测评_对edge的点评
- 6大模型推荐落地啦!融合知识图谱,蚂蚁集团发布!
- 7用python找对象_你还单身?Python 教你脱单
- 8axios全局配置及拦截器_axios crossdomain
- 9Window10数据库崩溃启动失败,MySQL8.0.30通过data文件夹恢复数据库到Docker_2024-03-13t05:33:08.592634z 0 [warning] [my-010915
- 10不用编程超简单的自动化测试工具:Airtest安装使用入门篇_airtest教程
信息论笔记(需要编辑格式)_信息是消息中包含的有意义的内容。如果消息很多,是不是意味着承载的信息量也很大
赞
踩
主要来源:吴军·信息论40讲
信息论介绍
- 世界上任何一个探索者都需要清楚三件事:我们现在的位置,我们的目标,以及通向目标的道路。
哲学是一门生活的艺术,它帮助我们认清自己,它回答了第一个问题。至于每一个人的目标,我相信大家比我更清楚。而第三件事其实是方法论。一般没有科学基础的方法论常常难以持久。 - 世界上的知识,可以分为道和术两个层面
这门课讲的是道的层面的知识,它不会讲述任何具体的方法,比如信息的采集、处理或者传输的理论细节。这样,我们就能够把重点放在讲述用信息论指导做事的方法上,以便让我们能够在不断变化,而且充满不确定性的世界里把握住机会,立于不败之地。
一个人的思维方式和做事方法常常决定了一个人能够走多远,而在历史的任何时期,都有最适合时代的方法论。如今,面对不确定性和非连续变化,信息论所提供的方法,能成为解决今天各种困惑的工具。即使不了解其中理论的细节,也应该知道 它的原理。 - 简介信息论
信息论从本源出发,为信息的收集、处理、分析提供里理论基础,是数据时代的树种。信息本是自然天成,信息论的众多规律符合奥卡姆剃刀原理,具有很多的普适性和延展性,更多需要我们从信息论的原理出发,分析我们今天的做事方法。
大数据思维,就是这种方法论的一个应用。数据思维的分析部分是信息思维。大数据的价值来自其更准更及时的提供信息。通过数量、维度将现实存在的问题转变为计算问题,信息收集则转化为为数据收集问题。这也是互信息的的体现。
信息产生:在面对大量信息时,排除噪音,提取利用有效信息,科学做决策的能力; 信息传播:向外界传递信息时,平衡分配有限资源,增加沟通带宽,放大影响力的模块三信息应用:看懂信息应用的逻辑和通信发展的趋势,提前抓住新机遇的能力。
信息量是用比特衡量,取决于系统的不确定性而不取决于表面编码。而信息的价值不在于信息量的多少,价值取决于不确定性的重要程度,真正的决策时需要的信息不过是1-2比特。而系统的不确定性则用引用信息熵来衡量。
从中可以看出,信息是自然界的固有属性,根源来自不确定性。存在与否并不随人的主观意志而改变,但我们能够发现并利用。例如通过数字文字等编码掌握不确定性。
除此之外信息还具有等价性、相关性,这为信息的传播提供了基础。从系统论出发,信息的编码、压缩、传输、解码、储存等为构成了信息的传播,整体的最佳则各部分都必须作出让步。
根据信息的等价性,我们对信息编码 ,意味着在不同维度上展开了信息,这是多维分析的根源。编码的方式有很多,各有利弊。其中哈夫曼编码对信息的编码方式极契合自然,同时也是利用系统确定性对资源分配的绝佳案例。增量编码则是在等价性的基础上,利用了信息的相关性。
编码的信息需要解码才能够还原为信息,为了解码的便捷和准确,原始信息在编码时具有一定的冗余。无论是编码还是传输,错误是一定存在的,所以信息必需有一定的纠错、容错能力,这些都建立在冗余的基础上,比如纠错码。为了信息的安全我们也会通过特殊的编码方式将信息进行加密,。
信息的冗余不利于信息的高效传输,便需要压缩、解压。各种编码方式有对应的压缩和解压方法。利用傅立叶变化进行信息的编码、压缩源于信息的等价性,增量编码和压缩则跟据相关性。为了更近一步提高效率,根据失真度,可以舍弃一部分维度的信息,这便是有损压缩。
信息的解码,则是逆向的。对于常规的信息,利用等价性原理可以根据编码,压缩的方式逆向运行。同样利用信息等价性进行也可以进行解码比如:核磁共振,被称为互信息。也可以逆向运用利用相关性和多维分解,解码非常规的信息,也被称为信息的正交性。
除了信息的基本面,更多的是我们需要对得到的信息进行分析判断。对于信息的可靠程度由置信度来衡量,只有样本的样本才能确定其可靠性。现实中这点做到很难,参杂着人有意无意的误导,幸存者偏差是较为典型的案例。新增信息的价值,可以用信息增益衡量,核心仍是信息熵,这点能有效的指导我们寻求新的信息。但获得的信息有限,我们又必须作出选择,就需要计算错误信息的代价,最大熵原理是面对这种局面的一种方式,极大降低主观判断带来的影响。
有信息必有噪音,在信息的捕捉、储存、传输和处理方面我们都必须考虑噪音,这就必须了解噪音的特性,区别于冗余。信噪比决定了我们能否有效接受信息,为了有效提高信噪比需要根据噪音的维度和来源对噪音进行过滤。
信息的传输需要信道,信道的容量就是信息传播的成本和边界。只有理解了传输率,我们才能够理解互联网的发展,包括5G和Iot,同时有利于我们现实中的沟通。更少的能量传输更多的信息是必然。
1.信息量和不确定性有关
关键词:决策、公式、损失
1."不要重视钱而轻视信息"信息的重要性等同于钱。它能四两拨千斤。信息能驱动很大的能量。而信息作用的大小和信息量有关。
1比特信息是非常少的,是一个计算机字节的1/8,一个像素1/24。但是,这么一点信息产生的作用却是巨大的。为什么信息有这样四两拨千斤的作用呢?这其实背后也是有科学根据的,在控制理论中有一种开关电路,控制这个开关只需要一比特的信息或者极低的能量,但是经过它的电流(可以被认为是能量)却能近乎无限大,今天我们很多电器中那些弱电控制强电的元器件就是利用这个特点工作的。信息的价值在于能够控制巨大的能量。
2.信息量和不确定性有关,大家都知道的事,就没有什么信息量了。
如果存在两种情况,它们出现的可能性相同,都是50这时要消除其不确定性所需要的信息是1比特。但是如果一种情况发生的可能性大,另一种发生的可能性小,所需要的信息就不到1比特。比如说,一种情况出现的概率是1/3,另一种是2/3,这种情况下消除不确定性的信息量则降低到0.9比特。在更极端的情况下,比如一种情况有99??可能性发生,另一种是1那么这时的不确定性只有0.08比特了。信息的这个性质,和我们生活的经验是一致的,大家都知道二者皆50%可能性最让人头疼。而公众都知道的信息,其实是没有信息量的。(二选择一的场景下,假设第一选择发生的概率是p(p介于O~100?那么根据信息量(所需比特)公式定义为 log§+log(1-p)=log[p*[(1-p],因为log函数是单调递增的,所以 p(1-p)取最大值的时候,信息量(比特)也最大,即 p=50%最大。那么当p往两边跑的时候,这个信息量就下降了。(大家可以想象一条抛物线,在中点 p=0.5的地方是最高点)
二战盟军登陆地点的信息量又有多大呢?虽然德军最后可能确实相信了盟军的假情报,在加莱重点设防(前线的两位元帅相信了,但是希特勒并没有相信),但是,整个诺曼底战役创下了英美军队在一场战役中阵亡的最高记录。为什么盟军骗过了德军,却还是损失惨重?因为德军采用了信息论中一种非常好的对策,也就是不把鸡蛋放在一个篮子中,他们在诺曼底也严密设防了。因此,德军在得到信息前和得到信息后,策略差不多,这1比特的信息作用就不大了。你可以通过这两个例子看出来,改变世界的情报,信息量可能1比特都不到,而且这1比特的信息很可能还会遇到更高明的应对策略,失去价值。不仅如此,很多时候,可能这1比特信息还会害了你。
3.对一个未知系统(黑盒子)所作出的估计和真实情况的偏离,就是信息的损失,偏离越多损失越大。此外,我们还提到了信息论的一个原则,不要把鸡蛋放在一个篮子中,这样可以避免因为信息缺失,而导致灾难性结果。
1比特的信息很可能还会遇到更高明的应对策略,失去价值。不仅如此,很多时候,可能这1比特信息还会害了你。在最后一个例子中,情况就是如此。赵括以为对方的主帅是王龁,但是结果正相反,真正的主帅是白起。这种情况最为悲催。怎么从信息论的角度分析这种危害最大的情况,我们在后面介绍交叉嫡时会专门讲。
(大家可以想象一条抛物线,在中点p|=0.5的地方是最高点)|对*“我们知道1比特信息是非常少的,|是一个计算机字节的1/8,一个像素的1/2|**的解释-计算机是二进制的,一个字节(1byte,1B)由八位0或1组成的数串组成,例如01011010,其中的每一位叫做比特(1bit,1B=8bit).-而一个像素对应的比特信息,需要看是什么模式了,有以下几种常见模式:-如果是灰度模式(黑白照片)1像素就是1byte;-如果是RGB模式,1像素则要用(R,G,B)三个byte表示;-如果是CMYK模式,1像素则要用(C,M,Y,K)四个byte表示;吴军老师在文中提到的1比特是一个像素的1/24,是指RGB模式下的场景。###吴军信息论##金勇笔记##延伸阅读##关于Peter_Norvig-他是全世界人工智能领域的殿堂级人物,人工智能教科书的作者,Google研究院的"火车头组"之一。-我无意之中曾经看过他2016年Berkely毕业生典礼上的演讲[YouCanAlwaysGetWhatYouWant—ButNotW|hatYouNeed],对我产生了很大的启示。为了方便我已经上传到B站,有兴趣的同学在Bilibil视频网站,搜索Norvig就能看到了。###吴军信息论##金勇笔记##个人收获#:-大家好,我是金勇。既是得到的普通|员工,又是吴军老师的粉丝。作为工程师,我会在未来的一个月常驻知识城邦,和大家一起学习吴军老师在得到App的第四门大课:《信息论》(继)。|谈谈我的过往故事。在2016年,我曾经在两个小型互联网公司的Offer中犹豫不决,它们除了商业模式上,在很多地方都很相似:年轻、朝气、重视数据但缺少|人才,面临着二选一的左右选择。因为缺少足够的信息和判断依据,我最后相信了直觉,选择了A公司,但是入职不久之后发现这家公司并不是想原来自己想象的||那样,我断言它的商业模式不可持续且没有新的变革基因。于是在半年之后,我离开了A再次去B求职,并在B公司完成|了自己的社会新人的转型。三年之后的今天,当初的A公司已经黯然消沉了,而B|公司则已经成为了互联网垂直领域的TOP|3。这就是本讲结尾处,“信息的损失,偏离越多损失越大”。如何避免这种情况(或者说降低这种损失)?得到大学的"多元思维模型”、2018年罗老师《知识就是力量》、罗辑思维专栏
2.信息的固有属性
关键词:本身存在、置信度、从0到1
信息是宇宙本身固有的属性。宇宙是如何产生的是:3K背景辐射;地球生命的共性和起点:沃森和克里克DNA结构;以及人类文明的起点:G蛋白偶联受体。信息并不被我们主观控制,但是我们可以发现它们。
置信度:有些推断可信度高一些,有些低一些,世界上没有绝对的可靠,只有可靠性的高和低,信号和噪音比率的高和低。从信息论上说,信息的可靠性就叫做置信度。
信息量高低取决于是否大家都知道:对于一件过去大家不知道的事情,现在知道了,信息量就大,对于一件大家基本上了解的事情,即使你的文章写得再长,信息量都有限。提出问题比解决问题更重要,因为提出问题的人,开创了一个重要的却是完全未知的领域,回答问题并且给出最初解答的人,由于通常只是在某种认识阶段上对未知的领域提供一些有限的信息,因此贡献有限,被认可的程度不高。在一个领域的贡献大小,不在于你提供了多少材料,而在于提供了多少信息量。
信息传递的效率:奥卡姆剃刀原则?
3.信息改变思维模式
关键词:计算模型、长尾、动态、创新
数据的四类应用。
第一类是解决人工智能问题。利用数据(信息)消除不确定性,这把需要人脑推理的问题,变成基于大数据的计算问题。
语音识别技术:贾里尼克用通信中的编解码模型代替计算机学会构词法。通过通信编解码理论以及有噪音的信道传输模型,构建了语音识别的模型。模型里面有很多参数需要计算出来,这就要用到大量的数据,于是,贾里尼克就把上述问题又变成了数据处理的问题了收集数据,训练各种统计模型 。贾里尼克思想的本质,是利用数据(信息)消除不确定性,这就是香农信息论的本质,也是大数据思维的科学基础。
第二类是利用大数据,进行精准的服务。公司从重研究方法转变到重数据收集的。
精准服务:理解用户的意图,进行个性化服务,需要非常非常多的数据。如果对每一个人进行统计,数据量就不够了,因为一个人搜索的数量再多,也无法和所有人相比。一旦数据量不够,统计就变得毫无意义。因此,这一方面需要尽可能多地收集数据,另一方面则需要对行为习惯和偏好类似的人进行聚类找到趋势。微软的搜索效果没有Google的好,不是技术不行,而是数据量不够。对于那些常见的搜索,大家其实水平差不多,微软差就差在了那些很少见到的长尾搜索关键词上。
第三类是动态调整我们做事情的策略。 足够多的数据可以帮助我们动态匹配最佳结果。
机械论的思维方式,是通过找到通用的规律试图一劳永逸地解决问题。通过几十年的工业革命,今天容易一劳永逸解决的那些问题大多数已经被解决了,留给我们的是不确定性的问题,因此我们做事情的策略也就要变化。优步和滴滴都是不允强调司机和乘客之间的固定性,比如A乘客坐B司机的车子比较满意,他下次依然希望提前预订B司机的服务。因为对于一个不断变化的打车人群分布和车辆分布,利用数据做动态调整是效率最高的策略。如果有了足够多的数据,在理论上有保障,只要调整的次数足够多,就能收到最佳匹配。如果你没有足够多的数据,一共只有200辆车,5000个人的数据,你是做不到这一点的。
第四类是发现原来不知道的规律。 互信息的理论。
处方药和各种疾病重新匹配今天研制一款新药需要20年时间,20亿美元的投入,这是惊人的投入。能否减少这方面的研发成本,缩短研发周期呢?过去一种治疗心脏病的药治疗胃病效果很好,于是他们直接进入小白鼠试验,然后进入了临床试验。由于这种药的毒性已经试验过了,因此临床试验的周期短了很多。这样,找到一种新的治疗方法平均只需要3年时间,投资1亿美元。
如果说存在问题,那一定是数据问题;如果说不存在问题,那只是没有人提出有问题的数据。
4.信息的度量
关键词:比特/不确定性
信息是可以量化度量的,单位就是比特。很多复杂交易和产品都是利用了信息的可度量性,把信息问题变成了概率问题。
信息的量化度量:单位是"比特"。信息量的大小不在于长短,而在于开创多少新知。度量信息,香农放弃了从信息的内容出发,将不确定作为"砝码",也就是将信息的量化度量和不确定性联系起来。给出一个度量信息量的基本单位,就是"比特’’。比特"定义:如果一个黑盒子中有A和B两种可能性,它们出现的概率相同,那么要搞清楚到底是A还是B,所需要的信息量就是一比特。如果我们对这个黑盒子有一点知识,知道A的概率比B大,那么解密它们所需要的信息就不到一比特。信息说到底是用于消除不确定性的。如果讲的事情大部分大家都知道,信息量就很少。这也是为什么那些心灵鸡汤的文章大家不愿意读,并非是它们说的不对,而是没有信息量。
不确定性的度量:信息熵
你可以把一个充满可能性的系统视为一个"信息源",它里面的不确定性叫做"信息嫡",而"信息"就是用来消除这些不确定性的,所以搞清楚黑盒子里是怎么一回事,需要的"信息量"就等于黑盒子里的"信息嫡"。嫡其实是一个热力学的概念,表示一个系统的无序状态,或者说随机性。一个系统中不确定性取决于:状态数量和各个状态的可能性。一个系统中的状态数量,也就是可能性,越多,不确定性就越大;在状态数量保持不变时,如果各个状态的可能性相同,不确定性就很大;相,如果个别状态容易发生,大部分状态都不可能发生,不确定性就小。信息嫡的公式:。永远不要听那些正确率总是50%的专家的建议,因为那相当于什么都没说,没有提供能够减少"信息嫡"的"信息量"。

开赌局的,只要收费比信息实际的价值高,都是稳赚不赔的。就是开赌局的从来不是拿自家的钱和你对赌,而是让你们彼此互相赌,他通过变相多收费盈利。
很多复杂交易背后其实都用到了信息的可度量性。
赌球:假如,我们能提前确定各个球队获得世界杯冠军的概率,设定它们分别是P1,P2,……,P32。那么我们套用上面的公式,就可以算出这件事需要多少信息,或者说这个问题的信息熵。我们假定为3.4比特,或者说对应于3.4块钱。如果有一个人提一次问题支付一块钱,从理论上讲,所有参加赌局的人只要平均支付3.4块钱就能得到谁是冠军这个信息。但是如果设定赌局的人将收费标准略微提高,提高到一个人平均4元。这里面的盈余就被设赌局的人拿走了。我们不可能提前知道概率,那每个球队得冠军的概率是如何预估的?其实这是我们这些下注的人告诉设赌局的人的。如果大家都往德国队身上下注,结果预测德国获冠军的概率就很高,所以押注的多少其实就是大家给出的概率。
结构化的投资证券(Structured Notes):比如说石油的价格上涨到100美元以上,每1美元高盛就付给你1.5美元。但是,如果没有到100美元,你需要每个月付给高盛1美元。并不是高盛在和石油公司,或者其他人对赌么。因为高盛转手就将和它完全相反的投资产品,卖给了希望油价波动的人。当然,高盛会包装得很好,让两边都感谢它,其实它才是真正挣钱的一方。
金融数学这个专业,那里面的人天天做的事情就是设计这种不容易为人所看懂的,自己永远不赔钱的金融产品。而所谓的基金经理,很多就是把这样的产品卖给你的人。
5.编码的长度
关键词:香农第一定律/不缺定性
香农第一定律:码长度≥ 信息嫡(信息量)/每一个码的信息量。香农第一定律告诉我们:
1.可以找到最短编码,只要编码设计得足够巧妙。数字和文字语言是人类用来消除信息不确定性的编码。
2.信息量与码长无关。信息量只取决于信息熵即不确定性,各种编码系统,其实都是在编码复杂性和编码长度之间作平衡,它们在信息量上是等价的。采用很多个符号,编码长度就短,但是系统就复杂;采用很少的符号编码,比如采用二进制,编码的长度就长
案例:有100个数,挑出一个,不确定性是100选1, 信息嫡为log100=6.65(注:log以2为底的100的对数,课程中的log函数如果没有特殊说明都是以2为底的。有6.65比特的信息,可以确定100个数中的一个。
第一种如用100种奇形怪状的符号对应这100个数字,这种编码所能表示的信息量,其实就是100选一的问题,也就log100=6.65比特。由于一个编码正好表示一个数,因此编码的长度为1。
第二种编码方法是采用十进制编码,也就是用10种符号,每个符号所代表的信息量只有log10=3.325比特,但是10个符号想表示100个数字,就需要两两组合。这样两个符号的信息量加起来还是6.65比特,是编码的长度是前一种的两倍。用二进制编码,就是只有0和1这两个符号,它们所包含的信息只有log2=1比特,如果我们想用它们来表达100个数,则需要6.65个码。进位取整以后,也就是7位的码长,才能表示100个数字。
3.各种编码系统是等价的,所以,在其他编码系统中解决不了的问题,换一个系统同样解决不了。这就是问题,比答案更有价值的原因。人不可能解决一个,自己都没有意识到的问题,即使碰巧解决也没有意义。
语言的形成过程:逐步意识各种不确定性是本源,各种编码是掌握不确定性的过程。
早期无论是苏美尔人、古埃及人、古中国人,还是印度河文明的古印度人,都采用的是象形文字是对实物及其类别的确定。一个图画就是一个意思。
但是后来要表达的意思实在太多了,总不能无限制地发明文字,于是就出现了用几个文字表达一个复杂的含义。
假如一个原始人家里有10样东西,他给每个东西起一个名字,这就是最简单的编码,而且早期起的那些名字都容易让人联想起东西的特性,就如同把狗叫成汪星人,把猫叫成咕星人一样。当然,家里的东西多了,要做的图像多了,就做不到把每一件事单独编码,就需要利用一些编码进行组合了。
人类使用动词,标志着文明的一大进步,这意味着他们能够把动作进行分类,编码了,而且这样才能表达复杂的意思,才有可能形成知识。比如说一个原始人让孩子把家里的石斧拿来,他就可以告诉他采用"拿来"这个动作,而要拿的对象是"石斧"。
有了象形文字和动词之后,人类就有了书写系统,各种信息就通过文字这种编码记录下来,这才让我们了解到过去的历史。但是,从此人类的不平等也开始加剧,因为能够认识编码的人,就掌握了其他人所没有的信息。
6.信息的编码
关键词:易辨识/信息量/信息组合
1.编码第一个特点就是:易辨识,要便于区分不同的信息。
例如:0~9就是一个很好的编码系统,对于描述数字信息来讲,它们的数量不多不少,形状差异大。如果采用一个小 圆点".“代 表一,两个”.“代表二,三个”…“代表三,十个”……"代表十,就不太好,因为大家容易看花眼。
此原则主要针对人的需求,高效的理解信息。在平时的表达和沟通中也很重要,德国著名的营销专家和演说家多米尼克·穆特勒提出的清晰表达的五个原则:明确、诚实、勇气、责任和同理心,前四条就和信息编码要便于识别有关。文字本身就是符号,许多专业文件都写得像八股文,无论是病例,律师写的法律文件,或者科学杂志上的论文,其最根本的目的就是要在同行中确保意思表达无误,不会产生任何误解。
2.编码要做到"有效"。高效编码能容纳更多的信息。
用十根手指头,能表达多少个数字?个巴掌就能表示十个数字,将巴掌组合起来,一个表示个位,一个表示十位,就能表示从0到99共100个数字。如果我们考虑采用二进制,每个手指对应于一位二进制,十个指头能表示10位2进制,则能表示1024个不同的数字。但如果让每个手指具有伸开、半伸开和收缩三个状态,表示59049个数,就过分强调有效性,而忽视了易辨识这个原则。
案例:
如何组合信息,保证它高效传递,还能不违背第一条"易辨识"的原则。
1.例如;
硅谷的公司里有这样一道面试题:有64瓶药,其中63瓶是无毒的,一瓶是有毒的。如果做实验的小白鼠喝了有毒的药,3天后会死掉,当然喝了其它的药,包括同时喝几种就没事。现在只剩下3天时间,请问最少需要多少只小白鼠才能试出那瓶药有毒?这是一个64选1的题目,那么需要的信息量就是log64,也就是6比特,只要6只老鼠。
1.我们将这些药从O~63按照二进制编号要点是:除二取余,倒序排列。
2.然后选六只老鼠从左到右排开,和二进制 的六位,从左到右地依次对应
3.从左边数第一个老鼠吃对应的二进制是1的药,0就不吃。
4.吃完药之后三天,某些老鼠可能死了,我们假定第1,2,6这三只老鼠死了,剩下的活着。说明编号110001号药有问题,而110001对应十进制的49,也就是说第49瓶药是毒药。
2.产品测试:
有效编码的思想在今天IT的产品性能比对测试中有直接的用途。其中很重要的一条就是采用大量用户反馈信息决定产品的设计和技术方案。
比如在一个产品中,有两种可用的方案,A和B,哪种更好呢?过去常常是工程师们和产品经理们拍脑袋想,有些时候某些人的"眼光"很好,正好蒙对了,选了一个用户也喜欢的方案,但是这种"眼光好"是无法复制的,一个公司将自己的商业 成功寄托在"眼光好"上早晚要失败。利用用户大数据评判A、B方案的好坏,通常的做法是随机选取1%用户作对比实验。比如Google在改进搜索算法或者其它产品体验后,会先做这样不公开的测试,一般会持续一周左右。但是像Google这样有好几万工程师的大公,每天的各种改进是很多的,如果每个项目都用掉1%用户,把全部用户用上也不够。通过高效编码问题,利用少量用户同时进行很多个实验的方法,就类似上面这种让小白鼠试毒药的方法,也就是将各种不会发生冲突的实验用二进制进行编码,几组实验者,就可以同时进行几十个不同的实验。
7.最短的编码
关键词:概率分析/哈夫曼决策
哈夫曼编码 :越常出现的信息采用较短的编码,不常出现的信息采用较长的编码。比采用同样码长的信息总体上更合算。这种最短编码方法等于香农第一定律的继续,由哈夫曼发明的,要点:
1.通过香农第一定律,可以从数学上可以证明哈夫曼的这种编码方法是最优化的。(相当于信息熵不变的情况下,提高每个码的信息量)
2.本质上是将最宝贵的资源(最短的编码)给出现概率最大的信息。分配原则:一条信息编码的长度和出现概率的对数成正比。
案例:
1.基础推导步骤:
我们不妨看一个具体的例子。我们假定有32条信息,每条信息出现的概率分别为1/2、1/4、1/8、1/16……依次递减,最后31、32两个信息出现的概率是1/231、1/231(这样32个信息的出现概率加起来就是1了)。现在需要用二进制数对它们进行编码。等长度和不等长度
两种编码方法,我们来对比一下:
方法一:采用等长度编码,码长为5。因为是log32=5比特。
方法二:不等长度编码,如果出现概率高就短一些,概率低就长一些。我们把第一条信息用0编码,第二条用10编码,第三条用110编码··最后31、32两条出现概率相同,都很低,码长都是31。第31条信息就用1111……110(30、个1加l个O)编码,第32条信息,就用1111……111(31个1)来编码。第一条消息出现的概率为1/2,我们知道1/2(以二为底)的对数等于-1,因此它的编码长度就是1(即码0)。最后两条消息出现的概率为1/2 -31次方,取对数后等于-31,因此它们的编码长度就是31。
这样的编码虽然大部分码的长度都超过了5,但是乘以出现概率后,平均码长只有2,也就是说节省了60%码长。如果利用这个原理进行数据压缩,可以在不损失任何信息的情况下压缩掉60%
2.压缩:比单独一条信息,其概率分布差异更大,因此对它们使用哈夫曼编码进行信息压缩,压缩比会更高。比如说,在汉语中,如果对汉字的频率进行统计,然后压缩,一篇文章通常能压缩掉50%上,但是如果按照词进行频率统计,再用哈夫曼编码压缩,可以压缩掉70%上。
3.莫尔斯电码:他根据常识对经常出现的字母采用较短的编码,对不常见的字母用较长的编码,这样就可以降低编码的整体长度。如果对英语26个字母采用等长度的编码,比如进行二进制编码,需要log26,就是约5比特信息。而采用莫尔斯的编码方法,平均只需要3比特,这个效率就高了很多,这样发报,时间就能节省大约1/3左右。如果所有的信息出现的概率相同,采用哈夫曼编码,每一条信息的码长都一样,这时哈夫曼编码就变成了等长编码,没有优势了。
抽象拓展:
3.在现实生活中,使用哈夫曼编码进行决策。
投资:不断尝试,坚决止损。一方面不排斥尝试新东西,这样不会失去机会,。另一方面对于花了一些精力,看样子做不成的事情,我是坚决做减法止损,以把最多的资源投入到成功率最高的事情上。
凯鹏华盈。虽然换了三代掌门人,但它能在四十多年,20多期基金中,平均每一期基金的回报总是有40倍左右,这说明它不是靠一两个人天才的眼光,而是有一整套系统的方法,保证投资的成功率。?其实就是哈夫曼编码的原理,即通过每一次双倍砸钱(double down),把最多的钱投入到最容易成功的项目上。
假定一期基金有1亿美元可以用来进行风险投资,怎样投资效果最好?还假设如果投资的公司最后能上市,将获得50倍的回报;如果上不了市,只是在下一轮融资被收购,将获得3~5倍的回报。在硅谷地
区,获得投资的公司最终能上市的概率大约是1%大家不要觉得这个比例低,它已经比世界其他地区,包括美国硅谷以外的地区和中国高很多了。至于被收购的概率,在硅谷地区大约是20比中国要高很多。我们列出三个做法:
1.平均地投入到100个初创公司。
2.利用我们的眼光投入到一家最可能的公司中。
3.利用哈夫曼编码原理投资。
如果使用第一种方法,基本上是拿到一个市场的平均回报,也就是一轮基金下来大约是31%到71%回报,如果扣除管理费和基金本身拿走的分红,出资人大约能得到20%-50%左右的回报。通常一期风险投资基金投资的时间是2~5年(持续的时间可以长达7~10年),这样年化回报大约是5%—20%间。这是硅谷风险投资的平均水平,大家不要觉得风险投资一定能挣钱,在中国,大部分风险投资基金是赔钱的,而在硅谷赔钱的基金的比例也高达40%。
第二种方法,只投一家,这其实是赌博,如果碰上这家公司上市,有50倍的回报,碰上被收购的有2~5倍的回报,但是绝大多数情况则血本无归。如果所有的基金都玩这样的赌博,虽然平均回报率和第一种情况相似,但是投资风险高达500%。
第三种方法是按照哈夫曼编码的原理,可以先把钱分成几部分逐步投入下去,每一次投资的公司呈指数减少,而金额倍增。具体操作方法如下:
第一轮,选择100家公司,每家投入25万美元,这样用掉2500万美元。
第二轮,假定有1/3的公司即33家表现较好,每家再投入75万美元左右,也用掉2500万美元。至于剩下了的2/3已经死掉或者不死不活的公司,千万不要救它们,更不要觉得便宜去抄底。
第三轮,假定1/10的公司,即10家表现较好,每家投入250万美元,再用掉2500万美元。
第四轮,假定3%公司,即3家表现较好,每家投入800万美元左右,用掉最后的2500万美元。
这样通常不会错失上市的那一家,而且还能投中很多被收购的企业。由于大部分资金集中到了最后能够被收购和上市的企业中,占股份的比例较高,这种投资的回报要远远高于前两种,大家可以估算一下,大约有3~10倍的回报。一个系统的方法和坚守纪律能够带来3~10倍的回报,而对于凯鹏华盈来讲,投资人的经验和人脉,带来的是剩下的那几倍回报。
公司管理:Google 和Facebook等公司的管理方法,内部其实是一个大风投,各个项目一开始都有获得资源(主要是人力和财力)的可能性。但是很快,通常是三个月到半年,类似的项目就要开始整合,资源开始集中到更有希望的项目上去。最后能够变成产品上市的,是少数项目,但是大量的资源投入在其中了。今天的华为养了一个拥有几万人的庞大的预研部门也是同样的道理。
8.编码的矢量化
关键词:维度/简化/平衡
简化的必要性:人类在进入到文明社会时,需要记录的信息越来越多,开始人类就通过动词和名词的组合来表达复杂的意思。但是新概念、新事物还是不断地涌现,人类只好造出更多的象形文字。信息越多,需要的编码越多,这是文明自然演变不可避免的过程。太多不同的编码(文字)出现后,就要对编码进行简化,否则大家就没法学习了。矢量化就是简化的原则之一。
1.信息的矢量化:
信息的矢量数字化原理(VQ):对编码进行简化法的过程,就是矢量化的过程。原理:将成千上万个彩色的形状,按照颜色和形状两个维度各四种情况,分到了16个格中。所有的图形,就被归为了16类。这便是矢量化的原理。常将信息投射到两个维度是不够的,根据应用场景会投射到多个维度中,这样的过程就被称为矢量化。
2.语言的演化,语言和文字是慢慢演化过来的,而不是人为利用信息论的编码原理刻意构造的,因此不可能只照顾易辨识和有效性,而不考虑人类接受它们的难度,以及演化的过程。相反,人们给计算机识别的单词,比如汇编语言的指令代号,基本上就是很的、等长的字母组合,因为那是完全利用编码原理人工设计的。
文字的演化,实际上就是这样一个矢量化的过程。第一步是抽象化。最初的文字和真实的物体非常相似,但是这些象形文字彼此之间缺乏共性是后面逐渐地,它们就被抽象化成一些直线或者弧线了。第二步以汉字为例来说明矢量化的过程。绝大多数汉字被映射到两个维度上,即一个表意的偏旁维度和一个示读音的发音维度。再往后,表达含义的偏旁已经和原来的图画不太像了。而这些偏旁就构成了文字的基本单元,而且慢慢固定下来了。以后有新的概念需要创作出新字时,使用那些基本单元即偏旁部首,重新组合就可以了。比 如 唐朝宗秦客为武 则天发明 了一个"瞾"字,意思是日月当空,献给武则天拍马屁。

拼音文字是如何矢量化的简化主要是围绕读音进行的。从复杂的楔形文字,索不达米亚人简化为几十个字母,这是一个巨大的进步,它使得人类学习读写变得很容易。再后来希腊人从腓尼基字母中总结成24个希腊字母,而罗马人又将它们变成22个拉丁字母。罗马人还在字母表中加入了x,代表所有那些无法表示的音和词,这既是英语里包含x的单词特别少的原因,也是后来人们用x表示未知数的原因。再后来拉丁文里的被拆成了i和j两个字母,v被拆成了u,V,W三个字母,最终就形成了今天英语的26个字母。拼音文字中,虽然没有表达意思的偏旁部首,但是有很多词根,前缀和后缀起到了表达意思的作用,也就是说这些语言实际上将表达信息的基本单元(单词)用一个词根、前缀、后缀这样三维的矢量表示了。
3.字体的矢量图:计算机中使用的字体有位图(bitmap)和矢量图两种。位图一经放大就会出现锯齿,而矢量图随便放大,都很清晰。它的原理是将字体的轮廓映射到一组曲线上。在显示(和打印)时,经过一系列的数学运算,恢复字体的形状。这一类字库不仅占用空间小,而且从理论上可以被无限地放大,笔划轮廓仍然能保持圆滑,非常美观
2.平衡信息的损失:如何平衡信息的便利性和完整性,是一门艺术。人在年轻的时候,总想两者兼而有之,学习了各种科学知识后,就知道这种事情在理论上就难办到。
无论是象形文字还是天然形成的拼音文字,都通过两到三个维度的矢量化兼顾了读音和达意的关系。但是,如果强制将中文拼音化,它将失去达意的功能,这不符合信息论的原则,因此做不下去。世界上人为想做的,但违背规律的事情,做起来总是困难重重。
矢量化在生活中也有应用,比如我们通过高考成绩录取大学生,或者通过身高选拔篮球运动员,其实就是利用矢量化的原理,只不过是将所有的人映射到了一维的空间中。这种做法给工作带来了极大的便利性,但是显然没有全面地考察每一个人,或者说有信息的损失。
在生活中其实也有很多矢量化的例子,它们让问题变得简单,但是会丢失信息,而平衡便利性和信息的完整性,就成为了艺术。
在信息论中,一个更有普遍意义的问题就是,矢量化会带来多大的信息损失,关于这一点,在信息论中有一套理论计算这种损失。而在工程中大家要做的事就是,如何平衡便利性和信息上的损失。
9.编码的冗余度
关键词:增加信息/双刃剑
冗余度概念:对信息的"密集"和"稀疏"程度进行描述。定义的:(信息的编码长度-一条信息的信息量)/信息的编码长度。信息量是按照信息嫡来计算。冗余是人理解和传播信息的需要。
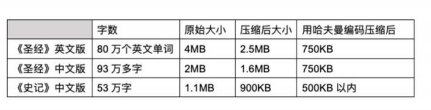
汉语是最简洁的语言:同样的信息采用不同的编码,信息量是不变的。通过压缩后对比,英语的压缩比高达3:1(2.5MB到750KB),而中文大约为2:1(1.6MB到750KB),也就是说中文更精炼。中文的信息比较"密集",相比之下,英文和其它欧洲语言)比较"稀疏"。中文的冗余度大约是1/2,英文的冗余度为2/3。
1.适当冗余来的三个好处:易理解、消歧义和容错性。
冗余为核心信息提供了解码基础,而这取决于客体已有信息的与主体信息的相关性。
语言中冗余度的第一个好处,也就是便于理解。提供信息的基础信息:比如我们对一篇经典的论文和一篇小说进行压缩,就会发现小说的冗余度要高得多,像沃森和克里克描述DNA双螺旋结构的论文,一共一页纸多一点,几乎每一个单词都不能漏掉,理解起来反而要花一点时间但也正是因为如此,小说才容易阅读。缺少基础信息,会严重影响理解信息的速度。
冗余度的第二个好处是,在语言学上它消除了很多歧义性。提供了辅助信息:汉语表达信息更需要结合上下文。汉语简洁的一个重要原因,是对比英语,汉语去掉了动词的各种时态、性别、单复数,和语气等信息,名词去掉了数量和阴阳信息,绝大部分名词去掉了正式和非正式的信息,所有这些信息都需要通过上下文来恢复,这其实就花工夫了,如果恢复得不好,在意思的理解上会略有差别,这就造成了误解。而在英语中,名词和动词数量的一致性,语句中语气和写法的一致性,都保证了相应的信息不容易漏掉。这都归功于它们的冗余度大,提高了信息局部的准确性。
冗余度的第三个好处是:带来信息的容错性(复原性)。文件丢失了一段,依然能够得到大部分内容,甚至能够通过前面或者后面的内容恢复出一部分丢失的内容。但是,如果把文件压缩成Zip格式,而压缩后的文件少了一点,完全无法恢复其中的内容。同样通过罗塞塔石碑能破解古埃及文字,也是因为冗余。石碑上刻有三种语言,言学家商博良根据石碑最下方的古希腊文字,破译出中间的世俗体古埃及文字。
2.信息冗余问题,一方面它造成信息存储和传输的浪费,另一方面它在有噪音的情况下,可能导致混淆。
首先是在存储和传递信息时的浪费。可以想象,如果存储的文件,编码的长度是信息量的好几倍,肯定是浪费。回浪费太多钱。文字的冗余度是在各种信息中非常低的。如果传输标准的4K电视,对于任何信息冗余,一点也不压缩,那你的网速需要每秒钟12Gbps,也就是采用光纤入户后峰值传输率的大约10倍,今天家庭使用的Wi-Fi的200倍左右。今天能收看4K电视,是因为通常这种视频图像的信息冗余度极高,压缩几十倍也不会损失任何信息,如果允许略微损失一点信息,则可以压缩上千倍。
息冗余的第二个问题是,如果在信息中混有噪音,过多没用的信息可能会导致错误。真实的世界里,很少有绝对干净的信息,它们总是混有噪音的,这些冗余的信息就可能彼此矛盾,信息完全不靠谱反而让大家糊涂。比如说,关于秦朝的末代秦王子婴是谁,《史记》里就有三种说法:秦二世胡亥的侄子(扶苏的儿子),秦二世的哥哥,秦始皇的弟弟即秦二世的叔叔)。
善用信息冗余沟通
1.讲东西时要通过加入一些看似是废话,但是实际上是从侧面诠释你的想法的句子,帮助对方理解你的意思。利用信息的冗余便于大家理解。
2.讲东西要有一致性,不要补充有可能和主要思想相矛盾的例子,或者和想法无关的冗余信息。
3.在我们脑子存储信息时,要进行压缩,这样脑子才记得住事情。很多人问我,你读那么多书,记那么多事情,怎么记得住的?其实我脑子的记忆力并不好,别人五分钟能背下来的英文单词,我15分钟也记不住。但是我无论读书,还是学习,都会做类似于写卡片的工作,也就是说,把这一本厚厚的书的内容,变成薄薄的几页纸的东西,那些冗余的信息,就删除掉了。我有时讲,读书要不求甚解。这不是说不读懂,而是说要读出主线,将一些细节过|滤掉。真到了需要寻找细节时,大不了回过头来再看看就好了。
10.信息等价性应用
关键词:周期性\ 正弦函数叠加\获取信息
一种原始的信息,它们虽然里面有很多冗余成分,但是很难直接压缩掉。但我们可以将它们转化为容易压缩的等价的信息,再进行压缩,然后进行存储和传输。在使用和接收到被压缩的等价信息后,我们先解压,再恢复回原来的信息。
价信息的重要性远不止信息压缩这件事情。它对于我们获取信息,乃至处理信息同样重要。善用等价信息,是我们这个年代每一个人都必须掌握的工作技巧。等价信息,面对错综复杂的信息时,如何利用其他信息的等价性为我们理清思路。
1.利用等价性压缩信息
利用等价性压缩信息原理:1.找到这种周期性信号的等价信息;2.对等价信息进行压缩;3.如果要使用原来的信号,通过压缩后的等价信息复原原来的信号。关键是找等价信息。
找等价信息——傅立叶变换。傅立叶变换:原有的信息和等价信息一 —对应的桥梁。傅立叶变换:周期性信号里面所包含的信息和若干正弦函数的频率、振幅信息完全等价。世界上所有的正弦波曲线形状都差不多,但是振动的幅度可大可小,振动的频率可高可低。正弦函数叠加:傅立叶发现所有的周期性信号都可以用频率和振幅不同的正弦函数叠加而成,也就是说周期性信号里面所包含的信息和若干正弦函数的频率、振幅信息完全等价,这种变换被称为傅立叶变换。
前提——周期性:傅立叶发现任何周期性的函数(信号)都等同于一些三角函数的线性组合。下面这张图,就是周期性函数的样子,也就是说它们的波形都是重复的。一般来讲,我们生活中的各种信号,都是随着时间变化的,比如一年中每一天的温度就是一个信号,它从每一年的第一天到第365天会有高有低地变化,如果我们把历史上全部温度的记录画成一条曲线,它大致就是上图那种周期性函数,一个周期就是一年。
信息压缩:利用周期性来进行信息压缩。如果我们要记录100年间每天的平均气温,就需要三万多个数据,这个数据量比较大。但是由于它具有周期性,我们就有可能利用这种周期性来进行信息压缩。
1.音频、图像和视频的压缩。
各种音频信号压缩,包括我们的语音、音乐等等,在较短的时间内,都有相对稳定的周期性,比如下图就是一段语音,你可以看出它有一定的周期性。利用傅立叶变换,可以对语音进行压缩编码,然后传输,这样可以将语音信息压缩10倍左右,当然这样可能会有很少的信息损失。比如用微信语音打电话,如果不进行信息压缩,可能要多用十倍的数据流量。
图像压缩——DCT。表面看上去不像是有周期性振动的波形啊。这其实只是我们在宏观上看一幅图,但是如果我们用放大镜把图放得特别大,看到的就是一个个像素,而且相邻的像素之间颜色和灰度的变化会是相对连续的。利用这个特性,人们发明了一种被称为"离散余弦变换"的数学工具,也称为DCT。DCT可以被认为是傅立叶变换的延伸,只不过它没有使用正弦波,而是采用了下面图中所示的64个基本灰度模板,任何照片都可以用这些模板组合而成。当然,对于彩色图片需要用带有红绿蓝三原色的彩色模板。这样一幅图片,就变成了一组数字,这些数字是模板中相应的模块的权重。我们经常使用的JPEG格式的图像,就是这么生成的。
2.Google信息处理:Google保存了互联网的所有的内容,只不过它在向大众服务时,把所有网页中的文字顺序打乱了,它按照每一个关键词在网页中出现的位置重新整理了互联网的内容。这样不仅方便查找,而且能够压缩信息,节省存储空间。你查找时,它不仅能够告诉你你要找的内容在哪里,还能够根据每一个词出现的位置,恢复出原来的网页展现给你。
获取信息
3.核磁共振就是利用了等价信息。人体各个部分各个部分氢原子振动的信息,就可以把人的结构画出来。
11.信息的增量编码
关键词:相关性\主干+微调\压缩\保守主义
相关性,其实是信息本身固有的特征。或者说,绝大多数时候,我们这个世界的变化是渐进的,而不是完全随机的。
1.增量编码与普通编码。
对这样一组数:3210, 3208,3206,3211, 3220,3212……·进行编码,需要多少比特(或者多少字节)呢?
普通编码:
首先数字毫无规律可言,不存在哪一个出现的概率更大,哪个更小的问题,因此无法利用哈夫曼编码的方法,将比较短的码分配给出现概率高的数字,只好将它们——编码。需要用12位2进制表示每一个数字。(2的11次方是 2048;2的12次方是 4095)。
增量编码:
其次各个数字剑动态范围不超过16,可以利用这个特性进行压缩编码。1.对第一个数字使用12比特的编码,我们没有办法做得更精简。2.对第二个以后的各个数字,我们将它和上一个数字相比较,发现它相比前一个数字,动态变化的范围在正负16以内。因此,我们只需要对差异(也被称为增量)进行增量编码,就可以了。不考虑符号的话,我们用4个比特就够了,因为log以2为底16的对数等于4,也就是2的4次方等于16。再加一个比特的信息表示符号,于是从第二个数字开始,我们采用5个比特就可以表示它和前一个数字的区别了。将上面一组数字做如下的编码:3210【-2】【-2】【5】【9】【-8]……除了第一个数字还需要12比特之外,剩下的只需要5个比特即可(4个比特表示变化范围的区间是16,1个比特表示加或者是减),相比原先每个数字12字节的编码,压缩比大约是2.4:1(12:5)。
2.利用前后位置的相关性进行压缩的思想。简单来说就是如果两个信息"长得很像",只要保留一个,对另一个,只要保留它们的差异,然后进行微调就行了
视频的压缩比要远比图片的高很多。通常会相差两个数量级,也就是说JPEG图片能压缩10 倍基本上也看不出损失,而MPEG视频能压缩近千倍,肉眼也分辨不出来是压缩过的。但不能利用用视频的压缩方式压缩图片。因为视频压缩时,利用了信息的相关性采用增量编码。单—图片中,不具有太多的相关性可以利用。对于视频的压缩,用的就是上述原理。我们知道一般的视频一秒钟有30帧,高清的是60帧,4K的是120帧(甚至240帧)。每一帧视频之间的差距其实极小。对第一帧视频(也被称为主帧)进行全画面编码,对于这一帧的压缩比,其实不会太高。对后面每一帧的视频,只要针对它们和上一帧的差异进行编码即可,这样除了主帧外,后面的每一帧的视频,其实编码的长度非常短,视频文件就显得比较小。
3.善用信息前后的相关性,对后面的信息做增量编码,达到大幅度压缩信息冗余的目的。
Google搜索所用的索引,其实也用到了前后相关性进行压缩。搜索引擎的索引是什么东西呢?它是把每一个单词在全部网页中出现的位置列出来。Google的做法是每一个网页只保存第一个单词的起始位置,剩下的单词是相对第一个单词的位置。比如"中国"出现在第50001,50008,50300等位置,"科学"出现在50009,50045等位置。比如某个网页起始的位置是50000。那么刚才我说出现"中国"这个词出现了三次,它的索引记录就的是50000,以及位移量1,8和300,"科学"这个词相应的一段索引,记录的是50000,和位移量9,45。这样就能有效压缩信息的长度。
搜索时,如果要找同时包含"中国"和"科学"的网页,只要看看它们是否有共同的网页起始位置即可,比如它们出现在了起始位置为50000的网页中。中国科学"(连起来的)这个词,除了保证它们在同一个网页中出现外,还要保证它们的位移量相差正好是1。
4.增量编码的弊端:
当我们把信息冗余都挤掉后,编码长度非常短时,容错的性能就会下降。你过去看影碟可能有这样的体会,当光盘被划了一道,它就经常跳盘,这就是因为视频的压缩是前后相关的,中间坏了一点,很多帧的视频就都看不了了。
为了防止这样编码造成的累积误差,也为了防止中间有一点点信息损失,后面的视频统统打不开,所以,每过若干帧,我们就要重新产生一个主帧,以免错误会传递太远
5.保守主义
"渐变"是我们这个世界的特征,保守主义的做法缺乏革命性,但从信息论的角度讲成本最低。所谓保守主义,其实就是坚持总体原则不变,不断作微调,达到渐进改变的目的。这样做,比每一次都推倒重来,或者干脆达不成一致,其实效率反而高,因为我们的世界在绝大多数时候都是渐变的。在绝大多数时候,我们不需要推倒重来,只需要对变化进行一些修补就好了。如果想一次完成巨大的突变,常常会因为牵扯的利益太多,最后总是搁浅,永远改不了,结果反而是不进步。
美国难以理解的现象:一个是美国的税法很复杂,每年报税是一个工作量很大的任务。利用增量进行修修补补的结果:每一个群体都有自己的利益,都想要尽可能让自己能够多免税,于是各方博弈,在原有的税法上不断修补。第二个现象是学区划分得犬牙交错。这也是为了平衡各方面利益不断修补的结果。
补充:
1.用前后信息的差异,计算出来的增量,在数学当中可以用"差分算子"的方法提取出来。
△y= y(N)-y(N-1)
2.集中趋势与离散趋势
把时间序列(Time Series)按三个角度进行解读:固定趋势、周期效应、随机扰动。
固定趋势是指序列有本来的上升趋势,比如说按线性上升或者下降;
周期效应就像是序列会一年四季按春-夏-秋-冬-春…周而复始出现;
假设我们不考虑固定趋势,只剩下随机扰动的影响,这时我会先计算出序列的平均值,然后把随机扰动项记为偏离均值的"残差"。举一个股票的例子,这只股票的平均价格是28元,扰动项是:0.05,0.03,-0.1,0.2,-0.09,0.05,…这里的28(平数,Mean)就是序列的集中趋势;而残差项(Residuals)就是原始信息的偏离程度一离散趋势。《时间序列分析》提醒过我们多次,真正有价值的信息,就藏在离散趋势当中。
12信息的压缩
压缩比和失真率:如何在信息取舍之间作平衡?
关键词:损失\目的\平衡
1.有损压缩
信息的有损和无损压缩。1.无损压缩,原先的信息能够完全复原,但是通常压缩比不会太高,因为它存在一个极限,香农第一定律给的信息嫡的极限(任何编码的长度都不会小于信息嫡)。傅里叶变换、离散余弦变换、哈夫曼编码进行压缩2.有损压缩,如果编码长度小于信息嫡,就会出现损失信息的现象。对于有损的压缩,信息复原后,会出现一定程度的失真。有损压缩最关键的是:要清楚如何保证因为压缩而丢失的信息不影响我们对信息的理解呢?这就需要平衡:压缩比和信息失真度之间的关系。今天对于音频、图像和视频的压缩,绝大多数情况都是有损的压缩,我们感受不到,这就说明压缩很好地考虑到了失真率。
2.压缩原理
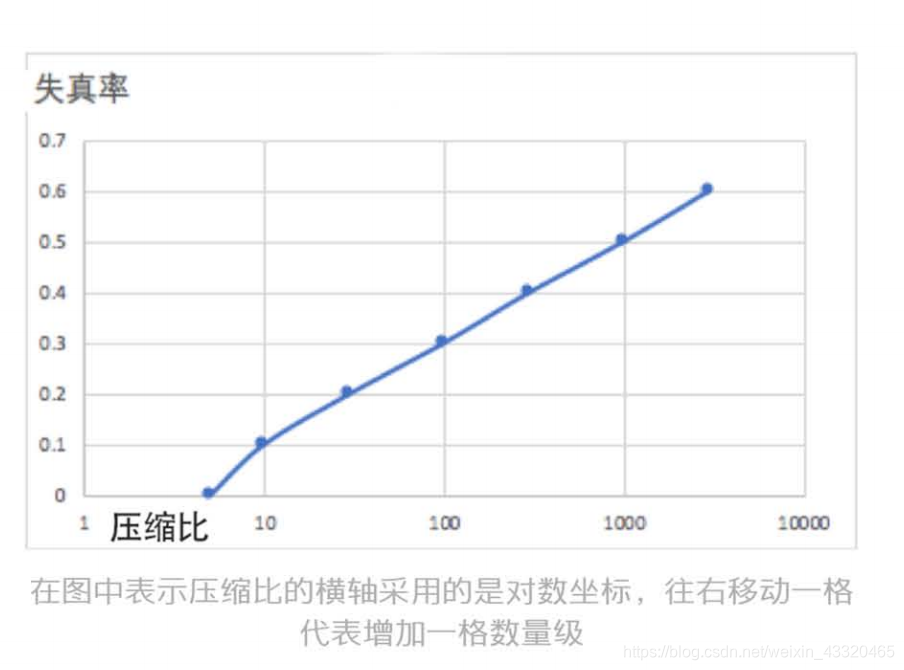
失真度,是压缩前、压缩后的两串信息的差的平方。失真率和压缩比直接相关,压缩比越 大,失真率越高。压缩比越高,信息越失真,还原信 息的难度越大。所以需要在压缩比和失真 率之间做平衡取舍。
第一个原则:明确压缩的目的。采用什么样的压缩方法,压缩到何种程度,通常要看具体的应用场景能接受失真度。场景不同,压缩比和压缩算法不同。语音通话时,牺牲一定的讲话人的口音,问题不大,因为它的目的是传递话音中的信息。声纹识别时,情况就正好相反, 那个人说了一句什么话不重要,重要的是说话者的信息。
第二个原则,用的信息少,永远不可能做得和原来一样好。最好的技术方案,在信息处理这个领域,常常不存在所谓的标准答案和最佳答案,只有针对某个场景的好的答案,而一切都是妥协的结果。至于如何平衡数据量和效果的关系,就看矛盾 的主要方面在哪一了。今天世界上最不缺的就是数据,在最近的三年 里,全世界产生的数据,比有文字以 来人类产生的数据的总和还多。在这种情况下,节省数据是一条错误的努力方向。
第三原则,任何与众不同的东西,总是先被压缩掉。任何与众不同的东西, 总是先被压缩掉,因为对那些与众不同的东西做编码占用的空间相对太多。人通常能够听到20赫兹到2万赫兹的声 音,但是人发音的范围只有300赫兹到4000赫 兹左右,因此任何高于4000赫兹的语音信号就被过滤掉。或者异常点(出 头鸟)。
3.原理拓展应用
信息压缩看似是信息处理专业的问题,但 是它的思想可以用到很多地方。我们有时强调要把知识学通,就是这个道理。
基因测序的储存。一个人以及他体内细菌的基因 都测序,储存要超过1PB的存 储空间,也就是1000个1T的硬盘。遗产压缩算法,利用基因之间的差异性压缩,可以节省1000倍的空间。
商业营销。人注意力和记忆力有限,会优先保存最重要的、相关的、有普适性、或者最感兴趣的信息,忽略不相关的、不重要的。 1.广告内容尽量精简,突出主题,但是不 能精简到识别不出品牌形象的地步;根据 消费者偏好,提供个性化服务,传递相关 的、对他们来说重要的信息内容,更容易|被接收。2.人们喜欢在混乱中寻找规律,以此减 少认知负担,所以企业可以帮助消费者进 |行模式识别,比如在广告内容中加入消费 者熟悉的元素,或者帮助他们理解事物的 运行规律和内在本质。
3.在不同场景下,信息的重要性可能会 有所不同,所以在决定压缩哪部分信息的 时候,需要考虑信息接收的时机和场合。 比如,消费者在网上搜索某件商品想要购 买的候,targeted ads上的价格折扣信 息也许更重要;而在消费者看电视娱乐消 遣的时候,广告内容的趣味性和独特性更 能让他们印象深刻;在发送电子邮件给顾 客的时候,跟个人相关的内容会让他们觉 得自己受到了关注,你知道我喜欢什么、 不喜欢什么,这对我来说很重要。
13信息的正交性
信息正交性:如何利用和组合信息,提高自己的决策水平
1.力学上,用力要在一个方向效果才好,在使用信息上,要选用彼此垂自的正交信息
2.正交信息的3个原则,和2 个做法。
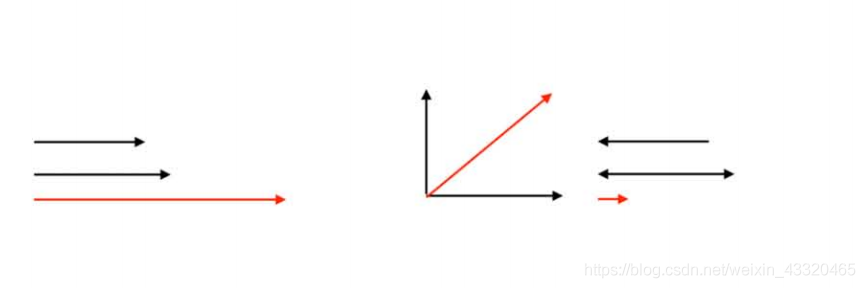
1.如何发挥信息叠加的力量?使用不同维度信息会有叠加效应。相同的信息使用两次,不会产生两倍的效果。
机械运动时,为了获得最大的加速度,用力 (或动量)的方向要一致,而在利用多种信息 并不难理解,因为相同的信息,它们在消除不确定性时,作用有重叠。但是很多人到了工作中就糊涂。比如同样的故事反复讲就没有那么吸引人。
什么时候不重叠呢?当信息是垂直的时时候,效果最好。信息编码时会简化到为空间中的矢量,也就是将不确定分解到了不同维度,也就是多维思考。但在使用信息时,如果利用了多个信息源的信息,大部分效果达不到每一种信息所产生效果的总和,因为它们在消除不确定性时,作用有重叠。实际工作中,绝大部分时候,如果每一种信 息可以减少1%错误,两种合在一起能够减 少1.2%不算失败,能够到1.5%就非常满意了。这也说明寻找正交的信息不容易。
第一个例子是语音识别:比如说汉语里大约有1260个左右的拼音读音, 对每个音节的识别就是1260选1的问题。要消 除这其中的不确定性,用到的最有效的信息是 两类,第一类是所谓语音的信息,也就是说每一个读音和各种语音之间的相关信息。 第二类是语言信息,也就是一种读音在上下文 中出现的可能性。这两种信息就是正交的。如果只采用语音信息,要进行语音识别的难度 相当于1000选1,如果同时采用了语言信息, 难度则下降到20选1。
第二个例子是名片的识别:是把纸质打印的名片扫描一下,储存成电子信息。它对准确率的要求极高,市面上大部分的软件识别率在98%左右,大家解决这个问题的思路比较单一,总是想着提高图像的识别率,虽然各种办法都想 了,但总是有些情况难以通过图像识别解决。2012年,一位华裔教授将名片识别的准确率提高到99.9%,怎么做的呢?说起来非常简单,就是把互联网上能找到的各个单位的信息找到,然后用 那些公开的信息验证纠正图像识别的结果。
2.怎么才能找到正交的信息呢?这和具体的应用场景有关,而且多少有点艺术的味道。但是依然有三个原则应该遵守,以免走弯路,另外有一个方法可以使用。
首先,不同的信息要来自不同的信息源,选用正交的信息进行交叉验证。比如在上述名片识别的例子中,图像信息和互联网上的信息,完全属于不同的来源。 比如医生给你看病,会让你做血项检查和医学 影像扫描,因为这两种也属于不同的信息来 源。如果做检查,你做了一遍X光透视,又做了一 遍CT扫描,最后还做了一次核磁共振,这三种信息基本上是一个维度的。核磁共振发现不了 的问题,前两种基本上也没有用。
第二个原则是,避免反复使用相互嵌套或者相 互包含的信息,即使信息来自不同的来源,因为那些信息即便不完全相同,但是可能一个覆盖了另一个,或者相似性太高。 很多人觉得他也注意了不同媒体的信息,而不 是只信一家之言,但是他忘记了今天很多媒体 的信息都是相互抄的,也就是说一种信息多次 使用而已。很多人申请工作,简历中提供的都是相互覆盖 的信息。比如最重要的两段工作经验本身已经 证明专业能力了,还罗列了一大堆无关紧要的 工作经历,以及可有可无的专业证书。这些对 |别人了解自己不会有更多的帮助。
最后一个原则,看问题要刻意改变一下观察的 角度,从几个不同的角度看。 下面这张图,你从前往后看是个正方形,从上 |往下看,则是一个圆。如果坚持只从一个角度 | 看这个物体,永远看不清楚全貌,因为它实际 上是一个圆柱。

在信息处理中常常有两个方法,一个是不断叠加,另一个是不 断删除。不断叠加,利用好手上的资源,有效排兵布阵。 我们假定有十种信息,需要选出三种,使其组合起来是最有效的。我们先对它们单独评估, 列出对于解决我们的问题的有效性,并且从大 到小排序,然后把排在第一位的作为基准。 第二步,是在第一种信息已经使用的基础上, 对剩下的九种重新评估,再重新排序,选出这 次排序最高的。 第三步类似于第二步。这样可以不断选择下 去。这种做法衡量的不是每一种信息单独的有效性,而是找到它们组合的有效性。 这就好比你是篮球教练,要打造一支好的球 队。你先选定控球后卫,然后选择一个和他配 合发挥最好的选手,再选第三个和前面已经选 定的人能够配合的人。 第二个方法是不断删除的方法,这和不断叠加 的方法类似,但是过程是逆向的。 但是不论是哪种方法,都有可能陷入一种局部 最佳值。而这件事其实至今也没有得到彻底的 解决,因此很多时候,成功有运气的成分。
14互信息:信息相关性
如何判断信息间的相关性和因果关系?
世界上大多数联系都是相关联系,而非因果联系。相关性是指它们之间只是一种动态的相互关联的关系,比如A发生后,B发生的可能性就增加。在大数据时代, 我们需要寻找的是强相关性,而相关的联系可以强,可以弱,我们需要寻找和利用的是强相关性。 互信息就是判断信息相关程度大小的工具
1.量化度量信息相关性的工具: 互信息。不相关的事情有时也会一同出现,但是只有互信息高的事情彼此才有较强的相关性。 而相关程度可以借助互信息的公式算出。
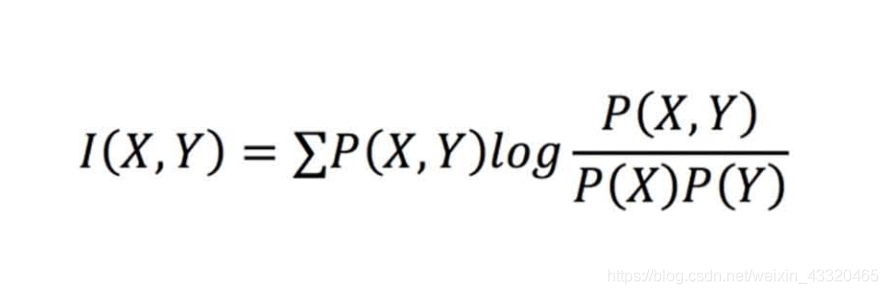
案例"牛市与裸露的大腿":假设裙子长度这个随机变量是 X,股市涨跌为Y,然后设定好时间等参数,带 入互信息的公式,女生的裙摆长度是随机变量,我 们假定为X。如果裙子的长度在膝盖处, X=0;如果高于膝盖一寸,X=1;高于两 寸,X=2;如果比膝盖长出一寸,X=-1; 长出两寸,X=-2,等等。 股市的涨跌幅度Y也是一个随机变量,我们假定涨1%=1;涨2%=2;如果 下跌,Y就是负的;如果不涨不跌,Y就是 0。如果我们把过去的100年以每一个月作 为一个单位,大约能得到1200个样点,这样就能估算出X和Y的概率分布P(X)和 P(Y)。如果女生穿短裙,而股票也上涨, 这两件事情同时发生了,它的概率就是 P(XY),被称为"这两个随机变量的联合概率分布"。假如裙摆比膝盖高一 寸的概率是10%股票某天上涨1%概率也是10%如果这两件事同时发生的概率是 0说明这两件事毫不相干,用上面的公式 计算,互信息就得到0。 反之如果这两件事情一同发生的概率有5%, 就说明它们高度相关。代入公式中算下来,它 们的互信息就非常大。经过计算,穿短裙这件事和股票上涨之间的互信息近乎为零。马尔基尔等不少人还用不同的 模型算过它们的互信息,得到的结论基本上 是"无法根据是否穿短裙来判断未来股票涨 跌"。
2.相关性和等价性的区别。以及不要在利用互信息时把两件强相关的事情之间的因果顺序颠倒了。
等价的信息之间有确定的因果关系,比如 从A一定能推导出B,那么知道了A就等同于知 道了B,它们是可以划等号的。但是世界上很多信息是无法直接衡量的,甚至 找不到完全等价的信息,只能依靠不同信息的 相关性猜测。大部分的信息之间未必有因果 系,它们之间只是相关性的关系,比如A发生后,B发生的可能性就增加。如果相关性比较强,我们在得到信息A之后, 就可以消除关于B的不确定性。但是,如果A和 B之间的相关性较弱,那种联系就没有意义。
案例:化石层序律":在不知道放射性同位素之前,人对地球年龄的估算就把岩石的时间与生物演化阶段联系起来。今天我们说到地质年代时会说诸如寒武纪、奥 陶纪、三叠纪等名词,那些词原本都是用来描 述古生物出现年代的名词。其实就是反映地质变 化和生物进化这两种相关信息的互信息,互信息有一个变化的范围,并不是非零即一的绝对度量。 它并不能确定因果关系,因此我们只能用它来 说A这件事发生后,B也同时发生的可能性的大 |小。 在众多的古生物门类中,有些门类特征显著, 而且只出现在一个地质时代,它们就可以作为 一个特定地质年代的标志,比如三叶虫,这种 化石就被科学家们称作"标准化石",也就是 它们的出现和相应的地质年代之间的互信息很 大。 但是,另一类古生物,比如舌形贝,从寒武纪 就已出现,今天依然在海洋中很常见。而且在 几亿年的时间跨度里,它们的形态和内部结 构,几乎没有显著变化,它们和地质年代的互 信息就非常小了。
使用互信息还要注意的一点就是不要把因果关系搞反了,很强的互信息总让人想到因果关系,但是谁是 因,谁是果,都要花点心思搞清楚。即使可以由A得到B,但是B未必能 够反过来确定A。
例如:"乌鸦叫,丧事到"事实上不是因为乌鸦来 了,所以人死了。而是人老了之后,特别是快 死的时候,会发出特殊的腐臭味,吸引来了嗅 觉非常灵敏的腐食动物乌鸦。很多以盖茨和扎克伯格退学创业的事情说事,鼓励大学生们退学,但事实却是,这两个人先是证明了自己初期的 创业已经成功了,然后才退学的。
3.如何找出事物之间更高的相关性呢?
信息论则是给我们一个科学方法,能够从整 体上估计那些看似无关的事件一同发生的可能 性到底有多大。专业人士做事情的方式 了,他们比业余的人普遍做得好,除了我在 《硅谷来信》中分析的发挥稳定,能够重复成 功等因素外,还一个原因就是他们有很多业余 人士没有的工具。
例如:在风险投资方面,正规的基金会有一些研究人员,研究具有哪一些特质的创业者成功的 可能性更大,第一次创业成功和第二次再成功 之间的互信息,以及受雇于某些大公司和创业 成功的互信息等等。 然后,他们会有意识地往特定的群体中进行投 资倾斜。而业余做天使投资的个人,常常只能 凭感觉作判断了。
在数据分析中,区分相关性和因果性是非常重要的。
15 新增信息的价值
条件嫡和信息增益:你提供的信息到底值多少钱
1.用条件嫡的概念,系统地、量化地分析一下,信息的价值。
2.我们给出了一个定量衡量每一条信息价值的尺度,就是信息增益。
3.我们用上述理论解释了为什么在一个研究领域最初的发明贡献,影响力最大。对于每个人,第一个发表意见,以及能够发表与众不同的意见,对提高自己的影响力至关重要。
1.条件熵
事件的不确定用X表示,在没有任何信息的情况下,信息熵就是X 的分布为 H(X)。条件嫡为在新条件Y下X概率分布的信息嫡,通常用 H(X|Y)表示被称,Y是条件,表示为H(X|Y) 。在信息论中可以证明,H(X|Y) 永远比H(X)小,或者相等,即H(XIY)≤ H(X)。等号成立的条件是Y纯粹与X无关。如果得到的是等价消息,X和Y是等价,它们的条件嫡瞬间降到了0。
案例:如果H(X|Y) 永远比H(X)小为什么大众已知的信息对投资和其它决策其实都没有意义。控制轮的自我调节有效解释这一点。
股市是一个非常不确定的地方,股市的涨跌是用X表示,在没有任何信息的情况下信息嫡为H(X),如果你获得了一种关于股市的独家信息Y,你得到的内部消息用 Y来表示,在你眼里,它的不确定性变成了H(X|Y)。由于H(X|Y)比 H(X)小,你获得信息Y之 后,股市在你那里的不确定性就降低了。你挣到钱的可能性大一点,但未必一定能挣到钱,它们未必构成因果关系。
由于市场的有效性,股价能够充分反映所有信息.比如说,你提前知道了苹果公司要回购100亿 美元的股票,按照19年4月股价可以算下来它的股票该增 长1.1%。也就是说苹果公司的股价会在一瞬间包含市场对回购股票那条信息的反应,苹果会在一瞬间上涨1.1%,这时你再使用那条信息作出购买苹果股票的决定,就挣不到钱了。
今天大家使用过的关于股市的各种技术指标分别是Y1,Y2,Y3,……·,YN, 有N种。 股市的不确定性其实已经不再是H(X) |了,而是在这些信息条件下的H(X(Y1,Y2,Y3,……,YN),也就是在Y1,Y2,Y3, ……,一直到YN所有信息都使用后的条件嫡。 这时,你再将其中的某个指数,比如Y5重复使 用,不会得到任何更好的结果。除非你有幸发现了一种新的和股市变化有关的信息,我们假设是YM,它不在Y1, Y2,……,YN中,那么恭喜你,你有可能挣到钱。
假设裙摆指数多少有点道理,那么利用它是否能够帮助炒股的 回报多哪怕是一点点?由于这个"裙摆指数"假说已经存在了 上百年,大家早就知道了,即使再有道理,一个人尽皆知的消息也没有用。不妨假定这也就是我常 说的,靠画K线炒股挣不到钱的原因,因为它 不过是众人所知的某个Y。事实上,专业投资 人没有靠画K线投资的,真正能够通过投资股票挣 钱的人,是不会告诉你所谓投资秘诀的。而在 电视上开讲座讲投资的,反而是自己挣不到钱 的。
2.信息增益 (Information Gain,简称IG)
事件的不确定用X表示,信息熵就是X 的分布为 H(X)。在新条件Y1信息熵表示为H(X|Y1) 。H(X|Y1) 永远比H(X)小,那么Y1所带来的信息增益就是H(X)- H(XIY1),我们写作IG(Y1)。事实上具体到这个特殊的情况,IG就是X和Y之间的互信息,这个值越大,说明消除的不确定 性越大,X和Y越具有相关性。假设后面还有N种不同的信息,从数学上看,它们带来的信息增益,每一个都是在原来 所有信息基础上递减的。通常,人们总是率先发现和所要解决问题互信息最大的信息,也就是增益最大的信息,因此 通常来讲,越往后发现的信息,带来的增益越 小。
案例:为什么反对年轻人花精力去找所谓的别 人没有发现的和股市相关的信息,包括反对专 业人士这么做。为什么呢?
因为最有效的信息已经被发现了,剩下来留给大家的微乎其微。世界上的股市已经被人研究了几百年,各 种直观的能够预测股市的有用信号已经被挖掘 殆尽。 有了计算机之后,一些专业的在对冲基金里建造数学模型的人,利用计算机把几乎所有的已 知信息都试验了一遍,如果有用他们就保留了 下来,于是很快股市就反映了那些信息使用后 的情况,也就是所谓的被price in了。
真的有幸找到一个大家都遗漏的信号, 那么还要确定两件事,才能知道它有没有用。1.这个信号不要和其它已经采用过的信号重 复,或者相互覆盖。 2. 这个信号带来的结果要有足够高的置信 度,也就是说,如果它让你的收益平均高出1%收益浮动的区间要远远小于1%, 否则浮动区间高达10%那就一点意义没 有了。如果把这两个条件再一限制,你就知道在股市 上系统性地捡漏近乎不可能。好,这就是从信 息论中信息增益的概念出发,我为什么不支持 年轻人去研究所谓的炒股秘笈。
3.案例:学术界,大家评估一个人的科研水平,主要 是他所发表的论文的两个指标,一个是引用的数量,另一个是所登载期刊的影响因子。 利用信息增益的概念,衡量一条信息的价值、一项研究发现的贡献。
一条信息的价值,它取决于这条信息对 未知系统所带来的信息增益。两条信息,先出现的,价值更大,第二条价值就小。一开始的时候,大家一无所知,提供 巨大的信息增益容易,后来则是在增益上补充 而已。 在数学上可以证明这一点。
影响因子是整个期刊一段时间内发表的所有论 文的引用数总和(不是直接计算的,来自不同 期刊的引用会有不同的加权)除以论文数,也 是引用数量的间接度量。 因此,论文的重要性几乎就等于引用数,而引 用数几乎无一例外地和信息增量相关。
最初的几篇论文你说出一个别人不知道的事情时,就会被大 量引用,很快就成了学术权威。即便绝对水平不是最高,但是 通常提供的信息增益最大,因此影响力也最 大。越往后,结果总是做别人已经解决得差不多的课题,做得再好,没有人引用。 信息增益就越来越少,影响力自然就少。在学术界也没有影响力
如果两条信息相互正交,那第二条信息依然像过去那样有价值,因为已经提供的信息都不相关的。很多人喜欢发表与众不同的意见,其实是有道 理的,因为标新立异的观点,才有可能提供之 前大家不了解的信息,当然那些观点本身需要有证据支持,符合逻辑。
16信息的可靠程度
只有被重复检验足 够多次之后,置信度才高, 这样的经验才可靠
置信度Confidence Leve:衡量一个信息的可靠程度。通过一个样点给出的数据,完全没 有置信度可言,也就是说那一条信息的可靠性 可以忽略不计。
例如:你扔了14 次的钢铺,有8次正面朝上,6次背面朝上,我们是否敢说这个"钢铺铸造有 偏差"呢?。有两种可能,其一是偏差确实存在。另 一个原因是,它就是偶然造成的。前者的可能性是57%后者是43%,也就是说,钢铺铸造有偏差这件事有可能是真的,但是我们不太确定。我们把自 己有多么确定这件事也量化地衡量一下,它就是置信度。具体到这个问题,置信度是57%当然相反的 结论"这个钢铺没有铸造问题"的置信度是 43%在统计上,我们一般认为,置信度不到 95%结论不大能相信
那么置信度要达到什么水平才算是可靠呢?在 工程上,包括在药物试验上,通常要求达到 95%上。衡量置信度的方法:“T测试”(也叫T检验)的方法。判断某种偏差的可能性大小,其一是偏差确实存在。另 一个原因是,它就是偶然造成的。统计上,我们一般认为,置信度不到 95%结论不大能相信。
怎么才能够提高置信度呢?通常的办法就 是要增加所统计的样本的数量。 量重复的事情发生背后常常有它固有的规 律。比如,常压下的水到了零摄氏度就要结 冰,这种事情很容易验证。
具体到上面的问题,如果一直保持8:6这个正反面的比例,我们扔得次数越多,最后就越有把握说,“钢铺两面不均匀”。根据T-测试原理的计算公式可以得 知,大概扔140次就能说置信度达到95%。 当然如果扔到几千次,我们的置信度就能达到 99%也就是说,扔了140次以后,我们有 95%把握说,这个钢铺两面不匀,它造成了 80:60的偏差。而运气的因素,只占剩下的 5%。
人们在对待信息时通常犯的一个错误,就是忽 视它的置信度,以至于我们把完全随机的事 情,当成必然的事情。世界上有很多道理其实都很难验证,大到历史 事件,由于很难多次重复,总结经验其实是非 常难的。
几乎每一件历史上 的事件,社会学上和经济学上的事情都是如此,甚至很多医学上的奇迹也是如此。虽然人们总能找到合理的解释,用一种理论证 实很多事情,但是换一种理论也能做到这一 点。因此,严肃的学者们才感到证伪比证实更 重要。
比如在投资的 回报方面,基金经理A声称比竞争对手B高 1是否能说明基金A就比基金B好呢? |我们假如以一个月为一个单位统计一次,按照 通常股市的波动幅度,需要1000个样点,也就 是需要大约100年的数据。 这个要求今天没有基金能达到,也就是说那些 声称10年平均回报略好于大盘的基金,其实都 在夸大其词,因为那一点差异根本不具有很高 的置信度。
比如某些企业的成功经验,其实都是事后总结 出的一套自圆其说的理论,让它们稍微换一个 环境甚至不换环境再来一遍,都很难获得同样 的成功。 小到个人,做成一件事也有很多偶然的因素, 下一次同样的方法是否可行,也要看情况而 定。 在《见识》一书中谈到了命运的作用,很多 时候我们不得不承认这一点,一定不能去总结 那些根本不存在的经验,或者用更科学的话 讲,就是别相信置信度不高的信息。
17错误信息的代价
如果使用置信度不高的经验或者信息指导行动 会有什么样的结果呢?
叉嫡——如何避免制订出与事实 相反的计划?
我们就从理论上分析一下误判的代价函 数,以防我们万一作出了误判,满盘皆输。同样是误判,德国人在诺曼底的损失要比赵括长平之战小很多。 这一方面是损失的绝对信息量有所不同,另一 方面是因为误判的方向所导致的代价函数差异 巨大。
代价函数被称为库尔贝勒交叉嫡 (K-L divergence也叫KL散度)。
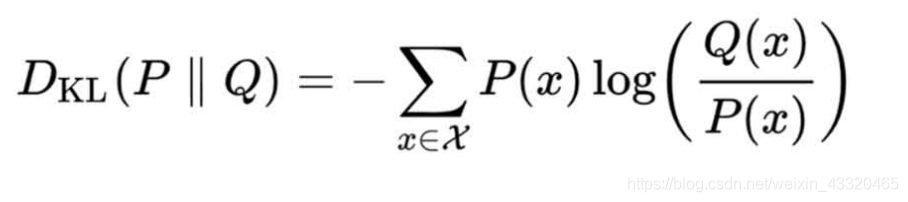
库尔贝勒交叉嫡的思想是这样 : 我们用X代表一个随机事件,它的各种可能性的概率分布用P(X)表示, 猜的结果是Q(X),通常Q(X)不会正好等 于P(X)。
1.比如说盟军登陆地点的真实可能性是,诺曼底 =0.7,加莱=0.3,P(X)=(0.7,0.3)。 如果登陆地点的可能性有5个,我们就写成 (0.5,0.2,0.1,0.05,0.15),分别表示这五 个地点的可能性,总之这些概率的和都是1。 假设想的结果是Q(X)=(0.3,0.7)。 信息偏差的推导: 代价函数KL= 诺曼底登陆的真实概率x log(诺曼底登陆的真实概率/诺曼底登陆 的预测概率)+ 加莱登陆的真实概率x log(加莱登陆的真实概率/加莱登陆的预 测概率) 注意公式前有负号,所以分子分母互为倒 数。代价函数值= 0.49比特。如果说Q(X)的数值恰 好也是(0.8,0.2),那么代价函数值=O比特,也就是说当你预测 的概率分布和真实情况完全一致时,损失是零。
2.硬性的决定就是将一些可能性设成零。接下来我们看第三个例子,赵括对秦军主帅的 估计。我们假定秦军主帅是白起和王龁的概率分布是 0.95和0.05,假定赵括的猜测是0.05和 0.95,正好反过来,那么根据上面的公式,计 算出的代价函数值=3.8,这可比德国人的损失 大多了。要知道信息的度量是个对数函数,差 出1,实际上就差了2倍出去。 当然,在长平之战中赵括的赌性更大,他完全 压宝秦国的统帅是王龁,也就是说,他的估计 是:王龁当主帅的概率为100也就是1,白 起的概率为0。 这时赵括错误的代价又是多少呢?代入上面的 公式,有一项是用0.95除以O,是无穷大。没 错,如果孤注一掷,又猜错了的话就是这个结 果!这也就是赵括的悲剧所在。
代价函数有什么用呢?库尔贝勒交叉嫡的理论和上面三个实际的例 子可以有下面五个更深入的思考。
1.猜测和真实情况完全一致,你不损 失任何东西,但是只要猜测和真实情况不一 致,就会或多或少有损失。
2.猜测和真实情况相差越大,损失越大。 特别是原来以为的小概率事件和容易遗漏很多原本应该考虑的 事情,损失最大,那些就是所谓的黑天鹅事件。
备选方案通常是针对小概率事件 的,但是对于小概率事件,我们也要分配资 源。在战 争中,一方常常想方设法把它的真实意图隐藏 得非常深。因此《孙子兵法》就讲,“夫未战而庙算胜 者,得算多也;未战而庙算不胜者,得算少 也。多 算胜,少算不胜,而 况 于无 算 乎!”(《孙子兵法·计篇》)。
赵括如此,后来的马谩也是如此。 我在《Google方法论》中介绍过英国名将惠灵 顿公爵,他在滑铁卢战役中打败了拿破仑,惠 灵顿自知自己在军事上比不过拿破仑,甚至比 不过当时很多人,因此他每次战役之前就做足 准备。 到了近代,大家即使没有学过信息论,已经懂 得要作万无一失的防范。因此像德国在防范盟 军登陆时,虽然押宝押错了,但是不至于像赵 括那样满盘皆输。
4.过分防范各种情况,患得患失,有损失。
为了计算简单起见,我们假设赵国主帅将四个 人的概率都设为了1/4。根据前面的公式计算,这时的代价函数值=1.73,比赵括的猜测 损失小不少,但是也不算太小。因此,如果没 有什么根据随意猜测,其实成本是很高的。
5.在信息论中,任 何硬性的决定(hard decision)都要损失信息。
损失可能是巨大的,而且是补不回来的。 今天做人工智能的人都有这样一个经验,在走 到最后一步之前,最好多保留一些可能性,哪 怕将那些可能性的权重设得非常低,而不要很 早就硬性地作决定,因为在硬性决定后失去的 信息是永远也补不回来的。
我在谈到教育时,常常讲在本科以前,要进行 通识教育,不要在一棵树上吊死,就是要避免 过早开始硬性决定。我常常提倡变色龙精神, 也是要避免一旦押宝押错了得到不可逆转的灾 难。 当然,对于那些可能性不大的事情,在有所防 范的同时,不要均匀分配力量,因为这种做法 |成本也很高,我们在上一条已经分析了。 至于该分配多少资源给那些虽然没有发生,却 不能排除可能性的事情
这次新型肺炎这之中各个企业
18第一模块信息的产生复盘
误导人的信息都有哪些特征呢?三大特征,
1.耸人听闻刻意要引起你注意。
这样的信息提供的信息量最大。特别小心所谓的"新知"。比如说:a.昨日股市暴跌了1%; b.美国政府对互联网公司动手,Google、 Facebook和亚马逊一天蒸发10000亿元的财 富;
如何判断耸人听闻信息的价值?
A.放在更大的时空中考量。
因为更大的时空提供了基本的信息量,而最近的消息,某一篇报道,某一个人的观点,某一本书的内 容,就算信息准确,提供的也只是增量信息。 这有点像图像压缩中的主帧和随后作为增量每 一帧的关系。 相比主帧,后面的信息量是很小的。就以美国股市为例,跌掉1大约会蒸发几千亿美元 的市值,这看似不小,但是1%跌幅是常有 的事情。2008—2009年金融危机期间,一天 跌掉10%情况也有。也就是说,很多信息需 要放回到更大的时空背景下考量,才能确定它 们真正的意义。
b.查看信息的一致性。
如:标题和内容不、表述方式。一致性是信息 本来的特征,但是人为地加入了很多虚假信息 后,就不一致了,标题党便是如此。 报道的标题玩了两个猫腻,首先它 把这三家公司的市值由美元转化成了人民币。
c.信息的失真率。 误导人的信息,它们把背景的 低频信号过滤掉,保留个别高频信号,这就如 同一张图片中蓝天上有一只鸟,那些人把背景 的风景都过滤掉了,把那只鸟刻意留下来。然 后他们刻意染——整个风景就是一只鸟,这 样的信息过滤后,失真率是极高的。
2.误导信息是没有出处。
没有出处,或者只有一个无法验证的出处,几乎所有的和阴谋论相关的信息都有这个特点。通常一个被上百家媒体报道的消息,溯源之后,来源通常不会超过5个,如果没有官方的报道,或者专业的媒体采访,可信度通常都比较差。对于不能溯源的信息,最简单的办法就是看同行评议
3.缺乏上下文。
信息要不断更新,因为很多是在变化的。
你如果看到一条报道,说俄罗斯是全世界最大的产油国,你信不信呢?这个说法不完全算错, 但是忽略了一个事实,就是时间维度。在历史 上它的确曾经是最大的产油国,但是现在不 是。 很多人为了证实俄罗斯的 强大,常常喜欢拿这个历史数据说事。事实 上,今天它不仅产量低于沙特,更低于美国。 而在人们印象中的石油进
5个原则总结
1.最好、最重要的资源要用于那些出现最频 繁的事情,这样分配资源最有效,其背后 的原理是香农第一定律和霍夫曼编码。
2.不要将相关性当成因果关系。弱相关性对 我们做事情没什么帮助,而对于强相关 性,要搞清楚谁可能是因,谁可能是果, 切忌因果倒置。
3.我们很多时候,要直接获得某种信息是很 困难的,因此可以通过获得等价信息,得 到同样的效果。
4.我们日常遇到的大部分事情,都是渐变 的,因此通过增量改进,要比推倒重来效 率高,这就如同对增量压缩,可以比静态压缩高很多一样
5.信息很多,一个比较高效率表示信息的方法是矢量化,也就是将很 多维度的信息映射到我们关心的几个维 度。我们用到的例子是:文字的演变就是 矢量化的结果。
概念
1.信息嫡,它说明信息量和不确定性的关 系。
2.冗余度,任何信息中都有冗余,去除冗余 是今天信息处理的一项重要工作,但是, 有时冗余又有它的好处,它可以避免出错。
3.不同信息的正交性:我们常常说的互补, 其实就是某种意义上的信息正交。同一种 信息用好几遍,效果不如使用两种正交的 信息。不仅信息如此,打造一个团队也是 如此。
19
历史真相有大势,无细节
很多细节,今天其实不清楚,比如为什么 赵国决定换将,赵国到底被坑杀多少人,等 等。对此今天至少有四五种非常合情合理,但 是却完全不同的解释,但那些都不能说是真 相。事实上由于古代信息在传递的过程中,混 入了大量的噪音,因此很多细节真相今天是无 法得知的
。著名的超现实主义画家达利画 的"林肯"。那里细节和林肯 没有什么关系,但是你远远地看它还是能看出 |林肯的轮廓
什么是噪音。
有信号必有噪音。在现实中信息和噪音的是一对孪生子,总是相伴存在的,就像真空等概念一样不存在绝对无噪音的信息。
在信息论中,它有下面三个特点:
1.未知,而且通常是随机的,也就是说难以 预测。我们在生活中有这样的经验,如果 你在房间里和别人谈话,有背景音乐让你 觉得谈话听不清,你关了音乐即可,很确定。但是对于那些不知道来源,或者你关 不掉的嗡嗡声,你就很烦。
2.不含有用信息。比如你在咖啡厅和朋友聊 天,有一些轻柔的背景音乐,不影响你们 |的谈话,还让你觉得增加了两个人接近 程度,但是从信息论的角度讲它也是噪 音,因为它其实影响到你们的语音通信。 但是,如果你们在谈话,后面有两个人在 悄悄议论你,被你无意间听到了,这时虽 然它影响了你和朋友的说话,但对你来讲 不仅不是噪音,甚至是很重要的信息。
3.噪音和信息不是绝对的,要看场景。你开 车时发动机的声音就是噪音,但是在检查 汽车工作状态时,那种嗡嗡声可能就是信 息了。
我们要想准确获得信息,信息本身的幅度(也就是能量)相比噪音需要足够高。也就是说,信号(能 量)和噪音(能量)的比例,决定了我们是否 能够有效地获取信息。这个比例在信息论上被称为信噪比。用信噪比来度量和还原信息。 当信噪比非常低的时候,我们是无 法从噪音中分离出信息的。因此很多时候我们 要通过过滤噪音,提高信噪比。
只要存在噪音置信度一定会受到影响。
信号的能量和噪音的能量会存在叠加, 因此具体到每一个信号点,它的准确性,或者 说置信度,都是严重受到干扰的。例如:下面两张图是相同的语音,前面的一张是比较 |干净的,后面的一张是被噪音覆盖了的。你如 果看细节,它们相差很大,但是你看整体的轮 廓,还是能找到相似性的。事实上,如果你播 放这两段语音,还是能够听出是同一个意思 的。

信噪比要多高,获取的信息才准确呢?
信噪比,在不同程度上能够恢复一定的信息。当总信息量非常非常大时, 即使单个信息的置信度不是很高,我们还是能 够在信噪比允许的范围内,恢复出不少信息 的。信号和噪音的比例达到一个什么程度, 就能恢复出有用的信息来呢?这件事没有一个 绝对的阈值,因为信息有用这件事本生就是根据真实情况而定。
比如:历史真相有大势,无细节。历史在传承的过程中混入了大量无关的信息,也就是噪音。只要历史的信噪比足够高,就能还原出历史的大脉络。历史的很多细节是不准确 的,而且也无法准确,因为历史书上记录的内 容犹如第二幅图中的语音,信号是被噪音所覆 盖的。但是,历史的轮廓还是可以看清楚的。
在噪音中处理信息的能力非常重要。
因为原始的信噪比往往不是我们能控制的。而信息和噪音的是一对孪生子,总是相伴存在的。 虽然我们在处理信息时总希望没有噪音,但是 这就如同我们希望找到全是优点没有缺点的人 一样,是不可能的。因此获取信息的准确性:取决于接收者捕获和处理信息的能力。
因此在噪音中处理信息的能力非常重要。考察和判断一个人是否有处理问题的能力,不是考察他在纯粹无噪音的条件下的能 力,而是要考察他能否在有噪音的情况下,依 然把信息找出来,处理好。有的人爱轻信,结果经常把噪音当成有用信 息,免不了作出错误的判断;有些人则完全相 反,只要有噪音就不信,这两个极端其实都是噪音处理能力不足的人,也就是缺乏处理问题的能力。
比如:
有的人耳朵非常好,信噪比比较低的讲话都能听清楚,但是有些人你就要冲他们大声吼。专业的音频处理设备和智能摄像头等电子设备,它们接受信息的能力远高于人类,能够处理信噪比比较低的图像信息, 而我们人类做不到。
冗余和噪音的区别
冗余度讲的是两件事:一是因为信息编码无 效,导致信息的(编码)长度超过了信息量。第二件事是重复信息,比如把一句话说了三 遍。无论是哪一种,信息显得很长,但是都是 准确的。
音则是另一回事,它在信息中夹杂了与信息 无关的东西。比如一篇报纸出现了一些错别 字,这就是噪音。
聋子:
我们选择关闭某一方面的消息,那么就是彻底成为了这方面的聋子,彻底接受不到消息,任何信息都会被当作噪音掠过。比如说:潮鞋、出海电商流行于我的创业时代我浑然不知。
积累的价值:
为了相同的目的,听到相同的消息,我们之所以有不同的反应。正是因为我们在这方面的相关信息积累不够,接受到的信息只是一个孤独,一滴水,无法拼接的信息,处理信息后得出的结论极其有限或者正确性有巨大的偏差。
脑机接口&处理信息的能力
处理更多的信息是人类发展的趋势。而脑机接口注定是昙花一现,这是人类的愿望提高自身信息的处理能力,但是人体硬件本身的局限,会是处理能力的上限。
数据分析:
噪音中得出信息时是数据分析核心。如何对待噪音的是能力之一,比如:处理脏数据的程度、速度。处理脏数据的程度取决于:判别脏数据的能力、信息的积累。速度取决于技术。
20如何去除噪音
当信噪比非常低的时候,我们是无 法从噪音中分离出信息的。因此很多时候我们 要通过过滤噪音,提高信噪比。
噪音产生的原因以及表现形式:
1.能够找到噪音来源的 Vs 不清楚来源的。
比如说开车时汽车马达的声音,就是已知来源 的噪音,而你打电话时,觉得对方的声音不清 楚,有噪音,那些噪音常常原因不明,或者说 来源太多,讲不清楚。
去除知道来源的噪音,最简单的方法就是屏蔽 它们,比如把汽车里面的隔音做好,车厢内就 会显得很安静。如果你坐过直升机,就会发现它的发动机和螺旋桨的噪音巨大,任何隔音材 |料都不可能把舱内的噪音降到你能听清楚说话 的程度,因此坐直升机大家都是戴耳罩,用麦 克风讲话。
还有很多时候你即使知道了噪音的来源,也有方法消除它们,但是无法实施。比如晚上10点 钟楼下一群跳广场舞的,搞出很大动静,但是 你显然没有本事让他们不跳,甚至没有本事让 他们降低噪音。这种时候就要采用我们后面提 到的方式降噪了。 至于来源不清楚的噪音,去除时,常常比清楚 噪音的来源要更困难。
2.有规律的噪音 vs 随机的噪音,固定频率的 噪音 VS 白噪音。
汽车的马达声其实是有规律的噪音,它的频率 比较固定。集市上的就是随机噪音了。显然前|一种比后一种好去除。 有些噪音频率比较固定,比如鸟叫,这很容易 从背景中去除但是如果是各种频率都有的噪 音,也就是白噪音,那就很难去除了。
了解了噪音的分类,我们就来谈谈利用计算机如何去除噪音的。
1.从信号源入手,通过信息的冗余和比对,过滤噪音。如果我们受到来源已知、规律性比较强的噪音 的干扰, 只从一个信息源了解信息,你其实很难 判断所获得的是噪音还是信号。如果你从多个 信息源了解信息,虽然它们各自都有噪音,但 是由于报道的角度不同,很多噪音彼此可以抵 消掉,获得的则是信噪比很高的信息。
,比如汽车发动机的声音,很容易去 除。比如在汽车中进行语音识别时,当麦克风 接收到人说话的声音后,在进行信号处理之 前,会先减去马达的声音。 这件事很容易做,增加一个专门接收发动机噪 音的麦克风即可。事实上在汽车里,哪怕发动 机的噪音能量极高,完全淹没了我们说话的声 音,人可能听不清,但是计算机识别起来并不 难。
类似的,如果一个领导在大会场作报告,在不 同角度安装几个麦克风即可(它们通常也被称 为麦克风阵列),通过对比几个麦克风收到的 语音,就可以判断哪些是信号,哪些是噪音。 这种方法,从本质上讲,利用了信息的冗余 度,也就是说,利用多余的信息,减少误差。
对于知道来源,但是没有规律性的噪音,处理 起来难度加大了不少。通常解决方案会和应用 场景有关。比如在卡拉OK厅使用的麦克风,对 距离非常敏感,这样不会将几米以外喝酒划拳 的声音收进去。
2.从分析维度出发,将有噪音的信息分解到不同的维度过 滤噪音。 在一个维度分不开的两件事,换个角度看就分 得清清楚楚了。比如下面这张图,从正面看蓝色的长方体和红色的椭球重叠了,分不开,但 是从侧面看,它们之间的距离其实很大。
两个维度叠加上比较,就很容易区分大小。将声音从能量的高低,利用傅里叶变换 投射到频率的维 度后,可以将所有的音频信号变成频率信号,鸟的叫声在特定的频率上,只要将那个频率的信号过滤掉就可以了。 音乐会现场录音时,会通过这种办法把类似咳嗽声处理干净。如果照相机的感光器上有了灰 尘,Photoshop也会用类似的方法进行过滤。
不过,如果噪音分布在各个频率,也就是所谓的白噪音,这一招就不灵了,香农证实噪音分布在各个频率,任何算法都无法过滤掉。但这有一个前提,就是对方不可能知道你产生白噪音的算法,否则他们可以复制这种白噪音, 然后从信号噪音相混的信息中将噪音滤除。 香农也就是在这个课题的基础上,发展起来了 信息论。因此信息论的出现,在一定程度上要 感谢噪音。
当然,很噪音存在于各种信号中,不仅仅在通信中 才会遇到,比如说历史上的记录,就混杂了很 多的噪音,而我们平时听到的消息,常常也是 如此。 有意思的是,生活中的噪音和通信中的一样, 有些能找到源头,有些则不能,有些能找到规 律,有些则没有。于是,过滤信息中的噪音最简单有效的方法,其实也不外乎上面两种。
最可贵的意见不是所谓客观的,而是真正反映自己想法的 主观的意见。过信息的冗余和比对,过滤噪音。因为那种看似唯一客观的理论, 其实是有偏差的,当一个企业,只有领导一个人的意见时,那些原本不大的噪音就被放大, 以至于会淹没信号。 相反,如果每一个人都把自己主观的意见说出 来,虽然每一个人有偏见,也就是说噪音,但 是合在一起我们就得到了大众想法的轮廓。
将有噪音的信息分解到不同的维度过 滤噪音,这个方法可以怎么用呢? 比如,中国人常常很纠结一个问题,就是老婆 和妈妈掉到水里后先救谁。这个问题两难的重 要原因在于,要考虑的因素太多,以至于大家 越想越糊涂。其实在这个问题上解套并非难 事,关键是分清楚什么是我们该考虑的信息, 什么是噪音,或者说你最看重哪方面。
21 信道容量C
信道:传输信息的通道,没有信道,信息就传输不了。从声带到空气到耳蜗,就形成一个真实的信道。你用手机进行无 线通信,虽然你看不见信道,它也是真实存在 的。
信道的容量C:香农给出了对于信道的量化度量,当信息传输所用的信道一旦固定,能承载的信息量是有限 。信息的传播是有成本的,其 成本就源于信道的容量。类似高速公路的宽度 ,有时我们直接使用"带宽"这个词 来描述它。被称 为信道的容量,。
语音通话所需要的信道的宽度:
人讲话的频率通常在300~3400赫兹 (Hz)之间,也就是说我们声音的音频一秒钟 振动300~3400次。振动300次的是低音,振 动3400次的是高音。任何周 期性信号,都可以变成很多不同频率正弦波 (或者余弦波)的叠加,人讲话的语音,等价成从 300赫兹、301赫兹、302赫兹……—直到 4000赫兹的正弦波的叠加。任何一个 频率的正弦波,都是由两个变量确定的。于是 这3100根曲线就对应了6200个变量。在工程上我们会把频率的范围放大一点,放大 到1~4000赫兹,于是1秒钟的语音就需要用 4000条正弦曲线,即8000个变量来描述。定每个变量用8比特信息编码,于是 传递我们说话语音的带宽就需要能每秒钟传递 8000x8=64K比特信息。1B=8bit。
信道这个概念和我们平时 生活的关系。
信息的传播是有成本的,其 成本就源于信道的容量。比如说你有一个好消 息,想让所有的领导知道,你就让张三和李四替 你去传播,他们就是你的信道,他们表达你意 思的能力有限,不可能无限传播,那就是他们 的信道容量。你如果想让你的消息传播得更快 点,就得多找些张三李四这样的信使。由于于他们会不断往你的信息中加入噪音,即便 是无意的,领导其实未必能够真实地了解你的 想法。有可能你通过他们表达了五次信息,领 导得到的信息量还是有限。
了解做事情的边界,在边界内尽可能把事情做 好,不仅在通信上是这样,在生活的方方面面 都是如此。在没有信道容量这个概念之前,人类在通信上 走了很多的弯路,把精力浪费在实现根本不可 能实现的事情上。这和过去人们寻找长生不老 药,发明永动机很相似。
#22 传输效率
信道的容量,决定了有效的 传输率,这就是信息论中有名的香农第二定 律。
传输率R的严格定义是单位时间 (通常是秒)传输多少比特的信息。香农发现:信息通道的传输 率R,是无论如何无法超越信道容量C的,即 R≤C。总能找到一种编码方 式,使得传输率R无限接近信道容量C,同时保 证传输不出任何错误。如果谁要试图超越信道 容量传输信息,不论你怎样编码,出错的概率 都是100%
那为什么明明理论上网速很快,或者说带宽还 可以,但是看网页还是会卡住呢?真实感受到的网速,也就是运营商告 诉你的1/10左右。
其实不是,因为在网络的某一处信道的容量难以满足传输率的要求后,你的计算机作为接收方很长时间没有收到某个包,就无法发出接收 完成的信息,传送信息的服务器就不断重新传输那些没有得到接收确认的数据包。传输就永 远无法完成了。
比如用电话线传网络信息,传输率R不会超过56K,一秒钟不会超过56,000个比特。传递汉字,不经过压 缩,每秒大约可以传递3500个(2字节/汉字)通常一个网页 都没有这么多字,因此从理论上讲,即使用电 话线上网,网页也应该是一眨眼的工夫就打开 了。事实上有时打开一个网页,刚刚显示了头上10% 内容就再也打不开下面的内容了。你就在想, 即便是网速很慢,只有56K的带宽,等待时间 长一点也该传完了吧。
如果网络的带宽很宽,也就是容量很大,一个 数据包就能迅速抵达接收方,接收方接收到之 后就会发送确认信息,往,发送就非常顺畅,你也不觉得慢。但是,如果网络容量有限,比如你只有56K的带宽,发送方在一个包 接一个包地拼命发,接收方就会丢掉很多包, 然后它就不断通知发送方,第2、3、5、6、 7·…各个包都没有收到,请再发一遍。从用户的角度 看,它在单位时间里传了10个包,应该是这10 个包的数据量除以自己等待的时间。是实际传输包的总数量, 比如在上个例子中是12个,加上每个数据包的数据头上额外的信 息,再加上接收后确认回传的信息,因此即使不堵死你也就=觉得传输率远没有标准 的高。实际上由于没有确认信息,发送方马上把那些包重新发送,结果原来包还没有发完,现在又要多发很多包,网络 就变得更加拥堵,最后无论是发送方还是接收 方都会锁死在那里,传输就永 远无法完成了。
如果我们只有一个很窄的信道,也就是说信道 容量C非常小,却想传输非常多的信息怎么 办?唯一的办法就是延长传输的时间,也就是 降低传输率。
1.间接沟通:张三是你和领导之间的信息 通道,但是他的信道容量非常有限,也就是说 通过他传递后,领导的意图和你所听到的意思 |之间互信息非常低。这样的人,如果还想要他 做信息通道,唯一的办法,就是领导每次只对 他讲一件简单的事情,由他传达给你,而且你 还需要复述一下你的理解,再传回给领导。 |这样虽然慢,但他好歹还是在工作的。如果领 导一口气和他说了10句话,他可能会六句都传 达错了。结果传输率降为了零。
2.直接沟通:这个例子是关于老师和学生之间信息通道 的。
3.学习:选择学习环境,要选择一个适合自己 的。不要一心往学霸的圈子里扎。今天的教学大纲定成这个样子,当然你可以把 它看成是信息的传输率,是考虑了老师的水平 和孩子们的接受能力的。也就是说,它是建立 在老师、孩子通信平均的信道容量基础之上 的,是有道理的。如果老师用4G不断用发送高清视频,而孩子只是2G的手机那你什么都接受不到。不如按照2G这个网速发文字内容,你虽然看到的内容不够丰 富、逼真,但是毕竟有效。
如果一个老师每讲一件事,学生就理解 了,那么他们之间通信的互信息就很高,也就 是说信息通道很宽。这时老师怎么讲都行。如 果老师是茶壶里煮饺子,有货倒不出,或者学 生的理解力很弱,接受不了,这就说明他想表 达的信息和学生接受的信息之间互信息太低, 他们通信信的信道的容量太低。 |这时候,唯一能够让教学取得一些成果的方 式,就是老师讲慢点,确定学生听懂了,再往 下讲。否则,老师越是着急,试图把更多的东 西教给学生,学生越是听不懂,最后效果等于 零。
客观地讲,绝大部分孩子都不是数学学 霸,不适合搞奥数,甚至不适合花太多时间做 难题,或者比别人学更多内容。 当然对于一部分学生来讲,他们和老师沟通的 信道容量非常大,这个信息传输率远远低于他 们的潜力,对他们可以增加信息传输率,也就 是,多讲,往深了讲。但是对于大部分学生来 讲,讲多了讲深了,就如同互联网很低的网 速,还想要快速传递信息,最后大部分数据包 都丢了,什么信息都没有送出去。
#23 从管理和商业上进一步理解香农第二定律。
1.信息时代的企业到底 要不要扁平化管理?
据香农第二定律,他只有两个结果,一个是 降低自己的信息传输率,也就是说延长信息交 |流的时间,比如把每周和下属进行一次的交 流,延长到每个月一次,这样的结果无非是, 下面真出现什么问题,他根本没法察觉。 第二个结果就是将大量的信息硬往不宽的信道 里塞,整天晕头转向,其结果是完全失真,信 息沟通的效果还不如前一种。
数字设备公司((DEC)曾经是历史上第二大的 计算机公司,但是到了上个世纪90年代就关 |门了,其主要的原因是管理方式无法适应信息 时代的要求了。 该公司曾经出现过八个领导指挥一个干活儿的。 这样糟糕的管理有两个明显的危害,首先是中 间六七层都是冗余人员,使得企业的成本 增,信噪比低。另一方面,使得上下沟通的带宽变得非常窄,带宽等于一—收一发两端的互信息,这 东西是随着信息传递次数衰减的。假如经过一 次传输,互信息是原来信息的90八次下来 就只剩下1/3了,下面工程师做的事情,恐怕 早就不是上面要的了。
今天新一代的企业,管理层级相对较少,这里 面有历史的成因,因此新的企业看到过去企业 的问题,可以避免。也有竞争的原因,今天信 息交流比较通畅,容易形成赢者通吃,上下交 流效率太低的企业就被淘汰了。因此,今天哪 怕是一个决策极为不民主的家族企业,也在努力往扁平化管理上面靠。
扁平化管理流行于信息时代,是有它的原因 的。这一方面是因为信息量太大,在管理上需 要更多的带宽,另一方面是新的通信手段增加 了带宽。扁平化管理从本质上讲,使得整个公司内部 信息交流的带宽比过去有了质的提升,基于这样的带宽,对内合作可以变得更顺畅,对外能 有更强的市场适应性。 所以,扁平化管理的本质就是对香农第二定律 的应用,保证一定带宽内的沟通效率或者利用科技提高带宽。其实除了管理,市场推广也是 一种应用,市场推广的本质,也是增加对外沟 通的带宽
将层级减少后,是否就真的受到了扁平 化管理的好处?也未必。
另一种极端情况,将大量的信息硬往不宽的信道 里塞。就是一个老板 下面有上百个直接的汇报者。这看似是绝对的 扁平,而且管理者的意图可以直达每一个汇报 者,但是这样的管理其实效率同样很低,因为 管理者自身通信的带宽是有限的,他要传递、接受的 信息量又太大。
还有一种虚假的扁平化管理,就是虽然在汇报 关系上,底层员工可以直接向高层领导汇报, 但是层级设置过于分明,部门的边界过于明显,你想约领导的时间他永远没空,你想和旁边部门沟通,你的领导会觉得你不忠,还对内部调动的下级进行打压,每 次都将最差的考核评分给予那些希望流动的员 工,使得这些员工因为具有了不良的业绩考核 记录而难以提升。。每个人的办公场所完全与职级挂钩。上级对下级具有过大的人事权,从招聘、考核 评估到提升无不由上级说了算。这种扁 平化就没有意义了。即使在汇报关系上再扁平,也起不到信息沟通顺畅的目的。因为各个 层级之间,一旦分出了三六九等,信息再往下 一层层传递时,就难免人为地根据自己的目 的,"截流"一些信息,任何一个环节都可以随意夹杂私货进去。下属往上汇报时,完 全可以报喜不报忧,甚至把丧事当喜事办,因 为第一级的管理者无法绕过第二级的中间层向 第三级的员工了解真实情况。最终做的事完全不是公司希望的,而是他的私活。
绝大部分企业发现和纠正这种问题的时间非 常长。因为三六九等的职级和部门之间的壁垒 将人与人通信的带宽变得非常窄,信息传输率 就非常低,同样一个信息传递出去的时间自然 长,当然收集信息也变得困难。所以上面说的 这种扁平化管理其实是虚假的,其实本质和集 权分层的企业一样,都让信息传递和反馈变得 漫长,沟通成本增高。
比如清朝康乾两朝,皇帝都是勤政的好皇帝, 但是到了他们统治的后期,对帝国的情况已经 完全没有准确的了解了。等到了道光时,完全 不清楚衣裳打个补丁需要多少钱,而光绪皇帝 则不清楚一枚鸡蛋要多少钱。 一个企业里,再勤勉的领导,智力、见识和体 力也未必能超得过康乾两位皇帝,如果不能保 持信息沟通的流畅,就算把自己累死,也未必 能把企业管好。
2.互联网的 本质是通信工具
实际上,香农第二定律描述了自然界 本身所固有的规律性,这也是它很容易应用于 通信之外的原因。我们说互联网思维时,不要老想着把 东西放到网上,就是互联网思维了。互联网的 本质是通信工具,通信里面自有它的规律,比 如香农第二定律。做信道的容量,也就是 带宽,是由双方的互信息决定的,在商业上, 它就是双方的信任。卖家传递的信息,和买家 认可的信息一致,两种信息之间的互信息就 高,带宽就大,生意就能做成。
我们常说做生意要靠人脉,其实这个人脉就是 人与人交往的带宽买卖双方彼此认可,这在 信息论上,就表现为彼此观点的互信息较高, 这种情况下买卖就能达成。 如果人脉不够,发出的信息和获得的信息都有 限,生意一定做不大。现代通信手段和传媒技 术的本质,就是以相对低廉的成本让人们获得 人脉。
在古代,浙江杭州周边的商品要想卖到南京上 海去,就需要很长的传播时间,因为商品信息 流通的带宽太窄,信息传输率不可能高。 有了近代的传媒,包括报纸、广播和后来的电 视,商品信息传播起来就比较容易。这是因为 信息传播的带宽增加了。但是,由于报纸和广 播具有地域性的特点,电视广告的成本很高, 因此大企业在这样的环境下收益多,小商家收 益少。
互联网的出现不仅进一步扩展了带宽,而且让带宽的成本大幅度下降。这样浙江的小商品不 仅能够很快卖到全国,而且不出几年就能卖到 世界的各个角落。这就是利用了互联网这个廉 价大容量传输渠道的结果。
从本质上讲,阿里巴巴所做的事情,就是拓宽 了商家和消费者之间信息交流的带宽。这里面 是指互联网平台怎样能够建立起商家和买家之 间彼此的信任。这便是 互联网思维,这种思维方式,是符合香农第二 定律的。
相反,如果卖家吹得天花乱坠,买家不认可, 互信息就为零,两者之间就没有沟通的带宽, |生意就做不下去。中国早期失败的电商代表 8848就没有能够让买卖双方在它的平台上产生 信任,因此生意就做不下去。
在互联网时代,除了信任,不信任也可以通过互联网来传播。2019年5月有一则新闻,一位西安奔驰车 主因为无法解决和厂家在汽车质量上的纠纷, 一屁股坐在了汽车发动机盖子上痛哭,于是成 为了网红,最后厂家和经销商不堪舆论指责, 还算比较好地解决了这个问题。这位车主就是 利用互联网思维让商家的负面信息迅速传播。车主能够得 到大家的支持,是因为她的行为引起了大家的共鸣。所谓共鸣,其实就是产生了很高的互信 息,也就是大家对汽车经销商不合理的所作所 为,都有共识。
#纠错码:对待错误
纠错码:对待错误的 正确态度是什么?
机器和我们人一样,也会出错,只不过它的出 错率会低一点。比如说你的电脑正在通过网络线传输信 息,有一个地方接触不良,产生了一个小的脉冲电压,0被传输成了1。但是由于机器处理和传输数据 的总量非常大,绝对的出错数量还是非常多 的。 因此,对于必然发生的错误我们该如何面对 呢?
不要高估自己的仔细,以及自己通过努力 | 做到最仔细后,能够达到的效果。不确定 性是我们这个世界自然的属性。因此,在 解决任何问题之前,都要考虑到世界的不 完美和不确定性。这就是所谓的预则立, 不预则废
如果我们采用正向思维,就会把工作做得更细 致一点,试图不出现错误来解决问题。比如多 检查检查线路,通信线路屏蔽做得好一点;在 通信时说话慢一点,发音标准一点。这样的努力不能说没有用,但一来使得成本剧增,二来依然有一些问题无法解决,因为出错 是人的天性,而干扰无处不在。对大部分人来 讲,就是花上三倍的时间,也未必能够做到绝 对准确的要求,总不能不让那些人通信吧。此外,很多随机事件我们并不知道它们什么时 候发生,像太阳的活动其实是极不稳定的,太 阳黑子略微的变化,就能够干扰我们的无线通 信。我们能够管得了飞机起降期间不用手机, 但是管不了太阳。
从根本上解决传输过程中信息错误的办 法,就是在信息传输编码时,考虑到错误必然 存在,然后通过巧妙的编码解决那些问题。这 就是在信息传输中的逆向思维。具体到通信 中,就是通过巧妙的信道编码保证有了错误能 够自动纠错。
信息纠错的前提是要有信息冗余。如果一条信 息已经被压缩得一点冗余都没有了,它容错的 能力就是零,更不要谈纠错的可能性了。 比如说别人给你一个网址,不小心写错了一个 字母,你拿到后发现打不开,然后再仔细看一 遍网址,根据单词的意思大概猜一猜可能出的 错误,可能就打开了网页。但是,如果给你一个没什么意义的短网址,比如xAy32DZ,错一 个字符就一点办法都没有了。
1.一个最简单的信息纠错的方式就是重复传输的 信息。也就是我们说的"重要的事情说三遍"。 比 如 我 们 要 传一个八 位的二 进 制数 10011101,中间任何一位都可能出错。假如 每一位出错的可能 性是1%。这1%错率看似很小,但是累计 起来就不小,对于这个二进制数,全部八位传 输都没有错的概率只剩下92.2%,也就是说 出错的可能性是7.8%。如果你用移动支付付款,每一百次有7.8次出 错,还是很可怕的。那么怎么办?最简单的方 法就是传三遍,这样一来,你传输的可靠性就 从92.2上升到99.99%当然,其代价是 使用了三倍的信息冗余,显然编码的效率不是 很高。
2.提高编码的效率的同时,提高信息传 输的准确率呢?答案是肯定的。
奇偶校验原理。我们还是以上面的二进制10011101 为例来说明。在这个二进制序列中,任何一个O或者1发生了 传输错误,我们都无法判断是否有错误发生。 但是,如果我们将它从8位二进制扩展到9位, 第9位就是所谓的奇偶校验位,记录这个八进 制到底是奇数个1还是偶数个1。如果在传输 时,错了一位,1的数量就对不上了,这样我 们就知道出了传输的错误。
在上述方法中,如果错了两位,那就检验不出 来了,但是这一种情况不多见。90%的传输 错误是能够发现的,不能发现的错误不到 10% 接下来我们从信息冗余的角度对它作一个分 析,它其实多用了1个比特的信息,也就是1/8 的信息冗余,这样信息编码的长度就略有增 加。 当然,这种方法只能发现错误,不能纠正错 误,因为错误可能出现在任何一位上。
3.那么我 们能否通过巧妙的编码纠正错误呢?答案也是 肯定的。 我们需要想个办法,如果发现传输出错时,能 够确定出错的位置,那么我们就可以纠正错误 了。我们回顾一下古代犹太人在抄书时定位错 误的方法,他们采用横竖两个维度交叉实现。
海明码 :940年,贝尔 实验 室 的科 学 家 海 明 (Hamming,也被翻译成汉明)设计了一种 原理和上述方法类似的纠错的编码方式。 他将一个很多位的二进制数投射到几个维度, 然后在每一个维度进行奇偶校验,如果有错, 就可以定位出错位置。这种编码后来被命名为 海明码,它在今天计算机中被广泛使用。 海明码要增加编码的冗余信息,如果纠正一个 8位2进制中的1位错误,就需要增加5个校验 位,这就是成本。这比简单将信息传输三遍已 经有效得多了。事实上,海明码的纠错效率接 近了信息论给出的最优值。
4.合理的编码如果太密集,就不容易纠错,如果 让合理的编码距离拉大,就容易发现错误。不断增加合法编码之间的距离,传输就变得越来越可靠,但是这样就要浪费 很多信息。因此,有效的纠错编码实际上是在平衡编码的效率和纠错的可靠性。
假如0——999这 1000个数字,每一个都被认为是正确编码,正 确编码之间的间隔只有1,比如87和86是正确 编码,它们的差距就是1。这样稍微错一点就 出错了。 如果我们要求正确的编码必须是个、十、百三 位数都一样,那么0—999只有10个正确的编 码,即000、111,一直到999。这时正确编 |码之间的距离至少为111,距离很大,就不容 易出错。
在这方面, 最极端的情况可能是我们自身DNA的编码了。 在上个世纪80年代之前,研究基因遗传的科学 家和研究信息的科学家鲜有交集,因此前者发 现DNA中很多碱基似乎毫无用处,因为它们根 本不和任何功能对应。 今天你依然能读到这样的观点,主要是采用了 几十年前的说法。但是后来随着人们对DNA的 进一步了解,认识到两件事: 1.—些原本不知道对应什么功能的碱基,现 在找到了它们的功能。 2.那些多余的DNA并非真的没有用,而是对 于防止基因之间在复制的时候因为一个错 误而引起一连串的错误很有帮助,你可以认为它们是基因之间的防火墙。甚至有人 认为它们可能起到了纠错的功能。事实 上,人的基因也是通过信息冗余起到了容错和纠错的效果。有一些自然存在的,看似没用的信息,先 不要下结论说它们没有用,在了解清楚之 后,你可能会惊叹于大自然的美妙之处。
25信息加密
加密的本质。
假如我们有一个原始信息进行编码,变成C,C是所有人都可以读懂 的,因此我们称之为明文。对C进行加密,得到 密文E,而使用的密码则是K。 加密的目的是什么呢?当敌方获得密文E之 后,无法破解的前提下,对明文C的知晓程度不会增加。换句话 说,如果敌方对原始信息的知晓程度原来是 10%拿到密文E之后还是10%。所以加密的原则必须是,当对方收到由密码 写的密文后,无法降低任何不确定性。也就是不知道密码。
加密的过程看成是这样的:明文+密码=密文。
样才能让密码在最大程度上做到信息不 泄密呢?
1.要将原本有规律的信息,变成看似毫无规律,随机分布 的编码。不是真的随 机的,而是伪随机的,是让敌方觉得是随机, 而我方其实知道背后的算法或编码原则。
2.密码要一次性。信息论密码传输中保证一定的时间内密码有效 就可以。从原理上讲,如果 一个密码重复使用,某些明文和密文的对应恰 好又不小心被泄露了,对方就可能倒推出密 码,于是整个密码系统都被破解。虽然在密码 破译之前很难找到明文和密文的对应,使得密 码在一段时间里是安全的,但是对方可以设计 圈套,获得这种对应。
韦小宝说谎的第一个要诀是:说话九句真,一 句假微谨慎一点的人,会想办法从侧面验 证韦小宝说话的真假,比如康熙的信息渠道 多,经常能识破他的谎话。但是并非任何时候 人们都有机会来验证,比如他通知兄弟们逃 跑,那时就没有时间去验证,要么信他,要么 不信。
二战时在中途岛海战之前,美军截获的 日军密电经常出现 AF 这样一个地名,应该是 太平洋的某个岛屿,但是美军无从知道是哪 个。当美军发出"中途岛供水系统坏了"这条假新 |闻后,从截获的日军情报中又看到含有AF的电 文(日军的情报内容是 AF 供水出了问题), 美军就断定中途岛就是 AF。
26极简通信史
通信的标准中有两部分最重要,一是对信息 的发送和接收的描述,比如打电话时大家的电 话号码;二是对信息编码的方式,比如文字就 是对信息的一种编码。好的信息编码能保证信息的传输率尽可能高, 接近信道的容量。在移动通信的发展过程中, 每隔十多年,就会出现新一代的通信标准。当 然,谁掌握了标准,谁就掌握了行业的制高 点。
1G
在早期的移动通信中,标准是以摩托罗拉为主 制定的,我们后来称之为1G。在1968年 的消费电子展(CES)上,最吸引眼球的是由 它推出的第一代商用移动电话的原型,当时一 部这样的电话售价2000美元,重达九公斤!
2G
到上个世纪 |80年代,诺基亚等公司就开始研制新一代的移 动通信设备,并且提出新的移动通信标准,它 们在1991年开始投入使用,为了区分,我们称 之为2G。1G 是模拟电路的,2G是数字电路的。从1G到2G,是从模拟电路到数字电路,由于 采用了专用集成电路,单位能量传输和处理信 息的能力提高了两个数量级。从外观上 看,2G的手机比1G小很多,更省电,而且收 发短信方便。1G到2G,单位能量处理信息的能力提高了百 倍。
为什么2G的手机小?因为数字电路可以把更多 |的数字芯片集成起来,用一个专用芯片就取代 了过去上百个芯片。而在摩尔定律的影响下, |这种技术进步的叠加效应更明显,就越做越 小。
3G
2G的手机只能打电话发短信,上 网很困难。3G的通信标准将信息的传输率提高 了一个数量级,2G到3G,实现了从语音通信到数据通信的 飞跃。这是一个飞跃,它使得移动互 联网得以实现,从此手机打电话的功能降到了 次要的位置,而数据通信,也就是上网,成为 了主要功能。
3G的系统是半吊子的,虽然标称的 网速很高,但是实际网速并不快。
1G到3G都存在一个大问题,那就是 上网用的移动通信的网络和原有打电话用的通信网络虽然能够彼此融合,但是却彼此独立。使得独立的移动网络就无法受益于网络技 术的快速进步。
2G和3G时代用手机打一个电 话实际上经过的物理路径很长。其中的原理细 节,请看下图2G、3G时代移动通信网络的原 理示意图。
一方面基站和基站之间的通信效率并不高,使得上网速度快 不起来;另一方面,由于在2G时代为了适合当时移动通信 的特点,手机端到端的通信要经过好几级的转发。手机信号 送到基站后,要经过基带单元(BBU)、无线网络控制器 (RNC),才能到核心网,然后再从核心网到RNC、 BBU,最后送到基站,基站再与接收者通信。
4G
一方面使用了扁平的网络结构,减少了端到端通信时信息转 发的次数,同时增加了基站之间光纤的带宽。 更重要的是,它同时利用了互联网和电信网络 的技术进步,从4G之后,电信网络的发展已经用到 ,比如云计算和虚拟 化,因此今天通信的很多节点,只是虚拟的, 在物理上,它们都在同一个云计算中心。这两种技术的融合才使得4G的速 度比3G快很多。从3G到4G,实现了移动通信网络和传统电信 网络的融合,将云计算等互联网技术用于了移 动通信,使得不同区域之间的流量能够动态平 |衡,大大地提高了带宽的使用率。你可以认为,到了4G,电信的网络已经统一了,但是它和互联网还没有完 全统一,你先记住这个事实。
虽然在4G时代从理论上讲移动通信的网速可以 变得很快,你今天能够想到的所有应用都是够 快的。但是,如果很多人同时上网,它不仅不 够快,甚至连不进去。一方面是因为 | 总的网速不够快,另一方面是很多人要同时和 基站通信,基站成为了瓶颈。
5G
在提高通信 频率的同时,把基站建得非常密.从4G到5G,可以实现移动互联网和有线的互 联网的彻底融合。当然,万物互联才会成为可 能。需要指出的是,由于网络基站的密度非常 高,每一个基站的功率非常小,因此单位能耗 | 传递信息的效率会进一步大幅度提高。
信号能量是和传输距离的平方成反比 。卫星离地面的距离,最近也有几百公里,至少 | 是4G网络的上百倍,因此到地面上的信号强度 |只有4G基站的万分之一。
如果我们说4G是一 公里的范围建一个基站,负责这方圆一公里范 围内的手机和基站的通信,那么5G则是在百米 的范围内建基站(今天的方案是基站距离平均 在200~300米左右),负责半径为一百多米 范围内的通信)
手机和基站的距离缩短,会带来三个好处。
首先是建筑物干扰的问题得到解决,这是显而 易见的。
其次是更少的人分享带宽。我们假定方圆一公 里范围里的人口是1万人,那么方圆百米范围 内就会下降到100人。这样每个人能够分到的 带宽就可以增加两个数量级。
最后,由于基站的通信范围可以从1公里减少 到100米,功率可以降低两个数量级,这样, 在基站周围电磁波辐射也会大大降低,我们生 活的环境反而变得安全了。
一个基站覆盖半径一公里的范围(基站之 间的距离通常在2~3公里),通常这方圆一公 里范围内的人不会同时上网,因此分给每个上 网的人的带宽是够用的,但是当大家都要发照 片时,总的传输率超过了信道的总的带宽,根 据香农第二定律,出错率是100于是大家 都传递不了信息了。
公平地讲,4G对于我们目前的上网需求绝大部 分时候是足够了,但是在未来我们有很多智能 设备,它们也要同时上网,就会出现像前面说 的那种"会场拥堵"的问题。 那么怎么解决这个问题呢?有人会想到继续增 加带宽。这是一种自然而然,颇为合理的想 |法。虽然在4G的基础上增加2~3倍的带宽并 非难事,但如果想增加1~2个数量级就办不到 了
一方面要求基站的功率增加很多,这在城市 里完全不可行,因为基站周围会因为电磁波辐 射太强而变得很不安全。
另一方面,要想增加 带宽,就要增加通信的频率范围,无线通信的 频率无法向下扩展,只能向上扩展,也就是让 无线电波的频率增加。 我们知道无线电波的频率越高,它绕过障碍物 的能力就越差,比如说它高到可见光的频率 时,你随便用张纸,用块布就能挡住它。因此 在城市里高楼会严重影响通信。
最后我们看看未来会是什么样子。
我们做什么 事情是顺应技术发展的趋势,做什么则是逆流 而动?
首先,如果基站的距离缩短到200~300米, 单位面积的基站密度比4G就要增加100倍,这 |是一个巨大的国家级的基础架构建设,因此从 事基础架构建设的企业都是受益者。你或许已 经听到这样的消息,5G的传闻一出,制造电线 |杆子企业的股票已经开始疯涨了。
其次,任何致力于将各种网络融合的努力都是 顺势而为,任何试图搭建一个独立的,单纯基 于无线技术的努力都是逆流而动。几个月前, |一些国家决策部门的领导问我,以现在的技术 再开发类似于依星的通信系统,是否可行?我 |说完全没有必要,因为那是逆流而动。从1G到 5G,将各种网络融合是一个大趋势。
再次,由于网速极大地提高,很多需要高速互 联网的应用可以开展起来了,包括loT,这个题 目我们明天会仔细讲。
最后,让我们一同来思考一个问题。有了5G, 光纤通信是否还需要?
答案是,不仅需要,而 且还要大幅度提高。 我们不妨从相反的角度思考这个问题,就很容 易得到答案。假如没有光纤,只有移动网络, 那么基站和基站之间的通讯就不得不用移动网 络实现,这就要占据很大的带宽,就会影响我 们每一个人和基站的通信。 因此光纤依然是必要的,不仅必要,而且要增 加,因为我们和基站通信的速率增加了,又有 |很多loT的设备连进来,总的通信量就增加了。 | 从这里我们还可以得出一个结论,从事光纤通 讯产业的人,将是5G的获益者。
27 loT万物互联
是loT?“物联网”,更是"万物互联",因为它不只是物和物的联网,而是所有东 西的联网,包括我们人自己。为了便于你理解万物互联,我常常把它比作第 三代互联网。当然,有第三代就有第一和第二 代。接下来,我们就来看看这三代互联网的区 别和特点。
第一代互联网从本质上讲是计算机和计算机的 联网。互联网诞生于1969年几台计算机服务 器的联网。虽然后来它不断扩大,并且演化成 个人的电脑通过服务器彼此相连,但依然是机 器和机器相连。 每一个使用互联网的人,只有坐到计算机前, 甚至在登录互联网之后,才算连到网上。当我 们离开计算机,比如下班开车或者坐地铁,我 们就离开了互联网。直到你吃完晚饭,做完家 务事,再坐回到计算机旁边,才算又和互联网 相连了。
第二代互联网是我们今天使用的移动互联网。 它从形式上讲是移动设备,主要是手机,通过 空中的无线电信号相连,但是从本质上讲它是 人和人的相连。我们加一个微信好友,扫一个 商家的二维码,不是为了让你的手机能够连接 上对方那台手机或者服务器,而是要随时找手 机背后的那个人。
第三代互联网是万物互联。
1.万物互联之后,联网设备的总数会极大地提 高。 从第一代互联网,即PC的互联网到第二代互联 网,即移动互联网,上网的设备数量增加了半 个数量级,即3倍左右,从10亿增加到今天的 30亿。而到了万物互联的时代,联网的设备数 量最保守地估计,也有500亿,比今天增加了 |一个多数量级。 更重要的是,我们人也会成为万物互联的一个 节点。最后这一点非常重要,它可以非常有效 地预防疾病。
2.这么多设备来了,就带来了那个问题。首先 是上网的带宽不够了,这就让5G成为必需品。 其次是为500亿个设备经常更换电池显然不太 现实,这就要求loT设备采用比今天移动设备功 率更低的芯片,最好很多设备终身(比如10 年)不需要更换电池,这就会导致新一代半导 体公司的兴起。
3.万物互联形成的市场规模,形成的经济规模 是极为可观的。。
2018年,全世界互联网企业的收入是4000多 亿美元,这里面既有PC互联网的收入,也有移 |动互联网的收入,也就是说,第一代互联网的 收入远低于这个水平。
但是同时期,通信产业的收入却是4万亿美元 左右,几乎高出了一个数量级。虽然这里有传 |统电信的存量,但是有很大一部分来自于移动 互联网。这说明移动互联网的市场规模比第一 |代互联网大得多,几乎大出了一个数量级。
最保守地估计,到2030年,应该能够让今天电 信市场规模扩大一倍,即从目前的4万亿美元 左右达到7万亿~8万亿美元,甚至更多。要知 道今天日本的GDP才4万多亿美元,如果说增 加出一个日本GDP的产业,那么商机是多么地 巨大不言而喻。
第一代 和第二代互联网的产业结构。
第一代互联网时期,最重要的设备就是PC 机和服务器,当时互联网本身的那点收入相比 设备的收入小得可怜。而谁是那时候设备的受 益者呢?不是生产计算机的惠普、戴尔和联 想,而是控制这个产业绕不过去的两个环节, 微软和英特尔。 因此那个时代也被称:Wintel时代,即(微软 的)WindowS,加上英特尔(的处理器)。在 PC互联网时代,你可以自由地选择计算机、打 印机、硬盘或者应用软件,甚至可以选择通过 哪家公司上网,但是微软和英特尔的两个环境 |绕不过去。
第二代互联网时期,最大的受益者无疑是 控制操 作系统的Google和控 制处理器的 ARM。你可以购买不同的手机,选用不同的屏 幕,还可以选择不同的移动运营商,但是 Google和ARM这两环是绕不过去的。 这里面有一个小问题,为什么微软和英特尔在 第二代互联网时期就失去控制力了呢?因为它 们的操作系统和处理器太耗电,不符合提高单 位能量处理更多信息的发展趋势。
第一代互联网到第二代互联网,受益的还有 一大堆终端制造商,比如在PC互联网时代的惠 |普、戴尔、宏基和联想,在移动互联网时代的 三星、小米、华为,以及vivo、oppo等。 这类公司又分为两类,第一类是成功转型。
第一类是成功转型产生 |的公司,比如惠普、三星;
第二类则是新出现 的,比如PC时代的戴尔、宏基和联想,智能手 机时代的小米、华为、vivo、oppO。显然,后 一类公司占大多数。
为什么原来占据了市场的大公司反而竞争不过 后来新成立的公司呢?主要是前者的基因不适 |合新产业发展。 联想是中国最早宣布向智能手机转型的公司, 但是它今天是这个市场最弱的一个竞争者;类 似的,戴尔也在很早的时候就宣布进入手机和 移动设备市场,但是却彻底失败了,因为它做 |移动设备的思路,还停留在卖PC的做法上。
第三代互联网,即万物互联的时代,情况 也是如此,谁控制了处理器和操作系统,就会 是最大的受益者。 我们在前面讲了新一代的loT芯片的能耗必须足 够低,今天用于手机的芯片都达不到这个要 求。这就给诞生新的半导体公司提供了发展空 间。接下来,还是需要有一个合适的操作系 统,将这么多设备管理好,这个目前还没有。 不过,在具有操作系统之前,先要有行业的通 信标准,这方面,华为占到了先机。据华为自 己讲,它在5G技术上领先其它设备商半代。半 代是很大的优势,这足以让它在全世界建设5G 网络时成为最大的受益者。 从
到 了loT的时代,也会诞生不少新的制作loT设备 的大公司。 从第一代互联网到第二代,还带动起关键性配 件公司的诞生和发展,包括闪存、显示屏和电 池。到了loT时代,也会如此。
29第二模块信息传输复盘 :沟通
核心的内容是香农第二定律。
噪音,以及 它对通信的影响。我们特别强调了噪音是我们 这个世界的固有特征,不要指望存在没有噪音 的信息,也不要指望不受噪音干扰的传输。 我们在真实的世界里做事情,就要有一个世界 不完美的假设,然后练就在不完美的世界里尽 可能做好事情的本领。因此,我们对世界的态度也应该如此,承认各 种噪音的存在,争取在有噪音的情况下,准确 传递信息。
息传递的速率。信息的传输速率不可能超过信道的容量。因 此,如果我们在人与人的沟通中想要变得顺 畅,就必须想办法增加信道容量,否则信息的 |传输就会很快遇到瓶颈。 |另一方面,如果信道容量有限,最好的做法是 降低信息的传输率,以便保证信息的传输依然 能够持续,而不是急于一次传输太多的信息, 因为那样一来,出错的概率为100什么信 息也传递不下去了。
我们在与他人的沟 通中应当注意这样几个要点:
1.如果我们需要经过他人传递信息,要特别挑选那些带话不走 样的人,而并非简单地和你关系好的人。决于他作为信道的能力。所谓人脉 宽,就是指我们有能力很快地把这种信息收集 |进来,或者传递出去。
2.传递任何信息要考虑双方的输出和接受。双方在认知上的差距逐渐地越 来越大,以至于无法沟通。所在表达意思时,一定要看听众是谁,用不同 的方式去表达。表达的速率,取决于听众接受 的能力。采用有针对性的方式,是为了增加你|和听众之间的互信息。控制速率,是为了保证 信息传输的速率不超过信道的容量,这样可以 |不出错。
蒂芬·库里可能是当今全世界最擅长投篮的选 手,他能够在各种干扰之下准确命中。他这个 本事是怎么练就的呢? 据他讲,他小时候个子也不高,身体也不强 |壮,老是被人挤来挤去,撞到一边,投篮永远 |受干扰。因此,一边被撞,一边还要投篮对他 来讲就是常态。久而久之,他练就了能够在任 |何情况下投篮命中的本领。
30交叉验证
交叉验证是我们每一个人必须掌握的做事方 法,它在我们的生活中,绝大部分时候,一个维度的信息是很难消除所有不确定性的。人们 通常习惯于在自己熟悉的维度中往深里挖,往 细了挖,但是这样的做法到后来成本很高,准 确性有限,而解决这个 问题最好的办法,不是把那个维度的信息搞 更准确,而是要用其它维度的信息进行交叉验证。

在交叉验证中,什么样的信息组合最有效呢? |那就是我们前面提到的垂直正交信息,因为当 两个不同维度的信息正交时,它们的共同作用 能够最大程度地降低信息嫡。
在左边的,两种交叉的信息是正交的,同时符 合它们的情况就比较少,确定性就很强。右边 的两种信息虽然交叉,却不正交,重合面积 | 大,同时符合它们的情况就比较多,确定性就 很弱。虽然真实的信息不能用这样两个箭头简 单地表示,但是道理基本上如此。
当然,定位了答案的范围后,我们还是需要一 个刻度很准的尺子,找到答案所在的那个点。 这就是具有大局观和能够精深钻研两者的关 系。
大数据的威力。大数据"和"大量数据"其实是两回事, 前者是多维度的,后者可能只是数据的体量 大,并不等于信息多。
比如,你如果在Facebook上点赞70多次,它 就可以给你画像;如果点赞150次,它可能比 你的父亲更了解你;如果点赞200多次,它甚 |至可能比你更了解自己。Facebook这个威力从哪里来?有人说是 数据量大。数据量大只是一方面的因素,更重 要的是它掌握了有关你的多维度的信息,从很 多方向上对你进行了交叉验证。相比之下,银行虽然掌握了你很多的数据,包 括非常宝贵的交易数据,但是那只是你一个维 度的信息,就如同知道某个人住在95号高速公 |路旁边一样。
跨界的另一种理 解。很多人把跨界理解为同时做很多种不同的事情,这其实很难做好。我对跨界的理解是, 从另一个领域来回望所在领域的问题,就容易 准确地找到答案。很多人提高工作质量的想法,就是在一个维度 上将刻度画得越来越细,因为这样可以更精 确。但是,如果一个维度从头到尾范围很大, 刻度画得再精细也并不能帮助我们确定答案的 范围。这时候,引入另一个维度的信息帮助定 位显然更有效。这就是跨界的意义所在。
比如:硅谷有一位很有名的投资人,失误率很低。他 在决定投资之前,除了向其他投资人一样认认 真真做背景调查之外,还会做一件事,晚上9 点之后到那家公司外面去转转,看看停车场里 |停了多少辆车,楼里面是否有很多人在工作。 大部分人要工作到11、12点,那不是 为了显得工作努力,而是确实有做不完的事 | 情。这位投资人的做法其实就是换了一个维度 对创始人们提供的信息进行了交叉验证。
31等价性
等价的信息
1.信息不可获得时,就是面对未知的黑盒子,我们了解它里面的情 况需要信息X,但是我们可能无法获得它,不 | 过如果我们获得了信息Y,也同样能够了解里 面的情况。于是,我们就说在了解这个黑盒子 时,信息Y等价于信息X。信息的等价性条件其 实是很严格的。如果我们说Y等价于X,那么从 Y就能完全推导出原本需要X才能得到的信息。
正如我们 前面所讲,了解了各种信息彼此之间是等价 的,还是相关的,然后在不同应用场景就知道 该使用什么信息,而不会过度依赖并不可靠的 信息了。
巴 菲特判断经济形势的方式很简单,也很独特, 就是到百货店里去看看。 在巴菲特看来,大家在百货店付出的真金白银 和经济形势是等价信息,而经济学家的各种模 型预测,最多算是相关信息。
1.直接获取某种信息,于 是我们提供了一个使用等价信息解决问题 的方法。
如何通过了解虱 |子基因的变化,推算人类开始穿衣服的时间;通过对人类DNA序列的测序和对照, 我们今天得到了"人类非洲起源说"这样的结 论;找化 石相似性得出人类起 源的多元说的做法其实只是找到了相关信息,并 不是等价信息,因此得到的结论,置信度远没 有通过基因信息来得准确。
2.分清楚等价性和相关性,对于我们理解今天的 很多技术有很大帮助。很多时候我们无法价信息和相关信息不同,后者的要求宽 松得多,但是可靠性也差很多,因此采用 不同信息源的信息进行交叉验证是必要 的。
信息的等价性和信息的相关性不同,找相关性 的要求要宽松得多。比如,我们说气象云图的形状分布,空气的气 压、湿度和下雨有关,那只是有关,我们无法 |从前面几条信息完全确定是否下雨。这就是相 关性,而非等价性。相关的信息有用,但是不 像等价的信息那么具有确定性。
今天,人工智能一个重 要的应用就是身份的认证。通常识别的方式是 根据人体的生物特征来识别:这些特征可以被分为外部特征和内在特征。脸 部特征(包括颅骨特征)、虹膜、指纹等生物 |特征都是外在的,基因则是内部的。严格来讲,外在特征只能作为相关信息使用,外部特征信息常常可 |以伪造,比如可以通过伪造指纹套混过指纹识 别,用照片混过人脸识别等等,但是体内特征 不仅具有唯一性,而且很难伪造。比如在上百万人中进行脸部识别,准确率其实 只有90%右,如果在商店买东西单纯靠刷脸验证身份 付费,也不是很安全,哪怕错了1%每天都 会出现不少纠纷。此它今天更多的是作为交叉验证 的信息——你在机场过安检,不能只靠刷脸就 让你通过,还需要验证护照。体内特征通常不方便使用,人们意识到等价信息和 相关信息之间的区别,就会想办法采用能够在体外提取的体内特征:红外摄像获得手掌内部的静脉血管。
3.人类的活动会留下痕迹,无论是物理的真 实痕迹,还是写作等习惯,它们可以几乎 准确无误地还原我们自身的很多信息。因 此在大数据时代,要保护隐私其实很难。
走 路的动作姿态:以色列和德国这方面的技术, 他们根据人的身体上百块肌肉的形状和在运动 中不同的伸缩方式,能够从人走路的姿势识别 人。人做事的风格:比 如说,每一个作家(特别是专业作家)有自己 的文风,这其实是很难改变的。统 计过世界上那些著名语料库中不同作者的文 风,发现很容易找到和作者信息完全等价的信 息。 通过文风,你可以看出一部作品是原创的,还 是假借他人之笔创作的。在文学史上,胡适先 |生就曾经根据写作视角的区别,考证出《红楼 梦》并非出自曹雪芹之手在Google,我们通过用词和句法的分析,很容 易找到那些抄袭者。
31.2大数据的本质
大数据的4个明显的特征, 即数据量大、多维度、完备性和在一些场 景下的实时性。我们特别强调了光是数据 量大还不能构成大数据,因为它可能无法 得出有效的统计规律,而多维度的特征则 让我们可以交叉验证信息,提高准确性。
1.数据量。
大数据要求数据量大,这一点大家没有 疑问。数据量小一定不符合大数据的原则。至 于数据量多大合适,我们在前面介绍了置信度 的概念,数据至少要大到让统计的结果具有非 常高的置信度。
2.多维度
数据需要具有多维度的特征,而且各 个维度最好是正交的。多维度的特征则 让我们可以交叉验证信息,提高准确性。数据量大但是维度不 足有什么问题?
以基因全图谱数据为例:一个人大约在1TB这 个数量级,也就是1000个GB,这个数据量不 可谓不大,但是它没有太大的统计意义,因为 我们无法从一个人的数据看出是否有潜在的疾 病。那么多几个人的数据是否就可以了呢?也 未必。如我们有100个人的基因数据,我们发现某 个人的一段基因和其他人不同,这是否说明他 有疾病呢?我们得不出这样的结论,因为不同 人的基因总是或多或少有些不同,否则也无法 通过基因确认人的身份了。如果我们有另一个维度的信息,比如这 100人过去的病例,那么就有可能发现某段基 因和某些疾病之间的联系。这就是大数据多维 度的作用。当然100人的数量还太少,得到的 统计结果未必可信。2016年,Google同斯坦福大学和杜克大学开 展了一项长期的合作,就是监测并取得5000人 |全部的医疗数据。由于有了各个维度的数据, |就有可能发现一些生活习惯或者基因和其它生 理特征与疾病之间的联系。
3.完备性
完备性使得大数据 可以算无遗策。它在过去常常被人忽略,因为过去使用 据做预测,都是采用抽样的办法来获取,根本不可能 做到完备。抽样统计有一个问题,就是总有 5%左右的小概率事件覆盖不到,如果最后运 气不好,正好落在那5统计的方法就失去 作用了。
今天情况就不同了,因为收集数据的设备无所 不在,我们也在有意无意向它输送数据,因此 获得完备的信息完全可能,这样一来就堵住了 采用数据作预测的死角。
4.实时性
大数据有实时性,因为在那些应用场景,一定时间过 了,数据就失去意义了。单纯从大数 |据出发,很多时候如果不能保证信息的实时 性,作出的决定常常是马后炮。现在的手机地图并不能显示几分钟之前的道路管制。如果我们能够随时获取道路信息,比如高速公 路被封堵的信息直接通过车联网送达我们的汽 车,那么也不至于面对路况那么狼狈。
大数据下各行业
其实大部分行业不会很快消 失,但是可能会以另一种形式出现。而具 |有行业知识的人要做的,就是用所谓的领域知识建立起不同维度之间信息的桥梁。
大数据维度非常多之后,就会出现矛盾。下面这张图。左边的图有两个维度的 | 信息,它们一同的作用是,圈定了一个目 标范围。右边的图有三个维度的信息,但 |它们并没有共同的交点,这下麻烦就来 了,我们到底该信谁呢?
消除数据之间的矛盾,也需要领域知识。因此 在一个行业里从业很长时间,具有专业知识的 人,不仅不会被大数据取代,而且有可能利用好大数据,在事业上更上一层楼。
大数据下的企业
一类企业是类似于腾讯、阿里巴巴或者今日 头条的公司,它们自己有数据,有技术,有应 用场景,不需外人帮忙。
今天,淘宝或者其他网店,能够有效地给你推 荐产品,在很大程度上就是因为它不仅具有了 你在网上购物的数据,而且还从其他渠道,包 括在你不知不觉中,获得了生活上的信息。 比如,它可以根据你上网的行为,了解你的年 龄、性别和教育背景,根据你晚上和白天的地 点,了解你的工作地点和住址,甚至你的工作 性质和生活习惯,比如是否经常出差,在什么 样的饭店吃过饭,是否爱运动,是否使用名牌 产品等等。 由于阿里巴巴数据收集的时间跨度比较长,它 还可以看出人们消费习惯的变化。根据这些信 息,它就知道你是谁,需要什么。在没有大数 据之前,这种事情很难做到。
第二类企业有数据没有技术,包括很多大企 业,比如移动通讯运营商、传统的银行和零售 业等等,它们需要外人帮忙,但是通常出于保 护自己利益的考虑,不会和第一类公司合作。 这里面的专业人士,就能够解决上面数据冲 突,以及将行业内不同维度的数据联系起来的 问题。
第三类企业缺乏数据,但是有技术,于是它们 需要为第二类企业解决实际问题。当然,在解 | 决问题的过程中,它们或许能够进入很多领 域,逐渐成为新的平台性公司,比如美国著名 的大数据公司Splunk就是这么一步步发展起来 的,它今天的市值高达200亿美元。但是在一 |开始,这类公司一定是做脏活累活
32大数据思维
我们过去说,量变会带来质变,那常常是在一 个维度上说的,而今天我们说大数据思维,已 经超出了这一层含义,是一种全新的思维方式 和做事情的方法。
大数据是一种思维方式的改变。它的英文名称Big |Data。不知道你有没有想过,它为什么叫Big Data,而不叫Large Data,或者叫 Vast Data、Huge Data,等等。big和它们的差别却在于它是强调相对抽 象意义上的大,而并非具体的。large Table"常常表示一张桌子 |尺寸很大,而如果说"Big Table"并不强调尺 寸,只是要强调已经称得上大了,比较抽象。
大数据思维的第一层含 义:大部分人所理解的大数据,是从大量的、 看似杂乱无章的数据点,总结出原来找不到的 相关性。很多人能够想到从 很多具体的数据样本总结、提炼出一般性的规 律,然后加以应用。我们在前面讲通过大量的数据,消除噪音的影响,寻找信号的轮廓,就 是指这个方向的思维方式。
大数据思维的第二层:逆向思维,不事先作假定,从大数据出发先得到结论,再分析原因。
大数据思维和过去通过大量数据验证一件事是有区别的。数据在产生和收集时是没有特定目的的, 因此怎样使用它们,则需要视特定的应用而 定。所以在分析结果上:是一种逆向的做法,是先有了结 果,再反推原因。由 于收集数据事先没有目的性,从这些数据中能 够得到什么结果事先也不知晓,这让它发现了很多过去没有想到的规律,(有固定目收集 的数据往往在数据上有筛选)。
比如研制新药:大数据寻找特效药的方法就和过 去有所不同了。世界上一共只有大约5000多种 被批准上市的药,人类会得的疾病大约有一万 种,包括很罕见的疾病。如果将每一种药和每 一种疾病进行配对,就会发现一些意外的惊 喜。相比过 去那种从病理出发分析原因,再寻找和研制药 物的正向过程,今天这种做法其实是先有了结 果,再反推原因,是一种逆向的做法,但是正 是因为有了足够的数据支持,它无疑会比较 快。
斯坦福大学医学院发现,原来用于治疗心 脏病的某种药物,对治疗某种胃病特别有效。 当然,为了证实这一点需要做相应的临床试 验,但是这样找到治疗胃病的药,只需要花费 三年时间,成本也只有一亿美元。
大数据思维的第 三层:洞察细枝末节,利用大数据在准确把控宏观规律的同 时,精准确到每一个细节。大数据的维度非常多,很多维度彼 此独立地提供相互补充的信息,可以让我们从 过去只能了解大体轮廓,变成可以把控每一个 细节。
开过小餐馆的人都会有这样的经验,自己是否 在店里看着,对营业额的影响特别大,因此做 这种餐饮买卖的人特别辛苦,稍微不注意就开 始亏损。
在美国一半小型服务企业,特别是餐馆、酒吧等,寿命不超过五年,很多不超过18 个月。于是他花了一年的时间,调查了美国酒吧行业的情况。D先生发现,酒吧之所以经营 不下去,除了一般所说的经营不善,更重要的 是大约23%酒都被酒保们偷喝了。 那么酒保们是如何偷喝掉将近1/4的酒的呢?D 先生讲,其实很简单,主要是酒保们趁老板不 在的时候偷喝酒,或者给熟人朋友免费的和超 量的酒饮。由于每一次的交易的损失都非常 小,不易察觉,因此在过去,酒吧的老板平时 必须盯得紧一点,如果有事离开一会儿,只好 认倒霉。
D先生针对酒吧老板的这些麻烦,利用大数据 |和loT设计了一一套解决方案。他把酒吧的酒架改 造了,装上了可以测量重量的传感器,以及无 源的射频识别芯片(RFID)的读写器,然后再 在每个酒瓶上贴上一个RFID的芯片。
这样,哪一瓶酒在什么时候动过,倾倒了多少 酒都会记录下来,并且和每一次的交易匹配 上。每一笔交易,酒吧的老板都可以用平板电 脑查询,因此即使出门办事也可以了解自己酒 吧经营的每一个细节。 D先生对酒吧的改造带来了一个额外的好处, 就是积累了不同酒吧,长时间经营的数据。在 这些数据的基础上,他可以为酒吧的主人提供 一些简单的数据分析。我把他提供的服务概括 起来,包括这样三方面:
首先,每一家酒吧自己过去经营情况的统计数 据,这有助于酒吧的主人全面了解经营情况。 在过去,像酒吧这样传统的行业,业主其实除 了知道每月收入多少钱,主要几项的开销是多 少,对经营是缺乏全面了解的。至于哪种酒卖 得好,什么时候卖得好,全凭经验和自己是否 上心,没有什么分析。D先生提供的数据分析 让这些酒吧老板首先对自己的酒吧有了准确的 了解。
第二项服务是,提供每一家酒吧异常情况的预 警。比如D先生可以提示酒吧老板某一天该酒 吧的经营情况和平时相比非常反常,这样就可 以引起酒吧老板的注意,找到原因。在过去, 比如某个周五晚上的收入比前后几个周五少了 20%老板们一般会认为是正常浮动,也无法 去一一检查库存是否和销售对得上。有了D先 生提供的数据服务,这些问题都能及时发现。
第三个服务是各家酒吧数据的收集 和分析,D先生会提供这个行业宏观的数据给 酒吧老板们参考。比如从春天到夏天,旧金山 市整体上酒吧营业额在上升,如果某个特定酒 吧的销售额没有增长,那么说明它可能有问 题。 再比如,D先生还可以提供各种不同酒的销售 变化趋势,比如从春天到夏天,啤酒的销量上 升比葡萄酒快,而烈酒的销售平缓等等。这样 有助于酒吧老板们改善经营。
第四个层次,是通过几个维度的 强相关性,替代过去的因果关系。衡量影响因子。
比如美 国的法律采用无罪推定原则,单纯 靠发病率高这个单一事件是无法定烟草公司的 罪的。
美国外科协 会的一份研究报告显示,吸烟男性肺癌的发病 率是不吸烟的男性的23倍,这从统计学上讲, 早已经不是随机事件的偶然性了,而是存在必 然的联系。 但是,就是这样看似如山的铁证,依然"不足 够"以此定烟草公司就是有罪,因为它们认为 吸烟和肺癌没有因果关系。烟草公司可以找出 很多理由来辩解,比如说一些人之所以要吸 烟,是因为身体里有某部分基因缺陷或者身体 缺乏某种物质,而导致肺癌的,是这种基因缺 陷或者某种物质的缺乏,而非烟草中的某些物资。
上个世纪90年代中期,密西西比州的总检察长 麦克·摩尔带领40多个州的总检察长再次对烟 草公司提起诉讼。这些专家们派助手和学生到第三世界国家的农 村的地区(包括中国的西南地区),去收集相 同族群、相同收入和生活习惯等人群的对比数 据。这样既排除了基因等先天的因素,也排除 了收入和生活习惯等后天的因素。然后再根据 吸烟是否对身体有影响作对比。
1997年,烟草公司和各州达成和解,同意赔偿 3655亿美元。这场胜利,标志着在法律上认可 了从不同维度找到的强相关性可以取代因果关 系作为法律证据
过去研制新药:
今天几乎所有的新 药的研制过程都和青霉素很类似:科学家们通 常需要分析疾病产生的原因,寻找能够消除这 些原因的物质,然后合成新药。 这个非常漫长的过程导致药品研制的周期很 |长,斯坦福医学院院长米纳(Lloyd Minor) 教授估计,从最重要的那篇研究论文发表算 起,到新药上市,平均需要20年的时间。 |另一方面,研制的资金投入也是巨大的,通常 需要20亿美元。这也就不奇怪为什么有效的新 药价格都非常昂贵,因为如果不能在专利有效 期内 挣回20亿美元的成本,就不可能有公司 愿意投钱研制新药了。 虽然美国的专利有效期长达17年并且可以延长3年,但是因 为大部分核心专利在药品进行试验时已经申请,中间有非常 长的各种试验过程,等到药品上市,剩下的专利有效期通常 不超过10年
33信息论对广告效果定量分析
怎么利用互联网 来打广告呢?那么多种互联网广告,哪种效果 最好呢?具体到哪家媒体或者网站上去做呢?
结论:Google的搜索广告优于Facebook的个性化展示广告,后者优于一般 的展示广告。电商平台上的广告系统比其他效果更好。离达成交易的环 节越短,广告的效果越有效。
广告主要投放广告
广告是一种商业信 息,虽然它和钱相关,但是如果我们不考虑内 容,只看信息量,它和网页搜索没什么差别。中国,Google和百度广告主的数量在几十万 到百万这个量级,但实际上,很多广告主把预 算花光了后,就不再及时续费了,此外还有一 些广告主的广告质量很差,点击率不高,我们 |也暂时不考虑。 于是,我们假设有12万广告主要做广告,要想 让用户从中把你这一家商店选出来,信息熵(不确定性)是17比特。
如果你不清楚任何用户的需求,那么只好随机 做展示广告。在历史上,展示广告效果从来都 不好,原因就在于它无法消除不确定性,在这 里就是17比特的信息嫡没法消除。因为展示的 广告和读者的意图无关,读者偶尔的点击也只 是好奇和不小心。据京东主管广告的负责人颜伟鹏先生介绍,在 门户网站上做展示广告,获得一个用户的成本 可以高达10000元以上,做那种广告完全得不 偿失。 当然了,展示广告的收费也就不可能太高,通 常每一千次展示的收费,也被称为RPM,不会 超过0.5美元。但你不是为了省钱,而是为了效 果,为了更便宜地获得客户。
Google的搜索
Google的搜索引擎中收录了大约 几十亿个常用的网页和上千亿个其它网页,当 然它还有近千万的广告主以及几千万种广告。 为了聚焦,我们只关注它几十亿个(我们假定 为40亿)常用网页和几千万种广告。如果每一个 网页大家查找的频率相同,那么从40亿中选 1,需要log(40亿)=32比特的信但实际上,有些网页大家查找得越频繁,是你 想要的那个网页的概率越大,所以根据这个频 率计算信息嫡,其实不需要32比特。我们假 设,需要大约一半信息,即16比特就够了。 另外,我们还考虑到用户的浏览器所使用的语 |言,比如英语最广泛,那么划定范围又小了一 些,又可以节约一些所需信息,这时候我们估 计大约需要12比特信息。
这时候,你在搜索框里输入的关键词,能减少这12比特的信息嫡吗?要知道,在英语 里,一个表达意思的英语单词,(即排除the, | a,is等使用太频繁,但没有鉴别力的单词)平 均大约只有6~8比特信息。(个汉语的两字 词,大约有8~10比特的信息,于是你用两个 两字词,在Google上基本上可以确定那个你唯 一要找到的网页)。 因此,你如果用两个关键词,通常可以保证你 所要找的内容排在第一位。当然,这几个关键 词所提供的信息最好是正交的,那样效果最 好。
搜索广告的效果
搜索广告收费比之前传统的展示广告高出了大约两个数量 级。Google通常可以做到30美 元,甚至50美元以上的RPM,百度也能做到 100人民币左右的RPM。虽然广告的收入并非和不确定性的减少呈 指数相关,但是,如果你作为广告主知道用户 的意图再进行服务,效果也要好得多。
假设用户搜索的关键词是两个 词,通常这两个词提供 的信息是正交的,息,基本 可以消除17比特的信息嫡。Google来说,已经可以确定该显示哪一个广 告了。也就是说广告和用户的需求其实完全匹 配了。这样,广告的效果就好很多。
个性化广告以及和内容相关的广告
个性化服务会带来的好处并没有人们想象的多,这里 面根本的原因是,人的差异远没有我们想象的 大。
关于个性化,我们可以理解成我们自身的 喜好,和大众平均值的差别。用叉嫡KL来分析。如果我们把自己日常关心的事情放到10个维度 中来考虑,每一个维度有一个权重,十个维度 放在一起,就是一个关注度的概率分布。我们假设P=(P1,P2,·…·,P10)。类似的, 我们假设大众在这十个维度上的关注度的概率 分布Q=(Q1,Q2,……,Q10)。那么所谓 个性化的差异,就是P和Q这两个概率分布的交叉嫡KL(P,Q)。交叉嫡有多大呢?如果是考虑十个维 度,其实并不大,根据我们在Google和腾讯使 用了大量的数据计算,它不到一比特。但是如果 考虑的维度比较多,比如细到100维,这个数 值就要大一些了,大约在1~2比特之间。中国人所说的"性相近,习相 |远"是对的,因为人的本性差不多。
Facebook的广告效果
如果说Google的广告效果主要是因为用户 主动告知自己的目的而极大地得到提高,那么 Facebook 广告系统的效果则是通过使用正交、可叠加信息的作用。个性化以及承 载广告页面本身的内容信息,以及社交网络的 |网络效应。
个性化的1~2比特信息虽然比不上搜索时用户自己输入 的信息那么多,但是对于改进广告系统还是有 用的。这其实是Facebook的广告效果比当年 |雅虎等门户网站好的原因之一。光靠那1~2比特的信 息,Facebook完全不可能做到今天的市场规 模,它的广告系统另有玄机,那就是利用了承 载广告页面本身的内容信息,以及社交网络的 |网络效应。
承载广告页面本身内容信息的作用。就 是所谓的和内容相关的广告。如果我们在一个介绍金融的网页中放一 个薯片的广告,效果恐怕好不了,但是如果放 一个高端旅游的广告,效果就会好一些。
社交网络的网络效应。你周围圈 子是什么人,你就被划分成什么人,他们点击 什么广告,你就被推送什么广告。这样一来, |广告的效果又有了进一步的提升。
虽然每一类信息的效果有限,但是由于使 用的信息彼此是正交的,它们的效果可以叠 加,几种主要信息在一起,效果就比传统门户 网站的展示广告好了很多。
电商平台上的广告系统
以亚马逊和阿里 巴巴为代表。 这类广告系统,实际上直接使用了用户过去的 购买行为信息,甚至可以预测上一次购买的消 费品是否已经用完。因此对用户信息的把控是 |极为准确的,它的效果也非常好。与其说是大数据帮助亚马逊和阿里巴巴 了解我们的意图,不如说我们自己直接将自己 的需求放到了亚马逊和阿里巴巴里面。它们的 成功还揭示了一个规律,就是离达成交易的环 节越短,广告的效果越有效。
离达成交易的环 节越短,广告的效果越有效。
根据我们在Google的研究,人从了解到一 些商业信息到最后达成购买并付费是一个非常 长的过程。开始先看到一些普通的信息,如果 他真感兴趣,会向周围朋友去了解,然后会去 做一些研究,包括看看使用者的点评,再随后 是搜索比价,最后才达成购买。大部分媒体,包括门户网站上的信息,只是提 供普通信息,它们离购买最远,因此广告的效 |果最差。社交网络的信息和Google搜索的信息 属于第二、第三阶段的,离购买越来越近,广 告的效果也就越来越好,电商上的属于最后一 环,效果最好。我在很多场合讲,做人做事要 |直截了当,效果最好,不要拐弯抹角,就是这 个道理。
交叉嫡KL(P,Q)?
这就是为什么新崛起的内容平台会有带货能力的缘故。
池水中捞鱼。谷歌在鱼的必经之路上,脸书、快手、抖音等在猜鱼的必经之路。共同点就是。大家都养育了一池鱼。
34幸存者偏差:如何避 免被已知信息误导?
当我们要进入一个之前一无 所知的领域时,通识课会给 我们带来一些最基本的原 则,和最有价值的经验。信 息论在一定程度上,可以让 我们的生活有一个基准,遇 事能够找出大致的方向。
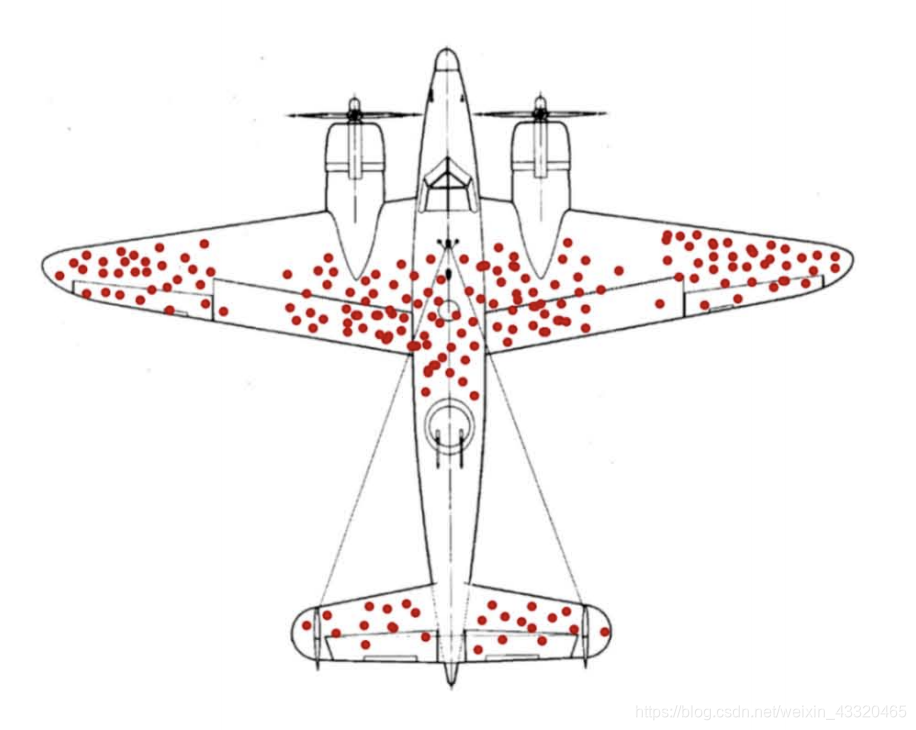
“幸 存 者 偏 差”(survivorship bias)
二战期间统计研究小组接到一个研究课题,如 何加固轰炸机的装甲,以提高它们被击中后的 生存率。战斗机的防护,多数人认为,应 该在机身中弹多的地方加强防护。但亚伯拉罕·瓦尔 德他认为,应该注意防护弹痕少的地 方。如果这部分有重创,后果会非常严 重。而往往这部分数据会被忽略。事实证 明,专家是正确的。,如果去战 地医院的病房看看,就会发现腿部受创的病人 比胸部中弹的病人多,这并不是因为胸部中弹 的人少,而是胸部中弹后难以存活。
信息缺失的情况下的误判和真 实的坠毁和返航比例应该是什么呢?
我们做一个简单的假设,飞机被击中的部位只有两 个,引擎和机翼,这两个随机事件分别被称之 为A和B。 |当然还有一种情况,就是A和B同时发生,为了 简单起见,我们不考虑它。于是飞机被击中的 总概率为P(A)+P(B)。接下来如果A发生 (也就是击中引擎),坠落的概率我们假定为 P1,返航的概率当然就是1-P1。类似的,我们假设B发生后,坠落和返航的概 率为P2和1-P2。
被击中后 坠毁的条件概率:【P(A)x PI+P(B)x P2】/ 【P(A)+P(B)】我们假定引擎被击中的概率为5%被击中 后坠毁的概率为60%机翼被击中的概率 为10%被击中后坠毁的概率为10%。缺失信息后坠毁和返航的比例:10%vs 90%。真实的返航 坠毁比例是27%vs 73%。两者个概率分布的交叉嫡是比 较高的,也就是说信息缺失很多
股市投资误导:通常理解的共同基金做不过大盘。标准普尔500指 数每年增长接近8%这是非常高的回报。但 是美国经济显然没有那么快的增长,大约也就 |是一半左右。著名的晨星 (Morningstar)公司,它宣称在1995— 2004年 之间,共同基 金年均增长高 达 10.8%高于标准普尔500指数的水平,这个差异是怎么形成的呢?
美国股市通过对表现不好的企 业强制退市,允许做空股票,彻底将表现不好 的企业清除出股市。标准普尔500指 |数几乎每年都把表现不好的企业从指数中淘汰 掉,换进那些表现好的。因此那些表现不好的 企业你就永远看不到了,这其实反映了幸存者的偏差。
共同基金的生命期通常不是很 长,大约有1/4的基金存活期只有一次股市 上行的周期,即8~10年。于2006年完成对上述数字的分析研 究。他们发现,已经消亡的基金不会被统计进 去,而真实情况却是,共同基金虽然有的会蓬 勃发展,而有的因为长期不赚钱则消亡。2011年对过去近5000只基金进行了综合的研 究,结果表明仍然存在的只有2600多只,略高 于50%而它们的收益率要明显高出消亡的。如果考虑这个因素,所有的共同基金年化回报 率只有8%右了,略低于同期标准普尔500指 数。
每次战斗中,自己被击落 | 的飞机比对方少5%消耗的油料低5%弹药 多5%机动性高5%就会最终成为胜利方。 这个结论也是有数学依据的,不是假设?
35简约之法则
奥卡姆剃刀法则,又被称为"简约之法则", 它是由14世纪圣方济各会修道士奥卡姆(英格 兰的一个地方)的威廉(Wiliam of Occam) |提出来的,他说过这样一段话: “切勿浪费较多东西,去做’用较少的东西, 同样可以做好的事情。最流行的解释是"若无 必要,勿增实体”(拉丁文是:Non sunt multiplicanda entia sine necessitate)。
在任何领域, 都有这种成为支撑点的关键信息,找到它们并 且使用它们,一切问题就可以迎刃而解,掌握 和利用这些支撑点。
看似复杂的,似 是而非的解释反而找起来容易一些。过于复杂的描述常常是骗局,因为骗局 只有被包装得很复杂才不容易被识破。
2008— 2009年金融危机前,有人向巴菲特推销金融衍 生品,巴菲特看了他们的说明书后,断然拒绝 了,理由是那说明书之所以要写成厚厚几百页 没人看得懂的东西,里面多半藏了不可告人的 事情。
信息论解释
如果能够得到同样好的结论,假设越少越好, 或者说条件越少越好。简洁的往往是正确的,越是复杂,越 容易犯错。
要消除不确定性,就要使用信息。使用什么样的信息, 使用多少信息合适呢?我们不妨假定需要预测的目标是Y,当然它有不确定性,因此就有信 息嫡,我们写作H(Y),它是大于零的。 我们现在有一大堆信息,我们写作X1,X2, X3,……,XN。这些信息可以帮助消除Y的不 确定性。我们不妨假定如果这些信息都用上, 那么所有的不确定性就消除了,也就是说在 X1,X2,X3,……·,XN的条件下Y的嫡降为 了0(即H(YX1,X2,X3,……,XN) =O)。
1.真的需要那么多信息么?
显然不是,因为总有信息不那么有用,甚至是 无效信息,那么就一定存在一个很小的集合, 比如X2和×4,我们用了这一点点信息就足够 了。也就是说Y在给定X2,×4条件下的嫡,等 同于它在给定所有条件下的嫡。
为什么简单的解释通常是正确 的。这里面有两个原因,一个是世界本身的规 律在形式上并不复杂,虽然通常找到这样简单 规律的过程极为复杂。在历史上各个时代,最 高深的物理学理论,从形式上讲都不复杂,从 牛顿力学,到爱因斯坦的相对论,到今天物理 学的标准模型。 牛顿在《自然哲学的数学原理》一书中讲了四 条法则,其中的法则一就是"除那些真实而已 足够说明其现象者外,不必去寻找自然界事物 的其它原因"。
2.既然不需要那么多的话,怎样找到一个最小 的集合?
数学上是有答案的,就是 找到一组所谓的基函数,我们前面讲到的傅里 叶变换,正弦或者余弦函数就是基函数。在计 算机科学中,对于一个复杂的联络图,或者网 络来说,就是找到一个所谓的最小支撑树。
体会:
1.做减法。
很多时候,我们生怕自己错过一些机会,于是 做了很多其实对目标结果不再有帮助的事情。
比如年轻人头几回在大会上作报告时,常常喜 欢尽可能多地把自己的工作讲出来。这样不仅 |无法在规定的时间里讲完,而且由于传递出的 信息其实有很大的重复性,接收者并不因为耐 着性子听完了就获得更多的认同。讲东西如 此,做事情也是如此,并非做得越多,效果就 越好
2.帮助我们提高判断力不要制造伪需求。
很多看似很重要的事情,其实是伪需求。这种现象普遍存在,同时我们难以觉察。
我在 《硅谷来信》中评论过无人超市是否需要,我 讲其实超市有没有人并不重要,重要的是顾客 是否能够以最便宜的价格,最短的排队时间买 到自己需要的日用品。至于可有可无的奢侈品 的销售,更是需要推销的了。 四月份我带人去参观了一家研制无人驾驶汽车 的企业。暂且不考虑他们研制的无人车在技术 上是否过关,他们想象中的市场就不存在。 按照他们的说法,节省一个司机能够让公交系 |统从需要政府补贴到盈利,但是他们的无人驾 驶汽车的成本比公交车贵100多万元,车子的 折旧费远远超过司机的工资。
3.要提高自己寻找基函数的能力。
我们说的做减法,不是把有用的信息剪掉,而 是设法只保留少量的,等同于全部信息的有效 |信息,这就是数学上所说的基函数。 如果我们保留了那些基函数,我们就获得了最 大的效益,但是如果我们保留了一堆似是而非 的信息和方法,就得到时灵时不灵的结果。提高这个能力,就要对自己进行专业的训 |练。
如说,投资的原则有很多很多,但是真正称 得上是基函数的其实很少,比如巴菲特和芒格 的价值投资,马尔基尔的定投指数基金等等就 是。而其它一些所谓的秘诀,什么低买高卖, 追涨杀跌,则不是。
36最大嫡原理
背景:
当我们找到基函数时,获得了全部的信息,事情就是确定的 了,就不要用概率模型进行预测了。我 们可以得到最根本规律的认识,对它最简单、最有效的描述。但形式上简单的东西,获得它未必容 易,在数学上漂亮,形式简单,但是实现起来 反而难度很大。这就 是牛顿、爱因斯坦、沃森、克里克和门捷列夫 等人所做的工作。、在寻找到这样的本质规律之前,我们可 能需要有很多过渡性的模型,让它们来帮助我 们解决当下的问题。毕竟,人类不可能等到建 立起牛顿力学才制定历法,等到门捷列夫画出 |元素的周期表才开始寻找基本元素。
最 大嫡模型的应用场景是:当我们遇到不确定性 时,或是没有信息或者是得到相互矛盾的信息,就要保留要保证所建立的模型满足所有的经验,同时对不确定的因素有一个相对准确的估计。
做了手脚的骰子
我们只知道两件事,五点朝上的概率大约是 2/5,两点朝上的概率大约是零,对于另外四 个面的概率不知道,大家要平均分配剩下来的概率,而不会 |觉得1点朝上的概率比6点朝上的概率来得大 呢?因为这样对大家来讲风险最小。 这时候你可以赌,比如赌三点朝上的概率为 1/3,四点朝上的概率为零。你或许会赌对, 又或许会赌错,但是长期看下来,这样赌的风 险很大,因为不符合概率上的计算结果
大家在猜骰子哪面朝上时,是基于 简单的算术加上直觉。而人作出这种基于直觉 的预测,背后的依据是让风险最小。已 经利用了所有已知信息,将信息嫡减少了,该 确定的已经确定了,我们不可能进一步减少信 息嫡了。于是剩下的信息嫡就达到了最大,这 就是把信息使用地刚刚好。 如果我们自作主张地想进一步降低信息嫡,作 了很多主观的假设,作出来的预测反而不准确 了,我们在前面学了,不准确的预测风险是极 大的。因此这就是老子所说的"过犹不 及"了。
最大嫡原理
当我们需要对一个随机事件的概率分布 进行预测时,我们的预测应当满足全部已知的 |条件,而对未知的情况不要作任何主观假设。
最大嫡模型
按照上述的方法,去建立一个概率的 |模型,可以证明这样的概率模型会使得嫡,也 就是不确定性,达到最大值,因此这种模型被 称为"最大嫡模型"。最大嫡模型用数学推理的办法解决了当同时满足面对两个矛盾的先决条件,会 自动地在这两个条件中找到一个中间点,保证 信息的损失最小。可以讲,最大嫡模型在形式 上是最漂亮、最完美的统计模型,在效果上也 是最好、最安全的模型。
最大嫡模型在技术上有什么好处,或 者相对其它技术有什么优势呢?
首先它显然和我们所有已知的信息相符合, 因为我们的模型就是用已知信息搭建起来的。
其次,这样的模型最光滑。一个光滑的模型,可以 |让预测的风险最小。光滑在数学上是一个什么概念?你可以理解为它不会遇到黑天鹅 事件,方方面面都考虑得很周全。最大嫡模型 光滑的原因,在于我们对于未知的信息,没有 作任何的主观猜测,就可以保证结果能覆盖所 有的可能性,不会有所遗漏。
这一点对投资非常重要。很多人觉得股市 连续涨了半年就一定会下跌,或者下跌了半年 就一定会涨,这些都是主观的假设。 我们在前面介绍投资时讲过,要想获得投资最 大的收益,就需要将钱长期放在一个健康的股市中。事实上时机你是把握不住的,而时间是 你的朋友。很多人对所谓时机的判断,都是主 观的,其实是一种投机行为。
最明显的弊端是计算量太大,模型复杂。
到奥卡姆剃刀法则时说简单的方法 常常最有效,可能会有人将简单和初级、低水 平划等号。形式上简单的东西未必初级,相 反,要把道理总结得简单易懂,自己需要有深 |刻的理解。
直到 21世纪之后,由于计算机速度的提升以及训练 算法的改进,很多复杂的问题才开始采用最大 嫡模型来解决,比如自然语言处理。
这就是我们
作出55开的决断,
尽可能减少主观带来的风险。
37负 嫡
克劳修斯发明了嫡这个概念来形容分子运动的无序状态,从有序到无序,是一个不断嫡增的过程。在一个封闭的系统中,永远 是朝着嫡增加的方向变化的。一定会越变越糟糕。而要 扭转这种局面,唯一的办法就是从外界引入负 嫡。
对于一个地区、一个组织也是如此。它只有成为一个开放的系统,会引入负嫡,才有可能让 系统通过与外界的交换变得更加有序,也就是 朝着越来越好的方向发展。(也可以理解为:一个封闭系统内原有的能量是有限的,在能量转化为生产资料不断损耗)。从外面引入负嫡有 两种办法,一种是直接与外界进行人的交换, 另一种则是接受外面新的思想。前者可以被看 成是引入负的能量嫡,后者则是引入负的信息 嫡。最初薛定谔等人用负嫡的概念来说明为什么生 物能够进化(越变越有序)
负嫡,管理学家们借用这个概念来说明一个公司或组织在外界 环境的影响下,可以变得更好。
数硅谷地区 了,它成功的一个重要原因,就是因为它自身 是一个开放的系统,不断地从世界各地引入新 的人才,不断地丰富本已很多元的文化。在过去的十多年里硅谷地区每年和世界各国进 行人才交换,净流入1.7万~1.8万人,这些人 大多是思想活跃的年轻的专业人士。我一直非常强调工作地点,反对年轻 人贪图安逸,跑到生活成本低的三四线城市 去,因为那些地方是相对封闭的系统。
对于个人来讲,什么算是引入负嫡呢?那就是 行万里路,读万卷书。第一件事是指自己走出去和别人接触,我把它 等同于在能量上引入负嫡。第二件事是指接受 新的信息,引入负的信息嫡。有时听一些朋友讲,我太忙,没时间走出 去,没时间学习,或者我太内向,不善于和别 人打交道。对此我想说的是,每个人都有自己 的困难,但是世界自有安排,不会因为谁困难 就照顾谁。不管什么原因,一个人一旦封闭起 来,他就离无序的状态不远了。
信息是补充的 没有问题就不会有信息
需要验证的 没有答案信息的准确性就会打折
能量扩散。宇宙最终所有地方的温度都会趋同,这 |就是所谓的"热寂说"。
38问题转化的意识和能力
计算机科学的工作:第一步是将我 们这个世界的现实问题变成一个数学问题,这 就是计算机科学家们做的事情,第二步就是将 数学问题重新描述一下,变成计算机能够处理 的问题,这就是计算机工程师的工作,这个重 新描述的过程,其实就是把人的自然语言变成 计算机程序语言。
很多人担心在信息社会里自己落伍,其实每一 个自己的专业特长,就是信息时代最大的价 值。关键看大家如何利用信息技术,发挥自己 的特长了。
在得到上学了不少有用的 课程,如何利用这些科学基础改进我们的生活和工作 呢?
这些方法、知识就相当于是人生的算法。得不同的人得到它,会产生不同的结果,绝大部 分人看了看,就放在一边了。我们需要做的是:将一个现实的、具体 的问题,变成了那个算法能够解决的问题。 例如:D先生通过大数据和 loT解决酒保偷喝酒的问题,他的贡献也是将一 个具体的问题变成了一个信息收集和处理的问 |题。
信息论的应用中,情况也大致如此。我们很多人所做的工作,就是将工作中的问题,变成 信息的收集、传输、综合、存储和处理的问 题。我们绝大多数人不需要知道上述信息技术 的细节,但是需要知道如何把自己领域中的问 题,描述成一个信息处理的问题。例如:CT和核磁共振(MRI) 等 医学影像仪器的发明,就是把医学中的一些问 题变成了信息处理中的信号检测问题。
一般没有科学基础的方法常常难以持久。
比如说无线充电。简单地讲就是一个相互转化的 电场和磁场,电场的变化产生变化的磁场,磁 |场的变化又产生变化的电场,于是它们就往远 处传播了。这种无线电可以做两件事,传递能 量或者传递信息。
给特斯拉投资研究无线电的是著名投资人J.P. 摩根,他看到特斯拉净做这些不靠谱的事情, |就停止了对他的资助,转而资助另一个年轻 人,从意大利来到美国的马可尼。
为什么距离远不了呢?因为电磁波辐射到 远方衰弱得特别快。如果我们让电磁波往四周 |辐射,在辐射源10米附近的强度,只有一米附 近的强度的1/100,100米以外的强度,只剩 |下万分之一了。因此不能距离很远。
那么为什么用无线电传递信息能传得较远呢? 因为信息可以叠加在无线电波(也被称为载 波)上传输,在接收时,只要信噪比足够高, 就能复原出信号,不需要在接收端具有太高的 能量。
39控制论与信息论
控制论与信息论结合,信息反馈系统。
控制论
在1948年,维纳将自己在控制论上 的研究成果发布了。 控制论的本质可以概括为下面三个要点:
首先,维纳突破了牛顿的绝对时间观。时间不是静态和片面的,事物发展 的过程不能简单拆成一个个独立的因果关系
什么是绝对时间观呢?在牛顿等人看来,时间 |是绝对恒定的物理量,比如昨天的一小时和今 天的一小时是一样的,昨天出去玩了一小时没 |有做作业,今天多花一小时补上就可以了。 维纳的时间观,“绵延”,。 比如昨天浪费了一小时,今天多花了一小时做 作业,就少了一小时的休息,就可能造成第二 天听课效果不好,因此浪费一小时和没有浪费 |一小时的人,其实已经不是同一个人了。
如果我们把这种观点应用到企业管理上,那么 工厂主强制员工在某一天加班—一小时,未必能 | 够多生产出通常一小时生产的产品,因为多加 班一小时的员工们已经不是原本的员工了。由 于事物发展的过程前后高度耦合,也就是紧密 咬合,没有空余。所以,我们在做事情时,就 要考虑它的连带影响
其次,任何系统(可以是我们人体系统、股 市、商业环境、产业链,等等)在外界环境刺 激(也称为输入)下必然作出反应(也称为输 出),然后反过来影响系统本身。(信息的叠加)
比如如果大家都觉得一种股票有利可图, 大量购买,就会瞬间抬高股价,于是,炒股的 |人并不能赚到预想的收益。这便是市场的有效 |性。正因如此,根据过去的经验或者任何已知的信 号去操作当下的股市,都不可能达到预期。在 维纳看来,任何系统,无论是机械系统、生命 系统,乃至社会系统,撇开它们各自的形态, 都存在这样的共性。
最后,为了维持一个系统的稳定,或者为了对 | 它进行优化,可以将它对刺激的反应反馈回系 统中,这最终可以让系统产生一个自我调节的 机制。
比如上百层楼高的摩天大厦,在自然状态下会 随风飘摆,顶层的位移会在一到两米之间,在 大楼的顶上安装一个非常重的阻尼减震球,让 它朝着与大楼摇摆相反的方向运动,大楼顶端 飘移(输入)得越多,它往相反方向运动(输 出)也越多,而这种反方向的运动反馈给大 楼,最终会让大楼稳定。
在管理上,一个组织为了保证计划的实现,就 要不断地对计划进行监控和调整,以防止偏差 继续扩大。
在做很多事情时,也 需要不断调整策略。霍夫曼风险投资,,即不断对好的项目加倍投入,其实 就是在投资上重反应的表现。自我反馈机制能够利用在公司的活动调整之中,加快活动、互动、黑天鹅的带来的影响因子的调节。同时这种反馈控制也是有一定限度的。
创业者要成为 变色龙,而不是恐龙,也是这个道理。
什么是 恐龙呢?它们架子很大,很唬人,但是适应性 差。今天不少创业者喜欢一开始就给投资人画一个 大饼,五年后的发展前景。其实稍微有点经验 的投资人都不会看它,因为即便有稳定市场、 |核心技术、专业团队的上市公司,都很难对一 年后的财报作准确预测,更何况一家初创公司 呢?
一个好的创始人需要是变色 龙,他能不断应对环境变化作出调整,而不是 一开始就把摊子铺得很大。很多成功的企业,它们最终做成的事情和创始 人最初的想法相差十万八千里呢,因为环境和 市场在不断变化。
#40系统论:如何让整体 效用大于部分之和?
系统论
将信息论和控制论结合起来的理论
系统论
1948年奥地利生物学家贝塔 朗菲出版的《生命问题》一书,标志着系统论 的问世。虽虽然系统论最初源于对生物系统的研 究,但是它适用于各种组织和整个社会。贝塔 朗菲和其他系统论的奠基人主要的观点如下:
首先,生命的系统的开放型。生命的系统是一个开放的系统,需要和外界进 行物质、能量或者信息的交换。非生命的系统的不同在于后者为了其稳 定性,需要和外界隔绝,才能保持其独立性, 比如一瓶纯净的氧气,盖子一旦打开,就和周 围环境中的空气相混合,就不再是纯氧了。
其次,一个封闭系统总 是朝着嫡增加的方向变化的,即从有序变为无 |序。无论对一 个热力学系统,还是一个信息系统,或者一个 组织机构都是如此。 特别需要强调的是,对于一个复杂的系统,比 如我们的生命体,或者一个公司、一个组织, 一旦它成为了一个封闭系统,一定是越变越糟 糕。相反,对于一个开放的系统,因为可以和 周围进行物质、能量和信息交换,有可能引入 所谓的"负嫡",这样就会让这个系统变得更 有序。
最后,贝塔朗菲认为,对于一个有生命的系 |统,其功能并不等于每一个局部功能的总和, 或者说将每一个局部研究清楚了,不等于整个 系统研究清楚了。
比如熟知人体每一个细胞的 功能,并不等于研究清楚了整个人体的功能。 相反,多出了一个部分,整体的功能未必会增 强,而少掉一个部分,相应的功能未必会失 去。比如各种维 生素,事实上,当我们的身体获取了所需要的 维生素后,多余的全部代谢排出体外了。
统论的思想对我们有什么启示呢?这里我不 妨分享一下我的体会。
首先要想办法做到整体大于部分之和。几年前的苹果,每次有新的手机问世时,从来 不宣传自己的速度提升了多少,容量有多大, 分辨率有多高,而是强调自己的手机使用起来 非常流畅,因为它在设计手机时,综合考虑了 各种因素,做到了整体大于部分之和。 事实上那时的苹果手机,同样的售价,各部分 | 性能指标只有大多数安卓手机的一半,同样的 性能指标,售价却是安卓手机的两倍。但是你 使用起来,会觉得物有所值。今天,很多安卓 手机也赶了上来,做到了整体大于部分之和,苹果的优势就没有了。
我的第二点体会是,在 一个有机的系统中,很多功能是可以相互替代 的,因此不会因为某一个缺损,而使得整个系 统瘫痪。人是一个完整鲜活的系统,增加局部的能力之 后,单独衡量那项能力,肯定是提高了,但是 人作为一个整体是否提高了,则是另一回事。 因此,每一个人往哪个方向努力才能提高整体 能力,就有讲究了。
第三个体会涉及到利用系统论改进做事方 法,毕竟我们光发现问题还不够,还需要有行 动指南。我把它们总结成四点:
1.整体。任何局部的改进,都需要放回到整 体中去考察。
2.综合。iPhone是一个很好的例子。
3.科学。在分析问题时必须要遵循科学方 法,而不是简单的经验,因为只有这样才 能获得可重复的成功。20多年前,公牛队 称霸NBA,靠的是乔丹等人的天赋,那是 不可重复的。今天勇士队的成功,靠的是 科学训练,特别是找到了投三分球这个秘 诀,以至于整个联盟的比赛都成了三分球 的比拼。这说明它的成功是可以重复的
4. 发展。系统工程不仅要求在空间上,作整 体考虑,还需要在时间上考虑一件事情的 |影响力,然后决定做不做。
这点与简约之法有相通之处。

