
- 1MySQL数据库系列(六):MySQL之索引数据结构分析_索引文件数据分析
- 2termux+cpolar+codeserver 自启动 打造远程开发环境_cpolar code server
- 3虹科Pico汽车示波器 | 免拆诊断案例 | 2006 款林肯领航员车发动机怠速抖动
- 4oracle的基本使用(建表,操作表等)_oracle建表
- 5发那科机器人上位机,C#,语音识别控制,FANUC_c#发那科机器人
- 6RabbitMQ和RocketMQ区别 | RabbitMQ和RocketMQ优缺点解析 | 消息队列中间件对比:RabbitMQ vs RocketMQ - 选择哪个适合您的业务需求?_rabbitmq rocketmq
- 7CrossOver 24.0.0 for mac 震撼发布 2024最新下载安装详细图文教程_codeweavers crossover 24下载
- 8【GitHub项目推荐--推荐,一个虚拟服装试穿开源AI项目】【转载】_ootdiffusion模型下载
- 9医院手术室麻醉信息管理系统源码 自动生成麻醉的各种医疗文书(手术风险评估表、手术安全核查表)
- 10idea中git基本操作命令_idea拉去指定分支
什么是分区分桶?
赞
踩
一、分区
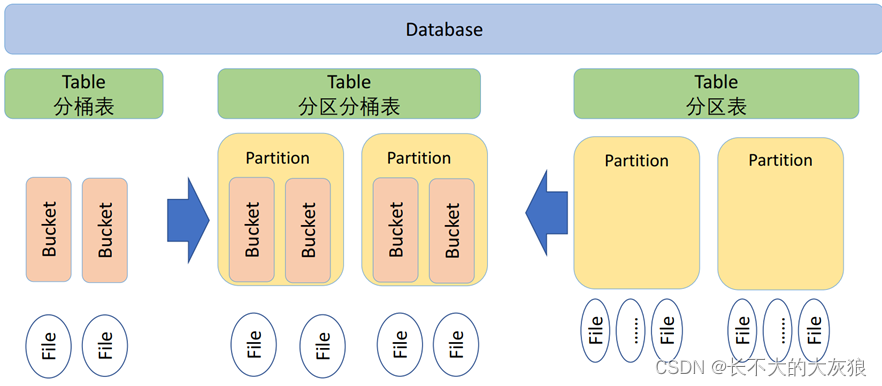
1、什么是分区
将整个表的数据在存储时,按照 ”分区键的列值“ 划分成多个子目录来存储。区从形式上可以理解为文件夹。
注意:
子目录名称就是分区名(分区键的列值)。
2、为什么要分区
随着系统运行时间的增加,表的数据量会越来越大,而Hive查询数据的数据的时候通常使用的是"全表扫描",这样将会导致查询效率大大的降低。 Hive引进的分区技术,能避免Hive全表扫描,提升查询效率。
比如我们要收集某个大型网站的日志数据,一个网站每天的日志数据存在同一张表上,由于每天会生成大量的日志,导致数据表的内容巨大,在查询时进行全表扫描耗费的资源非常多。那其实这个情况下,我们可以按照日期对数据表进行分区,不同日期的数据存放在不同的分区,在查询时只要指定分区字段的值就可以直接从该分区查找。
3、创建分区表
创建分区表的时候,要通过关键字 partitioned by (name string)声明该表是分区表,并且是按照字段name进行分区,name值一致的所有记录存放在一个分区中,分区属性name的类型是string类型。当然,可以依据多个列进行分区,即对某个分区的数据按照某些列继续分区。
注意:
千万不要以为是对属性表中真正存在的列按照属性值的异同进行分区。比如上面的分区依据的列name并不真正的存在于数据表中,是我们为了方便管理添加的一个伪列,这个列的值也是我们人为规定的,不是从数据表中读取之后根据值的不同将其分区。我们并不能按照某个数据表中真实存在的列,如userid来分区。
二、分桶
1、什么是分桶
分桶是相对分区进行更细粒度的划分。桶是通过对指定列进行哈希计算来实现的,通过哈希值将一个列名下的数据切分为一组桶,并使每个桶对应于该列名下的一个存储文件。
注意:
在hdfs目录上,桶是以文件的形式存在的,而不是像分区那样以文件夹的形式存在。
2、为什么要分桶
在分区数量过于庞大以至于可能导致文件系统崩溃时,我们就需要使用分桶来解决问题了。
分区中的数据可以被进一步拆分成桶,不同于分区对列直接进行拆分,桶往往使用列的哈希值对数据打散,并分发到各个不同的桶中从而完成数据的分桶过程。
注意
hive使用对分桶所用的值进行hash,并用hash结果除以桶的个数做取余运算的方式来分桶,保证了每个桶中都有数据,但每个桶中的数据条数不一定相等。
3、 创建分桶
与分区不同的是,分区依据的不是真实数据表文件中的列,而是我们指定的伪列,但是分桶是依据数据表中真实的列而不是伪列。所以在指定分区依据的列的时候要指定列的类型,因为在数据表文件中不存在这个列,相当于新建一个列。而分桶依据的是表中已经存在的列,这个列的数据类型显然是已知的,所以不需要指定列的类型。
参考文章
[1] Hive分区、分桶操作及其比较
[2] 分区、分桶语法


