
- 12015年认证杯SPSSPRO杯数学建模A题(第二阶段)绳结全过程文档及程序
- 2sklearn.tree.DecisionTreeClassifier()函数解析_decisiontreeclassifier函数
- 3python PyQt5的安装_pyqt5 安装
- 4工业制造中的大数据分析应用_工业大数据分析方案-美林数据_大数据分析在工业应用
- 5Resource punkt not found_tensorflow resource punkt not found
- 6更多代码阅读及测试(词典操作)_user_dict.txt
- 7在Blender中使用代码控制人物模型的头部姿态 - 前置知识_头部姿态 控制
- 8杨强 : 迁移学习——人工智能的最后一公里
- 9【多模态】17、CORA | 将 CLIP 使用到开集目标检测_clip 目标检测
- 10机器学习 主成分分析(Principal Component Analysis)_机器学习主成分分析
XGBoost详解(原理篇)
赞
踩
入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。
目录
一、XGBoost简介
XGBoost全称为eXtreme Gradient Boosting,即极致梯度提升树。
XGBoost是Boosting算法的其中一种,Boosting算法的思想是将许多弱分类器集成在一起,形成一个强分类器(个体学习器间存在强依赖关系,必须串行生成的序列化方法)。
Note:关于Boosting算法详见博文集成学习详解_tt丫的博客-CSDN博客
XGBoost是一种提升树模型,即它将许多树模型集成在一起,形成一个很强的分类器。其中所用到的树模型则是CART回归树模型。
Note:CART回归树模型详见博文决策树详解_tt丫的博客-CSDN博客
二、XGBoost原理
1、基本组成元素
XGBoost的基本组成元素是:决策树。
这些决策树即为“弱学习器”,它们共同组成了XGBoost;
并且这些组成XGBoost的决策树之间是有先后顺序的:后一棵决策树的生成会考虑前一棵决策树的预测结果,即将前一棵决策树的偏差考虑在内,使得先前决策树做错的训练样本在后续受到更多的关注,然后基于调整后的样本分布来训练下一棵决策树。
2、整体思路
(1)训练过程——构建XGBoost模型
从目标函数出发,可以推导出“每个叶子节点应该赋予的权值”,”分裂节点后的信息增益“,以及”特征值重要性排序函数“。
与之前决策树的建立方法类似。当前决策树的建立首先根据贪心算法进行划分,通过计算目标函数增益(及上面所说的”分裂节点后的信息增益“),选择该结点使用哪个特征。
选择好哪个特征后,就要确定分左右子树的条件了(比如选择特征A,条件是A<7):为了提高算法效率(不用一个一个特征值去试),使用“加权分位法”,计算分裂点(这里由”特征值重要性排序函数“得出分裂点)。
并且对应叶子节点的权值就由上述的“每个叶子节点应该赋予的权值”给出。
不断进行上述算法,直至所有特征都被使用或者已经达到限定的层数,则完整的决策树构建完成。
(2)测试过程
将输入的特征,依次输入进XGBoost的每棵决策树。每棵决策树的相应节点都有对应的预测权值w,将“在每一棵决策树中的预测权值”全部相加,即得到最后预测结果,看谁大,谁大谁是最后的预测结果。
3、目标函数
(1)最初的目标函数
设定第 t 个决策树的目标函数公式如下:
符号定义:
n表示样本数目;
表示与有关的损失函数,这个损失函数是可以根据需要自己定义的;
表示样本 i 的实际值;
表示前 t 棵决策树一起对样本 i 的预测值;
表示第t棵树的模型复杂度,这里是正则化项,为了惩罚更复杂的模型(通过减小树的深度和单个叶子节点的权重值),减缓过拟合。
T为当前子树的深度,w为叶子节点的节点值。
(2)推导
A、根据Boosting的原理简化
根据Boosting的原理:第 t 棵树对样本 i 的预测值=前 t-1 棵预测树的预测值 + 第 t 棵树的预测值
即:
这里补充一下:Shrinkage(收缩过程):
Shrinkage即:每次走一小步逐渐逼近结果的效果,要比每次迈一大步很快逼近结果的方式更容易避免过拟合。就是说它不完全信任每一个棵残差树(达到防止过拟合的效果),它认为每棵树只学到了真理的一小部分,累加的时候只累加一小部分,通过多学几棵树弥补不足。即给每棵数的输出结果乘上一个步长η (收缩率),如下公式所示:
后续的公式推导都默认 η = 1。
那么最初的目标函数就可以化为:
符号定义:
表示第 t 棵决策树对样本 i 的预测值
B、根据二阶泰勒展开
分析:
我们知道,二阶泰勒展开公式:
将上面的
当成
,即把
当作 x ,把
。
这样一来,
就是
啦。
那么就有:
其中:
——表示一阶导数,是可以求出来的已知数
——表示二阶导数,是可以求出来的已知数
C、去掉常数项
因为我们的目的是要最小化目标函数,那些常数项我们可以把它们暂时搁置。
4、从目标函数到特征划分准则 + 叶子节点的值的确定
(1) 的定义
XGBoost把 定义为
其中代表了样本 i 在哪个叶子节点上,w表示叶子结点的权重(即决策树的预测值)
(2)引入真实的和正则化项代换
进一步化为:
其中:
代表决策树 q 在叶子节点 j 上的取值(即表示位于第j个叶子结点有哪些样本)
这样就把累加项从样本总数变为了针对当前决策树的叶子节点。
再令 和
,
再次化简为:
(3)求出 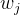 —— 定下该叶子结点的值
—— 定下该叶子结点的值
因为我们的目的是最小化目标函数,因此我们对上式求导,令其为0。
即我们应该将叶子结点的值设为
(4)目标函数的最优解——与信息增益的连接
这个又叫结构分数,类似于信息增益,可以对树的结构进行打分。
信息增益:更能确定多少——目标函数:预测对了多少
(5)特征划分准则——“信息增益”
其中 L 下标是值划分到左子树时的目标函数最优值,R 下标是值划分到右子树时的目标函数最优值。在实际划分时,XGBoost会基于“Gain最大”的节点进行划分。
第一部分是新的左子叶的分数(即该节点进行特征分裂后左子叶的目标函数);第二部分是新的右子叶的分数(即该节点进行特征分裂后右子叶的目标函数);第三部分是原来叶子的分数(即该节点未进行特征分裂前的目标函数);第四部分是新增叶子的正则系数。
体现的意义即为:判断分裂节点后的信息增益(第一部分+第二部分)是否大于未分裂的情况,并且考虑到模型会不会太复杂的问题(如果增加的分数小于正则项,节点不再分裂)。
5、从目标函数到加权分位法(实现对每个特征具体的划分)
(1)引入原因
比如说,有一个特征A是一个离散的连续变量,有100个不同的值,范围是[1,100]。那么如果选择特征D来分裂节点时,需要尝试100种不同的划分,一个一个算然后再对比Gain,可以是可以,但会导致算法的效率很低。
XGBoost为了实现可以不用尝试每一种的划分,只选取几个值进行尝试,提出了加权分位法。
(2)“特征值重要性”的提出
为了得到值得进行尝试的划分点,我们需要建立一个函数对该特征的特征值进行"重要性"排序。根据排序的结果,再选出值得进行尝试的特征值。
(3)目标函数到平方损失
我们前面得到的目标函数长这样:
我们把 提出来,变成:
然后因为 和
都是已知数,相当于常量,我们给他加上它们的相关运算,在后面再给他减掉一个常数,结果不变。
C为常数项
现在我们得到的式子即为:真实值为 ,权重为
的平方损失项+正则化项+常数项
(4)特征值重要性排序函数
因此,我们可以得出结论:一个样本对于目标函数值的贡献,在于其 。因此可以根据
对特征值的“重要性”进行排序。XGBoost提出了一个新的函数,这个函数用于表示一个特征值的"重要性"排名:(这里的特征值表示:某个等待判断分裂的节点属性,中的某个取值)
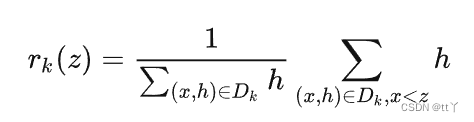
其中:
:第k个特征的每个样本的特征值(
)与其相应的
组成的集合;
:表示第 i 个样本对于第k个特征的特征值,和其对应的
的分母:第k个特征的所有样本的
式子表示的意义是:特征值小于z的样本特征重要性分布占比
(5)切分点寻找
之后对一个特征的所有特征值进行排序。在排序之后,设置一个值 ϵ (采样频率)。这个值用于对要划分的点进行规范。对于特征k的特征值的划分点有,两个相连划分点的
值之差的绝对值要小于 ϵ (为了让相邻的划分点的贡献度都差不多)。同时,为了增大算法的效率,也可以选择每个切分点包含的特征值数量尽可能多。
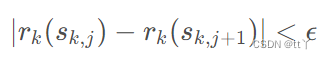
(6)计算分裂点的策略
基于加权分位法,我们有两种策略进行分裂点的计算:全局策略和局部策略。
A、全局策略
即在一棵树的生成之前,就已经计算好每个特征的分裂点。在整个树的生成过程当中,用的都是一开始计算的分裂点。这也就代表了使用全局策略的开销更低,但如果分裂点不够多的话,准确率是不够高的。
B、局部策略
根据每一个节点所包含的样本,重新计算其所有特征的分裂点(即边建立树边重新更新分裂点)。
因为在一棵树的分裂的时候,样本会逐渐被划分到不同的结点中(即每个结点所包含的样本,以及这些样本有的特征值是不一样的)。因此,我们可以对每个结点重新计算分裂点,以保证准确性,但这样会使局部策略的开销更大,但分裂点数目不用太多,也能够达到一定的准确率。
(1)在分裂点数目相同,即 ϵ 相同的时候,全局策略的效果比局部策略的效果差;
(2)全局策略可以通过增加分裂点数目,达到逼近局部策略的效果
三、XGBoost对缺失值的处理
对于特征A,我们首先将样本中特征A的特征值为缺失值的样本全部剔除。然后我们正常进行样本划分。
最后,我们做两个假设:一个是缺失值全部归在左子节点;一个是归在右子节点。哪一个得到的增益大,就代表这个特征最好的划分。
Note:对于加权分位法中对于特征值的排序,缺失值不参与(即缺失值不会作为分裂点,gblinear将缺失值视为0)
四、XGBoost的优缺点
1、优点
(1)精度高
XGBoost对损失函数进行了二阶泰勒展开, 一方面为了增加精度, 另一方面也为了能够自定义损失函数,二阶泰勒展开可以近似许多损失函数。(对比只用到一阶泰勒的GBDT)
(2)灵活性强
XGBoost不仅支持CART,还支持线性分类器;
XGBoost还支持自定义损失函数,只要损失函数有一二阶导数。
(3)防止过拟合
A、正则化
XGBoost在目标函数中加入了正则项,用于惩罚过大的模型复杂度,有助于降低模型方差,防止过拟合。
B、Shrinkage(缩减)
主要是为了削弱每棵树的影响,让后面有更大的学习空间,学习过程更加的平缓。
C、列抽样
在建立决策树的时候,不用再遍历所有的特征了,可以进行抽样。
一方面简化了计算,另一方面也有助于降低过拟合。
(4)缺失值处理
(5)并行化操作
有一些不相关可以很好的支持并行计算
2、缺点
时间复杂度和空间复杂度都较高(预排序过程)。
欢迎大家在评论区批评指正,谢谢~


