
- 1Jetson系列TensorRT .onnx转.trt/.engine_tensorrt转 engine需要 很久
- 2[709]python之pywifi_class my_gui() import pywifi
- 3开源 | 30余套STM32单片机、嵌入式Linux、物联网、人工智能项目(开发板+教程+视频)_stm32实战项目
- 4用Python 给财务写了个“群发工资条”,效果不错
- 5Attention注意力机制学习(二)------->一些注意力网络整理_分组通道注意力
- 6使用WPS进行编程文本输入_wps插入代码
- 7【期末复习】电子商务_在线零售相对邮购的优势有哪些
- 8Tomcat以服务方式启动,无法访问网络共享目录问题
- 9K近邻(KNN)原理及python实现_python实现knn
- 10GitHub 下载单个文件/文件夹_github下载某个文件夹
NVIDIA Triton系列-YOLOV5 部署(1) -环境搭建及部署并使用Perf_Analyze测试ONNX YOLOV5M_如何使用triton推理yolov5
赞
踩
背景
在一家国企的研发性质子公司上班,工作是负责CV产品线的算法从开发到部署全流程,由于公司刚成立不久,所有技术储备基本=0,导致整套部署流程都要自己摸索。开坑记录一下部署历程。
公司的部署要求:
1. 基于NVIDIA平台(T4)
2. 提供对外接口(公/私网)
3. 告警实时性,延迟不超过2S
Triton简介
英伟达的Triton推理服务器(之前称为TensorRT推理服务器)是一个开源项目,旨在简化部署AI模型到生产环境的过程。Triton可以支持多种AI框架,如TensorFlow、PyTorch、ONNX等,并可以同时为多个模型和多个框架提供推理服务。这使得开发者可以在一个统一的服务器上部署和管理各种不同的模型,而无需为每个模型单独建立一个推理服务。此外,Triton还优化了GPU利用率,从而实现高效、高性能的模型推理。其动态张量和批处理功能可以帮助提高吞吐量,而模型管道功能则可以简化复杂的AI工作流程。[来自ChatGPT]
为什么用Triton
最开始的方案
首先做一下简单的业务拆分:
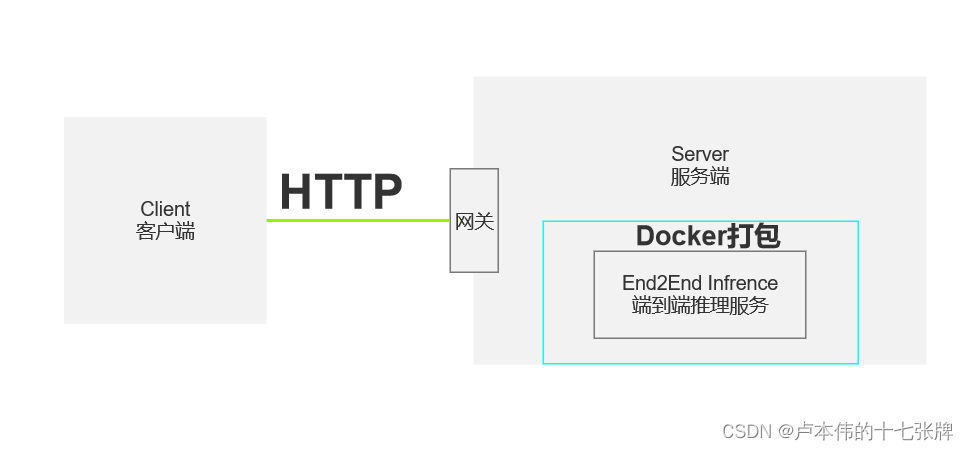
-
客户端:客户端可以通过HTTP请求将图片发送至服务端进行深度推理。在图片的传输过程中,主要有两种方式:
-
使用图片的BASE64编码进行传输。
-
首先将图片上传至公司的OBS服务,然后通过内网对该图片进行推理。
我个人更偏向于使用第二种传输方式。这是因为当图片被转化为BASE64编码时,它的大小会增加大约30%,导致传输成本增加。此外,客户端和服务端都需要为编码和解码付出额外的计算成本。而采用第二种方法只需增加一个存储服务器或使用公司的OBS云服务,通过这种方法可以有效地节省上述成本。然而,由于某些网络限制和公司内部的费用结算策略,我们最终还是选择了使用BASE64编码的方法进行图片传输,因为这种方式相对更加简便。
-
-
服务端:服务端负责对来自客户端的图片进行推理分析。在处理这些图片时,我们主要采用了开源的端到端解决方案,例如直接从YOLOV5的detect.py中提取关键函数。我们使用Flask作为提供API的框架,但除此之外并未进行其他操作,如批处理或多进程处理。
通过上述的简单方案,在当时人手紧缺的时候简单撑起了公司的推理业务,然而随着业务量的增加,几个问题摆在面前:
1. GPU资源紧缺
2. 现有的部署方案定制化程度太高(都需要根据算法特性重新编写整套推理服务)
3. 更多的复杂场景需要多个模型串行解决。
4.缺少专业的测试工具对推理服务进行压测以评估推理成本
5.缺少合理的数据管理工具
首先针对问题5,我们选择私有化部署CVAT进行解决。
针对问题1,2,3,4,我们采用过例如TRT部署、编写标准推理接口利用Torch.Hub等模块做模型的通用化部署等进行解决,然而由于部署环境受限,我们在使用TRT过程中发现不同机器哪怕同一型号GPU CPU,转出来的TRT也是无法通用的,必须要在本地重新转一次,同时编写BATCH策略等都比较耗时,最终看了美团的部署方案选定用Triton作为部署框架。
Triton的优势:
提供GRPC/HTTP接口
提供动态BATCH、多线程等提升吞吐量的方法。
提供模型版本管理工具
Nvidia自家生态,专门针对自己家的卡做了优化
一键式的部署方案–完美的契合了我们基于K8S容器式部署的方式,以前需要每个模型打包一个docker image,现在的话只需要一个标准docker image,然后把所有模型按照格式往里面丢就行,通过模型版本管理工具在配置文件中修改所需要启动的算法即可。这对我们“比较难用”的容器化服务平台真是一种救赎。
环境部署
我分别尝试了在自己3090电脑以及云T4环境的部署,鉴定为:没有区别。
- 登录https://catalog.ngc.nvidia.com/containers,选择适合自己电脑版本的Triton镜像(我无脑用最新版)

 根据图中的描述,一般来说选择xx.yy-py3这种形式的镜像即可,底下的SDK版本将会在用到perf_analyze的时候用到。而至于底下的一般用不到。
根据图中的描述,一般来说选择xx.yy-py3这种形式的镜像即可,底下的SDK版本将会在用到perf_analyze的时候用到。而至于底下的一般用不到。
点击TAG选择一个合适的镜像:执行docker pull nvcr.io/nvidia/tritonserver:23.08-py3
拉取的过程中可能会特别卡,有可能是因为XX的原因,不过我没遇到这些问题,如果遇到了尝试安装个代理吧。这里遇到的一个坑是docker在某个版本之后和之前,设置代理的配置文件和方式都不一样,所以在网上经常会看到好多种不同方式的设置方案,这里一定要确保自己的版本跟他们一样或者相差不大,如果有问题请记住一定是版本问题。

拉取完毕后可以用官方的指令进行测试:
git clone -b r23.08 https://github.com/triton-inference-server/server.git cd server/docs/examples ./fetch_models.sh # Step 2: Launch triton from the NGC Triton container docker run --gpus=1 --rm --net=host -v ${PWD}/model_repository:/models nvcr.io/nvidia/tritonserver:23.08-py3 tritonserver --model-repository=/models # Step 3: Sending an Inference Request # In a separate console, launch the image_client example from the NGC Triton SDK container docker run -it --rm --net=host nvcr.io/nvidia/tritonserver:23.08-py3-sdk /workspace/install/bin/image_client -m densenet_onnx -c 3 -s INCEPTION /workspace/images/mug.jpg # Inference should return the following Image '/workspace/images/mug.jpg': 15.346230 (504) = COFFEE MUG 13.224326 (968) = CUP 10.422965 (505) = COFFEEPOT

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
这里有个坑,执行命令如果报错GPU相关的问题,大概是有些docker版本可能需要安装nvidia container runtime ,具体安装说明https://docs.nvidia.com/datacenter/cloud-native/container-toolkit/latest/install-guide.html
除此之外,也有可能是驱动版本过低,如果输入nvidia-smi not found的那就是没有驱动。直接去英伟达官网安装一个最新的就行。
等到一切准备就绪以后,就可以开始准备内部的部署文件了。
简单的基于ONNX 的YOLOV5部署:
部署目录结构准备
首先我们要准备一个如下图的目录结构:
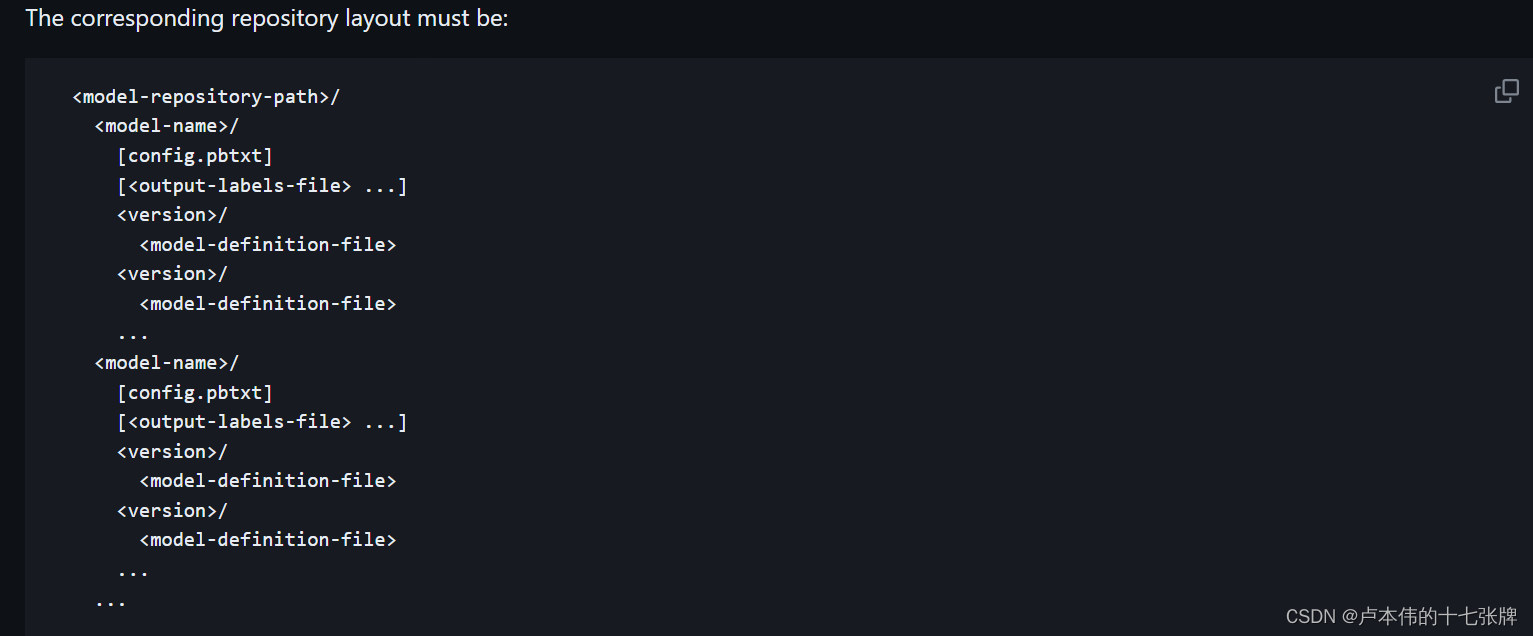
简单来说,就是在一个主文件下,每个模型文件各创建一个文件夹,里面包含模型版本文件夹以及一个config.pbtxt(目前只需要用到这个),一般来说,主文件里面可以包含无数个模型文件夹,而一个模型文件夹中又可以有无数个模型版本,每个模型文件夹中的相关配置都由config.pbtxt进行管理。
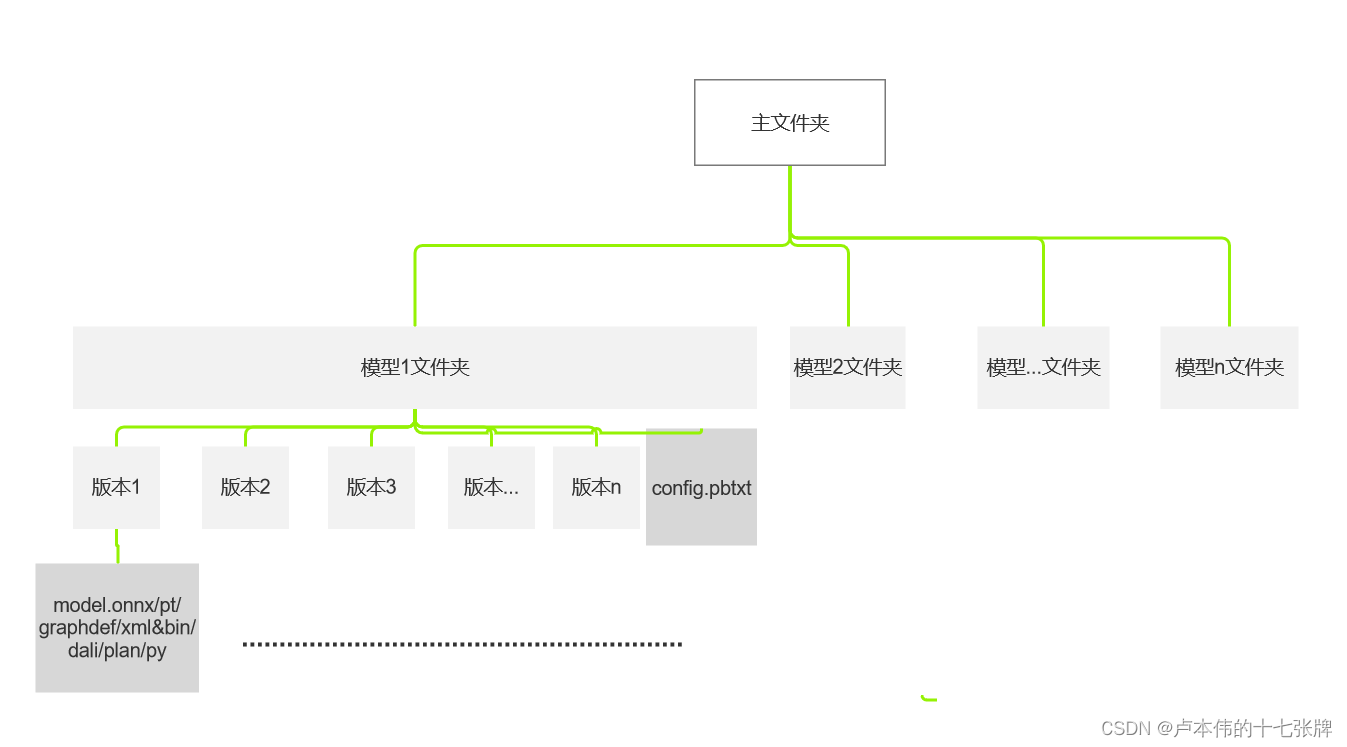
这里模型文件分别对应onnx\pytorch\TensorFlow\OpenVINO\DALI\TensorRT\Python脚本文件,具体规则:https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/user_guide/model_repository.html
以用onnx部署YOLOV5m为例:

这里yolov5是我的模型文件夹,1是版本文件夹,底下放了onnx/TensorRT和一个torchscript文件,Ttiton在启动的时候具体使用哪个模型取决于我在config.pbtxt中的设置,但且注意模型文件名必须为model。
config.pbtxt
name: "yolov5" #必须对应好自己模型文件夹的名称 platform: "onnxruntime_onnx" #ONNX选这个 max_batch_size : 0 #这个后面优化部分再解释,填0为不约束 input [ { name: "images" #这里的名称不同的模型有不同的名称,可以把onnx文件拖到netron里面查看输入和输出的名称。 data_type: TYPE_FP32 #这里填写转换的时候的格式 dims: [1,3, 640, 640] #这里填写输入大小,前面的1是batch大小 reshape: { shape: [1,3,640, 640] } #这里是可以自动执行转换,但建议还是把resize的事情放在客户端,resize还是比较耗资源的。 } ] output [ { name: "output" data_type: TYPE_FP32 dims: [1,25200,7] } ]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
使用Netron查看模型的输入输出:
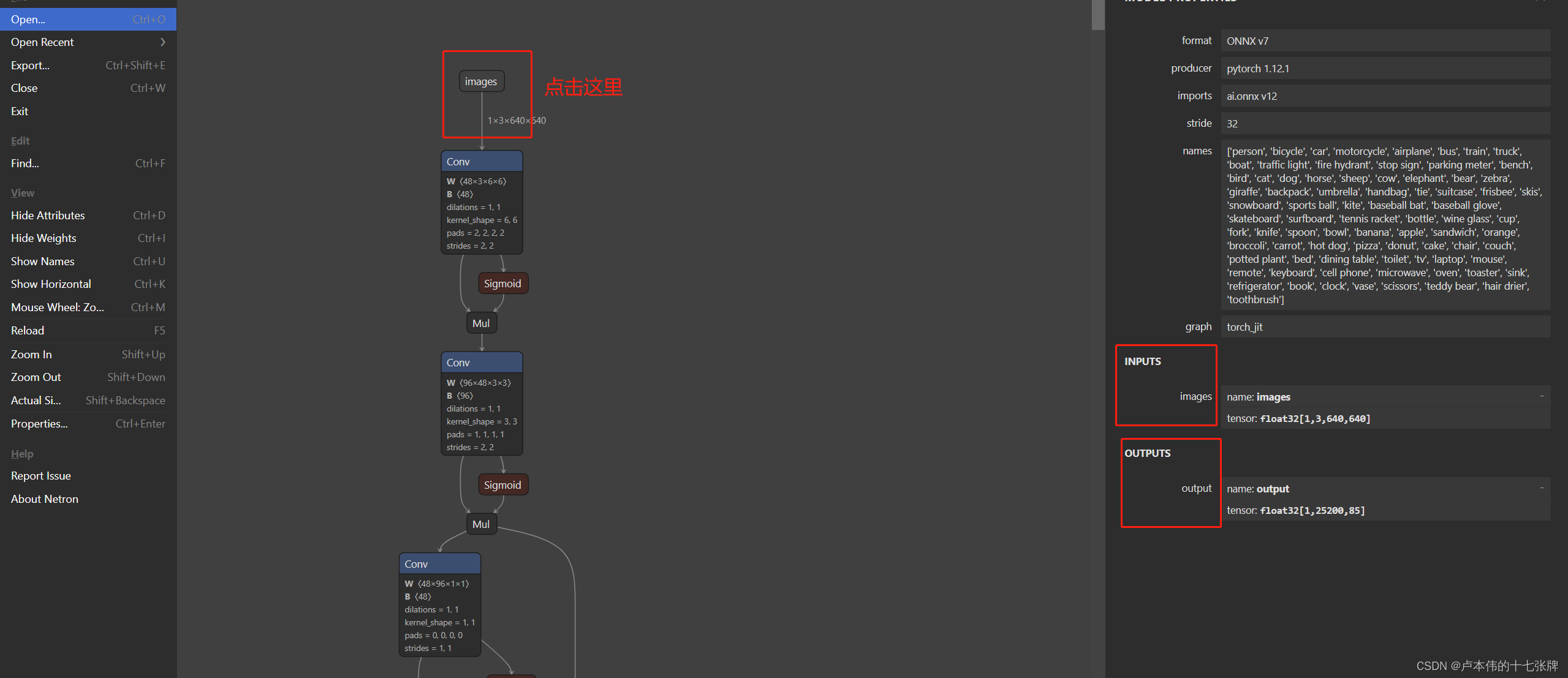
把这里的name和tensor填写到config.pbtxt中对应的地方就行。
全部完事之后,运行
docker run --gpus=all --rm -p8000:8000 -p8001:8001 -p8002:8002 -v/full/path/to/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:<xx.yy>-py3 tritonserver --model-repository=/models
- 1
上面的-v指向你的主文件夹就行,这里如果要指定对应的GPU,请修改–gpus,例如–gpus=‘“device=3,4”’
官方给的这串启动命令没有考虑到多模型和ensemble的情况,直接运行的话由于DOCKER的共享内存默认很少,我们需要再加一个参数设置共享参数:
--shm-size 2g #这里2g一般都够用,要是觉得不够的再加也都是可以的
- 1
最终命令:
docker run --gpus=all --shm-size 2g --rm -p8000:8000 -p8001:8001 -p8002:8002 -v/full/path/to/docs/examples/model_repository:/models nvcr.io/nvidia/tritonserver:<xx.yy>-py3 tritonserver --model-repository=/models
- 1
运行后,如果正常将会看到:
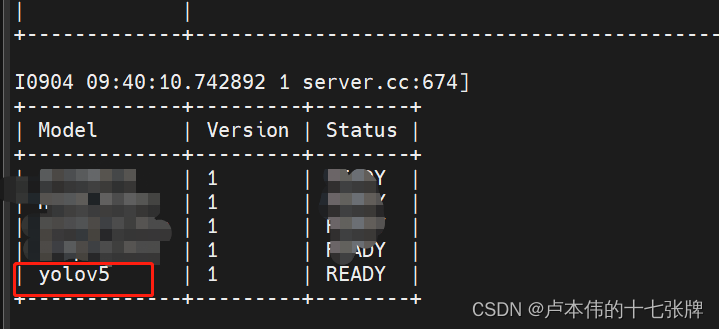
同时会开放:
如果想要换成其他端口,在容器启动命令-p的参数中修改映射端口就行。
Perf_Analyze性能测试(英伟达官方推理性能测试软件)
启动后,我们拉取SDK镜像进行进一步的性能测试:

docker pull nvcr.io/nvidia/tritonserver:23.08-py3-sdk
- 1
拉取后简单启动,但是请注意必须要有–net=host,因为我们要垮容器访问,这个命令就相当于不创建专属容器的虚拟网卡,直接用宿主机的网卡,那我们就可以直接通过localhost去访问Triton_Server映射出的端口。这里的gpus命令可以不带,我是习惯都加上万一要用。
docker run --gpus all --rm -it --net host nvcr.io/nvidia/tritonserver:23.08-py3-sdk
- 1
- 2
进入容器后,直接执行命令
perf_analyzer -m yolov5 --shape input:1,3,640,640 -i grpc --concurrency-range 1:50:10
- 1
-m 后面跟自己的模型名称,shape后面的input输入config.pbtxt里面的input,-i 可以选择grpc或者http两种模式,concurrency-range的官方解释:
–concurrency-range=start:end:step
指定性能分析器涵盖的并发级别范围。性能分析器将从“start”的并发级别开始,以“step”的步长走到“end”。
‘end’ 和 ‘step’ 的默认值是1。如果未指定“end”,则性能分析器将针对“start”确定的单个并发级别运行。如果 ‘end’ 设置为0,则并发限制将按 ‘step’ 递增,直到满足延迟阈值。‘end’ 并且–latency-threshold不能两者都是0。0使用异步模式时,“end”不能用于序列模型。
具体详情:https://github.com/triton-inference-server/client/blob/main/src/c%2B%2B/perf_analyzer/docs/cli.md
运行后,可以测得不同并发情况下的FPS、推理延迟以及GPU使用率:

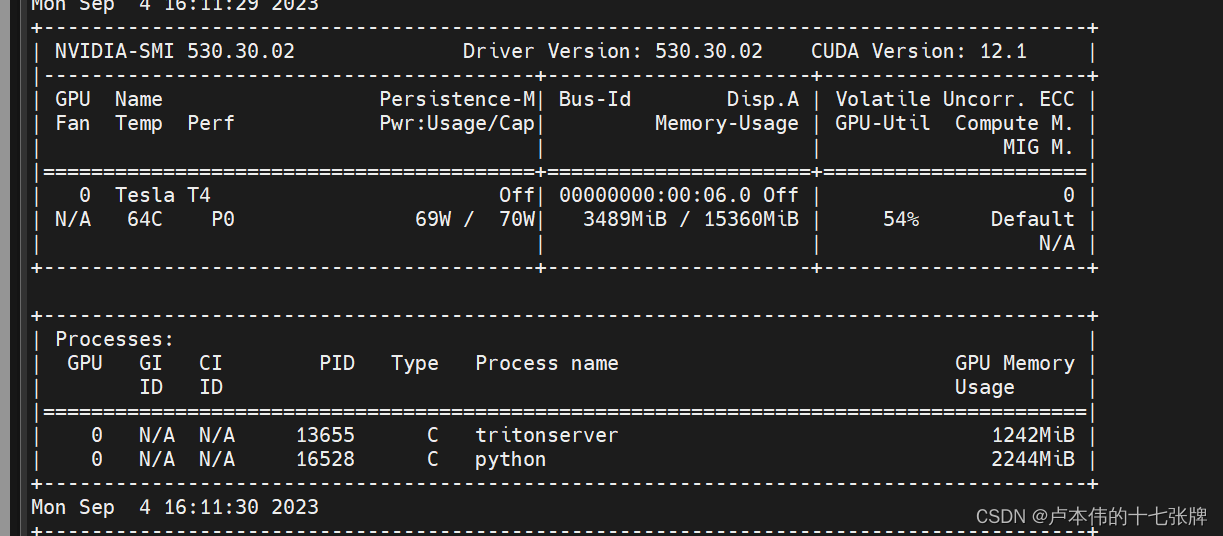
四核32G的T4+TRT的测试结果(加了前后处理,如果只是单纯的onnx yolov5m我记得是有大概70-80FPS。),至于为什么把前后处理也加到了Triton的服务中而没有做分离,这个后面会说。
下期将会更新ensemble策略以及对pre/post process的处理。


