
目标检测之Dynamic Head: Unifying Object Detection Heads with Attentions_头部目标检测
赞
踩
cvpr2021
论文:https://arxiv.org/pdf/2106.08322v1.pdf
代码:https://github.com/microsoft/DynamicHead
1、摘要
作者认为目标检测的头部是由三个部分组成:首先,头部应该是尺度感知的,因为多个具有极大不同尺度的物体经常共存于一幅图像中,FPN。其次,头部应该是空间感知的,因为物体通常在不同的视点下以不同的形状、旋转和位置出现,膨胀卷积、可变形卷积。第三,头部需要具有任务感知,因为目标可以有不同的表示形式(例如边界框、中心和角点),它们拥有完全不同的目标和约束没,RPN。
本文的动态检测头就是通过注意力学习将这三个任务集中在一起解决。
2.实现方法unified attention
1.尺度感知:物体尺度上的差异合起所在不同的特征层有关,可以通过改进不同尺度的特征来提高尺度感知
2.空间感知:改进不同空间位置的表示学习可以提高目标检测的空间感知能力
3.任务感知:改进不同通道的特征提取方式来提高任务感知能力
R
L
×
H
×
W
×
C
R^{L×H×W×C}
RL×H×W×C令
S
=
H
∗
W
S=H*W
S=H∗W得
R
L
×
S
×
C
R^{L×S×C}
RL×S×C分别代表着Layer,Space,Channel。分别在level-wise,spatial-wise,和channel-wise等每个独特的特征维度上分别地应用attention 机制:
W
(
F
)
=
π
c
(
π
s
(
π
l
(
F
)
∗
F
)
∗
F
)
W(F)=π_c(π_s(π_l(F)*F)*F)
W(F)=πc(πs(πl(F)∗F)∗F)

2.1Spatial-aware Attention
将这个模块分成两步:先用可变卷积学习稀疏的空间注意力,然后在同样的位置上,对不同层次的特征进行集成。
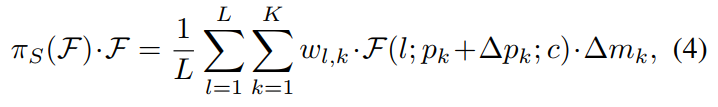
K
K
K是稀疏采样地点的数量,
p
k
+
Δ
p
k
p_{k}+\Delta p_{k}
pk+Δpk是self-learned空间位置的偏移量,通过自学习空间补偿
Δ
p
k
\Delta p_{k}
Δpk来关注有区别的区域,并且
Δ
m
k
\Delta m_{k}
Δmk是位置
p
k
p_{k}
pk处的自学习重要标量。两者都从
F
\mathcal{F}
F的输入特性从平均水平。
self.DyConv = nn.ModuleList()
self.DyConv.append(conv_func(in_channels, out_channels, 1))#只改stride和通道数的可变性卷积
self.DyConv.append(conv_func(in_channels, out_channels, 1))
self.DyConv.append(conv_func(in_channels, out_channels, 2))
- 1
- 2
- 3
- 4
2.2Scale-aware Attention πL
首先基于语义重要性,动态的融合融合特征
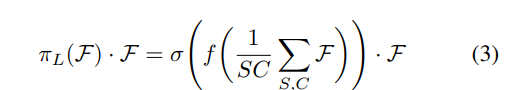
f为和1*1卷积类似的线性函数,σ为sigmoid函数
self.AttnConv = nn.Sequential(
nn.AdaptiveAvgPool2d(1),#自适应均值池化
nn.Conv2d(in_channels, 1, kernel_size=1),
nn.ReLU(inplace=True))
self.h_sigmoid = h_sigmoid()
spa_pyr_attn = self.h_sigmoid(torch.stack(attn_fea))
mean_fea = torch.mean(res_fea * spa_pyr_attn, dim=0, keepdim=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.3Task-aware Attention
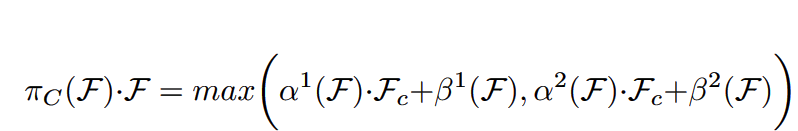
通过开关max()函数来控制是否学习这部分的注意力,这部分内容感觉有点牵强.αβ都是超参数,配合max函数来控制是否激活注意力的,fc是通道切片。动态的对通道进行开关,来适应不同的任务。
3.算法流程
在特征金字塔上的应用:首先在特征金字塔上应用scale-aware attention和spatial-aware attention,然后ROI-pooling layer之后开始使用task-aware attention来替代原来的全连接层


