
- 1深入理解SOAP协议:基于XML的分布式通信协议
- 2北京大学&快手发布统一的图文视频生成大模型Video-LaVIT
- 3javaSE基础篇------String,StringBuffer,StringBuilder
- 4P8707 [蓝桥杯 2020 省 AB1] 走方格
- 5..." to discard change" href="/w/花生_TL007/article/detail/458084" target="_blank">Git之git checkout再理解及用法汇总_(use "git checkout --
..." to discard change - 6Windows下部署Appium教程(Android App自动化测试框架搭建)_appium-windows
- 7第二章 单片机的硬件结构_mcs51能够运行的最基本配置是什么
- 8基于Xtrabackup的mysql物理备份详解_xtrabackup --slave-info
- 9【数据结构】排序算法(三)—— 希尔排序_希尔排序法是怎么排的
- 10shiro反序列化检测工具_Shiro rememberMe反序列化攻击检测思路
【大数据开发运维解决方案】OGG实时同步Oracle数据到Kafka实施文档(供flink流式计算)_ogg kafka
赞
踩
GoldenGate12C For Bigdata+Kafka:通过OGG将Oracle数据以Json格式同步到Kafka提供给flink流式计算
注意:这篇文章告诉了大家怎么搭建OGG for bigdata做测试,但是实际生活中,因为这个文章中对于insert,delete,update均放到一个topic,在后期flink注册流表或则Kylin流式构建cube时候解析有问题(因为json结构不一致),现在给出本人实际flink开发过程中用到的oggfor bigdata配置文档OGG For Bigdata 12按操作类型同步Oracle数据到kafka不同topic
Oracle可以通过OGG for Bigdata将Oracle数据库数据实时增量同步至hadoop平台(kafka,hdfs等)进行消费,笔者搭建这个环境的目的是将Oracle数据库表通过OGG同步到kafka来提供给flink做流计算。这里介绍Oracle通过OGG for Bigdata将数据变更同步至kafka的详细实施过程,整个过程已经通过本人测试没问题。
主机规划与配置:
篇幅原因,Linux系统、源端Oracle数据库和源端OGG12C的软件安装在其他文档写了,这里不再赘述。

一、安装Zookeeper集群
1、安装JDK(目的端操作)
之前安装的jdk1.7,1.7版本jdk在启replicat 进程时由于jdk版本问题导致进程abend,OGG For Bigdata12.3不支持1.7。具体报错详见:四、安装过程遇到的错误
1.1、先看下当前环境是否有安装的jdk
[root@zookeeper ~]# rpm -qa | grep java
java-1.7.0-openjdk-1.7.0.99-2.6.5.1.0.1.el6.x86_64
tzdata-java-2016c-1.el6.noarch
java-1.6.0-openjdk-1.6.0.38-1.13.10.4.el6.x86_64
[root@zookeeper ~]# rpm -qa | grep jdk
java-1.7.0-openjdk-1.7.0.99-2.6.5.1.0.1.el6.x86_64
java-1.6.0-openjdk-1.6.0.38-1.13.10.4.el6.x86_64
[root@zookeeper ~]# rpm -qa | grep gcj
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
1.2、删除Linux自带的jdk
[root@zookeeper ~]# rpm -e --nodeps java-1.7.0-openjdk-1.7.0.99-2.6.5.1.0.1.el6.x86_64
[root@zookeeper ~]# rpm -e --nodeps tzdata-java-2016c-1.el6.noarch
[root@zookeeper ~]# rpm -e java-1.6.0-openjdk-1.6.0.38-1.13.10.4.el6.x86_64
[root@zookeeper ~]# rpm -e java-1.7.0-openjdk-1.7.0.99-2.6.5.1.0.1.el6.x86_64
- 1
- 2
- 3
- 4
1.3、检查是否还存在linuk自带jdk
[root@zookeeper ~]# rpm -qa | grep java
[root@zookeeper ~]# rpm -qa | grep jdk
[root@zookeeper ~]# rpm -qa | grep gcj
已经不存在了
- 1
- 2
- 3
- 4
1.4、创建jdk目录
[root@zookeeper ~]# mkdir -p /usr/java
- 1
1.5、上传并解压jdk到此目录
[root@zookeeper ~]# cd /usr/java/
[root@zookeeper java]# ls
jdk-8u151-linux-x64.tar.gz
[root@zookeeper java]# tar -zxvf jdk-8u151-linux-x64.tar.gz
[root@zookeeper java]# rm -rf jdk-8u151-linux-x64.tar.gz
[root@zookeeper java]# ls
jdk1.8.0_151
- 1
- 2
- 3
- 4
- 5
- 6
- 7
1.6、编辑/etc/profile
[root@zookeeper java]# vim /etc/profile
写入下面jdk环境变量,保存退出
export JAVA_HOME=/usr/java/jdk1.8.0_151
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
使环境变量生效
[root@zookeeper java]# source /etc/profile
- 1
- 2
- 3
- 4
- 5
- 6
- 7
1.7、检查jdk是否配置成功
[root@zookeeper java]# java -version
java version "1.8.0_151"
Java(TM) SE Runtime Environment (build 1.8.0_151-b12)
Java HotSpot(TM) 64-Bit Server VM (build 25.151-b12, mixed mode)
配置没问题
- 1
- 2
- 3
- 4
- 5
2、安装Zookeeper集群 (目的端操作)
这里安装方式采用在一台机器上部署一套三节点(官方推荐最少三节点)的伪集群,后面的zookeeper、kafka、ogg for bigdata软件均放在/kafka目录下
2.1、创建软件存放目录
[root@zookeeper java]# mkdir /kafka
[root@zookeeper java]# chown -R oracle:oinstall /kafka/
[root@zookeeper java]# chmod -R 777 /kafka/
- 1
- 2
- 3
2.2、创建3个Zk server的集群安装目录
[root@zookeeper java]# mkdir -p /kafka/zookeeper/zookeeper1
[root@zookeeper java]# mkdir -p /kafka/zookeeper/zookeeper2
[root@zookeeper java]# mkdir -p /kafka/zookeeper/zookeeper3
- 1
- 2
- 3
2.3、上传解压zookeeper软件到三个目录
先上传文件并解压到第一个目录,cd /kafka/zookeeper/zookeeper1/做下面操作
[root@zookeeper zookeeper1]# tar -zxvf zookeeper-3.4.6.tar.gz
[root@zookeeper zookeeper1]# rm -rf zookeeper-3.4.6.tar.gz
[root@zookeeper zookeeper1]# mv zookeeper-3.4.6/* .
[root@zookeeper zookeeper1]# ls
bin CHANGES.txt contrib docs ivy.xml LICENSE.txt README_packaging.txt recipes zookeeper-3.4.6 zookeeper-3.4.6.jar.asc zookeeper-3.4.6.jar.sha1
build.xml conf dist-maven ivysettings.xml lib NOTICE.txt README.txt src zookeeper-3.4.6.jar zookeeper-3.4.6.jar.md5
另外两个目录的zookeeper软件可以通过第一个目录进行copy就可
[root@zookeeper zookeeper1]# cp -rp * /kafka/zookeeper/zookeeper2/
[root@zookeeper zookeeper1]# cp -rp * /kafka/zookeeper/zookeeper3/
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
2.4、创建日志目录
创建快照日志存放目录:
mkdir -p /kafka/zookeeper/zookeeper1/dataDir
mkdir -p /kafka/zookeeper/zookeeper2/dataDir
mkdir -p /kafka/zookeeper/zookeeper3/dataDir
创建事务日志存放目录:
mkdir -p /kafka/zookeeper/zookeeper1/dataLogDir
mkdir -p /kafka/zookeeper/zookeeper2/dataLogDir
mkdir -p /kafka/zookeeper/zookeeper3/dataLogDir
【注意】:如果不配置dataLogDir,那么事务日志也会写在dataDir目录中。这样会严重影响zk的性能。因为在zk吞吐量很高的时候,产生的事务日志和快照日志太多。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.5、修改/etc/hosts
修改/etc/hosts内容如下
127.0.0.1 localhost
192.168.1.21 zookeeper
192.168.1.21 zookeeper1
192.168.1.21 zookeeper2
192.168.1.21 zookeeper3
- 1
- 2
- 3
- 4
- 5
- 6
2.6、修改zookeeper配置文件
server1配置如下:
[root@zookeeper ~]# cd /kafka/zookeeper/zookeeper1/conf/
[root@zookeeper conf]# ls
configuration.xsl log4j.properties zoo_sample.cfg
[root@zookeeper conf]# mv zoo_sample.cfg zoo.cfg
[root@zookeeper conf]# vim zoo.cfg
配置内容如下:
[root@zookeeper conf]# cat zoo.cfg |grep -v ^#|grep -v ^$
tickTime=2000
initLimit=10
syncLimit=5
clientPort=2181
dataDir=/kafka/zookeeper/zookeeper1/dataDir
dataLogDir=/kafka/zookeeper/zookeeper1/dataLogDir
server.1=zookeeper1:2887:3887
server.2=zookeeper2:2888:3888
server.3=zookeeper3:2889:3889
server2配置文件内容如下:
[root@zookeeper conf]# cat /kafka/zookeeper/zookeeper2/conf/zoo.cfg |grep -v ^#|grep -v ^$
tickTime=2000
initLimit=10
syncLimit=5
clientPort=2182
dataDir=/kafka/zookeeper/zookeeper2/dataDir
dataLogDir=/kafka/zookeeper/zookeeper2/dataLogDir
server.1=zookeeper1:2887:3887
server.2=zookeeper2:2888:3888
server.3=zookeeper3:2889:3889
server3配置文件内容如下:
[root@zookeeper conf]# cat /kafka/zookeeper/zookeeper3/conf/zoo.cfg |grep -v ^#|grep -v ^$
tickTime=2000
initLimit=10
syncLimit=5
clientPort=2183
dataDir=/kafka/zookeeper/zookeeper3/dataDir
dataLogDir=/kafka/zookeeper/zookeeper3/dataLogDir
server.1=zookeeper1:2887:3887
server.2=zookeeper2:2888:3888
server.3=zookeeper3:2889:3889
在我们配置的dataDir指定的目录下面,创建一个myid文件,里面内容为一个数字,用来标识当前主机,conf/zoo.cfg文件中配置的server.X中X为什么数字,则myid文件中就输入这个数字:
[root@zookeeper conf]# echo "1" > /kafka/zookeeper/zookeeper1/dataDir/myid
[root@zookeeper conf]# echo "2" > /kafka/zookeeper/zookeeper2/dataDir/myid
[root@zookeeper conf]# echo "3" > /kafka/zookeeper/zookeeper3/dataDir/myid
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
2.7、关闭防火墙
关闭防火墙并禁止开机自启:
service iptables stop
sudo chkconfig iptables off
- 1
- 2
- 3
2.8、启动zookeeper集群
[root@zookeeper bin]# /kafka/zookeeper/zookeeper1/bin/zkServer.sh start
JMX enabled by default
Using config: /kafka/zookeeper/zookeeper1/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
这里虽然显示启动了,但是来看一下启动日志:
[root@zookeeper bin]# tail -f zookeeper.out
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:339)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:200)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:182)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:579)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectOne(QuorumCnxManager.java:368)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectAll(QuorumCnxManager.java:402)
at org.apache.zookeeper.server.quorum.FastLeaderElection.lookForLeader(FastLeaderElection.java:840)
at org.apache.zookeeper.server.quorum.QuorumPeer.run(QuorumPeer.java:762)
2018-12-11 16:58:26,328 [myid:1] - INFO [QuorumPeer[myid=1]/0:0:0:0:0:0:0:0:2181:FastLeaderElection@849] - Notification time out: 3200
2018-12-11 16:58:29,530 [myid:1] - WARN [QuorumPeer[myid=1]/0:0:0:0:0:0:0:0:2181:QuorumCnxManager@382] - Cannot open channel to 2 at election address zookeeper2/192.168.1.21:3888
java.net.ConnectException: Connection refused
at java.net.PlainSocketImpl.socketConnect(Native Method)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:339)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:200)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:182)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:579)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectOne(QuorumCnxManager.java:368)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectAll(QuorumCnxManager.java:402)
at org.apache.zookeeper.server.quorum.FastLeaderElection.lookForLeader(FastLeaderElection.java:840)
at org.apache.zookeeper.server.quorum.QuorumPeer.run(QuorumPeer.java:762)
2018-12-11 16:58:29,531 [myid:1] - WARN [QuorumPeer[myid=1]/0:0:0:0:0:0:0:0:2181:QuorumCnxManager@382] - Cannot open channel to 3 at election address zookeeper3/192.168.1.21:3889
java.net.ConnectException: Connection refused
at java.net.PlainSocketImpl.socketConnect(Native Method)
at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:339)
at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:200)
at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:182)
at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
at java.net.Socket.connect(Socket.java:579)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectOne(QuorumCnxManager.java:368)
at org.apache.zookeeper.server.quorum.QuorumCnxManager.connectAll(QuorumCnxManager.java:402)
at org.apache.zookeeper.server.quorum.FastLeaderElection.lookForLeader(FastLeaderElection.java:840)
at org.apache.zookeeper.server.quorum.QuorumPeer.run(QuorumPeer.java:762)
2018-12-11 16:58:29,531 [myid:1] - INFO [QuorumPeer[myid=1]/0:0:0:0:0:0:0:0:2181:FastLeaderElection@849] - Notification time out: 6400
查看日志,发现日志报错,报错内容为myid=1的节点不能连接到2和3节点,这里不用管,只要启动集群另外其他节点就可正常,直接继续手动启动节点二和节点三:
[root@zookeeper bin]# /kafka/zookeeper/zookeeper2/bin/zkServer.sh start
JMX enabled by default
Using config: /kafka/zookeeper/zookeeper2/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[root@zookeeper bin]# /kafka/zookeeper/zookeeper3/bin/zkServer.sh start
JMX enabled by default
Using config: /kafka/zookeeper/zookeeper3/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
节点二和节点三都起来之后,再去看节点一的日志:
[root@zookeeper bin]# tail -f zookeeper.out
2018-12-11 16:58:41,828 [myid:3] - INFO [QuorumPeer[myid=3]/0:0:0:0:0:0:0:0:2183:FileTxnSnapLog@240] - Snapshotting: 0x100000000 to /kafka/zookeeper/zookeeper3/dataDir/version-2/snapshot.1
000000002018-12-11 16:58:41,717 [myid:2] - INFO [zookeeper2/192.168.1.21:3888:QuorumCnxManager$Listener@511] - Received connection request /192.168.1.21:38969
2018-12-11 16:58:41,729 [myid:2] - INFO [WorkerReceiver[myid=2]:FastLeaderElection@597] - Notification: 1 (message format version), 3 (n.leader), 0x0 (n.zxid), 0x1 (n.round), LOOKING (n.st
ate), 3 (n.sid), 0x0 (n.peerEpoch) LEADING (my state)2018-12-11 16:58:41,761 [myid:2] - INFO [LearnerHandler-/192.168.1.21:49909:LearnerHandler@330] - Follower sid: 3 : info : org.apache.zookeeper.server.quorum.QuorumPeer$QuorumServer@7399ae
792018-12-11 16:58:41,802 [myid:2] - INFO [LearnerHandler-/192.168.1.21:49909:LearnerHandler@385] - Synchronizing with Follower sid: 3 maxCommittedLog=0x0 minCommittedLog=0x0 peerLastZxid=0x
02018-12-11 16:58:41,802 [myid:2] - INFO [LearnerHandler-/192.168.1.21:49909:LearnerHandler@462] - Sending SNAP
2018-12-11 16:58:41,802 [myid:2] - INFO [LearnerHandler-/192.168.1.21:49909:LearnerHandler@486] - Sending snapshot last zxid of peer is 0x0 zxid of leader is 0x100000000sent zxid of db as
0x1000000002018-12-11 16:58:41,831 [myid:2] - INFO [LearnerHandler-/192.168.1.21:49909:LearnerHandler@522] - Received NEWLEADER-ACK message from 3
2018-12-11 16:58:41,707 [myid:1] - INFO [zookeeper1/192.168.1.21:3887:QuorumCnxManager$Listener@511] - Received connection request /192.168.1.21:57295
2018-12-11 16:58:41,716 [myid:1] - INFO [WorkerReceiver[myid=1]:FastLeaderElection@597] - Notification: 1 (message format version), 3 (n.leader), 0x0 (n.zxid), 0x1 (n.round), LOOKING (n.st
ate), 3 (n.sid), 0x0 (n.peerEpoch) FOLLOWING (my state)
发现此时三个节点都通了,最后的状态为 FOLLOWING (my state),说明集群正常起来了。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
2.9、Zookeeper集群状态查看方式
可以通过命令jps查看Zookeeper进程:
[root@zookeeper bin]# jps
28216 QuorumPeerMain
28286 QuorumPeerMain
28356 Jps
28245 QuorumPeerMain
为了日后操作方便,决定手动编写zookeeper集群启动关闭脚本:
[root@zookeeper zookeeper]# pwd
/kafka/zookeeper
[root@zookeeper zookeeper]# cat startzookeeper.sh
#! /bin/bash
/kafka/zookeeper/zookeeper1/bin/zkServer.sh start
/kafka/zookeeper/zookeeper2/bin/zkServer.sh start
/kafka/zookeeper/zookeeper3/bin/zkServer.sh start
tail -f /kafka/zookeeper/zookeeper1/bin/zookeeper.out
[root@zookeeper zookeeper]# cat stopzookeeper.sh
#! /bin/bash
/kafka/zookeeper/zookeeper1/bin/zkServer.sh stop
/kafka/zookeeper/zookeeper2/bin/zkServer.sh stop
/kafka/zookeeper/zookeeper3/bin/zkServer.sh stop
tail -f /kafka/zookeeper/zookeeper1/bin/zookeeper.out
[root@hadoop zookeeper]# cat statuszookeeper.sh
#! /bin/bash
/hadoop/zookeeper/zookeeper1/bin/zkServer.sh status
/hadoop/zookeeper/zookeeper2/bin/zkServer.sh status
/hadoop/zookeeper/zookeeper3/bin/zkServer.sh status
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
2.10、测试zookeeper集群健康状态
可以通过ZooKeeper的脚本来查看启动状态,包括集群中各个结点的角色(或是Leader,或是Follower)
[root@zookeeper zookeeper]# /kafka/zookeeper/zookeeper1/bin/zkServer.sh status
JMX enabled by default
Using config: /kafka/zookeeper/zookeeper1/bin/../conf/zoo.cfg
Mode: follower
[root@zookeeper zookeeper]# /kafka/zookeeper/zookeeper2/bin/zkServer.sh status
JMX enabled by default
Using config: /kafka/zookeeper/zookeeper2/bin/../conf/zoo.cfg
Mode: leader
[root@zookeeper zookeeper]# /kafka/zookeeper/zookeeper3/bin/zkServer.sh status
JMX enabled by default
Using config: /kafka/zookeeper/zookeeper3/bin/../conf/zoo.cfg
Mode: follower
通过上面状态查询结果可见,节点二是集群的Leader,其余的两个结点是Follower。
另外,可以通过客户端脚本,连接到ZooKeeper集群上。对于客户端来说,ZooKeeper是一个整体,连接到ZooKeeper集群实际上感觉在独享整个集群的服务,所以,你可以在任何一个结点上建立到服务集群的连接。
[root@zookeeper zookeeper]# /kafka/zookeeper/zookeeper1/bin/zkCli.sh -server localhost:2181
Connecting to localhost:2181
2018-12-11 17:13:21,760 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.6-1569965, built on 02/20/2014 09:09 GMT
2018-12-11 17:13:21,764 [myid:] - INFO [main:Environment@100] - Client environment:host.name=<NA>
2018-12-11 17:13:21,765 [myid:] - INFO [main:Environment@100] - Client environment:java.version=1.7.0_80
2018-12-11 17:13:21,768 [myid:] - INFO [main:Environment@100] - Client environment:java.vendor=Oracle Corporation
2018-12-11 17:13:21,769 [myid:] - INFO [main:Environment@100] - Client environment:java.home=/usr/java/jdk1.7.0_80/jre
2018-12-11 17:13:21,769 [myid:] - INFO [main:Environment@100] - Client environment:java.class.path=/kafka/zookeeper/zookeeper1/bin/../build/classes:/kafka/zookeeper/zookeeper1/bin/../build
/lib/*.jar:/kafka/zookeeper/zookeeper1/bin/../lib/slf4j-log4j12-1.6.1.jar:/kafka/zookeeper/zookeeper1/bin/../lib/slf4j-api-1.6.1.jar:/kafka/zookeeper/zookeeper1/bin/../lib/netty-3.7.0.Final.jar:/kafka/zookeeper/zookeeper1/bin/../lib/log4j-1.2.16.jar:/kafka/zookeeper/zookeeper1/bin/../lib/jline-0.9.94.jar:/kafka/zookeeper/zookeeper1/bin/../zookeeper-3.4.6.jar:/kafka/zookeeper/zookeeper1/bin/../src/java/lib/*.jar:/kafka/zookeeper/zookeeper1/bin/../conf:.:/usr/java/jdk1.7.0_80/lib/dt.jar:/usr/java/jdk1.7.0_80/lib/tools.jar2018-12-11 17:13:21,770 [myid:] - INFO [main:Environment@100] - Client environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib
2018-12-11 17:13:21,770 [myid:] - INFO [main:Environment@100] - Client environment:java.io.tmpdir=/tmp
2018-12-11 17:13:21,770 [myid:] - INFO [main:Environment@100] - Client environment:java.compiler=<NA>
2018-12-11 17:13:21,771 [myid:] - INFO [main:Environment@100] - Client environment:os.name=Linux
2018-12-11 17:13:21,771 [myid:] - INFO [main:Environment@100] - Client environment:os.arch=amd64
2018-12-11 17:13:21,771 [myid:] - INFO [main:Environment@100] - Client environment:os.version=4.1.12-37.4.1.el6uek.x86_64
2018-12-11 17:13:21,772 [myid:] - INFO [main:Environment@100] - Client environment:user.name=root
2018-12-11 17:13:21,772 [myid:] - INFO [main:Environment@100] - Client environment:user.home=/root
2018-12-11 17:13:21,773 [myid:] - INFO [main:Environment@100] - Client environment:user.dir=/kafka/zookeeper
2018-12-11 17:13:21,775 [myid:] - INFO [main:ZooKeeper@438] - Initiating client connection, connectString=localhost:2181 sessionTimeout=30000 watcher=org.apache.zookeeper.ZooKeeperMain$MyW
atcher@49134043Welcome to ZooKeeper!
2018-12-11 17:13:21,821 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@975] - Opening socket connection to server localhost/127.0.0.1:2181. Will not attempt to authe
nticate using SASL (unknown error)2018-12-11 17:13:21,843 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@852] - Socket connection established to localhost/127.0.0.1:2181, initiating session
JLine support is enabled
[zk: localhost:2181(CONNECTING) 0] 2018-12-11 17:13:21,996 [myid:] - INFO [main-SendThread(localhost:2181):ClientCnxn$SendThread@1235] - Session establishment complete on server localhost/
127.0.0.1:2181, sessionid = 0x1679c86f3d50000, negotiated timeout = 30000
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: localhost:2181(CONNECTED) 0]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
二、安装Kafka
1.1、创建kafka安装目录上传并解压
[root@zookeeper ~]# mkdir /kafka/kafka
[root@zookeeper ~]# cd /kafka/kafka/
[root@zookeeper kafka]# ls
kafka_2.11-1.1.1.tgz
[root@zookeeper kafka]# tar zxf kafka_2.11-1.1.1.tgz
[root@zookeeper kafka]# ls
kafka_2.11-1.1.1 kafka_2.11-1.1.1.tgz
[root@zookeeper kafka]# rm -rf kafka_2.11-1.1.1.tgz
[root@zookeeper kafka]# ls
kafka_2.11-1.1.1
[root@zookeeper kafka]# mv kafka_2.11-1.1.1/* .
[root@zookeeper kafka]# rm -rf kafka_2.11-1.1.1
[root@zookeeper kafka]# ls
bin config libs LICENSE NOTICE site-docs
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
1.2、修改配置文件
[root@zookeeper config]# pwd
/kafka/kafka/config
[root@zookeeper config]# vim server.properties
修改内容如如下:
[root@zookeeper config]# cat server.properties |grep -v ^#|grep -v ^$
broker.id=0
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/kafka/kafka/logs
num.partitions=1
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=1073741824
log.retention.check.interval.ms=300000
zookeeper.connect=localhost:2181,localhost:2182,localhost:2183
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
delete.topic.enble=true -----如果不指定这个参数,执行删除操作只是标记删除
auto.create.topics.enable=true -----此参数可以考虑是否添加,如果不添加,在kafka.props中配置的topicname在启动应用进程前必须手动创建好,详细分析见:四、安装过程遇到的错误
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
1.3、启动kafka
在保证zookeeper集群没问题的前提下启动:
[root@zookeeper kafka]# nohup bin/kafka-server-start.sh config/server.properties&
如果nohup.out 无报错则说明启动成功。
- 1
- 2
- 3
1.4、 功能测试
创建一个topic
[root@zookeeper bin]# pwd
/kafka/kafka/bin
[root@zookeeper bin]# ./kafka-topics.sh --create --zookeeper zookeeper1:2181 --replication-factor 1 --partitions 1 --topic tests
Created topic "tests".
查看创建的topic
[root@zookeeper bin]# ./kafka-topics.sh -describe -zookeeper zookeeper1:2181
Topic:tests PartitionCount:1 ReplicationFactor:1 Configs:
Topic: tests Partition: 0 Leader: 0 Replicas: 0 Isr: 0
打开2个终端, 分别在Kafka目录执行以下命令
会话1:
[root@zookeeper bin]# ./kafka-console-producer.sh --broker-list localhost:9092 --topic tests
>
会话2:
[root@zookeeper bin]# ./kafka-console-consumer.sh --zookeeper localhost:2181 --topic tests --from-beginning
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper]
.
会话1输入消息:
[root@zookeeper bin]# ./kafka-console-producer.sh --broker-list localhost:9092 --topic tests
>zhaoyandong
>
会话2显示消息:
[root@zookeeper bin]# ./kafka-console-consumer.sh --zookeeper localhost:2181 --topic tests --from-beginning
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper]
.zhaoyandong
测试可以正常生产和消费。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
三、安装配置OGG12C For bigdata
1、上传并解压安装OGG for bigdata 软件
1.1、创建ogg软件安装目录
[root@zookeeper ~]# cd /kafka/
[root@zookeeper kafka]# mkdir ogg12
解压缩:
[root@zookeeper kafka]# ls
kafka ogg12 zookeeper
[root@zookeeper kafka]# cd ogg12/
[root@zookeeper ogg12]# unzip OGG_BigData_Linux_x64_12.3.2.1.1.zip
Archive: OGG_BigData_Linux_x64_12.3.2.1.1.zip
inflating: OGGBD-12.3.2.1-README.txt
inflating: OGG_BigData_12.3.2.1.1_Release_Notes.pdf
inflating: OGG_BigData_Linux_x64_12.3.2.1.1.tar
[root@zookeeper ogg12]# ls
OGGBD-12.3.2.1-README.txt OGG_BigData_12.3.2.1.1_Release_Notes.pdf OGG_BigData_Linux_x64_12.3.2.1.1.tar OGG_BigData_Linux_x64_12.3.2.1.1.zip
[root@zookeeper ogg12]# rm -rf OGG_BigData_Linux_x64_12.3.2.1.1.zip
[root@zookeeper ogg12]# tar xf OGG_BigData_Linux_x64_12.3.2.1.1.tar
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
1.2、配置环境变量
[root@zookeeper ~]# cat .bash_profile -----之前使用的jdk1.7后来启动应用进程时报错,现在配置为正确配置,之前错误详见后面实施过程中遇到的问题
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/bin
export PATH
export JAVA_HOME=/usr/java/jdk1.8.0_151
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
export GGHOME=/kafka/ogg12
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$JAVA_HOME/jre/lib/amd64/libjsig.so:$JAVA_HOME/jre/lib/amd64/server/libjvm.so:$JAVA_HOME/jre/lib/amd64/server:$JAVA_HOME/jre/lib/amd64:$GG_HOME:/lib
测试一下环境变量有没有问题:
[root@zookeeper ~]# cd /kafka/ogg12/
[root@zookeeper ogg12]# ./ggsci
Oracle GoldenGate for Big Data
Version 12.3.2.1.1 (Build 005)
Oracle GoldenGate Command Interpreter
Version 12.3.0.1.2 OGGCORE_OGGADP.12.3.0.1.2_PLATFORMS_180712.2305
Linux, x64, 64bit (optimized), Generic on Jul 13 2018 00:46:09
Operating system character set identified as UTF-8.
Copyright (C) 1995, 2018, Oracle and/or its affiliates. All rights reserved.
GGSCI (zookeeper) 1> info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER STOPPED
没问题。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
1.3、初始化目录
GGSCI (zookeeper) 2> create subdirs
Creating subdirectories under current directory /kafka/ogg12
Parameter file /kafka/ogg12/dirprm: created.
Report file /kafka/ogg12/dirrpt: created.
Checkpoint file /kafka/ogg12/dirchk: created.
Process status files /kafka/ogg12/dirpcs: created.
SQL script files /kafka/ogg12/dirsql: created.
Database definitions files /kafka/ogg12/dirdef: created.
Extract data files /kafka/ogg12/dirdat: created.
Temporary files /kafka/ogg12/dirtmp: created.
Credential store files /kafka/ogg12/dircrd: created.
Masterkey wallet files /kafka/ogg12/dirwlt: created.
Dump files /kafka/ogg12/dirdmp: created.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
1.4、配置MGR进程
编辑MGR进程
GGSCI (zookeeper) 5> edit params mgr
写入下面内容
PORT 7809
DYNAMICPORTLIST 7810-7860
AUTORESTART ER *, RETRIES 3, WAITMINUTES 5
PURGEOLDEXTRACTS ./dirdat/*, USECHECKPOINTS, MINKEEPDAYS 30
lagreporthours 1
laginfominutes 30
lagcriticalminutes 60
启动mgr进程
GGSCI (zookeeper) 7> start mgr
Manager started.
GGSCI (zookeeper) 8> info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
2、源端创建测试用表:
在scott下创建测试表kafka:
create table KAFKA
(
empno NUMBER(4) not null,
ename VARCHAR2(10),
job VARCHAR2(9),
mgr NUMBER(4),
hiredate DATE,
sal NUMBER(7,2),
comm NUMBER(7,2),
deptno NUMBER(2)
);
alter table KAFKA
add constraint PK_KAFKA primary key (EMPNO);
插入测试数据:
insert into kafka select * from emp where sal is not null;
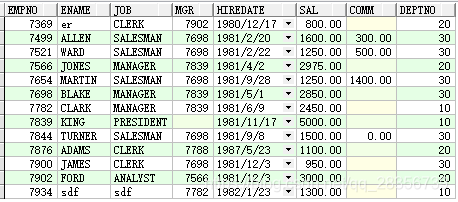
select * from kafka;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
3、源端增加配置管理、抽取、投递进程
3.1、添加kafka表附加日志
GGSCI (source) 5> dblogin userid ogg password ogg
Successfully logged into database.
GGSCI (source as ogg@orcl) 6> add trandata scott.kafka
TRANDATA for instantiation CSN has been added on table 'SCOTT.KAFKA'.
GGSCI (source as ogg@orcl) 7> add trandata scott.kafka
GGSCI (source as ogg@orcl) 8> info trandata scott.kafka
Logging of supplemental redo log data is enabled for table SCOTT.KAFKA.
Columns supplementally logged for table SCOTT.KAFKA: EMPNO.
Prepared CSN for table SCOTT.KAFKA: 1432176
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3.2、配置OGG的全局变量
GGSCI (source as ogg@orcl) 6> edit param ./globals
加入下面内容:
oggschema ogg
- 1
- 2
- 3
3.3、配置MGR进程
GGSCI (source) 1> edit params mgr
PORT 7809
DYNAMICPORTLIST 7810-7860
AUTORESTART ER *, RETRIES 3, WAITMINUTES 5
PURGEOLDEXTRACTS ./dirdat/*, USECHECKPOINTS, MINKEEPDAYS 30
lagreporthours 1
laginfominutes 30
lagcriticalminutes 60
启动mgr进程
GGSCI (source as ogg@orcl) 37> start mgr
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.4、编辑抽取进程
GGSCI (source) 2> edit params e_ka
extract e_ka
userid ogg,password ogg
setenv(NLS_LANG=AMERICAN_AMERICA.AL32UTF8)
setenv(ORACLE_SID="orcl")
reportcount every 30 minutes,rate
numfiles 5000
discardfile ./dirrpt/e_ka.dsc,append,megabytes 1000
warnlongtrans 2h,checkinterval 30m
exttrail ./dirdat/ka
dboptions allowunusedcolumn
tranlogoptions archivedlogonly
tranlogoptions altarchivelogdest primary /u01/arch
dynamicresolution
fetchoptions nousesnapshot
ddl include mapped
ddloptions addtrandata,report
notcpsourcetimer
NOCOMPRESSDELETES
NOCOMPRESSUPDATES
GETUPDATEBEFORES
----------scott.kafka
table SCOTT.KAFKA,tokens(
TKN-CSN = @GETENV('TRANSACTION', 'CSN'),
TKN-COMMIT-TS = @GETENV ('GGHEADER', 'COMMITTIMESTAMP'),
TKN-OP-TYPE = @GETENV ('GGHEADER', 'OPTYPE')
);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
3.5、添加抽取进程
GGSCI (source as ogg@orcl) 7> add extract e_ka,tranlog,begin now
EXTRACT added.
GGSCI (source as ogg@orcl) 9> add exttrail ./dirdat/ka,extract e_ka,megabytes 500
EXTTRAIL added.
启动抽取进程
GGSCI (source as ogg@orcl) 10>start e_ka
- 1
- 2
- 3
- 4
- 5
- 6
3.6、投递进程配置
GGSCI (source as ogg@orcl) 27> edit params d_ka
加入下面配置
extract d_ka
rmthost 192.168.1.21,mgrport 7809,compress
userid ogg,password ogg
PASSTHRU
numfiles 5000
rmttrail ./dirdat/ka
dynamicresolution
table scott.kafka;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.7、添加投递进程
GGSCI (source as ogg@orcl) 29> add extract d_ka,exttrailsource ./dirdat/ka
EXTRACT added.
GGSCI (source as ogg@orcl) 30> add rmttrail ./dirdat/ka,extract d_ka,megabytes 500
RMTTRAIL added.
启动投递进程
GGSCI (source as ogg@orcl) 38> start d_ka
- 1
- 2
- 3
- 4
- 5
- 6
4、表结构定义文件
4.1、defgen配置
GGSCI (source) 3> edit params test_kafka
defsfile /u01/app/oracle/ogg12/dirdef/kafka.def
userid ogg,password ogg
table scott.kafka;
- 1
- 2
- 3
- 4
- 5
4.2、生成表结构定义文件
[oracle@source ogg12]$ pwd
/u01/app/oracle/ogg12
[oracle@source ogg12]$ ./defgen paramfile dirprm/test_kafka.prm
***********************************************************************
Oracle GoldenGate Table Definition Generator for Oracle
Version 12.2.0.2.2 OGGCORE_12.2.0.2.0_PLATFORMS_170630.0419
Linux, x64, 64bit (optimized), Oracle 11g on Jun 30 2017 11:35:56
Copyright (C) 1995, 2017, Oracle and/or its affiliates. All rights reserved.
Starting at 2018-12-14 13:44:52
***********************************************************************
Operating System Version:
Linux
Version #2 SMP Tue May 17 07:23:38 PDT 2016, Release 4.1.12-37.4.1.el6uek.x86_64
Node: source
Machine: x86_64
soft limit hard limit
Address Space Size : unlimited unlimited
Heap Size : unlimited unlimited
File Size : unlimited unlimited
CPU Time : unlimited unlimited
Process id: 5928
***********************************************************************
** Running with the following parameters **
***********************************************************************
defsfile /u01/app/oracle/ogg12/dirdef/kafka.def
userid ogg,password ***
table scott.kafka;
Retrieving definition for SCOTT.KAFKA.
Definitions generated for 1 table in /u01/app/oracle/ogg12/dirdef/kafka.def.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
4.3、将生成的表定义文件发送到目标端
scp /u01/app/oracle/ogg12/dirdef/kafka.def root@192.168.1.21:/kafka/ogg12/dirdef/
- 1
5、OGG for bigdata 端配置
5.1、添加checkpoint表
在确保zookeeper集群和kafka正常的情况下做下面配置:
checkpoint即复制可追溯的一个偏移量记录,在全局配置里添加checkpoint表即可。
edit param ./GLOBALS
CHECKPOINTTABLE ogg.checkpoint
- 1
- 2
- 3
- 4
5.2、配置replicate进程
GGSCI (zookeeper) 5> edit params rkafka
REPLICAT rkafka
-- Trail file for this example is located in "AdapterExamples/trail" directory
-- Command to add REPLICAT
-- add replicat rkafka, exttrail AdapterExamples/trail/tr
TARGETDB LIBFILE libggjava.so SET property=dirprm/kafka.props
REPORTCOUNT EVERY 1 MINUTES, RATE
GROUPTRANSOPS 10000
GETUPDATEBEFORES ----12.3版本要加此参数,若不加,在普通update时,即便抽取进程加了GETUPDATEBEFORES等参数,kafka表中的被修改字段修改前的值也不会被写入,11G版本不需要此参数亦可,详情看后面实施过程遇到的错误列表
MAP SCOTT.*, TARGET SCOTT.*;
说明:REPLICATE rkafka定义rep进程名称;sourcedefs即在4.6中在源服务器上做的表映射文件;TARGETDB LIBFILE即定义kafka一些适配性的库文件以及配置文件,配置文件位于OGG主目录下的dirprm/kafka.props;REPORTCOUNT即复制任务的报告生成频率;GROUPTRANSOPS为以事务传输时,事务合并的单位,减少IO操作;MAP即源端与目标端的映射关系
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
5.3、配置custom_kafka_producer.properties
[root@zookeeper ogg12]# cd dirprm/
[root@zookeeper dirprm]# pwd
/kafka/ogg12/dirprm
[root@zookeeper dirprm]# vim custom_kafka_producer.properties
bootstrap.servers=localhost:9092
acks=1
reconnect.backoff.ms=1000
value.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
key.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
# 100KB per partition
batch.size=102400
linger.ms=10000
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
5.4、配置kafka.props
[root@zookeeper dirprm]# pwd
/kafka/ogg12/dirprm
[root@zookeeper dirprm]# vim kafka.props
写入下面内容
gg.handlerlist = kafkahandler
gg.handler.kafkahandler.type=kafka
gg.handler.kafkahandler.KafkaProducerConfigFile=custom_kafka_producer.properties
#The following resolves the topic name using the short table name
gg.handler.kafkahandler.topicMappingTemplate=kafka
#The following selects the message key using the concatenated primary keys
#gg.handler.kafkahandler.keyMappingTemplate=${primaryKeys}
gg.handler.kafkahandler.format=json
gg.handler.kafkahandler.SchemaTopicName=scott
gg.handler.kafkahandler.BlockingSend =true
gg.handler.kafkahandler.includeTokens=false
gg.handler.kafkahandler.mode=op
gg.handler.kafkahandler.format.includePrimaryKeys=true
goldengate.userexit.writers=javawriter
javawriter.stats.display=TRUE
javawriter.stats.full=TRUE
gg.log=log4j
gg.log.level=INFO
gg.report.time=30sec
#Sample gg.classpath for Apache Kafka
gg.classpath=dirprm/:/kafka/kafka/libs/*:/kafka/ogg12/:/kafka/ogg12/lib/*
#Sample gg.classpath for HDP
#gg.classpath=/etc/kafka/conf:/usr/hdp/current/kafka-broker/libs/*
javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=ggjava/ggjava.jar
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
5.5、添加应用进程
add replicat rkafka,exttrail ./dirdat/ka
--默认是从ka00000开始读取, 如果需要修改应用进程读物位置可以执行:alter rkafka extseqno 3 extrba 1123
启动应用进程:
GGSCI (zookeeper) 4> start rkafka
- 1
- 2
- 3
- 4
6、验证数据同步
源端对表kafka做insert、普通update、主键+普通列一起修改的PK Update操作并切换归档:
SQL> insert into kafka(empno,ename)values(321,'aa');
1 row created.
SQL> commit;
Commit complete.
SQL> update kafka set ename='ggg' where empno=321;
1 row updated.
SQL> commit;
Commit complete.
SQL> update kafka set ename='ggg',empno=123 where empno=321;
1 row updated.
SQL> commit;
Commit complete.
SQL> delete from kafka where empno=123;
1 row deleted.
SQL> commit;
Commit complete.
SQL> alter system switch logfile;
System altered.
目标端查看:
[root@zookeeper ~]# cd /kafka/kafka/
[root@zookeeper kafka]# ls
bin config console.sh libs LICENSE list.sh logs nohup.out NOTICE productcmd.sh site-docs startkafka.sh
[root@zookeeper kafka]# ./console.sh
input topic:kafka
Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper]
{"table":"SCOTT.KAFKA","op_type":"I","op_ts":"2018-12-12 00:40:05.640034","current_ts":"2018-12-12T00:41:06.144000","pos":"00000000040000004377","primary_keys":["EMPNO"],"after":{"EMPNO":32
1,"ENAME":"aa","JOB":null,"MGR":null,"HIREDATE":null,"SAL":null,"COMM":null,"DEPTNO":null}}
{"table":"SCOTT.KAFKA","op_type":"U","op_ts":"2018-12-12 00:40:26.640034","current_ts":"2018-12-12T00:41:16.160000","pos":"00000000040000004889","primary_keys":["EMPNO"],"before":{"EMPNO":3
21,"ENAME":"aa"},"after":{"EMPNO":321,"ENAME":"ggg"}}
{"table":"SCOTT.KAFKA","op_type":"U","op_ts":"2018-12-12 00:40:45.640034","current_ts":"2018-12-12T00:41:26.180000","pos":"00000000040000005298","primary_keys":["EMPNO"],"before":{"EMPNO":3
21,"ENAME":"ggg"},"after":{"EMPNO":123,"ENAME":"ggg"}}
{"table":"SCOTT.KAFKA","op_type":"D","op_ts":"2018-12-12 00:40:55.640034","current_ts":"2018-12-12T00:41:36.193000","pos":"00000000040000005502","primary_keys":["EMPNO"],"before":{"EMPNO":1
23,"ENAME":"ggg","JOB":null,"MGR":null,"HIREDATE":null,"SAL":null,"COMM":null,"DEPTNO":null}}
发现这几种情况的before和after值都能正常捕获。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
四、安装过程遇到的部分错误
1、设置topicName的属性问题
在启动replicat进程时报错如下:
原因:在kafka.props中配置topicName时使用了下面参数;
gg.handler.kafkahandler.topicName=oggtopic
翻阅官方文档,在OGG for bigdata中,配置topicName属性的参数换成了如下:
gg.handler.kafkahandler.topicMappingTemplate=kafka
解决方法:
将kafka.props中参数替换成上面第二个再次重启replicat进程。

2、自动创建topicname失败
replicat进程启动成功后,同步数据时报错如下:
原因:gg.handler.kafkahandler.topicMappingTemplate=kafka参数配置的topicname在进程启动后同步数据时,会自动在kafka创建一个名为kafka的topic来向此topic生产数据,
但是由于kafka本身参数文件server.properties并未启用当生产者或则消费者生产或则消费某个不存在的topic时会自动创建此topic的参数,所以OGG应用进程中定义的kafka主题名自动创建时失败报错。
解决方法:在kafka参数文件server.properties参数文件中加入下面参数:
auto.create.topics.enable=true
OGG for bigdata官方说明如下:
https://docs.oracle.com/goldengate/bd123110/gg-bd/GADBD/using-kafka-handler.htm#GADBD451
说明如下:
To enable the automatic creation of topics, set the auto.create.topics.enable property to true in the Kafka Broker Configuration. The default value for this property is true.
If the auto.create.topics.enable property is set to false in Kafka Broker configuration, then all the required topics should be created manually before starting the Replicat process.

3、JDK版本不兼容
2018-12-11 22:25:33 WARNING OGG-15053 Java method main(([Ljava/lang/String;)V) is not found in class oracle/goldengate/datasource/UserExitMain.
2018-12-11 22:25:33 WARNING OGG-15053 Java method getDataSource(()Loracle/goldengate/datasource/UserExitDataSource;) is not found in class oracle/goldengate/datasource/UserExitMain.
2018-12-11 22:25:33 WARNING OGG-15053 Java method shutdown(()V) is not found in class oracle/goldengate/datasource/UserExitMain.
Exception in thread "main" java.lang.UnsupportedClassVersionError: oracle/goldengate/datasource/UserExitMain : Unsupported major.minor version 52.0
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:800)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:449)
at java.net.URLClassLoader.access$100(URLClassLoader.java:71)
at java.net.URLClassLoader$1.run(URLClassLoader.java:361)
at java.net.URLClassLoader$1.run(URLClassLoader.java:355)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:354)
at java.lang.ClassLoader.loadClass(ClassLoader.java:425)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:308)
at java.lang.ClassLoader.loadClass(ClassLoader.java:358)
Source Context :
SourceModule : [gglib.ggdal.adapter.java]
SourceID : [/scratch/aime/adestore/views/aime_adc4150560/oggcore/OpenSys/src/gglib/ggdal/Adapter/Java/JavaAdapter.cpp]
SourceMethod : [HandleJavaException]
SourceLine : [246]
ThreadBacktrace : [16] elements
: [/kafka/ogg12/libgglog.so(CMessageContext::AddThreadContext()+0x1e) [0x7fa29ea530ae]]
: [/kafka/ogg12/libgglog.so(CMessageFactory::CreateMessage(CSourceContext*, unsigned int, ...)+0x6ac) [0x7fa29ea439bc]]
: [/kafka/ogg12/libgglog.so(_MSG_String(CSourceContext*, int, char const*, CMessageFactory::MessageDisposition)+0x39) [0x7fa29ea31d19]]
: [/kafka/ogg12/libggjava.so(+0x2e9e7) [0x7fa295c9d9e7]]
: [/kafka/ogg12/libggjava.so(ggs::gglib::ggdal::CJavaAdapter::Open()+0x8b5) [0x7fa295c9fb05]]
: [/kafka/ogg12/replicat(ggs::gglib::ggdal::CDALAdapter::Open(ggs::gglib::ggunicode::UString const&)+0x20) [0x82ef60]]
: [/kafka/ogg12/replicat(GenericImpl::Open(ggs::gglib::ggunicode::UString const&)+0x2c) [0x8163fc]]
: [/kafka/ogg12/replicat(odbc_param(char*, char*)+0xb1) [0x808f41]]
: [/kafka/ogg12/replicat(get_infile_params(ggs::gglib::ggapp::ReplicationContextParams&, ggs::gglib::ggdatasource::DataSourceParams&, ggs::gglib::ggdatatarget::Dat
aTargetParams&, ggs::gglib::ggmetadata::MetadataContext&)+0x9951) [0x5d5e11]]
: [/kafka/ogg12/replicat() [0x6e47bd]]
: [/kafka/ogg12/replicat(ggs::gglib::MultiThreading::MainThread::ExecMain()+0x5e) [0x7e2d8e]]
: [/kafka/ogg12/replicat(ggs::gglib::MultiThreading::Thread::RunThread(ggs::gglib::MultiThreading::Thread::ThreadArgs*)+0x173) [0x7e7153]]
: [/kafka/ogg12/replicat(ggs::gglib::MultiThreading::MainThread::Run(int, char**)+0x140) [0x7e79c0]]
: [/kafka/ogg12/replicat(main+0x3b) [0x6e7e0b]]
: [/lib64/libc.so.6(__libc_start_main+0xfd) [0x323e21ed1d]]
: [/kafka/ogg12/replicat() [0x550831]]
2018-12-11 22:25:33 ERROR OGG-15051 Java or JNI exception:
java.lang.UnsupportedClassVersionError: oracle/goldengate/datasource/UserExitMain : Unsupported major.minor version 52.0.
2018-12-11 22:25:33 ERROR OGG-01668 PROCESS ABENDING.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
原因:根据上面错误日志来看,需要将Java的libjvm.so 和 libjsig.so库文件所在目录加入LD_LIBRARY_PATH环境变量,需要注意的是,LD_LIBRARY_PATH环境变量成效后,需要将MGR也重启一下,但是我这里环境变量已经配置了,我当前用的Java版本是1.7,OGG for Big Data要的版本是1.8,所以版本不对导致上面问题。
解决办法:jdk1.7换成1.8重新配置后从启即可。
4、Kafka中无update前数据
源端做下面操作:
SQL> insert into kafka(empno,ename,job)values(222,'zyd','dba');
1 row created.
SQL> commit;
Commit complete.
SQL> update kafka set ename='zhaoyd' where empno=222;
1 row updated.
SQL> commit;
Commit complete.
SQL> update kafka set ename='yd',empno=666 where empno=222;
1 row updated.
SQL> commit;
Commit complete.
SQL> delete from kafka where empno=666;
1 row deleted.
SQL> commit;
Commit complete.
SQL> alter system switch logfile;
System altered.
SQL> /
System altered.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
查看kafka消费情况:
{"table":"SCOTT.KAFKA","op_type":"I","op_ts":"2018-12-12 04:33:36.707853","current_ts":"2018-12-12T04:35:01.911000","pos":"00000000040000006618","primary_keys":["EMPNO"],"after":{"EMPNO":22
2,"ENAME":"zyd","JOB":"dba","MGR":null,"HIREDATE":null,"SAL":null,"COMM":null,"DEPTNO":null}}
{"table":"SCOTT.KAFKA","op_type":"U","op_ts":"2018-12-12 04:34:11.707853","current_ts":"2018-12-12T04:35:22.452000","pos":"00000000040000007136","primary_keys":["EMPNO"],"before":{},"after"
:{"EMPNO":222,"ENAME":"zhaoyd"}}
{"table":"SCOTT.KAFKA","op_type":"U","op_ts":"2018-12-12 04:34:29.707853","current_ts":"2018-12-12T04:35:32.567000","pos":"00000000040000007550","primary_keys":["EMPNO"],"before":{"EMPNO":2
22},"after":{"EMPNO":666,"ENAME":"yd"}}
{"table":"SCOTT.KAFKA","op_type":"D","op_ts":"2018-12-12 04:34:42.707853","current_ts":"2018-12-12T04:35:42.577000","pos":"00000000040000007753","primary_keys":["EMPNO"],"before":{"EMPNO":6
66,"ENAME":"yd","JOB":"dba","MGR":null,"HIREDATE":null,"SAL":null,"COMM":null,"DEPTNO":null}}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这里总结一下上面消费出现的问题:
源端抽取进程已经添加了
NOCOMPRESSDELETES
NOCOMPRESSUPDATES
GETUPDATEBEFORES
三个参数,此时:
1、如果在源端做非PK Update ,抽取进程应该把主键值以及被修改字段的修改前和修改后的数据都写到trail文件,以供应用进程以json格式写before和after值及其他信息到kafka;
2、如果在源端做PK Update操作,抽取进程会把主键被修改前和修改后的值以及同时修改的其他的字段的修改前和后的值都记录到trail文件,以供应用进程以json格式写before和after值及其他信息到kafka;
3、如果在源端做delete操作,抽取进程会把所有被删除的字段值写到trail文件,以供应用进程以json格式写before信息到kafka。
但是根据看上面的操作发现,现在只有insert的数据是全的,update更新非主键字段before是没有数据的,只有after有数据,更新主键before只有主键的数据,delete正常,是因为虽然加了GETUPDATEBEFORES
参数,trail文件仍然只是写了after的值吗?接下来验证一下:
源端做非PK Update操作:
SQL> select empno,ename from kafka;
EMPNO ENAME
---------- ----------
7369 er
7499 ALLEN
7521 WARD
7566 JONES
7654 MARTIN
7698 BLAKE
7782 CLARK
7839 KING
7844 TURNER
7876 ADAMS
7900 JAMES
7902 FORD
7934 sdf
3233 dsdds
14 rows selected.
SQL> update kafka set ename='test'where empno=7369;
1 row updated.
SQL> commit;
Commit complete.
SQL> alter system switch logfile;
System altered.
SQL> select empno,ename from kafka;
EMPNO ENAME
---------- ----------
7369 test
7499 ALLEN
7521 WARD
7566 JONES
7654 MARTIN
7698 BLAKE
7782 CLARK
7839 KING
7844 TURNER
7876 ADAMS
7900 JAMES
7902 FORD
7934 sdf
3233 dsdds
14 rows selected.
源端修改成功,去挖掘trail文件:
Logdump 92 >n
TokenID x47 'G' Record Header Info x01 Length 194
TokenID x48 'H' GHDR Info x00 Length 36
450c 0041 001a 0fff 02f2 a32a d082 7880 0000 0000 | E..A.......*..x.....
0005 7c10 0000 0109 0252 0000 0001 0001 | ..|......R......
TokenID x44 'D' Data Info x00 Length 26
TokenID x54 'T' GGS Tokens Info x00 Length 24
TokenID x55 'U' User Tokens Info x00 Length 84
TokenID x5a 'Z' Record Trailer Info x01 Length 194
___________________________________________________________________
Hdr-Ind : E (x45) Partition : . (x0c)
UndoFlag : . (x00) BeforeAfter: A (x41)
RecLength : 26 (x001a) IO Time : 2018/12/14 16:38:42.000.000
IOType : 15 (x0f) OrigNode : 255 (xff)
TransInd : . (x02) FormatType : R (x52)
SyskeyLen : 0 (x00) Incomplete : . (x00)
AuditRBA : 265 AuditPos : 359440
Continued : N (x00) RecCount : 1 (x01)
2018/12/14 16:38:42.000.000 FieldComp Len 26 RBA 3299
Name: SCOTT.KAFKA (TDR Index: 1)
After Image: Partition 12 GU e
0000 000a 0000 0000 0000 0000 1cc9 0001 0008 0000 | ....................
0004 7465 7374 | ..test
Column 0 (x0000), Len 10 (x000a)
0000 0000 0000 0000 1cc9 | ..........
Column 1 (x0001), Len 8 (x0008)
0000 0004 7465 7374 | ....test
User tokens: 84 bytes
TKN-CSN : 1462257
TKN-COMMIT-TS : 2018-12-14 16:38:42.000000
TKN-OP-TYPE : SQL COMPUPDATE
GGS tokens:
TokenID x52 'R' ORAROWID Info x00 Length 20
4141 4156 7458 4141 4541 4141 414a 6a41 4141 0001 | AAAVtXAAEAAAAJjAAA..
Logdump 93 >n
TokenID x47 'G' Record Header Info x01 Length 216
TokenID x48 'H' GHDR Info x00 Length 36
450c 0042 0018 0fff 02f2 a32a d082 7880 0000 0000 | E..B.......*..x.....
0005 7c10 0000 0109 0052 0000 0001 0001 | ..|......R......
TokenID x44 'D' Data Info x00 Length 24
TokenID x54 'T' GGS Tokens Info x00 Length 48
TokenID x55 'U' User Tokens Info x00 Length 84
TokenID x5a 'Z' Record Trailer Info x01 Length 216
___________________________________________________________________
Hdr-Ind : E (x45) Partition : . (x0c)
UndoFlag : . (x00) BeforeAfter: B (x42)
RecLength : 24 (x0018) IO Time : 2018/12/14 16:38:42.000.000
IOType : 15 (x0f) OrigNode : 255 (xff)
TransInd : . (x00) FormatType : R (x52)
SyskeyLen : 0 (x00) Incomplete : . (x00)
AuditRBA : 265 AuditPos : 359440
Continued : N (x00) RecCount : 1 (x01)
2018/12/14 16:38:42.000.000 FieldComp Len 24 RBA 3083
Name: SCOTT.KAFKA (TDR Index: 1)
Before Image: Partition 12 GU b
0000 000a 0000 0000 0000 0000 1cc9 0001 0006 0000 | ....................
0002 6572 | ..er
Column 0 (x0000), Len 10 (x000a)
0000 0000 0000 0000 1cc9 | ..........
Column 1 (x0001), Len 6 (x0006)
0000 0002 6572 | ....er
User tokens: 84 bytes
TKN-CSN : 1462257
TKN-COMMIT-TS : 2018-12-14 16:38:42.000000
TKN-OP-TYPE : SQL COMPUPDATE
GGS tokens:
TokenID x52 'R' ORAROWID Info x00 Length 20
4141 4156 7458 4141 4541 4141 414a 6a41 4141 0001 | AAAVtXAAEAAAAJjAAA..
TokenID x4c 'L' LOGCSN Info x00 Length 7
3134 3632 3235 37 | 1462257
TokenID x36 '6' TRANID Info x00 Length 9
322e 3238 2e31 3134 31 | 2.28.1141
通过挖掘trail文件发现,抽取进程已经把被update字段的before和after值都写到了trail文件,去kafka 查看消费情况:
{"table":"SCOTT.KAFKA","op_type":"U","op_ts":"2018-12-12 00:23:10.639439","current_ts":"2018-12-12T00:23:19.143000","pos":"00000000040000003346","primary_keys":["EMPNO"],"before":{},"after"
:{"EMPNO":7369,"ENAME":"test"}}
发现还是只有after的值,没有before的值,接下来再看看做PK Update的操作:
源端操作如下:
SQL> update kafka set ename='test',empno=3333 where empno=3233;
1 row updated.
SQL> commit;
Commit complete.
SQL> alter system switch logfile;
System altered.
再去看消费情况:
{"table":"SCOTT.KAFKA","op_type":"U","op_ts":"2018-12-12 00:29:02.639408","current_ts":"2018-12-12T00:29:11.125000","pos":"00000000040000003759","primary_keys":["EMPNO"],"before":{"EMPNO":3
233},"after":{"EMPNO":3333,"ENAME":"test"}}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
发现pkupdate也是只有主键列有update前值,为什么普通update前和后的值明明写到trail文件了,为什么应用进程写kafka,看kafka消费时只有after数据,而before为空呢,在11g版本的OGG for bigdata没有这类问题,于是去查看12c的官方文档这个参数的介绍:
https://docs.oracle.com/goldengate/c1221/gg-winux/GWURF/getupdatebefores-ignoreupdatebefores.htm#GWURF515
这个参数现在也要在应用进程中添加,这样应用进程才会将before值写到kafka,接下来做修改:

GGSCI (zookeeper) 54> edit params rkafka
修改内容如下:
REPLICAT rkafka
-- Trail file for this example is located in "AdapterExamples/trail" directory
-- Command to add REPLICAT
-- add replicat rkafka, exttrail AdapterExamples/trail/tr
TARGETDB LIBFILE libggjava.so SET property=dirprm/kafka.props
REPORTCOUNT EVERY 1 MINUTES, RATE
GROUPTRANSOPS 10000
GETUPDATEBEFORES
MAP SCOTT.*, TARGET SCOTT.*;
GGSCI (zookeeper) 55> stop rkafka
Sending STOP request to REPLICAT RKAFKA ...
Request processed.
GGSCI (zookeeper) 56> start rkafka
Sending START request to MANAGER ...
REPLICAT RKAFKA starting
GGSCI (zookeeper) 57> info all
Program Status Group Lag at Chkpt Time Since Chkpt
MANAGER RUNNING
REPLICAT RUNNING RKAFKA 00:00:00 00:00:03
再次在源端做普通update操作:
SQL> update kafka set ename='zhaoyd' where empno=3333;
1 row updated.
SQL> commit;
Commit complete.
SQL> alter system switch logfile;
System altered.
去kafka查看消费情况:
{"table":"SCOTT.KAFKA","op_type":"U","op_ts":"2018-12-12 00:37:39.639361","current_ts":"2018-12-12T00:37:47.418000","pos":"00000000040000004181","primary_keys":["EMPNO"],"before":{"EMPNO":3
333,"ENAME":"test"},"after":{"EMPNO":3333,"ENAME":"zhaoyd"}}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
发现这时before也有了值,正常了。原来在11g的版本做,没有这个问题,12.3需要在应用进程也加入GETUPDATEBEFORES参数。
五、安装Appach Flink
这里只是为了测试,不再重新配置hadoop环境,只简单安装一个单机无hadoop环境版本的Flink用于测试
1、下载上传解压Flink 1.4软件:
下载连接:
https://archive.apache.org/dist/flink/flink-1.4.0/
2、启动和关闭flink
[root@zookeeper kafka]# cd /kafka/flink/
[root@zookeeper flink]# ./bin/start-local.sh
Warning: this file is deprecated and will be removed in 1.5.
Starting cluster.
Starting jobmanager daemon on host zookeeper.
Starting taskmanager daemon on host zookeeper.
[root@zookeeper flink]./bin/stop-local.sh
Warning: this file is deprecated and will be removed in 1.5.
Stopping taskmanager daemon (pid: 5641) on host zookeeper.
Stopping jobmanager daemon (pid: 5323) on host zookeeper.
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3、编写程序
参考1.4版本的官方文档案例写法:
https://ci.apache.org/projects/flink/flink-docs-release-1.4/quickstart/run_example_quickstart.html#writing-a-flink-program
https://github.com/wangshubing1/flink/blob/master/flink-examples/flink-examples-streaming/src/main/scala/org/apache/flink/streaming/scala/examples/kafka/Kafka010Example.scala
package com.learn.Flink.kafka
import org.apache.flink.api.common.restartstrategy.RestartStrategies
import org.apache.flink.api.common.serialization.SimpleStringSchema
import org.apache.flink.api.java.utils.ParameterTool
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer010, FlinkKafkaProducer010}
import org.apache.flink.api.scala._
/**
* @Author: king
* @Datetime: 2018/10/16
* @Desc: TODO
*
*/
object Kafka010Example {
def main(args: Array[String]): Unit = {
// 解析输入参数
val params = ParameterTool.fromArgs(args)
if (params.getNumberOfParameters < 4) {
println("Missing parameters!\n"
+ "Usage: Kafka --input-topic <topic> --output-topic <topic> "
+ "--bootstrap.servers <kafka brokers> "
+ "--zookeeper.connect <zk quorum> --group.id <some id> [--prefix <prefix>]")
return
}
val prefix = params.get("prefix", "PREFIX:")
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.getConfig.disableSysoutLogging
env.getConfig.setRestartStrategy(RestartStrategies.fixedDelayRestart(4, 10000))
// 每隔5秒创建一个检查点
env.enableCheckpointing(5000)
// 在Web界面中提供参数
env.getConfig.setGlobalJobParameters(params)
// 为卡夫卡0.10 x创建一个卡夫卡流源用户
val kafkaConsumer = new FlinkKafkaConsumer010(
params.getRequired("input-topic"),
new SimpleStringSchema,
params.getProperties)
//消费kafka数据
/*val transaction = env
.addSource(
new FlinkKafkaConsumer010[String](
params.getRequired("input-topic"),
new SimpleStringSchema,
params.getProperties))
transaction.print()*/
//消费kafka数据
val messageStream = env
.addSource(kafkaConsumer)
.map(in => prefix + in)
messageStream.print()
// 为卡夫卡0.10 X创建一个生产者
val kafkaProducer = new FlinkKafkaProducer010(
params.getRequired("output-topic"),
new SimpleStringSchema,
params.getProperties)
// 将数据写入kafka
messageStream.addSink(kafkaProducer)
env.execute("Kafka 0.10 Example")
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72

