
- 1Flutter使用Texture在安卓端实现Camera预览_flutter camera 预览区
- 2Hadoop-熟悉常用的HDFS操作_hadoop的常用命令实验报告
- 3进阶数据库系列(十六):PostgreSQL 数据库高可用方案_postgresql高可用构架
- 4Element drawer无法上下滚动_arco design drawer弹出其他区域无法滚动
- 5全网最详细的Flutter开发入门基础教程,Flutter跨平台终极之选
- 6在linux下编译安装xvid
- 7动态规划的思想_大事化小小事化了体现出的问题求解思想是
- 8一份面经让你面试成功率加80%,985大佬分享自己的字节三面面经!_字节一面和二面通过率
- 9【python游戏】努力制造阳光,让植物有力量对抗僵尸吧~_pycharm植物大战僵尸
- 10面试官喜欢与岗位匹配度较高的求职者,怎么准备?_面试官问你岗位的匹配度
Raki的读paper小记:XLNet: Generalized Autoregressive Pretraining for Language Understanding_paper: xlnet: generalized autoregressive pretraini
赞
踩
Abstract & Introduction & Related Work
- 研究任务
- 预训练语言模型
- 已有方法和相关工作
- BERT
- 面临挑战
- 依靠用掩码破坏输入,BERT忽略了被掩码位置之间的依赖性,并受到预训练-调整差异的影响
- 创新思路
- 通过对因式分解顺序的所有排列组合的预期可能性最大化,实现了双向语境的学习
- 由于其自回归方法,克服了BERT的限制
- 结合了Transformer-XL,打破了512token的限制
- 实验结论
- 大幅超越BERT的性能
- XLNet不是像传统的AR模型那样使用固定的前向或后向因式分解顺序,而是将序列的预期对数似然在因式分解顺序的所有可能的排列中最大化。由于排列操作,每个位置的上下文可以由左右两边的标记组成。在期望中,每个位置学会利用来自所有位置的上下文信息,即捕捉双向的上下文
- 作为一个广义的AR语言模型,XLNet并不依赖于数据损坏。因此,XLNet不会像BERT那样受到预训练-调整差异的影响。同时,自回归目标还提供了一种自然的方法,可以使用乘积法则对预测标记的联合概率进行因子化,消除了BERT中的独立假设
首先,以前的模型旨在通过在模型中植入 "无序 "的inductive bias来改善密度估计,而XLNet的动机是使AR语言模型能够学习双向语境。从技术上讲,为了构建一个有效的目标意识预测分布,XLNet通过双流注意将目标位置纳入隐藏状态,而以前基于互换的AR模型则依赖于其MLP架构中固有的隐含位置意识。最后,对于无序的NADE和XLNet,我们想强调的是,"无序 "并不意味着输入序列可以随机排列,而是该模型允许分布的不同因子化顺序
Proposed Method
Background
自回归模型的优化目标
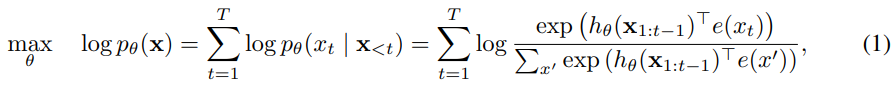
BERT的优化目标,用破坏后的
x
^
\hat{x}
x^ 来预测原始的
x
ˉ
\bar{x}
xˉ
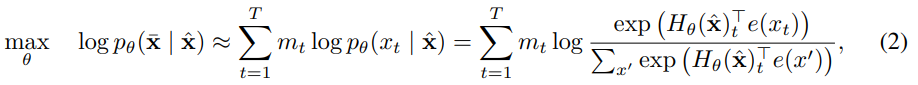
Independence Assumption
BERT基于一个独立的假设对联合条件概率 p ( x ˉ ∣ x ^ ) p(\bar{x}|\hat{x}) p(xˉ∣x^)进行因子化,即所有被屏蔽的标记 x ˉ \bar{x} xˉ都是单独的重构。相比之下,AR语言建模等式(1)使用乘积规则对 p θ ( x ) p_θ(x) pθ(x)进行因子化,该规则在没有这种独立性假设的情况下普遍适用
Input noise
BERT训练过程中的mask在下游任务中是没有出现的,会导致训练和fine-tune行为不一致,用[MASK]代替BERT中的原始token并不能解决问题,因为原始tplem只能以很小的概率被使用–否则,公式(2)的优化将是微不足道的。(2)将是非常容易优化的。相比之下,AR语言建模并不依赖于任何输入破坏,因此不会出现这个问题
Context dependency
自回归模型的表示只建立在位置t之前,而BERT用了双向的上下文信息,使其有更好的捕捉上下文信息的能力
Objective: Permutation Language Modeling
我们提出排列语言建模目标既保持了两者的优势,不仅受益于AR模型,又有捕捉双向上下文信息的能力
一个长度为T的序列,有T!种不同的有效自回归排列因子
直观地说,如果模型参数在所有因式分解顺序中都是共享的,那么在预期中,模型将学会从两边的所有位置收集信息
对于一个文本序列x,我们每次对一个因子化顺序z进行抽样,并根据因子化顺序对似然
p
θ
(
x
)
p_θ(x)
pθ(x)进行分解。由于同一模型参数θ在训练期间在所有的因式分解顺序中都是共享的,在期望中,
x
t
x_t
xt 已经看到了序列中每一个可能的元素
x
i
≠
x
t
x_i \ne x_t
xi=xt ,因此能够捕获双向的上下文。此外,由于这个目标符合AR框架,它自然避免了第2.1节中讨论的独立假设和训练前-调整后的差异

Remark on Permutation
提出的目标只改变因式分解的顺序,不改变序列的顺序。换句话说,我们保留原始序列的顺序,使用与原始序列相对应的位置编码,并依靠transformer中适当的注意力掩码来实现因式分解顺序的互换。请注意,这种选择是必要的,因为模型在微调过程中只会遇到具有自然顺序的文本序列

Architecture: Two-Stream Self-Attention for Target-Aware Representations
使用标准的transformer参数化并不work,需要改成如下形式,也就是把h换成了g,一种新的表征类型,它还将目标位置
z
t
z_t
zt 作为输入
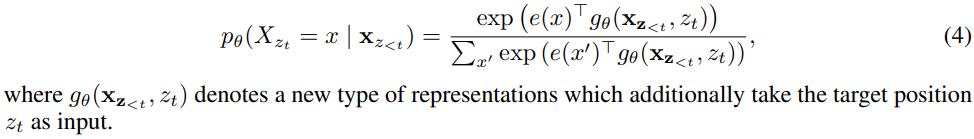
Two-Stream Self-Attention
为了解决标准transformer结构的矛盾,提出用两个集合的隐状态的表示来代替一个(双流注意力):


Partial Prediction
虽然排列语言建模目标有很多好处,但是如何优化它是一个问题,由于排列导致的收敛速度慢,为了减轻这个优化难题,我们选择仅预测因子顺序的最后一个token
我们把 z split成一个非目标子序列,和一个目标子序列,c是分割点
优化公式5

Incorporating Ideas from Transformer-XL
用sota自回归模型transformer-XL来作为我们的AR模型,并命名我们的模型,我们在Transformer-XL中整合了两项重要技术,即相对位置编码方案和分段循环机制

如何缓存之前的文本信息

Modeling Multiple Segments
跟BERT一样的建模方式,但是移除了NSP任务
Relative Segment Encodings
不同于BERT使用绝对位置编码,这里我们使用相对位置编码
给一对位置i和j,如果i和j属于同一个片段
we use a segment encoding s i j = s + s_{ij} = s_+ sij=s+ or otherwise s i j = s − s_{ij} = s_− sij=s−,这两者都是注意力头里面的可学习模型参数,换句话来说,我们只考虑两个位置是否属于同一片段
使用相对片段编码有两个好处:
- 归纳偏置促进泛化
- 打开了在fine-tune时候不仅有两个片段的可能性,用绝对位置编码是不可行的

Discussion
比较公式(2)和(5),我们发现BERT和XLNet都进行部分预测,即只预测序列中的一个子集的标记。这对BERT来说是一个必要的选择,因为如果所有的标记都被屏蔽了,就不可能做出任何有意义的预测。此外,对于BERT和XLNet来说,部分预测通过只预测具有足够上下文的标记,起到了降低优化难度的作用。然而,第2.1节中讨论的独立假设使BERT无法对目标之间的依赖性进行建模
为了更好地理解区别,让我们考虑一个具体的例子 [New, York, is, a, city]。假设BERT和XLNet都选择两个标记[New, York]作为预测目标,并最大化 l o g p ( N e w Y o r k ∣ i s a c i t y ) log p(New York | is a city) logp(NewYork∣isacity)。又假设XLNet对因子化顺序[is, a, city, New, York]进行采样。在这种情况下,BERT和XLNet分别简化为以下目标

Experiments
与BERT的公平比较

跟RoBERTa的比较




Conclusions
XLNet是一种广义的AR预训练方法,它采用了包络语言建模目标,结合了AR和AE方法的优点。XLNet的神经结构是为了与AR目标无缝衔接而开发的,包括整合Transformer-XL和双流注意机制的精心设计。与以前的预训练目标相比,XLNet在各种任务上取得了实质性的改进
Remark
XLNet打败了RoBERTa,RoBERTa打败了XLNet,这是什么左右互搏术吗?

