
- 1王爽 汇编语言 第三章 实验二_汇编语言实验二王爽
- 2从分布式一致性算法到区块链共识算法(一)_一般来讲,强一致性
- 3论文阅读:FLGCNN: A novel fully convolutional neural network for end-to-endmonaural speech enhancement_flgcnn: a novel fully con- volutional neural netwo
- 4mysql数据库:迁移数据目录至另一台服务器步骤_mysql数据库迁移到另一台服务器
- 5KG-开源项目:QASystemOnMedicalKG【以疾病为中心的一定规模医药领域知识图谱,并以该知识图谱完成自动问答与分析服务】
- 6paddle detection 配置文件怎么实例化的 代码梳理 -----(regiester)
- 7【网站项目】游戏美术外包管理信息系统
- 8Navicat premium 15出现的bug集合_navicat premium 筛选 按不了
- 9uniapp - [安卓|苹果]实现App端引入高德地图,详细获取当前用户手机定位、两个地点的路线规划及相关示例代码,uniapp安卓Android平台软件下使用高德地图,获取当前位置信息及规划路线_uni-app 安卓app中导入高德地图
- 10GPT提示词系统学习-第三课-规范化提示让样本走在提示词前_gpt提示语 qa问答
12.Kafka系列之Stream核心原理(一)_kafka stream
赞
踩
Kafka Streams is a client library for processing and analyzing data stored in Kafka. It builds upon important stream processing concepts such as properly distinguishing between event time and processing time, windowing support, and simple yet efficient management and real-time querying of application state.
Kafka Streams 是一个客户端库,用于处理和分析存储在 Kafka 中的数据。它建立在重要的流处理概念之上,例如正确区分事件时间和处理时间、窗口支持以及简单而高效的管理和应用程序状态的实时查询
Kafka Streams has a low barrier to entry: You can quickly write and run a small-scale proof-of-concept on a single machine; and you only need to run additional instances of your application on multiple machines to scale up to high-volume production workloads. Kafka Streams transparently handles the load balancing of multiple instances of the same application by leveraging Kafka’s parallelism model
Kafka Streams入门门槛低:您可以在单机上快速编写和运行小规模的概念验证;并且您只需要在多台机器上运行应用程序的额外实例即可扩展到大批量生产工作负载。Kafka Streams 通过利用 Kafka 的并行模型透明地处理同一应用程序的多个实例的负载平衡
Some highlights of Kafka Streams:
Kafka Streams 的一些亮点:
-
Designed as a simple and lightweight client library, which can be easily embedded in any Java application and integrated with any existing packaging, deployment and operational tools that users have for their streaming applications.
设计为简单轻量级的客户端库,可以轻松嵌入到任何 Java 应用程序中,并与用户为其流式应用程序拥有的任何现有打包、部署和操作工具集成 -
Has no external dependencies on systems other than Apache Kafka itself as the internal messaging layer; notably, it uses Kafka’s partitioning model to horizontally scale processing while maintaining strong ordering guarantees.
除了作为内部消息传递层的Apache Kafka 本身之外,对系统没有外部依赖;值得注意的是,它使用 Kafka 的分区模型来水平扩展处理,同时保持强大的排序保证 -
Supports fault-tolerant local state, which enables very fast and efficient stateful operations like windowed joins and aggregations.
支持容错本地状态,这可以实现非常快速和高效的状态操作,如窗口连接和聚合 -
Supports exactly-once processing semantics to guarantee that each record will be processed once and only once even when there is a failure on either Streams clients or Kafka brokers in the middle of processing.
支持exactly-once处理语义以保证每条记录将被处理一次且仅一次,即使在处理过程中 Streams 客户端或 Kafka 代理出现故障也是如此 -
Employs one-record-at-a-time processing to achieve millisecond processing latency, and supports event-time based windowing operations with out-of-order arrival of records.
采用一次一条记录处理以实现毫秒级处理延迟,并支持基于事件时间的窗口操作,记录无序到达 -
Offers necessary stream processing primitives, along with a high-level Streams DSL and a low-level Processor API
提供必要的流处理原语,以及高级 Streams DSL和低级 Processor API
We first summarize the key concepts of Kafka Streams
我们首先总结一下 Kafka Streams 的关键概念。
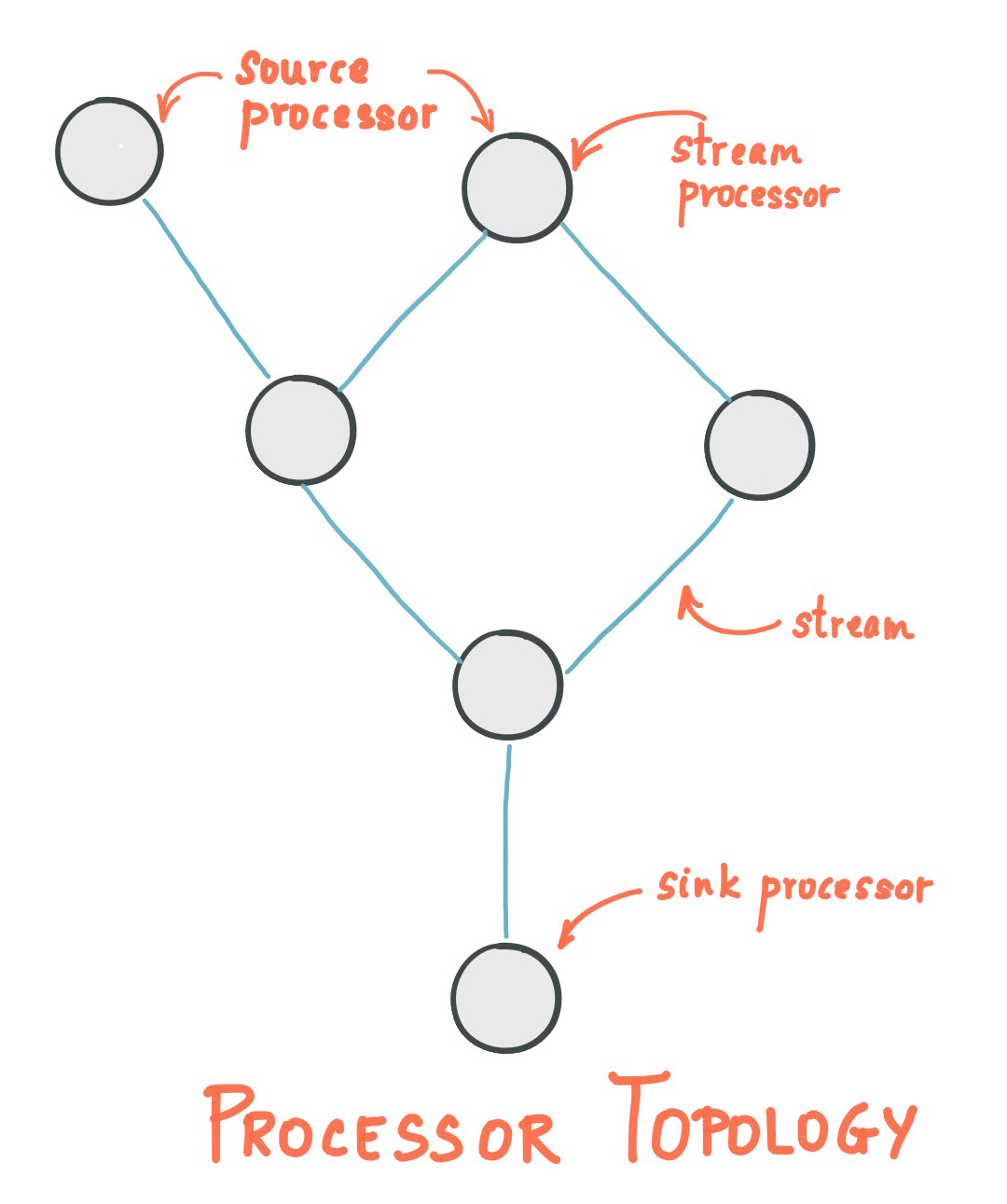
Stream Processing Topology流处理拓扑
-
A stream is the most important abstraction provided by Kafka Streams: it represents an unbounded, continuously updating data set. A stream is an ordered, replayable, and fault-tolerant sequence of immutable data records, where a data record is defined as a key-value pair.
流是 Kafka Streams 提供的最重要的抽象:它代表一个无限的、不断更新的数据集。流是不可变数据记录的有序、可重放和容错序列,其中数据记录定义为键值对 -
A stream processing application is any program that makes use of the Kafka Streams library. It defines its computational logic through one or more processor topologies, where a processor topology is a graph of stream processors (nodes) that are connected by streams (edges).
流处理应用程序是任何使用 Kafka Streams 库的程序。它通过一个或多个处理器拓扑定义其计算逻辑,其中处理器拓扑是由流(边)连接的流处理器(节点)的图形 -
A stream processor is a node in the processor topology; it represents a processing step to transform data in streams by receiving one input record at a time from its upstream processors in the topology, applying its operation to it, and may subsequently produce one or more output records to its downstream processors
流处理器是处理器拓扑中的一个节点;它表示一个处理步骤,通过一次从拓扑中的上游处理器接收一个输入记录,将其操作应用于它,并可能随后向其下游处理器产生一个或多个输出记录,从而转换流中的数据
There are two special processors in the topology:
拓扑中有两个特殊的处理器:
-
Source Processor: A source processor is a special type of stream processor that does not have any upstream processors. It produces an input stream to its topology from one or multiple Kafka topics by consuming records from these topics and forwarding them to its down-stream processors.
源处理器:源处理器是一种特殊类型的流处理器,它没有任何上游处理器。它通过使用来自这些主题的记录并将它们转发到其下游处理器,从一个或多个 Kafka 主题生成到其拓扑的输入流。 -
Sink Processor: A sink processor is a special type of stream processor that does not have down-stream processors. It sends any received records from its up-stream processors to a specified Kafka topic
接收器处理器:接收器处理器是一种特殊类型的流处理器,没有下游处理器。它将从其上游处理器接收到的任何记录发送到指定的 Kafka 主题
Note that in normal processor nodes other remote systems can also be accessed while processing the current record. Therefore the processed results can either be streamed back into Kafka or written to an external system
请注意,在正常的处理器节点中,在处理当前记录时也可以访问其他远程系统。因此,处理后的结果可以流回 Kafka 或写入外部系统
Kafka Streams offers two ways to define the stream processing topology: the Kafka Streams DSL provides the most common data transformation operations such as map, filter, join and aggregations out of the box; the lower-level Processor API allows developers define and connect custom processors as well as to interact with state stores.
Kafka Streams 提供了两种定义流处理拓扑的方式:Kafka Streams DSL提供了最常见的数据转换操作,例如map filter join aggregations,开箱即用;较低级别的处理器 API允许开发人员定义和连接自定义处理器以及与状态存储交互。
A processor topology is merely a logical abstraction for your stream processing code. At runtime, the logical topology is instantiated and replicated inside the application for parallel processing
处理器拓扑仅仅是流处理代码的逻辑抽象。在运行时,逻辑拓扑在应用程序内部被实例化和复制以进行并行处理
Time时间
A critical aspect in stream processing is the notion of time, and how it is modeled and integrated. For example, some operations such as windowing are defined based on time boundaries.
流处理的一个关键方面是时间 的概念,以及它是如何建模和集成的。例如,某些操作(例如窗口)是根据时间边界定义的
Common notions of time in streams are:
流中时间的常见概念是:
-
Event time - The point in time when an event or data record occurred, i.e. was originally created “at the source”. Example: If the event is a geo-location change reported by a GPS sensor in a car, then the associated event-time would be the time when the GPS sensor captured the location change.
事件时间——事件或数据记录发生的时间点,即最初“在源头”创建的时间点。例如:如果事件是由汽车中的 GPS 传感器报告的地理位置变化,则关联的事件时间将是 GPS 传感器捕获位置变化的时间 -
Processing time - The point in time when the event or data record happens to be processed by the stream processing application, i.e. when the record is being consumed. The processing time may be milliseconds, hours, or days etc. later than the original event time. Example: Imagine an analytics application that reads and processes the geo-location data reported from car sensors to present it to a fleet management dashboard. Here, processing-time in the analytics application might be milliseconds or seconds (e.g. for real-time pipelines based on Apache Kafka and Kafka Streams) or hours (e.g. for batch pipelines based on Apache Hadoop or Apache Spark) after event-time.
处理时间——事件或数据记录恰好被流处理应用程序处理的时间点,即记录被消费的时间点。处理时间可能比原始事件时间晚几毫秒、几小时或几天等。例如:想象一个分析应用程序读取和处理从汽车传感器报告的地理位置数据,以将其呈现给车队管理仪表板。在这里,分析应用程序中的处理时间可能是事件时间之后的毫秒或秒(例如,对于基于 Apache Kafka 和 Kafka Streams 的实时管道)或小时(例如,对于基于 Apache Hadoop 或 Apache Spark 的批处理管道) -
Ingestion time - The point in time when an event or data record is stored in a topic partition by a Kafka broker. The difference to event time is that this ingestion timestamp is generated when the record is appended to the target topic by the Kafka broker, not when the record is created “at the source”. The difference to processing time is that processing time is when the stream processing application processes the record. For example, if a record is never processed, there is no notion of processing time for it, but it still has an ingestion time.
摄取时间——事件或数据记录被 Kafka 代理存储在主题分区中的时间点。与事件时间的不同之处在于,此摄取时间戳是在 Kafka 代理将记录附加到目标主题时生成的,而不是在“在源”创建记录时生成的。与处理时间的区别在于处理时间是流处理应用程序处理记录的时间。例如,如果一条记录从未被处理过,那么它就没有处理时间的概念,但它仍然有一个摄取时间
The choice between event-time and ingestion-time is actually done through the configuration of Kafka (not Kafka Streams): From Kafka 0.10.x onwards, timestamps are automatically embedded into Kafka messages. Depending on Kafka’s configuration these timestamps represent event-time or ingestion-time. The respective Kafka configuration setting can be specified on the broker level or per topic. The default timestamp extractor in Kafka Streams will retrieve these embedded timestamps as-is. Hence, the effective time semantics of your application depend on the effective Kafka configuration for these embedded timestamps.
event-time 和 ingestion-time 之间的选择实际上是通过 Kafka(不是 Kafka Streams)的配置完成的:从 Kafka 0.10.x 开始,时间戳自动嵌入到 Kafka 消息中。根据 Kafka 的配置,这些时间戳表示事件时间或摄取时间。可以在代理级别或每个主题上指定相应的 Kafka 配置设置。Kafka Streams 中的默认时间戳提取器将按原样检索这些嵌入的时间戳。因此,应用程序的有效时间语义取决于这些嵌入式时间戳的有效 Kafka 配置
Kafka Streams assigns a timestamp to every data record via the TimestampExtractor interface. These per-record timestamps describe the progress of a stream with regards to time and are leveraged by time-dependent operations such as window operations. As a result, this time will only advance when a new record arrives at the processor. We call this data-driven time the stream time of the application to differentiate with the wall-clock time when this application is actually executing. Concrete implementations of the TimestampExtractor interface will then provide different semantics to the stream time definition. For example retrieving or computing timestamps based on the actual contents of data records such as an embedded timestamp field to provide event time semantics, and returning the current wall-clock time thereby yield processing time semantics to stream time. Developers can thus enforce different notions of time depending on their business needs.
Kafka Streams通过接口为每条数据记录分配一个时间戳TimestampExtractor。这些每条记录的时间戳描述了流在时间方面的进展,并被依赖于时间的操作(例如窗口操作)利用。因此,这个时间只会在新记录到达处理器时提前。我们将此数据驱动时间称为应用程序的流时间,以区别于此应用程序实际执行时的挂钟时间。具体实现TimestampExtractor然后接口将为流时间定义提供不同的语义。例如,根据数据记录的实际内容检索或计算时间戳,例如嵌入时间戳字段以提供事件时间语义,并返回当前挂钟时间,从而将处理时间语义产生给流时间。因此,开发人员可以根据他们的业务需求实施不同的时间概念。
Finally, whenever a Kafka Streams application writes records to Kafka, then it will also assign timestamps to these new records. The way the timestamps are assigned depends on the context:
最后,每当 Kafka Streams 应用程序将记录写入 Kafka 时,它也会为这些新记录分配时间戳。时间戳的分配方式取决于上下文:
-
When new output records are generated via processing some input record, for example, context.forward() triggered in the process() function call, output record timestamps are inherited from input record timestamps directly.
当通过处理某些输入记录生成新的输出记录时,例如context.forward()在process()函数调用中触发,输出记录时间戳直接继承自输入记录时间戳。 -
When new output records are generated via periodic functions such as Punctuator#punctuate(), the output record timestamp is defined as the current internal time (obtained through context.timestamp()) of the stream task.
当通过 周期函数 生成新的输出记录时Punctuator#punctuate(),输出记录时间戳被定义为context.timestamp()流任务的当前内部时间 -
For aggregations, the timestamp of a result update record will be the maximum timestamp of all input records contributing to the result.
对于聚合,结果更新记录的时间戳将是对结果有贡献的所有输入记录的最大时间戳
You can change the default behavior in the Processor API by assigning timestamps to output records explicitly when calling #forward().
您可以通过在调用时显式地将时间戳分配给输出记录来更改处理器 API 中的默认行为#forward()
For aggregations and joins, timestamps are computed by using the following rules.
对于聚合和连接,时间戳是使用以下规则计算的
-
For joins (stream-stream, table-table) that have left and right input records, the timestamp of the output record is assigned max(left.ts, right.ts).
对于具有左输入记录和右输入记录的连接(流-流、表-表),分配输出记录的时间戳 max(left.ts, right.ts) -
For stream-table joins, the output record is assigned the timestamp from the stream record.
对于流表连接,输出记录被分配来自流记录的时间戳 -
For aggregations, Kafka Streams also computes the max timestamp over all records, per key, either globally (for non-windowed) or per-window.
对于聚合,Kafka Streams 还计算max 所有记录的时间戳,每个键,全局(对于非窗口)或每个窗口
For stateless operations, the input record timestamp is passed through. For flatMap and siblings that emit multiple records, all output records inherit the timestamp from the corresponding input record.
对于无状态操作,传递输入记录时间戳。对于flatMap发出多条记录,所有输出记录都继承相应输入记录的时间戳
Duality of Streams and Tables流和表的二元性
When implementing stream processing use cases in practice, you typically need both streams and also databases. An example use case that is very common in practice is an e-commerce application that enriches an incoming stream of customer transactions with the latest customer information from a database table. In other words, streams are everywhere, but databases are everywhere, too.
在实践中实现流处理用例时,您通常需要流和数据库。一个在实践中非常常见的示例用例是一个电子商务应用程序,它使用数据库表中的最新客户信息来丰富传入的客户交易流。换句话说,流无处不在,但数据库也无处不在
Any stream processing technology must therefore provide first-class support for streams and tables. Kafka’s Streams API provides such functionality through its core abstractions for streams and tables, which we will talk about in a minute. Now, an interesting observation is that there is actually a close relationship between streams and tables, the so-called stream-table duality. And Kafka exploits this duality in many ways: for example, to make your applications elastic, to support fault-tolerant stateful processing, or to run interactive queries against your application’s latest processing results. And, beyond its internal usage, the Kafka Streams API also allows developers to exploit this duality in their own applications.
因此,任何流处理技术都必须为流和表提供一流的支持。Kafka 的 Streams API 通过其 对流和表的核心抽象提供了此类功能,我们将在稍后讨论。现在,一个有趣的观察是,流和表之间实际上存在着密切的关系,即所谓的流表二元性。Kafka 以多种方式利用这种二元性:例如,使您的应用程序具有弹性,支持容错状态处理,或运行交互式查询针对您的应用程序的最新处理结果。而且,除了内部使用之外,Kafka Streams API 还允许开发人员在他们自己的应用程序中利用这种二元性
Before we discuss concepts such as aggregations in Kafka Streams, we must first introduce tables in more detail, and talk about the aforementioned stream-table duality. Essentially, this duality means that a stream can be viewed as a table, and a table can be viewed as a stream. Kafka’s log compaction feature, for example, exploits this duality.
在我们讨论 Kafka Streams 中的聚合等概念之前 ,我们必须首先更详细地介绍表,并谈谈前面提到的流表二元性。本质上,这种二元性意味着一个流可以被看作一个表,一个表可以被看作一个流。例如,Kafka 的日志压缩功能就利用了这种二元性
A simple form of a table is a collection of key-value pairs, also called a map or associative array. Such a table may look as follows:
表的一种简单形式是键值对的集合,也称为映射或关联数组。这样的表格可能如下所示

The stream-table duality describes the close relationship between streams and tables.
流表二元性描述了流和表之间的密切关系
-
Stream as Table: A stream can be considered a changelog of a table, where each data record in the stream captures a state change of the table. A stream is thus a table in disguise, and it can be easily turned into a “real” table by replaying the changelog from beginning to end to reconstruct the table. Similarly, in a more general analogy, aggregating data records in a stream - such as computing the total number of pageviews by user from a stream of pageview events - will return a table (here with the key and the value being the user and its corresponding pageview count, respectively).
Stream as Table:流可以被认为是表的变更日志,其中流中的每个数据记录都捕获表的状态更改。因此,流是一个伪装的表,通过从头到尾重放更改日志以重建表,它可以很容易地变成一个“真实”的表。类似地,在更一般的类比中,在流中聚合数据记录——例如从页面浏览事件流中计算用户的页面浏览总数——将返回一个表(这里的键和值是用户及其对应的浏览量) -
Table as Stream: A table can be considered a snapshot, at a point in time, of the latest value for each key in a stream (a stream’s data records are key-value pairs). A table is thus a stream in disguise, and it can be easily turned into a “real” stream by iterating over each key-value entry in the table.
Table as Stream:表可以被认为是流中每个键的最新值在某个时间点的快照(流的数据记录是键值对)。因此,一个表是一个伪装的流,通过遍历表中的每个键值条目,它可以很容易地变成一个“真正的”流
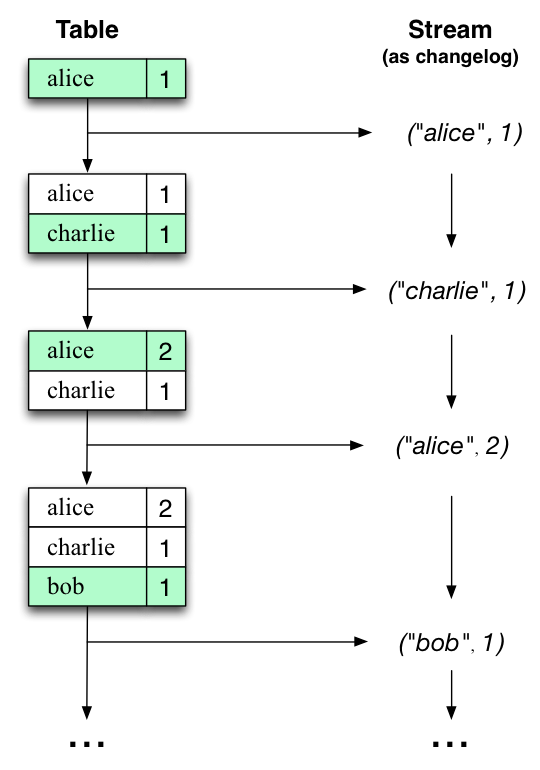
Let’s illustrate this with an example. Imagine a table that tracks the total number of pageviews by user (first column of diagram below). Over time, whenever a new pageview event is processed, the state of the table is updated accordingly. Here, the state changes between different points in time - and different revisions of the table - can be represented as a changelog stream (second column)
让我们用一个例子来说明这一点。想象一个表格,它跟踪用户的页面浏览总数(下图的第一列)。随着时间的推移,无论何时处理新的页面浏览事件,表的状态都会相应更新。在这里,不同时间点之间的状态变化 - 以及表的不同修订 - 可以表示为变更日志流(第二列)
Interestingly, because of the stream-table duality, the same stream can be used to reconstruct the original table (third column)
有趣的是,由于流表二元性,可以使用相同的流来重构原始表(第三列)
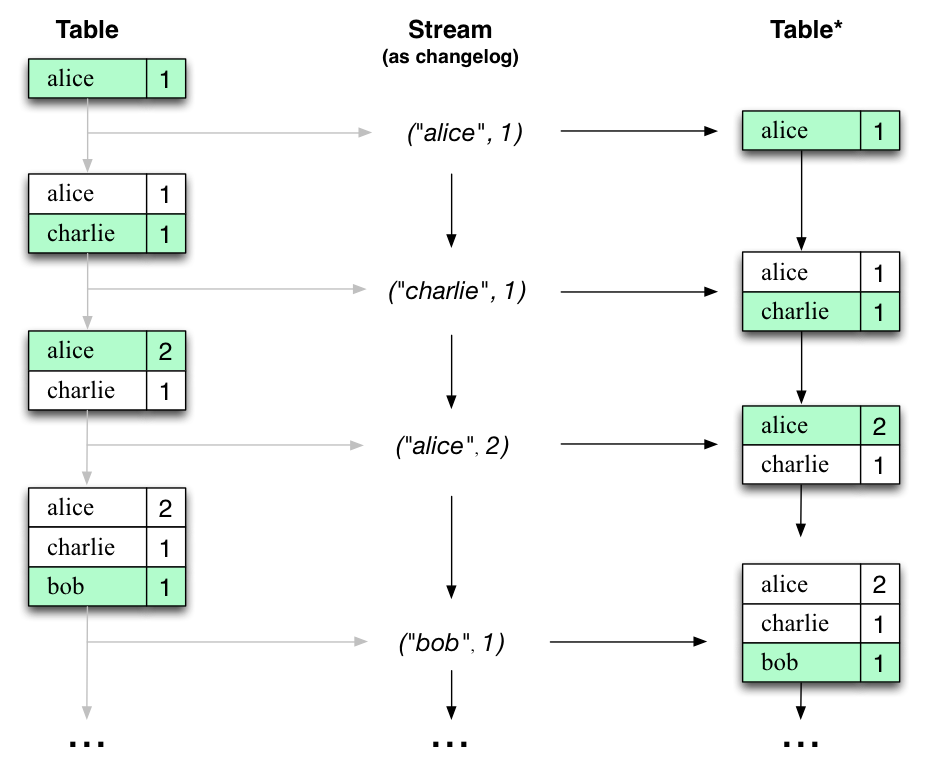
The same mechanism is used, for example, to replicate databases via change data capture (CDC) and, within Kafka Streams, to replicate its so-called state stores across machines for fault-tolerance. The stream-table duality is such an important concept that Kafka Streams models it explicitly via the KStream, KTable, and GlobalKTable interfaces
例如,使用相同的机制通过变更数据捕获 (CDC) 复制数据库,并在 Kafka Streams 中跨机器复制其所谓的状态存储以实现容错。流表二元性是一个非常重要的概念,Kafka Streams 通过KStream、KTable 和 GlobalKTable 接口对其进行显式建模
Aggregations聚合
An aggregation operation takes one input stream or table, and yields a new table by combining multiple input records into a single output record. Examples of aggregations are computing counts or sum.
聚合操作采用一个输入流或表,并通过将多个输入记录组合成一个输出记录来生成一个新表。聚合的示例是计算计数或求和。
In the Kafka Streams DSL, an input stream of an aggregation can be a KStream or a KTable, but the output stream will always be a KTable. This allows Kafka Streams to update an aggregate value upon the out-of-order arrival of further records after the value was produced and emitted. When such out-of-order arrival happens, the aggregating KStream or KTable emits a new aggregate value. Because the output is a KTable, the new value is considered to overwrite the old value with the same key in subsequent processing steps.
在Kafka Streams DSL中,一个输入流aggregation可以是一个 KStream 或一个 KTable,但输出流总是一个 KTable。这允许 Kafka Streams 在值生成和发出后,在更多记录无序到达时更新聚合值。当发生这种乱序到达时,聚合 KStream 或 KTable 发出一个新的聚合值。因为输出的是一个KTable,所以在后续的处理步骤中,新值被认为是用相同的key覆盖了旧值
Windowing窗口
Windowing lets you control how to group records that have the same key for stateful operations such as aggregations or joins into so-called windows. Windows are tracked per record key.
Windowing 允许您控制如何将具有相同键的记录分组以进行有状态操作,例如aggregationsorjoins到所谓的windows中。Windows 按记录键进行跟踪
Windowing operations are available in the Kafka Streams DSL. When working with windows, you can specify a grace period for the window. This grace period controls how long Kafka Streams will wait for out-of-order data records for a given window. If a record arrives after the grace period of a window has passed, the record is discarded and will not be processed in that window. Specifically, a record is discarded if its timestamp dictates it belongs to a window, but the current stream time is greater than the end of the window plus the grace period.
Windowing operations中可用Kafka Streams DSL
使用窗口时,您可以为窗口指定一个宽限期。此宽限期控制 Kafka Streams 等待给定窗口的无序数据记录的时间。如果记录在窗口的宽限期过去后到达,则该记录将被丢弃并且不会在该窗口中进行处理。具体来说,如果记录的时间戳指示它属于一个窗口,但当前流时间大于窗口结束加上宽限期,则该记录将被丢弃
Out-of-order records are always possible in the real world and should be properly accounted for in your applications. It depends on the effective time semantics how out-of-order records are handled. In the case of processing-time, the semantics are “when the record is being processed”, which means that the notion of out-of-order records is not applicable as, by definition, no record can be out-of-order. Hence, out-of-order records can only be considered as such for event-time. In both cases, Kafka Streams is able to properly handle out-of-order records
乱序记录在现实世界中总是可能的,应该在您的应用程序中适当考虑。这取决于如何有效地time semantics 处理乱序记录。在处理时间的情况下,语义是“当记录正在处理时”,这意味着乱序记录的概念不适用,因为根据定义,没有记录可以乱序。因此,乱序记录只能被视为事件时间。在这两种情况下,Kafka Streams 都能够正确处理乱序记录
States状态
Some stream processing applications don’t require state, which means the processing of a message is independent from the processing of all other messages. However, being able to maintain state opens up many possibilities for sophisticated stream processing applications: you can join input streams, or group and aggregate data records. Many such stateful operators are provided by the Kafka Streams DSL.
一些流处理应用程序不需要状态,这意味着消息的处理独立于所有其他消息的处理。然而,能够维护状态为复杂的流处理应用程序开辟了许多可能性:您可以加入输入流,或者分组和聚合数据记录。Kafka Streams DSL提供了许多这样的有状态运算符。
Kafka Streams provides so-called state stores, which can be used by stream processing applications to store and query data. This is an important capability when implementing stateful operations. Every task in Kafka Streams embeds one or more state stores that can be accessed via APIs to store and query data required for processing. These state stores can either be a persistent key-value store, an in-memory hashmap, or another convenient data structure. Kafka Streams offers fault-tolerance and automatic recovery for local state stores.
Kafka Streams 提供所谓的状态存储,流处理应用程序可以使用它来存储和查询数据。这是实施有状态操作时的一项重要功能。Kafka Streams 中的每个任务都嵌入了一个或多个状态存储,可以通过 API 访问这些状态存储,以存储和查询处理所需的数据。这些状态存储可以是持久键值存储、内存中哈希映射或其他方便的数据结构。Kafka Streams 为本地状态存储提供容错和自动恢复。
Kafka Streams allows direct read-only queries of the state stores by methods, threads, processes or applications external to the stream processing application that created the state stores. This is provided through a feature called Interactive Queries. All stores are named and Interactive Queries exposes only the read operations of the underlying implementation
Kafka Streams 允许通过创建状态存储的流处理应用程序外部的方法、线程、进程或应用程序直接对状态存储进行只读查询。这是通过称为交互式查询的功能提供的。所有存储均已命名,交互式查询仅公开底层实现的读取操作
PROCESSING GUARANTEES处理保证
In stream processing, one of the most frequently asked question is “does my stream processing system guarantee that each record is processed once and only once, even if some failures are encountered in the middle of processing?” Failing to guarantee exactly-once stream processing is a deal-breaker for many applications that cannot tolerate any data-loss or data duplicates, and in that case a batch-oriented framework is usually used in addition to the stream processing pipeline, known as the Lambda Architecture. Prior to 0.11.0.0, Kafka only provides at-least-once delivery guarantees and hence any stream processing systems that leverage it as the backend storage could not guarantee end-to-end exactly-once semantics. In fact, even for those stream processing systems that claim to support exactly-once processing, as long as they are reading from / writing to Kafka as the source / sink, their applications cannot actually guarantee that no duplicates will be generated throughout the pipeline.
在流处理中,最常被问到的问题之一是“我的流处理系统是否保证每条记录都被处理一次且仅一次,即使在处理过程中遇到一些故障?” 对于许多不能容忍任何数据丢失或数据重复的应用程序来说,无法保证恰好一次流处理是一个交易破坏者,在这种情况下,除了流处理管道之外,通常还使用面向批处理的框架,称为Lambda架构. 在 0.11.0.0 之前,Kafka 仅提供至少一次交付保证,因此任何利用它作为后端存储的流处理系统都无法保证端到端的精确一次语义。事实上,即使是那些声称支持 exactly-once 处理的流处理系统,只要它们是从 Kafka 读取/写入作为 source/sink,它们的应用程序实际上并不能保证在整个 pipeline 中不会产生重复。
Since the 0.11.0.0 release, Kafka has added support to allow its producers to send messages to different topic partitions in a transactional and idempotent manner, and Kafka Streams has hence added the end-to-end exactly-once processing semantics by leveraging these features. More specifically, it guarantees that for any record read from the source Kafka topics, its processing results will be reflected exactly once in the output Kafka topic as well as in the state stores for stateful operations. Note the key difference between Kafka Streams end-to-end exactly-once guarantee with other stream processing frameworks’ claimed guarantees is that Kafka Streams tightly integrates with the underlying Kafka storage system and ensure that commits on the input topic offsets, updates on the state stores, and writes to the output topics will be completed atomically instead of treating Kafka as an external system that may have side-effects. For more information on how this is done inside Kafka Streams
从 0.11.0.0 版本开始,Kafka 增加了支持,允许其生产者以事务和幂等的方式将消息发送到不同的主题分区,因此 Kafka Streams 通过利用这些特性添加了端到端的 exactly-once 处理语义。更具体地说,它保证对于从源 Kafka 主题读取的任何记录,其处理结果将在输出 Kafka 主题以及有状态操作的状态存储中准确反映一次。请注意,Kafka Streams 端到端精确一次保证与其他流处理框架声称的保证之间的主要区别在于,Kafka Streams 与底层 Kafka 存储系统紧密集成,并确保提交输入主题偏移量、更新状态存储和写入输出主题将以原子方式完成,而不是将 Kafka 视为可能有副作用的外部系统
As of the 2.6.0 release, Kafka Streams supports an improved implementation of exactly-once processing, named “exactly-once v2”, which requires broker version 2.5.0 or newer. This implementation is more efficient, because it reduces client and broker resource utilization, like client threads and used network connections, and it enables higher throughput and improved scalability. As of the 3.0.0 release, the first version of exactly-once has been deprecated. Users are encouraged to use exactly-once v2 for exactly-once processing from now on, and prepare by upgrading their brokers if necessary. For more information on how this is done inside the brokers and Kafka Streams
从 2.6.0 版本开始,Kafka Streams 支持精确一次处理的改进实现,名为“exactly-once v2”,它需要代理版本 2.5.0 或更新版本。此实现更高效,因为它减少了客户端和代理资源利用率,如客户端线程和使用的网络连接,并且它实现了更高的吞吐量和改进的可伸缩性。从 3.0.0 版本开始,exactly-once 的第一个版本已被弃用。鼓励用户从现在开始使用 exactly-once v2 进行 exactly-once 处理,并在必要时通过升级他们的代理做好准备。有关如何在代理和 Kafka 流中完成此操作的更多信息
To enable exactly-once semantics when running Kafka Streams applications, set the processing.guarantee config value (default value is at_least_once) to StreamsConfig.EXACTLY_ONCE_V2 (requires brokers version 2.5 or newer). For more information, see the Kafka Streams Configs section
要在运行 Kafka Streams 应用程序时启用精确一次语义,请将processing.guarantee配置值(默认值为at_least_once)设置为StreamsConfig.EXACTLY_ONCE_V2(需要代理版本 2.5 或更新版本)
Out-of-Order Handling乱序处理
Besides the guarantee that each record will be processed exactly-once, another issue that many stream processing application will face is how to handle out-of-order data that may impact their business logic. In Kafka Streams, there are two causes that could potentially result in out-of-order data arrivals with respect to their timestamps:
除了保证每条记录只处理一次外,许多流处理应用程序将面临的另一个问题是如何处理可能影响其业务逻辑的乱序数据。在 Kafka Streams 中,有两个原因可能会导致数据到达时间戳的乱序
-
Within a topic-partition, a record’s timestamp may not be monotonically increasing along with their offsets. Since Kafka Streams will always try to process records within a topic-partition to follow the offset order, it can cause records with larger timestamps (but smaller offsets) to be processed earlier than records with smaller timestamps (but larger offsets) in the same topic-partition
在主题分区内,记录的时间戳可能不会随着它们的偏移量单调增加。由于 Kafka Streams 将始终尝试处理主题分区内的记录以遵循偏移顺序,因此它可能导致具有较大时间戳(但较小偏移)的记录比同一主题中具有较小时间戳(但较大偏移)的记录更早被处理 -
Within a stream task that may be processing multiple topic-partitions, if users configure the application to not wait for all partitions to contain some buffered data and pick from the partition with the smallest timestamp to process the next record, then later on when some records are fetched for other topic-partitions, their timestamps may be smaller than those processed records fetched from another topic-partition
在可能正在处理多个主题分区的流任务中,如果用户将应用程序配置为不等待所有分区都包含一些缓冲数据并从具有最小时间戳的分区中挑选来处理下一条记录,那么稍后当一些记录为其他主题分区获取,它们的时间戳可能小于从另一个主题分区获取的那些已处理记录
For stateless operations, out-of-order data will not impact processing logic since only one record is considered at a time, without looking into the history of past processed records; for stateful operations such as aggregations and joins, however, out-of-order data could cause the processing logic to be incorrect. If users want to handle such out-of-order data, generally they need to allow their applications to wait for longer time while bookkeeping their states during the wait time, i.e. making trade-off decisions between latency, cost, and correctness. In Kafka Streams specifically, users can configure their window operators for windowed aggregations to achieve such trade-offs (details can be found in Developer Guide). As for Joins, users have to be aware that some of the out-of-order data cannot be handled by increasing on latency and cost in Streams yet:
对于无状态操作,无序数据不会影响处理逻辑,因为一次只考虑一条记录,而无需查看过去处理记录的历史;然而,对于聚合和连接等有状态操作,无序数据可能导致处理逻辑不正确。如果用户想要处理这种无序的数据,通常他们需要让他们的应用程序等待更长的时间,同时在等待时间内记录他们的状态,即在延迟、成本和正确性之间做出权衡决策。具体来说,在 Kafka Streams 中,用户可以为窗口化聚合配置他们的窗口操作符来实现这种权衡(详细信息可以在开发人员指南中找到). 至于 Join,用户必须意识到一些乱序数据还不能通过增加 Streams 中的延迟和成本来处理:
-
For Stream-Stream joins, all three types (inner, outer, left) handle out-of-order records correctly
对于 Stream-Stream 连接,所有三种类型(内部、外部、左侧)都能正确处理乱序记录。 -
For Stream-Table joins, out-of-order records are not handled (i.e., Streams applications don’t check for out-of-order records and just process all records in offset order), and hence it may produce unpredictable results
对于 Stream-Table join,不处理乱序记录(即Streams 应用程序不检查乱序记录,只是按偏移顺序处理所有记录),因此可能会产生不可预测的结果 -
For Table-Table joins, out-of-order records are not handled (i.e., Streams applications don’t check for out-of-order records and just process all records in offset order). However, the join result is a changelog stream and hence will be eventually consistent
对于表-表连接,不处理乱序记录(即Streams 应用程序不检查乱序记录,只是按偏移顺序处理所有记录)。然而,连接结果是一个变更日志流,因此最终是一致的

