
- 1什么是迭代和增量开发_对迭代开发和增量开发
- 2【VUE/H5】H5调起数字键盘的坑,及手写移动端键盘代码_type="number" 调出数字键盘
- 3Linux下使用sed命令卡死_linux sed 坑
- 4C#模拟鼠标和键盘操作_c# 模拟键盘鼠标包
- 5配置运行video retalking遇到的问题和注意事项_videoretalking 模型下载
- 6linux shell下修改分辨率_xshell分辨率调整
- 7【0基础入门Pytorch】Pytorch的简介与安装(Windows)_pytorch容器启动后,访问是什么界面
- 8[Xcode]iOS代码签名(Code Signing)_xcode11 signing
- 9宇视出入口PMS注册停车云指导
- 10把一个字符串中的大写字母和小写字母分别存储到一个新的字符串中_输入字符串,分别提取出小写与大写字母,分别保存
python自然语言处理库_Python之gensim自然语言处理库
赞
踩
gensim是一个python的自然语言处理库,能够将文档根据TF-IDF, LDA, LSI 等模型转化成向量模式,以便进行进一步的处理。此外,gensim还实现了word2vec功能,能够将单词转化为词向量。关于词向量的知识可以看我之前的文章
关于gensim的使用方法,我是根据官网的资料来看的,思路也是跟着官网tutorial走的,英文好的或者感觉我写的不全面的可以去官网看
1. corpora 和 dictionary
1.1 基本概念和用法
corpora是gensim中的一个基本概念,是文档集的表现形式,也是后续进一步处理的基础。从本质上来说,corpora其实是一种格式或者说约定,其实就是一个二维矩阵。举个例子,现在有一个文档集,里面有两篇文档
hurry up
rise up
1
2
这两篇文档里总共出现了3个词,hurry, rise, up。如果将这3个词映射到数字,比如说hurry, rise, up 分别对应1,2,3, 那么上述的文档集的一种表现形式可以是
1,0,1
0,1,1
1
2
这种方法只考虑了词频,且不考虑词语间的位置关系。因为第一个文档中的两个词分别编号1,3且都只出现了一次,所以第1个和第3个为1,第2个数为0。
当然了,在实际运行中,因为单词数量极多(上万甚至10万级别),而一篇文档的单词数是有限的,所以如果还是采用密集矩阵来表示的话,会造成极大的内存浪费,所以gensim内部是用稀疏矩阵的形式来表示的。
那么,如何将字符串形式的文档转化成上述形式呢?这里就要提到词典的概念(dictionary)。词典是所有文档中所有单词的集合,而且记录了各词的出现次数等信息。
在实际的操作中,对于字符串形式的文档,首先要将字符串分割成词语列表。比如”hurry up”要分割成[“hurry”,”up”]。 对于中文来讲,分词就是一个很关键的问题,不过可以去找一些分词库来实现。我一般用的是jieba. 而对于英文来说,虽然分词方便,但是要注意词干提取和词形还原。
在将文档分割成词语之后,使用dictionary = corpora.Dictionary(texts)生成词典,并可以使用save函数将词典持久化。生成词典以后corpus = [dictionary.doc2bow(text) for text in texts]档转化为向量形式。示例代码如下
from gensim import corpora
from collections import defaultdict
documents = ["Human machine interface for lab abc computer applications",
"A survey of user opinion of computer system response time",
"The EPS user interface management system",
"System and human system engineering testing of EPS",
"Relation of user perceived response time to error measurement",
"The generation of random binary unordered trees",
"The intersection graph of paths in trees",
"Graph minors IV Widths of trees and well quasi ordering",
"Graph minors A survey"]
# 去掉停用词
stoplist = set('for a of the and to in'.split())
texts = [[word for word in document.lower().split() if word not in stoplist]
for document in documents]
# 去掉只出现一次的单词
frequency = defaultdict(int)
for text in texts:
for token in text:
frequency[token] += 1
texts = [[token for token in text if frequency[token] > 1]
for text in texts]
dictionary = corpora.Dictionary(texts) # 生成词典
# 将文档存入字典,字典有很多功能,比如
# diction.token2id 存放的是单词-id key-value对
# diction.dfs 存放的是单词的出现频率
dictionary.save('/tmp/deerwester.dict') # store the dictionary, for future reference
corpus = [dictionary.doc2bow(text) for text in texts]
corpora.MmCorpus.serialize('/tmp/deerwester.mm', corpus) # store to disk, for later use
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
注意最后的corpora.MmCorpus.serialize 将corpus持久化到磁盘中。相反,可以用
corpus = corpora.MmCorpus('/tmp/deerwester.mm')
1
来从磁盘中读取corpus。
除了MmCorpus以外,还有其他的格式,例如SvmLightCorpus, BleiCorpus, LowCorpus等等,用法类似。
1.2 dictionary的其他一些用法
dictionary还有其他的一些用法,现罗列一部分
dictionary.filter_n_most_frequent(N)
过滤掉出现频率最高的N个单词
dictionary.filter_extremes(no_below=5, no_above=0.5, keep_n=100000)
1.去掉出现次数低于no_below的
2.去掉出现次数高于no_above的。注意这个小数指的是百分数
3.在1和2的基础上,保留出现频率前keep_n的单词
dictionary.filter_tokens(bad_ids=None, good_ids=None)
有两种用法,一种是去掉bad_id对应的词,另一种是保留good_id对应的词而去掉其他词。注意这里bad_ids和good_ids都是列表形式
dictionary.compacity()
在执行完前面的过滤操作以后,可能会造成单词的序号之间有空隙,这时就可以使用该函数来对词典来进行重新排序,去掉这些空隙。
1.3 分批处理和分布式计算结果的汇总
dictionary和corpora的基本用法在上一节已经提过,但是当文本的规模很大时,也许会造成内存不足以容纳文本的情况,这就需要将所有文本分批处理,最后再将各批次计算得到的结果进行汇总。分布式计算时也有类似的需求。
这里假设在两个批次中,分别生成了dict1,corpus1以及dict2,corpus2.
第一步,首先将两个词典合并。当然,如果是先统一生成词典再分批生成词向量的话,可以跳过这一步,因为词典是一样的。
合并词典很简单
dict2_to_dict1 =dict1.merge_with(dict2)
1
要注意的是,得到的dict2_to_dict1并不是生成后的词典,而是dict2中的单词序号到这些词在合并后词典新序号的映射表。而dict1本身成为合并后的新词典。
第二部,合并corpus
如果之前跳过了第一步,即dict1就是dict2的话,可以直接进行合并。合并有两种方式,一种是
merged_corpus = [x for x in corpus1] + [x for x in corpus2]
1
另外一种,则需使用内置的itertools类
merged_corpus = itertools.chain(corpus1, corpus2)
merged_corpus = [x for x in merged_corpus]
1
2
如果之前的词典也是分批生成的话,则需要对corpus2进行一定的处理
new_corpus2 = dict2_to_dict1[corpus2]
merged_corpus = itertools.chain(corpus1, new_corpus2)
merged_corpus = [x for x in merged_corpus]
1
2
3
这样,就把分批处理得到的dict和corpus都合并起来了。
2. models
在models中,可以对corpus进行进一步的处理,比如使用tf-idf模型,lsi模型,lda模型等,非常强大。
在按照之前的方法生成了corpus和dictionary以后,就可以生成模型了
tfidf_model =models.TfidfModel(corpus)
1
注意,目前只是生成了一个模型,但这是类似于生成器,并不是将对应的corpus转化后的结果。对tf-idf模型而言,里面存储有各个单词的词频,文频等信息。想要将文档转化成tf-idf模式表示的向量,还要使用如下命令
corpus_tfidf =tfidf_model[corpus]
1
对于lda和lsi模型,用法有所不同
lsi_model = models.LsiModel(corpus_tfidf, id2word=dictionary, num_topics=2)
corpus_lsi = lsi_model[corpus_tfidf]
1
2
可以看到,这里除了corpus以外,还多了num_topic的选项。这是指的潜在主题(topic)的数目,也等于转成lsi模型以后每个文档对应的向量长度。转化以后的向量在各项的值,即为该文档在该潜在主题的权重。因此lsi和lda的结果也可以看做该文档的文档向量,用于后续的分类,聚类等算法。值得注意的是,id2word是所有模型都有的选项,可以指定使用的词典。
由于这里num_topics=2 ,所以可以用作图的方式直观的显现出来
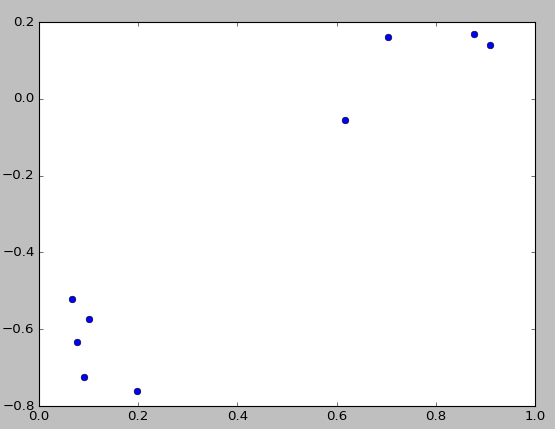
可以很清楚的看到,9个文档可以看成两类,分别是前5行和后4行。
这一部分的代码如下
import os
from gensim import corpora, models, similarities
from pprint import pprint
from matplotlib import pyplot as plt
import logging
# logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
def PrintDictionary(dictionary):
token2id = dictionary.token2id
dfs = dictionary.dfs
token_info = {}
for word in token2id:
token_info[word] = dict(
word = word,
id = token2id[word],
freq = dfs[token2id[word]]
)
token_items = token_info.values()
token_items = sorted(token_items, key = lambda x:x['id'])
print('The info of dictionary: ')
pprint(token_items)
print('--------------------------')
def Show2dCorpora(corpus):
nodes = list(corpus)
ax0 = [x[0][1] for x in nodes] # 绘制各个doc代表的点
ax1 = [x[1][1] for x in nodes]
# print(ax0)
# print(ax1)
plt.plot(ax0,ax1,'o')
plt.show()
if (os.path.exists("/tmp/deerwester.dict")):
dictionary = corpora.Dictionary.load('/tmp/deerwester.dict')
corpus = corpora.MmCorpus('/tmp/deerwester.mm')
print("Used files generated from first tutorial")
else:
print("Please run first tutorial to generate data set")
PrintDictionary(dictionary)
# 尝试将corpus(bow形式) 转化成tf-idf形式
tfidf_model = models.TfidfModel(corpus) # step 1 -- initialize a model 将文档由按照词频表示 转变为按照tf-idf格式表示
doc_bow = [(0, 1), (1, 1),[4,3]]
doc_tfidf = tfidf_model[doc_bow]
# 将整个corpus转为tf-idf格式
corpus_tfidf = tfidf_model[corpus]
# pprint(list(corpus_tfidf))
# pprint(list(corpus))
## LSI模型 **************************************************
# 转化为lsi模型, 可用作聚类或分类
lsi_model = models.LsiModel(corpus_tfidf, id2word=dictionary, num_topics=2)
corpus_lsi = lsi_model[corpus_tfidf]
nodes = list(corpus_lsi)
# pprint(nodes)
lsi_model.print_topics(2) # 打印各topic的含义
# ax0 = [x[0][1] for x in nodes] # 绘制各个doc代表的点
# ax1 = [x[1][1] for x in nodes]
# print(ax0)
# print(ax1)
# plt.plot(ax0,ax1,'o')
# plt.show()
lsi_model.save('/tmp/model.lsi') # same for tfidf, lda, ...
lsi_model = models.LsiModel.load('/tmp/model.lsi')
# *********************************************************
## LDA模型 **************************************************
lda_model = models.LdaModel(corpus_tfidf, id2word=dictionary, num_topics=2)
corpus_lda = lda_model[corpus_tfidf]
Show2dCorpora(corpus_lsi)
# nodes = list(corpus_lda)
# pprint(list(corpus_lda))
# 此外,还有Random Projections, Hierarchical Dirichlet Process等模型
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
3. similarities
这一部分主要负责计算文档间的相似度。与向量的相似度计算方式一样,采用余弦方法计算得到。一般来讲,使用lsi模型得到的向量进行计算效果比较好。
corpus_simi_matrix = similarities.MatrixSimilarity(corpus_lsi)
# 计算一个新的文本与既有文本的相关度
test_text = "Human computer interaction".split()
test_bow = dictionary.doc2bow(test_text)
test_tfidf = tfidf_model[test_bow]
test_lsi = lsi_model[test_tfidf]
test_simi = corpus_simi_matrix[test_lsi]
print(list(enumerate(test_simi)))
1
2
3
4
5
6
7
8
得到结果[(0, 0.99916452), (1, 0.99632162), (2, 0.9990505), (3, 0.99886364), (4, 0.99996823), (5, -0.058117405), (6, -0.021589279), (7, 0.013524055), (8, 0.25163394)]。可以看到显然属于第一类


