
热门标签
当前位置: article > 正文
图的广度优先搜索和深度优先搜索_图 广度优先 深度优先
作者:繁依Fanyi0 | 2024-04-16 13:30:55
赞
踩
图 广度优先 深度优先
目录
一、图的基本操作
//备注为图在邻接矩阵法和邻接表法下的时间复杂度,问题规模V为顶点数,E为边数。
邻接矩阵法的顶点表为一维数组,边表为二维数组存储。
邻接表法的顶点表为一维数组,边表为V个链表。
- Adjacent(G,x,y) 判断图G是否存在边(x,y)或<x,y>。//邻接矩阵法为O(1),邻接表法为O(E)
- Neighbors(G,x) 列出图G中与顶点x邻接的边。//邻接矩阵法为O(V),邻接表法为O(E)
- InsertVex( &G, x ) 在图G中增添新顶点x。//邻接矩阵法为O(V),邻接表法为O(1)
- DeleteVex( &G, x ) 在图G中删除顶点x及其相关的弧。//邻接矩阵法为O(
) ,邻接表法需遍历整个邻接表找相关弧故为O(E)。
- AddEdge( &G, x, y ) 若无向边(x,y)或有向边<x,y>不存在,则向图中添加该边。//邻接矩阵法为O(1),邻接表法即同单链表头插为O(1)。
- RemoveEdge( &G, x, y ) 若无向边(x,y)或有向边<x,y>存在,则在图中删除该边。//邻接矩阵法为O(1),邻接表法为O(E)。
- Get_edge_value(G,x,y) 获取图G无向边(x,y)或有向边<x,y>对应的权值。 //等同判断该边是否存在。
- Set_edge_value(G,x,y,v) 设置图G无向边(x,y)或有向边<x,y>的权值为v。//等同判断该边是否存在。
- //对于有向图G=(V,E),如果有弧<v,v’>,则称顶点V邻接到顶点V’,或顶点V’邻接自顶点V
- FirstNeighbor( G, x) 返回顶点x的第一个邻接顶点的顶点号。若顶点在G中没有邻接顶点,则返回-1。//邻接矩阵法为O(V),邻接表法为O(1)
- NextNeighbor( G, x, y ) 假设顶点y是顶点x的一个邻接顶点,返回除y外顶点x的下一个邻接点的顶点号,若y是x的最后一个邻接顶点,则返回-1。//邻接矩阵法为O(V),邻接表法为O(1)
二、图的遍历
图的遍历是指从图中某一个顶点出发,按某种搜索方法沿着图中的边对图中的所有顶点都访问一次且仅访问一次。
图的任一顶点都可能会和其余的顶点相邻接,所以在访问某个顶点后,可能沿着某条路径搜索又回到该顶点上。为避免同一顶点被访问多次,在遍历图的过程中,我们必须记下每个已经访问过的顶点,为此可以设置一个辅助数组visited[]来标记顶点是否被访问过。
图的遍历算法主要有两种:广度优先搜索和深度优先搜索。
①广度优先搜索
(Breadth-First-Search,BFS)类似于树的层序遍历算法。
基本思想
- 首先访问起始顶点v;
- 然后依次访问v的未访问过的邻接顶点
、
,...,
;
- 然后依次访问
- 再从依次从这些访问过的邻接顶点出发,访问它们的所有未被访问过的邻接顶点;
- 依次类推,直到与V连通的所有顶点都被访问过为止。
- 若此时图中尚有顶点未被访问,则选另图中一个未曾被访问过的顶点作为起始顶点,重复上述过程,直到图中所有顶点都被访问过为止。
BFS实现方法
- 找一个顶点的所有未访问过的邻接顶点我们用到这两个接口函数FirstNeighbor( G, x)、NextNeighbor( G, x, y )
- 我们访问完
- bool型辅助数组visited[MAX_VERTEX_NUM]的下标用来代表每个顶点的编号,并存放它们是否被访问过的信息。
BFS算法代码

BFS算法分析
- 无论是邻接表法还是邻接矩阵的存储方式,我们都需要一个辅助队列Q,空间复杂度为O(|V|)
- 采用邻接表存储方式时,每个顶点都入队一次时间复杂度为O(|V|),每条边都至少被访问一次(出边表遍历)时间复杂度为O(|E|)。故总的时间复杂度为O(|V|+|E|)。采用邻接矩阵存储方式时,查找每个顶点的邻接点所需的时间为O(|V|),故算法总的时间复杂度为O(|
BFS算法应用
- 我们可以使用BFS算法求解无权图的单源最短路径问题。这是由BFS算法总是按照距离由近及远来遍历图中的每个顶点的性质决定的。
②深度优先搜索
(Depth-First-Search,DFS)类似于树的先序遍历算法。
基本思想
- 首先访问起始顶点v;
- 然后访问v的未访问过的邻接顶点
- 然后访问
- 重复上述过程,当不能再向下访问时,依次退回到最近被访问的顶点,若它还有邻接顶点未被访问过,则从该点开始继续2~4的的过程。直到所有与起始顶点连通的顶点都被访问过为止。
- 若此时图中尚有顶点未被访问,则另选图中一个未曾被访问过的顶点作为起始顶点,重复上述1~4过程,直到图中所有顶点都被访问过为止。
DFS实现方法
- 找一个顶点的所有未访问过的邻接顶点我们用到这两个接口函数FirstNeighbor( G, x)、NextNeighbor( G, x, y )
- 我们看到第3步对
- bool型辅助数组visited[MAX_VERTEX_NUM]的下标用来代表每个顶点的编号,并存放它们是否被访问过的信息。
DFS算法代码
DFS算法分析
- 深度优先搜索遍历算法是一个递归算法,需要借助一个递归工作栈,故空间复杂度为O(|V|)
- 采用邻接表存储方式时,每个顶点都标记过,故时间复杂度为O(|V|),每条边都至少被访问一次(出边表遍历)时间复杂度为O(|E|),故时间复杂度为O(|V|+|E|)。采用邻接矩阵存储方式时,查找每个顶点的邻接点所需的时间为O(|V|),故算法总的时间复杂度为O(|
DFS算法应用
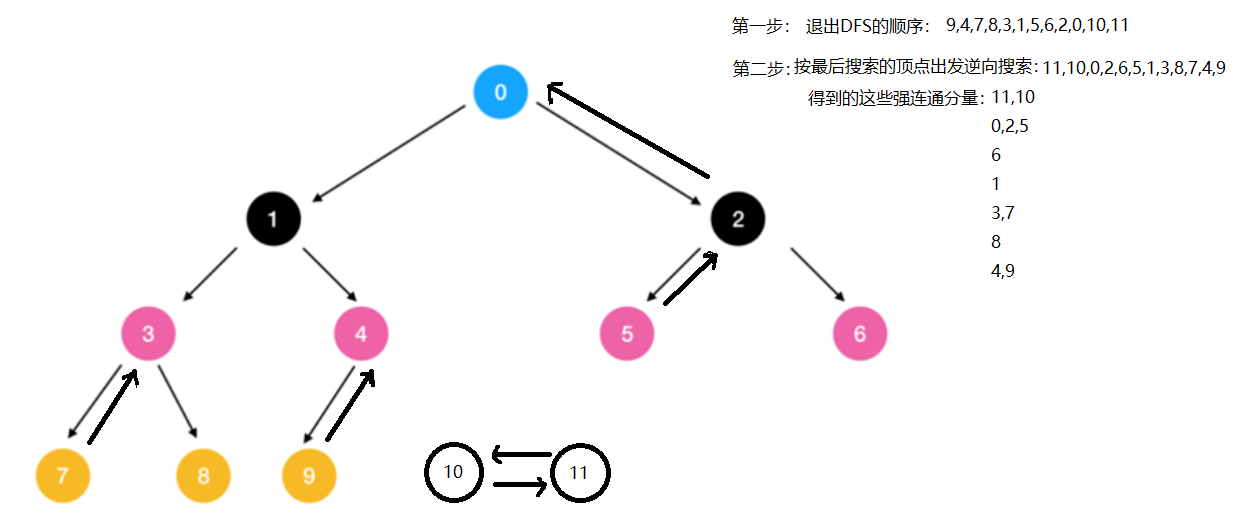
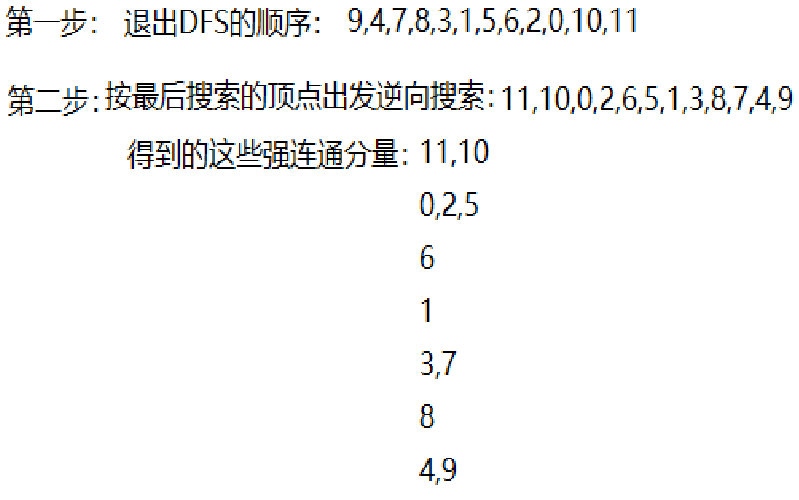
深度优先搜索是求有向图的强连通分量的一个有效方法。假设以十字链表作为有向图的存储结构(方便我们一会逆向搜索,即从找出边变为找入边了),求强连通分量的步骤如下:
- 在有向图G上,从某个顶点出发沿着以该顶点为尾的弧进行深度优先搜索遍历,并按其所有邻接点的搜索都完成(即退出DFS函数)的顺序将顶点排列起来。
- 在有向图G上,从最后完成搜索的顶点出发,沿着以该顶点为头的弧进行逆向的深度优先搜索遍历。若此次遍历不能访问到有向图中所有顶点,则从余下的顶点中最后完成搜索的顶点出发,继续做逆向的深度优先搜索遍历,直到有向图中的顶点都被访问到为止。
- 由此,第二步每一次调用DFS作逆向深度优先遍历所访问到的顶点集便是有向图G中一个强连通分量的顶点集。
三、遍历得到的生成树、生成森林相关问题
回顾:
- 任意两个顶点都连通的无向图为连通图,任意两个顶点都强连通的有向图为强连通图。
- 连通分量是无向图中的极大连通子图,强连通分量是有向图中的极大强连通子图。
- 生成子图是包含全部顶点的子图,连通图的生成树是包含全部顶点的极小连通子图,非连通无向图的连通分量的生成树构成了非连通无向图的生成森林。
- 只有一个顶点的入度为0,其余顶点的入度均为1的有向图,称为有向树。
- 一个有向图的生成森林由若干有向树组成,含有图中的全部顶点,但只有足以构成若干棵不相交的有向树的弧。
广度优先搜索(BFS)
- 无向图:
- 连通图经过广度优先搜索后得到的遍历树为广度优先生成树。
- 非连通无向图经过广度优先搜索后得到的遍历树集合为广度优先生成森林。
- 有向图:
- 强连通图经过广度优先搜索后得到的遍历树为广度优先生成树。
- 非强连通有向图经过广度优先搜索后得到的遍历树集合为广度优先生成森林。
王道教材上给的解释是只说了连通图,也就是无向图的生成森林问题。但举的例子又是一个有向图,很明显是牛头不对马嘴。具体怎么样不用管了,先按这样理解。
- 图按邻接矩阵存储时表示是唯一的,故其广度优先生成树、森林也是唯一的。按邻接表法存储时是不唯一的,故其广度优先生成树、森林也是不唯一的。
深度优先搜索 (DFS)
- 无向图:
- 连通图经过深度优先搜索后得到的遍历树为深度优先生成树。
- 非连通无向图经过深度优先搜索后得到的遍历树集合为深度优先生成森林。
- 有向图:
- 强连通图经过深度优先搜索后得到的遍历树为深度优先生成树。
- 非强连通有向图经过深度优先搜索后得到的遍历树集合为深度优先生成森林。
- 图按邻接矩阵存储时表示是唯一的,故其深度优先生成树、森林也是唯一的。按邻接表法存储时是不唯一的,故其深度优先生成树、森林也是不唯一的。
BFS与DFS综合对比
- 对于无向图的广度优先生成树,起点到其他顶点的路径是图中对应的最短路径,即所有生成树中树高最小。此外,深度优先总是尽可能“深”地搜索图,因此路径可能会更长,故深度优先生成树的树高总是大于或等于广度优先生成树的树高。
- 对于无向图而言,void BFSTraverse(Graph G)调用遍历函数(BFS或DFS)的次数为无向图的连通分量的个数。
- 对于有向图而言,如果调用一次遍历函数(BFS或DFS)可以遍历到所有结点,不能说明该有向图强连通。调用遍历函数(BFS或DFS)的次数与有向图的强连通分量的个数无关,具体求强连通分量的算法见上述DFS算法的应用。
正文结束。
DFS算法求强连通分量好像也可以这么做,不知道对不对。
可以看到也可以求出强连通分量 。

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/434449
推荐阅读
相关标签

