
- 1Ubuntu下配置Tomcat服务器(初始化文件,使用脚本进行自启动)_ubuntu 调用tomcat
- 2姿态解算-陀螺仪+欧拉法_陀螺仪姿态解算
- 3day21-二叉树part08
- 4新手尝试硬件买单片机还是树莓派?
- 5完美解决 git 报错fatal: Not a git repository (or any of the parent directories): .git_gitlab idea,如何将令牌改为用户名密码 报错fatal: not a git reposi
- 6如果你想进大厂,那对不起,算法是笔试面试的必考题_大厂社招考算法吗
- 7html网页制作之简单登入界面_html表格登录界面
- 8【 stable diffusion LORA模型训练最全最详细教程】_stable diffusion 训练 秋叶
- 9解决Error:Kotlin:Module was compiled with an incompatible version of Kotlin.The binary 。。。报错_error:kotlin: module was compiled with an incompat
- 10【Flutter】顶部导航栏实现 ( Scaffold | DefaultTabController | TabBar | Tab | TabBarView )
Transformers微调BERT模型实现文本分类任务(colab)_added_tokens_decoder={0: addedtoken("[pad]", rstri
赞
踩
1. 数据准备
使用colab进行实验
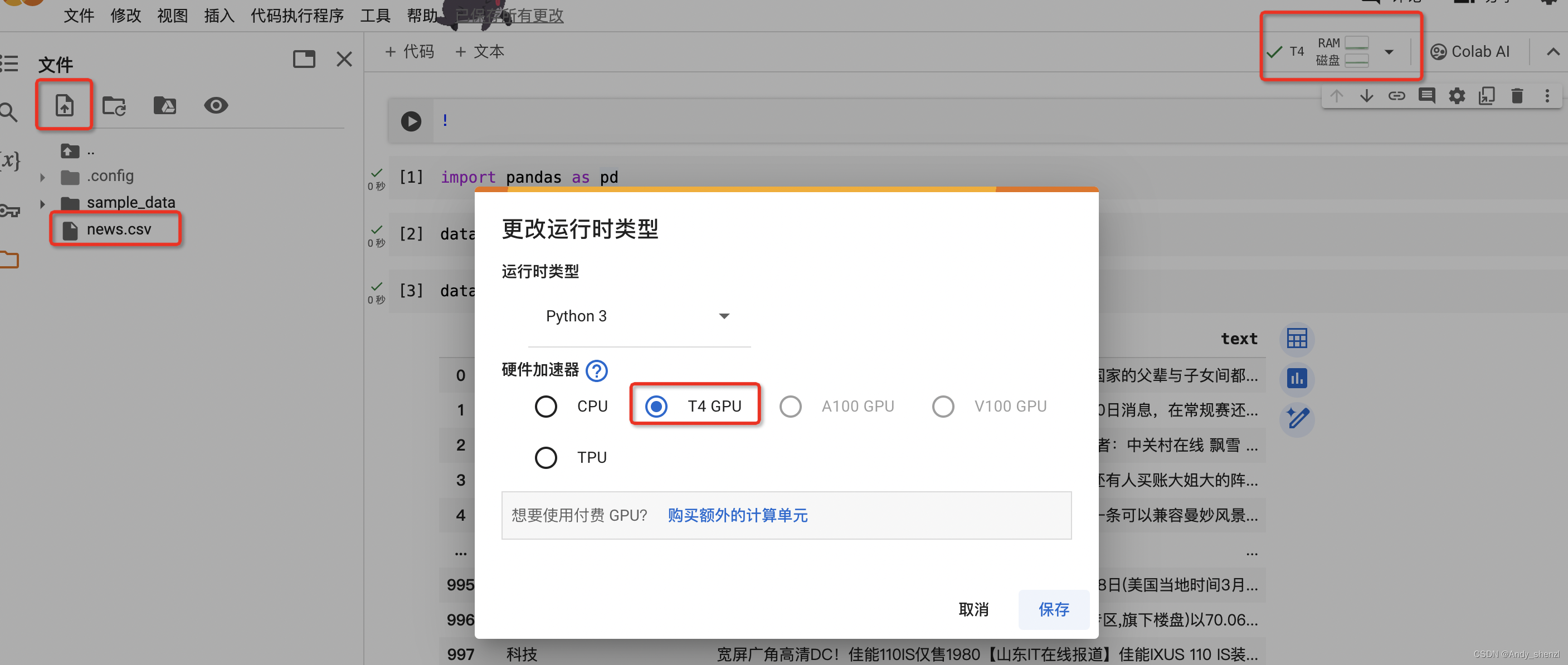
左上角上传数据,到当前实验室
右上角设置GPU选择
! nvidia-sm
- 1
- 2
安装需要的库
!pip install datasets
!pip install transformers[torch]
!pip install torchkeras
- 1
- 2
- 3
1.1 读取数据
import pandas as pd
data = pd.read_csv("/content/news.csv")
data
- 1
- 2
- 3

1.2 数据处理
我们看到label是中文字符串,训练时需要转换成数值型,如下
{'教育': 0,
'体育': 1,
'科技': 2,
'时尚': 3,
'房产': 4,
'家居': 5,
'财经': 6,
'时政': 7,
'娱乐': 8,
'游戏': 9}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
遍历一下就可以,并将全数据转换为data frame
#处理标签 def label_dic(data,label): d = {} labels = data[label].unique() for i,v in enumerate(labels): d[v] = i return d #数据整理 def get_train_data(data,col_x,col_y,label_dic): content = data[col_x] label = [] for i in data[col_y]: label.append(label_dic.get(i)) return content,label label_dic = label_dic(data,"label") content,label = get_train_data(data,"text","label",label_dic)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
1.3 数据转换
将数据转换成可以进行训练的数据
data = pd.DataFrame({"content":content,"label":label})
data = shuffle(data)
- 1
- 2
1.4 创建分词
from transformers import AutoTokenizer #BertTokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-chinese')
tokenizer
- 1
- 2
- 3
tokenizer
BertTokenizerFast(name_or_path=‘bert-base-chinese’, vocab_size=21128, model_max_length=512, is_fast=True, padding_side=‘right’, truncation_side=‘right’, special_tokens={‘unk_token’: ‘[UNK]’, ‘sep_token’: ‘[SEP]’, ‘pad_token’: ‘[PAD]’, ‘cls_token’: ‘[CLS]’, ‘mask_token’: ‘[MASK]’}, clean_up_tokenization_spaces=True), added_tokens_decoder={
0: AddedToken(“[PAD]”, rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
100: AddedToken(“[UNK]”, rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
101: AddedToken(“[CLS]”, rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
102: AddedToken(“[SEP]”, rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
103: AddedToken(“[MASK]”, rstrip=False, lstrip=False, single_word=False, normalized=False, special=True),
}
训练集取80%
train_len = round(len(data)*0.8)
train_data = tokenizer(data.content.to_list()[:train_len], padding = "max_length", max_length = 128, truncation=True ,return_tensors = "pt")
train_label = data.label.to_list()[:train_len]
- 1
- 2
- 3
2. 模型训练
2.1 导入模型
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("bert-base-chinese", num_labels=10)
- 1
- 2
- 3

在AutoModelForSequenceClassification.from_pretrained(“bert-base-chinese”, num_labels=10) 这个函数中,transformer 已经帮你定义了损失函数,既10个分类的交叉熵损失,所以下方我们只需要自己定义优化器和学习率即可。
2.2 定义优化器和学习率
import torch
from torch.utils.data import TensorDataset, DataLoader, RandomSampler, SequentialSampler
batch_size = 16
train = TensorDataset(train_data["input_ids"], train_data["attention_mask"], torch.tensor(train_label))
train_sampler = RandomSampler(train)
train_dataloader = DataLoader(train, sampler=train_sampler, batch_size=batch_size)
- 1
- 2
- 3
- 4
- 5
- 6
-
train_data 是一个包含输入数据的字典,其中 “input_ids” 是模型输入的token ID,“attention_mask” 是用于标识输入序列中哪些位置是有效的前景tokens,“labels” 是序列分类任务的标签。我们可以自己打印下我们前面定义好的训练数据,如下
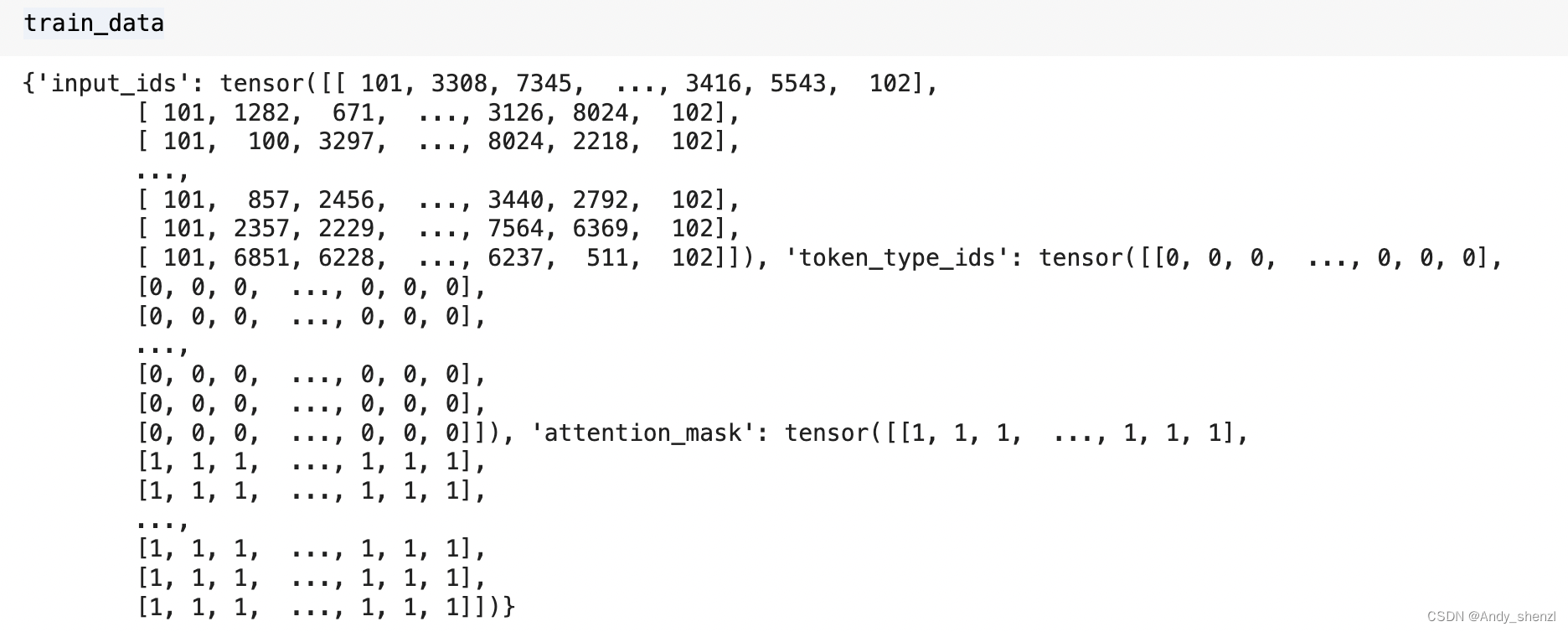
-
TensorDataset 将数据转换为一个PyTorch张量数据集,其中每个样本是一个包含input_ids、attention_mask和label的元组。
-
RandomSampler 从数据集中随机抽取样本进行训练,这对于避免过拟合和获得更具代表性的训练集是有益的。
-
DataLoader 负责将数据集划分为批次,并为训练提供迭代器。
#定义优化器
from torch.optim import AdamW
optimizer = AdamW(model.parameters(), lr=1e-4)
#定义学习率和训练轮数
num_epochs = 1
from transformers import get_scheduler
num_training_steps = num_epochs * len(train_dataloader)
lr_scheduler = get_scheduler(
name="linear", optimizer=optimizer, num_warmup_steps=0, num_training_steps=num_training_steps
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- model 是需要训练的模型,我们前面导入的预训练模型。
- AdamW 是用于优化模型参数的优化器,它是一种改进的Adam优化器,常用于深度学习。
- lr_scheduler 是学习率调度器,它用于在训练过程中调整学习率。在这个例子中,使用的是"linear"调度器,它会在训练开始时逐渐增加学习率,然后逐渐减少。
- num_epochs 定义了训练的轮数。
- num_training_steps 定义了训练的总步数,它是 epochs 乘以训练数据集的总步数。
- get_scheduler 函数用于根据提供的参数创建学习率调度器。
2.3 开始训练
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)
- 1
- 2
检查是否有可用的GPU,如果有,则将device设置为cuda;否则,设置为cpu。模型移动到选定的设备上。
循环
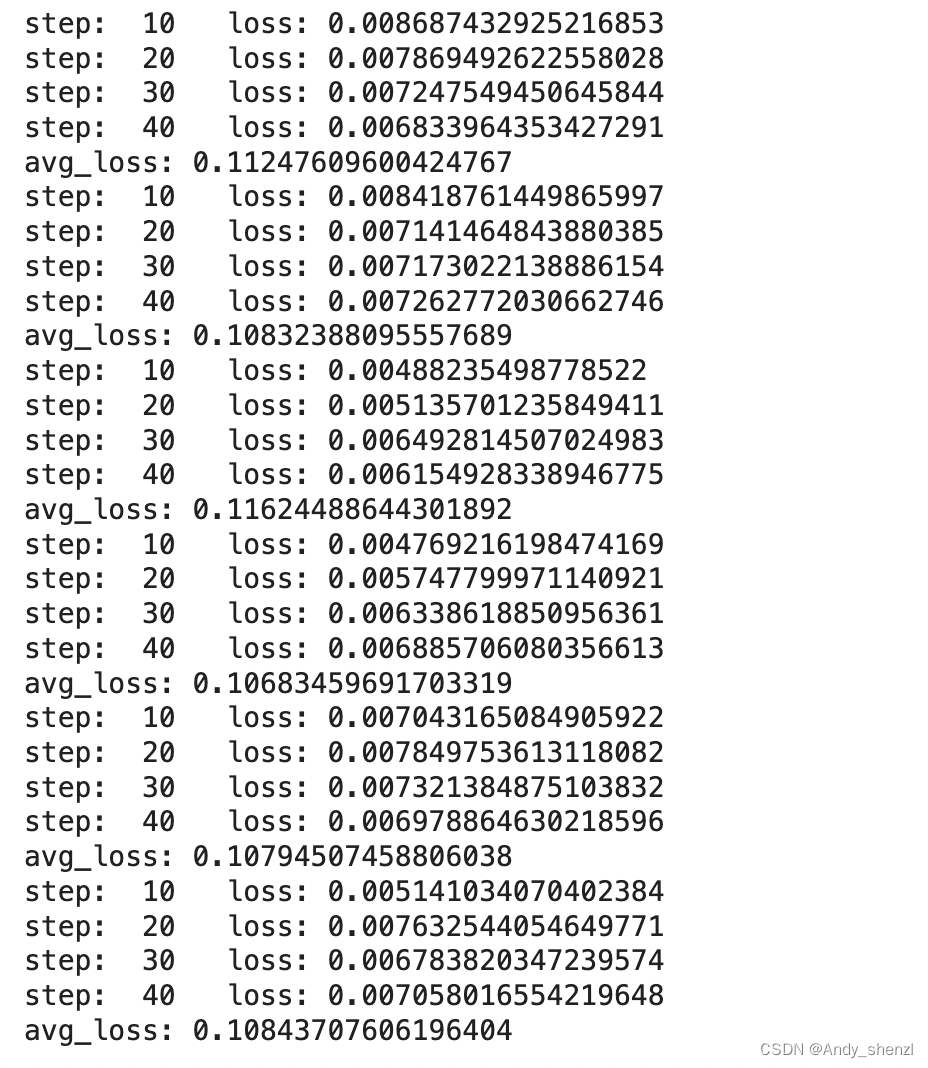
for epoch in range(num_epochs): total_loss = 0 model.train() for step, batch in enumerate(train_dataloader): if step % 10 == 0 and not step == 0: print("step: ",step, " loss:",total_loss/(step*batch_size)) b_input_ids = batch[0].to(device) b_input_mask = batch[1].to(device) b_labels = batch[2].to(device) model.zero_grad() outputs = model(b_input_ids, token_type_ids=None, attention_mask=b_input_mask, labels=b_labels) loss = outputs.loss total_loss += loss.item() loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) optimizer.step() lr_scheduler.step() avg_train_loss = total_loss / len(train_dataloader) print("avg_loss:",avg_train_loss)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
-b_input_ids、b_input_mask、b_labels:这些是从批次中提取的输入ID、掩码和标签,并移动到device上。
- model.zero_grad():清除模型的梯度。
- outputs = model(…):使用模型进行前向传播。
- loss = outputs.loss:从输出中提取损失。
- total_loss += loss.item():累加损失。
- loss.backward():进行反向传播,计算损失关于模型参数的梯度。
- torch.nn.utils.clip_grad_norm_(…):对梯度进行裁剪,以防止梯度爆炸。
- optimizer.step():更新模型的参数。
- lr_scheduler.step():更新学习率。
3. 模型预测
inp = "专家指导:参加SSAT考试读美国优质高中(图)SSAT考试的全称是Secondary SchoolAdmission Test),是美国(微博)中学入学测试,相当于中国的中考,近年来,越来越多的中国学生通过参加SSAT申请美国高中,然后一步步进入世界一流大学。"
import numpy as np
test = tokenizer(inp,return_tensors="pt",padding="max_length",max_length=128)
model.eval()
with torch.no_grad():
test["input_ids"] = test["input_ids"].to(device)
test["attention_mask"] = test["attention_mask"].to(device)
outputs = model(test["input_ids"],
token_type_ids=None,
attention_mask=test["attention_mask"])
pred_flat = np.argmax(outputs["logits"].cpu(),axis=1).numpy().squeeze()
pred_flat.tolist()
#0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
我们也可以把标签进行一个映射
id2label_dic={}
for k,v in label_dic.items():
id2label_dic[v] = k
id2label_dic[pred_flat.tolist()]
#教育
- 1
- 2
- 3
- 4
- 5
4. 模型保存
model.config.id2label = id2label_dic
model.save_pretrained("./bert0207")
tokenizer.save_pretrained("./bert0207")
- 1
- 2
- 3
- 4
- 5
调取模型预测
from transformers import pipeline
classifier = pipeline("text-classification",model="./bert0207")
classifier(inp)
#[{'label': '教育', 'score': 0.9345001578330994}]
- 1
- 2
- 3
- 4
- 5
- 6

