
- 1数据结构--顺序表的c语言实现(超详细注释/实验报告)_数据结构顺序表的定义和实现实验报告
- 2LeetCode1题:两数之和(python3)
- 3神经网络基础-线性模型_线性神经网络模型
- 4计算机网络——TCP/IP协议_根据现在计算机的操作系统进行设置tcp/ip协议,确定现在使用的是 操作系统
- 5【chrome】iframe与Permissions_permissions policy violation: fullscreen is not al
- 6关键词提取_关键词提取数据集
- 7git修改之前的commit提交的作者信息和邮箱信息_git 修改 作者信息
- 8当vue项目运行时,控制台出现“WebSocketClient.js:13 WebSocket connection to ‘ws://10.10.244.95:8080/ws‘ failed: E”_websocketclient.js:13 websocket connection to 'ws:
- 9python学习一点 快乐一点(6)考勤信息_用python3写出程序,并详细解释 公司用一个字符串来表示员工的出勤信息 absent:缺
- 10对单片机的一点理解
集合框架,超详细解析源码_集合框代码
赞
踩
本文图片出处均来自 B站-----韩顺平 老师视频
集合

1.理解集合的好处
数组的确定主要是灵活性不够

集合吸收了数组的优点,去除了数组的缺点

2.集合的框架体系
JAVA的集合类优很多,主要分为两大类(单列集合与双列集合)
Conllection接口主要有两个重要的子接口Lis Set他们的实现子类都是单列集合Map接口的主要实现的子类是双列集合 ,存放的值为 K-V
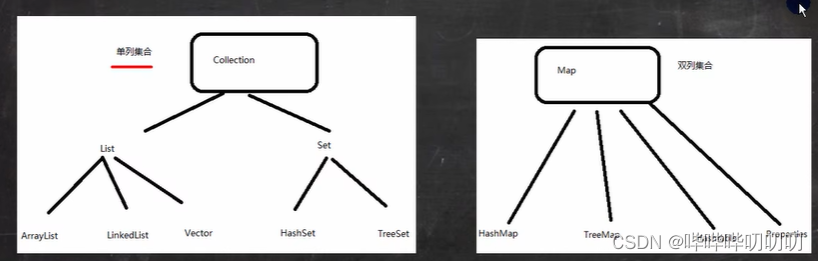
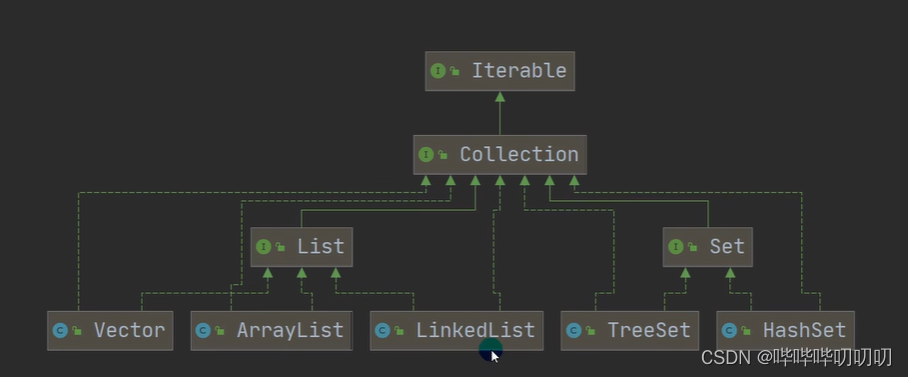
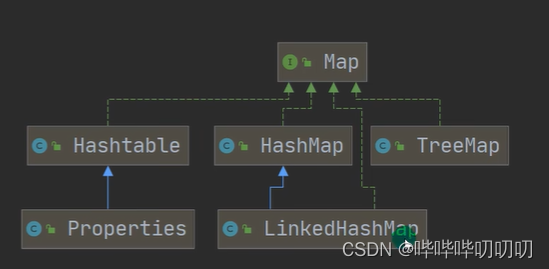
单列双列集合区别
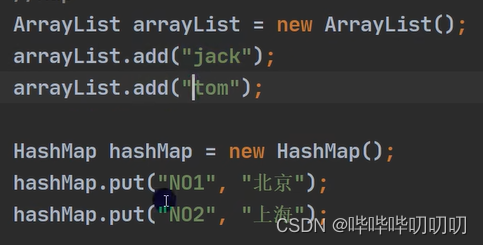
3.Collection接口和常用方法


List list = new ArrayList(); //添加单个元素add list.add("jeck"); //因为add()方法参数是一个Object对象,也就是必须是类,当给入一个继承类型值的时候,add()会自动装箱 list.add(15);//new Integer(10) list.add(true);//new Boolean(true) System.out.println(list);//[jeck, 15, true] //remove boolean bool = list.remove("jeck"); Object i = list.remove(0); System.out.println(list+""+bool+i);//[true]true15 //contanis 查找元素是否存在 System.out.println(list.contains(true));//true //size 返回元素的个数 System.out.println(list.size());//1 //addAll 添加多个元素 List list1 = new ArrayList(); list1.add("xia"); list1.add("dong"); list.addAll(list1); System.out.println(list);//[true, xia, dong] list.addAll(2,list1); System.out.println(list);//[true, xia, xia, dong, dong] //constainsAll 查询多个元素是否存在 boolean b = list.containsAll(list1); System.out.println(b);//true //removeAll 删除多个元素 list.removeAll(list1); System.out.println(list);//[true]

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
4.迭代器(iterator)遍历
collection继承自iterable,所有可以实例化的子类必须要实现的一个方法,它返回的就是iterator类
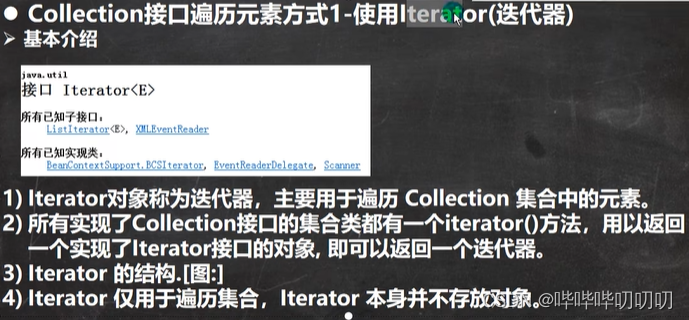
迭代器执行原理


迭代器案例

5.List接口和常用方法
5.1.List接口方法

5.2.List的三种遍历方式

5.3.List注意事项

5.4.ArrayList与LinkedList源码分析
ArrayList本质上就是一个可扩容数组,LinkedList本质上就是一个双向链表.两者对外的接口都是List接口,所以其拥有的功能几乎相同,但是内部实现完全是两套体系,

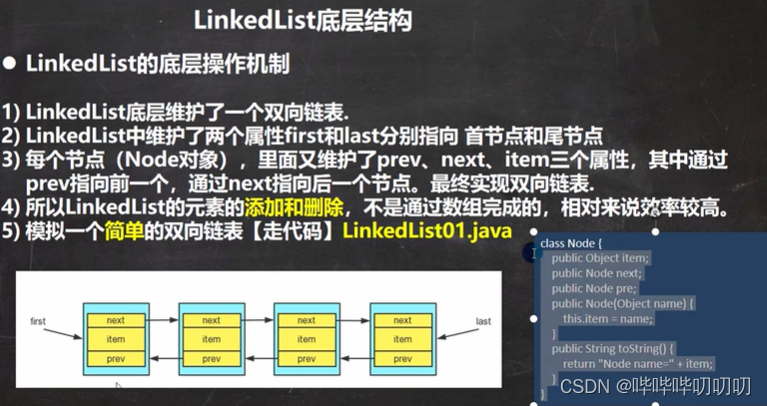
5.4.1.ArrayList的知识
ArrayList通过数组实现一个List,其本质上是对一个数组的简单封装,所以最后表现出来的特点是一个可扩容数组。- 在大多数情况下,我们只需要直到
ArrayList底层是一个可扩容数组就可以了,但是在面试中ArrayList这一内容被问的五花八门,这里统一进行一次解析。
ArrayList继承了AbstractList,这意味着ArrayList并不需要实现List接口中的每一个内容,而只是从中选出一部分方法进行实现。
ArrayList总结
ArrayList内部封装了一个数组引用,使得其可以伪装为数组动态扩容,但是实际上数组的容量在申请后就不可以增加或者缩小了,其中动态扩容是著名的考题。比如:数组怎样实现扩容?
封装数组扩容,
ArrayList一般扩容为原本的多少倍?1.5倍扩容,
为什么建议给ArrayList一个初始容量?
(扩容本质上就是申请内存,比较吃时间,给定容量可以大幅减少扩容次数,从而优化时间。)
ArrayList与Vector的区别在哪里?
ArrayList和Vector都是基于数组的线性表,很多代码都是重复的,但是Vector是一个线程安全的线性表,其内部存在大量的“synchronized”锁,并且Vector扩容方式为2倍扩容,而ArrayList线程不安全,1.5倍扩容,我们一般情况下不推荐使用Vector
ArrayList默认容量在添加第一个元素之前,默认容量为0,节省空间,在添加第一个元素是,其默认容量为10.
ArrayList和LinkedList的区别?
ArrayList和LinkedList的区别本质上就是数组与链表的区别,数组能够随机读取,但是增加或三处速度较慢,而且扩容比较吃时间,链表则与其相反。
LinkedList的本质?含有指向头尾节点的双向链表(非循环).
ArrayList 和int[]的区别?
ArrayList只能容纳对象,无法容纳基本类型,所以在加入时比较耗费时间,因为要进行自动装箱。我们在时间不敏感时,或者比较小型的集合时,推荐使用ArrayList,此时程序员的效率重要性大于执行效率
6.Set接口
6.1.Set接口与常用方法
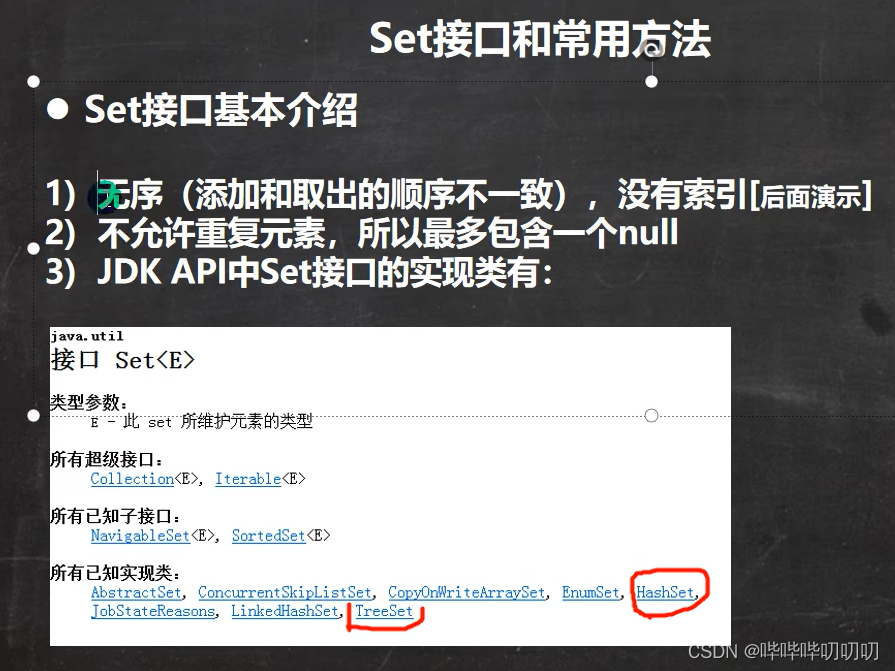
6.2.Set接口测试
6.2.1.Set的数据存储
//以Set实现类HashSet为例,体会Set接口的方法
Set set = new HashSet();
set.add("qq");
set.add("ww");
set.add("qq");//重复的数据
set.add("rr");
set.add(null);
set.add(null);//一共两个null
System.out.println(set);//[qq, ww, rr, null]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
通过输出结果来看:
Set接口的实现类的对象,不能存放重复的元素,- 可以添加NULL,但是只能存在一个
- 存放数据是无序的(即添加的顺序与取出的顺序不一致)
- 虽然添加的顺序与取出的顺序不一致,但是取出的顺序是一致的
HashSet的底层,是一个数组加链表的形式来管理的
6.2.2.Set的遍历
由于Set接口不能使用索引,所以不存在普通for循环
//方式一 : 迭代器
Iterator iterator = set.iterator();
while (iterator.hasNext()) {
Object next = iterator.next();
System.out.print( next );
}
//方式二 : 增强for循环(底层实质上就是迭代器)
for (Object obj: set) {
System.out.print(obj);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
6.3.Set接口实现类HashSet
6.3.1.HashSet基础
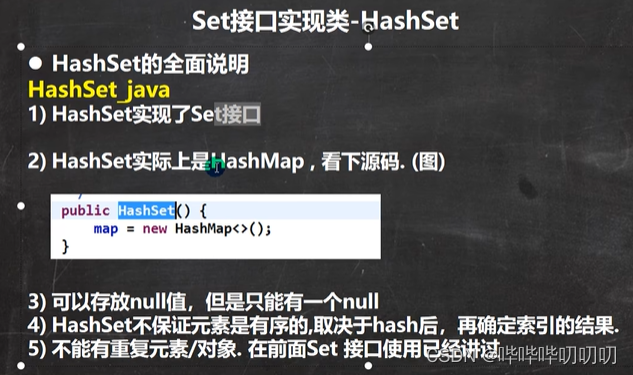
HashSet构造器源码(底层就是一个HashMap,HashMap底层是数组+链表+红黑树)
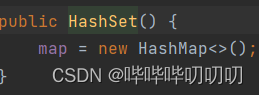
案例说明
在执行
add()方法后,会返回一个bool值,告知内容是否添加成功第二个案例中两个
Dog()都会添加成功下面针对字符串的情况下,会添加失败,为什么???得追寻源码来分析(要去看看源码了,看
add()到底发生了什么)set.add(new String("zw")); set.add(new String("zw"));//添加失败
- 1
- 2
6.3.2.HashSet结构模拟
public class HashSetStructure { public static void main(String[] args) { //模拟一个HashSet的底层(HashMap)结构 //创建一个数组,数组的类型为Node //Node[] 也可以直接被称为 表 Node[] table = new Node[16]; //在索引为2的位置,添加一串节点 Node node1 = new Node("qq", null); Node node2 = new Node("ww", null); Node node3 = new Node("ee", null); table[2] = node1; node1.next = node2; node2.next = node3; } } //节点,储存数据,可以指向下一个节点,形成链表 class Node{ Object item; Node next; public Node(Object item, Node next) { this.item = item; this.next = next; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
6.3.3.HashSet源码解析

DEFAULT_INITIAL_CAPACITYTable数组的初始化长度: 1 << 4 2^4=16(为什么要是 2的n次方?)MAXIMUM_CAPACITY Table数组的最大长度: 1<<30 2^30=1073741824DEFAULT_LOAD_FACTOR负载因子:默认值为0.75。 当元素的总个数>当前数组的长度 * 负载因子。数组会进行扩容,扩容为原来的两倍(为什么是两倍?)TREEIFY_THRESHOLD链表树化阙值: 默认值为 8 。表示在一个node(Table)节点下的值的个数大于8时候,会将链表转换成为红黑树。UNTREEIFY_THRESHOLD红黑树链化阙值: 默认值为 6 。 表示在进行扩容期间,单个Node节点下的红黑树节点的个数小于6时候,会将红黑树转化成为链表。MIN_TREEIFY_CAPACITY = 64最小树化阈值,当Table所有元素超过改值,才会进行树化(为了防止前期阶段频繁扩容和树化过程冲突)。
public static void main(String[] args) {
HashSet hashSet = new HashSet();
hashSet.add("qq");
hashSet.add("ww");
hashSet.add("ee");
hashSet.add("rr");
System.out.println(hashSet);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
构造器源码
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HtYIm8Bw-1679557242477)(C:\javaProgram\workdata\笔记\picture\collections\HashSet源码_01.png)]
"qq"作为一个实参传入入第一个add()----e
map作为HashSet的一个HashMap类型的属性
put()方法第二个参数PRESENT是HashSet的一个静态常量Obejec类型,作用是占位 (因为底层为HashMap,HashMap为键值对,所以value值需要占位)(让HashSet使用到HashMap,value统一放的都是Object),将来不管map.put执行多少次,key是变化的,但是value始终都是PRESENT
put()方法中使用的hash(key)用来计算表中的地址,在执行hash(key)方法后,得到一个对应的哈希值(这个哈希值是HashCode经计算后得出的值)



执行
putVal()!!!!!
n = (tab = resize()).length;进入到resize()方法中resize()过后,table具有16个空间大小
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) { //定义为辅助变量 Node<K,V>[] tab; Node<K,V> p; int n, i; //这里的table是作为HashMap的一个属性,类型为Node[]节点数组 //第一次进来,并没有对属性做操作,所以现在table为空并且长度为0 //if语句对table进行第一次扩容,大小为16 if ((tab = table) == null || (n = tab.length) == 0) //这里辅助变量n的作用也告诉了,记录table的长度 //此时table具有16个空间大小,常量值计算为1<4 n = (tab = resize()).length; //1,得到的hash值,来计算key应该存放到table表的那个索引位置,这个位置的对象,赋给p //2,断p是否为null //这里辅助变量 i 也告诉了其作用,由来存储hash计算得出的数组索引 if ((p = tab[i = (n - 1) & hash]) == null) //2.1,如果p为空,说明该位置目前并没有存放数据,就创建一个Node(key="qq",value=PRESENT),放在table[i]位置 //这一步如果进来了,完成后直接跳到++modCount; //专门为某个位置第一次存储数据做的操作 tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } //保证线程安全的操作数 ++modCount; //threshold就是临界值,在resize()方法中定义的,临界系数0.75,超过临界值就要扩容 //这里的扩容机制需要了解一下 // 并不是长度为16的数组沾满了12个内存时扩容 // 而是所有的节点加起来为12时选择扩容(最多其实有16*8个节点) if (++size > threshold) resize(); //这个方法是HashMap留给子类,例如LinkedHashMap,对于本类,此方法是一个空方法, afterNodeInsertion(evict); return null; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
自此,第一个
add()方法执行完毕,接下来是第二个add()
- 与第一个
add()一样,先执行put(k,v)方法,再执行putVal(hash_K,k,v)- 第二次就不会执行第一个
if()语句- 在第二个
if()语句中,计算出数组索引位置后,发现当前位置也是空,于是进行第一次一样的过程
自此,第二个
add()方法也执行完毕,第三个add()方法比较特殊,我们丢了一个重复的数据进去,看看底层源码是如何运行的。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); //进入else的前提条件:table表不为空,存储位置不为空 // else { //辅助变量 Node<K,V> e; K k; //p :要存放数据的节点开始位置 //先判断hash值相不相等,再判断两个key是不是同一个对象,或者内容相同 //是---则e = p 不是----则进入下一个else if判断 if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; //判断 p 是不是红黑数,如果是,则调用putTreeVal来进行添加(方法内部会对key进行判断) else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { //依次和链表中的每一个元素比较后都不相同,则加入到最后 //for循环里面的p代表当前遍历到的节点 for (int binCount = 0; ; ++binCount) { //如果当前节点后续没有节点了,则直接把新数据挂到最后新加的节点上 //讲数据接上后,break if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); //判断是否要树化链表 //两个条件----链表长度等于8 // ----数组长度等于64 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } //先判断hash值相不相等,再判断两个key是不是同一个对象,或者内容相同 //有相同数据时,直接结束 if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; //让p指向下一个节点,开启新的循环 p = e; } } //如果e!=null进入到if语句内,函数返回oldValue,则添加失败 if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } //保证线程安全的操作数 ++modCount; //threshold就是临界值,在resize()方法中定义的,临界系数0.75,超过临界值就要扩容 if (++size > threshold) resize(); //这个方法是HashMap留给子类,例如LinkedHashMap,对于本类,此方法是一个空方法, afterNodeInsertion(evict); return null; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
???两个new出来的String对象内容相同,地址不一样,如何不能一起放入hash表中呢,就算是匹配机制,两个地址不同的对象,如何放入同一个链表中比较呢?
6.4.LinkedHashSet(继承于Set)

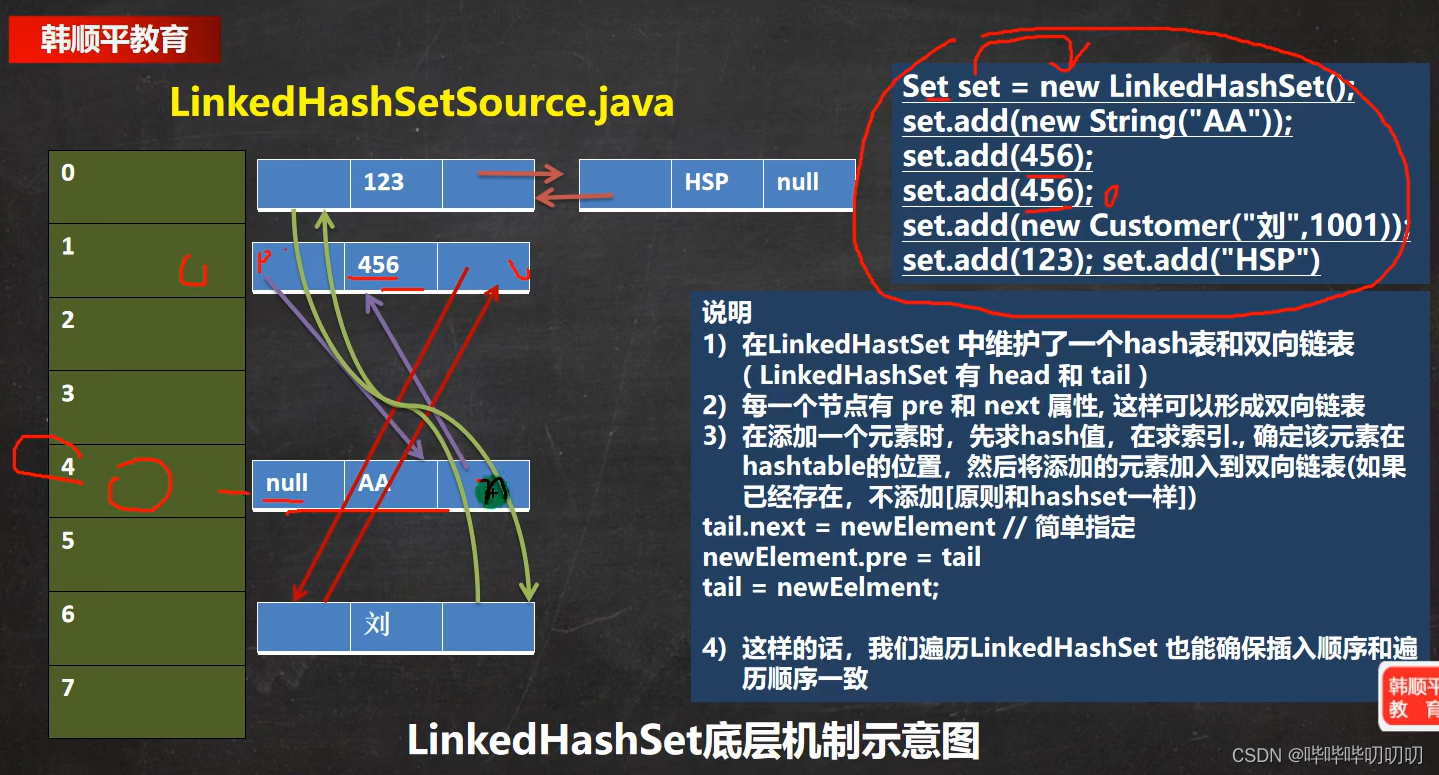
LinkedHashSet与HashSet第一个区别就是前者输入顺序与输出顺序一致,而后者不一致两者都不允许出现重复值
LinkedHashSet底层维护的是一个LinkedHashMap(是HashMap的子类)第一次添加数据,
table数组扩容到16,存放的节点类型是LinkedHashMap$Entry数组类型是
HashMap$Node[],存放的数据是LinkedHashMap$Entry类型其中的继承关系在内部类中发生
Entry存在三个指针----自己两个after,before父类一个next
6.5.TreeSet(继承自Set)
TreeSet以调用空参的形式添加数据的情况下,是无法对输出进行排序的TreeSet treeSet = new TreeSet(); treeSet.add("zw"); treeSet.add("wl"); treeSet.add("hy"); treeSet.add("sq");
- 1
- 2
- 3
- 4
- 5
TreeSet以TreeSet(Comparator<? super E> comparator)构造器来创建的时候,可以完成对字符串的顺序输出(按照字母排序)如果想跟换排序规则,只需要改变匿名内部类的方式(比如希望按照长度排序,只需要将方法体改为
((String) o2).length - ((String) o1).length即可但是!!!系统会将长度相等的数据当作同一个数据//TreeSet treeSet = new TreeSet(); TreeSet treeSet = new TreeSet((o1, o2) -> ((String) o2).compareTo((String) o1)); treeSet.add("zw"); treeSet.add("wl"); treeSet.add("hy"); treeSet.add("sq");
- 1
- 2
- 3
- 4
- 5
- 6
源码追击----
TreeSet(Comparator<? super E> comparator)构造器来创建的情况下
首先了解一下
Comparator是一个函数式接口我们在重写接口时,调用
String的compareTo方法对接口方法进行重写
compareTo返回参与比较的前后两个字符串的asc码的差值,如果两个字符串首字母不同,则该方法返回首字母的asc码的差值即参与比较的两个字符串如果首字符相同,则比较下一个字符,直到有不同的为止,返回该不同的字符的
asc码差值由于
TreeSet是一个树结构,在添加数据时会与前一个节点比较,按compareTo返回值正负来区分放入左节点还是右节点开始----构造器初始化属性
//用来占位 private static final Object PRESENT = new Object();
- 1
- 2
//构造器调用本地构造器,参数为一个TreeMap对象(带上comparator) public TreeSet(Comparator<? super E> comparator) { this(new TreeMap<>(comparator)); }
- 1
- 2
- 3
- 4
//通过TreeMap构造器将comparator赋值给TreeMap属性 //TreeSet的底层还是使用的TreeMap,也就是说TreeSet对象有TreeMap对象属性 public TreeMap(Comparator<? super K> comparator) { this.comparator = comparator; }
- 1
- 2
- 3
- 4
- 5
添加数据
//TreeSet的add方法实际上就是TreeMap的put方法 public boolean add(E e) { return m.put(e, PRESENT)==null; }
- 1
- 2
- 3
- 4
//put方法中存在这样的代码 //其中cpr代表传入的匿名内部类 //在这里我们调用cpr的compare(也就是我们重写的方法)方法对前一个值与当前值进行比较,返回一个正负数 //通过分辨cmp的正来决定将结点接在那 //如果相等,数据加入失败 if (cpr != null) { do { parent = t; cmp = cpr.compare(key, t.key); if (cmp < 0) t = t.left; else if (cmp > 0) t = t.right; else { V oldValue = t.value; if (replaceOld || oldValue == null) { t.value = value; } return oldValue; } } while (t != null);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
7.Map接口
7.1.Map接口与常用方法

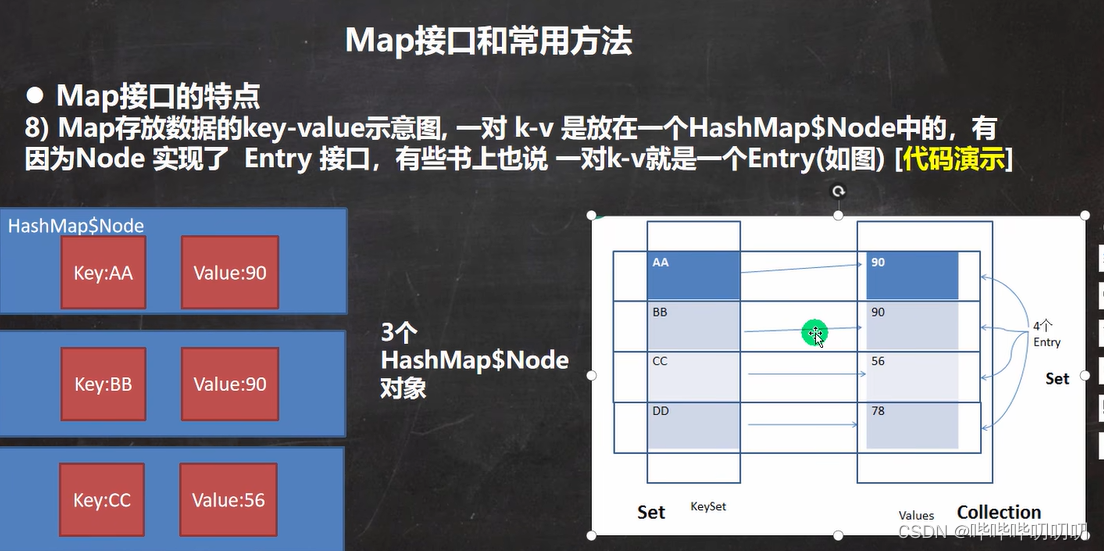
Mpa将K-V数据以HashMap$Node数据类型存放到内存中- 同时为了方便遍历,系统还会创建存放类型为
Entry的EntrySet集合- 在
EntrySet中,定义的类型是Map.Entry,但是存放的数据任然是HashMap$Node,多态产生,后者实现了前者- 值得注意的是,
EntrySet中存放的只是HashMap$Node类型的地址值,其地址指向HashMap$Node内存。
Node<K,V> newNode(int hash, K key, V value, Node<K,V> next) {
return new Node<>(hash, key, value, next);
}
- 1
- 2
- 3

7.2.Map接口遍历方式
第一组----先取出
key,通过key取出value
for增强
HashMap的keySet()方法返回的是一个Set接口类型的集合- 这里作为一个多态表现,真正返回的类型是实现了
Set接口的子类HashMap$KeySet- 其中
HashMap$KeySet继承抽象类AbstractSet,抽象类AbstractSet又实现了Set接口keySet()方法将集合中的Key以String类型的方式放入Set(HashMap$KeySet)集合Set set = map.keySet(); System.out.println(set.getClass()); for (Object obj: set) { System.out.println(map.get(obj)); }
- 1
- 2
- 3
- 4
- 5
IteratorIterator iterator = set.iterator(); while(iterator.hasNext()){ Object next = iterator.next(); //System.out.println(next.getClass()); System.out.println(map.get(next)); }
- 1
- 2
- 3
- 4
- 5
- 6
第二组----把所有的
Value取出,并不关心Key
for增强
HashMap的values()方法返回的是一个Collection接口类型的集合这里作为一个多态表现,真正返回的类型是实现了
Collection接口的子类HashMap$Values其中
HashMap$Values继承抽象类AbstractCollection,抽象类AbstractCollection又实现了Collection接口
values()方法将集合中的Value以String类型的方式放入Collection(HashMap$Values)集合Collection values = map.values(); for (Object value : values) { System.out.println(value); }
- 1
- 2
- 3
- 4
IteratorIterator iterator1 = values.iterator(); while(iterator1.hasNext()){ System.out.println(iterator1.next()); }
- 1
- 2
- 3
- 4
第三组----通过
EntrySet来获取key-value值
for增强
HashMap的entrySet()方法返回的是一个Set接口类型的集合- 这里作为一个多态表现,真正返回的类型是实现了
Set接口的子类HashMap$EntrySet- 其中
HashMap$EntrySet继承抽象类AbstractSet<Map.Entry<K,V>>,
- 这里规定了一个泛型
<Map.Entry<K,V>>接口,说明HashMap$EntrySet内部存放的都是<Map.Entry<K,V>>接口的实现子类- 通过
getClass()方法可以知道,HashMap$EntrySet内部存放的是HashMap$Node类对象- 值得注意的是,因为
HashMap$Node类是内部类,所以在外部无法调用,但是可以通过它的实现接口Map.Entry来访问它实现的方法entrySet()方法将集合中的Value与Key以HashMap$Node类型的方式放入Set(HashMap$EntrySet)集合Set entrySet = map.entrySet(); for (Object o : entrySet) { Map.Entry entry = (Map.Entry) o; System.out.println(entry.getKey()+""+entry.getValue()); }
- 1
- 2
- 3
- 4
- 5
IteratorIterator iterator2 = entrySet.iterator(); while (iterator2.hasNext()) { Object next = iterator2.next(); Map.Entry entry = (Map.Entry) next; System.out.println((entry.getKey()+" "+entry.getValue())); }
- 1
- 2
- 3
- 4
- 5
- 6
第四组----
lambda表达式
通过
Map的froEach(),结合lambda表达式来完成
forEach()的参数要求是BiConsumer类型,BiConsumer是一个接口,还是一个函数式接口匿名内部类的三种方式练习
以对象的方式
new BiConsumer() { @Override public void accept(Object o, Object o2) { System.out.println("以对象的方式"); } }.accept(new Object(),new Object());
- 1
- 2
- 3
- 4
- 5
- 6
以多态的方式
以正常多态的方式
BiConsumer b1 = new BiConsumer() { @Override public void accept(Object o, Object o2) { System.out.println("以正常多态的方式"); } };
- 1
- 2
- 3
- 4
- 5
- 6
以参数多态的方式
map.forEach(new BiConsumer() { @Override public void accept(Object o, Object o2) { System.out.println("以参数多态的方式"); } });
- 1
- 2
- 3
- 4
- 5
- 6
以
lambda方式
- 这里需要注意一下,
forEach(BiConsumer)这个方法是属于HashMap从Map中继承而来的,里面内容已经写好了,就是遍历本类的table表,再每一次得到遍历结果后,都需要调用BiConsumer接口的方法来处理,所以在这里需要重写一下BiConsumer接口的方法,以参数的形式传入forEach()map.forEach((k,v)->{ System.out.println(k+" "+v); });
- 1
- 2
- 3
如果大家都表现的好
这个奖惩计划有一个砍,肯定是低过多少分的才要进行惩罚。
7.3.遍历练习

HashMap map = new HashMap(); Employee e1 = new Employee("zw", 20000, "001"); Employee e2 = new Employee("lly", 18000, "002"); Employee e3 = new Employee("hy", 15000, "003"); map.put(e1.getId(),e1); map.put(e2.getId(),e2); map.put(e3.getId(),e3); //第一种 // Set set = map.keySet(); // for (Object key : set) { // System.out.println(key); // if (((Employee) map.get(key)).getSal()>18000) System.out.println(map.get(key)); // } //第二种 // Collection values = map.values(); // Iterator iterator = values.iterator(); // while(iterator.hasNext()){ // Employee next = (Employee) iterator.next(); // if (next.getSal()>18000) // System.out.println(next); // } //第三种 // Set set = map.entrySet(); // for (Object o : set) { // Map.Entry entry = (Map.Entry) o; // Employee employee = (Employee) entry.getValue(); // if (employee.getSal()>18000) System.out.println(employee); // } //第四种 map.forEach((k,y)->{ Employee employee = (Employee) y; if (employee.getSal()>18000) System.out.println(employee); });
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
7.4.HashMap(继承自Map)
7.4.1.HashMap底层机制


7.4.2.HashMap源码解析

put()方法进去,进入到putVal()方法(带值----根据key计算出的hash,key,value)其源码分析与
HashSet相同
7.4.3.HashMap的扩容与树化
- 什么时候调用扩容?
- 当节点数量达到8时,会调用树化方法,数化方法中如果判断表的长度未达到64,则只进行扩容处理
- 每添加一个数据,变量
size就会加1,当数量达到临界值(0.75临界系数)时,就会扩容
- 扩容一次扩多少?
- 一次扩容2倍
7.5.HashTable(继承自Map)
extends Dictionary<K,V> implements Map<K,V>, Cloneable, java.io.Serializable
- 1
- 2
- 基本与
HashMap一样- 不同点在于它的线程是安全的
- 以及内部维护的是一个
HashTable$Entry类型的数组,同样也是继承自AbstractSet抽象类,抽象类又实现了Set接口- 初始化大小11
threshold(临界值)大小为8,loadFactor(加载因子)为0.75- 扩容为两倍+1

HashTable的遍历方式与前者一样
// Set set = hashtable.entrySet(); // System.out.println(set.getClass()); // for (Object o : set) { // Map.Entry entry = (Map.Entry) o; // System.out.println(entry.getKey()+" "+entry.getValue()); // } // Set set = hashtable.keySet(); // for (Object o : set) { // System.out.println(hashtable.get(o)); // } // Collection values = hashtable.values(); // for (Object value : values) { // System.out.println(value); // } hashtable.forEach((k,y)->{ System.out.println(k +" "+ y); });
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
7.6.properties(继承自HashTable)

重点在于本类主要读取配置文件(键值对形式----链接数据库的配置文件)
- 作为
HashTable子类也不能添加空值

7.7.TreeMap(继承自Map)
7.7.1.底层结构对比
先来看一下与
HashMap、LinkedHashMap的对比,同时就当是复习一下:
HashMap使用数组存储数据,并使用单向链表结构存储hash冲突数据,同一个冲突桶中数据量大的时候(默认超过8,并且table表长度超过或者等于64)则使用红黑树存储冲突数据。LinkedHashMap使用数组+双向链表存储数据,冲突数据存储方式同HashMap。TreeMap使用红黑树存储数据,注意是直接使用红黑树,不使用table数组。
7.7.2.TreeMap底层支持两种排序方式
TreeMap对象实例化时传入comparator对象。- key值对象实现
Comparable接口。
- 比如
TreeMap<String,Object>,由于String实现了Comparable接口,所以是没有问题的。- 但是如果自定义的对象,没有实现
Comparable接口,同时在TreeMap实例化的时候没有设置comparator对象,则该TreeMap对象实际是不可用的。使用默认构造器(没有排序)
TreeMap treeMap = new TreeMap();
treeMap.put("zw","20000");
treeMap.put("wl","18000");
treeMap.put("hy","16000");
treeMap.put("sq","15000");
treeMap.put("sq","20000");
System.out.println(treeMap);
//{hy=16000, sq=20000, wl=18000, zw=20000}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
要求 : 按照字符串的大小来进行排序(
compareTo方法TreeSet章节已经介绍)
TreeMap treeMap = new TreeMap((o1, o2) -> ((String) o1).compareTo((String) o2));
- 1
7.7.3.基本方法
put方法
- 由于
TreeMap支持自动排序,所以put方法会检查是否满足规则。- 不满足排序规则,抛出异常。
- 否则,按照红黑树算法规则要求,创建红黑树,存储数据。
get方法
- 根据红黑树查找算法查找并返回数据,红黑树是平衡二叉树,查询时间复杂度为O(log(n))。
key遍历
- 比如调用
TreeMap.keySet方法,采用遍历二叉树算法,按照从小到大的顺序返回所有key值组成的循环器。- 但是如果自定义的对象,没有实现
Comparable接口,同时在TreeMap实例化的时候没有设置comparator对象,则该TreeMap对象实际是不可用的。使用默认构造器(没有排序)
TreeMap treeMap = new TreeMap();
treeMap.put("zw","20000");
treeMap.put("wl","18000");
treeMap.put("hy","16000");
treeMap.put("sq","15000");
treeMap.put("sq","20000");
System.out.println(treeMap);
//{hy=16000, sq=20000, wl=18000, zw=20000}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
要求 : 按照字符串的大小来进行排序(
compareTo方法TreeSet章节已经介绍)
TreeMap treeMap = new TreeMap((o1, o2) -> ((String) o1).compareTo((String) o2));
- 1
7.7.3.基本方法
put方法
- 由于
TreeMap支持自动排序,所以put方法会检查是否满足规则。- 不满足排序规则,抛出异常。
- 否则,按照红黑树算法规则要求,创建红黑树,存储数据。
get方法
- 根据红黑树查找算法查找并返回数据,红黑树是平衡二叉树,查询时间复杂度为O(log(n))。
key遍历
- 比如调用
TreeMap.keySet方法,采用遍历二叉树算法,按照从小到大的顺序返回所有key值组成的循环器。

