
- 1Java之方法的重载(求最大值方法的重载)_求最大值方法对重载
- 2SpringBoot从入门到精通教程(三十一)- 爬虫框架集成_springboot爬虫教程
- 3CodeForces978C Letters(模拟)_there are nn dormitories in berland state universi
- 4Git总结 | Git面试都问些啥?_git在分支里面创造新的分支
- 5AI系列:大语言模型的function calling(下)- 使用LangChain
- 6PyCharm环境下Git与Gitee联动:本地与远程仓库操作实战及常见问题解决方案_pycharm连接gitee
- 7【每日一题】求一个整数的惩罚数
- 8百度UIE:Unified Structure Generation for Universal Information Extraction paper详细解读和相关资料
- 9Python 动态抓取 Android 进程内存信息 数据可视化_python实现对手机性能的可视化分析
- 10桌面虚拟化之最佳实践篇1-- VIEW COMPOSER
【尚硅谷】【大数据】 Zookeeper 入门【学习笔记】_大数据技术之zookeeper 3.5.7版本教程百度云下载
赞
踩
视频地址:【尚硅谷】大数据技术之Zookeeper 3.5.7版本教程_哔哩哔哩_bilibili
第 1 章 Zookeeper 入门
1.1 Zookeeper工作机制
Zookeeper 是一个开源的分布式的,为分布式框架提供协调服务的 Apache 项目。
Hadoop等是动物(大象),ZooKeeper 是动物园的饲养员
Zookeeper工作机制
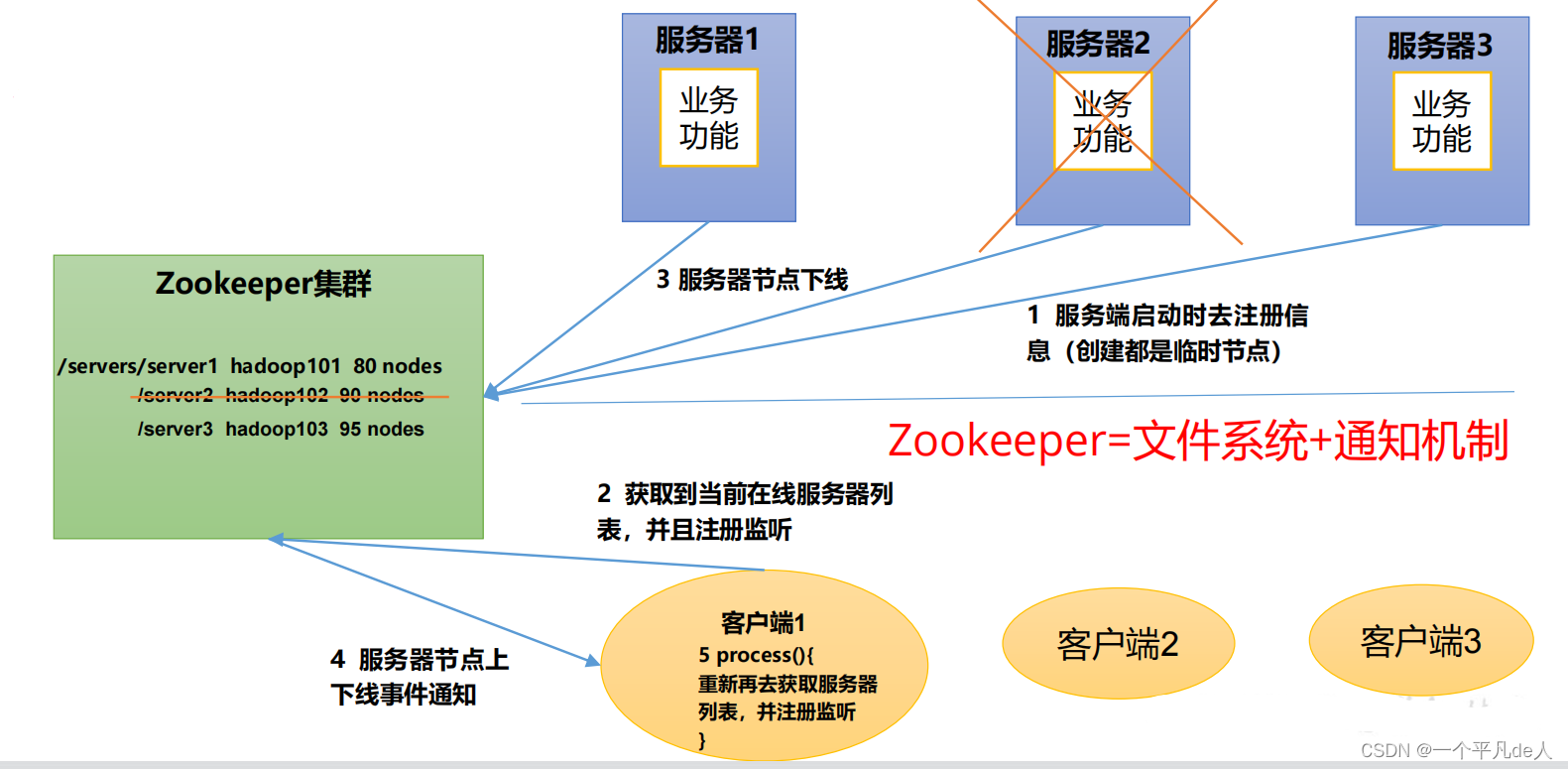
Zookeeper从设计模式角度来理解:是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应。
Zookeeper=文件系统+通知机制
1.2 Zookeeper 特点
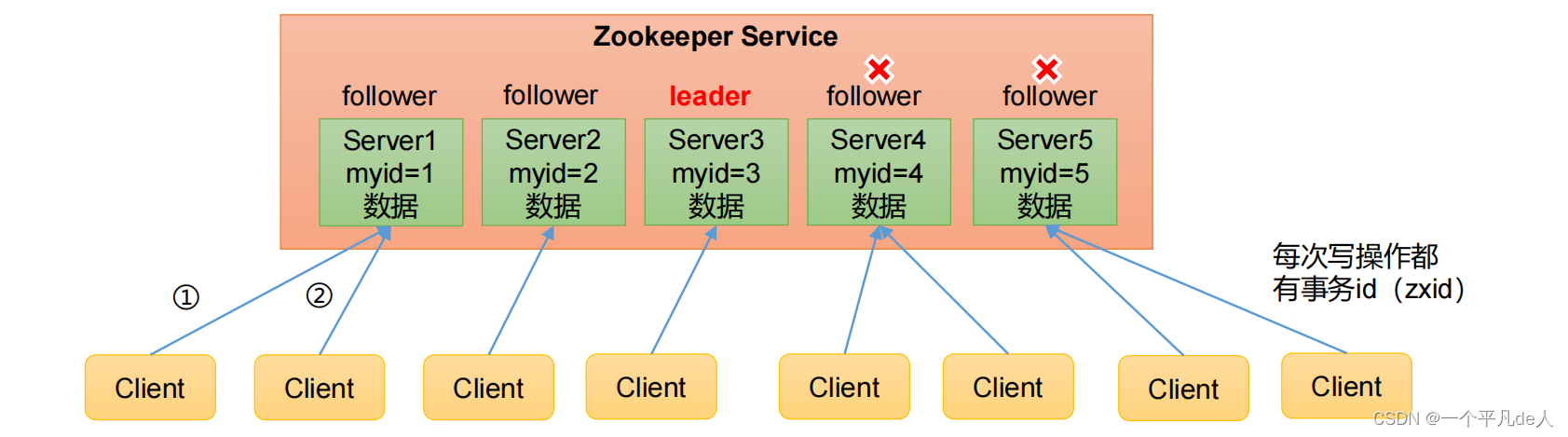
(1)Zookeeper:一个领导者(Leader),多个跟随者(Follower)组成的集群。
(2)集群中只要有半数以上节点存活,Zookeeper集群就能正常服务。所以Zookeeper适合安装奇数台服务器。
(3)全局数据一致:每个Server保存一份相同的数据副本,Client无论连接到哪个Server,数据都是一致的。
(4)更新请求顺序执行,来自同一个Client的更新请求按其发送顺序依次执行。
(5)数据更新原子性,一次数据更新要么成功,要么失败。
(6)实时性,在一定时间范围内,Client能读到最新数据。
- 一般读操作占操作比例的90%以上,所以,一般跟随者(Follower)负责读数据,领导者(Leader)负责写数据,同时保证数据的一致性(主从一致)。
1.3 数据结构
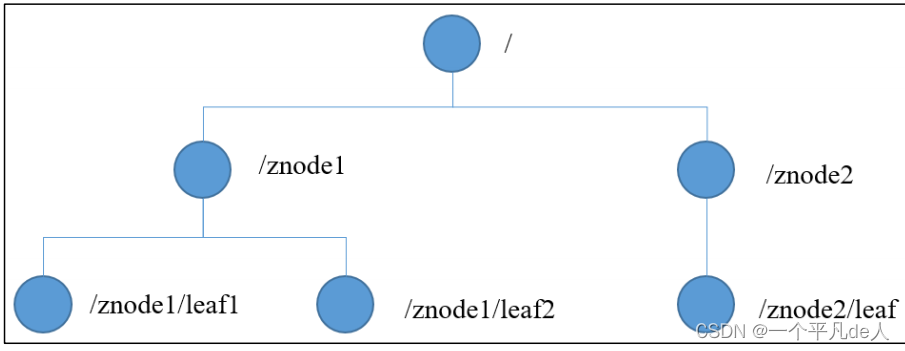
ZooKeeper 数据模型的结构与 Unix 文件系统很类似,整体上可以看作是一棵树,每个节点称做一个 ZNode。每一个 ZNode 默认能够存储 1MB 的数据,每个 ZNode 都可以通过其路径唯一标识。
1.4 应用场景
提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
统一命名服务
在分布式环境下,经常需要对应用/服务进行统一命名,便于识别。
例如:IP不容易记住,而域名容易记住。
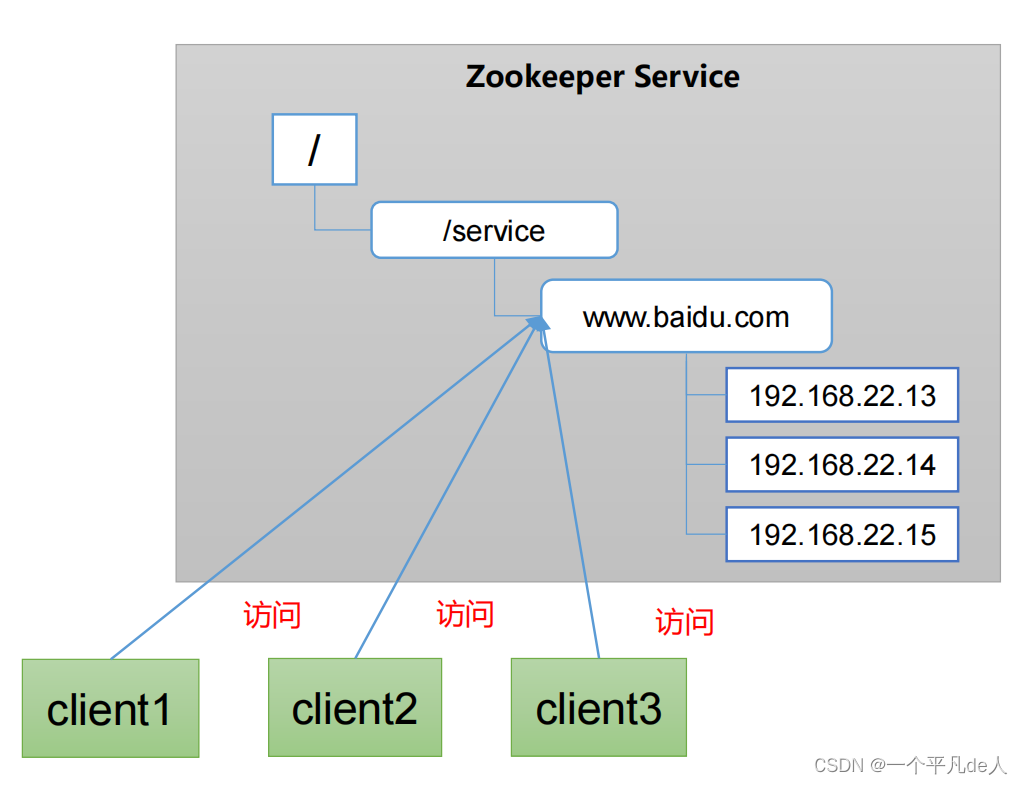
统一配置管理
1、分布式环境下,配置文件同步非常常见。
(1)一般要求一个集群中,所有节点的配置信息是一致,比如 Kafka 集群。
(2)对配置文件修改后,希望能够快速同步到各个节点上。
2、配置管理可交由ZooKeeper实现。
(1)可将配置信息写入ZooKeeper上的一个Znode。
(2)各个客户端服务器监听这个Znode。
(3)一旦Znode中的数据被修改,ZooKeeper将通知各个客户端服务器。
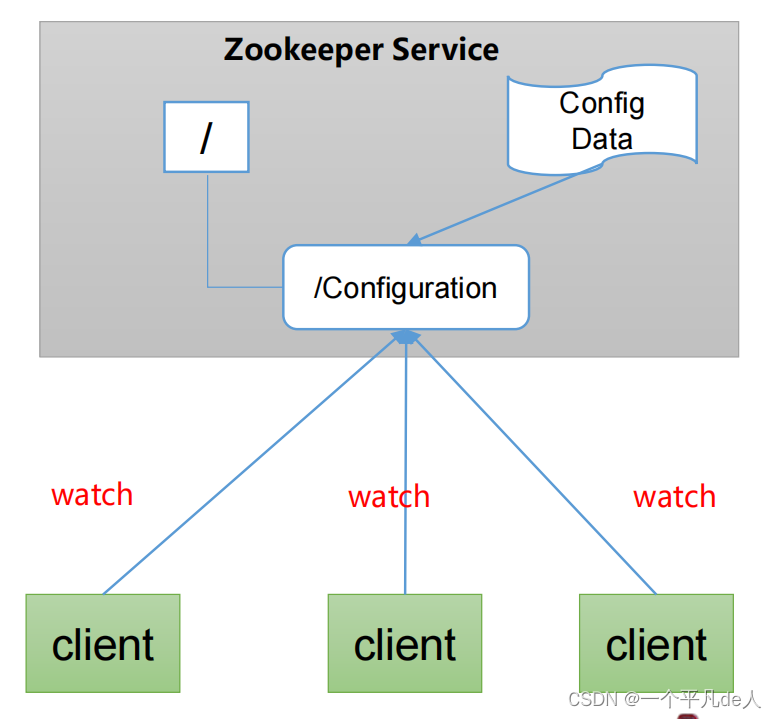
统一集群管理
1、分布式环境中,实时掌握每个节点的状态是必要的。
(1)可根据节点实时状态做出一些调整。
2、ZooKeeper可以实现实时监控节点状态变化
(1)可将节点信息写入ZooKeeper上的一个ZNode。
(2)监听这个ZNode可获取它的实时状态变化。
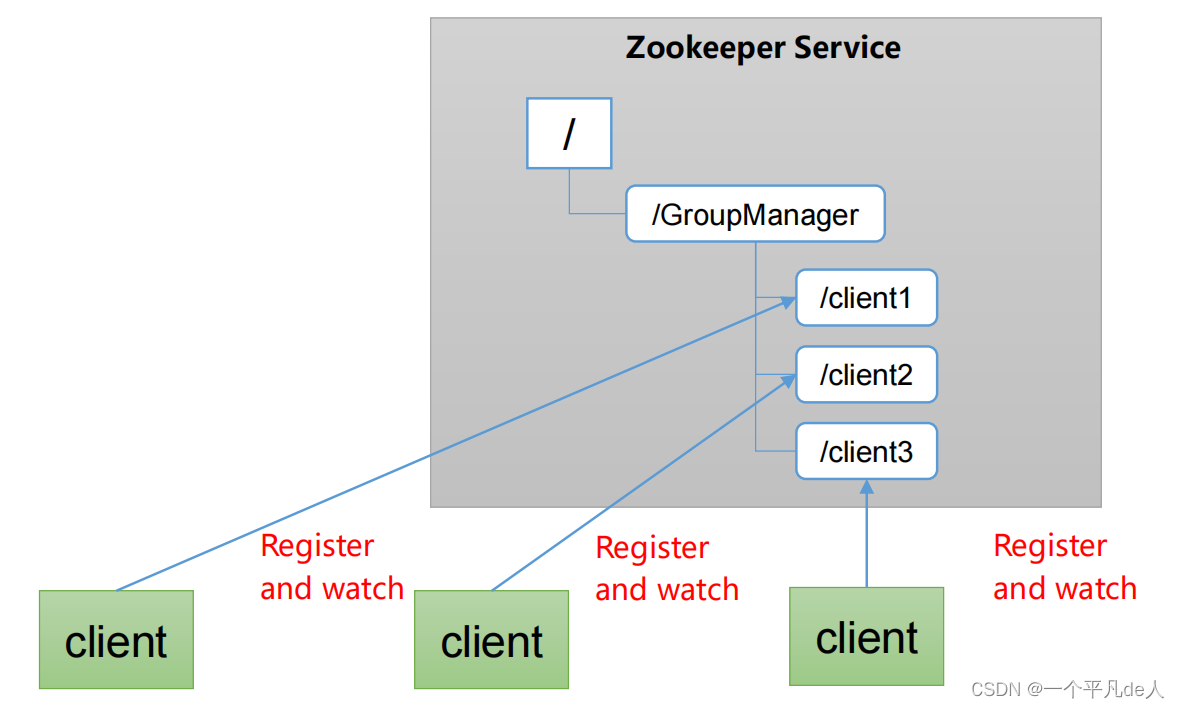
服务器动态上下线
客户端能实时洞察到服务器上下线的变化,讲Zookeeper工作机制时已经讲解。
软负载均衡
在Zookeeper中记录每台服务器的访问数,让访问数最少的服务器去处理最新的客户端请求
2、 Zoopeeper 安装
安装机器 hadoop102
2.1 Zoopeeper 下载
Index of /dist/zookeeper (apache.org)
Index of /dist/zookeeper/zookeeper-3.5.7 (apache.org)
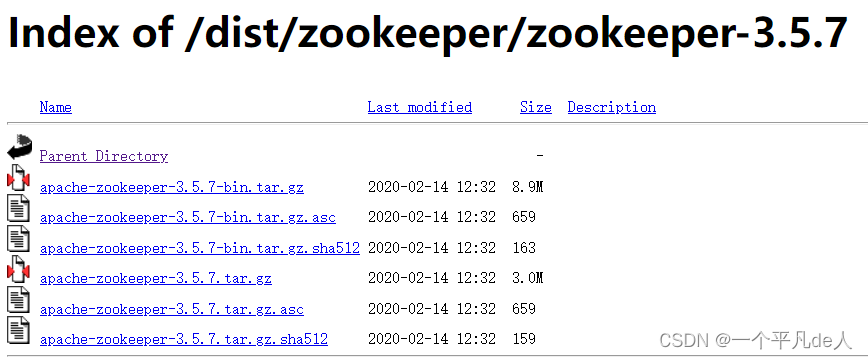
2.2 安装前准备
1、安装 JDK
2、拷贝 apache-zookeeper-3.5.7-bin.tar.gz 安装包到 Linux 系统下
3、解压到指定目录
[root@hadoop102 software]$ tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
- 1
4、修改名称
[root@hadoop102 module]$ mv apache-zookeeper-3.5.7-bin zookeeper-3.5.7
- 1
5、查看安装目录
[root@hadoop102 zookeeper-3.5.7]$ ls
bin conf docs lib LICENSE.txt NOTICE.txt README.md README_packaging.txt
- 1
- 2
2.3 配置修改
(1)将/opt/module/zookeeper-3.5.7/conf 这个路径下的 zoo_sample.cfg 修改为 zoo.cfg;
[root@hadoop102 conf]$ mv zoo_sample.cfg zoo.cfg
- 1
(2)打开 zoo.cfg 文件
[root@hadoop102 zookeeper-3.5.7]$ vim zoo.cfg
- 1
- 修改 dataDir 路径:
dataDir=/opt/module/zookeeper-3.5.7/zkData
- 1
(3)在/opt/module/zookeeper-3.5.7/这个目录上创建 zkData 文件夹
[root@hadoop102 zookeeper-3.5.7]$ mkdir zkData
- 1
2.4 操作 Zookeeper
(1)启动 Zookeeper
[root@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start
- 1
(2)查看进程是否启动
[root@hadoop102 zookeeper-3.5.7]$ jps
3233 QuorumPeerMain
3266 Jps
- 1
- 2
- 3
(3)查看状态
[root@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: standalone # 本地模式
- 1
- 2
- 3
- 4
- 5
(4)启动客户端
[root@hadoop102 zookeeper-3.5.7]$ bin/zkCli.sh
- 1
[zk: localhost:2181(CONNECTED) 3] ls /
[zookeeper]
- 1
- 2
(5)退出客户端:
[zk: localhost:2181(CONNECTED) 0] quit
- 1
(6)停止 Zookeeper
[root@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh stop
- 1
2.5 配置参数解读
Zookeeper中的配置文件zoo.cfg中参数含义解读如下:
# 通信心跳时间
tickTime=2000
# LF初始通信时限
initLimit=10
# LF同步通信时限
syncLimit=5
# 保存Zookeeper中的数据
dataDir=/opt/module/zookeeper-3.5.7/zkData
# 客户端连接端口,通常不做修改
clientPort=2181
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
(1)tickTime = 2000:通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
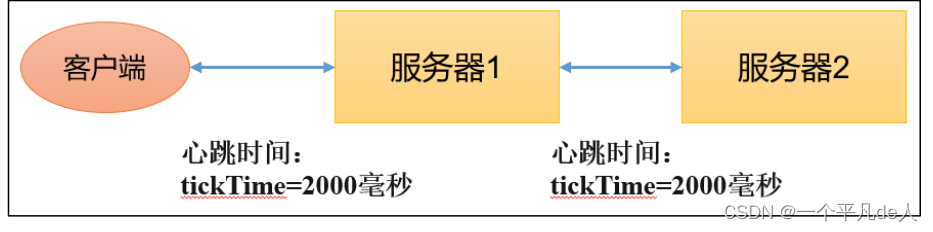
(2)initLimit = 10:LF初始通信时限

Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量)
(3)syncLimit = 5:LF同步通信时限

Leader和Follower之间通信时间如果超过syncLimit * tickTime,Leader认为Follwer死
掉,从服务器列表中删除Follwer。
(4)dataDir:保存Zookeeper中的数据
注意:默认的tmp目录,容易被Linux系统定期删除,所以一般不用默认的tmp目录。
(5)clientPort = 2181:客户端连接端口,通常不做修改
第 3 章 Zookeeper 集群操作
3.1 集群安装
1、集群规划
在 hadoop102、hadoop103 和 hadoop104 三个节点上都部署 Zookeeper。
思考:如果是 10 台服务器,需要部署多少台 Zookeeper**?
2、配置Zookeeper服务器编号
(1)在/opt/module/zookeeper-3.5.7/zkData 目录下创建一个 myid 的文件
[root@hadoop102 zkData]$ vim myid
- 1
在文件中添加与 server 对应的编号2(注意:上下不要有空行,左右不要有空格),相当于Zookeeper服务器的身份标识
注意:添加 myid 文件,一定要在 Linux 里面创建,在 notepad++里面很可能乱码
(2)拷贝配置好的 zookeeper 到其他机器上
[root@hadoop102 module ]$ xsync zookeeper-3.5.7
- 1
- 并分别在 hadoop103、hadoop104 上修改 myid 文件中内容为 3、4
3、配置zoo.cfg文件,增加如下配置
#######################cluster##########################
server.2=hadoop102:2888:3888
server.3=hadoop103:2888:3888
server.4=hadoop104:2888:3888
- 1
- 2
- 3
- 4
(1)配置参数解读
# server.2=hadoop102:2888:3888
server.A=B:C:D
- 1
- 2
A 是一个数字,表示这个是第几号服务器;
集群模式下配置一个文件 myid,这个文件在 dataDir 目录下,这个文件里面有一个数据就是 A 的值,Zookeeper 启动时读取此文件,拿到里面的数据与 zoo.cfg 里面的配置信息比较从而判断到底是哪个 server。
B 是这个服务器的地址;
C 是这个服务器 Follower 与集群中的 Leader 服务器交换信息的端口;
D 是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
(2)同步 zoo.cfg 配置文件
[root@hadoop102 conf]$ xsync zoo.cfg
- 1
3.2 集群操作
1、三个主机分别启动 Zookeeper
[root@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh start
[root@hadoop103 zookeeper-3.5.7]$ bin/zkServer.sh start
[root@hadoop104 zookeeper-3.5.7]$ bin/zkServer.sh start
- 1
- 2
- 3
2、查看状态,此时hadoop103是leader, hadoop102和hadoop104 是follower
[root@hadoop102 zookeeper-3.5.7]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /opt/module/zookeeper-3.5.7/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost.
Mode: follower
- 1
- 2
- 3
- 4
- 5
[root@hadoop102 zookeeper-3.5.7]$ jpsall
=============== hadoop102 ===============
4148 QuorumPeerMain
4295 Jps
=============== hadoop103 ===============
2653 QuorumPeerMain
2765 Jps
=============== hadoop104 ===============
2640 QuorumPeerMain
2750 Jps
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
3.3 选举机制(面试重点)
Zookeeper选举机制——第一次启动
SID:服务器ID。用来唯一标识一台ZooKeeper集群中的机器,每台机器不能重复,和myid一致。
ZXID:事务ID。ZXID是一个事务ID,用来标识一次服务器状态的变更。在某一时刻,集群中的每台机器的ZXID值不一定完全一
致,这和ZooKeeper服务器对于客户端“更新请求”的处理逻辑有关。
Epoch:每个Leader任期的代号。没有Leader时同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加
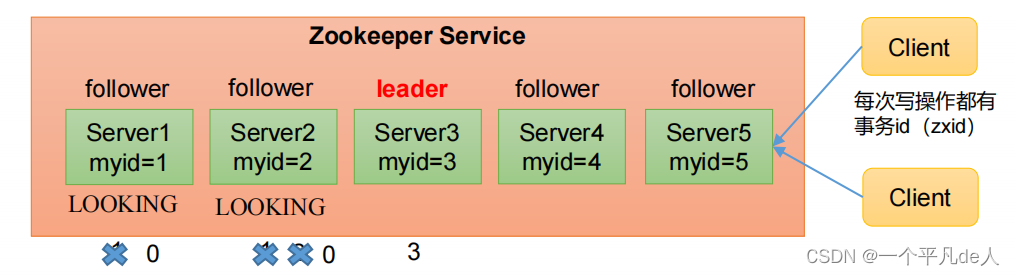
(1)服务器1启动,发起一次选举。服务器1投自己一票。此时服务器1票数一票,不够半数以上(3票),选举无法完成,服务器1状态保持为LOOKING;
(2)服务器2启动,再发起一次选举。服务器1和2分别投自己一票并交换选票信息:此时服务器1发现服务器2的myid比自己目前投票推举的(服务器1) 大,更改选票为推举服务器2。此时服务器1票数0票,服务器2票数2票,没有半数以上结果,选举无法完成,服务器1,2状态保持LOOKING
(3)服务器3启动,发起一次选举。此时服务器1和2都会更改选票为服务器3。此次投票结果:服务器1为0票,服务器2为0票,服务器3为3票。此时服务器3的票数已经超过半数,服务器3当选Leader。服务器1,2更改状态为FOLLOWING,服务器3更改状态为LEADING;LOOKING LOOKING1 1 2 0 3 0
(4)服务器4启动,发起一次选举。此时服务器1,2,3已经不是LOOKING状态,不会更改选票信息。交换选票信息结果:服务器3为3票,服务器4为 1票。此时服务器4服从多数,更改选票信息为服务器3,并更改状态为FOLLOWING;
(5)服务器5启动,同4一样当小弟。
Zookeeper选举机制——非第一次启动
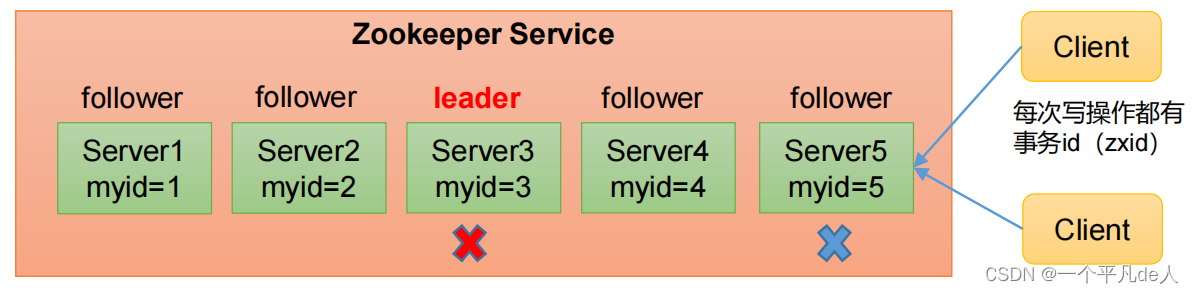
(1)当ZooKeeper集群中的一台服务器出现以下两种情况之一时,就会开始进入Leader选举:
• 服务器初始化启动。
• 服务器运行期间无法和Leader保持连接。
(2)而当一台机器进入Leader选举流程时,当前集群也可能会处于以下两种状态:
• 集群中本来就已经存在一个Leader。
对于第一种已经存在Leader的情况,机器试图去选举Leader时,会被告知当前服务器的Leader信息,对于该机器来说,仅仅需要和Leader机器建立连接,并进行状态同步即可。
• 集群中确实不存在Leader。
假设ZooKeeper由5台服务器组成,SID分别为1、2、3、4、5,ZXID分别为8、8、8、7、7,并且此时SID为3的服务器是Leader。某一时刻,3和5服务器出现故障,因此开始进行Leader选举。
- 机器投票情况
| SID(服务器ID) | EPOCH(每个Leader任期的代号) | ZXID(事务ID) |
|---|---|---|
| 1 | 1 | 8 |
| 2 | 1 | 8 |
| 4 | 1 | 7 |
- 选举Leader规则:
①EPOCH大的直接胜出 ②EPOCH相同,事务id大的胜出 ③事务id相同,服务器id大的胜出
- 所以服务器ID 为2的当选Leader
3.4 ZK 集群启动停止脚本
1、在 hadoop102 的/home/ywl/bin 目录下创建脚本
[root@hadoop102 bin]$ vim zk.sh
- 1
- 在脚本中编写如下内容
#!/bin/bash case $1 in "start"){ for i in hadoop102 hadoop103 hadoop104 do echo ---------- zookeeper $i 启动 ------------ ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start" done };; "stop"){ for i in hadoop102 hadoop103 hadoop104 do echo ---------- zookeeper $i 停止 ------------ ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop" done };; "status"){ for i in hadoop102 hadoop103 hadoop104 do echo ---------- zookeeper $i 状态 ------------ ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status" done };; esac

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
2、增加脚本执行权限
[root@hadoop102 bin]$ chmod 777 zk.sh
- 1
3、使用脚本
(1)Zookeeper 集群启动脚本
[root@hadoop102 module]$ zk.sh start
- 1
(2)Zookeeper 集群停止脚本
[root@hadoop102 module]$ zk.sh stop
- 1
(3)查看集群状态
[root@hadoop102 module]$ zk.sh status
- 1
4、同步脚本
[root@hadoop102 bin]$ xsync zk.sh
- 1
3.5 客户端命令行操作
3.5.1 命令行语法
| 命令基本语法 | 功能描述 |
|---|---|
| help | 显示所有操作命令 |
| ls path | 使用 ls 命令来查看当前 znode 的子节点 [可监听] ,-w 监听子节点变化,-s 附加次级信息 |
| create | 普通创建,-s 含有序列号,-e 临时(重启或者超时消失) |
| get path | 获得节点的值 [可监听] ,-w 监听节点内容变化 -s 附加次级信息 |
| set | 设置节点的具体值 |
| stat | 查看节点状态 |
| delete | 删除节点 |
| deleteall | 递归删除节点 |
1、启动客户端,连接集群,直接不指定-server连接的是本地
[root@hadoop102 zookeeper-3.5.7]$ bin/zkCli.sh -server hadoop102:2181
- 1
3.5.2 znode 节点数据信息
1、查看当前znode中所包含的内容
[zk: hadoop102:2181(CONNECTED) 0] ls /
[zookeeper]
- 1
- 2
2、查看当前节点详细数据
[zk: hadoop102:2181(CONNECTED) 2] ls -s /
[zookeeper]cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x0
cversion = -1
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
(1)czxid:创建节点的事务 zxid
每次修改 ZooKeeper 状态都会产生一个 ZooKeeper 事务 ID。事务 ID 是 ZooKeeper 中所有修改总的次序。每次修改都有唯一的 zxid,如果 zxid1 小于 zxid2,那么 zxid1 在 zxid2 之前发生。
(2)ctime:znode 被创建的毫秒数(从 1970 年开始)
(3)mzxid:znode 最后更新的事务 zxid
(4)mtime:znode 最后修改的毫秒数(从 1970 年开始)
(5)pZxid:znode 最后更新的子节点 zxid
(6)cversion:znode 子节点变化号,znode 子节点修改次数
(7)dataversion:znode 数据变化号
(8)aclVersion:znode 访问控制列表的变化号
(9)ephemeralOwner:如果是临时节点,这个是 znode 拥有者的 session id。如果不是临时节点则是 0。 (10)dataLength:znode 的数据长度
(11)numChildren:znode 子节点数量
3.5.3 节点类型(持久/短暂 | 有序号/无序号)
短暂(Ephemeral):客户端和服务器端断开连接后,创建的节点自己删除
持久(Persistent):客户端和服务器端断开连接后,创建的节点不删除
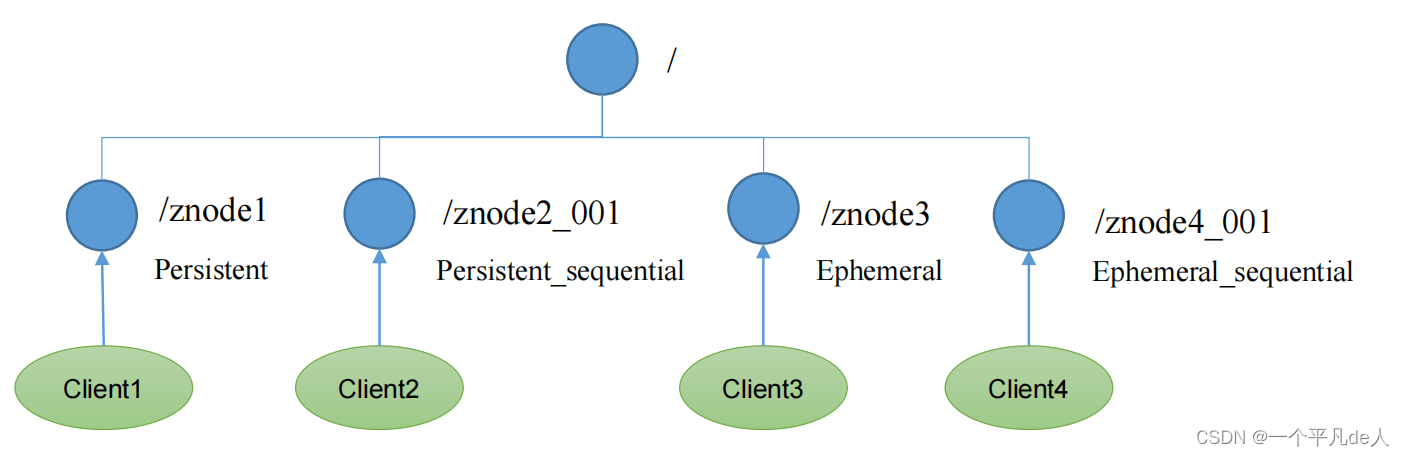
(1)持久化目录节点(无序号)
客户端与Zookeeper断开连接后,该节点依旧存在
(2)持久化顺序编号目录节点(有序号)
客户端与Zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
(3)临时目录节点(无序号)
客户端与Zookeeper断开连接后,该节点被删除
(4)临时顺序编号目录节点(有序号)
客户端与 Zookeeper 断开连接后 , 该 节 点 被 删 除 , 只是Zookeeper给该节点名称进行顺序编号。
说明:创建znode时设置顺序标识,znode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护
注意:在分布式系统中,顺序号可以被用于为所有的事件进行全局排序,这样客户端可以通过顺序号推断事件的顺序
创建节点</

