
- 1当"狂飙"的大模型撞上推荐系统
- 2seleniumbasic+VBA配置自动控制网页_vba selenium
- 3Python爬虫 利用百度翻译抓包实现查单词小工具(英翻中)_抓包软件抓包的字符怎么翻译
- 4flutter 数据储存的几种方式_flutter 存储数据
- 5esxi如何挂载物理机上的磁盘_ESXi 安装 macOS 虚拟机
- 6CSRF漏洞原理攻击与防御(非常细)_nginx 反向代理场景下如何 应对csrf 攻击
- 7水下机器人(rov)小知识(2)_水下机器人推进器分布
- 8IOS渲染流程之RenderServer处理图层信息_render service
- 9JLink不能识别CPU错误的解决办法: Could not find supported CPU core on JTAG chain
- 10大模型重构云计算:AI原生或将改变格局_大模型全方位重构云计算
springboot应用,cpu高、内存高问题排查_springboot cpu占用太高
赞
踩
前几天,排查了2个生产问题。一个cpu高,一个内存高。今天把解决过程整理一下
1、cpu高问题排查
先说cpu高的这个问题
新系统,上线半年,一直比较稳定。有一天,运维过来说:cpu有点高,超过80%了。这个系统的量没有那么大,也没有什么很复杂的计算任务。cpu不应该这么高。
1.1、获取栈日志
让运维拿了2份栈日志,两份栈日志间隔1分钟左右获取。之所以下载两份,是为了比较,如果两份栈日志都有某个功能在执行,那这个功能就有很大的嫌疑。
//栈日志获取方式.将pid换成你系统的pid
jstack -l pid >> order.txt
- 1
- 2
1.2、分析栈日志
打开栈日志,直接搜项目代码里的包名,只要两份日志都有这个包名,那基本八九不离十,看一下对应的逻辑就行了。
我这个cpu高的原因,是实习小伙伴做了一个excel文件解析的功能,解析完成之后的业务逻辑处理,有几个点非常耗时,加上这段时间,业务调用的比较频繁,cpu就猛增。知道了原因,解决起来就比较简单了。
2、内存高问题排查
再说内存高,在排查cpu问题的时候,运维又说了一句:你这个服务的内存也有点高啊,我先给你加点内存。我觉着不太对,因为这个服务也没有啥操作内存的大任务。就看了看内存趋势,趋势很陡峭,而且不下降,这肯定是有问题的,接下来就是漫长的排查过程,整个排查过程大概持续了3天左右。
2.1、dump日志分析
让运维拿了dump日志。
//dump日志获取命令 pid替换为你的系统pid
jmap -dump:format=b,file=/tmp/order.dump pid
- 1
- 2
本地装了MAT,分析了一下内存的占用。将近3个G的文件,2.7G都是不可达的对象
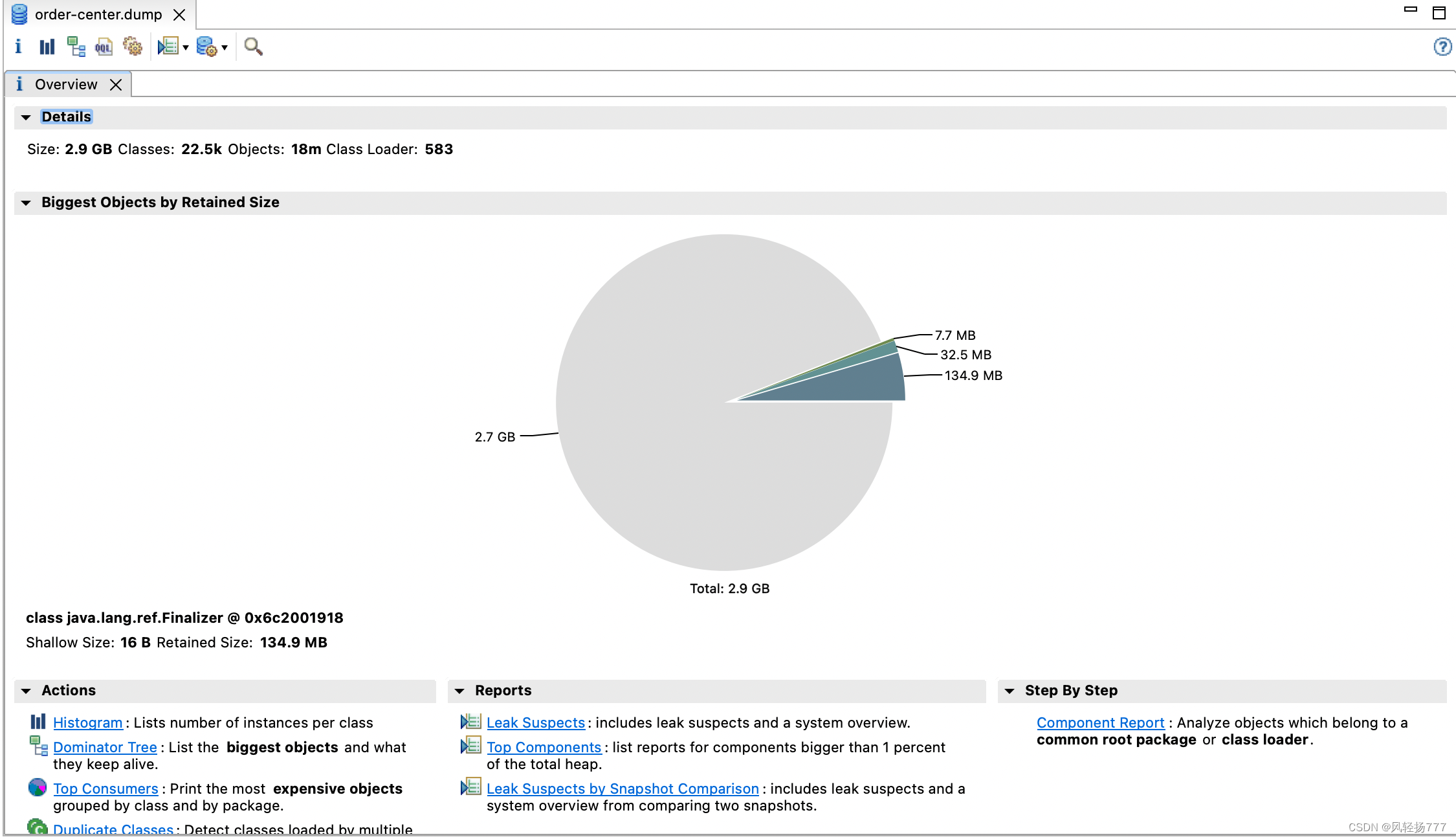
这说明,内存虽然涨的快,但是可以回收。
2.2、堆内存使用情况
再看一下堆内存的情况(生产机器用的是CMS垃圾收集器)
//查看堆内存的使用情况
jsat -gcutil pid 间隔 次数
//举例
输出pid为200的程序的堆内存使用情况,每隔1秒打印一次,不限制次数
jsat -gcutil 200 1000
- 1
- 2
- 3
- 4
- 5

我这是后来补的图,当时的堆内存老年代基本接近96%。而且可以看到FGC有4次,但是停顿时间还凑活。这进一步验证了我们的猜想,有大对象的生成,但是可以回收。
2.3、解决方案
知道了以上结论,和最近做过这个系统需求的小伙伴沟通了一下,都没印象做过什么耗时高的需求。而且这个内存升高的趋势,也不一定是最近才有的,可能一直存在,只不过项目发布频繁,所以没有发现。运维那的Grafana,只存一星期的数据,也看不到是从什么时候出现的这个问题。
针对这种情况。我当时做了2个方案。
第一个,让运维给内存加了报警,超过3个G,就报警。报警之后,从Kibana上查看对应时间段对应系统的日志,重点找一下耗时高的日志。然后用arthas的trace命令看一下耗时高的点
第二个,如果实在找不到耗时高的请求,最差的解决方案,就是按照最近做的需求,挨个方法进行trace,这样慢一点,但是感觉最终可以找到问题
2.4、arthas trace解决问题
幸运的是,内存报警之后,看对应的日志,找到了一个耗时高的接口,长达两秒。然后trace这个接口,就发现了问题所在。
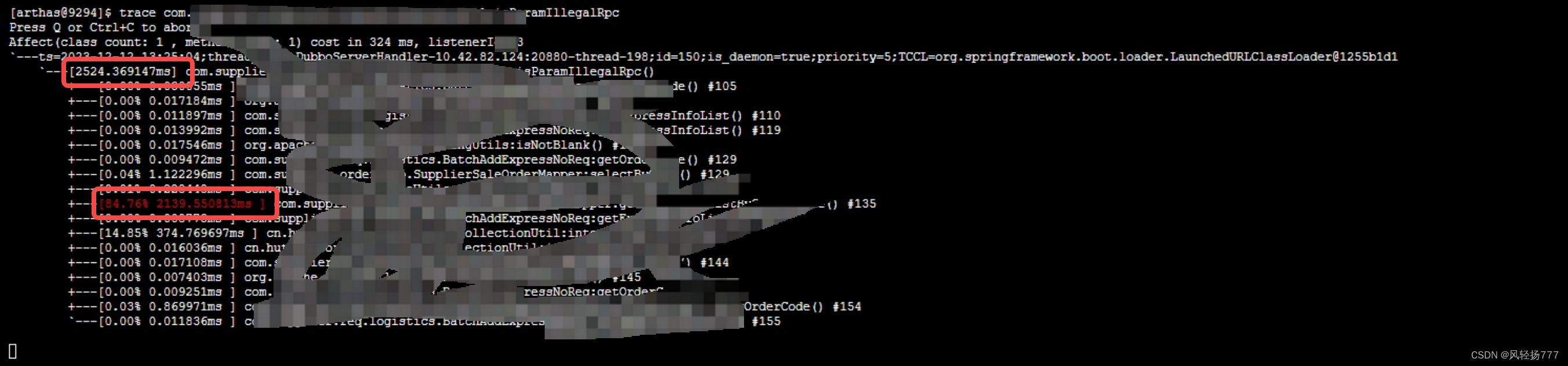
接口耗时高达两秒,有一个方法占用了84%的耗时,看这个方法的实现,是从数据库里加载几个月的数据,进行业务校验。最开始上线,数据不多,后面数据涨的很快,目前拿到的数据量在150万左右。
2.5、总结
回顾一下整个排查过程,有几个点说一下
1)、写方法一定要注意数据动态增长的情况,比如此例,数据后期增长较快。不能只考虑当时的数据。
2)、有个疑问,就算对象不可达了,正常来说也可以从MAT里看到点相关东西才对,但是翻了很久,啥也没看到,MAT的使用还要再看看,感觉是遗漏了细节
3)、还有个疑问,虽然对象确实很大,但是可以回收,那rancher上看到的内存为啥还会这么高呢?这也是一个疑问点,需要找时间了解一下rancher

