
- 1Python编程入门学什么?_python程序设计学什么
- 2数组在Java中的运用_java 数组使用
- 3【问题记录】02 Linux服务器安装MySql数据库报错:Failing package is: mysql-community-server GPG Keys are configured as_linux mysql8 yum安装 gpg keys are configured
- 4软考证到底有多大个鸟用?_软考有什么用
- 5央视的AI动画《AI我中华》宣传视频,原来用AI工具Stable Diffusion制作,竟然这么简单?
- 6给大家推荐一个用Java开发的开源的AI模型_java 开源的ai
- 7虚拟机red hat linux下oracle9.2i的安装配置_oraclelinux9.2 安装oracle
- 8<网络安全>《83 微课堂<国家数据要素总体框架>》
- 9鸿蒙开发 - 常用UI组件介绍_鸿蒙开发中其他组件知识点
- 10抖音短视频数据抓取实战系列(十一)——Appium与Mitmproxy联合-自动取存抖音用户信息_appnium抓取数据
算法原理-Yolo v2_yolov2算法原理
赞
踩
相比于YOLO v1,YOLO v2的改进如下:
1)batch normalization(批归一化)
2)使用高分辨率图像微调分类模型
YOLO v1使用ImageNet的图像分类样本采用 224*224 作为输入,来训练CNN卷积层。然后在训练对象检测时,检测用的图像样本采用更高分辨率的 448*448 的图像作为输入。但这样切换对模型性能有一定影响。
YOLO2在采用 224*224 图像进行分类模型预训练后,再采用 448*448 的高分辨率样本对分类模型进行微调(10个epoch),使网络特征逐渐适应 448*448 的分辨率。然后再使用 448*448 的检测样本进行训练,缓解了分辨率突然切换造成的影响。
3)采用先验框(Anchor Boxes)Convolutional With Anchor Boxes
之前的YOLO v1利用全连接层的数据完成边框的预测,导致丢失较多的空间信息,定位不准。作者在这一版本中借鉴了Faster R-CNN中的anc hor思想: 简单理解为卷积特征图上进行滑窗采样,每个中心预测9种不同大小和比例的建议框。由于都是卷积不需要reshape,很好的保留的空间信息,最终特征图的每个特征点和原图的每个cell一一对应。而且用预测相对偏移(offset)取代直接预测坐标简化了问题,方便网络学习。
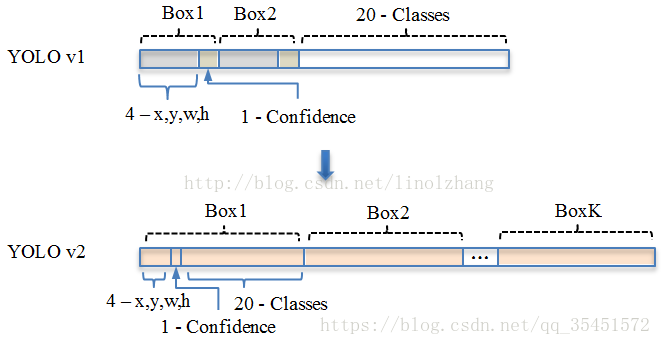
YOLO v1: S*S* (B*5 + C) => 7*7(2*5+20)
其中B对应Box数量,5对应 Rect 定位+置信度。每个Grid只能预测对应两个Box,这两个Box共用一个分类结果(20 classes),这是很不合理的临时方案。
YOLO v2: S*S*K* (5 + C) => 13*13*9(5+20)
分辨率改成了13*13,更细的格子划分对小目标适应更好,再加上与Faster一样的K=9,计算量增加了不少。通过Anchor Box改进,mAP由69.5下降到69.2,Recall由81%提升到了88%。
为了引入anchor boxes来预测bounding boxes,作者在网络中果断去掉了全连接层。首先,作者去掉了后面的一个池化层以确保输出的卷积特征图有更高的分辨率。然后,通过缩减网络,让图片输入分辨率为416 * 416,这一步的目的是为了让后面产生的卷积特征图宽高都为奇数,这样就可以产生一个center cell。作者观察到,大物体通常占据了图像的中间位置, 就可以只用中心的一个cell来预测这些物体的位置,否则就要用中间的4个cell来进行预测,这个技巧可稍稍提升效率。最后,YOLOv2使用了卷积层降采样(factor为32),使得输入卷积网络的416 * 416图片最终得到13 * 13的卷积特征图(416/32=13)。
4)聚类提取先验框尺度
之前先验框都是手工设定的,YOLO2尝试统计出更符合样本中对象尺寸的先验框,这样就可以减少网络微调先验框到实际位置的难度。YOLO2的做法是对训练集中标注的边框进行聚类分析,以寻找尽可能匹配样本的边框尺寸。
5)约束预测边框的位置
6)passthrough层检测细粒度特征
对象检测面临的一个问题是图像中对象会有大有小,输入图像经过多层网络提取特征,最后输出的特征图中(比如YOLO2中输入416*416经过卷积网络下采样最后输出是13*13),较小的对象可能特征已经不明显甚至被忽略掉了。为了更好的检测出一些比较小的对象,最后输出的特征图需要保留一些更细节的信息。
YOLO2引入一种称为passthrough层的方法在特征图中保留一些细节信息。具体来说,就是在最后一个pooling之前,特征图的大小是26*26*512,将其1拆4,直接传递(passthrough)到pooling后(并且又经过一组卷积)的特征图,两者叠加到一起作为输出的特征图。

7)多尺度图像训练
因为去掉了全连接层,YOLO2可以输入任何尺寸的图像。因为整个网络下采样倍数是32,作者采用了{320,352,...,608}等10种输入图像的尺寸,这些尺寸的输入图像对应输出的特征图宽和高是{10,11,...19}。训练时每10个batch就随机更换一种尺寸,使网络能够适应各种大小的对象检测。
8)更快的神经网络模型
为了进一步提升速度,YOLO2提出了Darknet-19(有19个卷积层和5个MaxPooling层)网络结构。DarkNet-19比VGG-16小一些
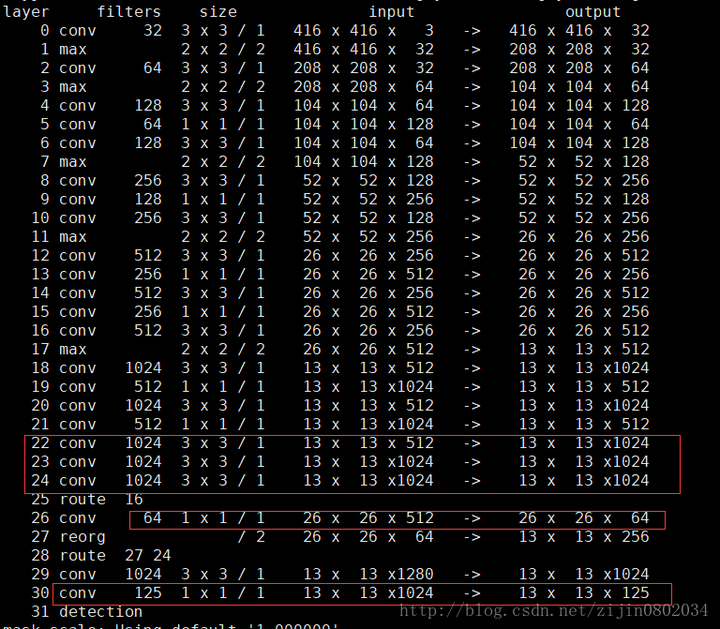
YOLO2的训练主要包括三个阶段。第一阶段就是先在ImageNet分类数据集上预训练Darknet-19,此时模型输入为 224*224 ,共训练160个epochs。然后第二阶段将网络的输入调整为 448*448 ,继续在ImageNet数据集上finetune分类模型,训练10个epochs,此时分类模型的top-1准确度为76.5%,而top-5准确度为93.3%。第三个阶段就是修改Darknet-19分类模型为检测模型,移除最后一个卷积层、global avgpooling层以及softmax层,并且新增了三个 3*3*1024卷积层,同时增加了一个passthrough层,最后使用 1*1 卷积层输出预测结果,输出的channels数为:num_anchors*(5+num_classes),和训练采用的数据集有关系。
------------------------------------------------------------------------------------------
损失函数定义
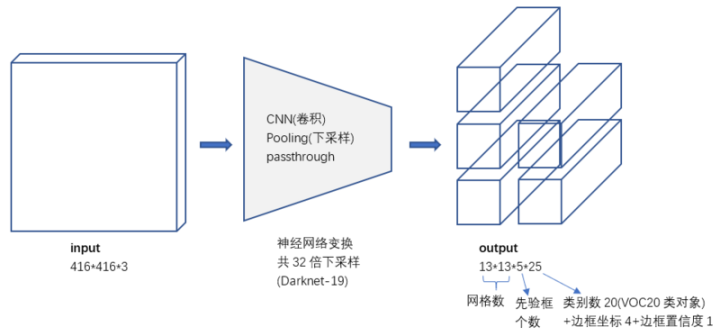
输入输出:
损失函数:


