
- 1双指针仪表盘读数(二) ——表盘位置识别_指针仪表 多圈刻度圈识别
- 2文本特征属性选择_ifi文档的词条频率
- 3OpenCV探索之路(二十三):特征检测和特征匹配方法汇总_opencv特征点检测与匹配
- 4ssm+Vue计算机毕业设计疫情信息管理系统(程序+LW文档)_疫情历史数据系统e-r图
- 5pytorch 笔记: torch.nn.Embedding_pytorch embeding的权重
- 6JVM性能调优详解_directmemorysize 优化
- 7TypeScript 基础 - 05 (模块的导入、导出)_ts export default
- 8自然语言处理中的命名实体识别:技术与挑战
- 9基于Springboot框架高校学校实验室预约系统设计与实现(安装部署+源码+文档)
- 10RabbitMQ的五种消息模型_rabbitmq五种消息模型
NÜWA:女娲算法,多模态预训练模型,大杀四方!(附源代码下载)
赞
踩
关注并星标
从此不迷路
计算机视觉研究院


公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式

论文地址:https://arxiv.org/abs/2111.12417
源代码:https:// github.com/microsoft/NUWA
计算机视觉研究院专栏
作者:Edison_G
最近看到一篇论文,名字首先吸引了,内容大概看了后,觉得还是不错的,今天有幸给大家慢慢分享,有兴趣的同学可以阅读论文,深入继续了解!
一、前言
今天分享的论文,主要提出了一个统一的多模态预训练模型,称为NÜWA,可以为各种视觉合成任务生成新的或操纵现有的视觉数据(即图像和视频)。针对不同场景同时覆盖语言、图像和视频,设计了3D Transformer编码器-解码器框架,不仅可以将视频作为3D数据处理,还可以分别将文本和图像作为1D和2D数据进行适配。还提出了3D Nearby Attention(3DNA)机制来考虑视觉数据的性质并降低计算复杂度。在8个下游任务上评估NÜWA。与几个强大的基线相比,NÜWA在文本到图像生成、文本到视频生成、视频预测等方面取得了最先进的结果。此外,它还显示了令人惊讶的良好的文本零样本能力——引导图像和视频处理任务。
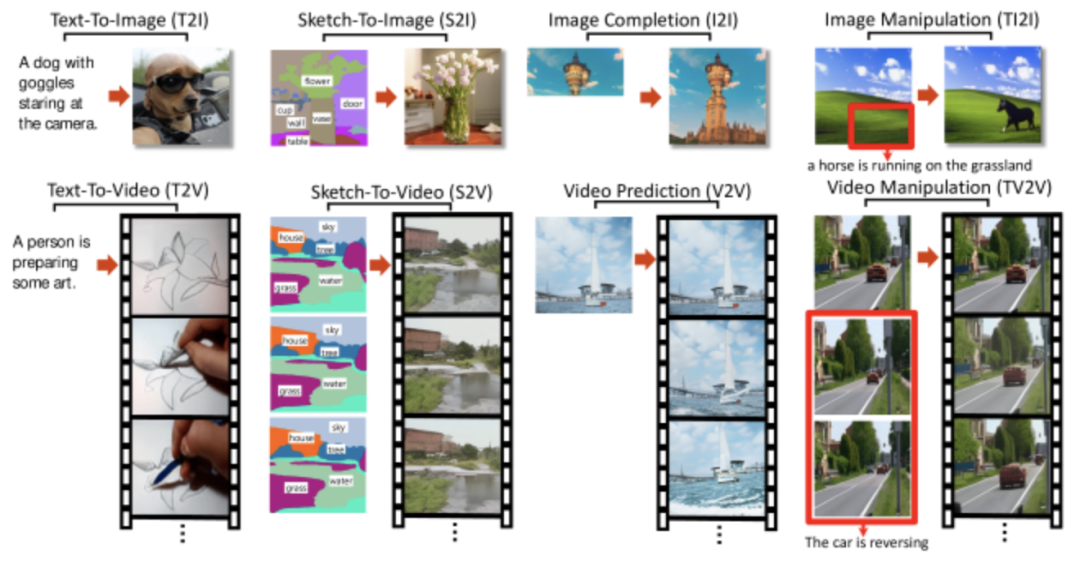
8个任务的案例
二、背景
如今,网络变得比以往任何时候都更加视觉化,图像和视频已成为新的信息载体,并已被用于许多实际应用中。在此背景下,视觉合成正成为越来越受欢迎的研究课题,其目的是构建可以为各种视觉场景生成新的或操纵现有视觉数据(即图像和视频)的模型。
自回归模型【Auto-regressive models】在视觉合成任务中发挥着重要作用,因为与GAN相比,它们具有显式的密度建模和稳定的训练优势。早期的视觉自回归模型,如PixelCNN、PixelRNN、Image Transformer、iGPT和Video Transformer,都是以“pixel-by-pixel”的方式进行视觉合成的。然而,由于它们在高维视觉数据上的高计算成本,这些方法只能应用于低分辨率的图像或视频,并且难以扩展。
最近,随着VQ-VAE作为离散视觉标记化方法的出现,高效和大规模的预训练可以应用于图像的视觉合成任务(例如DALL-E和CogView) 和视频(例如GODIVA)。尽管取得了巨大的成功,但此类解决方案仍然存在局限性——它们分别处理图像和视频,并专注于生成它们中的任何一个。这限制了模型从图像和视频数据中受益。
三、NÜWA的表现
Text-To-Image(T2I)

一只戴着护目镜,盯着摄像机的狗

Sketch-To-Image (S2I)

草图转图片任务,就是根据草图的布局,生成对应的图片
Image Completion (I2I)

图像补全,如果一副图片残缺了,算法可以自动“脑补”出残缺的部分
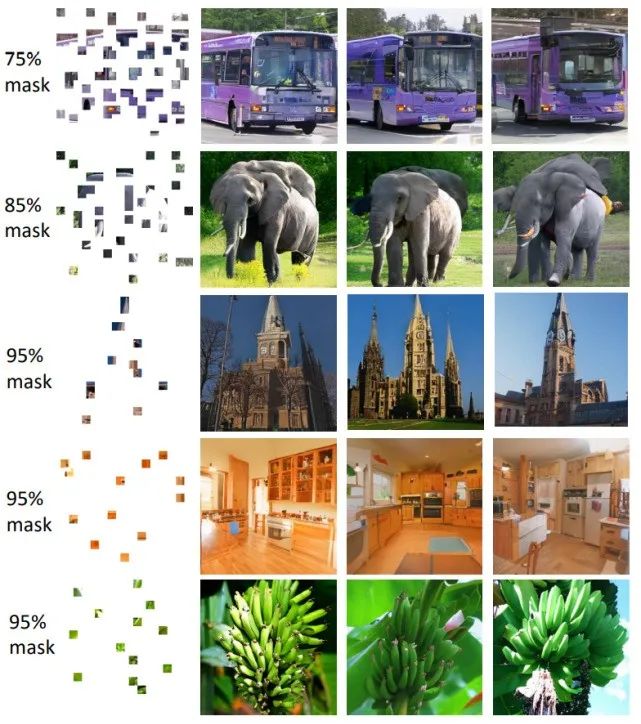
Image Manipulation (TI2I)

图片处理,根据文字描述,处理图片
例如:有一副草原的图片,然后增加一段描述:一匹马奔跑在草原上,然后就可以生成对应的图片。

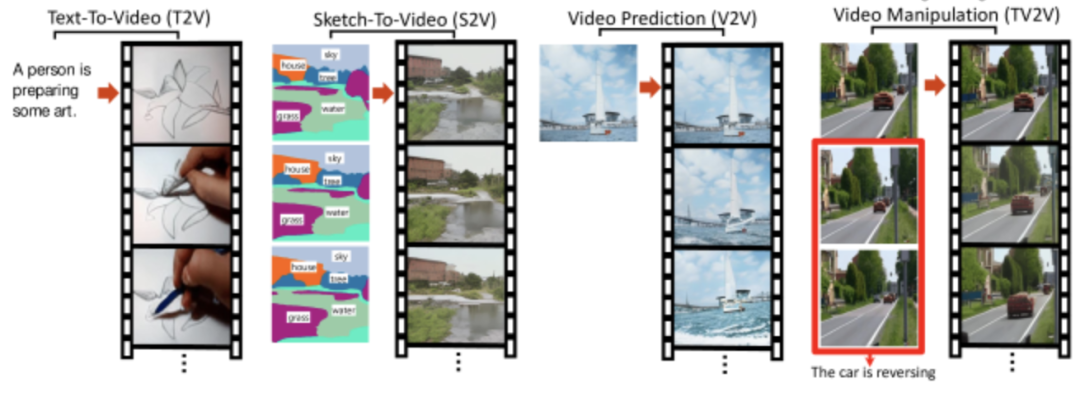
Video
四、新框架
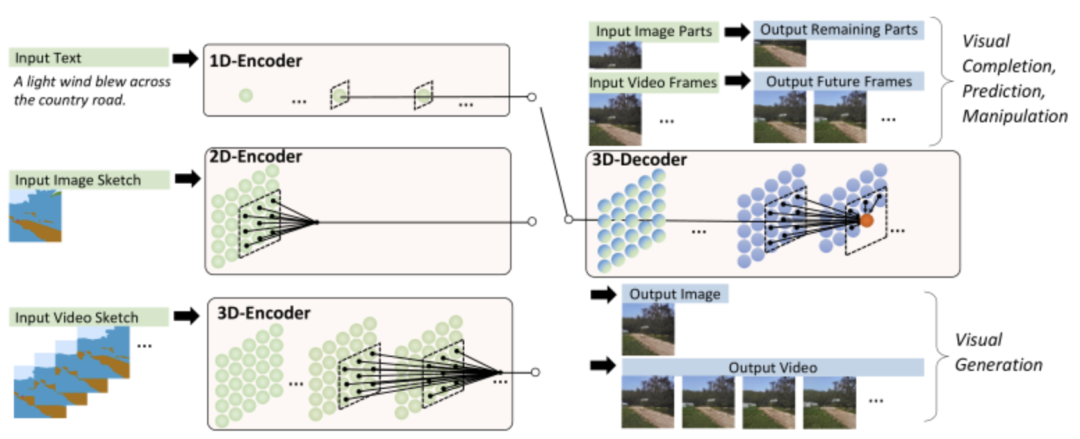
NÜWA模型的整体架构包含一个支持多种条件的 adaptive 编码器和一个预训练的解码器,能够同时使图像和视频的信息。对于图像补全、视频预测、图像处理和视频处理任务,将输入的部分图像或视频直接送入解码器即可。
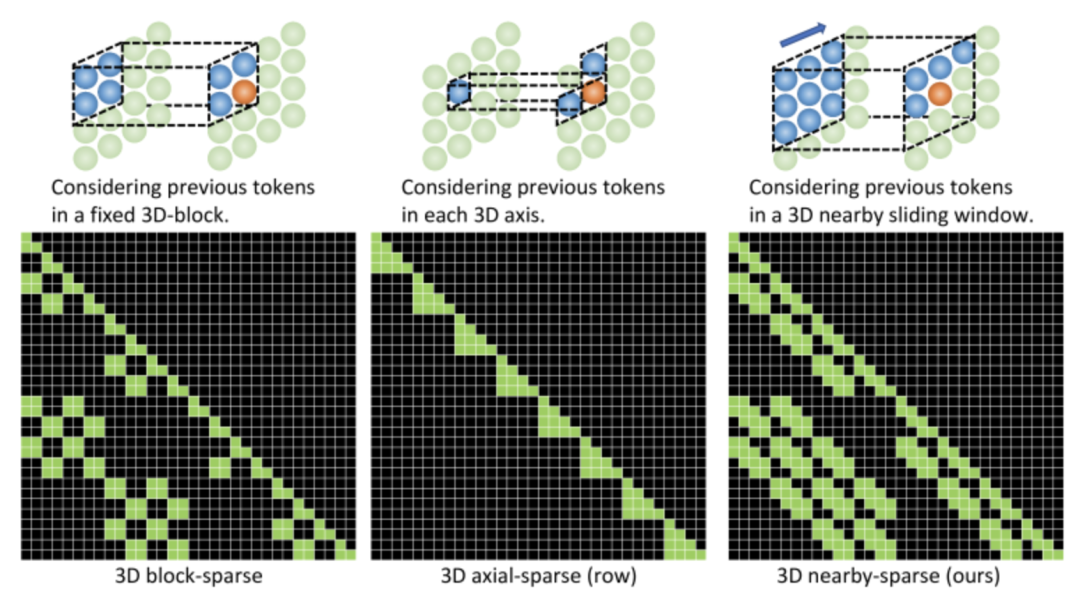
而编码解码器都是基于一个3D NEARBY SELF-ATTENTION(3DNA)建立的,该机制可以同时考虑空间和时间轴的上局部特性,定义如下:
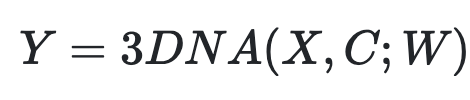
W 表示可学习的权重,X 和 C 分别代表文本、图像、视频数据的 3D 表示。
3DNA考虑了完整的邻近信息,并为每个token动态生成三维邻近注意块。注意力矩阵还显示出3DNA的关注部分(蓝色)比三维块稀疏注意力和三维轴稀疏注意力更平滑。
3D DATA REPRESENTATION
为了涵盖所有文本、图像和视频或其草图,研究者将它们全部视为标记并定义统一的 3D符号X∈Rh×w×s×d,其中h和w表示空间轴(分别为高度和宽度)中的标记数量,s表示时间轴上的标记数量,d是每个标记的维度。
3D NEARBY SELF-ATTENTION
基于之前的3D数据表示定义了一个统一的3D Nearby Self-Attention (3DNA) 模块,支持自注意力和交叉注意力。首先给出方程中3DNA的定义:
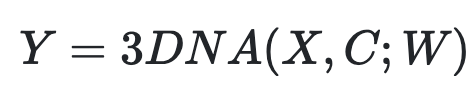
并在如下等式中介绍详细的实现。
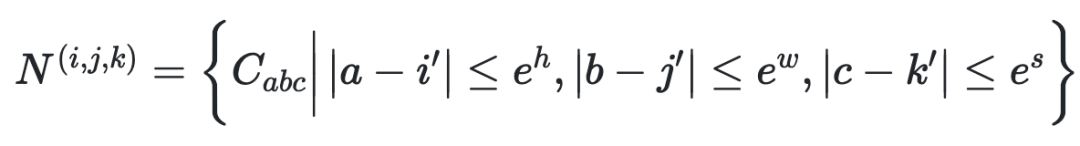

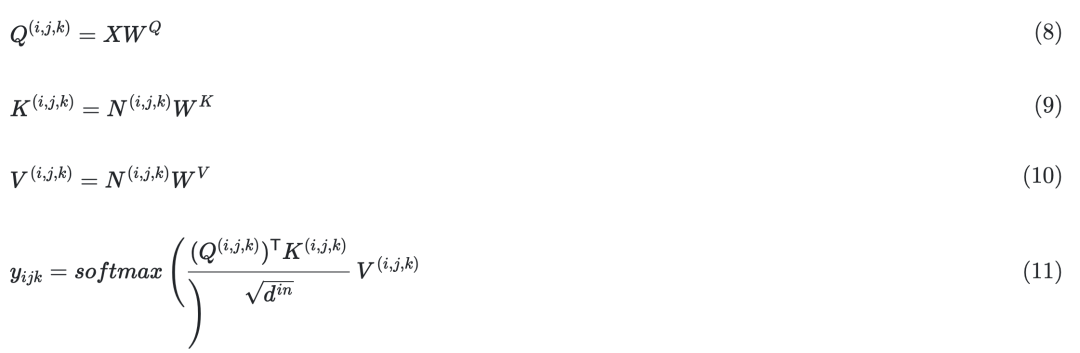
3D ENCODER-DECODER
开始介绍基于3DNA构建的3D编码-解码器。为了在C∈Rh′×w′×s′×din的条件下生成目标Y∈Rh×w×s×dout,Y和C的位置编码通过考虑高度、宽度和时间轴的三个不同的可学习词汇更新。
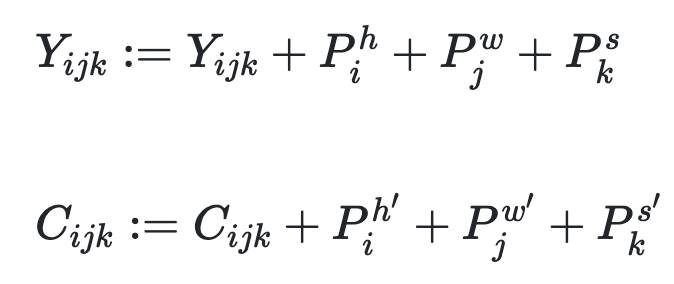
然后,条件C被输入到具有L 3DNA层堆栈的编码器中,以对自注意力交互进行建模,第l层在等式中表示:
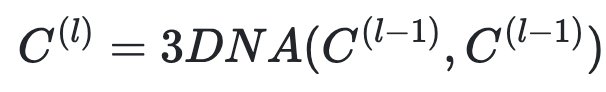
同样,解码器也是一堆L 3DNA层。解码器计算生成结果的自注意力以及生成结果和条件之间的交叉注意力。第l层表示如下等式。
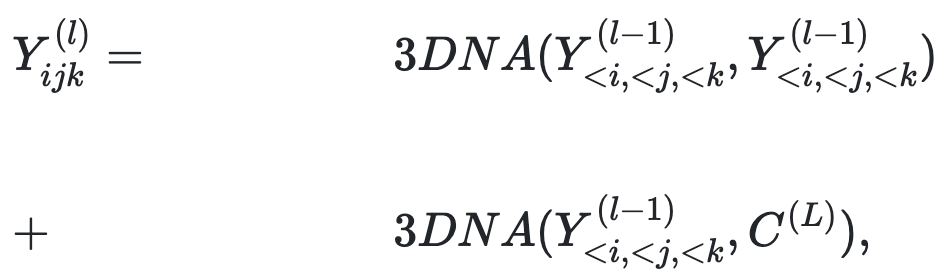
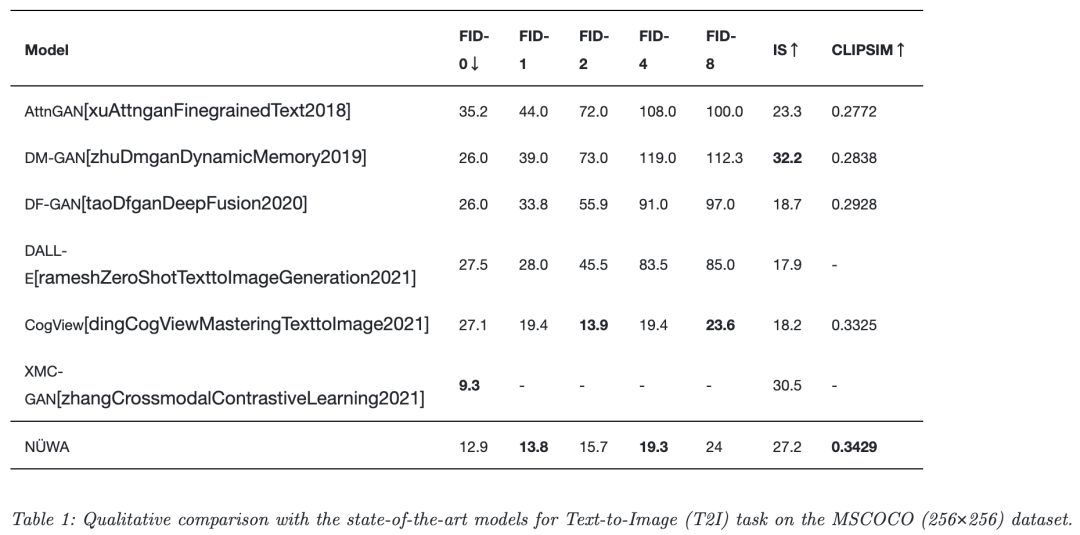
五、实验简单分析
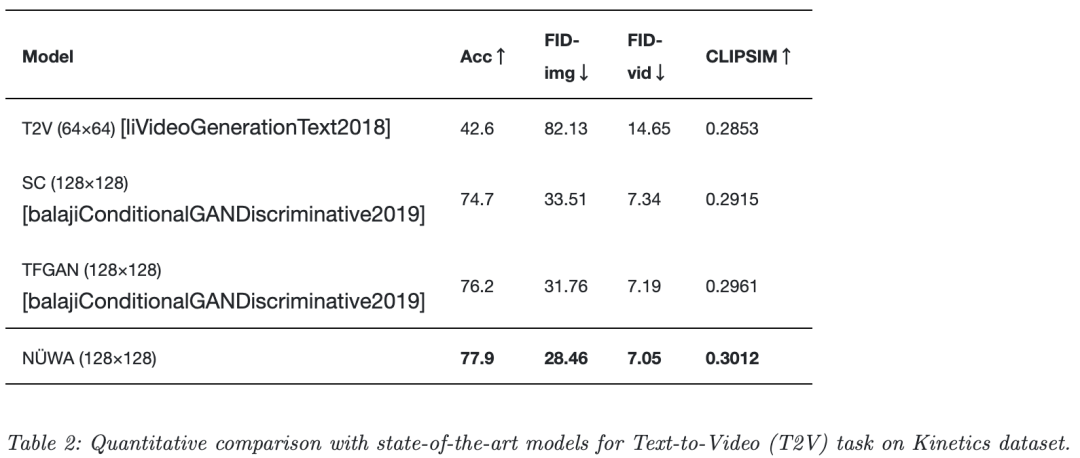
其他实验可在论文中获取!
© The Ending
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!

扫码关注
计算机视觉研究院
公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式
往期推荐
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

