
- 1Java岗外包干了五年,废了。。。_java一直干外包
- 2Firewalld防火墙
- 3HashMap与HashSet_hashmap hashset
- 4【设计模式】最快理解设计模式的几大原则_设计模式 如何抽象思维
- 5大数据技术原理与应用实验指南——Spark安装与编程实践1_大数据技术原理与应用实验一
- 6华为OD机试真题 Python 实现【星际篮球争霸赛】【100%通过率】【2022.11 Q4 新题】_星际篮球争霸赛,mvp争夺战python
- 7使用nvm切换node.js版本,vue项目中node.js对应的node-sass和sass-loader版本_vue": "2.6.10", 对应node版本
- 8yolov8实时推理目标识别、区域分割、姿态识别 Qt GUI_unity yolo
- 9创业冲突的五种解决方法是_合伙人要怎么相处?创业企业如何解决利益冲突?...
- 10ccpc河北大学生程序设计竞赛dp小总结_河北农大萌新程序设计大赛比赛原题
MyCat2数据库分库分表,读写分离中间件(踩坑大实战内附详细图文教程)
赞
踩
目录
介绍
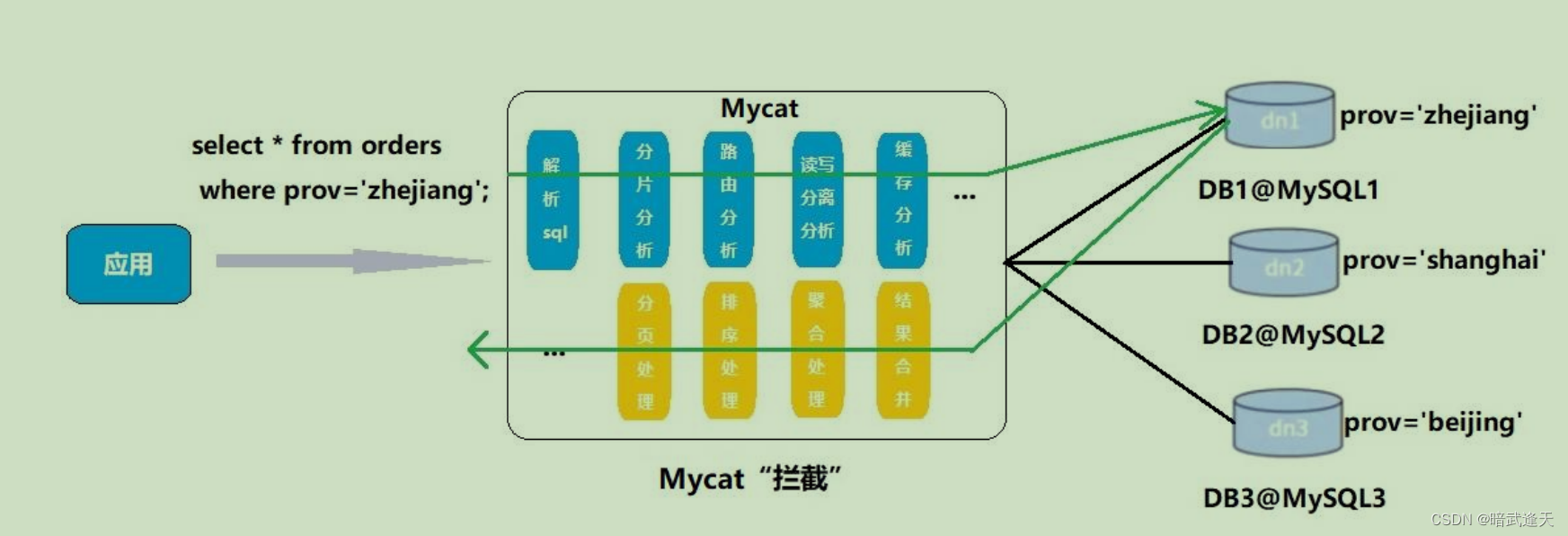
1.读写分离
Java操作MyCat,Mycat作为数据源访问,根据Java读、写请求分发到主从Mysql上,从而实现了读写分离。
2.数据分片
对数据库垂直拆分(分库)、对表水平拆分(分表)、对数据库垂直与表水平拆分(分库分表)
3.多数据源整合
Java操作MyCat,Mycat作为数据源访问,根据不同业务进行数据源划分,MyCat访问不同的数据源(MySql、MongoDB),从而实现多数据源整合。
安装使用
mycat工具包
提取码:k06y
登录进服务器中,将解压后的文件夹mycat传到服务器上,这里可以直接下载博主提供的,本博主也把原先需要copy在lib目录的jar包也已copy压缩好,所以可以直接上传服务器
注意mycat启动需要依赖jdk8或者以上环境,启动前需在服务器上部署好jdk环境
更改文件权限
进入到mycat的bin目录下更改必需文件的权限
更改这四个文件的权限为777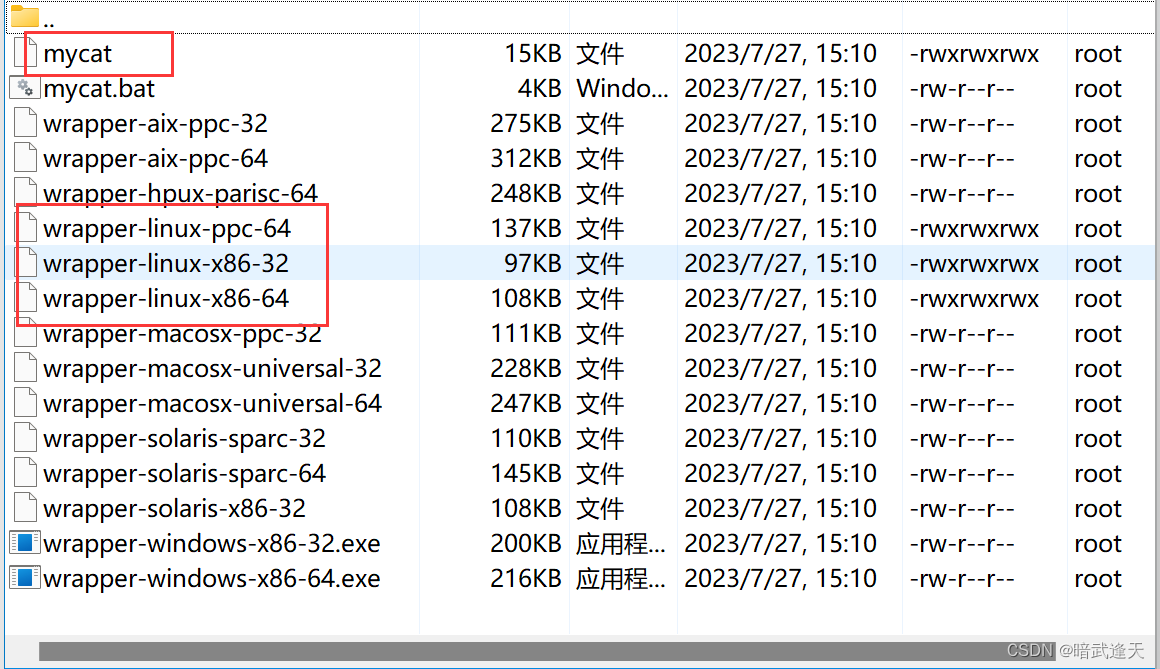
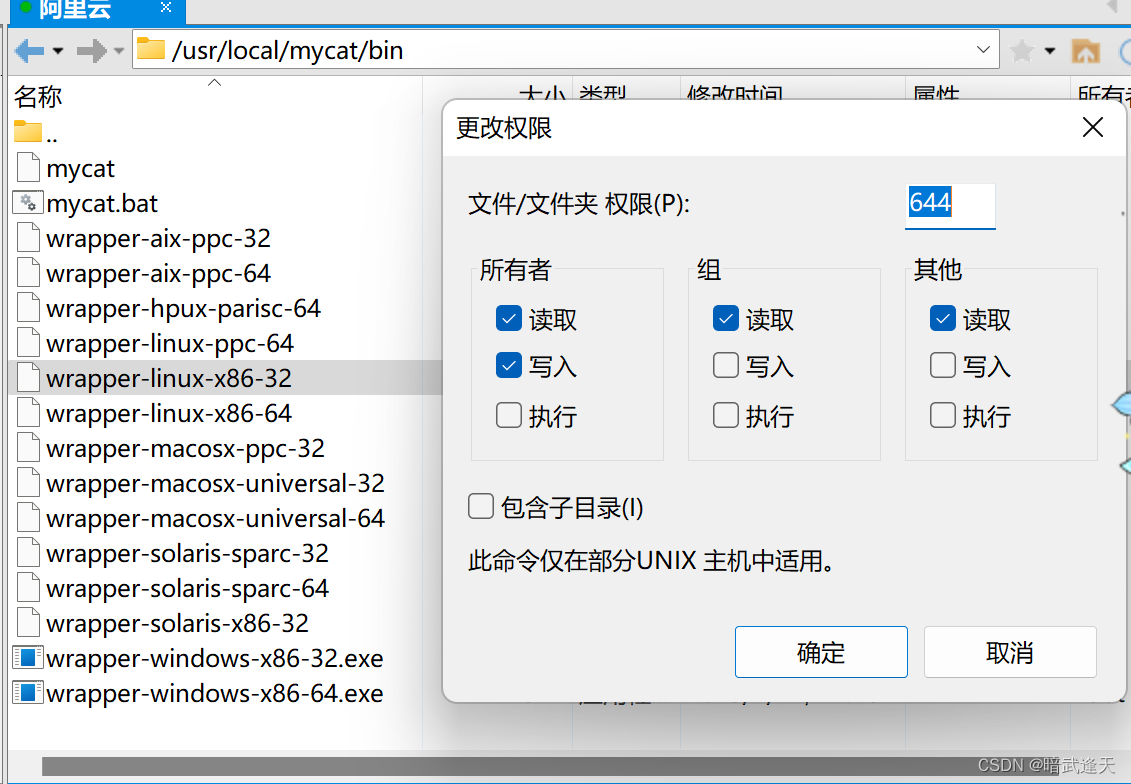
更改数据库配置
进入到mycat的conf目录下更改数据源配置

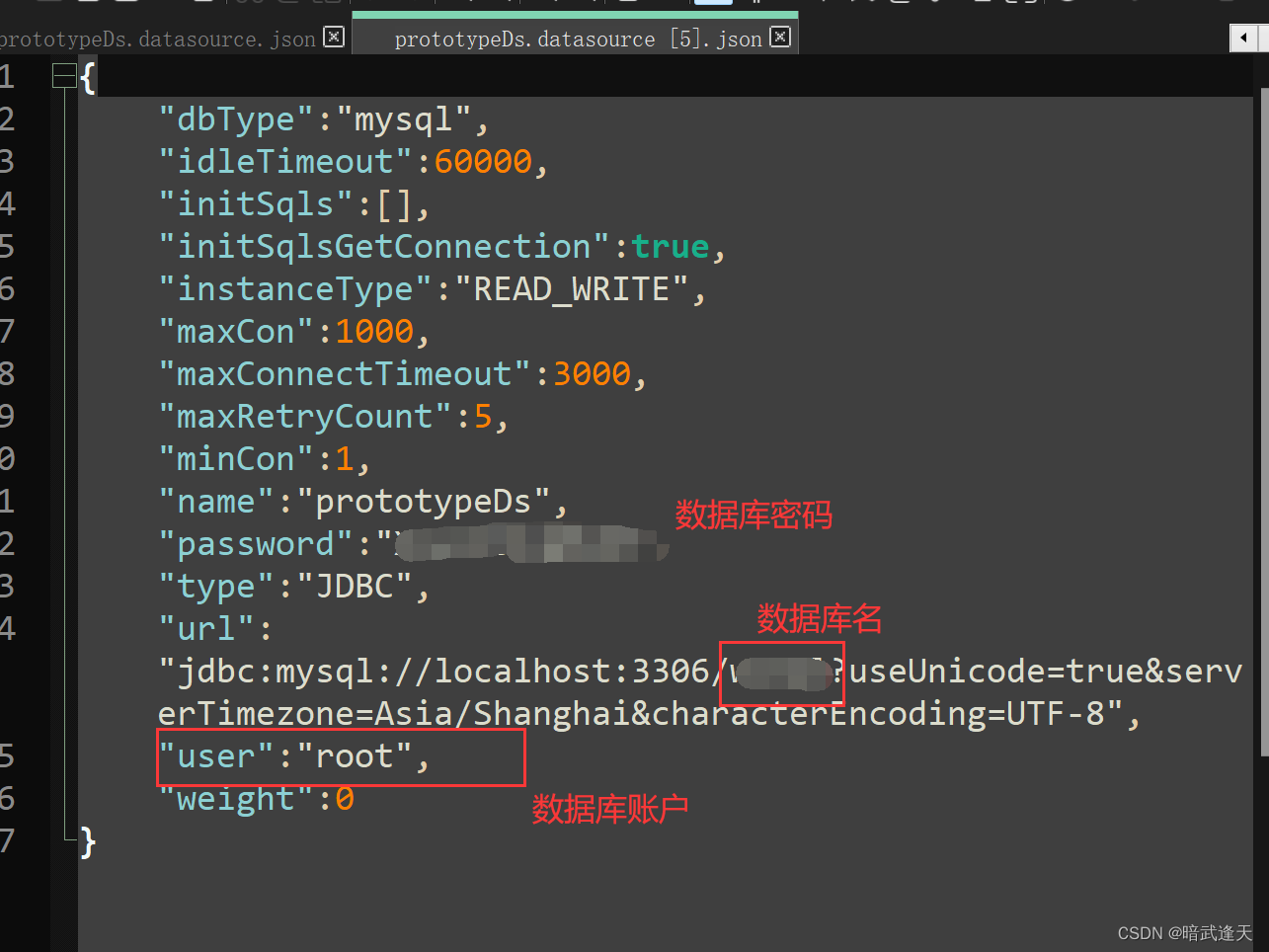
更改后保存
本人实际踩坑,按照网上绝大多数教程这里直接就启动mycat使用navicat连接就可以了,其实还需要再更改一个mycat的用户配置:

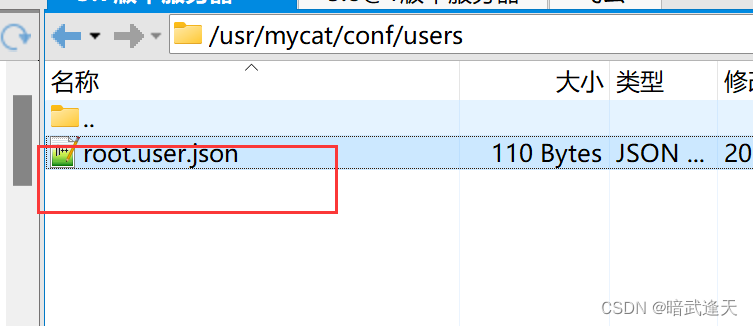
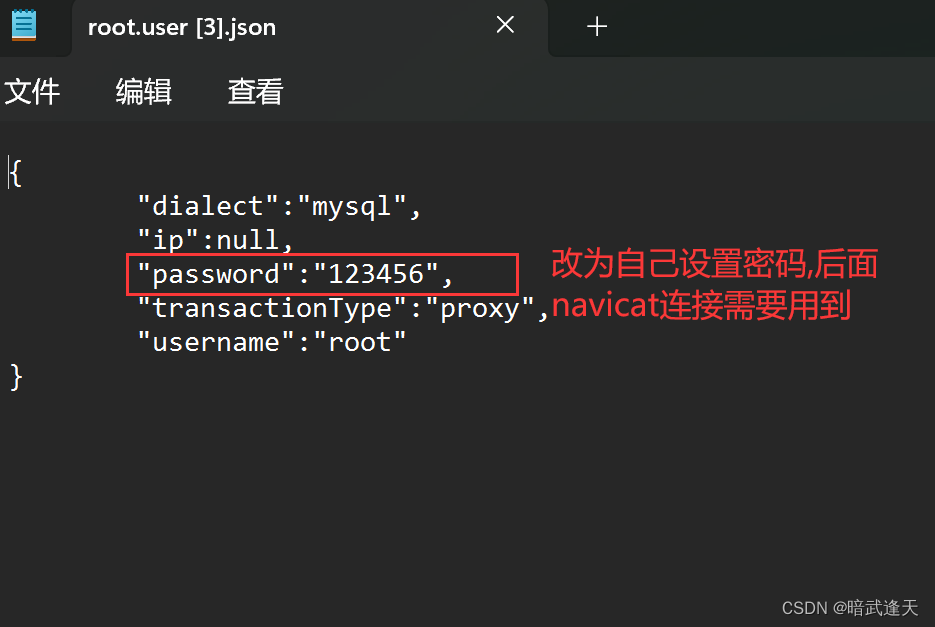
实际踩坑,这里博主因为没有改动这里的配置导致后面navicat连接时一直连接不上,被搞了一天的心态都快崩了o(╥﹏╥)o
进入到mycat的bin目录下启动mycat
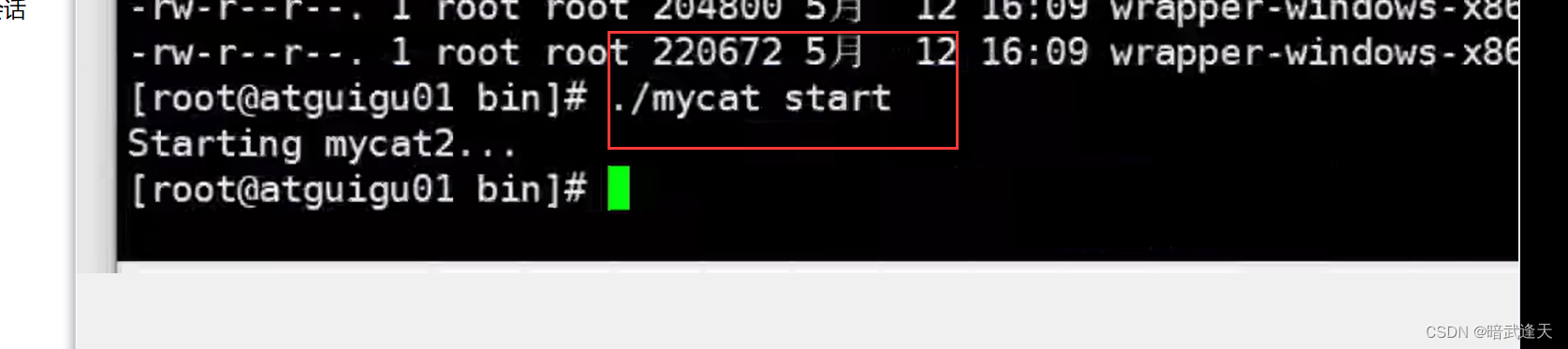
输入jps,出现wrapperSimpleApp说明mycat启动成功
连接数据库
mysql -u账户 -p密码 -P 8066
连接成功
搭建mysql主从复制
准备两个服务器,两个服务器都提前安装好mysql,开始搭建主从复制
这里以5.7为主,5.8为从机,最好是版本相同的进行搭建,这里由于服务器上已经分别搭建好了5.7mysql和5.8就不再重装了,直接开始
搭建主机
5.7版本mysql的配置文件是/etc目录下的my.cnf文件
找到该文件进行主机配置
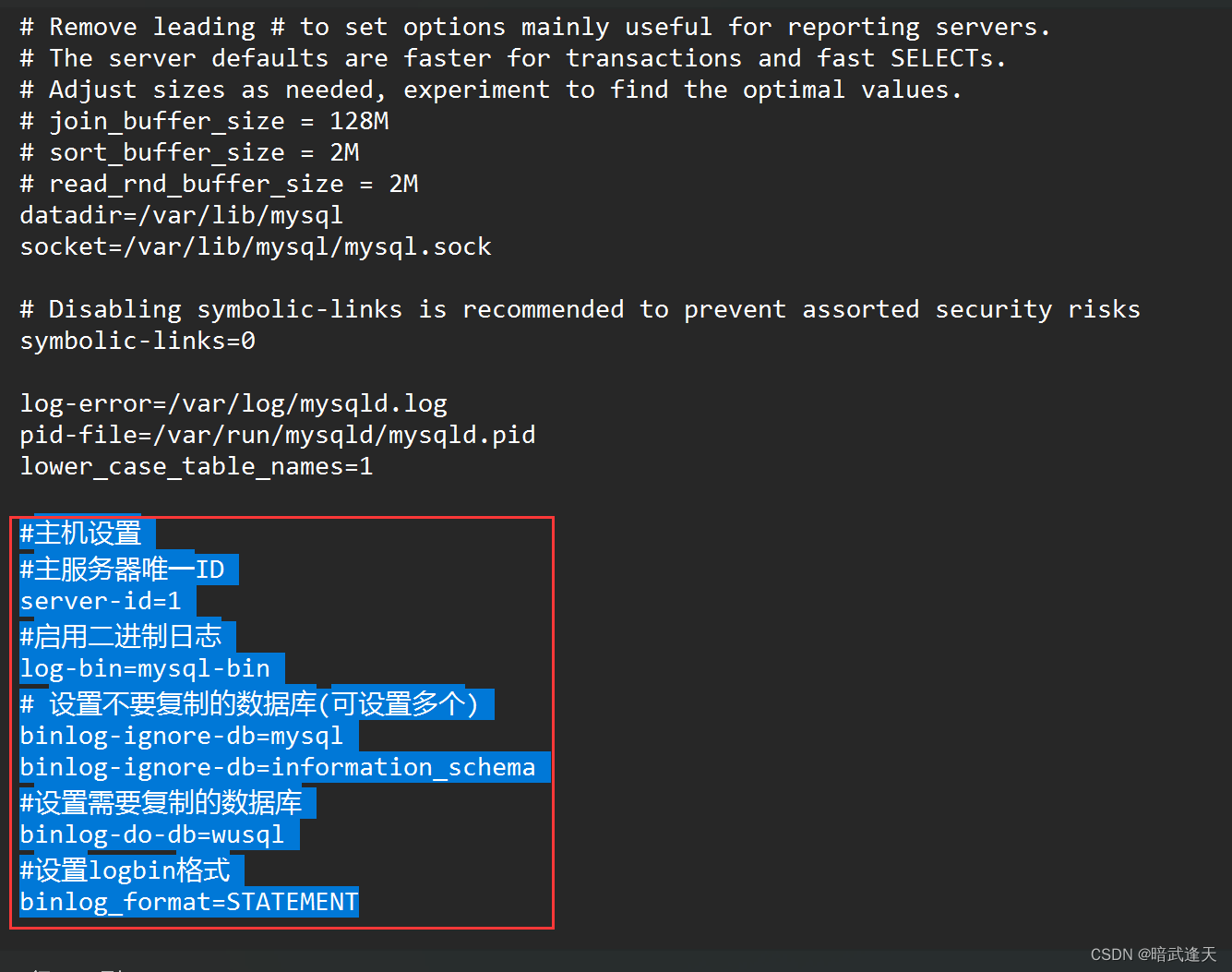
#主机设置
#主服务器唯一ID
server-id=1
#启用二进制日志
log-bin=mysql-bin
# 设置不要复制的数据库(可设置多个)
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
#设置需要复制的数据库
binlog-do-db=wusql
#设置logbin格式
binlog_format=STATEMENT
设置后重启主机mysql
systemctl restart mysqld.service
CREATE USER 'slave'@'%' IDENTIFIED BY '密码';
ALTER USER 'slave'@'%' IDENTIFIED WITH mysql_native_password BY '密码';
GRANT REPLICATION SLAVE ON *.* TO 'slave'@'%';
flush privileges;
show master status;
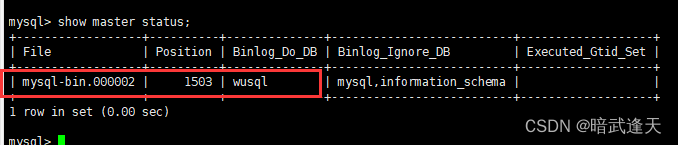
注意file,和Position两个值等会儿要在从机中设置值
配置从机
注意5.8版本mysql的配置文件是在/etc/my.cnf.d目录下的mysql-server.cnf文件
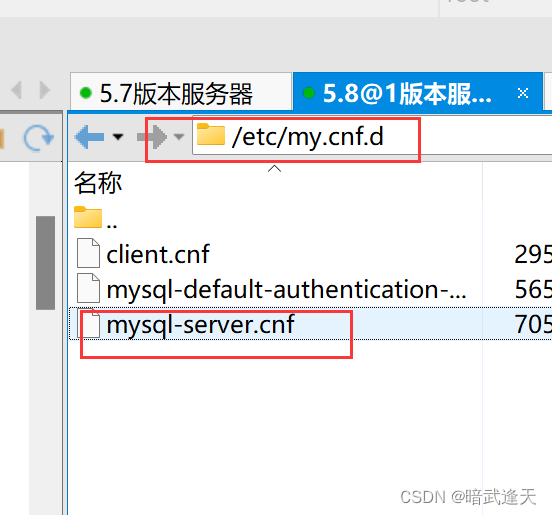
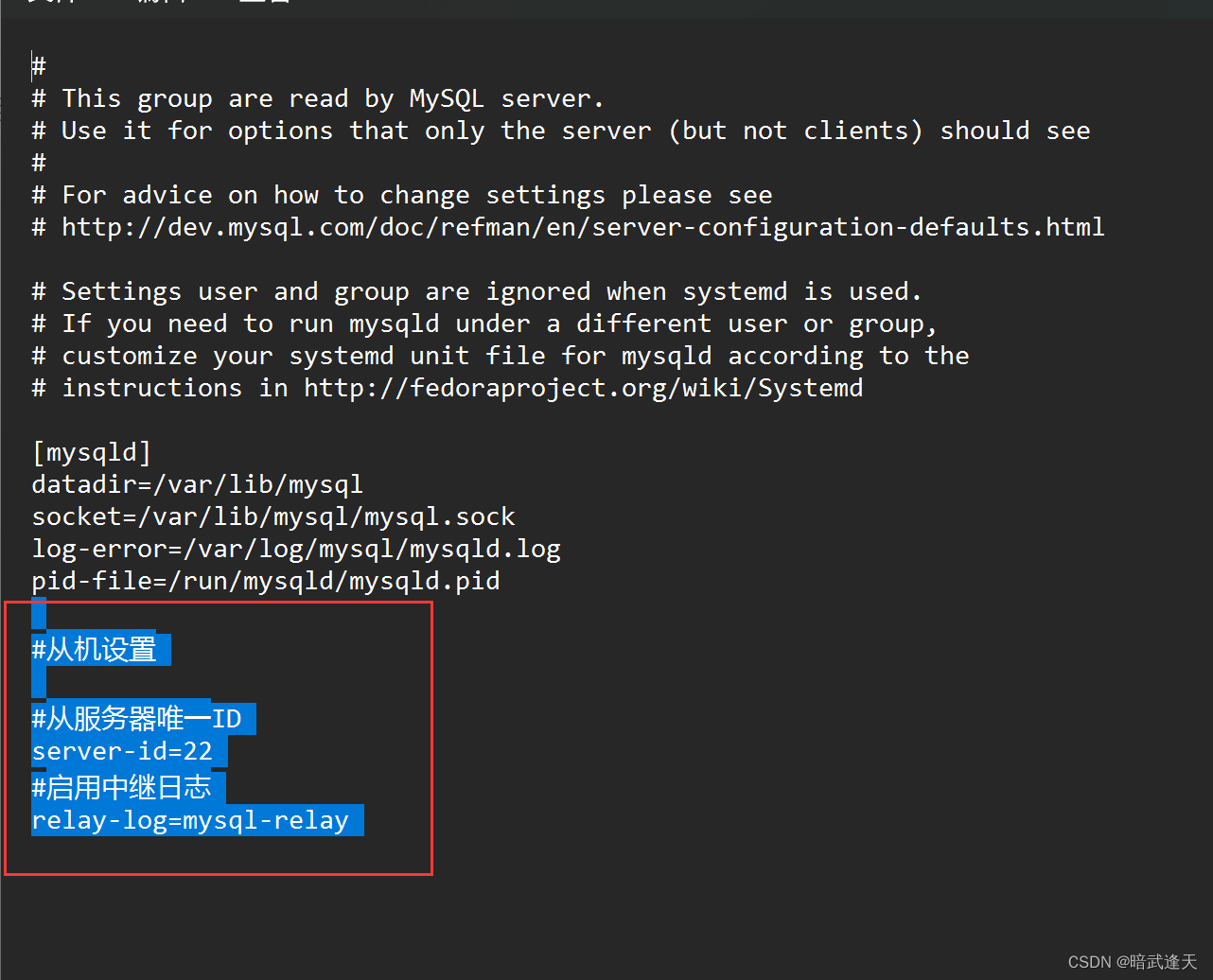
#从机设置#从服务器唯一ID
server-id=22
#启用中继日志
relay-log=mysql-relay
 配置好保存重启从机mysql
配置好保存重启从机mysql
systemctl restart mysqld.service
注意主从机都要关闭防火墙
CHANGE MASTER TO MASTER_HOST='主机ip',
MASTER_USER='slave',
MASTER_PASSWORD='密码',MASTER_LOG_FILE='主机File值',MASTER_LOG_POS=主机Position值;

开始主从复制:
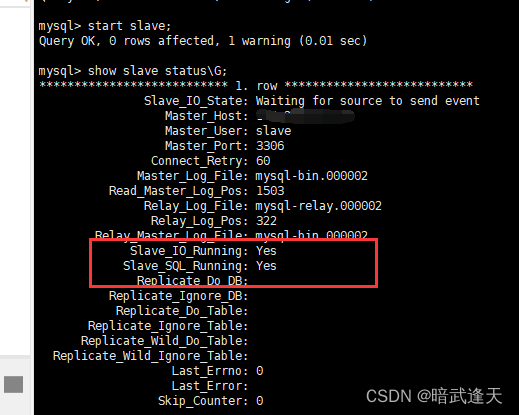
start slave;

show slave status\G;
创建数据库
create database wusql;
切换数据库use wusql;
建表
create table stu(
id int,name varchar(10));插入数据
insert stu values(1,'zhang');
去从机中查看是否有数据同步
搭建成功(*^▽^*)!
读写分离配置
连接mycat
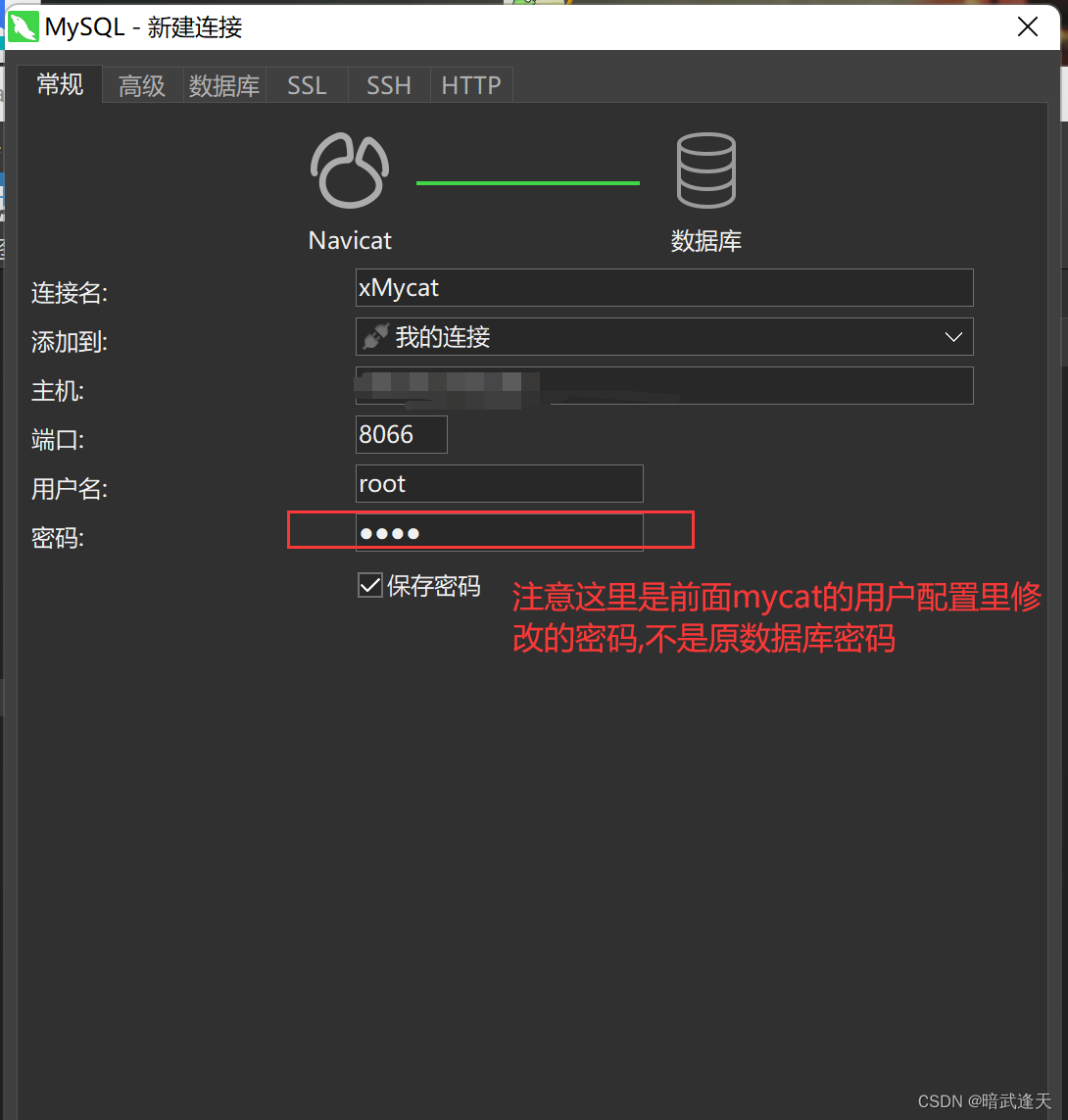
即这里配置的密码
在mycat中创建数据库wusql,注意这里mycat创建的数据库名要和主从机数据库名字一致,博主之前第一次测试时候名字故意设置不一致导致数据不同步导致失败,所以这里最好还是一致命名吧
create database wusql
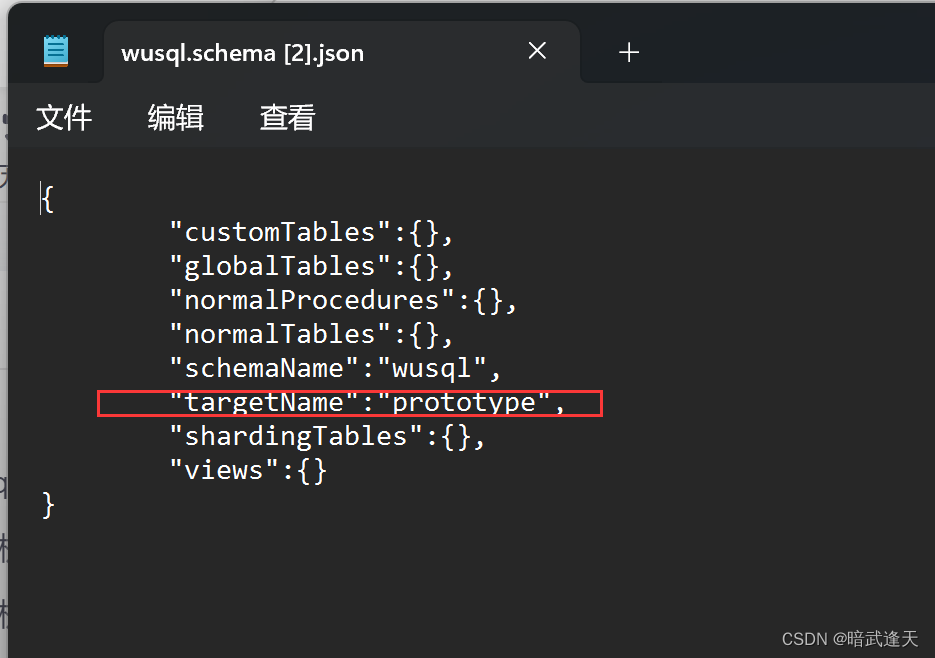
使用注解方式添加数据源
注意下面命令在运行时不要有换行符,不然可能会执行错误
#配置写数据源 主机
/*+mycat:createDataSource{"name":"rwSepw","url":"jdbc:mysql://主机ip:3306/wusql?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true", "user":"root","password":"密码" } */;#配置读数据源 从机
/*+mycat:createDataSource{"name":"rwSepr","url":"jdbc:mysql://从机ip:3306/wusql?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true","user":"root","password":"密码" } */;
#查询配置数据源结果
/*+ mycat:showDataSources{} */;

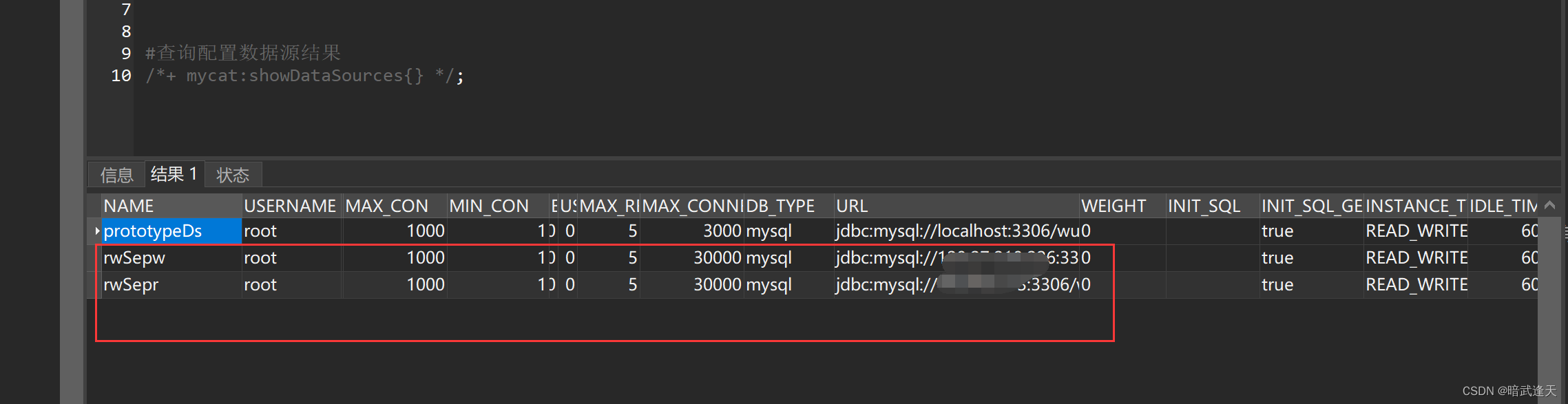
配置成功
/*!mycat:createCluster{"name":"prototype","masters":["rwSepw"],"replicas":["rwSepr"]} */;

查看配置集群信息
/*+ mycat:showClusters{} */;
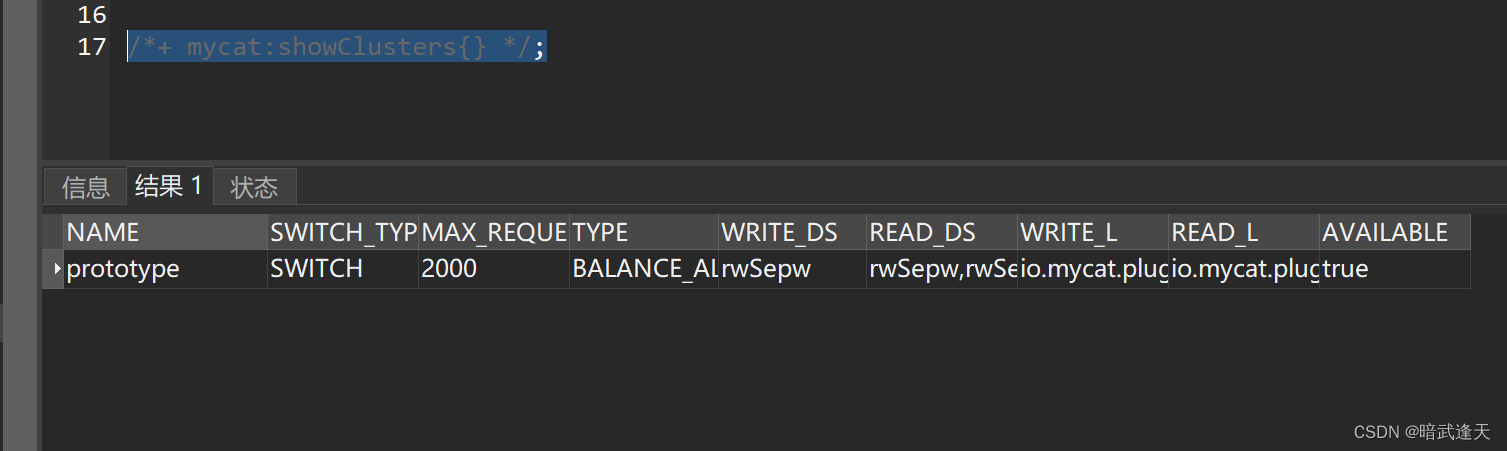
查看集群配置文件
vim /usr/local/mycat/conf/clusters/prototype.cluster.json
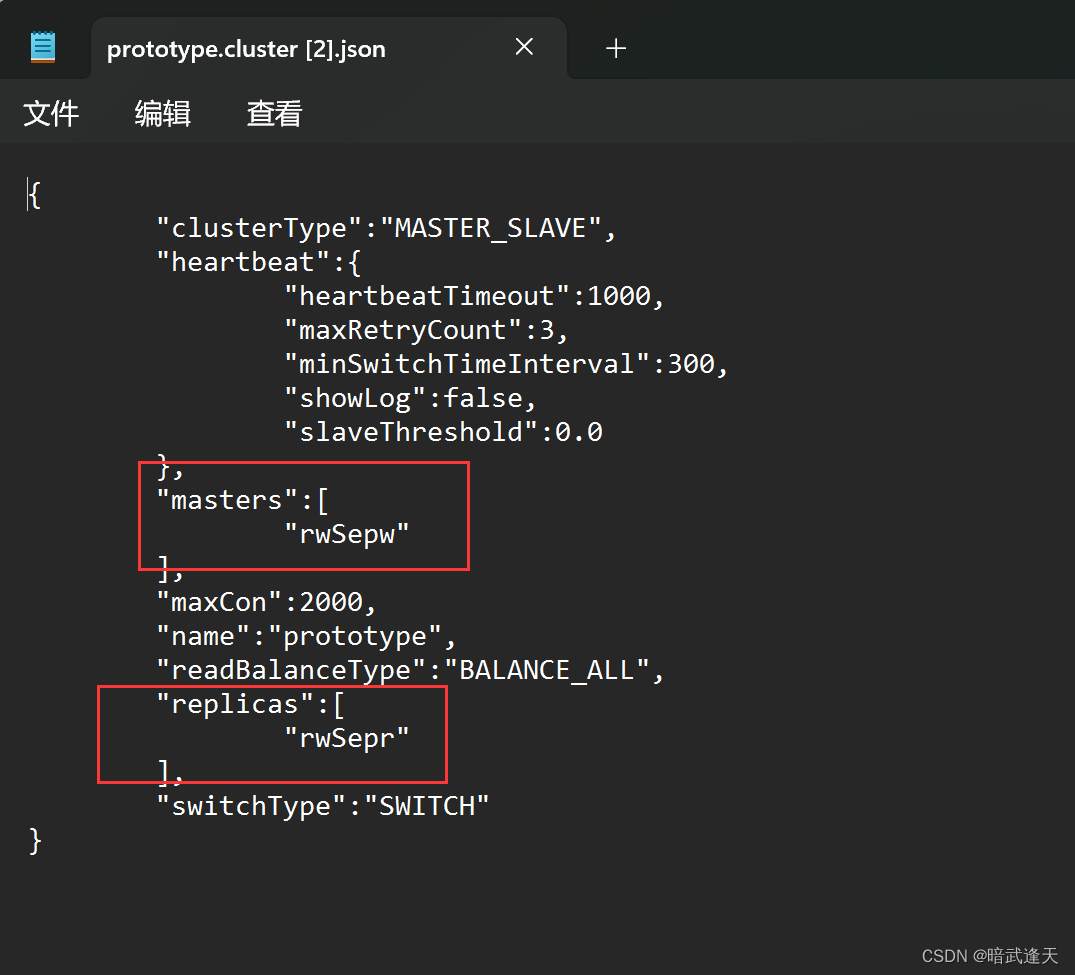
在mycat的bin目录下重启./mycat restart
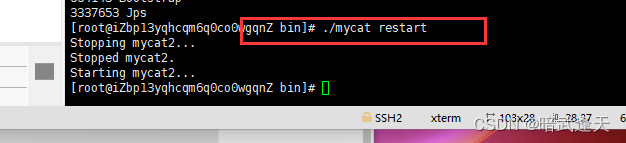
刷新mycat连接
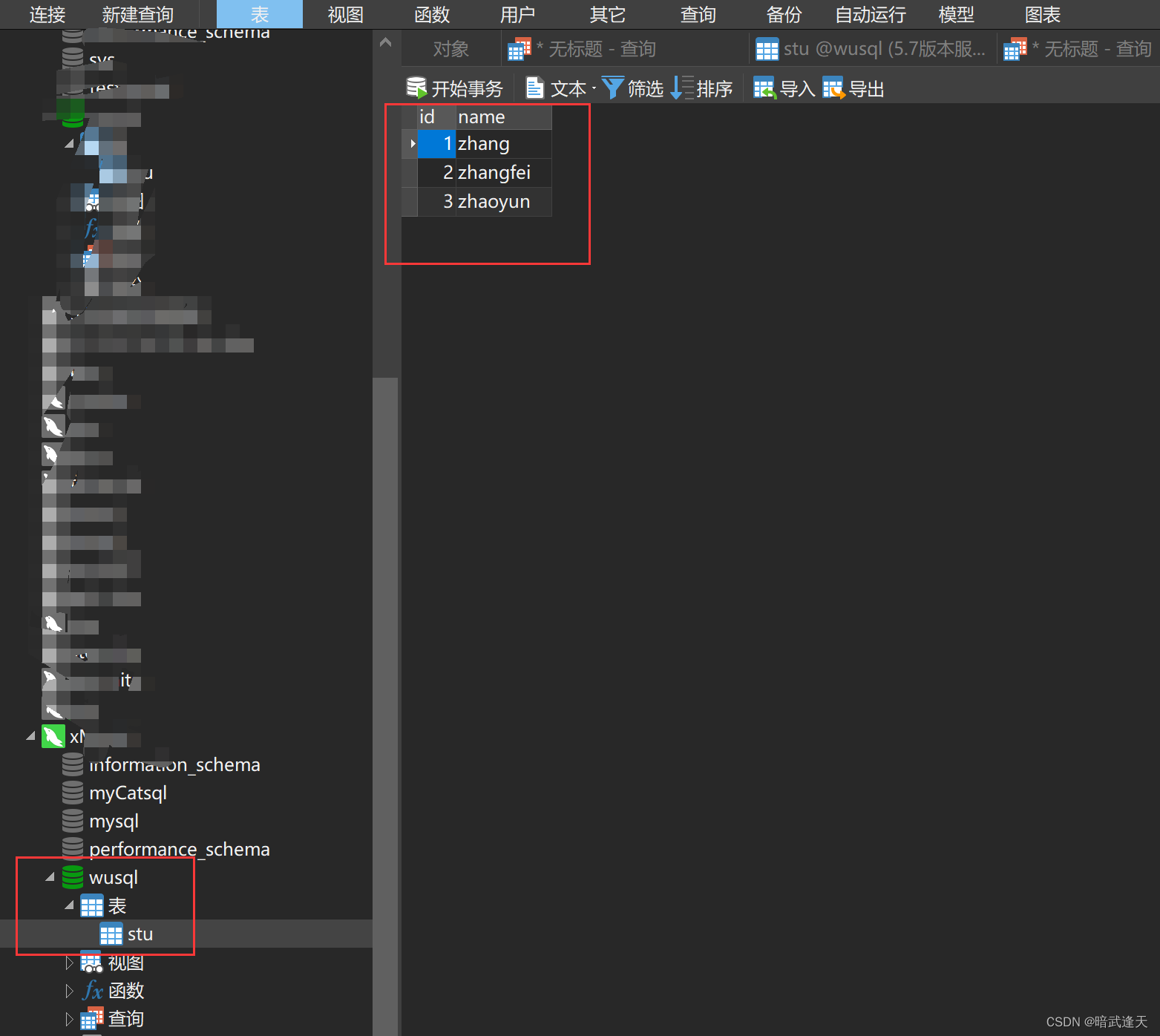
可以看到读取到了之前主表里插入的数据
验证主从读写分离
由于之前配置的主从关系,所以此时主机和从机表数据都是一致的,所以这里看不出来区别,可以手动在从表中插入一条数据,这样主表不会更新,就造成了主表从表数据不一致的情况
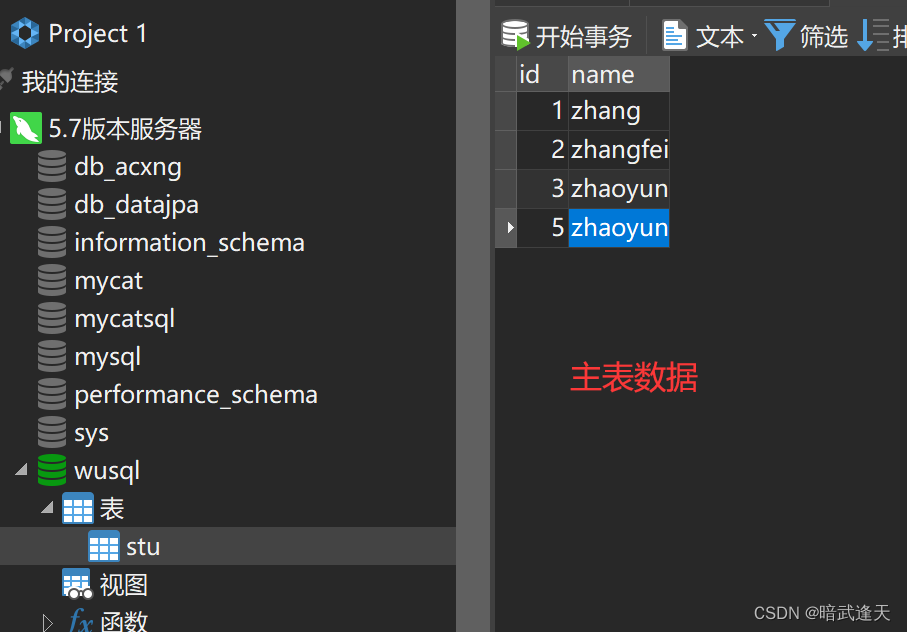
此时的主表数据
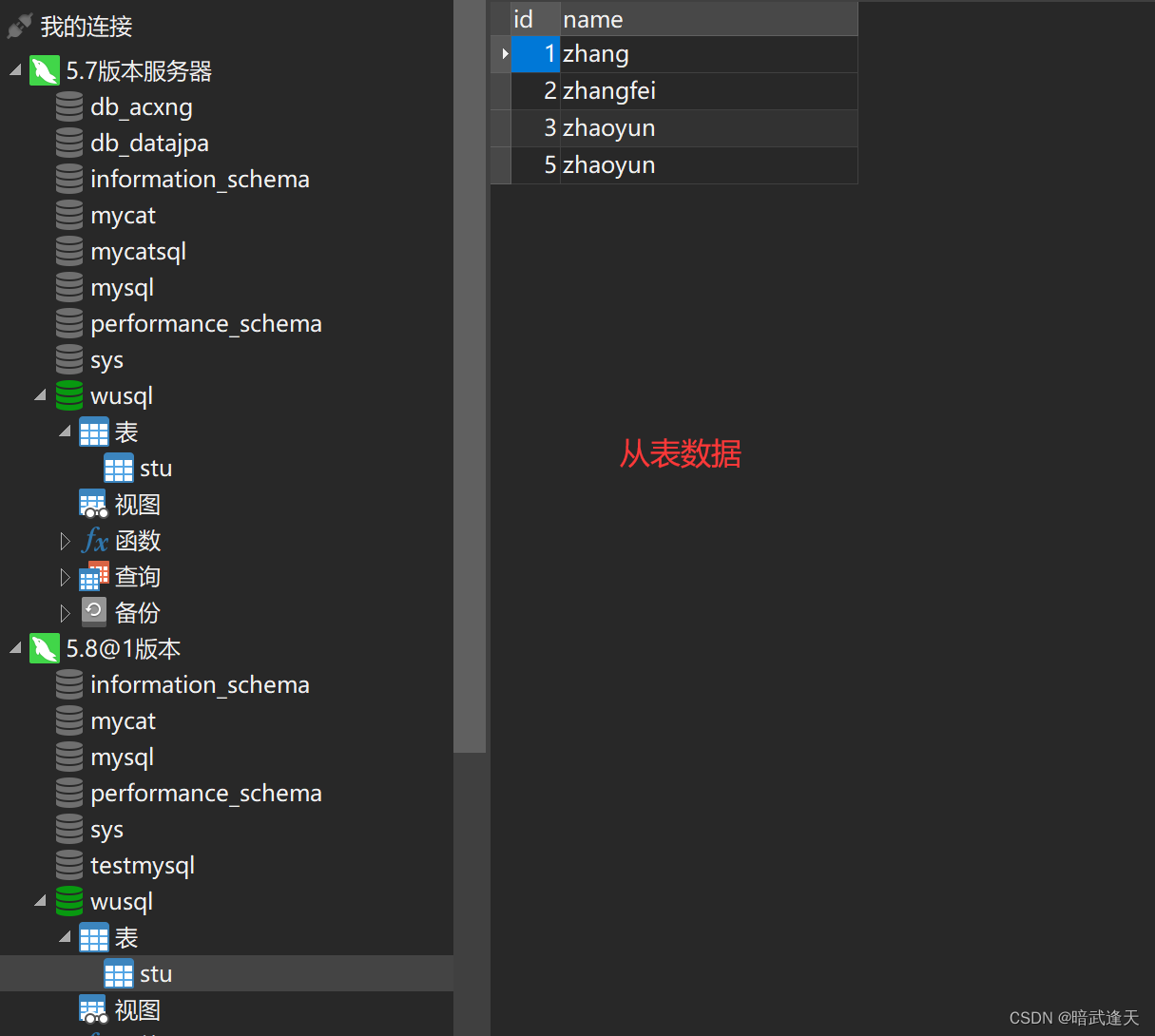
在从表中插入一条数据
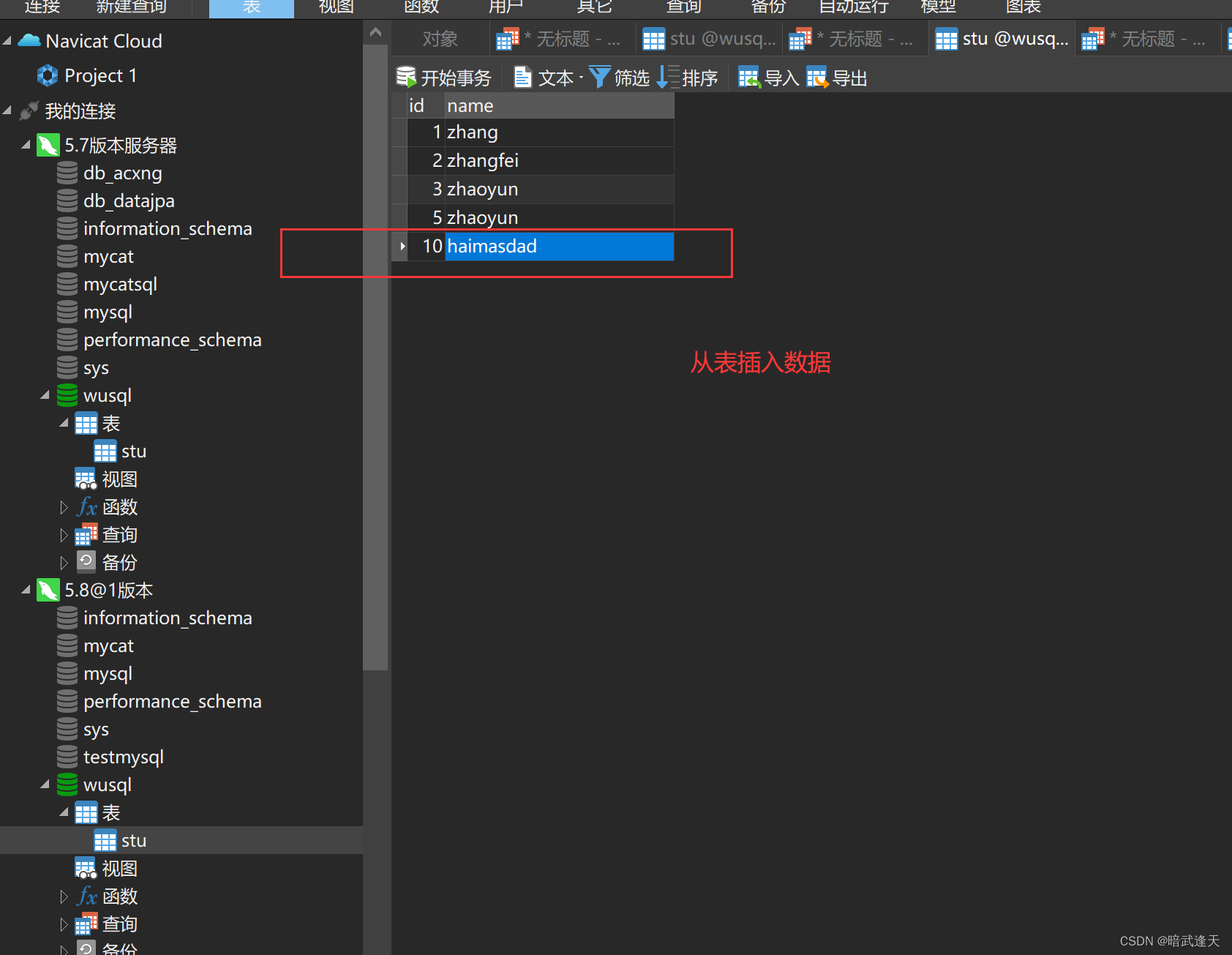 查看主表数据
查看主表数据
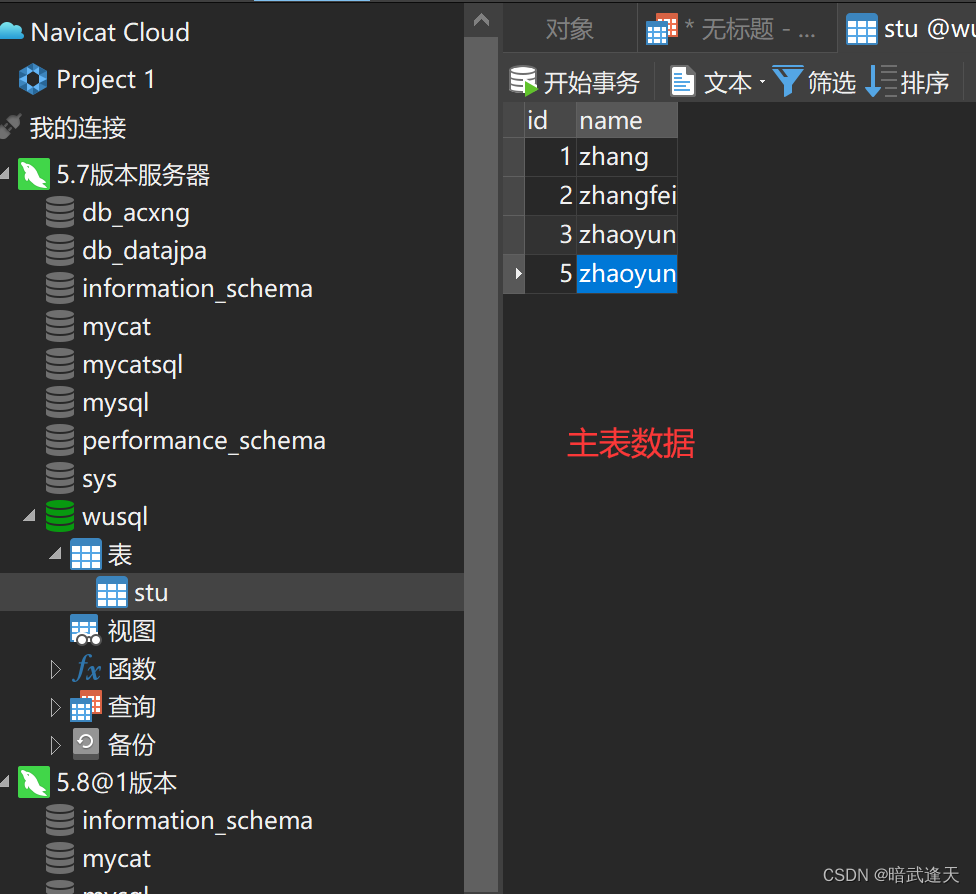
主表还是四条数据,此时就造成了主从不一致
此时再去mycat中查看数据

可以看到mycat在轮询显示主表和从表的数据
这是因为之前的配置中是获取所有数据源的数据,所以无论是主机和从机数据都会获取到,默认轮询获取
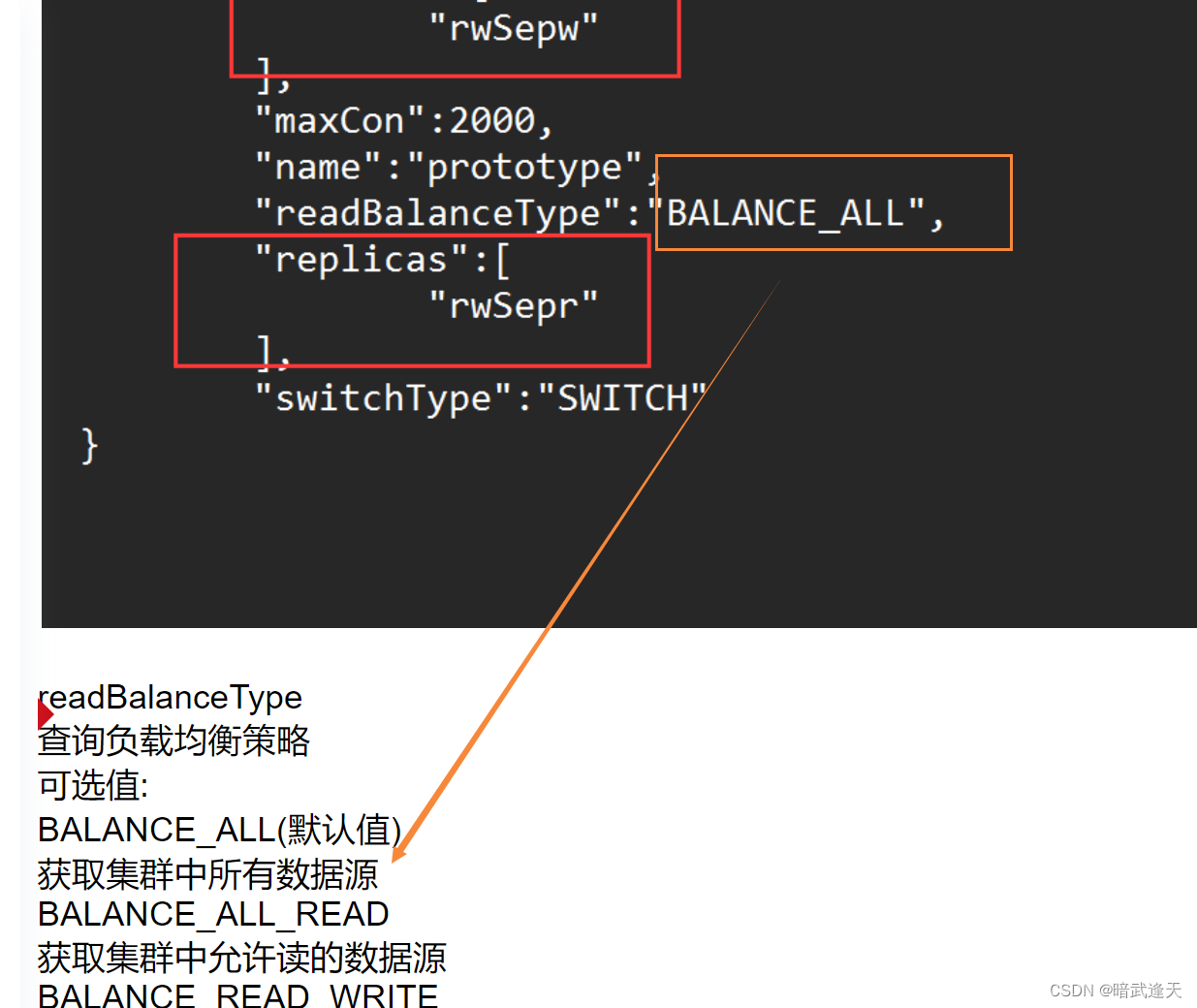
分库分表
原理
分库原则
一个问题:在两台主机上的两个数据库中的表,能否关联查询?
分表
正式分库分表
/*+ mycat:createDataSource{
"name":"dw0","url":"jdbc:mysql://ip:3306",
"user":"root",
"password":"密码"
} */;
/*+ mycat:createDataSource{
"name":"dr0",
"url":"jdbc:mysql://ip:3306",
"user":"root",
"password":"密码"
} */;
/*+ mycat:createDataSource{
"name":"dw1",
"url":"jdbc:mysql://ip:3306",
"user":"root",
"password":"密码"
} */;
/*+ mycat:createDataSource{
"name":"dr1",
"url":"jdbc:mysql://ip:3306",
"user":"root",
"password":"密码"
} */;
找到自己的mycat安装目录cd /usr/mycat/conf/datasources
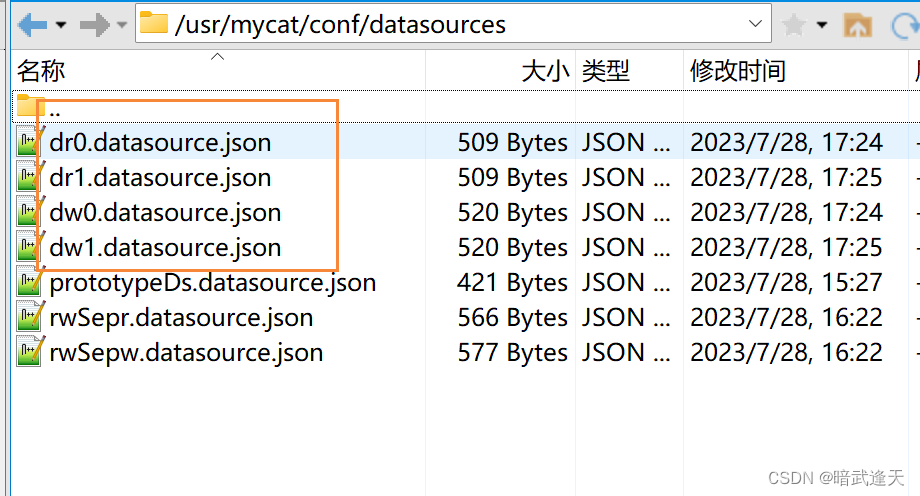
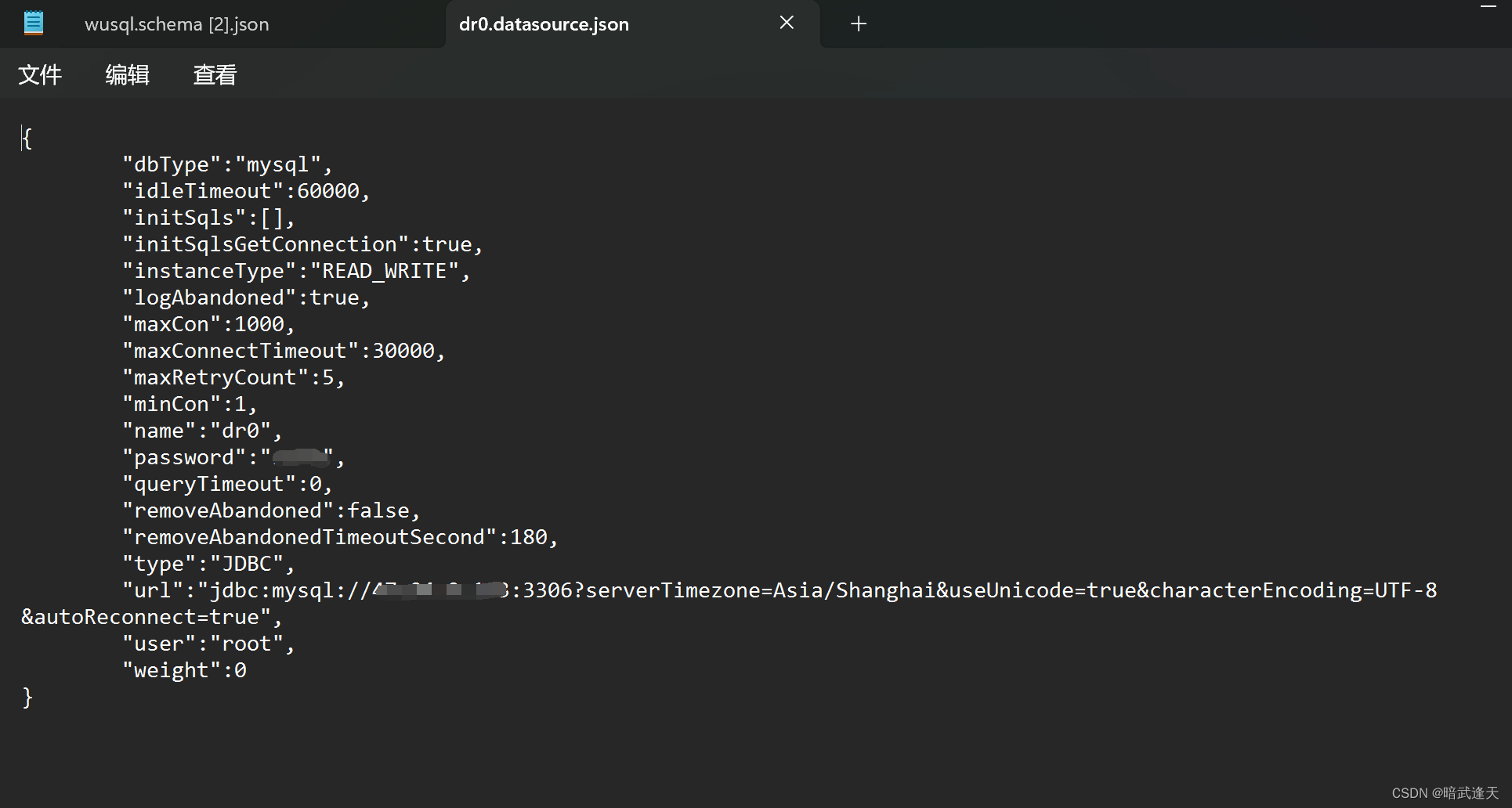
添加集群配置
把新添加的数据源配置成集群
在 mycat 终端输入

/*!
mycat:createCluster{"name":"c0","masters":["dw0"],"replicas":["dr0"]}
*/;
/*!
mycat:createCluster{"name":"c1","masters":["dw1"],"replicas":["dr1"]}
*/;
可以查看集群配置信息
cd /usr/mycat/conf/clusters
两个集群
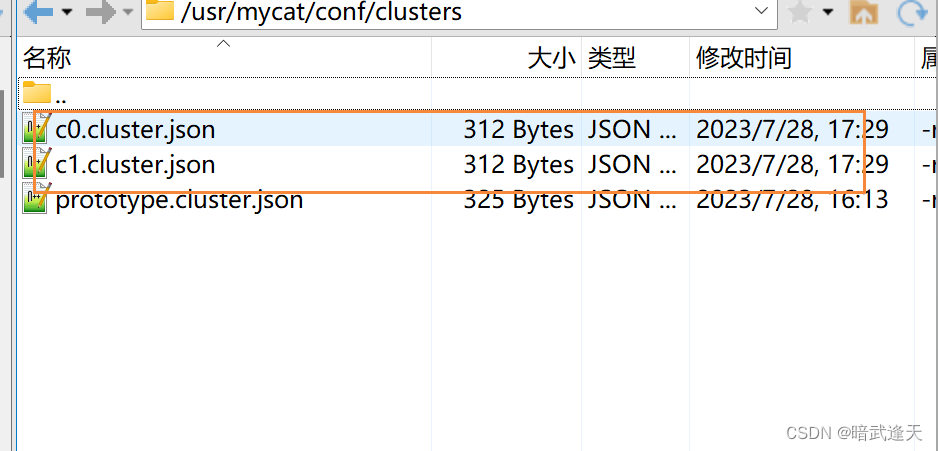
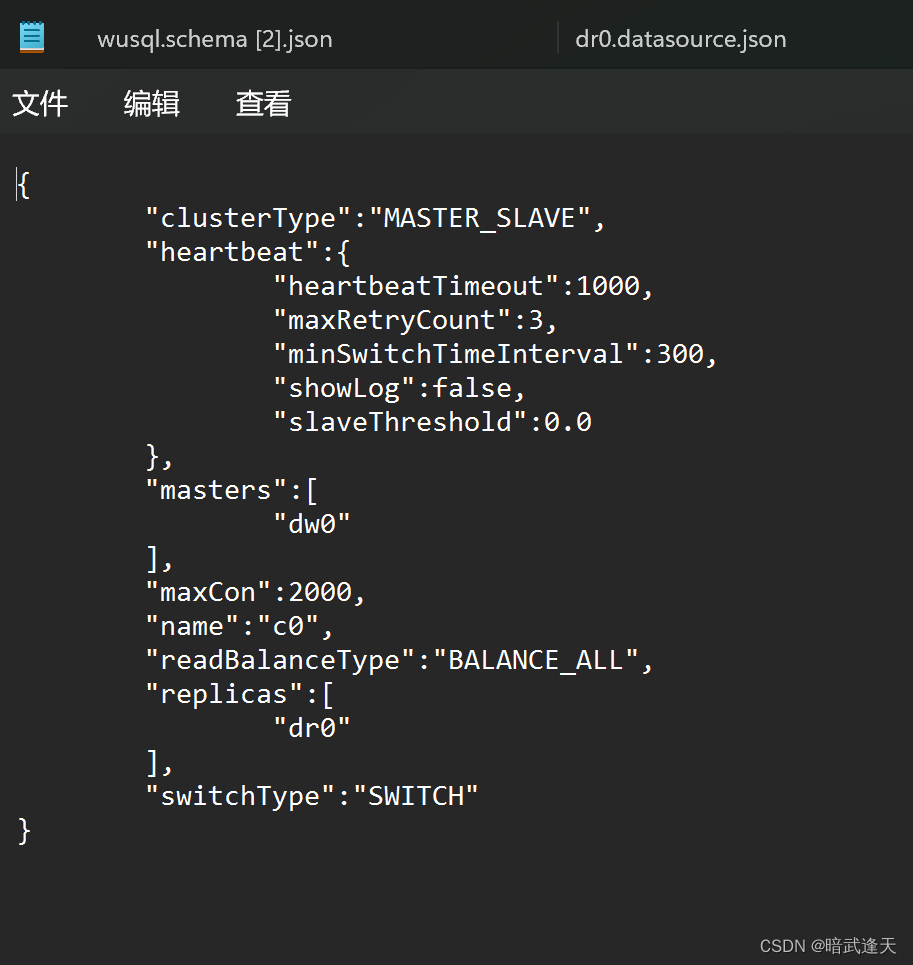
创建全局表(广播表)
创建数据库db1
create database db1
切换到db1
use db1;
在建表语句中加上关键字 BROADCAST(广播,即为全局表)
CREATE TABLE db1.`travelrecord` (
`id` bigint NOT NULL AUTO_INCREMENT,
`user_id` varchar(100) DEFAULT NULL,
`traveldate` date DEFAULT NULL,
`fee` decimal(10,0) DEFAULT NULL,
`days` int DEFAULT NULL,
`blob` longblob,
PRIMARY KEY (`id`),
KEY `id` (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 BROADCAST;
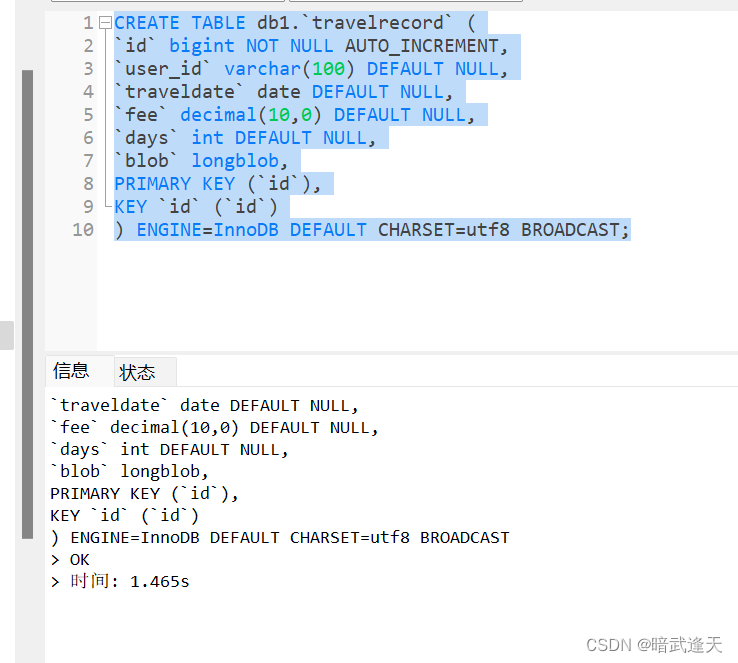
可以看到主机和从机也都同步了db1数据库
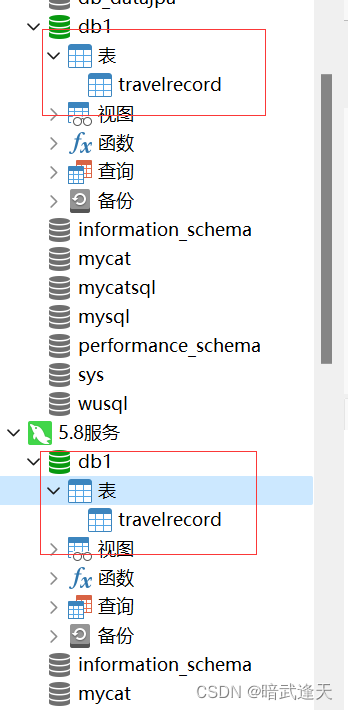
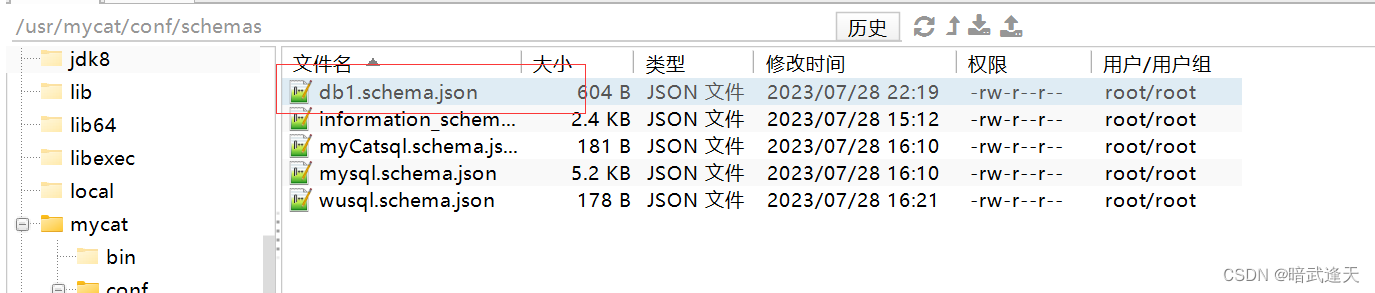
进入mycat安装目录查看db1数据库配置
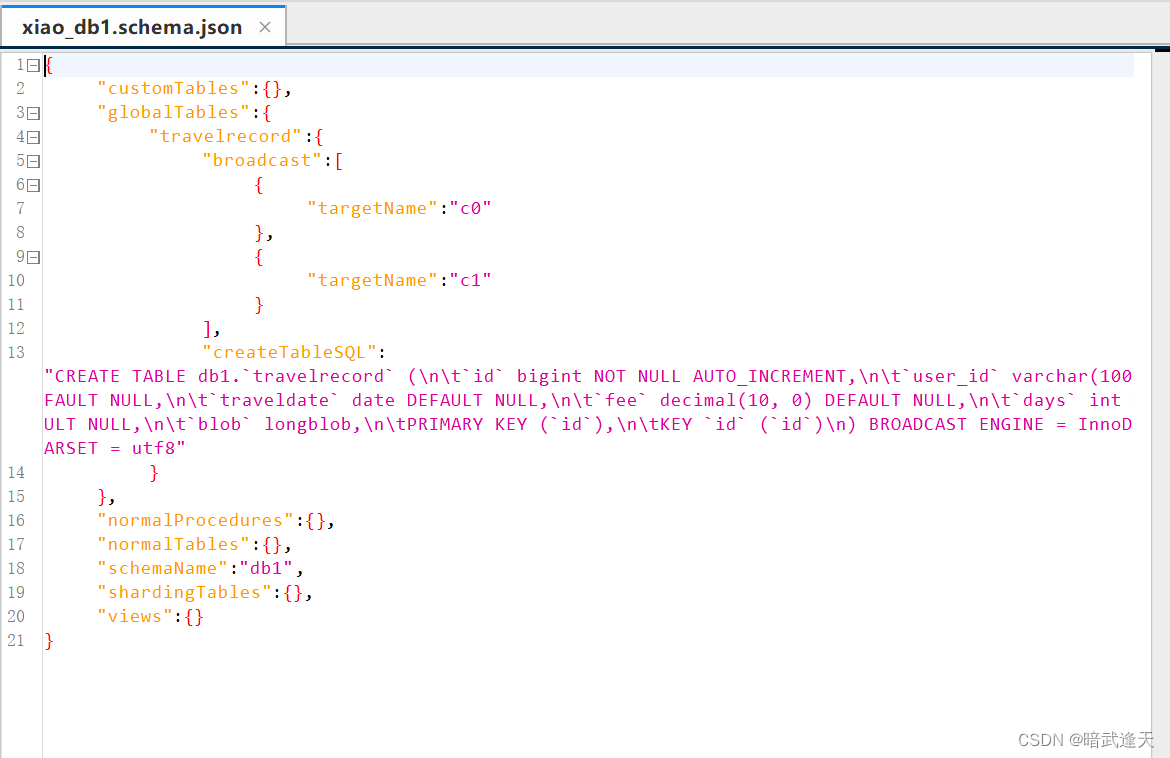
在 Mycat 终端直接运行建表语句进行数据分片
核心就是后面的分片规则。 dbpartition表示分库规则,tbpartition表示分表规则。而mod hash表示按照customer id字段取模进行分片
tbpartitions 1 dbpartitions 2 表示分一片,数据库两个
CREATE TABLE db1.orders(
id BIGINT NOT NULL AUTO_INCREMENT,
order_type INT,
customer_id INT,
amount DECIMAL(10,2),
PRIMARY KEY(id),
KEY `id` (`id`)
)ENGINE=INNODB DEFAULT CHARSET=utf8
dbpartition BY mod_hash(customer_id) tbpartition BY mod_hash(customer_id)
tbpartitions 1 dbpartitions 2;
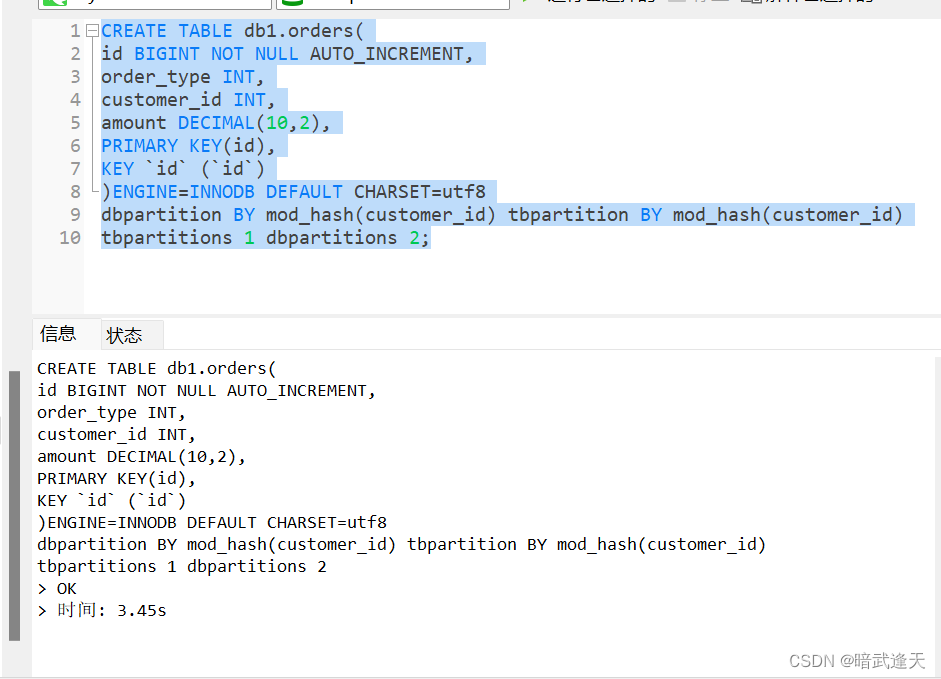
数据库分片规则,表分片规则,以及各分多少片
插入语句测试:
INSERT INTO orders(id,order_type,customer_id,amount)
VALUES(1,101,100,100100);
INSERT INTO orders(id,order_type,customer_id,amount)
VALUES(2,101,100,100300);
INSERT INTO orders(id,order_type,customer_id,amount)
VALUES(3,101,101,120000);
INSERT INTO orders(id,order_type,customer_id,amount)
VALUES(4,101,101,103000);
INSERT INTO orders(id,order_type,customer_id,amount)
VALUES(5,102,101,100400);
INSERT INTO orders(id,order_type,customer_id,amount)
VALUES(6,102,100,100020);
在mycat中查看数据
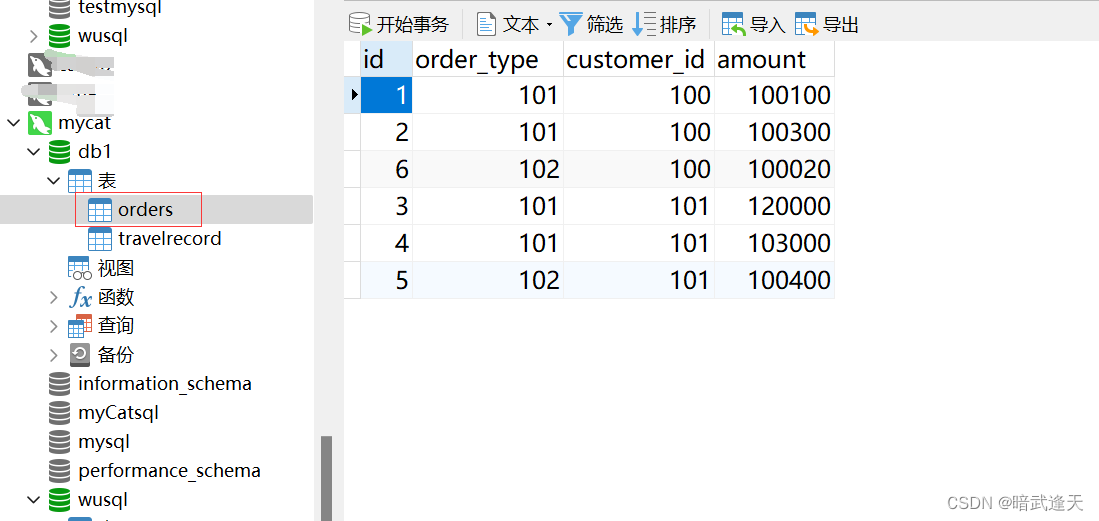
在主机中查看:
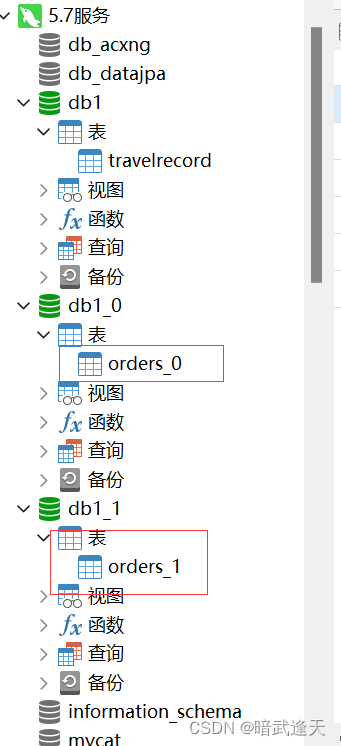
可以看到主机中直接创建了两个新的db库
分别查看两个db库的数据
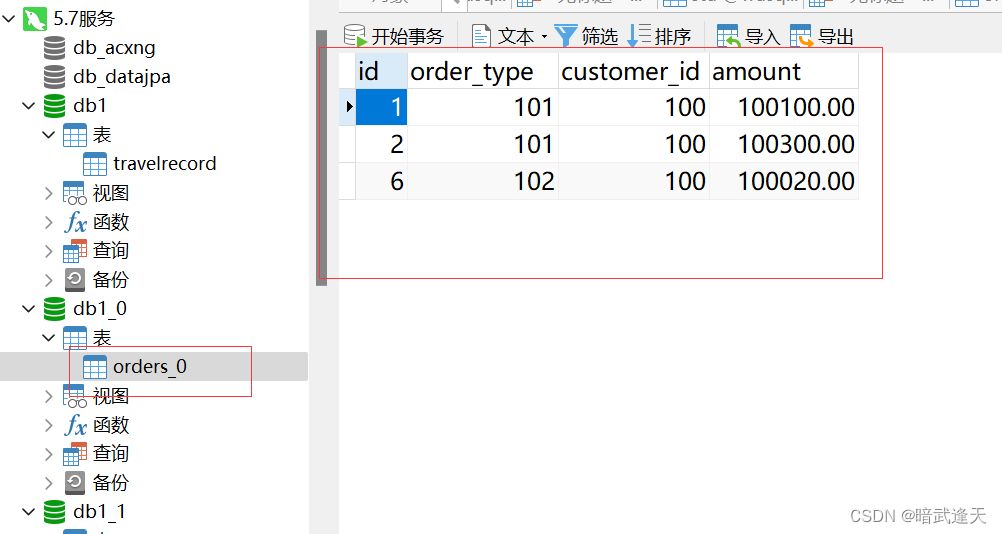
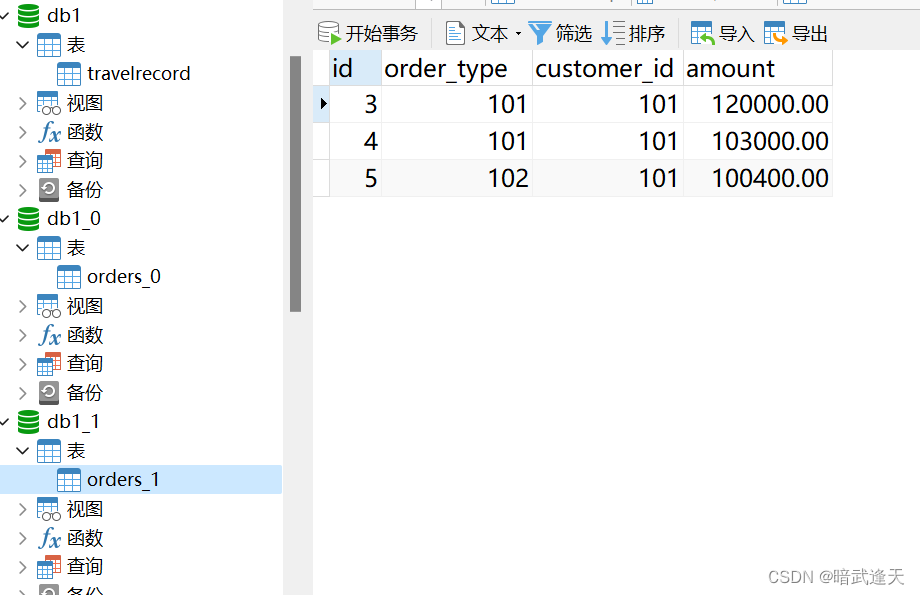
可以看到两个db库分别有三条数据,总和就是mycat的六条数据,从而实现了分库分表功能
创建 ER 表
与分片表关联的表如何分表,也就是 ER 表如何分表
在 Mycat 终端直接运行建表语句进行数据分片
CREATE TABLE orders_detail(
`id` BIGINT NOT NULL AUTO_INCREMENT,
detail VARCHAR(2000),
order_id INT,
PRIMARY KEY(id)
)ENGINE=INNODB DEFAULT CHARSET=utf8
dbpartition BY mod_hash(order_id) tbpartition BY mod_hash(order_id)
tbpartitions 1 dbpartitions 2;
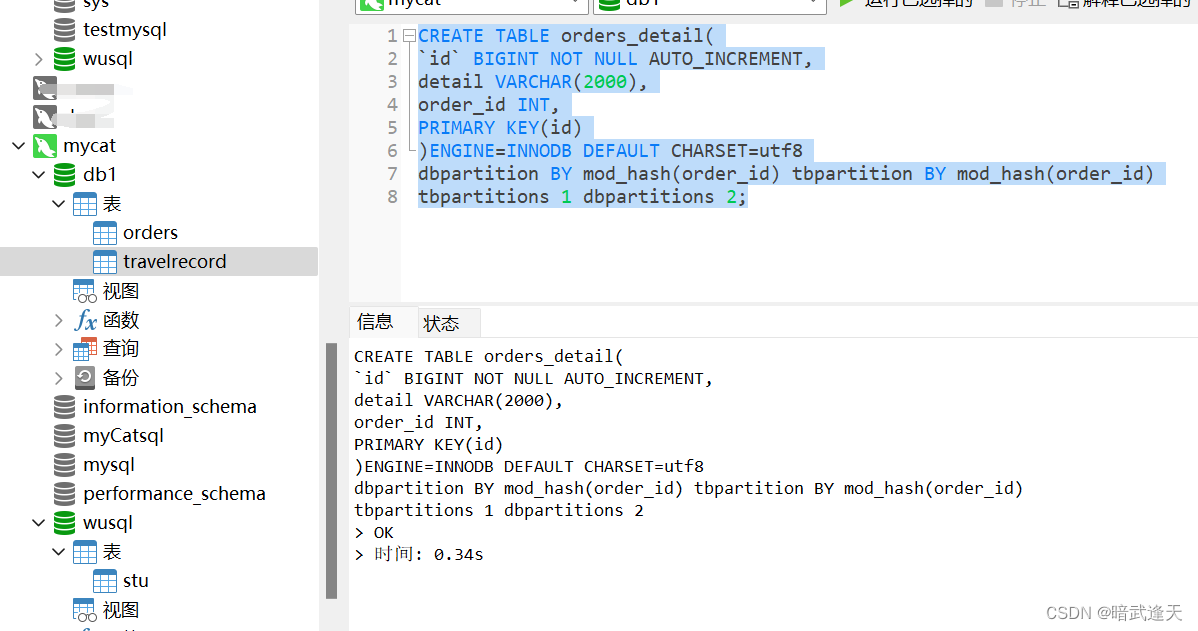
插入数据测试:
INSERT INTO orders_detail(id,detail,order_id) VALUES(1,'detail1',1); INSERT INTO orders_detail(id,detail,order_id) VALUES(2,'detail1',2); INSERT INTO orders_detail(id,detail,order_id) VALUES(3,'detail1',3); INSERT INTO orders_detail(id,detail,order_id) VALUES(4,'detail1',4); INSERT INTO orders_detail(id,detail,order_id) VALUES(5,'detail1',5); INSERT INTO orders_detail(id,detail,order_id) VALUES(6,'detail1',6);
运行关联语句查询数据
SELECT * FROM orders o INNER JOIN orders_detail od ON od.order_id=o.id;

对比数据节点1
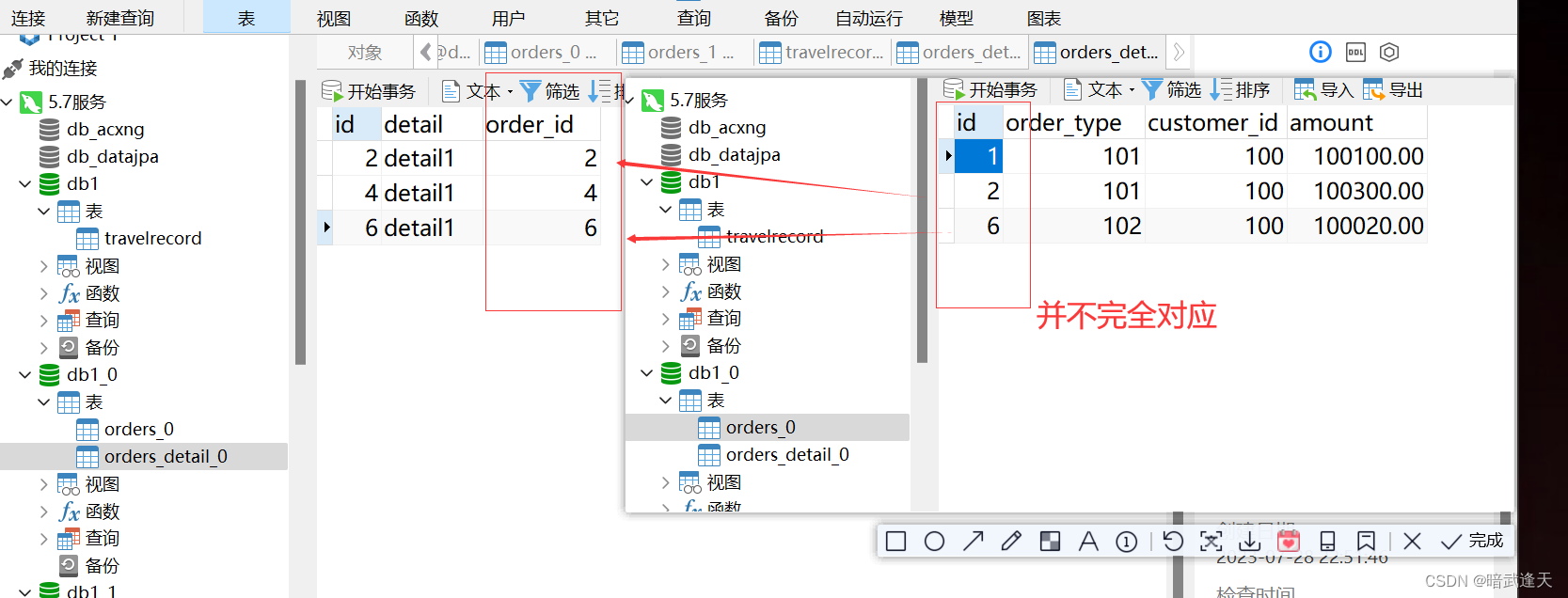
对比数据节点2
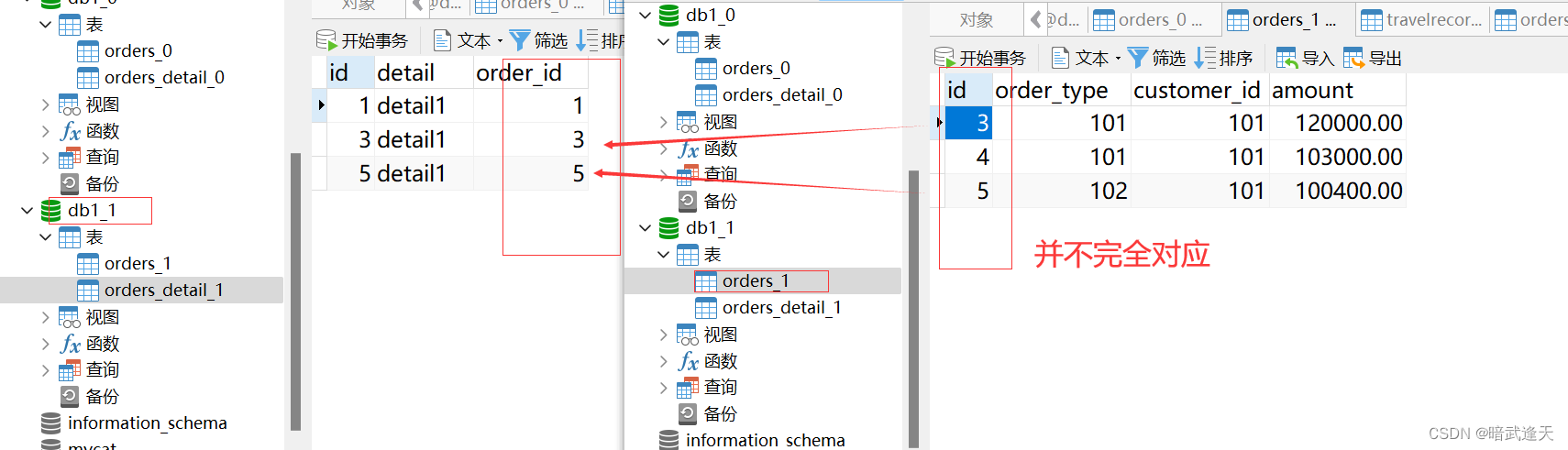
两个数据库节点中的关联表中的数据并不都是完全对应的,但是关联语句却可以查询出所有关联字段数据
上述两表具有相同的分片算法,但是分片字段不相同
Mycat2 在涉及这两个表的 join 分片字段等价关系的时候可以完成 join 的下推
Mycat2 无需指定 ER 表,是自动识别的,具体看分片算法的接口
查看配置的表是否具有 ER关系
/*+ mycat:showErGroup{}*/
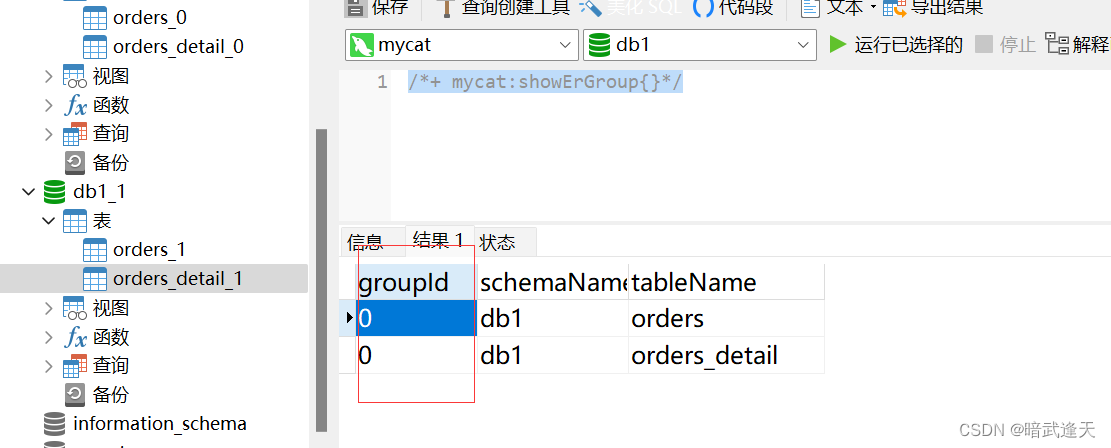
可以看到group_id 表示相同的组,该组中的表具有相同的存储分布
原理如下:
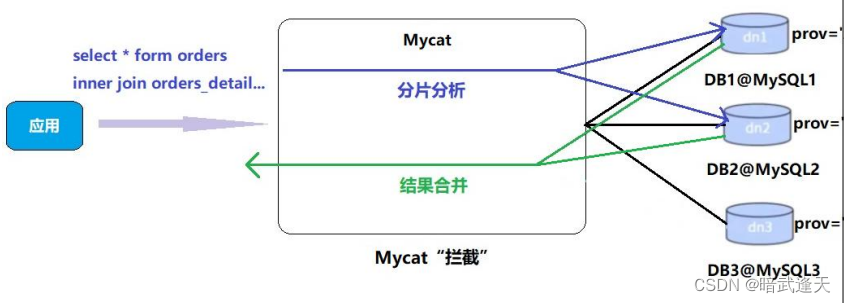
常用分片规则
1、分片算法简介
Mycat2 支持常用的(自动)HASH 型分片算法也兼容 1.6 的内置的(cobar)分片算法. HASH 型分片算法默认要求集群名字以 c 为前缀,数字为后缀,c0 就是分片表第一个 节点,c1 就是第二个节点.该命名规则允许用户手动改变
2、Mycat2 与 1.x 版本区别
Mycat2 Hash 型分片算法多数基于 MOD_HASH(MOD 对应 JAVA 的%运算),实际上是取 余运算。 Mycat2 Hash 型分片算法对于值的处理,总是把分片值转换到列属性的数据类型再 运算。 而 1.x 系列的分片算法统一转换到字符串类型再运算且只能根据一个分片字段计算 出存储节点下标。 Mycat2 Hash 型分片算法适用于等价条件查询。 而 1.x 系列由于含有用户经验的路由规则。1.x 系列的分片规则总是先转换成字符 串再运算。
3、分片规则与适用性
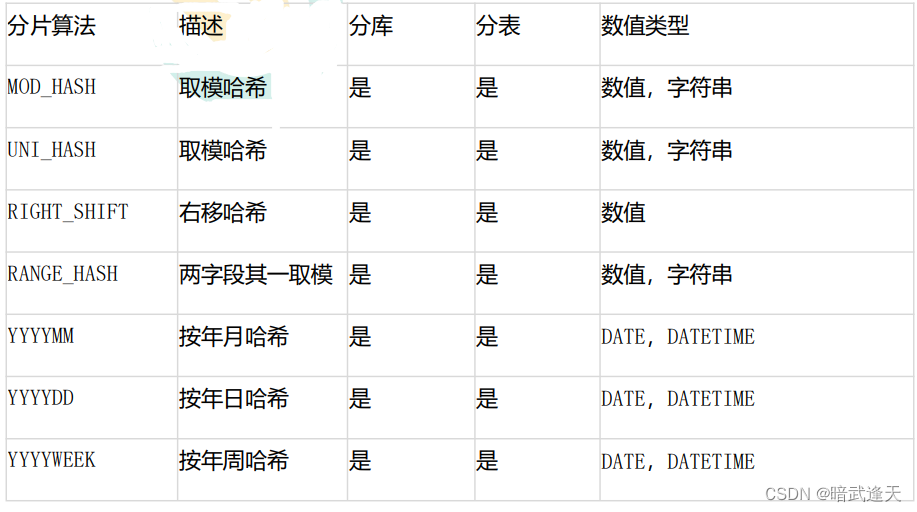
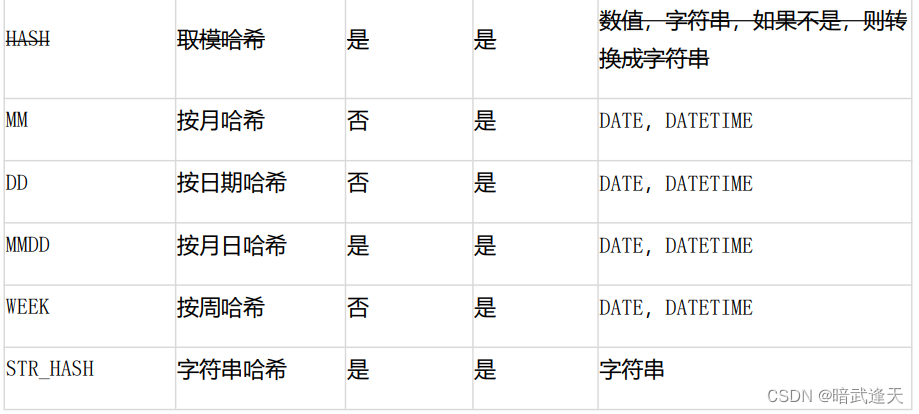
4、常用分片规则简介
(1)MOD_HASH
[数据分片]HASH 型分片算法-MOD_HASH 如果分片值是字符串则先对字符串进行 hash 转换为数值类型 分库键和分表键是同键: 分表下标=分片值%(分库数量*分表数量) 分库下标=分表下标/分表数量 分库键和分表键是不同键: 分表下标= 分片值%分表数量 分库下标= 分片值%分库数量
(2)RIGHT_SHIFT
[数据分片]HASH 型分片算法-RIGHT_SHIFT RIGHT_SHIFT(字段名,位移数) 仅支持数值类型 分片值右移二进制位数,然后按分片数量取余
(3)YYYYMM
[数据分片]HASH 型分片算法-YYYYMM 仅用于分库 (YYYY*12+MM)%分库数.MM 是 1-12
(4)MMDD
仅用于分表 仅 DATE/DATETIME 一年之中第几天%分表数 tbpartitions 不超过 366
全局序列
Mycat2 在 1.x 版本上简化全局序列,自动默认使用雪花算法生成全局序列号,如 不需要 Mycat 默认的全局序列,可以通过配置关闭自动全局序列
带 AUTO_INCREMENT 关键字使用默认全局序列
如果不需要使用 mycat 的自增序列,而使用 mysql 本身的自增主键的功能,需要在 配置中更改对应的建表 sql,不设置 AUTO_INCREMENT 关键字,这样,mycat 就不认为这个 表有自增主键的功能,就不会使用 mycat 的全局序列号.这样,对应的插入 sql 在 mysql 处理,由 mysql 的自增主键功能补全自增值. 雪花算法:引入了时间戳和 ID 保持自增的分布式 ID 生成算法

