
- 1论文解读 | 百度 ERNIE: Enhanced Representation through Knowledge Integration
- 2基于卡尔曼滤波的一阶电池系统的非线性状态估计_考虑单体电池soc不均匀等效电路模型
- 3哈工程计算机调剂系统开方时间,转需!2020考研调剂系统已开通:调剂时间、入口、流程来啦!...
- 4SpringBoot缓存注解@Cacheable之自定义key策略及缓存失效时间指定原创_@cacheable key
- 5Lua脚本操作redis_lua 写hset
- 6python对图像数据增强,包括翻转、镜像、加噪。_图像线下增强镜像旋转代码
- 7自然语言处理技术原理解析_nlp自然语言处理原理
- 8【今日CV 计算机视觉论文速览 92期】 2 Apr 2019_mao, chengsheng, liang yao, and yuan luo. "imagegc
- 9华为OD机试 - 农场施肥(Java)_最小施肥机能效
- 10【算法刷题day14】层次遍历、226.翻转二叉树、101.对称二叉树
Python入门基础知识总结
赞
踩
目录
一:简介:
Python 是一种解释型、面向对象的语言
Python的语法和动态类型,以及解释性语言的本质,使它成为多数平台上写脚本和快速开发应用的编程语言
二:Python基础语法
2.1.字面量
字面量:在代码中,被写下来的的固定的值,称之为字面量
Python中有6种常用的值(数据)的类型
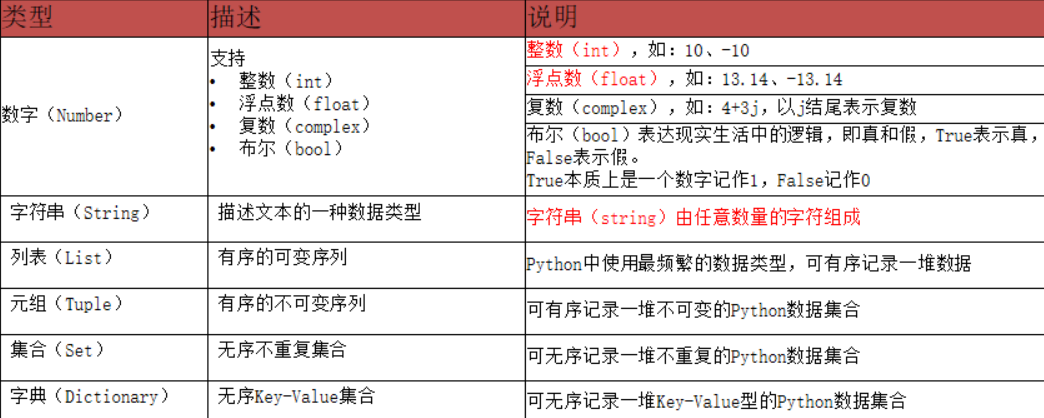
注意:type()语句可以查看变量存储的数据类型
2.2.注释
单行注释:以 #开头,#右边 的所有文字当作说明,而不是真正要执行的程序,起辅助说明作用

注意:#号和注释内容一般建议以一个空格隔开
多行注释: 以 一对三个双引号 引起来

2.3.数据类型转换
| 语句(函数) | 说明 |
| int(x) | 将x转换为一个整数 |
| float(x) | 将x转换为一个浮点数 |
| str(x) | 将对象 x 转换为字符串 |
2.4.标识符
标识符: 是用户在编程的时候所使用的一系列名字,用于给变量、类、方法等命名
标识符命名中,只允许出现: 英文 中文 数字 下划线(_) 这四类元素。
注意:不推荐使用中文,数字不可以开头,且不可使用关键字
2.5.运算符
算术(数学)运算符:
| 运算符 | 描述 | 实例 |
| + | 加 | 两个对象相加 a + b 输出结果 30 |
| - | 减 | 得到负数或是一个数减去另一个数 a - b 输出结果 -10 |
| * | 乘 | 两个数相乘或是返回一个被重复若干次的字符串 a * b 输出结果 200 |
| / | 除 | b / a 输出结果 2 |
| // | 取整除 | 返回商的整数部分 9//2 输出结果 4 , 9.0//2.0 输出结果 4.0 |
| % | 取余 | 返回除法的余数 b % a 输出结果 0 |
| ** | 指数 | a**b 为10的20次方, 输出结果 100000000000000000000 |
复合赋值运算符:
| 运算符 | 描述 | 实例 |
| += | 加法赋值运算符 | c += a 等效于 c = c + a |
| -= | 减法赋值运算符 | c -= a 等效于 c = c - a |
| *= | 乘法赋值运算符 | c *= a 等效于 c = c * a |
| /= | 除法赋值运算符 | c /= a 等效于 c = c / a |
| %= | 取模赋值运算符 | c %= a 等效于 c = c % a |
| **= | 幂赋值运算符 | c **= a 等效于 c = c ** a |
| //= | 取整除赋值运算符 | c //= a 等效于 c = c // a |
2.6.字符串
2.6.1.字符串的三种定义方式
单引号定义法: 双引号定义法: 三引号定义法:

其中,单引号定义法,可以内含双引号; 双引号定义法,可以内含单引号 ;并且可以使用转义字符(\)来将引号解除效用,变成普通字符串
2.6.2.字符串拼接
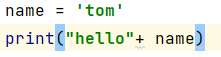
注意:字符串无法和非字符串变量进行拼接

默认print语句输出内容会自动换行,在print语句中,加上 end='' 即可输出不换行了
2.6.3.字符串格式化
我们可以通过如下语法,完成字符串和变量的快速拼接
| 格式符号 | 转化 |
| %s | 将内容转换成字符串,放入占位位置 |
| %d | 将内容转换成整数,放入占位位置 |
| %f | 将内容转换成浮点型,放入占位位置 |
如下代码,完成字符串、整数、浮点数,三种不同类型变量的占位
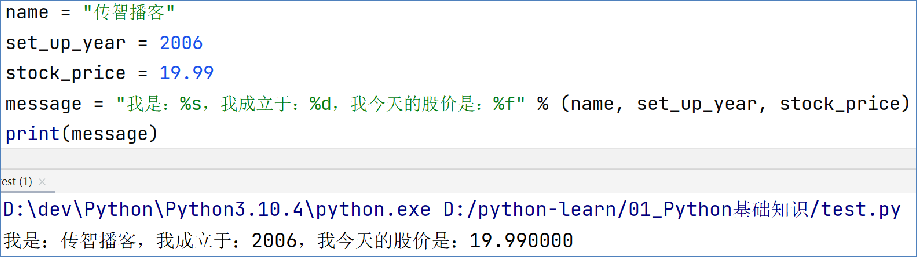
其中,% 表示占位符,且在无需使用变量进行数据存储的时候,可以直接格式化表达式(变量的位置放入表达式),简化代码
2.6.4.格式化的精度控制
我们可以使用辅助符号"m.n"来控制数据的宽度和精度
m,控制宽度,要求是数字,如果设置的宽度小于数字自身,则不生效
.n,控制小数点精度,要求是数字,会进行小数的四舍五入
示例: %5d:表示将整数的宽度控制在5位,如数字11,就会变成:[空格][空格][空格]11,用三个空格补足宽度。
%5.2f:表示将宽度控制为5,将小数点精度设置为2 。小数点和小数部分也算入宽度计算。如,对11.345设置了%7.2f 后,结果是:[空格][空格]11.35。2个空格补足宽度,小数部分限制2位精度后,四舍五入为 .35
%.2f:表示不限制宽度,只设置小数点精度为2,如11.345设置%.2f后,结果是11.35
2.6.5.字符串快速格式化
通过语法:f"内容{变量}"的格式来快速格式化

注意:这种写法不做精度控制,不理会类型
2.7.数据输入
使用input()语句可以从键盘获取输入
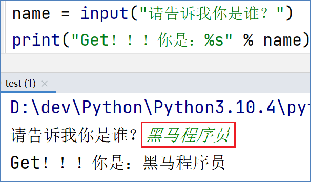
注意:无论键盘输入什么类型的数据,获取到的数据永远都是字符串类型
三:python判断语句
3.1.if语句的基本格式

归属于if判断的代码语句块,需在前方填充4个空格缩进
Python通过缩进判断代码块的归属关系。
3.2.if elif else语句
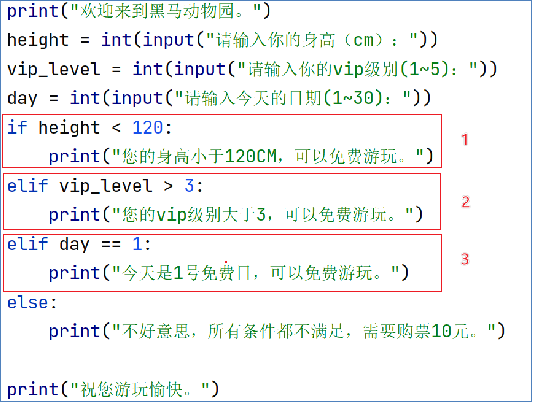
四:python循环语句
4.1.while循环

4.2.for循环

4.3.range语句
用于获得一个数字序列
语法1:range(num)
从0开始,到num结束(不含num本身)
语法2:range(num1, num2)
从0开始,到num结束(不含num本身)
语法3:range(num1, num2, step)
从0开始,到num结束(不含num本身)
五:Python函数
函数:是组织好的,可重复使用的,用来实现特定功能的代码段
函数的定义:

注意:如果函数没有使用return语句返回数据,会返回None这个字面量;在if判断中,None等同于False;定义变量,但暂时不需要变量有具体值,可以用None来代替
使用 global关键字 可以在函数内部声明变量为全局变量

六:Python数据容器
一种可以容纳多份数据的数据类型,容纳的每一份数据称之为1个元素。 每一个元素,可以是任意类型的数据
6.1.list(列表)
基本语法:

列表的方法:
| 编号 | 使用方式 | 作用 |
| 1 | 列表.append(元素) | 向列表的尾部追加一个元素 |
| 2 | 列表.extend(容器) | 将数据容器的内容(无结构)依次取出,追加到列表尾部 |
| 3 | 列表.insert(下标, 元素) | 在指定下标处,插入指定的元素 |
| 4 | del 列表[下标] | 删除列表指定下标元素 |
| 5 | 列表.pop(下标) | 删除列表指定下标元素(能得到返回值) |
| 6 | 列表.remove(元素) | 从前向后,删除此元素第一个匹配项 |
| 7 | 列表.clear() | 清空列表 |
| 8 | 列表.count(元素) | 统计此元素在列表中出现的次数 |
| 9 | 列表.index(元素) | 查找指定元素在列表的下标 找不到报错ValueError |
| 10 | len(列表) | 统计容器内有多少元素 |
列表特点:

6.2.tuple(元组)
基本语法:


注意:元组只有一个数据,这个数据后面要添加逗号
元组的方法:
| 编号 | 方法 | 作用 |
| 1 | index() | 查找某个数据,如果数据存在返回对应的下标,否则报错 |
| 2 | count() | 统计某个数据在当前元组出现的次数 |
| 3 | len(元组) | 统计元组内的元素个数 |
元组特点:
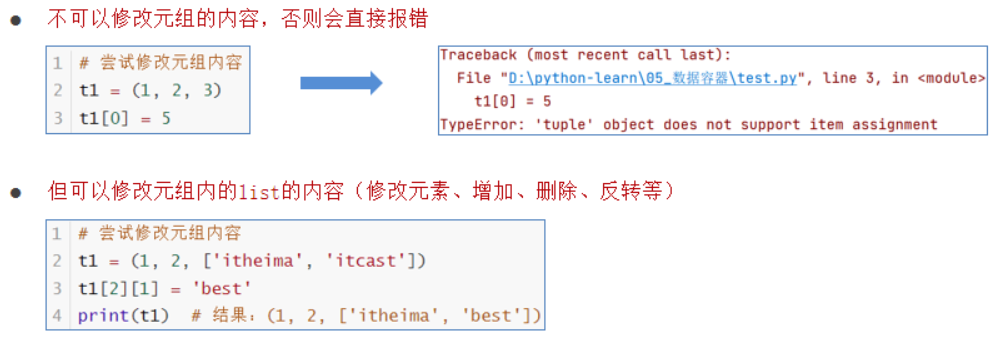
6.3.str(字符串)
字符串的方法:
| 编号 | 操作 | 说明 |
| 1 | 字符串[下标] | 根据下标索引取出特定位置字符 |
| 2 | 字符串.index(字符串) | 查找给定字符的第一个匹配项的下标 |
| 3 | 字符串.replace(字符串1, 字符串2) | 将字符串内的全部字符串1,替换为字符串2 不会修改原字符串,而是得到一个新的 |
| 4 | 字符串.split(字符串) | 按照给定字符串,对字符串进行分隔 不会修改原字符串,而是得到一个新的列表 |
| 5 | 字符串.strip() 字符串.strip(字符串) | 移除首尾的空格和换行符 或指定字符串 |
| 6 | 字符串.count(字符串) | 统计字符串内某字符串的出现次数 |
| 7 | len(字符串) | 统计字符串的字符个数 |
字符串特点:
字符串容器可以容纳的类型是单一的,只能是字符串类型。
字符串不可以修改,如果必须要修改,只能得到一个新的字符串,旧的字符串是无法修改
6.4.序列的切片
序列是指:内容连续、有序,可使用下标索引的一类数据容器
列表、元组、字符串,均可以可以视为序列
语法:序列[起始下标:结束下标:步长]
表示从序列中,从指定位置开始,依次取出元素,到指定位置结束,得到一个新序列
- 起始下标表示从何处开始,可以留空,留空视作从头开始
- 结束下标(不含)表示何处结束,可以留空,留空视作截取到结尾
- 步长表示,依次取元素的间隔
- 步长为负数表示,反向取(注意,起始下标和结束下标也要反向标记)

6.5.set(集合)
基本语法:

集合的方法:
| 编号 | 操作 | 说明 |
| 1 | 集合.add(元素) | 集合内添加一个元素 |
| 2 | 集合.remove(元素) | 移除集合内指定的元素 |
| 3 | 集合.pop() | 从集合中随机删除一个元素并返回 |
| 4 | 集合.clear() | 将集合清空 |
| 5 | 集合1.difference(集合2) | 得到一个新集合,内含2个集合的差集 原有的2个集合内容不变 |
| 6 | 集合1.difference_update(集合2) | 在集合1中,删除集合2中存在的元素 集合1被修改,集合2不变 |
| 7 | 集合1.union(集合2) | 得到1个新集合,内含2个集合的全部元素 原有的2个集合内容不变 |
| 8 | len(集合) | 得到一个整数,记录了集合的元素数量 |
集合特点:
相较于列表、元组、字符串来说,不支持元素的重复(自带去重功能)、并且内容无序
6.6.dict(字典)
字典定义

字典的常用操作:
| 编号 | 操作 | 说明 |
| 1 | 字典[Key] | 获取指定Key对应的Value值 |
| 2 | 字典[Key] = Value | 添加或更新键值对 |
| 3 | 字典.pop(Key) | 取出Key对应的Value并在字典内删除此Key的键值对 |
| 4 | 字典.clear() | 清空字典 |
| 5 | 字典.keys() | 获取字典的全部Key,可用于for循环遍历字典 |
| 6 | len(字典) | 计算字典内的元素数量 |
字典特点:
- 键值对的Key和Value可以是任意类型(Key不可为字典)
- 字典内Key不允许重复,重复添加等同于覆盖原有数据
- 字典不可用下标索引,而是通过Key检索Value
6.7.数据容器的通用操作
数据容器特点对比:
| 列表 | 元组 | 字符串 | 集合 | 字典 | |
| 元素数量 | 支持多个 | 支持多个 | 支持多个 | 支持多个 | 支持多个 |
| 元素类型 | 任意 | 任意 | 仅字符 | 任意 | Key:Value Key:除字典外任意类型 Value:任意类型 |
| 下标索引 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 重复元素 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 可修改性 | 支持 | 不支持 | 不支持 | 支持 | 支持 |
| 数据有序 | 是 | 是 | 是 | 否 | 否 |
| 使用场景 | 可修改、可重复的一批数据记录场景 | 不可修改、可重复的一批数据记录场景 | 一串字符的记录场景 | 不可重复的数据记录场景 | 以Key检索Value的数据记录场景 |
容器通用功能:
| 功能 | 描述 |
| 通用for循环 | 遍历容器(字典是遍历key) |
| max | 容器内最大元素 |
| min() | 容器内最小元素 |
| len() | 容器元素个数 |
| list() | 转换为列表 |
| tuple() | 转换为元组 |
| str() | 转换为字符串 |
| set() | 转换为集合 |
| sorted(序列, [reverse=True]) | 排序,reverse=True表示降序 得到一个排好序的列表 |
七:Python函数进阶
7.1.函数多返回值

按照返回值的顺序,写对应顺序的多个变量接收即可 变量之间用逗号隔开
7.2.函数多种传参方式
7.2.1.位置参数
调用函数时根据函数定义的参数位置来传递参

传递的参数和定义的参数的顺序及个数必须一致
7.2.2.关键字参数
函数调用时通过“键=值”形式传递参数

7.2.3.缺省参数
缺省参数也叫默认参数,用于定义函数,为参数提供默认值,调用函数时可不传该默认参数的值(注意:所有位置参数必须出现在默认参数前,包括函数定义和调用)

函数调用时,如果为缺省参数传值则修改默认参数值, 否则使用这个默认值
7.2.4.不定长参数
不定长参数也叫可变参数. 用于不确定调用的时候会传递多少个参数(不传参也可以)的场景.
不定长参数的类型: ①位置传递 ②关键字传递
1.位置传递

传进的所有参数都会被args变量收集,它会根据传进参数的位置合并为一个元组(tuple),args是元组类型,这就是位置传递
2.关键字传递

参数是“键=值”形式的形式的情况下, 所有的“键=值”都会被kwargs接受, 同时会根据“键=值”组成字典.
7.2.5.函数作为参数传递

7.3.匿名函数
函数的定义中
- def关键字,可以定义带有名称的函数
- lambda关键字,可以定义匿名函数(无名称)
有名称的函数,可以基于名称重复使用。 无名称的匿名函数,只可临时使用一次
匿名函数定义语法:
![]()
- lambda 是关键字,表示定义匿名函数
- 传入参数表示匿名函数的形式参数,如:x, y 表示接收2个形式参数
- 函数体,就是函数的执行逻辑,要注意:只能写一行,无法写多行代码

八:Python文件操作
8.1.文件的读取
mode常用的三种基础访问模式:
| 模式 | 描述 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,原有内容会被删除。 如果该文件不存在,创建新文件。 |
| a | 打开一个文件用于追加。如果该文件已存在,新的内容将会被写入到已有内容之后。 如果该文件不存在,创建新文件进行写入。 |
| 操作 | 功能 |
| 文件对象 = open(file, mode, encoding) | 打开文件获得文件对象 |
| 文件对象.read(num) | 读取指定长度字节 不指定num读取文件全部 |
| 文件对象.readline() | 读取一行 |
| 文件对象.readlines() | 读取全部行,得到列表 |
| for line in 文件对象 | for循环文件行,一次循环得到一行数据 |
| 文件对象.close() | 关闭文件对象 |
| with open() as f | 通过with open语法打开文件,可以自动关闭 |
8.2.文件的写入

- 直接调用write,内容并未真正写入文件,而是会积攒在程序的内存中,称之为缓冲区
- 当调用flush的时候,内容会真正写入文件
- 这样做会频繁的操作硬盘,导致效率下降
九:Python异常、模块与包
9.1.异常的捕获
在可能发生异常的地方,进行捕获。当异常出现的时候,提供解决方式,而不是任由其导致程序无法运行。

异常的种类多种多样,如果想要不管什么类型的异常都能捕获到,那么使用:except Exception as e:
9.2.Python模块
模块(Module),是一个 Python 文件,以 .py 结尾. 模块能定义函数,类和变量,模块里也能包含可执行的代码
模块的导入方式:
![]()
常用的组合形式如:
- import 模块名
- from 模块名 import 类、变量、方法等
- from 模块名 import *
- import 模块名 as 别名
- from 模块名 import 功能名 as 别名
自定义模块:
每个Python文件都可以作为一个模块,模块的名字就是文件的名字
在实际开发中,当一个开发人员编写完一个模块后,为了让模块能够在项目中达到想要的效果, 这个开发人员会自行在py文件中添加一些测试信息,但是在模块导入的时候都会自动执行`test`函数的调用
解决方案:

如果一个模块文件中有`_ _all_ _`变量,当使用`from xxx import *`导入时,只能导入这个列表中的元素

9.3.Python包
从物理上看,包就是一个文件夹,在该文件夹下自动创建了一个 _ _init_ _.py 文件,该文件夹可用于包含多个模块文件 从逻辑上看,包的本质依然是模块
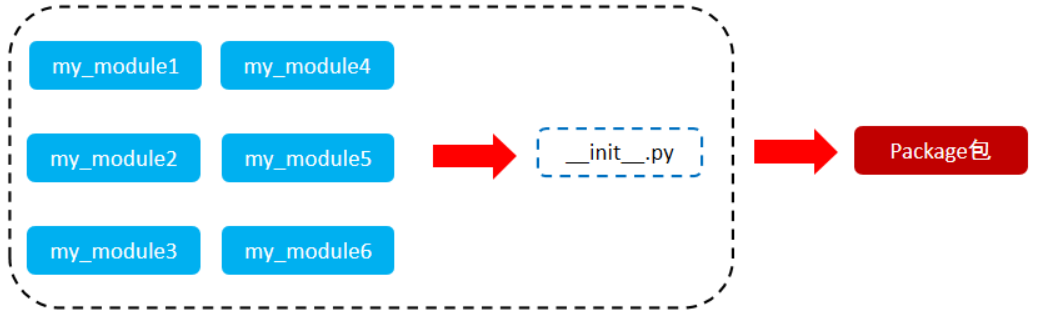
当我们的模块文件越来越多时,包可以帮助我们管理这些模块, 包的作用就是包含多个模块,但包的本质依然是模块
导入包:
1.import 包名.模块名 调用:包名.模块名.目标
2.from 包名 import * 必须在`__init__.py`文件中添加`__all__ = []`,控制允许导入的模块列表
十:面向对象
10.1.成员方法

在Python中,如果将函数定义为class(类)的成员,那么函数会称之为:方法

方法和函数功能一样, 有传入参数,有返回值,只是方法的使用格式不同:

在类中定义成员方法和定义函数基本一致,但仍有细微区别:

可以看到,在方法定义的参数列表中,有一个:self关键字 ,它是成员方法定义的时候,必须填写的,但是传参的时候可以忽略它
- 它用来表示类对象自身的意思
- 当我们使用类对象调用方法的是,self会自动被python传入
- 在方法内部,想要访问类的成员变量,必须使用self
10.2.构造方法
基于类创建对象的语法:
![]()
Python类可以使用:_ _init_ _()方法,称之为构造方法
在创建类对象(构造类)的时候,会自动执行,并将传入参数自动传递给__init__方法使用

10.3.封装
面向对象编程,是基于模板(类)去创建实体(对象),使用对象完成功能开发
面向对象包含3大主要特性:封装 继承 多态
将现实世界事物在类中描述为属性和方法,即为封装

现实事物有部分属性和行为是不公开对使用者开放的。同样在类中描述属性和方法的时候也需要达到这个要求,就需要定义私有成员了
成员变量和成员方法的命名均以_ _作为开头即可
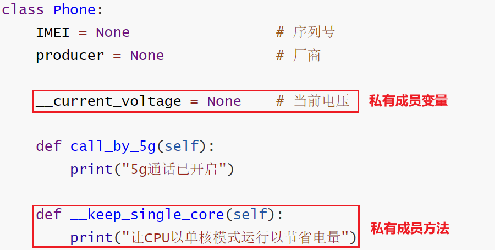
私有成员无法被类对象使用,但是可以被其它的成员使用。

10.4.继承
继承:将从父类那里继承(复制)来成员变量和成员方法(不含私有)
单继承:

多继承:

多个父类中,如果有同名的成员,那么默认以继承顺序(从左到右)为优先级
pass是占位语句,用来保证函数(方法)或类定义的完整性,表示无内容,空的意思
复写:
子类继承父类的成员属性和成员方法后,如果对其“不满意”,那么可以进行复写。即在子类中重新定义同名的属性或方法即可

一旦复写父类成员,那么类对象调用成员的时候,就会调用复写后的新成员 如果需要使用被复写的父类的成员,需要特殊的调用方式:


注意:只能在子类内调用父类的同名成员,子类的类对象直接调用会调用子类复写的成员
10.5.多态
多态:指的是完成某个行为时,使用不同的对象会得到不同的状态,多态常作用在继承关系上

抽象类(接口):含有抽象方法的类称之为抽象类
抽象方法:方法体是空实现的(pass)称之为抽象方法
抽象类多用于做顶层设计(设计标准),以便子类做具体实现,要求子类必须复写(实现)父类的一些方法

