
- 1后台管理系统模板推荐(vue-element-admin)_elementui管理系统模板
- 2refusing to merge unrelated histories;please enter a commit message to explain;Can‘t update masterha_can't update master
- 3【JMeter】JMeter控制RPS
- 4MySQL之误删数据如何处理
- 52024 基于深度学习的毕业设计(论文)选题指南 开题指导_机器学习本科毕业设计
- 6pytorch模型转keras模型
- 7在macOS中,卸载Python3.8步骤_mac卸载python3.8
- 8python自动化设备工程师-机械设计制造及其自动化专业就业前景怎么样?薪资如何?...
- 9通用漏洞评估方法CVSS3.0简表
- 10云计算探索-如何在服务器上配置RAID(附模拟器)
基本的bash shell命令_使用man查看bash的手册,并将其标准输出重定向到 bash.txt,
赞
踩
bash手册
man命令用来访问存储在Linux系统上的手册页面。在想要查找的工具的名称前面输入man命令就可以找到那个工具相应的手册条目。当使用man命令查看手册时,手册是由分页程序来显示的,使用空格键翻页或使用回车键逐行查看,q建退出。输入man man来查看与手册也相关的手册页。
手册页将与命令相关的信息分成了不同的节。每一节惯用的命名标准如表3-1所示。
| 节 | 描 述 |
|---|---|
| Name | 显示命令名和一段简短的描述 |
| Synopsis | 命令的语法 |
| Configuration | 命令配置信息 |
| Description | 命令的一般性描述 |
| Options | 命令选项描述 |
| Exit Status | 命令的退出状态指示 |
| Return Value | 命令的返回值 |
| Errors | 命令的错误消息 |
| Environment | 描述所使用的环境变量 |
| Files | 命令用到的文件 |
| Versions | 命令的版本信息 |
| Conforming To | 命名所遵从的标准 |
| Notes | 其他有帮助的资料 |
| Bugs | 提供提交bug的途径 |
| Example | 展示命令的用法 |
| Authors | 命令开发人员的信息 |
| Copyright | 命令源代码的版权状况 |
| See Also | 与该命令类型的其他命令 |
如果不记得命令名怎么办?可以使用关键字搜索手册页。语法是:man -k 关键字。例如,要查找与终端相关的命令,可以输入man -k terminal。
除了对节按照惯例进行命名,手册页还有对应的内容区域。每个内容区域都分配了一个数字,从1开始,一直到9,如表3-2所示。
| 区 域 号 | 所涵盖的内容 |
|---|---|
| 1 | 可执行程序或shell命令 |
| 2 | 系统调用 |
| 3 | 库调用 |
| 4 | 特殊文件 |
| 5 | 文件格式与约定 |
| 6 | 游戏 |
| 7 | 概览、约定及杂项 |
| 8 | 超级用户和系统管理员命令 |
| 9 | 内核例程 |
man工具通常提供的是命令所对应的最低编号的内容。例如,我们输入的是命令man xterm,请注意,在现实内容的左上角和右上角,单词XTERM后的括号中有一个数字:(1)。
这表示所显示的手册页来自内容区域1(可执行程序或shell命令)。
一个命令偶尔会在多个内容区域都有对应的手册页。比如说,有个叫作hostname的命令。
手册页中既包括该命令的相关信息,也包括对系统主机名的概述。要想查看所需要的页面,可以输入man section# topic。对手册页中的第1部分而言,就是输入man 1 hostname。对于手
册页中的第7部分,就是输入man 7 hostname。
手册页不是唯一的参考资料。还有另一种叫作info页面的信息。可以输入info info来了解info页面的相关内容。另外,大多数命令都可以接受-help或–help选项。例如你可以输入hostname -help来查看帮助。关于帮助的更多信息,可以输入help help。
浏览文件系统
常见Linux目录名称
| 目录 | 用途 |
|---|---|
| / | 虚拟目录的根目录。通常不会在这里存储文件 |
| /bin | 二进制目录,存放许多用户级的GNU工具 |
| /boot | 启动目录,存放启动文件 |
| /dev | 设备目录,Linux在这里创建设备节点 |
| /etc | 系统配置文件目录 |
| /home | 主目录,Linux在这里创建用户目录 |
| /lib | 库目录,存放系统和应用程序的库文件 |
| /media | 媒体目录,可移动媒体设备的常用挂载点 |
| /mnt | 挂载目录,另一个可移动媒体设备的常用挂载点 |
| /opt | 可选目录,常用于存放第三方软件包和数据文件 |
| /proc | 进程目录,存放现有硬件及当前进程的相关信息 |
| /root | root用户的主目录 |
| /sbin | 系统二进制目录,存放许多GNU管理员级工具 |
| /run | 运行目录,存放系统运作时的运行时数据 |
| /srv | 服务目录,存放本地服务的相关文件 |
| /sys | 系统目录,存放系统硬件信息的相关文件 |
| /tmp | 临时目录,可以在该目录中创建和删除临时工作文件 |
| /usr | 用户二进制目录,大量用户级的GNU工具和数据文件都存储在这里 |
| /var | 可变目录,用以存放经常变化的文件,比如日志文件 |
文件和目录列表
| 命令 | 描述 |
|---|---|
| ls -F | 可用带-F参数的ls命令轻松区分文件和目录,-F参数在目录名后加了正斜线(/) |
| ls -a | 要把隐藏文件和普通文件及目录一起显示出来,就得用到-a参数 |
| ls -R | -R参数是ls命令可用的另一个参数,叫作递归选项。它列出了当前目录下包含的子目录中的文件 |
| ls -l | -l参数会产生长列表格式的输出,包含了目录中每个文件的更多相关信息 |
| ls -l --time=atime test_one | 显示的是文件中的数据最后被访问的时间 |
| ls -d | 只列出目录本身的信息,不列出其中的内容 |
| ls -i *data_file | 要查看文件或目录的inode编号,可以给ls命令加入-i参数 |
长列表格式的输出在每一行中列出了单个文件或目录。除了文件名,输出中还有其他有
用信息。输出的第一行显示了在目录中包含的总块数。在此之后,每一行都包含了关于文件(或目录)的下述信息:
文件类型,比如目录(d)、文件(-)、字符型文件(c)或块设备(b);
文件的权限;
文件的硬链接总数;
文件属主的用户名;
文件属组的组名;
文件的大小(以字节为单位);
文件的上次修改时间;
文件名或目录名。
当用户指定特定文件的名称作为过滤器时,ls命令只会显示该文件的信息。有时你可能不知道要找的那个文件的确切名称。ls命令能够识别标准通配符,并在过滤器中用它们进行模式匹配:
问号(?)代表一个字符;
星号(*)代表零个或多个字符。
问号可用于过滤器字符串中替代任意位置的单个字符。
ls -l my_scr?pt
ls -l my*
ls -l my_s*t
ls -l my_scr[ai]pt #a或i
ls -l f[a-i]ll #a到i
ls -l f[!a]ll #排除a
- 1
- 2
- 3
- 4
- 5
- 6
处理文件
| 命令 | 描述 |
|---|---|
| touch test_one | 创建文件 |
| touch -a test_one | 如果只想改变访问时间,可用-a参数。 |
| cp source destination | 当source和destination参数都是文件名时,cp命令将源文件复制成一个新文件,并且以destination命名。新文件就像全新的文件一样,有新的修改时间。 |
| cp -i test_one test_two | 强制shell询问是否需要覆盖已有文件 |
| cp -R Scripts/ Mod_Scripts | cp命令的-R参数威力强大。可以用它在一条命令中递归地复制整个目录的内容 |
| ln -s data_file sl_data_file | 要为一个文件创建符号链接,原始文件必须事先存在。然后可以使用ln命令以及-s选项来创建符号链接 |
| ln code_file hl_code_file | 引用硬链接文件等同于引用了源文件。要创建硬链接,原始文件也必须事先存在 |
| mv fall fzll | mv命令可以将文件和目录移动到另一个位置或重新命名 |
| rm -i fall | -i命令参数提示你是不是要真的删除该文件 |
| rm -i f?ll | 可以使用通配符删除成组的文件。别忘了使用-i选项保护好自己的文件 |
| rm -f | rm命令的另外一个特性是,如果要删除很多文件且不受提示符的打扰,可以用-f参数强制删除 |
| rm -ri My_Dir | 使用-r选项使得命令可以向下进入目录,删除其中的文件,然后再删除目录本身 |
处理目录
| 命令 | 描述 |
|---|---|
| mkdir New_Dir | 创建目录 |
| mkdir -p New_Dir/Sub_Dir/Under_Dir | 要想同时创建多个目录和子目录,需要加入-p参数 |
| rmdir New_Dir | 删除目录 |
查看文件内容
| 命令 | 描述 |
|---|---|
| file my_file | 查看文件类型 |
| cat test1 | 查看文件内容 |
| cat -n test1 | -n参数会给所有的行加上行号 |
| cat -b test1 | 如果只想给有文本的行加上行号,可以用-b参数 |
| cat -T test1 | 如果不想让制表符出现,可以用-T参数 |
| more testfile | more命令会显示文本文件的内容,但会在显示每页数据之后停下来 |
| less testfile | less命令的操作和more命令基本一样,一次显示一屏的文件文本。 |
| tail log_file | tail命令会显示文件最后几行的内容(文件的“尾部”)。默认情况下,它会显示文件的末尾10行。 |
| tail -n 2 log_file | 可以向tail命令中加入-n参数来修改所显示的行数 |
| tail -f log_file | tail命令会保持活动状态,并不断显示添加到文件中的内容 |
| head log_file | 会显示文件开头那些行的内容。默认情况下,它会显示文件前10行的文本 |
| head -5 log_file | 类似于tail命令,它也支持-n参数,这样就可以指定想要显示的内容了 |
监测程序
探查进程
默认情况下,ps命令只会显示运行在当前控制台下的属于当前用户的进程。基本输出显示了程序的进程ID(Process ID,PID)、它们运行在哪个终端(TTY)以及进程已用的CPU时间。
Linux系统中使用的GNU ps命令支持3种不同类型的命令行参数:
Unix风格的参数,前面加单破折线;
BSD风格的参数,前面不加破折线;
GNU风格的长参数,前面加双破折线。
- Unix风格的参数
| 参 数 | 描 述 |
|---|---|
| -A | 显示所有进程 |
| -N | 显示与指定参数不符的所有进程 |
| -a | 显示除控制进程(session leader①)和无终端进程外的所有进程 |
| -d | 显示除控制进程外的所有进程 |
| -e | 显示所有进程 |
| -C | cmdlist 显示包含在cmdlist列表中的进程 |
| -G | grplist 显示组ID在grplist列表中的进程 |
| -U | userlist 显示属主的用户ID在userlist列表中的进程 |
| -g | grplist 显示会话或组ID在grplist列表中的进程② |
| -p | pidlist 显示PID在pidlist列表中的进程 |
| -s | sesslist 显示会话ID在sesslist列表中的进程 |
| -t | ttylist 显示终端ID在ttylist列表中的进程 |
| -u | userlist 显示有效用户ID在userlist列表中的进程 |
| -F | 显示更多额外输出(相对-f参数而言) |
| -O | format 显示默认的输出列以及format列表指定的特定列 |
| -M | 显示进程的安全信息 |
| -c | 显示进程的额外调度器信息 |
| -f | 显示完整格式的输出 |
| -j | 显示任务信息 |
| -l | 显示长列表 |
| -o | format 仅显示由format指定的列 |
| -y | 不要显示进程标记(process flag,表明进程状态的标记) |
| -Z | 显示安全标签(security context)①信息 |
| -H | 用层级格式来显示进程(树状,用来显示父进程) |
| -n | namelist 定义了WCHAN列显示的值 |
| -w | 采用宽输出模式,不限宽度显示 |
| -L | 显示进程中的线程 |
- BSD风格的参数
| 参 数 | 描 述 |
|---|---|
| T | 显示跟当前终端关联的所有进程 |
| a | 显示跟任意终端关联的所有进程 |
| g | 显示所有的进程,包括控制进程 |
| r | 仅显示运行中的进程 |
| x | 显示所有的进程,甚至包括未分配任何终端的进程 |
| U | userlist 显示归userlist列表中某用户ID所有的进程 |
| p | pidlist 显示PID在pidlist列表中的进程 |
| t | ttylist 显示所关联的终端在ttylist列表中的进程 |
| O | format 除了默认输出的列之外,还输出由format指定的列 |
| X | 按过去的Linux i386寄存器格式显示 |
| Z | 将安全信息添加到输出中 |
| j | 显示任务信息 |
| l | 采用长模式 |
| o | format 仅显示由format指定的列 |
| s | 采用信号格式显示 |
| u | 采用基于用户的格式显示 |
| v | 采用虚拟内存格式显示 |
| N | namelist 定义在WCHAN列中使用的值 |
| O | order 定义显示信息列的顺序 |
| S | 将数值信息从子进程加到父进程上,比如CPU和内存的使用情况 |
| c | 显示真实的命令名称(用以启动进程的程序名称) |
| e | 显示命令使用的环境变量 |
| f | 用分层格式来显示进程,表明哪些进程启动了哪些进程 |
| h | 不显示头信息 |
| k | sort 指定用以将输出排序的列 |
| n | 和WCHAN信息一起显示出来,用数值来表示用户ID和组ID |
| w | 为较宽屏幕显示宽输出 |
| H | 将线程按进程来显示 |
| m | 在进程后显示线程 |
| L | 列出所有格式指定符 |
| V | 显示ps命令的版本号 |
- GNU长参数
| 参 数 | 描 述 |
|---|---|
| –deselect | 显示所有进程,命令行中列出的进程 |
| –Group | grplist 显示组ID在grplist列表中的进程 |
| –User | userlist 显示用户ID在userlist列表中的进程 |
| –group | grplist 显示有效组ID在grplist列表中的进程 |
| –pid | pidlist 显示PID在pidlist列表中的进程 |
| –ppid | pidlist 显示父PID在pidlist列表中的进程 |
| –sid | sidlist 显示会话ID在sidlist列表中的进程 |
| –tty | ttylist 显示终端设备号在ttylist列表中的进程 |
| –user | userlist 显示有效用户ID在userlist列表中的进程 |
| –format | format 仅显示由format指定的列 |
| –context | 显示额外的安全信息 |
| –cols | n 将屏幕宽度设置为n列 |
| –columns | n 将屏幕宽度设置为n列 |
| –cumulative | 包含已停止的子进程的信息 |
| –forest | 用层级结构显示出进程和父进程之间的关系 |
| –headers | 在每页输出中都显示列的头 |
| –no-headers | 不显示列的头 |
| –lines n | 将屏幕高度设为n行 |
| –rows n | 将屏幕高度设为n排 |
| –sort order | 指定将输出按哪列排序 |
| –width n | 将屏幕宽度设为n列 |
| –help | 显示帮助信息 |
| –info | 显示调试信息 |
| –version | 显示ps命令的版本号 |
实时监测进程
top命令跟ps命令相似,能够显示进程信息,但它是实时显示的。
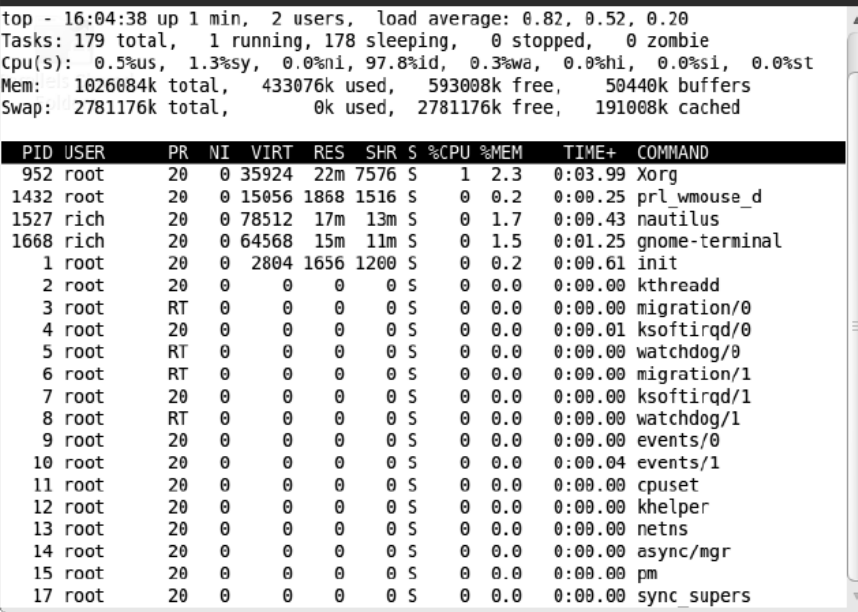
输出的第一部分显示的是系统的概况:第一行显示了当前时间、系统的运行时间、登录的用户数以及系统的平均负载。
平均负载有3个值:最近1分钟的、最近5分钟的和最近15分钟的平均负载。值越大说明系统的负载越高。由于进程短期的突发性活动,出现最近1分钟的高负载值也很常见,但如果近15分
钟内的平均负载都很高,就说明系统可能有问题。
Linux系统管理的要点在于定义究竟到什么程度才算是高负载。这个值取决于系统的硬件配置以及系统上通常运行的程序。对某个系统来说是高负载的值可能对另一系统来说就是正常值。通常,如果系统的负载值超过了2,就说明系统比较繁忙了。
第二行显示了进程概要信息——top命令的输出中将进程叫作任务(task):有多少进程处在
运行、休眠、停止或是僵化状态(僵化状态是指进程完成了,但父进程没有响应)。
下一行显示了CPU的概要信息。top根据进程的属主(用户还是系统)和进程的状态(运行、
空闲还是等待)将CPU利用率分成几类输出。
紧跟其后的两行说明了系统内存的状态。第一行说的是系统的物理内存:总共有多少内存,
当前用了多少,还有多少空闲。后一行说的是同样的信息,不过是针对系统交换空间(如果分配了的话)的状态而言的。
最后一部分显示了当前运行中的进程的详细列表,有些列跟ps命令的输出类似。
PID:进程的ID。
USER:进程属主的名字。
PR:进程的优先级。
NI:进程的谦让度值。
VIRT:进程占用的虚拟内存总量。
RES:进程占用的物理内存总量。
SHR:进程和其他进程共享的内存总量。
S:进程的状态(D代表可中断的休眠状态,R代表在运行状态,S代表休眠状态,T代表
跟踪状态或停止状态,Z代表僵化状态)。
%CPU:进程使用的CPU时间比例。
%MEM:进程使用的内存占可用内存的比例。
TIME+:自进程启动到目前为止的CPU时间总量。
COMMAND:进程所对应的命令行名称,也就是启动的程序名。
默认情况下,top命令在启动时会按照%CPU值对进程排序。可以在top运行时使用多种交互
命令重新排序。每个交互式命令都是单字符,在top命令运行时键入可改变top的行为。键入f允
许你选择对输出进行排序的字段,键入d允许你修改轮询间隔。键入q可以退出top。
结束进程
在Linux中,进程之间通过信号来通信。进程的信号就是预定义好的一个消息,进程能识别它并决定忽略还是作出反应。进程如何处理信号是由开发人员通过编程来决定的。大多数编写完善的程序都能接收和处理标准Unix进程信号。
| 信 号 | 名 称 | 描 述 |
|---|---|---|
| 1 | HUP | 挂起 |
| 2 | INT | 中断 |
| 3 | QUIT | 结束运行 |
| 9 | KILL | 无条件终止 |
| 11 | SEGV | 段错误 |
| 15 | TERM | 尽可能终止 |
| 17 | STOP | 无条件停止运行,但不终止 |
| 18 | TSTP | 停止或暂停,但继续在后台运行 |
| 19 | CONT | 在STOP或TSTP之后恢复执行 |
- kill命令
kill命令可通过进程ID(PID)给进程发信号。默认情况下,kill命令会向命令行中列出的全部PID发送一个TERM信号。遗憾的是,你只能用进程的PID而不能用命令名,所以kill命令有时并不好用。要发送进程信号,你必须是进程的属主或登录为root用户。
$ kill 3940
-bash: kill: (3940) - Operation not permitted
$
TERM信号告诉进程可能的话就停止运行。不过,如果有不服管教的进程,那它通常会忽略这个请求。如果要强制终止,-s参数支持指定其他信号(用信号名或信号值)。
你能从下例中看出,kill命令不会有任何输出。
kill -s HUP 3940
- 1
要检查kill命令是否有效,可再运行ps或top命令,看看问题进程是否已停止。
- killall命令
killall命令非常强大,它支持通过进程名而不是PID来结束进程。killall命令也支持通配符,这在系统因负载过大而变得很慢时很有用。
killall http*
- 1
上例中的命令结束了所有以http开头的进程,比如Apache Web服务器的httpd服务。
警告 以root用户身份登录系统时,使用killall命令要特别小心,因为很容易就会误用通配符而结束了重要的系统进程。这可能会破坏文件系统。
监测磁盘空间
挂载存储媒体
mount命令
Linux上用来挂载媒体的命令叫作mount。默认情况下,mount命令会输出当前系统上挂载的设备列表。
mount命令提供如下四部分信息:
媒体的设备文件名
媒体挂载到虚拟目录的挂载点
文件系统类型
已挂载媒体的访问状态
要手动在虚拟目录中挂载设备,需要以root用户身份登录,或是以root用户身份运行sudo命
令。下面是手动挂载媒体设备的基本命令:
mount -t type device directory
- 1
type参数指定了磁盘被格式化的文件系统类型。Linux可以识别非常多的文件系统类型。如
果是和Windows PC共用这些存储设备,通常得使用下列文件系统类型。
vfat:Windows长文件系统。
ntfs:Windows NT、XP、Vista以及Windows 7中广泛使用的高级文件系统。
iso9660:标准CD-ROM文件系统。
后面两个参数定义了该存储设备的设备文件的位置以及挂载点在虚拟目录中的位置。比如说,手动将U盘/dev/sdb1挂载到/media/disk,可用下面的命令:
mount -t vfat /dev/sdb1 /media/disk
- 1
如果要用到mount命令的一些高级功能,表4-5中列出了可用的参数。
| 参 数 | 描 述 |
|---|---|
| -a | 挂载/etc/fstab文件中指定的所有文件系统 |
| -f | 使mount命令模拟挂载设备,但并不真的挂载 |
| -F | 和-a参数一起使用时,会同时挂载所有文件系统 |
| -v | 详细模式,将会说明挂载设备的每一步 |
| -I | 不启用任何/sbin/mount.filesystem下的文件系统帮助文件 |
| -l | 给ext2、ext3或XFS文件系统自动添加文件系统标签 |
| -n | 挂载设备,但不注册到/etc/mtab已挂载设备文件中 |
| -p | num 进行加密挂载时,从文件描述符num中获得密码短语 |
| -s | 忽略该文件系统不支持的挂载选项 |
| -r | 将设备挂载为只读的 |
| -w | 将设备挂载为可读写的(默认参数) |
| -L label | 将设备按指定的label挂载 |
| -U uuid | 将设备按指定的uuid挂载 |
| -O | 和-a参数一起使用,限制命令只作用到特定的一组文件系统上 |
| -o | 给文件系统添加特定的选项 |
-o参数允许在挂载文件系统时添加一些以逗号分隔的额外选项。以下为常用的选项。
ro:以只读形式挂载。
rw:以读写形式挂载。
user:允许普通用户挂载文件系统。
check=none:挂载文件系统时不进行完整性校验。
loop:挂载一个文件。
umount命令
从Linux系统上移除一个可移动设备时,不能直接从系统上移除,而应该先卸载。
umount命令的格式非常简单:
umount [directory | device ]
使用 df 命令
df命令会显示每个有数据的已挂载文件系统。如你在前例中看到的,有些已挂载设备仅限系统内部使用。命令输出如下:
设备的设备文件位置;
能容纳多少个1024字节大小的块;
已用了多少个1024字节大小的块;
还有多少个1024字节大小的块可用;
已用空间所占的比例;
设备挂载到了哪个挂载点上。
df命令有一些命令行参数可用,但基本上不会用到。一个常用的参数是-h。它会把输出中
的磁盘空间按照用户易读的形式显示,通常用M来替代兆字节,用G替代吉字节。
使用 du 命令
du命令可以显示某个特定目录(默认情况下是当前目录)的磁盘使用情况。这一方法可用来快速判断系统上某个目录下是不是有超大文件。
默认情况下,du命令会显示当前目录下所有的文件、目录和子目录的磁盘使用情况,它会以磁盘块为单位来表明每个文件或目录占用了多大存储空间。对标准大小的目录来说,这个输出会
是一个比较长的列表。
每行输出左边的数值是每个文件或目录占用的磁盘块数。注意,这个列表是从目录层级的最
底部开始,然后按文件、子目录、目录逐级向上。这么用du命令(不加参数,用默认参数)作用并不大。我们更想知道每个文件和目录占用了多大的磁盘空间,但如果还得逐页查找的话就没什么意义了。
下面是能让du命令用起来更方便的几个命令行参数。
-c:显示所有已列出文件总的大小。
-h:按用户易读的格式输出大小,即用K替代千字节,用M替代兆字节,用G替代吉字节。
-s:显示每个输出参数的总计。
处理数据文件
排序数据
默认情况下,sort命令按照会话指定的默认语言的排序规则对文本文件中的数据行排序。默认情况下,sort命令会把数字当做字符来执行标准的字符排序,产生的输出可能根本就不是你要的。解决这个问题可用-n参数,它会告诉sort命令把数字识别成数字而不是字符,并且按值排序。
另一个常用的参数是-M,按月排序。Linux的日志文件经常会在每行的起始位置有一个时间戳,用来表明事件是什么时候发生的。如果用-M参数,sort命令就能识别三字符的月份名,并相应地排序。
sort -M file3
Jan
Feb
Mar
Apr
May
Jun
Jul
Aug
Sep
Oct
Nov
Dec
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
还有其他一些方便的sort参数可用,如表4-6所示。
| 单破折线 | 双破折线 | 描 述 |
|---|---|---|
| -b | –ignore-leading-blanks | 排序时忽略起始的空白 |
| -C | –check=quiet | 不排序,如果数据无序也不要报告 |
| -c | –check | 不排序,但检查输入数据是不是已排序;未排序的话,报告 |
| -d | –dictionary-order | 仅考虑空白和字母,不考虑特殊字符 |
| -f | –ignore-case | 默认情况下,会将大写字母排在前面;这个参数会忽略大小写 |
| -g | –general-number-sort | 按通用数值来排序(跟-n不同,把值当浮点数来排序,支持科学计数法表示的值) |
| -i | –ignore-nonprinting | 在排序时忽略不可打印字符 |
| -k | –key=POS1[,POS2] | 排序从POS1位置开始;如果指定了POS2的话,到POS2位置结束 |
| -M | –month-sort | 用三字符月份名按月份排序 |
| -m | –merge | 将两个已排序数据文件合并 |
| -n | –numeric-sort | 按字符串数值来排序(并不转换为浮点数) |
| -o | –output=file | 将排序结果写出到指定的文件中 |
| -R | –random-sort | 按随机生成的散列表的键值排序 |
| –random-source=FILE | 指定-R参数用到的随机字节的源文件 | |
| -r | –reverse | 反序排序(升序变成降序) |
| -S | –buffer-size=SIZE | 指定使用的内存大小 |
| -s | –stable | 禁用最后重排序比较 |
| -T | –temporary-directory=DIR | 指定一个位置来存储临时工作文件 |
| -t | –field-separator=SEP | 指定一个用来区分键位置的字符 |
| -u | –unique | 和-c参数一起使用时,检查严格排序;不和-c参数一起用时,仅输出第一例相似的两行 |
| -z | –zero-terminated | 用NULL字符作为行尾,而不是用换行符 |
-k和-t参数在对按字段分隔的数据进行排序时非常有用,例如/etc/passwd文件。可以用-t参数来指定字段分隔符,然后用-k参数来指定排序的字段。举个例子,要对前面提到的密码文件/etc/passwd根据用户ID进行数值排序,可以这么做:
sort -t ':' -k 3 -n /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
- 1
- 2
- 3
- 4
- 5
- 6
现在数据已经按第三个字段——用户ID的数值排序。-n参数在排序数值时非常有用,比如du命令的输出。
$ du -sh * | sort -nr
1008k mrtg-2.9.29.tar.gz
972k bldg1
888k fbs2.pdf
760k Printtest
- 1
- 2
- 3
- 4
- 5
搜索数据
grep命令会在输入或指定的文件中查找包含匹配指定模式的字符的行。grep的输出就是包
含了匹配模式的行。
grep [options] pattern [file]
| 命令 | 描述 |
|---|---|
| grep three file1 | |
| grep -v t file1 | 反向搜索(输出不匹配该模式的行),可加-v参数 |
| grep -n t file1 | 如果要显示匹配模式的行所在的行号,可加-n参数 |
| grep -c t file1 | 如果只要知道有多少行含有匹配的模式,可用-c参数 |
| grep -e t -e f file1 | 如果要指定多个匹配模式,可用-e参数来指定每个模式 |
压缩数据
Linux上的文件压缩工具
| 工 具 | 文件扩展名 | 描 述 |
|---|---|---|
| bzip2 | .bz2 | 采用Burrows-Wheeler块排序文本压缩算法和霍夫曼编码 |
| compress | .Z | 最初的Unix文件压缩工具,已经快没人用了 |
| gzip | .gz | GNU压缩工具,用Lempel-Ziv编码 |
| zip | .zip | Windows上PKZIP工具的Unix实现 |
gzip是Linux上最流行的压缩工具。gzip软件包是GNU项目的产物,意在编写一个能够替代原先Unix中compress工具的免费版本。这个软件包含有下面的工具。
gzip:用来压缩文件。
gzcat:用来查看压缩过的文本文件的内容。
gunzip:用来解压文件。
这些工具基本上跟bzip2工具的用法一样。
gzip命令会压缩你在命令行指定的文件。也可以在命令行指定多个文件名甚至用通配符来一次性批量压缩文件。
$ gzip my*
$ ls -l my*
-rwxr--r-- 1 rich rich 103 Sep 6 13:43 myprog.c.gz
-rwxr-xr-x 1 rich rich 5178 Sep 6 13:43 myprog.gz
-rwxr--r-- 1 rich rich 59 Sep 6 13:46 myscript.gz
-rwxr--r-- 1 rich rich 60 Sep 6 13:44 myscript2.gz
- 1
- 2
- 3
- 4
- 5
- 6
归档数据
tar命令最开始是用来将文件写到磁带设备上归档的,然而它也能把输出写到文件里,这种用法在Linux上已经普遍用来归档数据了。
下面是tar命令的格式:
tar function [options] object1 object2 …
| 功 能 | 长 名 称 | 描 述 |
|---|---|---|
| -A | –concatenate | 将一个已有tar归档文件追加到另一个已有tar归档文件 |
| -c | –create | 创建一个新的tar归档文件 |
| -d | –diff | 检查归档文件和文件系统的不同之处 |
| –delete | 从已有tar归档文件中删除 | |
| -r | –append | 追加文件到已有tar归档文件末尾 |
| -t | –list | 列出已有tar归档文件的内容 |
| -u | –update | 将比tar归档文件中已有的同名文件新的文件追加到该tar归档文件中 |
| -x | –extract | 从已有tar归档文件中提取文件 |
| 选 项 | 描 述 |
|---|---|
| -C dir | 切换到指定目录 |
| -f file | 输出结果到文件或设备file |
| -j | 将输出重定向给bzip2命令来压缩内容 |
| -p | 保留所有文件权限 |
| -v | 在处理文件时显示文件 |
| -z | 将输出重定向给gzip命令来压缩内容 |
| 命令 | 描述 |
|---|---|
| tar -cvf test.tar test/ test2/ | 创建一个归档文件 |
| tar -tf test.tar | 列出tar文件test.tar的内容 |
| tar -xvf test.tar | 从tar文件test.tar中提取内容 |

