
- 1vue+neo4j +纯前端(neovis.js / neo4j-driver) 实现 知识图谱的集成 大干货--踩坑无数!!!将经验分享给有需要的小伙伴_neo4j vue
- 2MD-VQA:视频质量评价算法_视频质量评估
- 3ifcfg-eth0 配置文件的详细解释
- 4yolov8模型训练结果分析以及如何评估yolov8模型训练的效果_yolov8训练结果分析
- 5【Docker】安装Redis、Nginx、MongoDb、Jenkins
- 6弃文从理,一个文科生的编程之路_文科生学编程的努力
- 7谷粒商城学习笔记(1.环境搭建)
- 8排序算法总结及java实现_排序算法 实现特性 csdn
- 9umount: 提示 target is busy_umount: /data: target is busy.
- 10数据结构与算法(C语言)代码实现-线性表的相关操作代码实现(单链表)_数据结构与算法线性表实验代码
图书知识图谱的设计与实现_知识图谱实现
赞
踩
前言
知识图谱,最早起源于Google Knowledge Graph,从最开始的Google搜索,到现在的聊天机器人、推荐系统、智能医疗、大数据风控、证券投资,都有知识图谱的身影。最近导师安排我复现一篇基于知识图谱和NLP的图书问答系统,以下浅浅的说一下这几天所学的内容和碰到的问题。
一、知识图谱是什么?
知识图谱是由实体节点和关系边组成的图的形式,这种图的形式可以将现实中不同类型的事物连接在一起。知识图谱的实体(entity)是节点,边(edge)是两个节点中间的有向连线,代表着实体之间的关系(relation)。知识图谱的基本组成单位是三元组,使用<头实体(head),关系(relation),尾实体(tail)>的结构来描述事实,构建成复杂的网络。下面就是图书领域的一个局部知识图谱。

除了实体和关系这种三元组形式,知识图谱中的每个实体还存在着属性。实体与属性的三元组结构是<实体,属性,属性值>,比如,“三体这本书的类型是小说”中“三体”是实体,“类型”是属性,“小说”是属性值,可以存储到<三体,类型,小说>中。
二、图书知识图谱问答系统实现的两大主要模块
1.知识图谱构建模块
构建图书知识图谱,我们主要需要考虑三个方面,数据获取,数据处理,以及数据存储。
最初的想法是去各大图书网站上,通过爬虫手段爬取相关数据。因为从图书网站爬取获得的数据中包含一些非格式化、杂乱的数据。所以需要对数据获取部分得到的初始数据进行数据清洗,使其变成格式化数据。并且对获取的这些数据进行分析和设计,抽取实体、关系和属性的知识三元组。最后用图数据库Neo4j进行存储。
由于笔者才疏学浅,爬虫技术和数据分析和清洗等技术是另外一门手艺,这里我就暂时不考虑这两个方面,而是直接从相关渠道直接下载一些处理好的数据集,并将其导如Neo4j中。
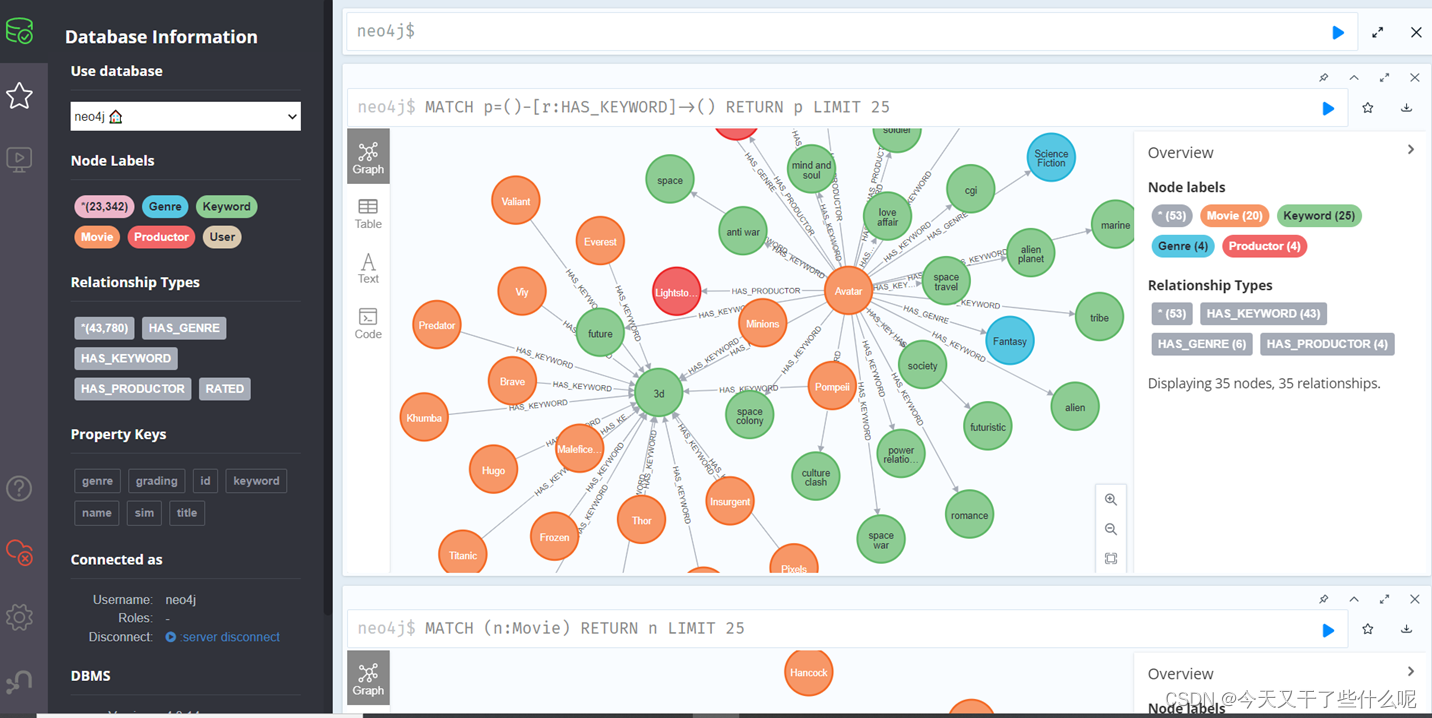
上图是Neo4j的界面。由于我只找到了电影方面的相关数据,但是为了体验一下强大的Neo4j的功能,就将电影数据导入里面玩了玩。至于后续图书数据的问题,要是最后还没找到的话,笔者就打算自己人工生产百来个图书信息。
2.基于模板方法的问答模块
基于模板方法的问答模块的实现,也需要考虑三个方面,分别是实体识别、文本分类和答案获取。具体框架如下:
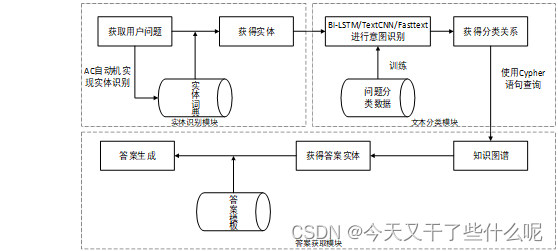
(1)实体识别模块:这个模块是对用户的问句进行实体识别操作,采用Aho-Corasick自动机算法对用户输入的问句匹配图书实体词典中的实体词,图书实体词典即构建知识图谱时数据存储模块导出的图书实体的txt文件,通过实体识别操作即可从用户的问句中获得相关图书实体
(2)文本分类模块:这个模块对用户的问句进行文本分类,也就是对用户输入的问题进行意图识别,即获取用户是要获得某本书的作者,还是某本书的出版日期,或者是某作者写的书等意图。本模块采用可以进行文本分类操作的深度学习模型,通过标注后的数据进行训练,使得模型能够获得意图识别功能。系统从用户问句中获得意图后,将识别到的意图转化为图数据库中存在的关系类型。
(3)答案获取模块:将用户问句从实体识别模块得到的实体,和意图识别模块得到的关系封装成字典,将字典转化为Cypher语句到Neo4j数据库中进行查询,得到实体的名字属性加入到经过提前设置好的回答模板中,从而获得了用户所需的答案。
该问答模块的设计,笔者目前只是浅浅地学习了一下上面的设计流程,还没有进行实际操作。
三、碰到的小问题
在写代码的过程中,因为要导入一个包pandas,由于解释器python3.7没有这个包,所以我就尝试在这里面搜索并下载导入
但是接下来它提示error

于是我就在终端控制台上尝试用镜像网站导入这个包,最后还是失败了
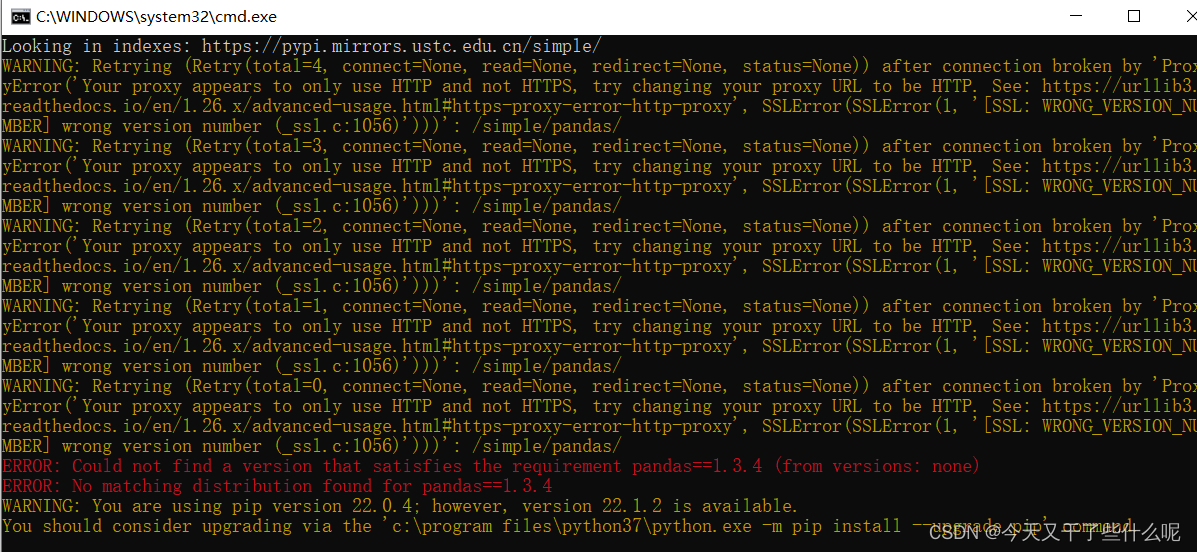
最后一行提示让我更新pip,我照做了,但也没能成功更新
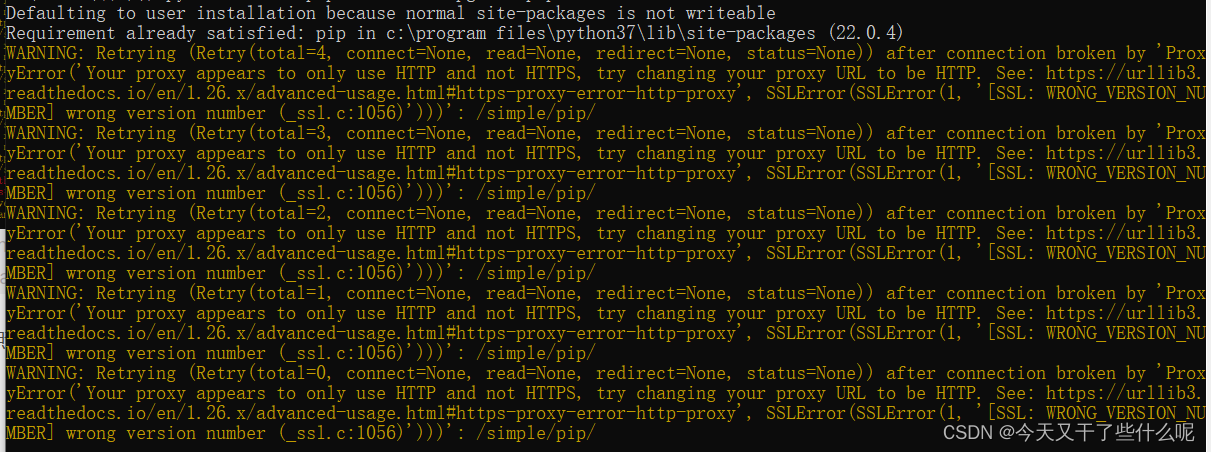
我在网上也看到过类似的问题,于是我便按照他们的解决方案操作,令人悲哀的是,依旧失败了,所以我很崩溃,希望有友友们能帮我解决一下。
总结
以上就是这几天所学习的内容,经过这几天的学习,对知识图谱也有一定的认识,并且也了解了一下Neo4j的一些操作。

