- 1git push提示non-fast-forward的解决方法_you need 'push' rights with 'force' flag set to do
- 2RuntimeError: CUDA out of memory. Tried to allocate 5. If reserved memory is >> allocated memory_if reserved memory is >> allocated memory try sett
- 3html/html5学习
- 4Docker 镜像库国内加速的几种方法_docker 加速
- 5Linux下redis配置参数说明_linux readis 设置值
- 6中国的程序员数量是否已经饱和或者过剩?_每年毕业生加培训出来的软件开发 有多少人
- 7飞凌嵌入式即将亮相德国纽伦堡「Embedded World 2024」
- 8【Java】实现顺序表基本的操作(数据结构)_顺序表的基本操作 java实现
- 9nvm的安装和使用(详细)
- 10flask教程8:模板_flask 模板
docker安装flink_docker flink
赞
踩
docker安装flink
5.1、拉取flink镜像,创建网络
docker pull flink
docker network create flink-network
- 1
- 2
5.2、创建 jobmanager
# 创建 JobManager
docker run \
-itd \
--name=jobmanager \
--publish 8081:8081 \
--network flink-network \
--env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" \
flink:latest jobmanager
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
5.3、创建 TaskManager
# 创建 TaskManager
docker run \
-itd \
--name=taskmanager \
--network flink-network \
--env FLINK_PROPERTIES="jobmanager.rpc.address: jobmanager" \
flink:latest taskmanager
- 1
- 2
- 3
- 4
- 5
- 6
- 7
5.4、访问公网ip
http://localhost:8081/
访问 http://150.158.119.225/:8081/
5.5 修改Task Slots
默认的Slots num是1,我们可以修改为5:
修改的目录是jobmanager和taskmanager的/opt/flink/conf的flink-conf.yaml文件:
修改taskmanager.numberOfTaskSlots:即可。
注意:默认的docker容器中没有vi/vim命令,可以使用docker cp命令,复制出来修改,然后在复制回去,如下:
docker cp taskmanager:/opt/flink/conf/flink-conf.yaml .
docker cp flink-conf.yaml taskmanager:/opt/flink/conf/
- 1
- 2
5.6、通过flinksql消费Kafka
Docker安装kafka 3.5
并且通过python,简单写一个生产者
Python生产、消费Kafka
5.7 导入flink-sql-connector-kafka jar
顾名思义,用于连接flinksql和kafka。
进入flink
docker exec -it jobmanager /bin/bash
- 1
进入 flink的bin目录
cd /opt/flink/bin
- 1
查看flink版本:
flink --version
- 1
根据自己的flink版本,下载对应的 flink-sql-connector-kafka jar包
https://mvnrepository.com/artifact/org.apache.flink/flink-sql-connector-kafka
因为我是1.18.0,所以选择下图的版本包:
将下载的jar包,分别在jobmanager,taskmanager /opt/flink/lib目录下,注意,是两个都要放,如下图:
可以使用docker cp test.txt jobmanager:/opt/flink/lib命令,用户宿主机和docker容器文件传输。把test.txt换成对应的jar包即可
docker cp test.txt jobmanager:/opt/flink/lib
docker cp test.txt taskmanager:/opt/flink/lib
- 1
- 2
5.8 flinksql消费kafka
java结合日志
kafka.send("GatewayLog", JSONUtil.toJsonStr(gatewayLog));
- 1
GatewayLog是topic
yaml的服务配置
spring:
kafka:
bootstrap-servers: "10.10.10.155:9092"
consumer:
group-id: "teleGatewayGroup"
- 1
- 2
- 3
- 4
- 5
我在本地生成了一条log,将使用flinksql处理这个数据。
进入jobmanager中,执行
cd /opt/flink/bin
sql-client.sh
- 1
- 2
Flink SQL执行以下语句:
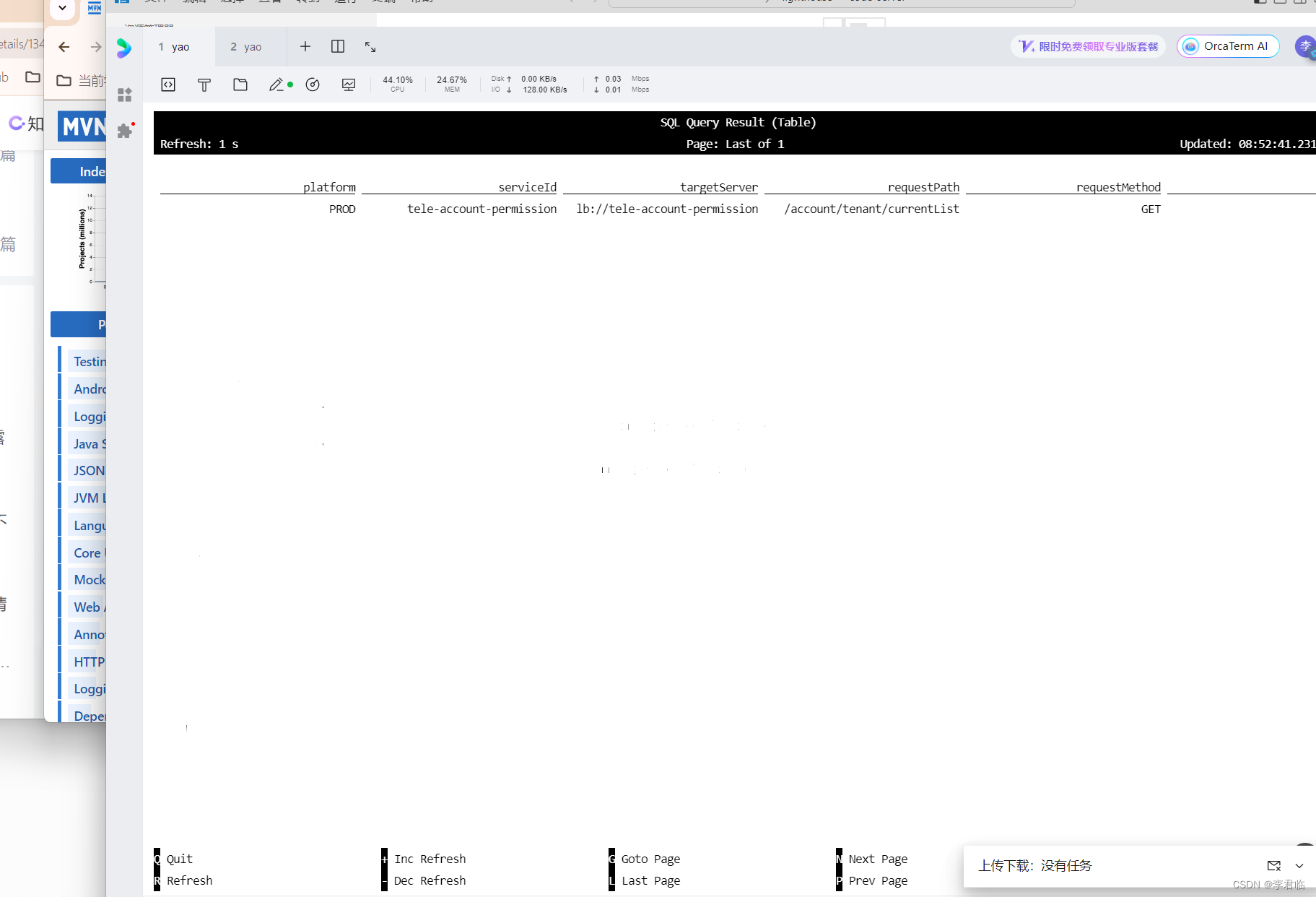
CREATE TABLE GatewayLog ( platform VARCHAR, serviceId VARCHAR, targetServer VARCHAR, requestPath VARCHAR, requestMethod VARCHAR, schema VARCHAR, requestContentType VARCHAR, headers VARCHAR, requestBody VARCHAR, ip VARCHAR, startTime TIMESTAMP, endTime VARCHAR, executeTime VARCHAR, status VARCHAR, nickName VARCHAR, account VARCHAR, accountType VARCHAR, serviceName VARCHAR, orgCode VARCHAR ) WITH ( 'connector' = 'kafka', 'topic' = 'GatewayLog', 'properties.bootstrap.servers' = '150.158.119.225:9092', 'properties.group.id' = 'flinKGroup', 'scan.startup.mode' = 'earliest-offset', 'format' = 'json' ); select * from GatewayLog;

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
可以看到Flink在消费kafka数据,如下图:
中间缺少很多包。
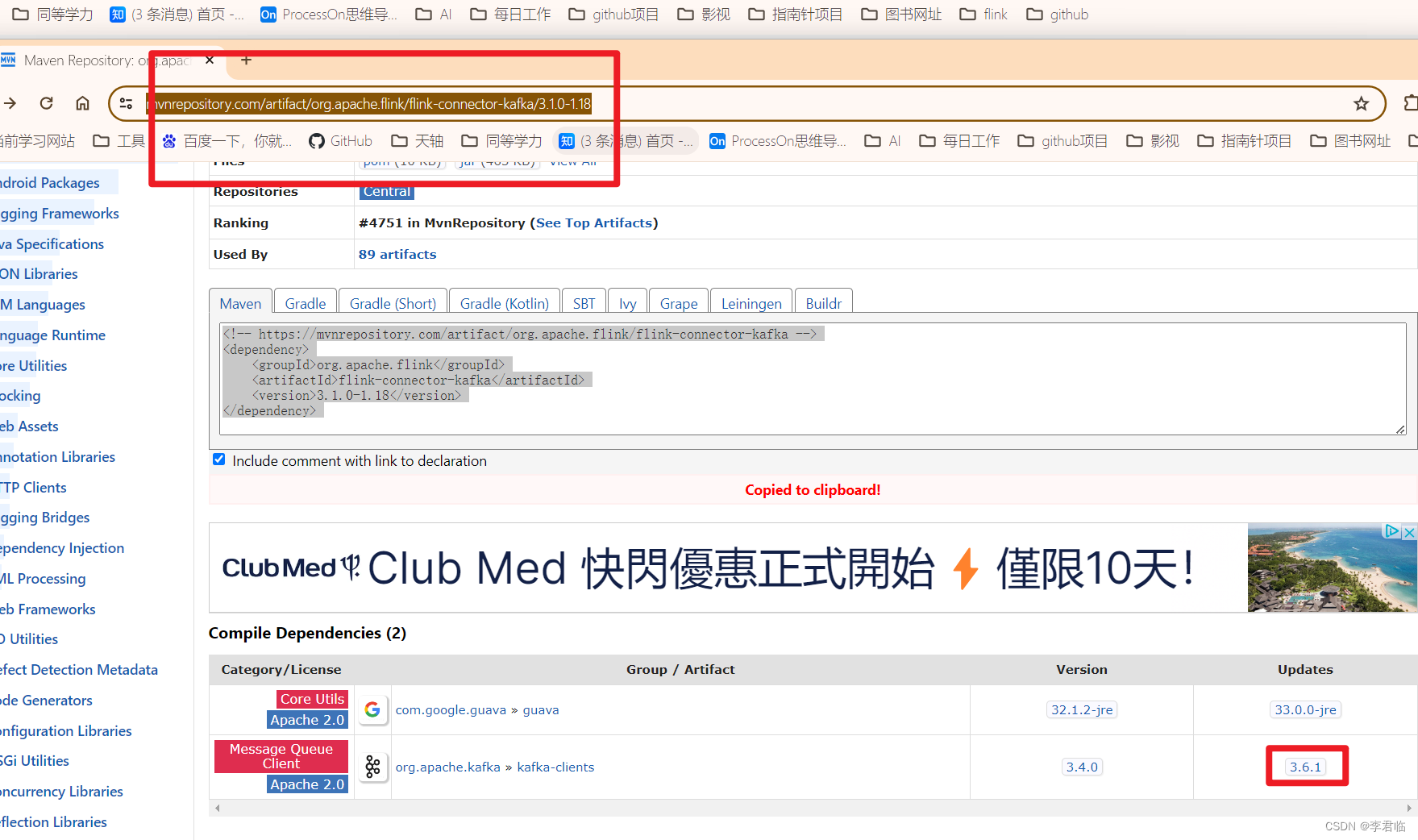
flink-connector-kafka
https://mvnrepository.com/artifact/org.apache.flink/flink-connector-kafka/3.1.0-1.18
- 1
依赖的kafka-clients
https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients/3.6.1
- 1
然后在Linux需要看权限问题。
chmod -R 777 /lib
- 1
把文件夹都改成777 所有人。
然后执行
sql最好先改成varchar,变成成功。
最后select * from table
执行成功。