
- 1OpenAI 为 GPT-3.5 Turbo 推出微调功能 (fine-tuning)_fine-tuning openai's gpt 3.5 for langchain agents
- 2华为鸿蒙系统支持什么手机_什么样的手机可以刷鸿蒙系统?看看你的手机支持吗?...
- 3安卓连接java_从零学习安卓自动化(java+appium方向):手机连接Appium(二)
- 4基于FPGA的UDP协议栈设计第四章_UDP层设计
- 5yolov5训练高精度非机动车驾驶检测_非机动车数据集
- 6modelsim仿真验证后,修改代码,不用重新关闭打开的调试技巧_modelsim仿真改原文件后
- 7【证明】对极几何:本质矩阵内在性质_本质矩阵的内在性质
- 8Unity开发(六) Prefab加载自动化管理引用计数管理器_unity assetbundle 和 gameobject的 引用计数
- 9怎么样去处理样本不平衡问题 | (文后分享大量检测+分割框架)
- 10【无人机综合题】+题解
多模态(一)--- CLIP原理与源码解读_clip训练流程
赞
踩
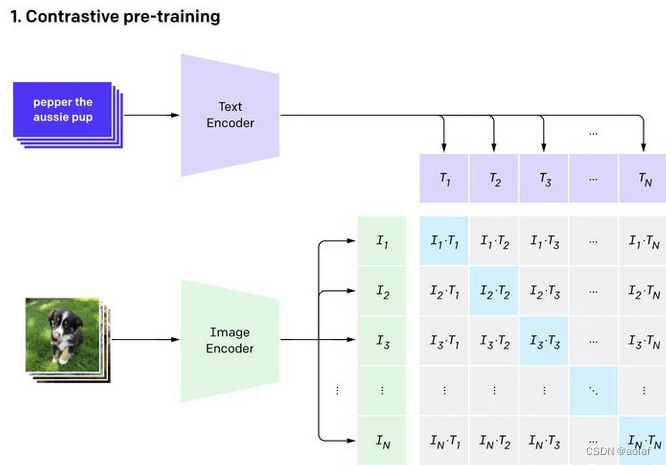
1 clip简介
CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练模型。
CLIP是一种基于对比学习的多模态模型,训练数据是文本—图像对:一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系。
2 clip训练过程
假如模型输入的是n对图片-文本对,那么这n对互相配对的图像–文本对是正样本(下图输出特征矩阵对角线上标识蓝色的部位),其它n2-n对样本都是负样本。此时模型的训练过程就是最大化n个正样本的相似度,同时最小化n2-n个负样本的相似度。
相似度是计算文本特征和图像特征的余弦相似性cosine similarity
CLIP包括两个模型:Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer。
2.1 训练流程伪代码
# image_encoder - ResNet or Vision Transformer # text_encoder - CBOW or Text Transformer # I[n, h, w, c] - 输入图片维度 # T[n, l] - 输入文本维度,l表示序列长度 # W_i[d_i, d_e] - learned proj of image to embed # W_t[d_t, d_e] - learned proj of text to embed # t - learned temperature parameter # 分别提取图像特征和文本特征 I_f = image_encoder(I) #[n, d_i] T_f = text_encoder(T) #[n, d_t] # 对两个特征进行线性投射,得到相同维度的特征d_e,并进行l2归一化,保持数据尺度的一致性 # 多模态embedding [n, d_e] I_e = l2_normalize(np.dot(I_f, W_i), axis=1) T_e = l2_normalize(np.dot(T_f, W_t), axis=1) # 计算缩放的余弦相似度:[n, n] logits = np.dot(I_e, T_e.T) * np.exp(t) # symmetric loss function labels = np.arange(n) # 对角线元素的labels loss_i = cross_entropy_loss(logits, labels, axis=0) # image loss loss_t = cross_entropy_loss(logits, labels, axis=1) # text loss loss = (loss_i + loss_t)/2 # 对称式的目标函数

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
2.2 文本图像预处理
2.2.1 文本预处理
文本采用数字编码,以sot_token_id + encode(text) + eot_token_id方式,其中sot_token_id:49406,
eot_token_id:49407,
中间则为每个单词对应的数字。
整个文本长度限制为77,不足77的部分补0,超过77的部分只取前77个。
def __call__(self, texts: Union[str, List[str]], context_length: Optional[int] = None) -> torch.LongTensor: if isinstance(texts, str): texts = [texts] context_length = context_length or self.context_length assert context_length, 'Please set a valid context length' # 将texts中每个单词编码成数字,self.sot_token_id:开始的第一个id为49406,self.eot_token_id:结束的最后一个id为49407,中间为每个单词对应的id all_tokens = [[self.sot_token_id] + self.encode(text) + [self.eot_token_id] for text in texts] # 只取77个单词,不足77个单词的文本补0,超过的的舍去,同时保证最后一个以self.eot_token_id结尾 result = torch.zeros(len(all_tokens), context_length, dtype=torch.long) for i, tokens in enumerate(all_tokens): if len(tokens) > context_length: tokens = tokens[:context_length] # Truncate tokens[-1] = self.eot_token_id result[i, :len(tokens)] = torch.tensor(tokens)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
2.2.2 图像预处理
将输入图像大小resize为(224, 224),RandomCrop, 转RGB,归一化。
{'image': Compose(
RandomResizedCrop(size=(224, 224), scale=(0.9, 1.0), ratio=(0.75, 1.3333), interpolation=bicubic, antialias=warn)
<function _convert_to_rgb at 0x7f8771c14790>
ToTensor()
Normalize(mean=(0.48145466, 0.4578275, 0.40821073), std=(0.26862954, 0.26130258, 0.27577711))
)
- 1
- 2
- 3
- 4
- 5
- 6
2.3 Text Encoder
def encode_text(self, text, normalize: bool = False): cast_dtype = self.transformer.get_cast_dtype() # text: [b, 77]--->[b, 77, 768] 77个字,每个字的维度为512 x = self.token_embedding(text).to(cast_dtype) # [batch_size, n_ctx, d_model] # 可学习的positional_embedding:[b, 77, 768], x: [b, 77, 768] x = x + self.positional_embedding.to(cast_dtype) # NLD -> LND [b, 77, 768]--->[77, b, 768] x = x.permute(1, 0, 2) # transformer网络学习 x = self.transformer(x, attn_mask=self.attn_mask) # LND -> NLD [77, b, 768]--->[b, 77, 768] x = x.permute(1, 0, 2) # layerNorm,[b, 77, 768] x = self.ln_final(x) # x:提取每个文本中,最后一个结束符号(eot embedding)的特征: [batch, 512], # _: 全部文本的特征:[batch, 77, 768] x, _ = text_global_pool(x, text, self.text_pool_type) if self.text_projection is not None: if isinstance(self.text_projection, nn.Linear): x = self.text_projection(x) else: # [b, 768]@[768, 768]--->[b, 768], self.text_projection:可学习参数 x = x @ self.text_projection # 归一化 return F.normalize(x, dim=-1) if normalize else x def text_global_pool(x, text: Optional[torch.Tensor] = None, pool_type: str = 'argmax'): if pool_type == 'first': pooled, tokens = x[:, 0], x[:, 1:] elif pool_type == 'last': pooled, tokens = x[:, -1], x[:, :-1] elif pool_type == 'argmax': # take features from the eot embedding (eot_token is the highest number in each sequence) assert text is not None # pooled:提取每个文本中,最后一个结束符号(eot embedding)的特征: [batch, 768], tokens: 全部文本的特征:[b, 77, 768] pooled, tokens = x[torch.arange(x.shape[0]), text.argmax(dim=-1)], x else: pooled = tokens = x return pooled, tokens
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
2.4 Image Encoder
def forward(self, x: torch.Tensor): # [b, 3, 224, 224]--->[b, 1024, 16, 16] x = self.conv1(x) # [b, 1024, 16, 16]--->[b, 1024, 256] x = x.reshape(x.shape[0], x.shape[1], -1) # [b, 1024, 256]--->[b, 256, 1024] x = x.permute(0, 2, 1) # 图像的每个grid嵌入一个类别,x:[b, 256 + 1, 1024] x = torch.cat([_expand_token(self.class_embedding, x.shape[0]).to(x.dtype), x], dim=1) # 嵌入位置编码,x:[b, 256 + 1, 1024] x = x + self.positional_embedding.to(x.dtype) # patch_dropout, x:[b, 256 + 1, 1024] x = self.patch_dropout(x) # LayerNorm处理 x:[b, 256 + 1, 1024] x = self.ln_pre(x) # NLD -> LND [b, 256 + 1, 1024]---> [256 + 1, b, 1024] x = x.permute(1, 0, 2) # transformer网络处理 x = self.transformer(x) # LND -> NLD [256 + 1, b, 1024]--->[b, 256 + 1, 1024] x = x.permute(1, 0, 2) if self.attn_pool is not None: if self.attn_pool_contrastive is not None: # This is untested, WIP pooling that should match paper x = self.ln_post(x) # TBD LN first or separate one after each pool? tokens = self.attn_pool(x) if self.attn_pool_type == 'parallel': pooled = self.attn_pool_contrastive(x) else: assert self.attn_pool_type == 'cascade' pooled = self.attn_pool_contrastive(tokens) else: # this is the original OpenCLIP CoCa setup, does not match paper x = self.attn_pool(x) x = self.ln_post(x) pooled, tokens = self._global_pool(x) elif self.final_ln_after_pool: pooled, tokens = self._global_pool(x) pooled = self.ln_post(pooled) else: # layernorm:[b, 256+1, 1024]--->[b, 256+1, 1024] x = self.ln_post(x) # pooled: 类别token:[b, 1024] tokens:图像token:[b, 256, 1024] pooled, tokens = self._global_pool(x) # pooled: [4, 1024]@[1024, 768]--->[4, 768] if self.proj is not None: pooled = pooled @ self.proj return pooled
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
2.5 损失函数计算
def get_logits(self, image_features, text_features, logit_scale): # 计算图像和文本的余弦相似度 logits_per_image = logit_scale * image_features @ text_features.T # 计算文本和图像的余弦相似度 logits_per_text = logit_scale * text_features @ image_features.T return logits_per_image, logits_per_text def forward(self, image_features, text_features, logit_scale, output_dict=False): device = image_features.device # 假设有N个图像-文本对: logits_per_image: [N, N], logits_per_text: [N, N] logits_per_image, logits_per_text = self.get_logits(image_features, text_features, logit_scale) # 假设有N个图像-文本对:labels=[0, 1, 2,....N] labels = self.get_ground_truth(device, logits_per_image.shape[0]) # 总损失 = (图像维度的损失 + 文本维度的损失)/ 2 total_loss = ( F.cross_entropy(logits_per_image, labels) + # 图像维度的损失 F.cross_entropy(logits_per_text, labels) # 文本维度的损失 ) / 2 return {"contrastive_loss": total_loss} if output_dict else total_loss
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
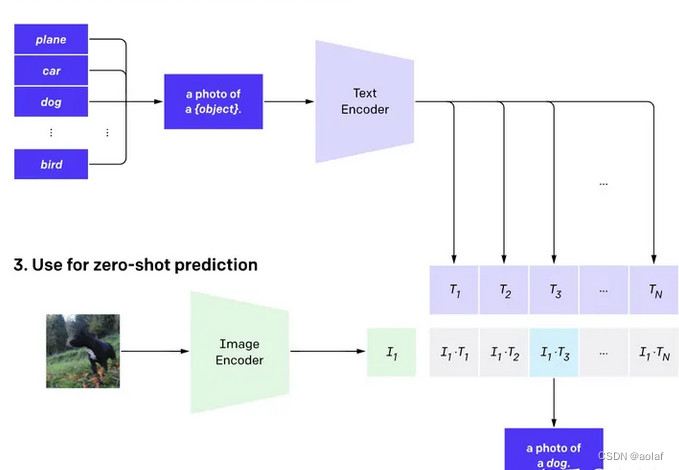
3 利用clip实现zero-shot分类
传统的视觉模型需要在新的数据集上进行微调,而clip可以直接实现zero-shot的图像分类,即不需要任何训练数据,就能在某个具体下游任务上实现分类。
操作步骤:
- 根据任务的分类标签构建每个类别的描述文本:A photo of {label},然后将这些文本送入Text Encoder得到对应的文本特征,如果类别数目为N,那么将得到N个文本特征;
- 将要预测的图像送入Image Encoder得到图像特征,然后与N个文本特征计算缩放的余弦相似度(和训练过程一致),选择相似度最大的文本对应的类别作为图像分类预测结果,进一步地,可以将这些相似度看成logits,送入softmax后可以到每个类别的预测概率。
# 首先生成每个类别的文本描述 labels = ["dog", "cat", "bird", "person", "mushroom", "cup"] text_descriptions = [f"A photo of a {label}" for label in labels] text_tokens = clip.tokenize(text_descriptions).cuda() # 提取文本特征 with torch.no_grad(): text_features = model.encode_text(text_tokens).float() text_features /= text_features.norm(dim=-1, keepdim=True) # 读取图像 original_images = [] images = [] texts = [] for label in labels: image_file = os.path.join("images", label+".jpg") name = os.path.basename(image_file).split('.')[0] image = Image.open(image_file).convert("RGB") original_images.append(image) images.append(preprocess(image)) texts.append(name) image_input = torch.tensor(np.stack(images)).cuda() # 提取图像特征 with torch.no_grad(): image_features = model.encode_image(image_input).float() image_features /= image_features.norm(dim=-1, keepdim=True) # 计算余弦相似度(未缩放) similarity = text_features.cpu().numpy() @ image_features.cpu().numpy().T # 注意这里要对相似度进行缩放,余弦相似度范围是0-1,不太适合直接作为交叉熵的logits,因为一般logits都是没有上限的,这样区分度会更好一些。所以模型训练增加了一个可训练的温度参数来放大 logit_scale = np.exp(model.logit_scale.data.item()) text_probs = (logit_scale * image_features @ text_features.T).softmax(dim=-1) top_probs, top_labels = text_probs.cpu().topk(5, dim=-1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
import numpy as np import torch import clip from PIL import Image device = "cuda" if torch.cuda.is_available() else "cpu" model, preprocess = clip.load("ViT-B/32", device=device) image = preprocess(Image.open("./run.jpeg")).unsqueeze(0).to(device) text = clip.tokenize(["plane", "dog", "human", "runner"]).to(device) with torch.no_grad(): image_features = model.encode_image(image) text_features = model.encode_text(text) logits_image, logits_text = model(image, text) probs = logits_image.softmax(dim=-1).cpu().numpy() # 和图片最相似的文本就是图片的类别 print("Label probs:", probs) Label probs: [[1.508e-03 5.999e-04 1.063e-02 9.873e-01]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
4 Prompt Engineering(提示工程)
prompt learning的核心是通过构建合适prompt(提示)来使预训练模型能够直接应用到下游任务中。
推理时,只使用类别标签作为文本描述效果并不够好,原因有二:
-
词语存在歧义性
如果我们直接采用类别标签作为文本描述,那么很多文本就是一个单词,缺少具体的上下文,并不能很好的描述图片内容。
比如在做物体检测时,有一个类别是remote(遥控器)。但如果直接喂给文本编码器,很可能被模型认为是遥远的意思。
同一个词语在不同数据集中所表示的意思可能有所不同。例如在 Oxford-IIIT Pets 数据集中,boxer指的是狗的一个种类,在其他数据集中指的是拳击运动员。
所以 CLIP预训练时,用来描述图片内容的文本是一个句子,比如A photo of {label}。这里的label就只能是名词,一定程度上消除了歧义性。 -
使推理和预训练时保持一致(消除distribution gap)。
5 局限性
- 性能有待提高
CLIP在很多数据集上,平均下来看可以和ResNet-50打成平手(ImageNet精度为76.2),但与现在最好的模型(VIT-H/14,MAE等精度可以上90)还存在十几个点的差距。预测大概还需要当前1000倍的规模才可以弥补上十几个点的这个差距,现有的硬件条件也无法完成。所以扩大数据规模是不行了,需要在数据计算和高效性上需要进一步提高。 - 难以理解抽象/复杂概念
CLIP在一些更抽象或更复杂的任务上zero-shot表现并不好。例如数一数图片中有多少个物体,或者在监控视频里区分当前这一帧是异常还是非异常,因为CLIP无法理解什么是异常、安全。所以在很多情况下,CLIP都不行。 - out-of-distribution泛化差
对于自然图像的分布偏移,CLIP还是相对稳健的。但如果在做推理时,数据和训练时的数据相差太远(out-of-distribution),CLIP泛化会很差。例如CLIP在MNIST数据集上精度只有88%,随便一个分类器都都能做到99%,可见CLIP还是很脆弱的。(作者研究发现,4亿个样本没有和MNIST很像的样本) - 虽然CLIP可以做zero-shot的分类任务,但它还是从给定的那些类别里去做选择,无法直接生成图像的标题。作者说以后可以将对比学习目标函数和生成式目标函数结合,使模型同时具有对比学习的高效性和生成式学习的灵活性。
- 数据的利用不够高效
在本文的训练过程中,4亿个样本跑了32个epoch,这相当于过了128亿张图片。可以考虑使用数据增强、自监督、伪标签等方式减少数据用量。 - 引入偏见
本文在研发CLIP时一直用ImageNet测试集做指导,还多次使用那27个数据集进行测试,所以是调了很多参数才定下来网络结构和超参数。这并非真正的zero-shot,而且无形中引入了偏见。 - 社会偏见
OpenAI自建的数据集没有清洗,因为是从网上爬取的,没有经过过滤和审查,训练的CLIP模型很有可能带有一些社会偏见,例如性别、肤色。 - 需要提高few-shot的性能
很多复杂的任务或概念无法用文本准确描述,这时就需要提供给模型一些训练样本。但当给CLIP提供少量训练样本时,结果反而不如直接用zero-shot。例如3.1.4中CLIP的few-shot分类。后续工作考虑如何提高few-shot的性能

