
- 1EasyExcel向模板中写入多个sheet页_easyexcel 写入多sheet
- 2STM32——DMA详解_stm32 dma通道
- 3Android java项目添加kotlin混合开发环境配置_android java引入kotlin库
- 4银河麒麟v10重新挂载磁盘_银河麒麟挂载磁盘
- 5list、map、stream记录
- 6XXE漏洞详解 一文了解XXE漏洞
- 7STM32下载Bin文件的几种方式
- 8两万字长文总结,梳理 Java 入门进阶哪些事(推荐收藏)_大概是半年前吧,在知乎上有个知友私信给我,问我关于零基础如何学习java,以及在学
- 9CVPR 2024 | 通用异常检测新网络!InCTRL:学习基于少量正常样本提示的上下文差异实现通用异常检测...
- 10HLSL常用函数笔记_hlsl lerp
Linux 入门篇[常用指令&权限管理]_简单描述linux权限控制常用命令及作用
赞
踩
前言
一切皆文件
文件的分类
普通文件,文件属性为[-]
目录文件,属性为[d],文件夹(目录)也是一种文件,是内容为文件的文件,是能用 # cd指令进入的
块设备文件,属性为[b],表示为装置文件里面的可供储存的接口设备(可随机存取装置),比如硬盘、光驱等。例如一号硬盘的代码是 /dev/hda1等文件
字符设备文件,属性为[c],表示为装置文件里面的串行端口设备,例如键盘、鼠标(一次性读取装置)、屏幕等
套接字文件,属性为[s],这类文件通常用在网络数据连接,可以启动一个程序来监听客户端的要求,客户端就可以通过套接字来进行数据通信。最常在 /var/run目录中看到这种文件类型
管道文件,属性为[p],FIFO也是一种特殊的文件类型,它主要的目的是,解决多个程序同时存取一个文件所造成的错误。FIFO是first-in-first-out(先进先出)的缩写
链接文件,属性为[l],类似于Windows里的快捷方式和macOS的替身
常用的单词:
command 命令
option 选项
dirname 目录名
建议有不懂的指令就去man查找!
常用指令
一个指令由基本指令、选项、目标、其他内容组成的,除基本指令外的内容都并不是必须的,内容对应相应功能
一条指令可以添加多个选项,意味着一条指令实现多种功能的结合
凡是放方括号里的内容都代表不是必须的,可以不存在,括号外的内容都是必须的
指令中,选项的位置正常来讲是可以移动的,并不是固定的必须要按照某种顺序出现在某个位置
ls
语法:
ls [选项] [指定文件]
功能:
对于目录,该命令列出该目录下的所有文件;对于一般文件,将列出该文件。(默认是按照名称排序的)
(如果不跟指定目录或文件,则默认是当前目录)

常用选项:
-l # 列出各文件的详细信息。ls -l 可以简写成 ll
-a # 列出所有文件, 包括以.开头的隐藏文件
-d # 只显示指定目录,不显示目录内容
-s(小写) # 显示文件的块数
-S(大写) # 按大小降序排列
-r # 反向排序
-t # 按修改时间先后排序
-h # 按用户易读的方式显示文件大小
-k # 以k字节的形式输出大小(一般输出的时候就是以这种方式输出的,用处不是很大)
-R # 列出所有子目录的文件(递归)
-1 # 一行只输出一个文件
-n # 用数字的UID、GID代替owner、group名称
-i # 显示文件的inode(索引节点)
-F # 在每个文件名后附上一个字符以说明该文件的类型,*表示可执行程序,/表示目录,@表示符号连接,|表示FIFOs,=表示套接字(sockets)。(目录类型识别)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
-l :列出各文件的详细信息。ls -l 可以简写成 ll

Linux文件默认是按照名称排序的-a :列出所有文件, 包括以.开头的隐藏文件。例如:ls -a [指定目标]

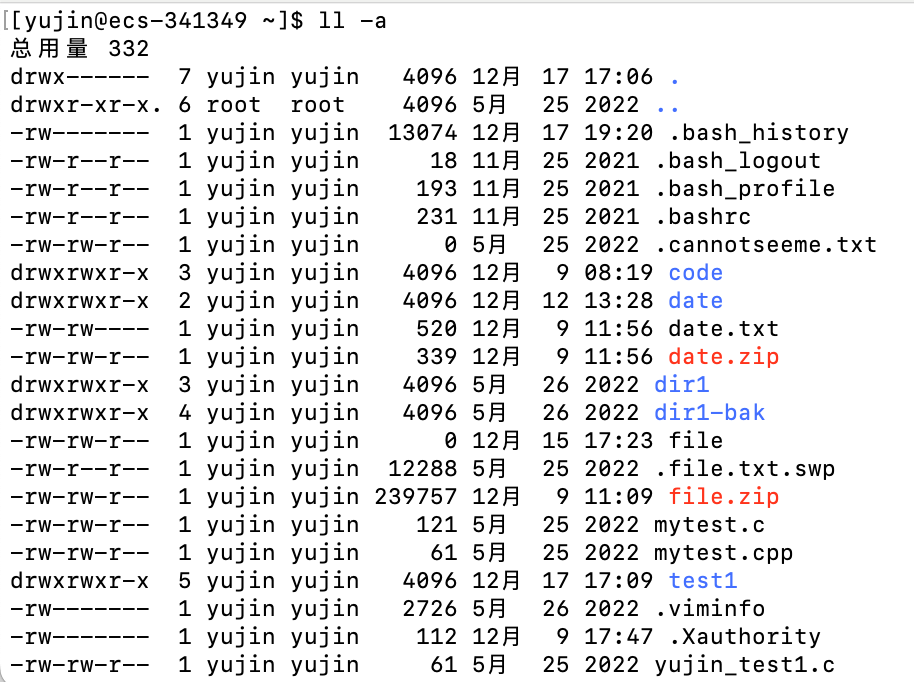
可以看出当前目录.和上级目录…是作为隐藏文件保存的
注意:当前目录.和上级目录…算是当前目录的子目录!
所以会显示当前目录.的子目录个数是7,分别是:当前目录.,上级目录…,code,date,dir1,dir1-bak,test1
显示code目录中的子目录个数是3,但是实际上一看code中只有一个子目录hellobite,这就是因为code的当前目录和上级目录也算作了code的子目录,而当前目录和上级目录是隐藏文件
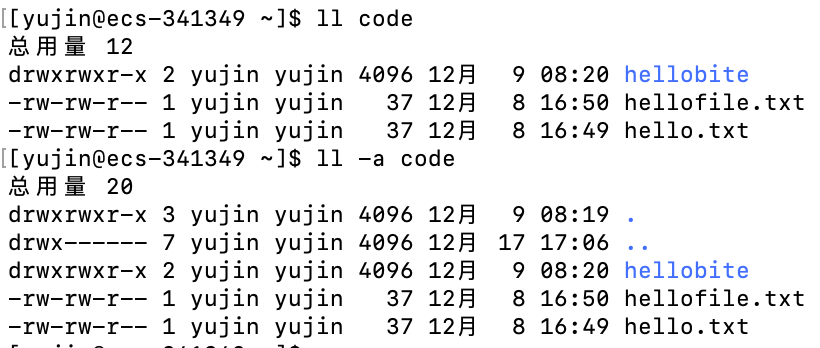
同样,显示code的子目录hellobite含有的子目录的个数是2,但是实际上查看发现hellobite中没有子目录
-d :只显示指定目录,不显示目录内容


-s(小写 :显示文件的块数

-S(大写:按大小降序排列
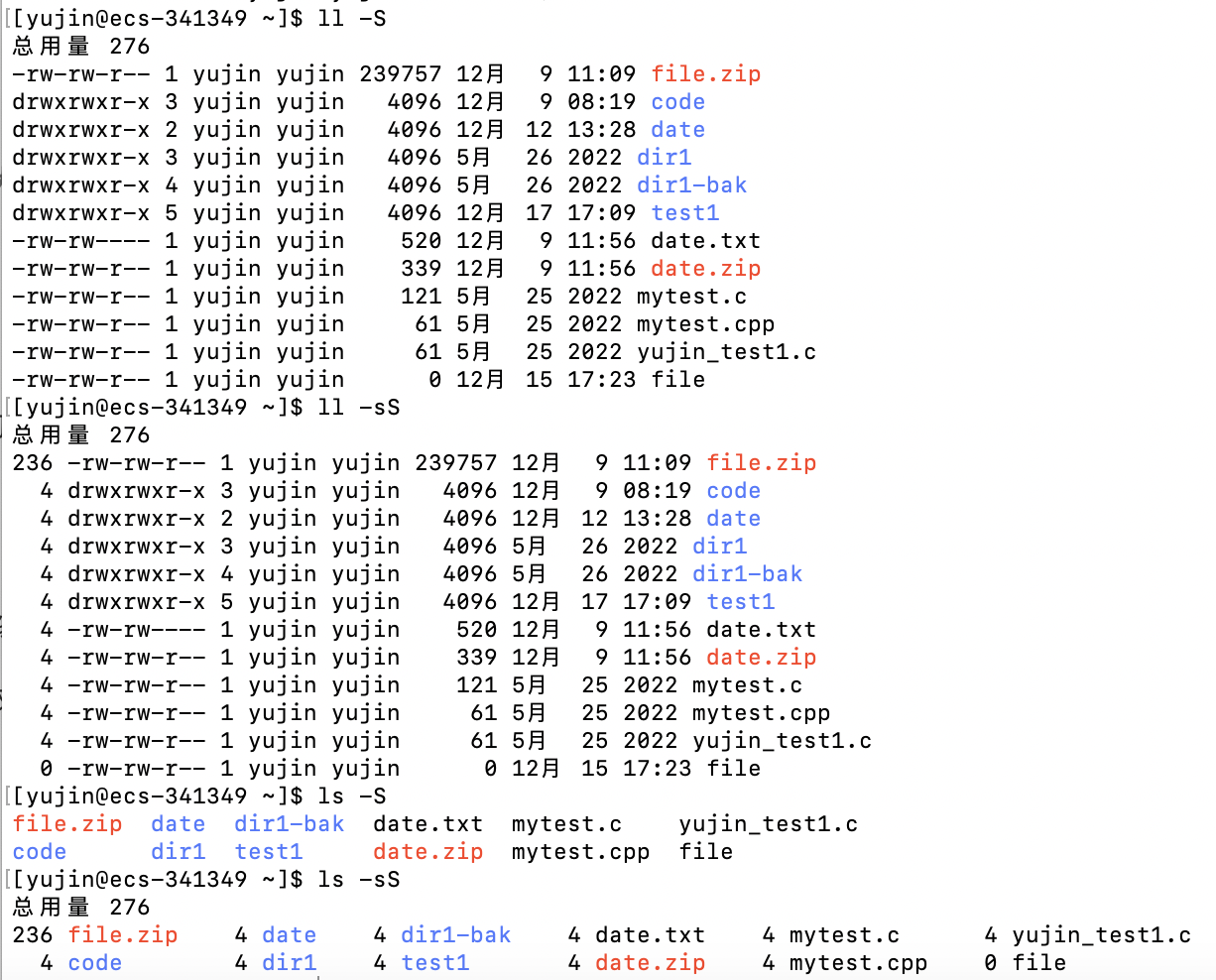
-r :反向排序
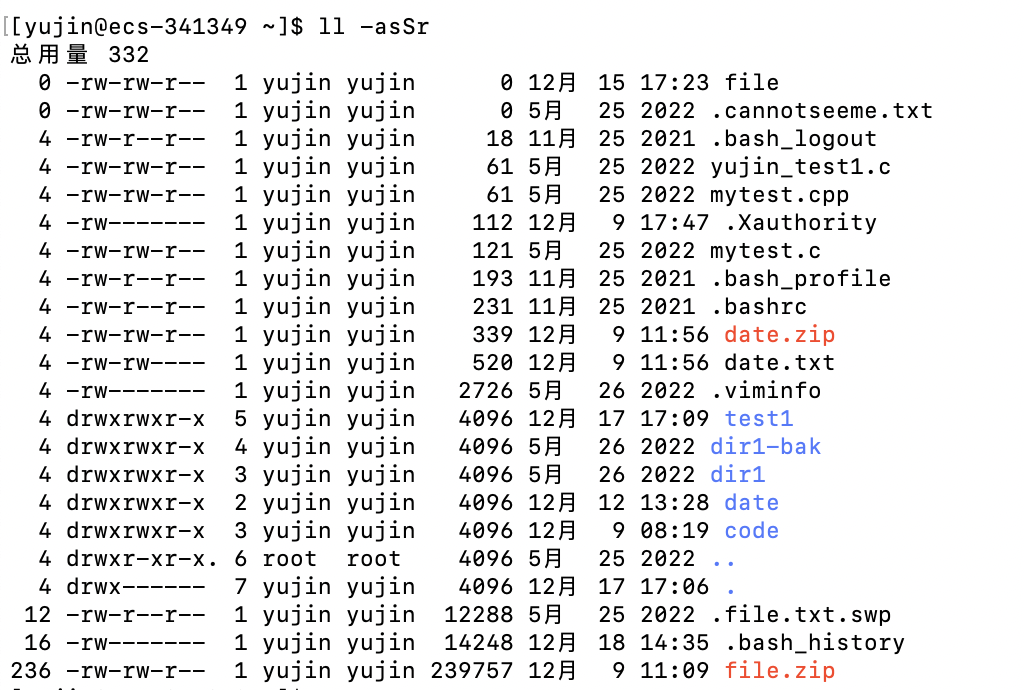
-t : 按修改时间先后排序
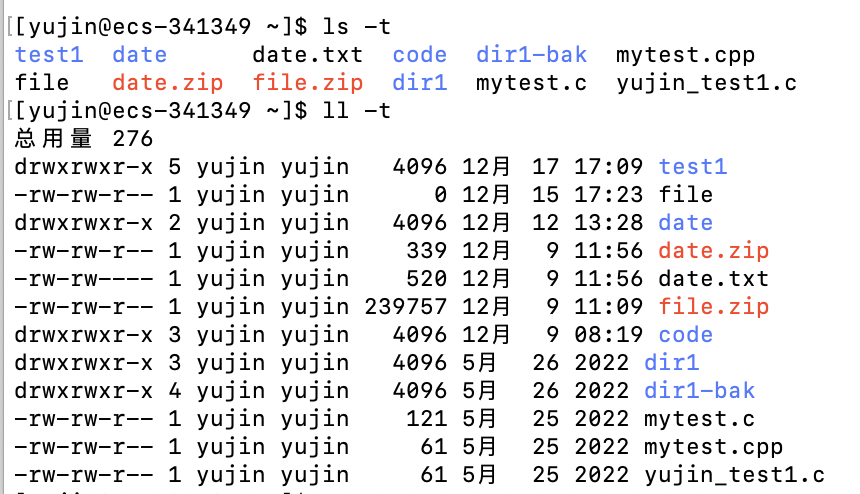
-h :按用户易读的方式显示文件大小
就是换算了一下单位
-R : 列出所有子目录的文件(递归)


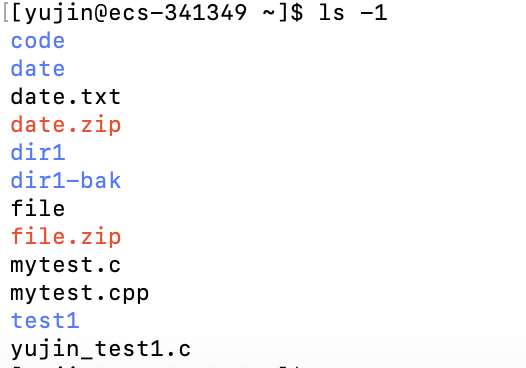
-1 : 一行只输出一个文件
-n:用数字的UID、GID代替owner、group名称
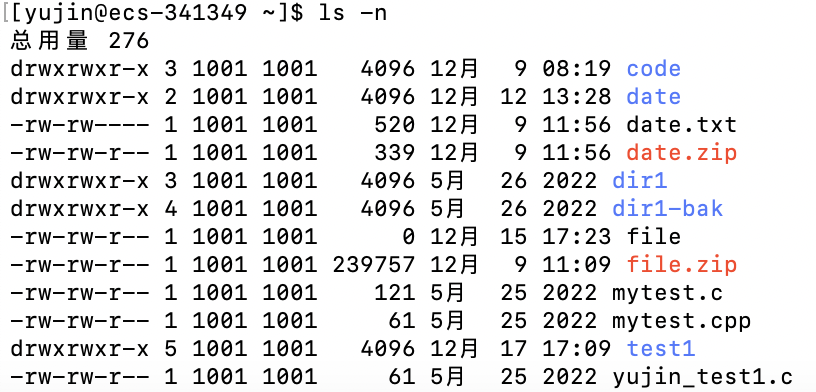
-i:显示文件的inode(索引节点)

-F:在每个文件名后附上一个字符以说明该文件的类型,*表示可执行程序,/表示目录,@表示符号连接,|表示FIFOs,=表示套接字(sockets)。(目录类型识别)

文件块(简介)
(后续会详细学习)
Linux系统的心脏部分就是其文件系统,文件系统提供了层次结构的目录和文件。
一般情况下,文件系统将磁盘空间划分为每1024个字节一组,也称为一块(有的Linux将512字节划为一块),编号从0到整个内存的最大块数。
文件访问系统访问磁盘的时候基本单位是4kb,也就是说是4个块为一个基本单位
所以在查看文件的总块数的时候会发现都是4的倍数
inode索引节点(简介)
(后续会详细学习)
用来存放档案和目录的基本信息,包含时间、档名、使用者及群组等
UID和GID(简介)
(后续会详细学习)
登陆 Linux 系统时,虽然输入的是自己的用户名和密码,但其实 Linux 并不认识你的用户名称,它只认识用户名对应的 ID 号(也就是一串数字)。Linux 系统将所有用户的名称与 ID 的对应关系都存储在 /etc/passwd 文件中
说白了,用户名并无实际作用,仅是为了方便用户的记忆而已。
Linux 系统中,每个用户的 ID 细分为 2 种,分别是用户 ID(User ID,简称 UID)和组 ID(Group ID,简称 GID),这与文件有拥有者和拥有群组两种属性相对应
每个文件都有自己的拥有者 ID 和群组 ID,当显示文件属性时,系统会根据 /etc/passwd 和 /etc/group 文件中的内容,分别找到 UID 和 GID 对应的用户名和群组名,然后显示出来
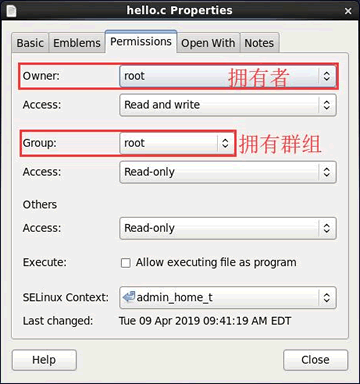
/etc/passwd 文件和 /etc/group 文件,后续文章会做详细讲解,这里只需要知道,在 /etc/passwd 文件中,利用 UID 可以找到对应的用户名;在 /etc/group 文件中,利用 GID 可以找到对应的群组名
pwd
语法:
pwd
功能:
显示用户当前所在目录
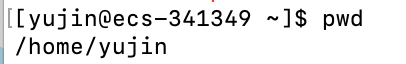
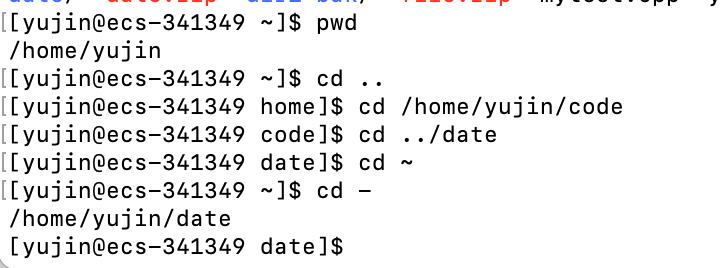
cd
语法:
cd [指定目录]
功能:
进入到指定目录下
举例:
cd .. # 返回上级目录(相对路径)
cd /home/litao/linux/ # 绝对路径
cd ../day02/ # 相对路径
cd ~ # 进入用户家目录
cd - # 返回最近访问的目录
- 1
- 2
- 3
- 4
- 5
date
语法:
date [option]......[+format]
option用来设置时间
format用来显示时间
功能:
显示与设定系统的日期与时间

用法:
- 显示时间:
使用者可以设定欲显示的格式,格式设定为一个加号后接数个标记,其中常用的标记列表如下
+%Y # 显示完整年份(0000~9999)
+%m # 显示月份(1~12)
+%d # 显示天(01~31)
+%F # 显示年月日,相当于指令 +%Y-%m-%d
+%H # 显示小时(00~23)
+%M # 显示分钟(00~59)
+%S # 显示秒(00~61)
+%X # 显示时分秒,相当于指令 +%H:%M:%S
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
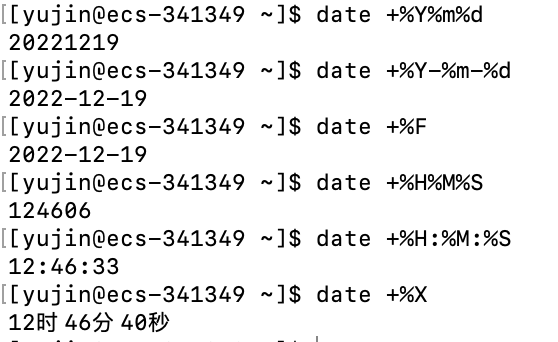
Mac的终端默认是中文所以输出的最后一行是中文的
- 设定时间
只有root才有权限设置
date -s # 设置当前时间,只有root权限才能设置,其他只能查看。
date -s 20080523 # 设置成20080523,这样会把具体时间设置成空00:00:00
date -s 01:01:01 # 设置具体时间,不会对日期做更改
date -s "01:01:01 2008-05-23" # 这样可以设置全部时间
date -s "01:01:01 20080523" # 这样可以设置全部时间
date -s "2008-05-23 01:01:01" # 这样可以设置全部时间
date -s "20080523 01:01:01" # 这样可以设置全部时间
- 1
- 2
- 3
- 4
- 5
- 6
- 7
3.时间戳转换
Unix时间戳(英文为Unix epoch, Unix time, POSIX time 或 Unix timestamp)是从1970年1月1日(UTC/GMT的 午夜)开始所经过的秒数,不考虑闰秒
时间->时间戳:
date +%s
- 1
时间戳->时间:
date -d@时间戳时间
- 1

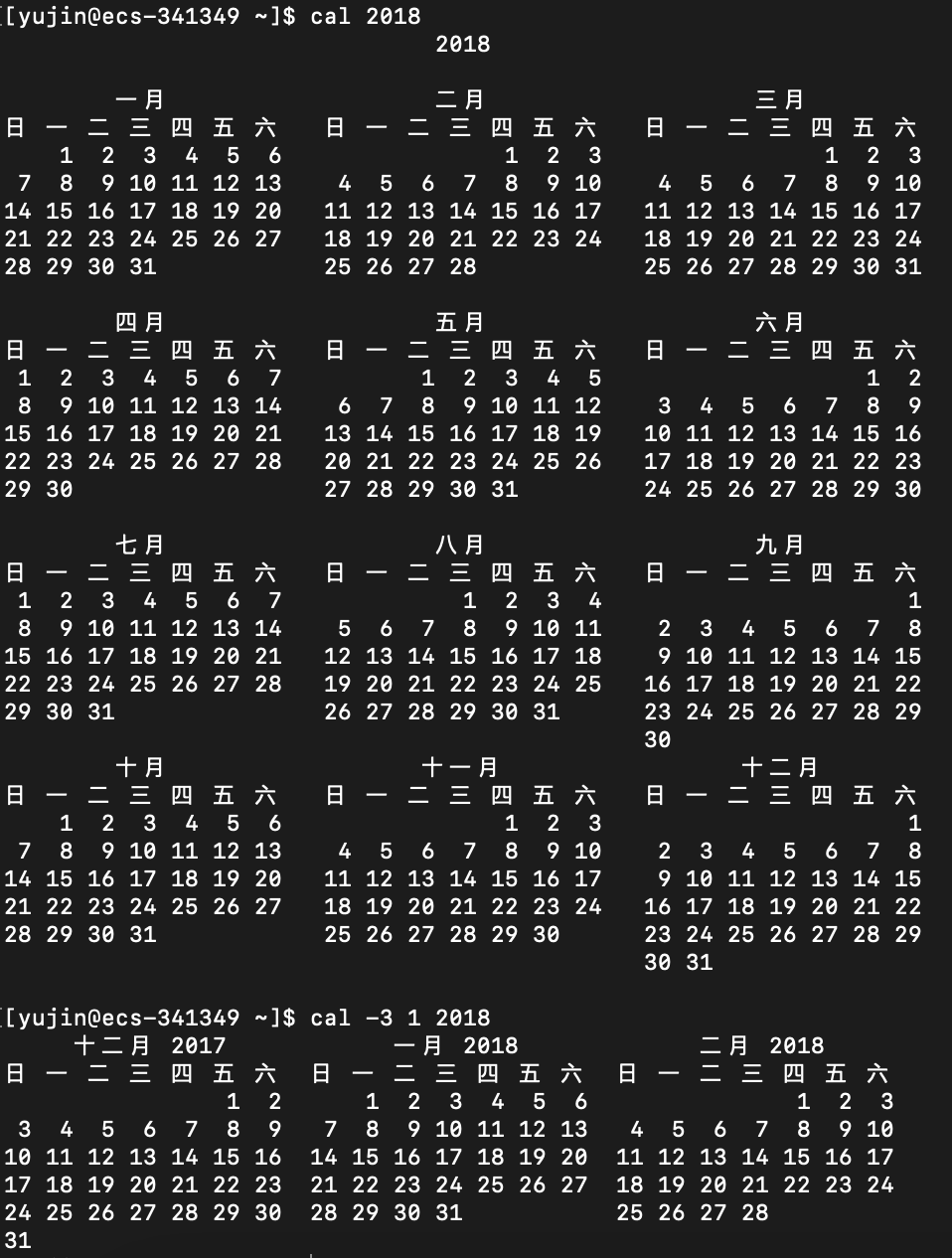
cal
语法:
cal [option] [月份] [年份]
功能:
查看并输出指定年份的指定月份的日历
省略月份则输出指定年份整年的日历(如果只有一个参数,只能表示年份)
都省略则输出系统时间所在月的日历
常用选项:
-3 # 显示指定日期所在的前一个月份、当前月份、后一个月份的日历
-j # 显示指定日期在当前年中的第几天(从1月1号开始算)
-y # 显示一整年12个月的日历
- 1
- 2
- 3

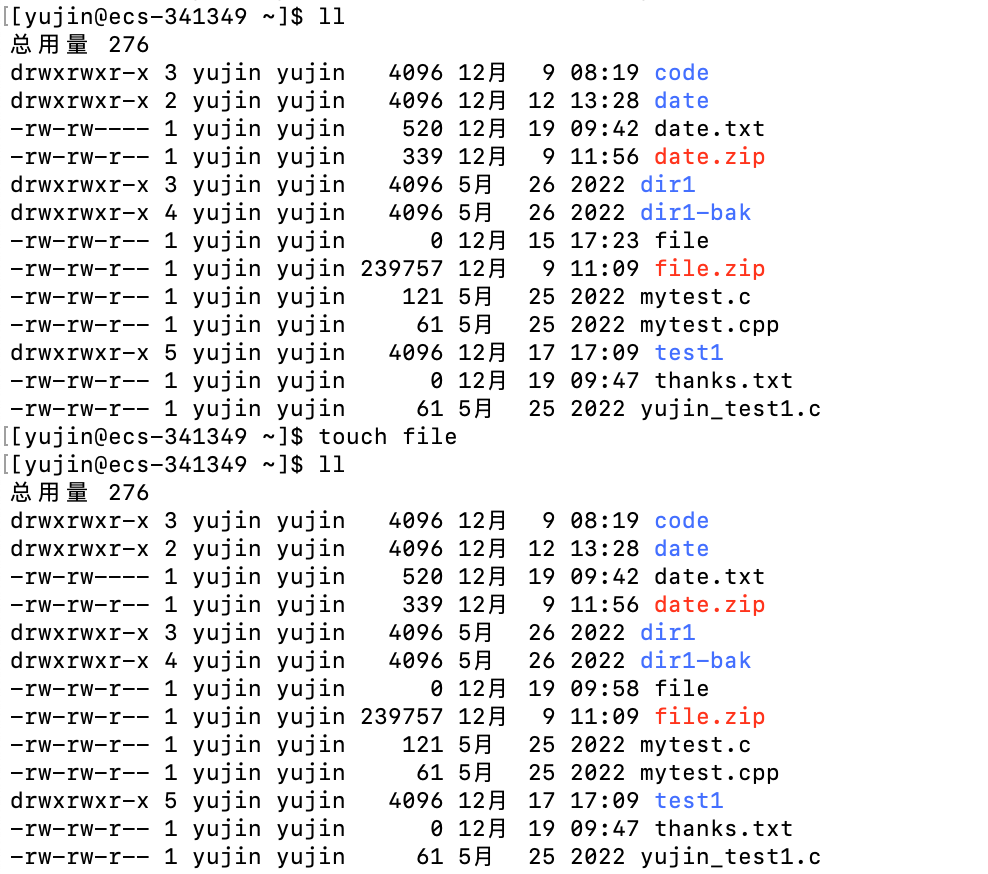
touch
语法:
touch [选项]……[文件]……
功能:
- 如果文件已存在,更改文件(包括目录文件)的时间记录,包括存取时间和修改时间
- 如果文件不存在,创建这个文件(不能新建目录)
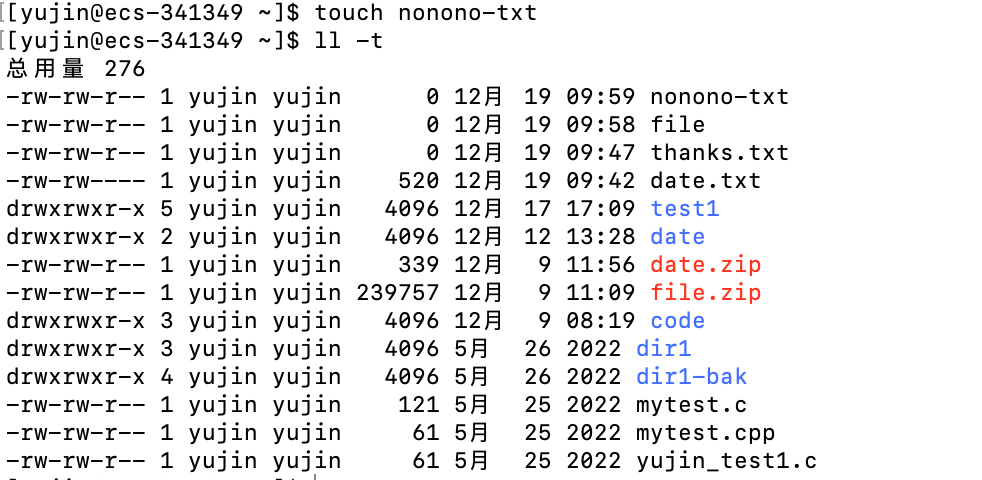
常用选项:
-a,--time=atime,--time=access,--time=use # 只更改存取时间
-m,--time=mtime,--time=modify # 只更改修改时间
-c,--no-creat # 不创建文件
-d [时间] # 将时间记录改为给定的时间,时间可以使用各种不同的格式
-t [时间] # 将时间记录改为给定的时间,时间必须使用[[YY]YY]MMDDhhmm[.SS],不再放括号里的是必须有的,方括号里的是可以省略的
-r [参考文件] # 将时间记录改为跟参考文件一样的时间
-f # 会被忽略处理,是为了与其他 unix 系统的相容性而保留
- 1
- 2
- 3
- 4
- 5
- 6
- 7
-a
无法直观展示
-m

-c
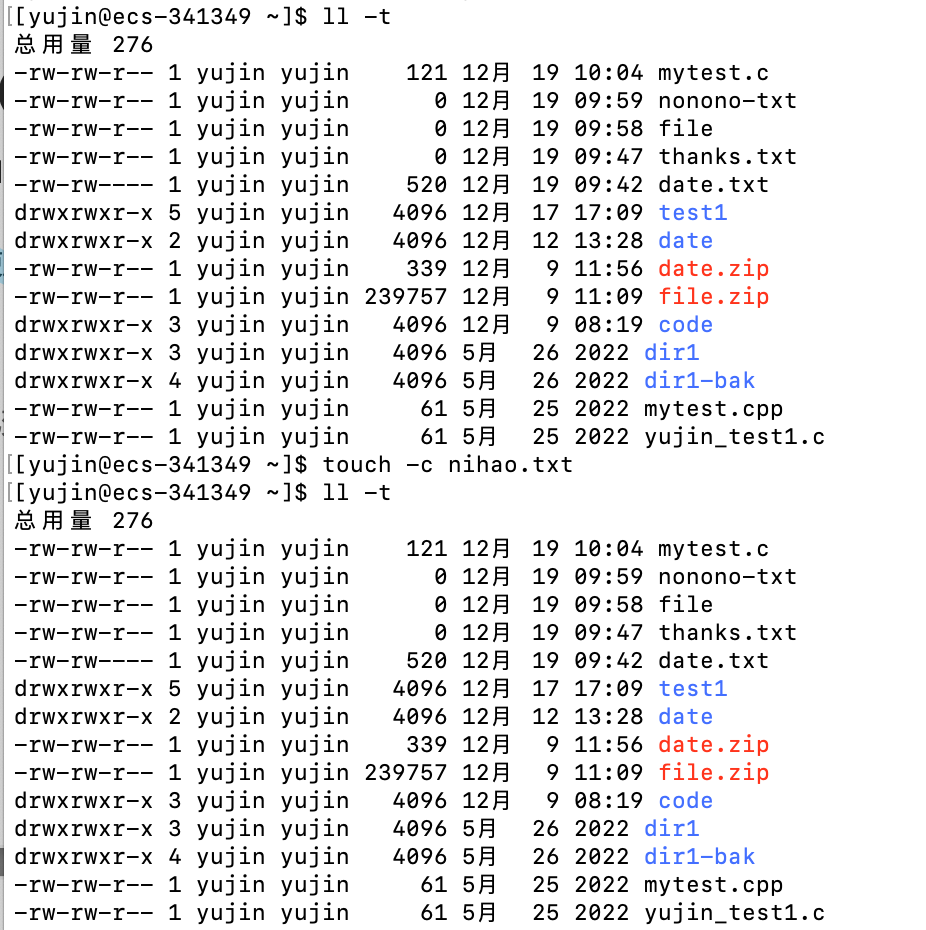
-d [时间]
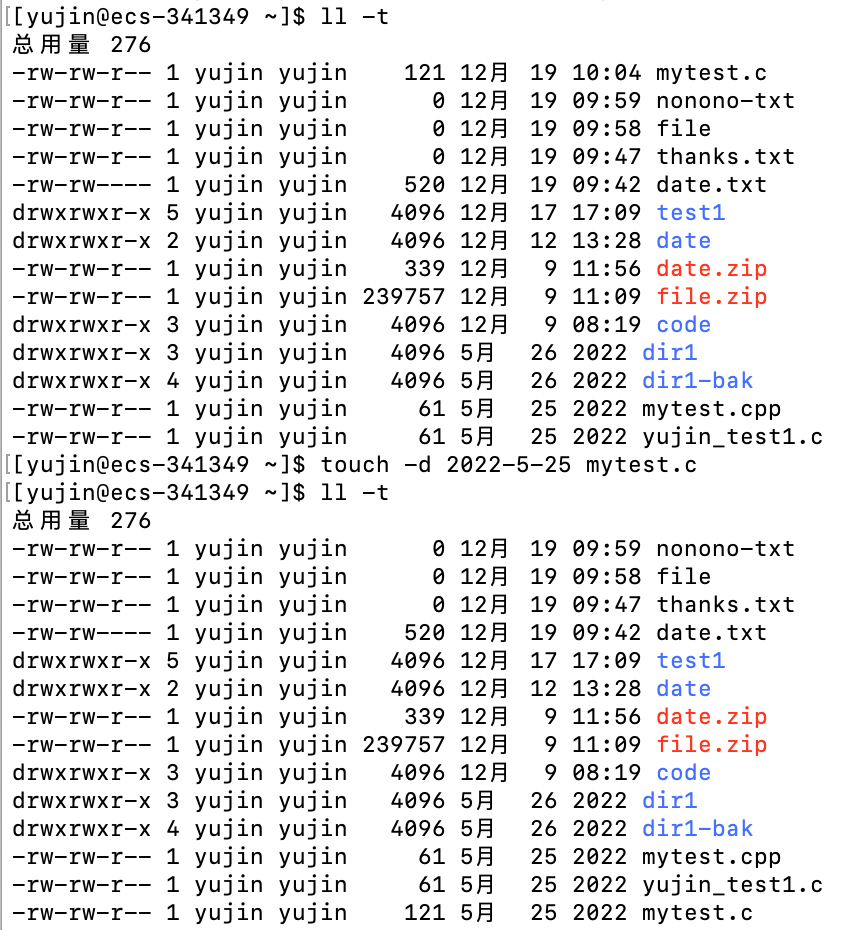
-t [时间]
mkdir
语法:
mkdir [-p] DIRNAME
功能:
在当前目录下创建一个名为DIRNAME的目录
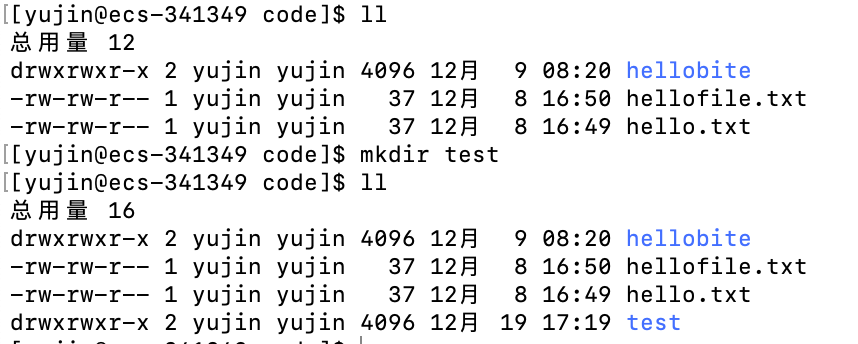
常用选项:
-p # 后跟一个路径。如果路径中有不存在的目录,则会创建出这些不存在的路径。也就是可以一次性创建一个路径,多个目录。(或--parents)
- 1

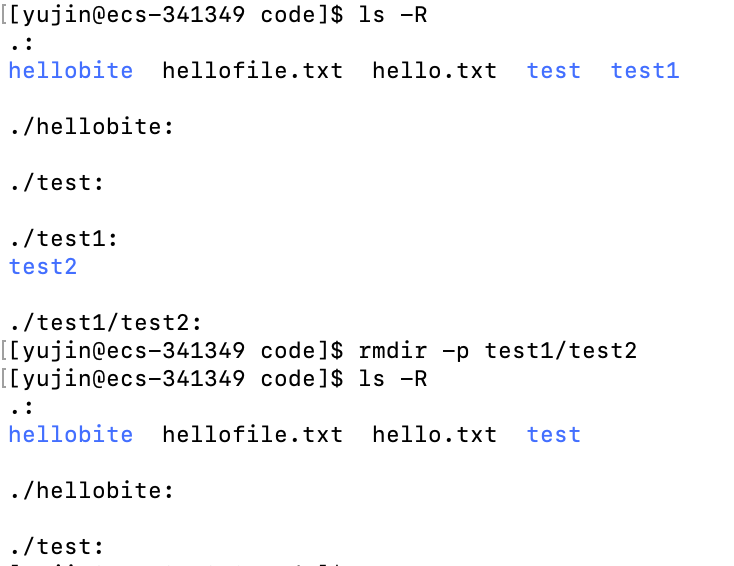
rmdir
语法:
rmdir [-p] 目录
适用对象:
具有指定目录的权限的所有使用者
功能:
删除指定目录,目录必须是空的

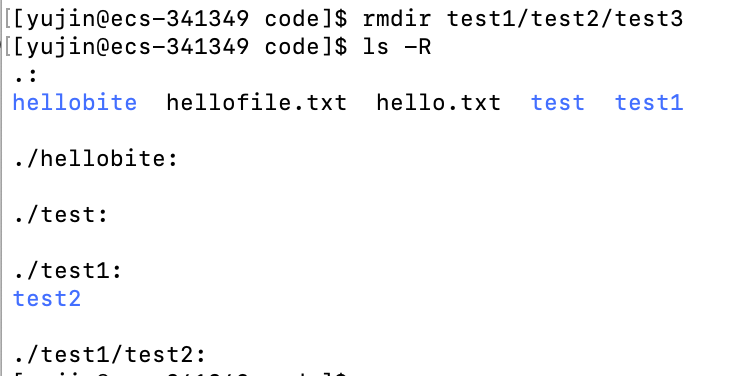
常用选项:
-p # 当指定目录被删除后它的父目录变成空的话,连同父目录一起删除
* # 借助通配符*,满足匹配条件的文件都会被复制。
? # 同上
- 1
- 2
- 3
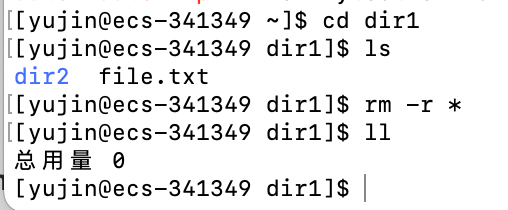
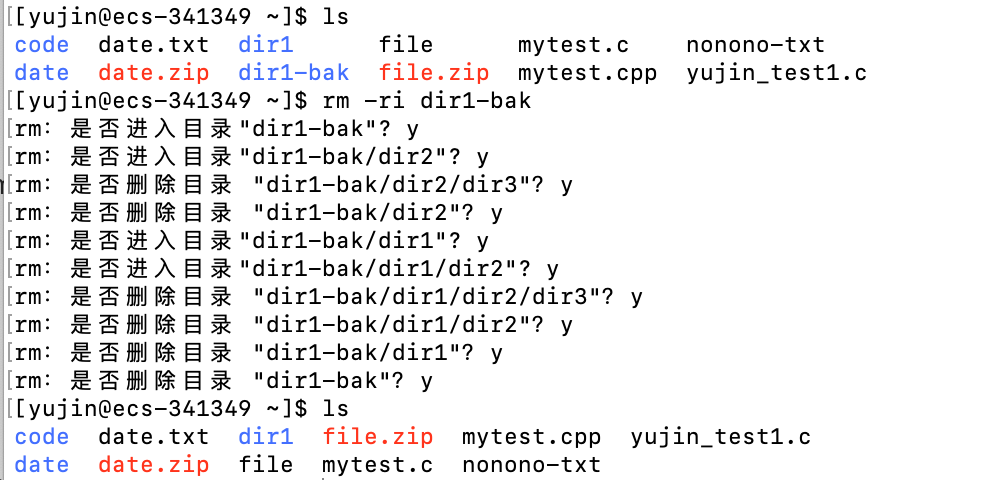
rm
语法:
rm [option] 文件
适用对象:
所有使用者
功能:
删除文件,搭配选项可以删除目录
注意,文件一旦删除无法恢复!

常用选项:
-r # 删除目录及其下所有文件
* # 借助通配符*,满足匹配条件的文件都会被复制。
? # 同上
-f # 即使文件属性为只读(即写保护),亦直接删除,无需逐一确认
-i # 删除前逐一询问确认
- 1
- 2
- 3
- 4
- 5

man
语法:
man [option] command
功能:
查找指定命令的用法
补充说明:
-
Linux手册是联机手册,进行联机查找
-
执行
man man指令可以查询man的详细信息,包括用法、每章节的内容分类等 -
帮助文档分为8章:
1 是普通的命令
2 是系统调用,如open,write之类的(通过这个,至少可以很方便的查到调用这个函数,需要加什么头文 件)
3 是库函数,如printf,fread
4 是特殊文件,也就是/dev下的各种设备文件
5 是指文件的格式,比如passwd, 就会说明这个文件中各个字段的含义
6 是给游戏留的,由各个游戏自己定义
7 是附件还有一些变量,比如向environ这种全局变量在这里就有说明
8 是系统管理用的命令,这些命令只能由root使用,如ifconfig
-
man 命令中常用按键以及用途
按键 用途 空格键 向下翻一页 PaGe down 向下翻一页 PaGe up 向上翻一页 home 直接前往首页 end 直接前往尾页 / 从上至下搜索某个关键词,如“/linux” ? 从下至上搜索某个关键词,如“?linux” n 定位到下一个搜索到的关键词 N 定位到上一个搜索到的关键词 q 退出帮助文档 鼠标滚轮 上下翻页
常用选项:
num # 只在第num章节中进行查找
-k # 后面的command可以是缺省的,进行模糊查找
-a,--all # 寻找所有匹配的手册页
-f,--whatis # 相当于whatis
-i,--ignore-case # 查找手册页时不区分大小写(默认)
-I,--match-case # 区分大小写
- 1
- 2
- 3
- 4
- 5
- 6
whatis
Linux 中的 whatis 命令可以从它的字面意思可以看出来,就是“这是什么”,通过它可以知道某命令是用来干什么的,而且是用很简短的方式来描述。

cp
语法:
cp [option] 源文件 指定目录下的目标文件
功能:
将 源文件 在指定目录下 复制出指定文件
如果省略指定目录,则默认是当前目录
如果省略目标文件,则会在指定目录下复制出跟源文件同名的文件
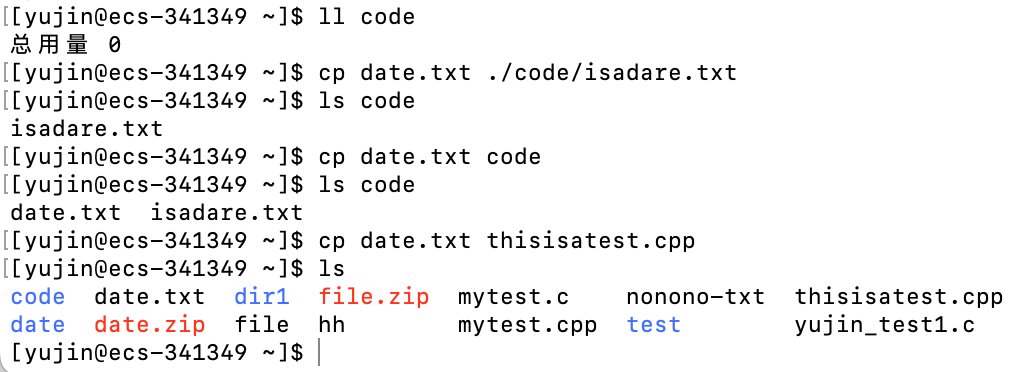
说明:
-
本质过程是根据源文件复制创建出一个新的文件,所以如果目标文件跟已存在的文件重名,会覆盖已存在的文件(且默认不会询问)
-
如果要复制目录,则必须加上
-r选项, -
指定文件的类型必须跟源文件类型一样,普通文件只能复制出普通文件,源文件只能复制出源文件
-
可以一次性复制多个源文件,各个源文件之间用空格间隔,最后跟一个指定目录,各个源文件会复制到指定目录中去

常用选项:
-r # 复制目录(并递归复制该源目录下所有的子目录和文件)
-f,--force # 强制复制,且覆盖已经存在的文件之前不询问用户。如果文件不能打开,可以用它强行复制
-i,--interactive # 在覆盖已存在的文件之前选询问用户(与-f相反)
-u # 当源文件比目标文件新时才会复制,否则不复制成目标文件
* # 借助通配符*,满足匹配条件的文件都会被复制。
? # 同上
- 1
- 2
- 3
- 4
- 5
- 6
通配符(简介)
(后续会详细学习)
linux常用通配符有* ,?,[ ],[^],[:space:],[:punct:],[:lower:],[:upper:],[:digit:],[:alnum:]等等
它是由shell解析,并且一般用于匹配文件名,实际上就是shell解释器去解析的特殊符号
通配符不仅会匹配当前目录下的满足条件的文件,还会递归匹配子目录下的满足条件的文件
开始字符和结束字符都可以省略
在匹配文件的时候,被匹配的文件名会被分成三部分:开始字符、中间字符、结束字符
分别对应文件名的开头、中间、结尾
如果开始字符被省略,那么被匹配的字符就变成了:中间字符、结束字符
则文件名的开头、中间都被视为中间字符,结尾被视为结束字符
匹配时寻找 文件名结尾 跟 结束字符 相同,且 文件名开头和中间 满足中间字符要求 的文件
(比如有的通配符要求中间只能有一个字符,那么只有文件名结尾跟结束字符相同,且除了文件名结尾之外的部分(也就是开头和中间)只有一个字符的才能满足匹配要求)
如果结束字符被省略,那么被匹配的字符就变成了:开始字符、结束字符
那么文件名的开头被视为开始字符,中间和结尾被视为结束字符
匹配时寻找 文件名开头 跟 开始字符 相同,且 文件名中间和结尾 满足中间字符要求 的文件
如果开始字符和结束字符都被省略,被匹配的字符只有中间字符
整个文件名都被视为中间字符,所有 满足中间字符要求 的文件名都会被匹配上
*:匹配任意多个字符
开始字符*结束字符 # 会匹配满足 文件名开头 和 文件名结尾 分别与开始字符和结束字符相同的、中间有任意多个字符的文件
- 1
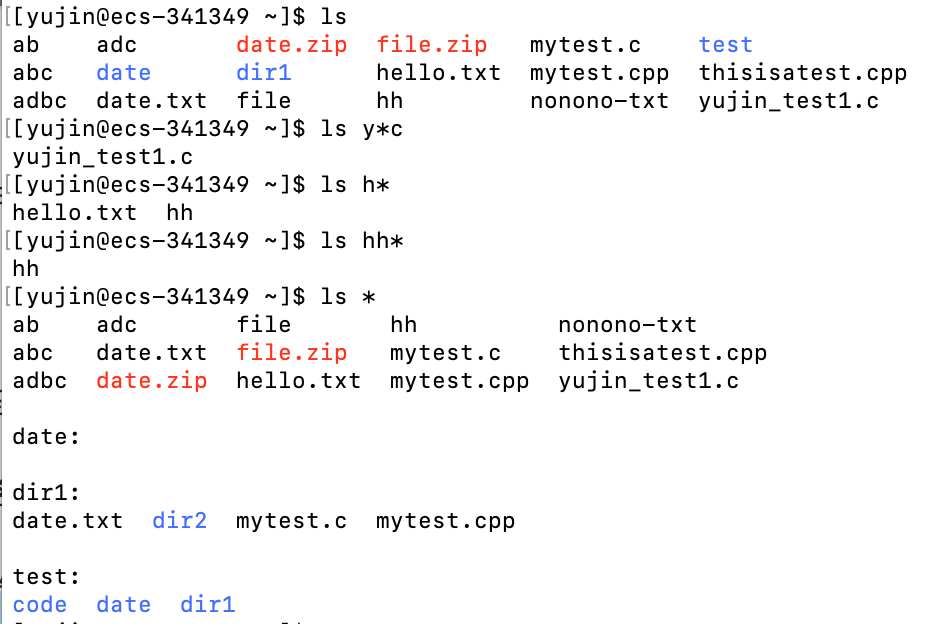
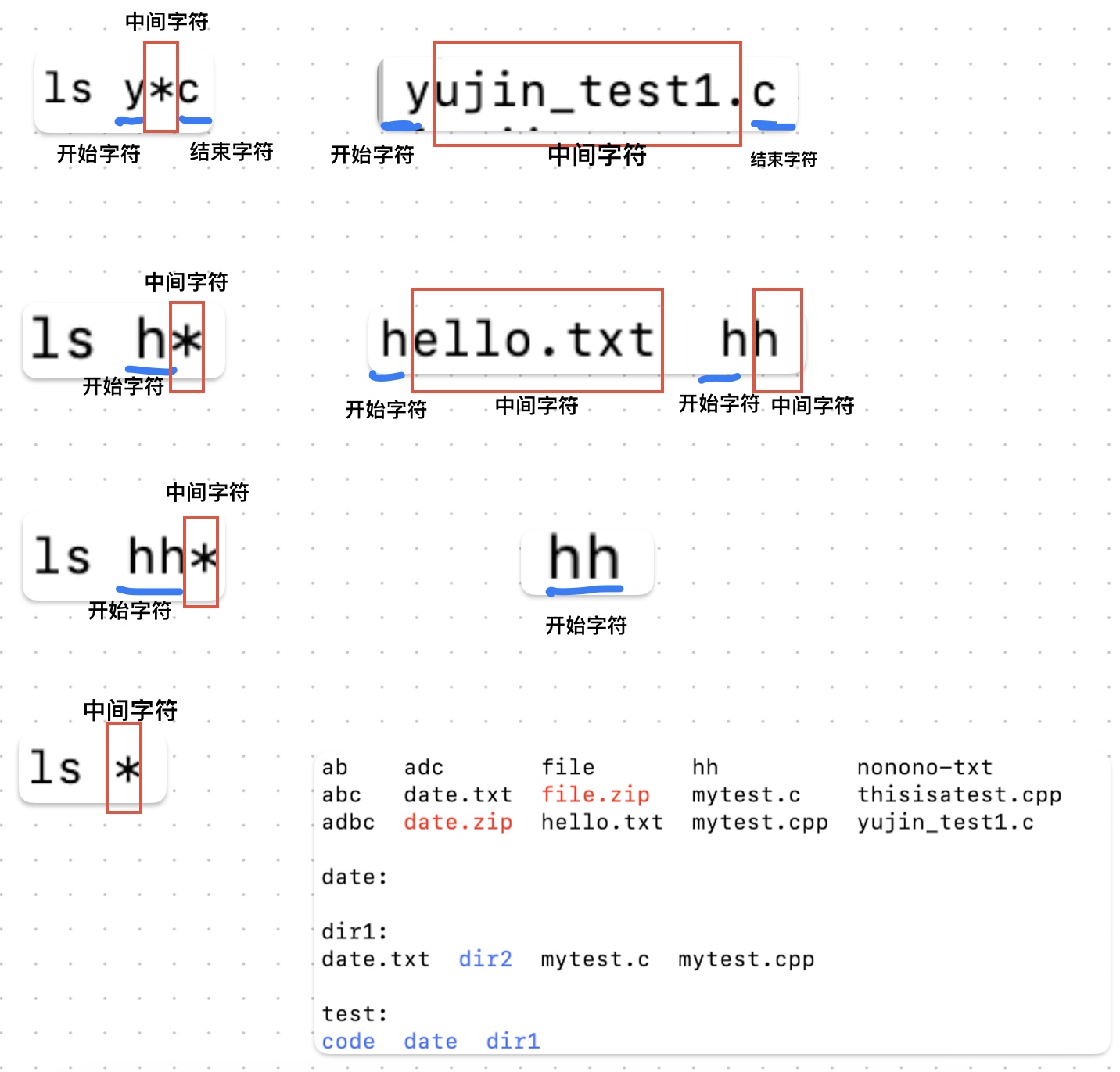
?:匹配任意一个字符
开始字符?结束字符 # 会匹配满足 文件名开头 和 文件名结尾 分别与开始字符和结束字符相同的、中间只有一个字符的文件。
- 1
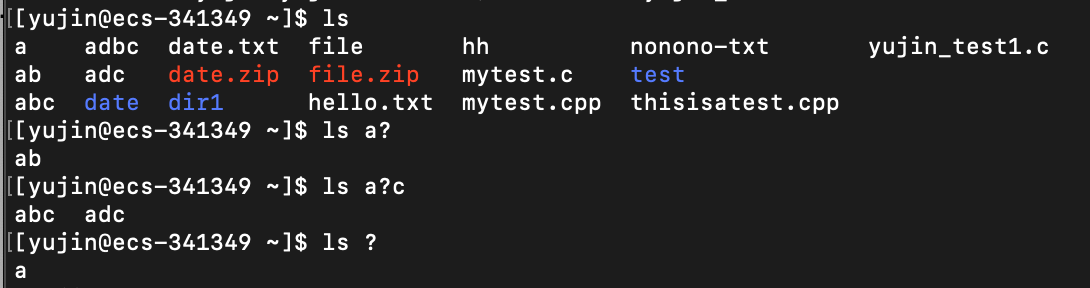
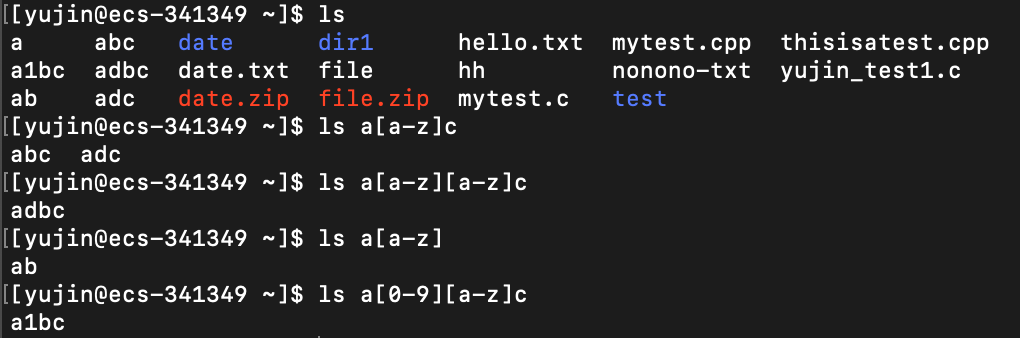
[…]:匹配中括号内出现的任意一个字符
开始字符[…]结束字符 # 会匹配满足 文件名开头 和 文件名结尾 分别与开始字符和结束字符相同的、中间存在于[]内且只有一个字符的文件
- 1
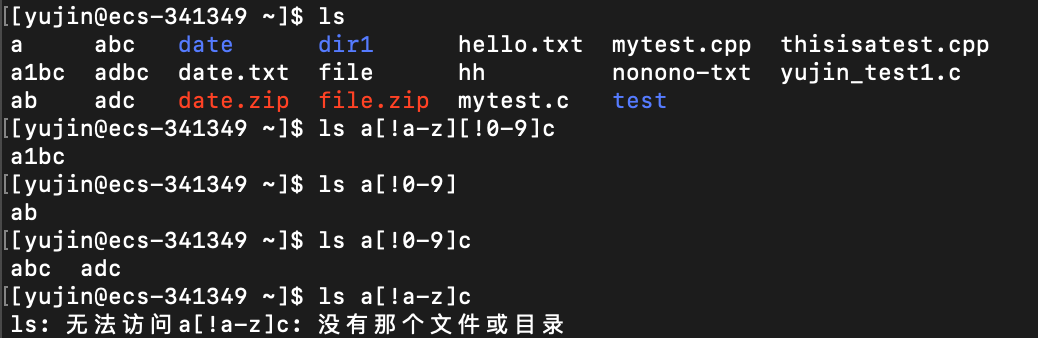
[!..]:不匹配中括号内出现的任意一个字符
开始字符[!…]结束字符 # 会匹配满足 文件名开头 和 文件名结尾 分别与开始字符和结束字符相同的、中间不存在于[]内且只有一个字符的文件
- 1
通配符可以作为一个选项,在非常多的命令中都可以用到,用来匹配文件名
一般出现在要shell命令或脚本中,匹配特定的文件名
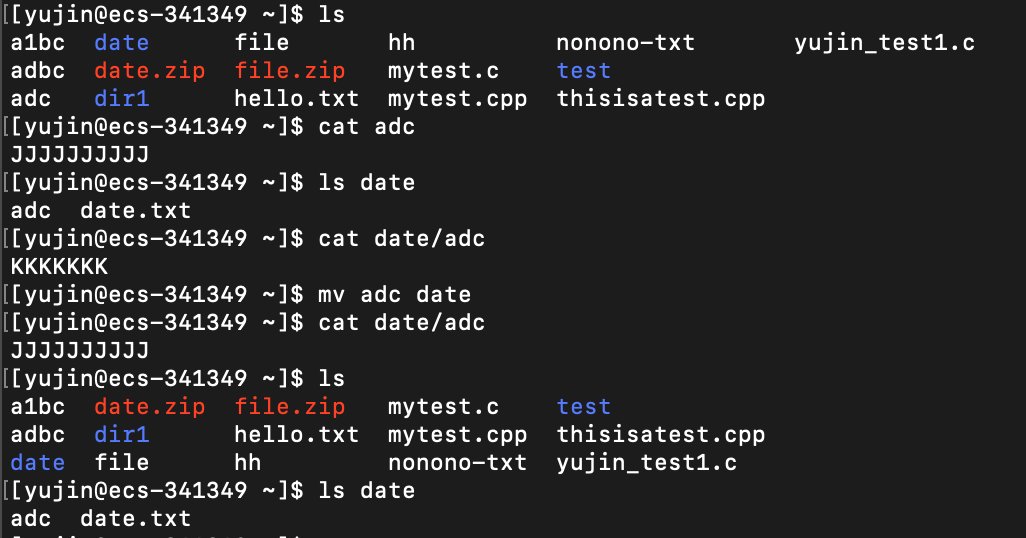
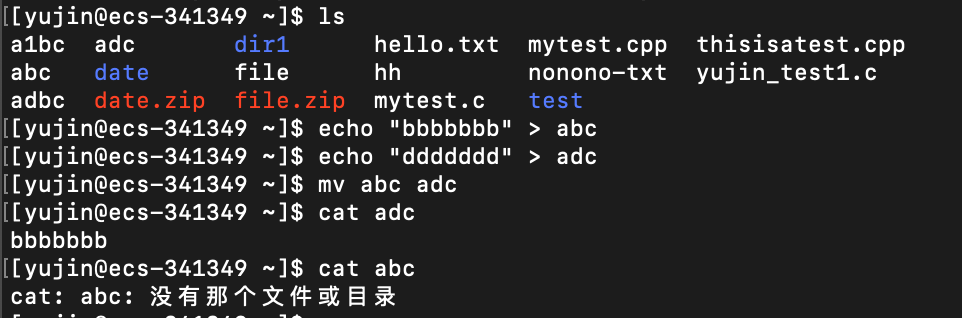
mv
语法:
mv [option] 源文件 指定目录
mv [option] 源文件 文件名(文件名也可以是指定目录下的某个文件的文件名,但是这样不是多此一举了吗)
功能:
将 源文件 移动 到指定目录下。如果指定目录下存在与源文件重名的文件,则默认会被刚移动进来的源文件覆盖掉
将 源文件 改名为 给定的文件名。如果当前目录下已经存在与给定文件名重名的文件,则默认会被新改过名的源文件覆盖掉
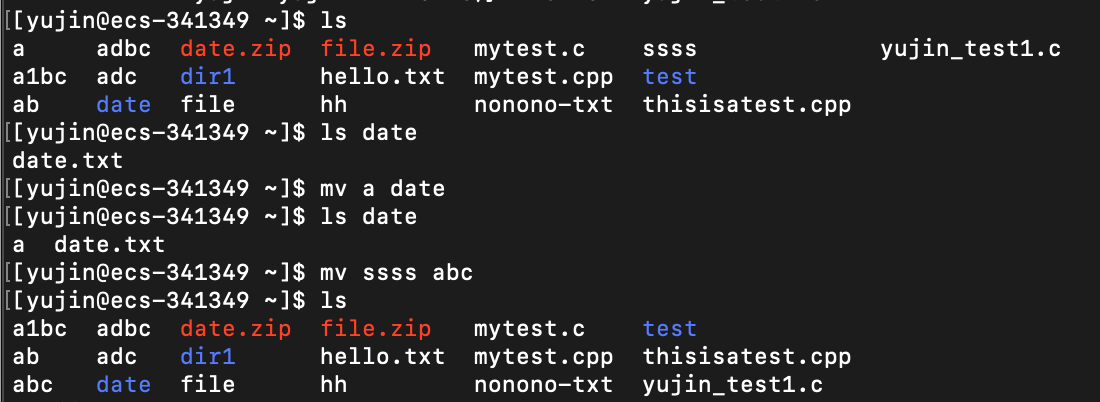
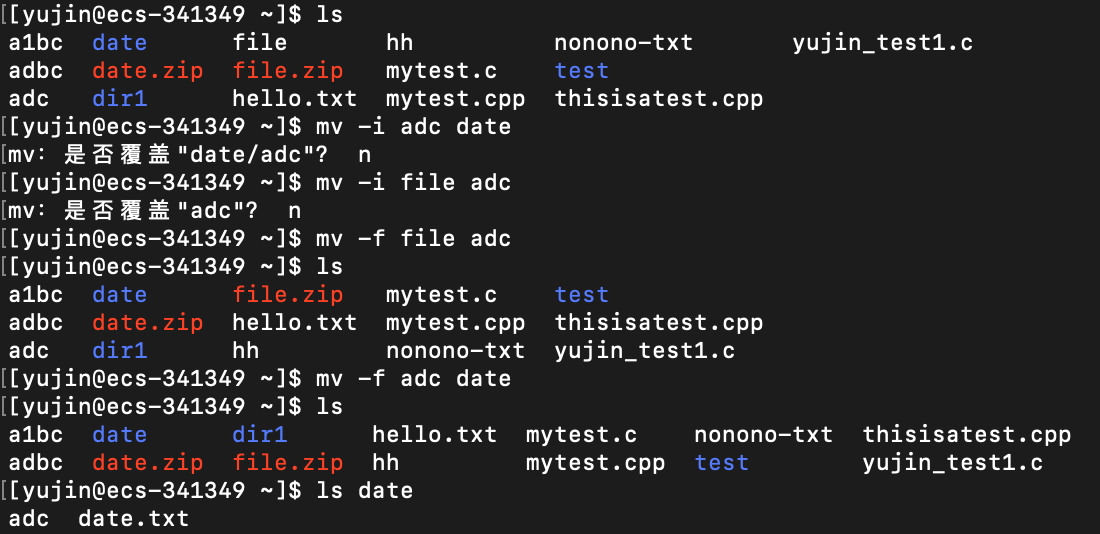
常用选项:
-f # force强制,在移动或改名时,如果出现了重名情况,不会询问而是直接复覆盖
-i # 在移动或改名时,如果出现了重名情况,会询问是否覆盖
- 1
- 2
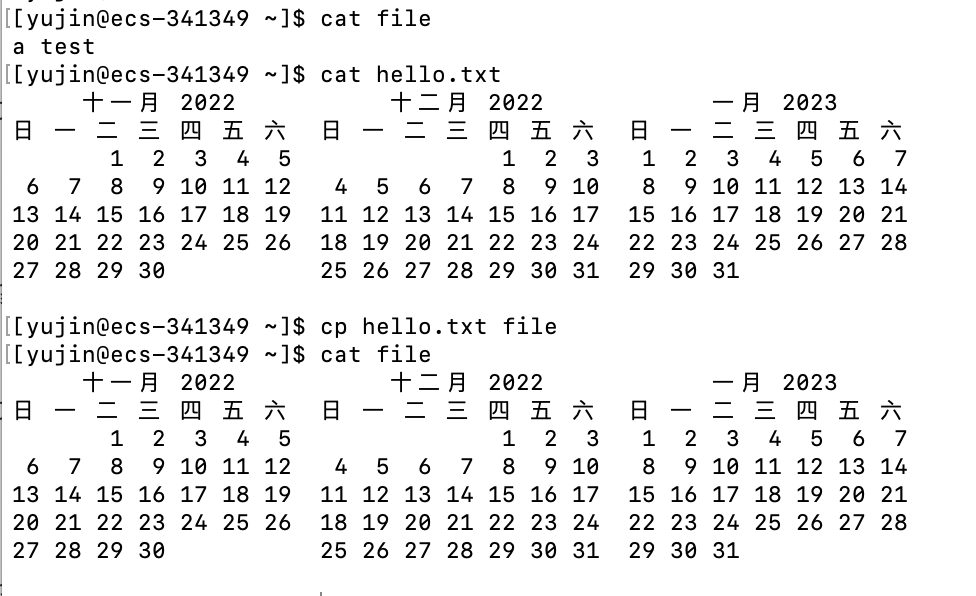
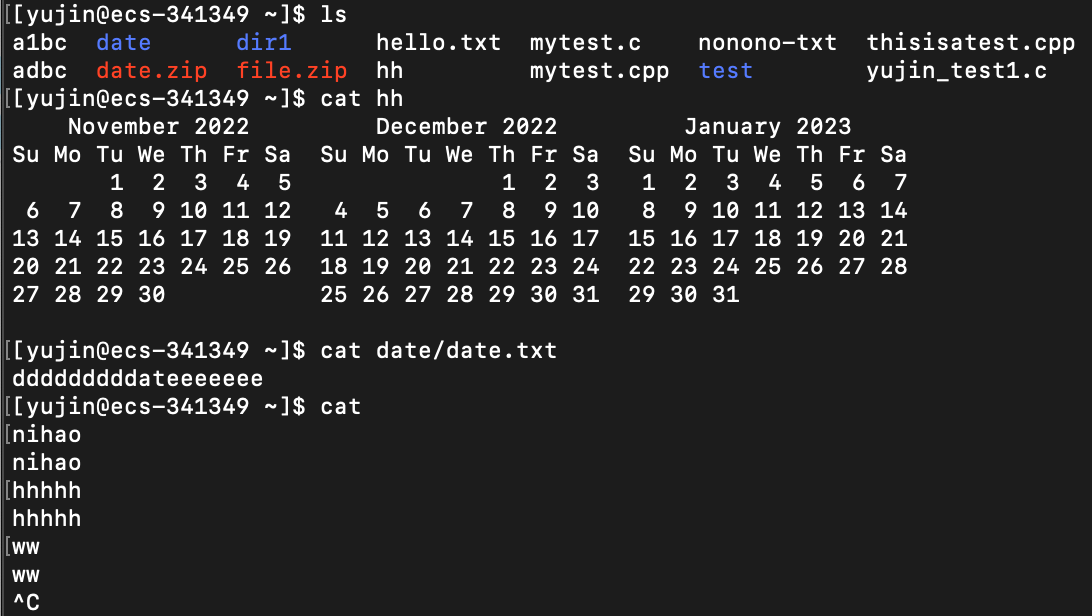
cat
语法:
cat [选项] [目标文件]
功能:
输出内容到指定输出设备(默认指定输出设备是显示器):
如果目标文件没被省略,打印/输出目标文件的内容
如果目标文件被省略,则是打印/输出刚刚从键盘上输入的内容(Linux下一切皆文件,默认将键盘视为了文件),ctrl + c结束
常用选项:
-b # 对非空输出行编号
-n # 对输出的所有行编号
-s # 不输出多行空行
- 1
- 2
- 3
more
语法:
more [选项] 文件
功能:
类似于cat,但是逐页后翻逐页打印/输出,并可以查看前面已打印/输出的内容,支持跳转
按键用途:
按键 用途 空格space,f,ctrl+f 向下滚动一屏(后翻,下一页) b(意味着back),ctrl+b 向上滚动一屏(前翻,上一页) q 退出查看 enter 向下n行,需要定义。默认为1行 = 输出当前的行号 !命令 调用shell,并执行命令 v 调用vi编辑器
向后翻页

向前翻页,按q退出
文件内容是被打印出来的

常用选项:
+NUM # 从文件的第NUM行开始打印
-NUM # 每页只输出NUM行
+/STRING # 在目标文件中寻找含有字符串STRING的一行,并从它的前两行开始打印
-p # 不滚屏,清屏并打印文本
-c # 不滚屏,打印文本并清理行尾
-u # 不打印文件中的下划线
-s # 压缩多个连续空行为一个空行
-d # 显示帮助,提示“Press space to continue,’q’ to quit(按空格键继续,按q键退出)”,禁用响铃功能
-f # 统计逻辑行数而不是屏幕行数
-l # 忽略ctrl+l(换页)字符,抑制换页(form feed)后的暂停
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
说明:
cat和more指令的本质是将文件内容==打印==出来。
因此实际上只能不断打印输出文件后面的内容,对于文件前面的内容,只能通过翻页的方式查看已经打印出来的。
当用 more +NUM,从第NUM行开始查看的时候,NUM行之前的内容由于没有被打印出来,所以无法查看到。
所以cat和more指令更像是文件内容打印指令,而不是正统的文件内容查看指令。
less
说明:
Linux正统的文件内容查看工具
less是进入文件内部加载,进行浏览查看,而不是将文件内容打印出来再进行查看
less在查看之前不会加载整个文件,只加载浏览位置的内容
less可以随意浏览文件内容,可以用上下、翻页(pagedown\pageup)、空格、回车、b、f等按键 随意前后移动查看,功能强大,用法具有弹性
前后移动查看
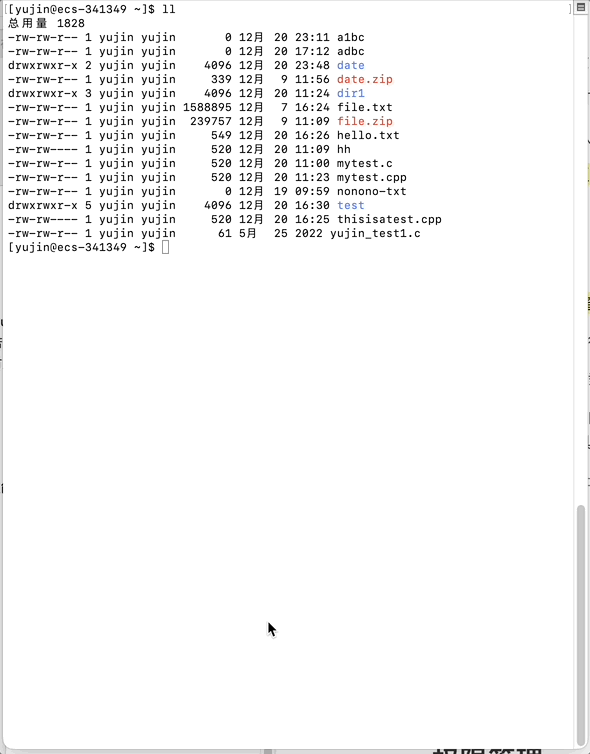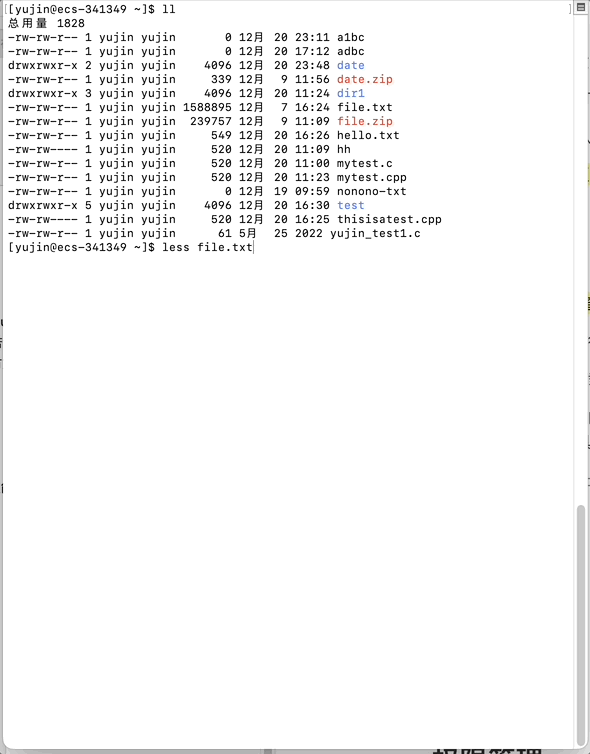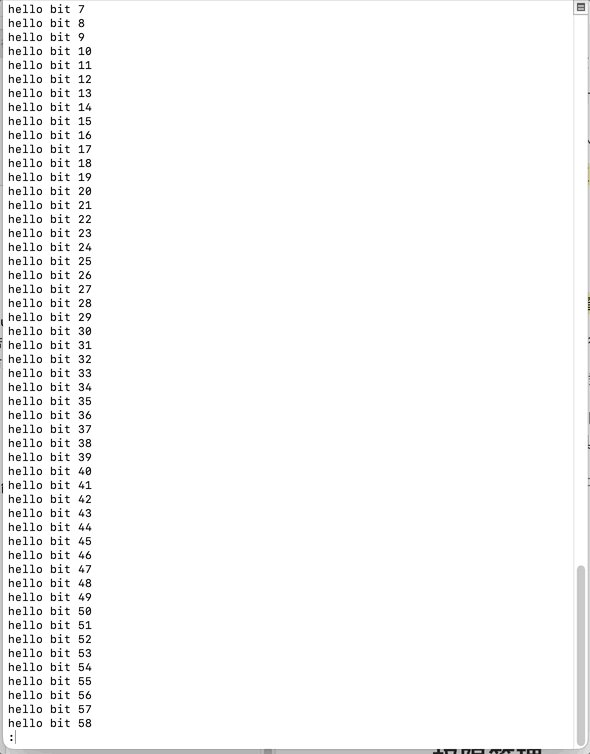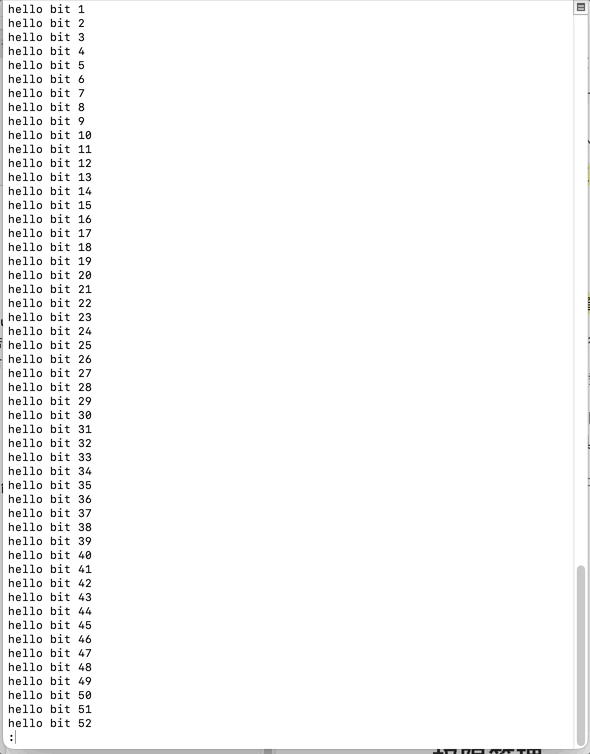
退出,发现less并不是将文件内容打印出来,而是进入文件加载,进行浏览查看
语法:
less [option] 文件
按键用途:
| 按键 | 用途 |
|---|---|
| 按键 | 用途 |
| 空格space,f,ctrl+f,pageup | 向下滚动一屏(后翻,下一页) |
| b(意味着back),ctrl+b,pagedown | 向上滚动一屏(前翻,上一页) |
| d,ctrl + d | 向下滚动半屏 |
| u,ctrl + u | 向上移动半屏 |
| ↓,j | 向下滚动一行 |
| ↑,k | 向上滚动一行 |
| g | 移动到第一行 |
| NUMg | 移动到文件的第NUM行 |
| G | 移动到最后一行 |
| enter | 向下n行,需要定义。默认为1行 |
| q,ZZ | 退出查看 |
| /STRING | 向下搜索“STRING” |
| ?STRING | 向上搜索“STRING” |
| n | 重复前一个搜索(与 / 或 ? 有关) |
| N | 反向重复前一个搜索(与 / 或 ? 有关) |
| ma | 使用a标记文本的当前位置 |
| a | 跳转到a标记处 |
| h | 显示less的帮助文档 |
| !命令 | 调用shell,并执行命令 |
| v | 调用vi编辑器 |
常用选项(可以在浏览文件时使用):
-i # 忽略搜索时的大小写
-N # 显示每行的行号,再用一次会取消显示每行的行号
- 1
- 2
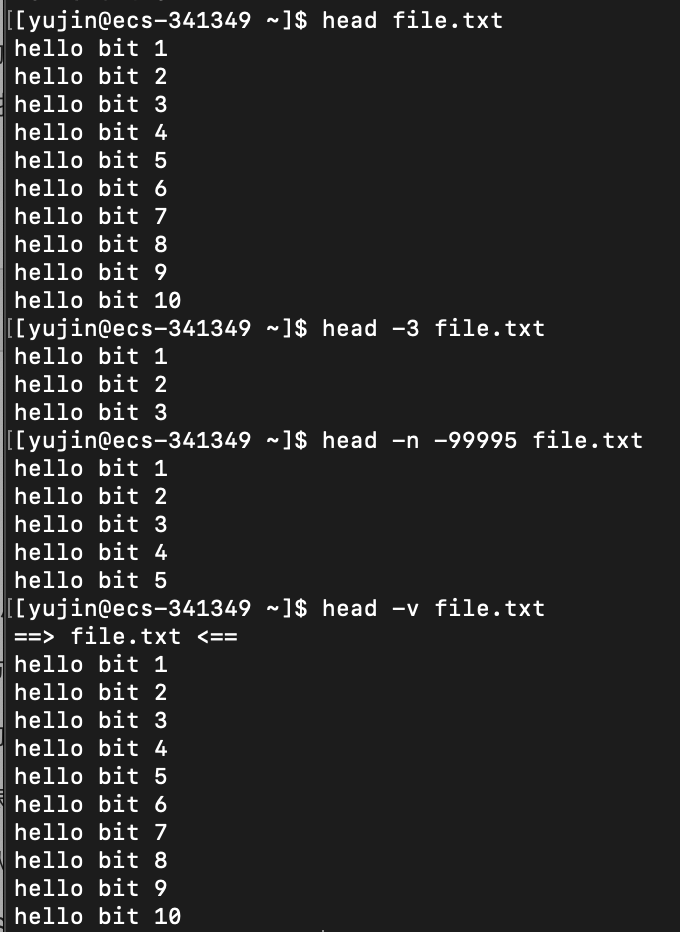
head
语法:
head [option] 文件
功能:
从指定文件的开头开始输出到标准输出,到文件的某位置结束。默认打印前10行
常用选项:
-n +NUM # 打印前NUM行,可以简写成 -n NUM 或 -nNUM 或者 -NUM
-n -NUM # 从第一行开始打印,到倒数第NUM行停止。
-c +SIZE # 从头开始打印,到SIZE个字节停止。可以简写成 -c SIZE 或 -cSIZE
-c -SIZE # 从头开始打印,到倒数第SIZE个字节停止。
-q # 不显示详细处理信息,比如文件名 (默认就是隐藏的)
-v # 显示详细处理信息
- 1
- 2
- 3
- 4
- 5
- 6
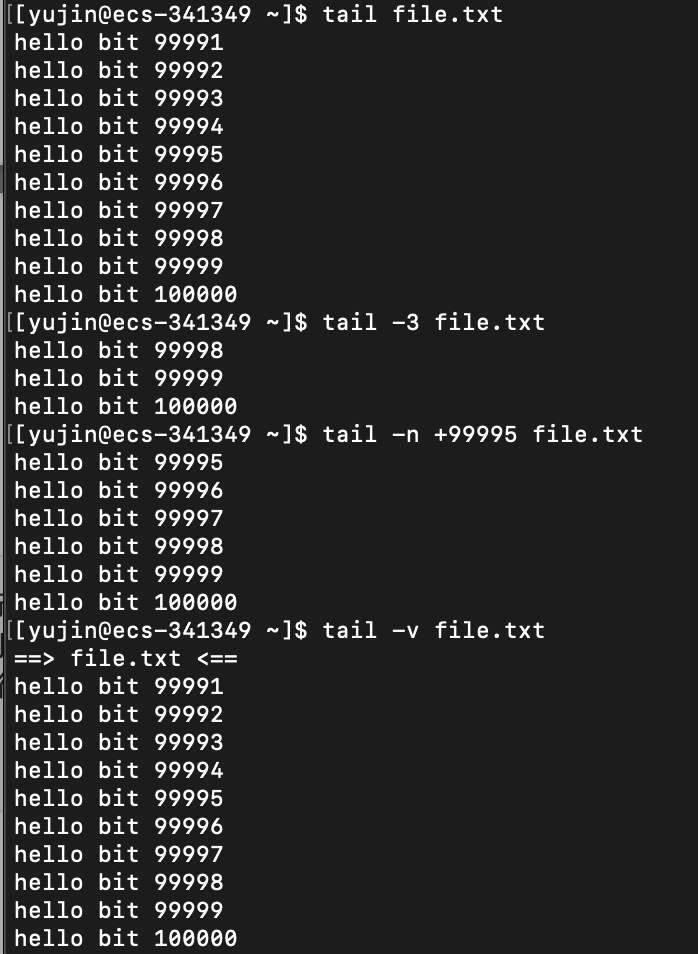
tail
语法:
tail [option] [文件]
功能:
有指定文件时,用于从文件某位置开始输出到标准输出,到文件末尾结束。默认打印文件的最后10行。
无指定文件时,作为输入信息进行处理。
常用来查看日志文件。
常用选项:
-n -NUM # 从倒数第NUM行开始输出,到结尾结束。可以简写成 -n NUM 或 -nNUM 或 -NUM。
-n +NUM # 从正数第NUM行开始输出,到结尾结束。
-c -SIZE # 从倒数第SIZE个字节开始输出,到结尾结束。可以简写成 -c SIZE 或 -cSIZE
-c +SIZE # 从正数第SIZE个字节开始输出,到结尾结束。
-f # 循环读取
-p # 不显示详细处理信息,比如文件名(默认就是不显示的)
-v # 显示详细的处理信息
-s S # 与-f合用,表示在每反复的间隔休息S秒
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
现在创建了一个一共100行的文件,请取出第50行
生成1到100的序列并输出重定向到文件atest方法一:
将atest的前50行输出重定向到新文件tmp中

输出tmp的最后一行

方法二:
利用管道,输出atest的前五十行的最后一行s

管道(简介)
将两个或者多个命令(程序或者进程)连接到一起,把一个命令的输出作为下一个命令的输入,以这种方式连接的两个或者多个命令就形成了管道(pipe)
管道可以级联多个命令,将上一个命令的输出作为下一个命令的输入,实现流水线式的操作
command1 | command2
command1 | command2 |......| commandN
- 1
- 2

当在两个命令之间设置管道时,管道符|左边命令的输出就变成了右边命令的输入。只要第一个命令向标准输出写入,而第二个命令是从标准输入读取,那么这两个命令就可以形成一个管道。大部分的 Linux 命令都可以用来形成管道。
这里需要注意,command1 必须有正确输出,而 command2 必须可以处理 command2 的输出结果;而且 command2 只能处理 command1 的正确输出结果,不能处理 command1 的错误信息。
多个被级联起来的命令就像是组成了几条管道联通起来,数据资源在里面进行了传输,非常形象
echo
语法:
echo [option] 输出内容 [输出重定向]
功能:
将内容输出到到标准输出(默认输出设备是显示器,可以通过输出重定向进行更改输出设备)
常用选项:
-e # 支持反斜杠控制的字符转换(具体参见下表)
-n # 取消输出后行末的换行符号(内容输出后换行)
- 1
- 2

| 控制字符 | 作 用 |
|---|---|
| \ | 输出\本身 |
| \a | 输出警告音 |
| \b | 退格键,也就是向左删除键 |
| \c | 取消输出行末的换行符。和“-n”选项一致 |
| \e | Esc键 |
| \f | 换页符 |
| \n | 换行符 |
| \r | 回车键 |
| \t | 制表符,也就是Tab键 |
| \v | 垂直制表符 |
| \Onnn | 按照八进制 ASCII 码表输出字符。其中 0 为数字 0,nnn 是三位八进制数 |
| \xhh | 按照十六进制 ASCH 码表输出字符。其中 hh 是两位十六进制数 |

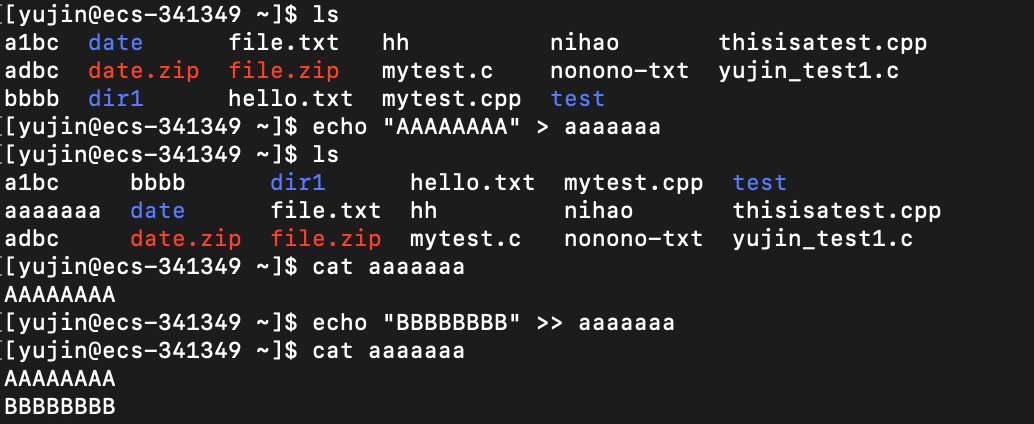
echo经常搭配输出重定向使用,将输入输出到指定文件中,而且如果指定文件不存在,还会创建出来(输出重定向的作用)
重定向(简介)
Linux 中标准的输入设备/标准输入 默认是 键盘,标准的输出设备/标准输入 默认是 显示器
- 输入重定向:指的是重新指定设备来代替键盘作为新的输入设备;
- 输出重定向:指的是重新指定设备来代替显示器作为新的输出设备。
新的输入设备:通常是指文件或者命令的执行结果
新的输出设备:通常是指文件
输入重定向:
命令符号格式 作用 命令 < 文件 将指定文件作为命令的输入设备 命令 << 分界符 表示从标准输入设备(键盘)中读入,直到遇到分界符才停止(读入的数据不包括分界符),这里的分界符其实就是自定义的字符串 命令 < 文件 1 > 文件 2 将文件 1 作为命令的输入设备,该命令的执行结果输出到文件 2 中。 命令 < 文件:用文件代替默认输入设备(键盘)的输入
当使用cat命令时,如果不加目标文件,会从默认输入设备上获取输入并输出到默认输出设备
更改默认输入设备为指定文件(这就跟cat命令后面加目标文件一个效果了)

命令 << 分界符:
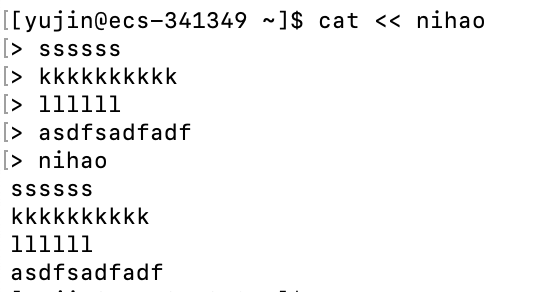
命令 < 文件 1 > 文件 2:是输入重定向和输出重定向的结合使用

输出重定向:
使用频率更高,将命令的结果重定向输出到指定的新输出设备(即文件)中
注意如果指定的文件是不存在的,输出重定向的时候会创建出这个文件
输出重定向按性质 分为 标准输出重定向和 错误输出重定向 两种
当命令正确执行时,会产生正确的输出结果,此时将正确的输出结果作为输出设备时是标准输出重定向
当命令执行失败时,会产生错误输出信息,此时将错误输出信息作为输出设备时时错误输出重定向
两种在写法上没有区别,只是按照命令的执行成功与否进行了分类
输出重定向按用法 分为 清空写入重定向(>) 和 追加写入重定向(>>)
清空写入重定向(>):将命令的结果重定向输出到指定的文件中,如果该文件原来已经包含数据,会清空原有数据,再写入新数据
追加写入重定向(>>):将命令的结果重定向输出到指定的文件中,如果该文件原来已经包含数据,新数据会写入原有数据的后面
命令符号格式 作用 命令 > 文件 将命令执行的标准输出结果重定向输出到指定的文件中,如果该文件已包含数据,会清空原有数据,再写入新数据。 命令 2> 文件 将命令执行的错误输出结果重定向到指定的文件中,如果该文件中已包含数据,会清空原有数据,再写入新数据。
注意,"2>"是固定格式命令 >> 文件 将命令执行的标准输出结果重定向输出到指定的文件中,如果该文件已包含数据,新数据将写入到原有内容的后面。 命令 2>> 文件 将命令执行的错误输出结果重定向到指定的文件中,如果该文件中已包含数据,新数据将写入到原有内容的后面。
注意,"2>"是固定格式命令 >> 文件 2>&1 或者 命令 &>> 文件 将标准输出或者错误输出写入到指定文件,如果该文件中已包含数据,新数据将写入到原有内容的后面。
注意,第一种写法中,最后的 “2>&1” 是一体的,可以认为是固定写法。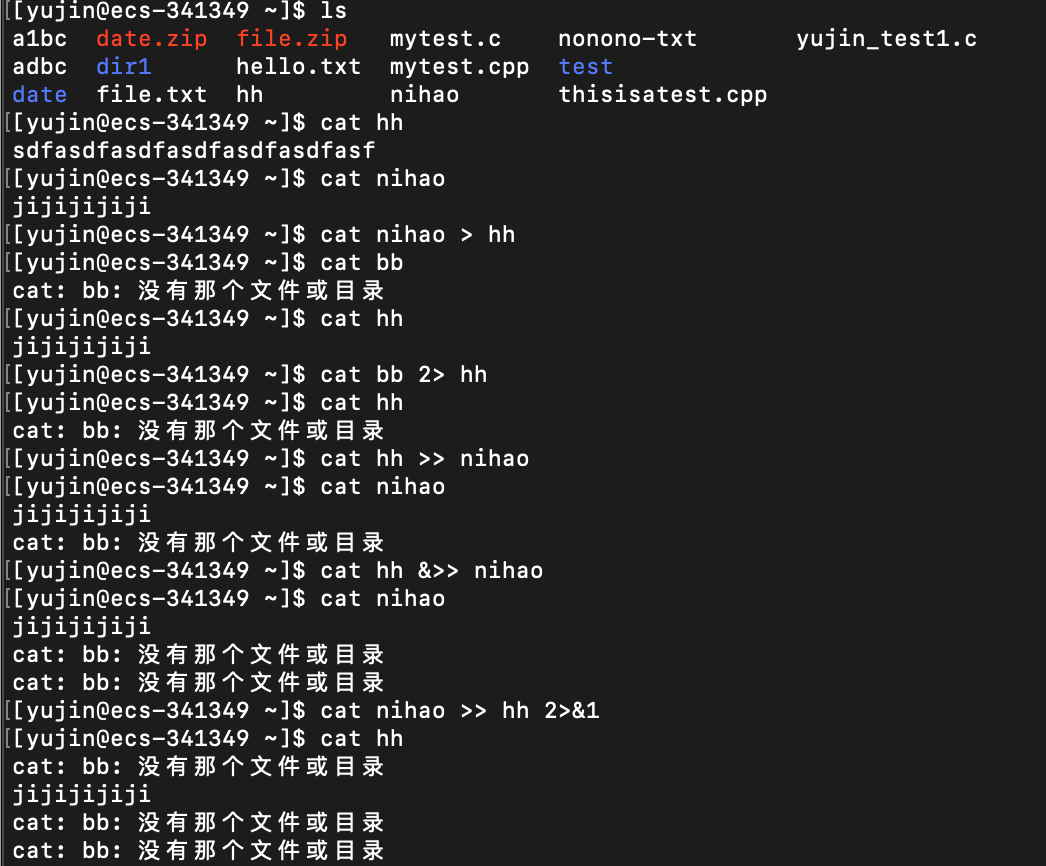
find
语法:
find [pathname] [option]
功能:
在指定目录下查找文件
任何位于选项参数之前的字符串都被视为指定目录
如果使用该命令时,不设置任何参数,则 find 命令将在当前目录下查找子目录与文件。并且将查找到的子目录和文件全部进行显示。
常用选项:
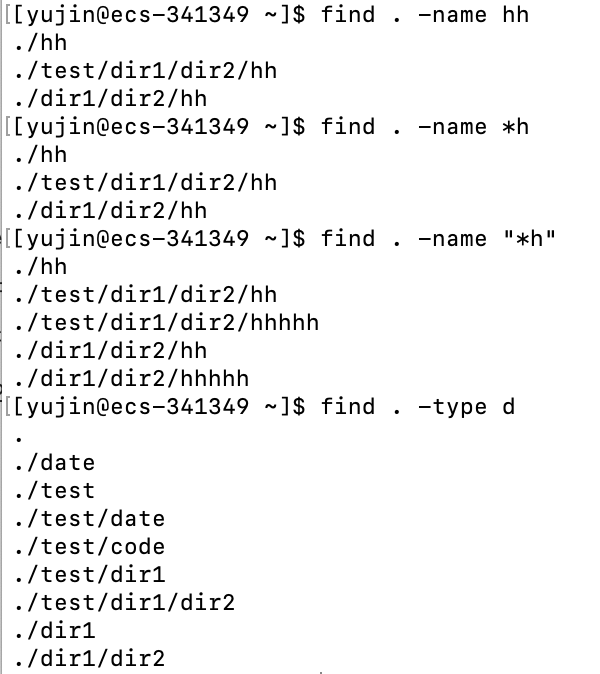
-name "NAME" # 在指定目录和子目录下查找文件名为NAME的文件,双引号可以省略。可以结合通配符使用,这个时候加上双引号搜索到的才是是全面的
-type TYPE # 文件类型是TYPE的文件。f是普通文件,d是目录
- 1
- 2
查看更多用法点这里
Linux下find命令提供了相当多的查找条件,功能很强大。由于find具有强大的功能,所以它的选项也很 多,其中大部分选项都值得我们花时间来了解一下。
即使系统中含有网络文件系统( NFS),find命令在该文件系统中同样有效,只你具有相应的权限。
在运行一个非常消耗资源的find命令时,很多人都倾向于把它放在后台执行,因为遍历一个大的文件系 统可能会花费很长的时间(这里是指30G字节以上的文件系统)。
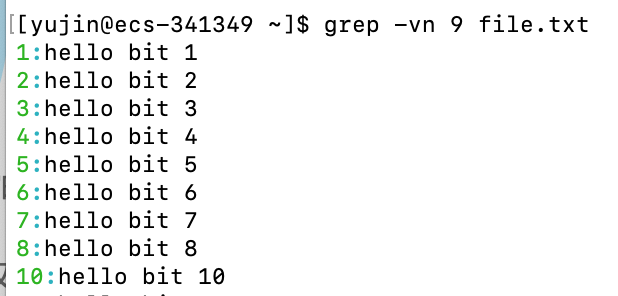
grep
行文本过滤工具
语法:
grep [option] "STRING" 指定文件
功能:
用于查找指定文件里包含STRING的行,将其打印出来
双引号可以省略
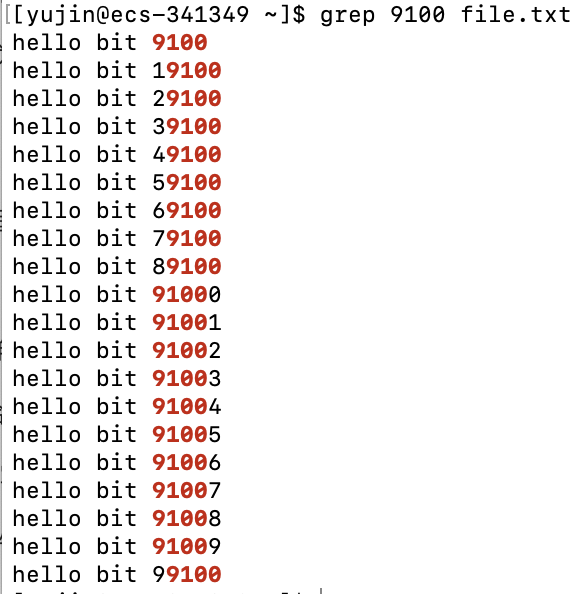
常用选项:
-i # 查找时忽略大小写
-n # 顺便输出在文件中的行号
-v # 反向选择,即打印出不包含被查找的字符串的行
- 1
- 2
- 3
打包 和 压缩:
打包:也称归档、备份,指的是一个文件或者目录的集合,而这个集合被存储在一个文件中。打包文件没有经过压缩,因此占用的空间就是打包文件中所有文件的总空间。
将多个文件打包形成一个包
压缩:利用算法将文件进行处理,以达到保留最大文件信息而让文件体积变小的目的。
只能将一个文件压缩成一个压缩包
打包就像是将行李放进行李箱。压缩就像是为了减少行李的大小,用收纳法将行李的体积折叠的尽可能小,这样就能在箱子里放入更多的行李,也可以将打包好的行李进行收纳,这样行李占用的体积就更小,可以用更小的行李箱。
压缩是将文件的大小减小,起到减少资源占用的作用。
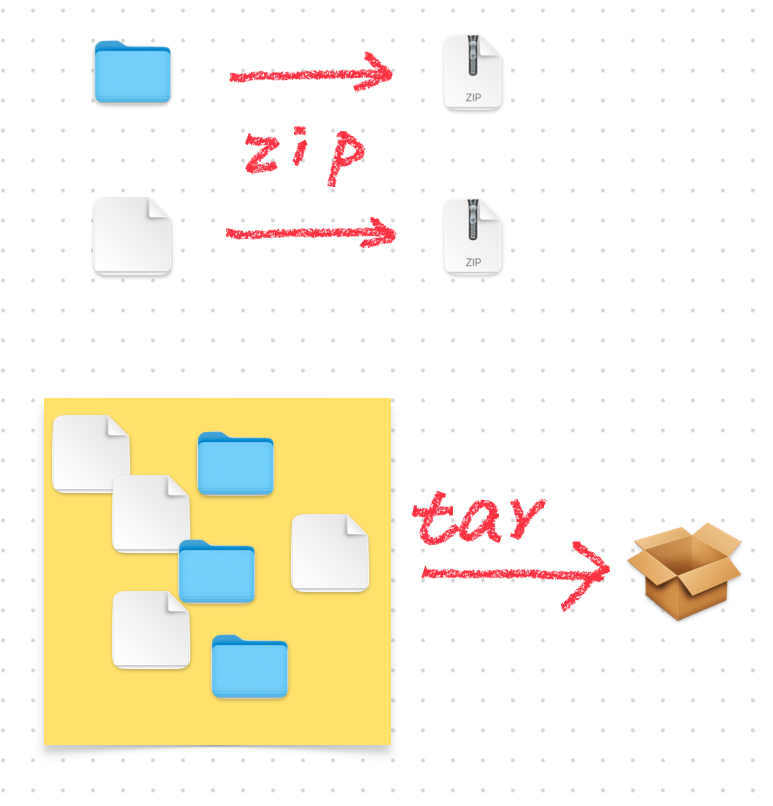
如果想一次性压缩许多零零散散的文件或目录,就得要先把它们打成一个包,然后把这个包压缩。
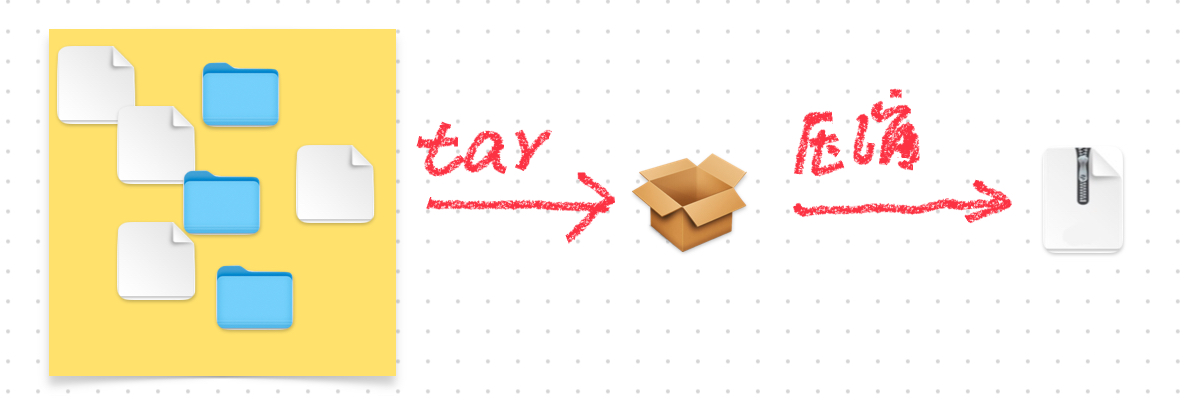
压缩软件打包压缩格式界面:
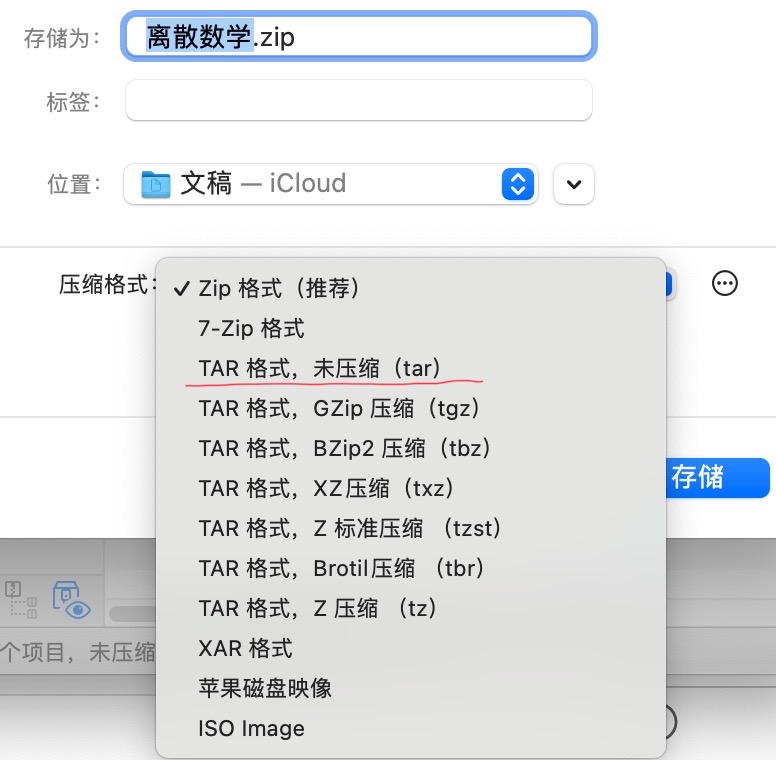
关于普通文件类型的说明:
文件的分类就分为上面介绍的几类
在Linux中,并不以文件的后缀来区分文件类型,无论是.c .cpp .zip .tar .txt等,都是普通文件类型,文件后缀只是在处理文件的时候进行区分,比如只有.zip等才能解压,.c .cpp等才能编译等。它们都是普通文件。
zip/unzip压缩
压缩包拓展名/后缀 是.zip
语法/功能:
zip [option] ZIPNAME 目标文件 :将目标文件压缩为名称为ZIPNAME的压缩包。压缩包的.zip后缀可带可不带,会自动补上
unzip [option] 指定压缩包 :将压缩包解压到当前目录下。若当前目录下有文件与解压后文件重名,会进行询问是否覆盖。注意,解压后文件的名称是压缩前文件的名称,并不是压缩包的名称。
常用选项:
zip
-r # 递归处理,将指定目录下的所有文件和子目录一并处理,分别形成单独的压缩包
-m # 将文件压缩之后,删除原始文件,相当于把文件移到压缩文件中
-v # 显示详细的压缩过程信息(默认)
-q # 在压缩的时候不显示命令的执行过程
-数字 # 压缩级别是从 1~9 的数字,-1 代表压缩速度更快,-9 代表压缩效果更好
-u # 更新压缩文件,即往压缩文件中添加新文件
- 1
- 2
- 3
- 4
- 5
- 6
unzip
-d 指定目录 # 将压缩包解压到指定目录
-n # 解压时不覆盖已经存在的文件
-o # 解压时覆盖已经存在的文件,且不向用户询问
-v # 不解压,只是查看压缩包的详细信息,包括压缩包中包含的文件大小、文件名、压缩比等
-t # 不解压,测试压缩包有损坏
-x 文件列表 # 解压,但不包含文件列表中的指定文件
- 1
- 2
- 3
- 4
- 5
- 6
gzip
只能压缩普通文件。
就算指定了目录,也是将目录下的所有普通文件一一单独压缩出来。压缩文件的拓展名/后缀是.gz
gzip压缩完之后源文件会被删除
语法/功能:
gzip [option] 指定文件
gzip命令十分简单,不需要指定压缩后的文件的名称,压缩后文件的名称是
源文件名.gz
常用命令:
-c # 将压缩数据输出到标准输出中,并保留源文件。可以将数据重定向到压缩包中,这样在不删除源文件的同时还不会将数据打印到屏幕上
-d # 对压缩包解压
-f # 强行压缩或解压文件,不理会文件名或者硬连接是否存在以及该文件是否为符号连接。
-r # 递归压缩指定目录下及其子目录下的所有普通文件
-v # 压缩和解压时,显示压缩包的文件名和压缩比等详细信息
-l # 显示每个压缩文件的大小、压缩比,未压缩文件的大小、未压缩文件的名称等详细信息
-数字 # 压缩级别是从 1~9 的数字,-1 代表压缩速度更快,-9 代表压缩效果更好
-h # 显示帮助
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

bzip2
只能压缩普通文件。
就算指定了目录,也是将目录下的所有普通文件一一单独压缩出来。压缩文件的拓展名/后缀是.bz2
从理论上来讲,bzip2的算法比gzip更先进、压缩比更好;而gzip的压缩速度相对来讲更快
bzip2压缩完之后源文件会被删除
语法:
bzip2 [option] 指定文件
gzip命令十分简单,不需要指定压缩后的文件的名称,压缩后文件的名称是
源文件名.bz2
常用命令:
-c # 将压缩和解压的结果送到标准输出
-d # 解压
-f # 压缩或解压时,若出现输出文件与现有文件重名,会直接覆盖。(默认是不会覆盖的)
-h # 显示帮助
-k # 在压缩或解压后不会删除源文件
-s # 强制进行压缩
-V # 显示版本信息
- 1
- 2
- 3
- 4
- 5
- 6
- 7
tar打包/解包
语法:
tar [option] 指定文件
打包:
也称归档、备份
打包并不是压缩,只是将文件打包到一个集合中,但是如果想要将一堆文件进行压缩的话,首先就得先把这堆零零散散的文件打一个包,这样才方便压缩。所以打包是很重要的。打包后的文件后缀为.tar
常用选项:
-c # 进行打包的指令
-f TARNAME # 指定包的文件名为TARNAME。注意要加上.tar后缀
# 本质上是将打包好的内容输出到名为TARNAME的tar包中
-v # 显示详细过程信息
-A # 追加tar文件到打包文件中
-z TARGZIPNAME # 询问是否在打包后同时进行gzip压缩,并将压缩包命名为TARGZIPNAME。注意要加上后缀.tar.gz
-j TARBZIP2NAME # 询问是否在打包后同时进行bzip2压缩,并将压缩包命名为TAEBZIP2NAME。要加后缀.tar.bz2
-p # 打包的时候保留源文件的属性(权限等)
-N "YYYY/MM/DD" # 打包比某日期新的文件
--exclude 文件 # 打包时不打包该文件
-u # 更新原压缩包的文件
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
说明:
- -cfv 常视作打包的习惯用法
- tar命令的选项中
-是可加可不加的,比如-cfv和cfv是一样的- tar可以将多个文件进行打包,文件之间用空格间隔开就可以。
- tar也可以将目录下的所有文件都打包,例如将date目录下的所有文件都打包:
tar -cvf date.tar ./date/- 通常都是在打包时同时进行gzip或者bzip2压缩
- 要注意,一般情况Linux命令的选项是可以不管顺序的,但是在这里,-f后面紧跟包的名称,所以压缩的时候要把-f放在选项最后,否则会报错
应用举例:
将 ./test 目录下的文件全部打包为
test.tar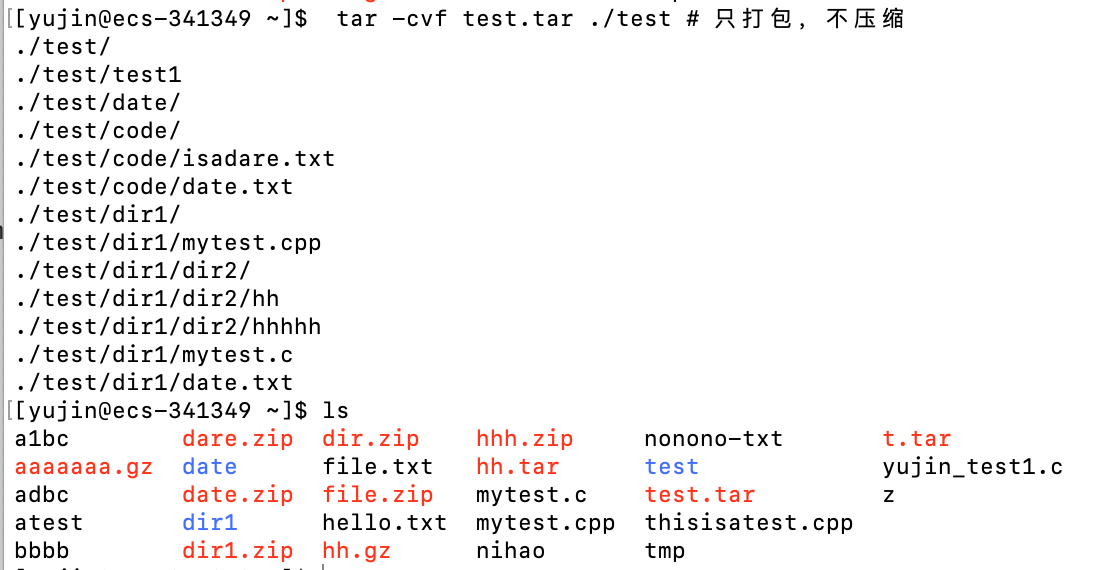
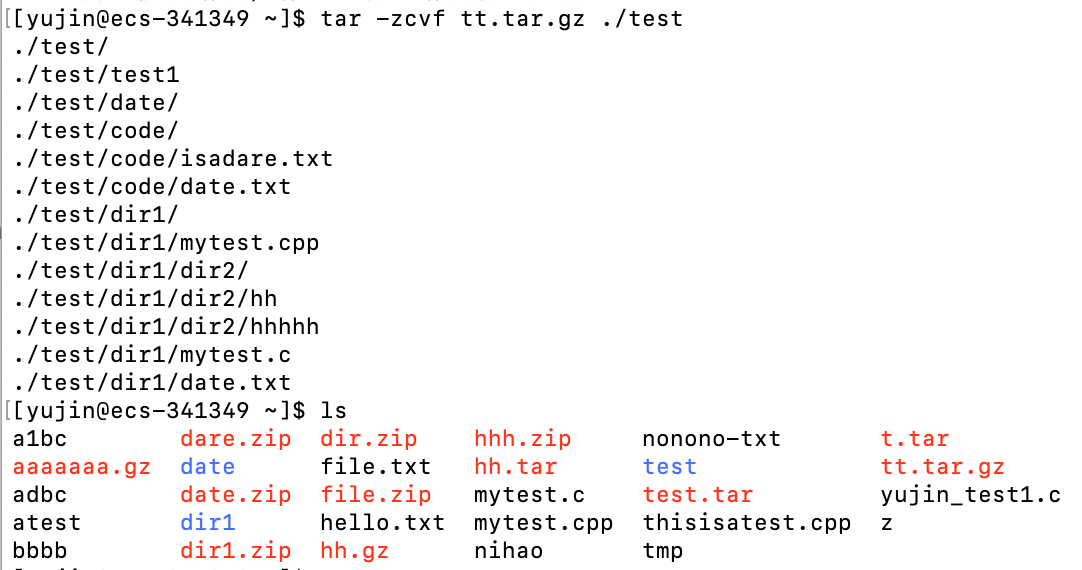
将test目录下的文件全部打包并压缩为
tt.tar.gz注意选项的顺序,-f要放在选项的最后面,否则会报错

打包 ./test 和 ./date并压缩为
myfile.tar.gz,但是不打包./test中的date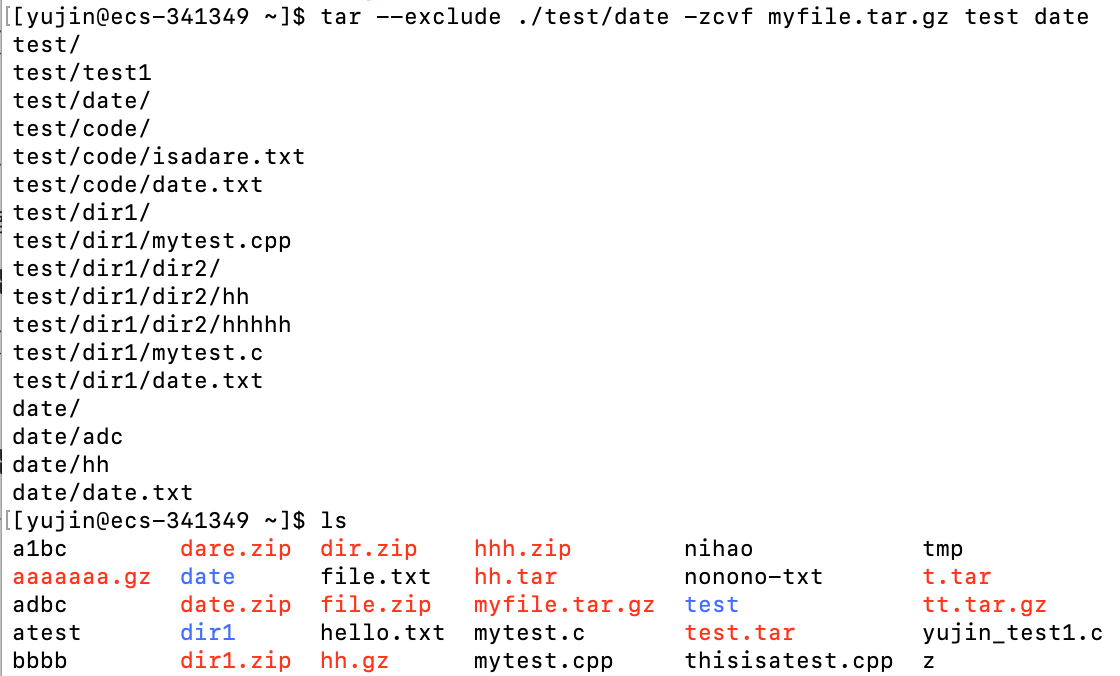
将用户目录下的所有文件备份并压缩,且保留其权限
(使用的相对路径,也可以使用绝对路径)

在最后一行会提示:
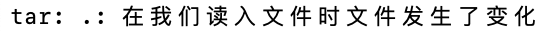
这是因为我们将用户目录中的所有文件都备份并压缩了,在执行完命令之后,会在当前目录下生成压缩包
而当前目录就是用户目录,所以压缩包声明在了用户目录下
原来的目标文件,也是用户目录,所以原来的目标文件内容发生了变化,就会给出这个提示
如果再执行一次这个命令(使用的绝对路径,也可以使用相对路径)
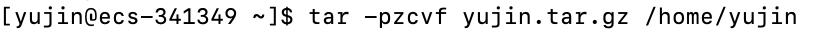
会在压缩的时候显示
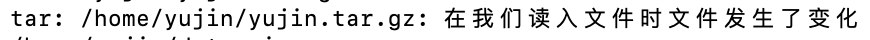
因为在压缩之前已经有了yujin.tar.gz这个文件,在压缩用户目录的时候会将它压缩,然后在压缩完用户目录之后又会生成yujin.tar.gz这个压缩包,相当于时间先后、新旧文件的更改,所以会给出这种说明
在test目录下,比2022/12/26新的文件才会被打包
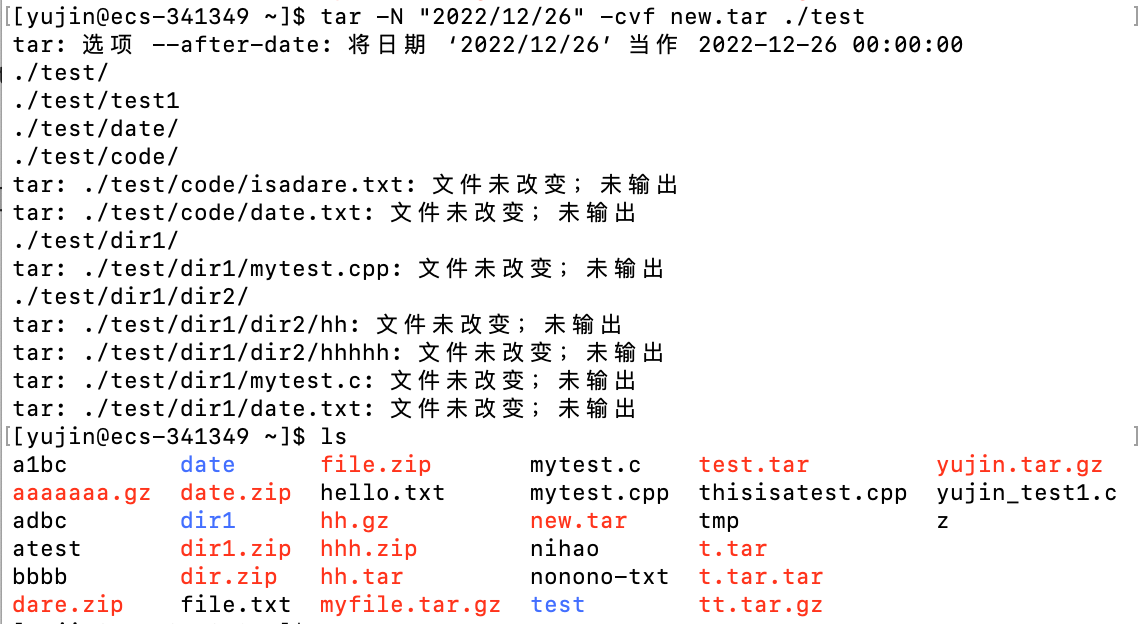
命令的最后面可以是
./test也可以是./test/或者test、test/
解包:
常用选项:
-t # 不解包,直接查看tar包里的内容
-x # 解包
-v # 显示详细过程信息
-f # 查看或解包.tar时带上这个选项
-z # 如果压缩包是.tar.gz,那么查看或者解包的时候要加上这个选项
-j # 如果压缩包是.tar.bz2,那么查看或者解包的时候要加上这个选项
-C 指定目录 # 解压到指定目录。如果不带此选项,默认是解包到当前目录
- 1
- 2
- 3
- 4
- 5
- 6
- 7
应用举例:
查看上面压缩的
mylife.tar.gz中的文件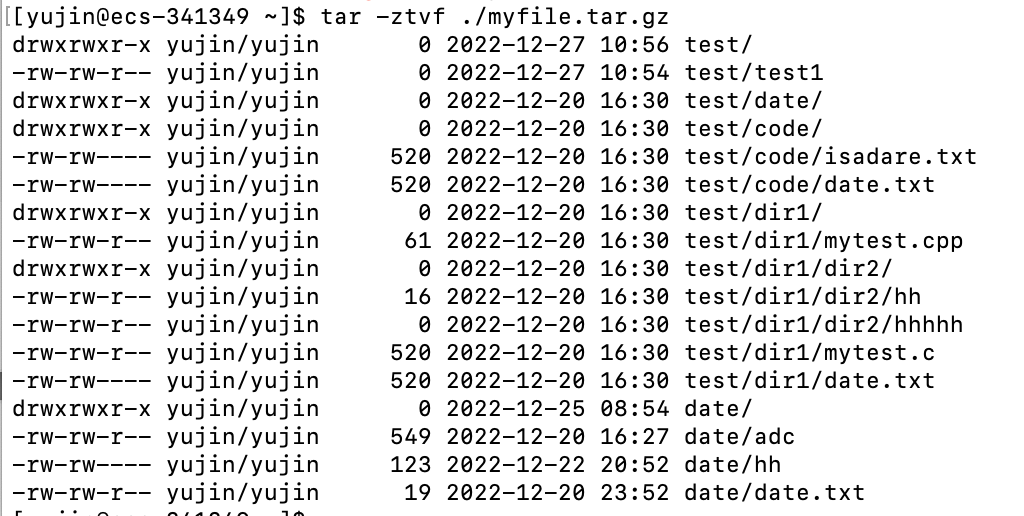
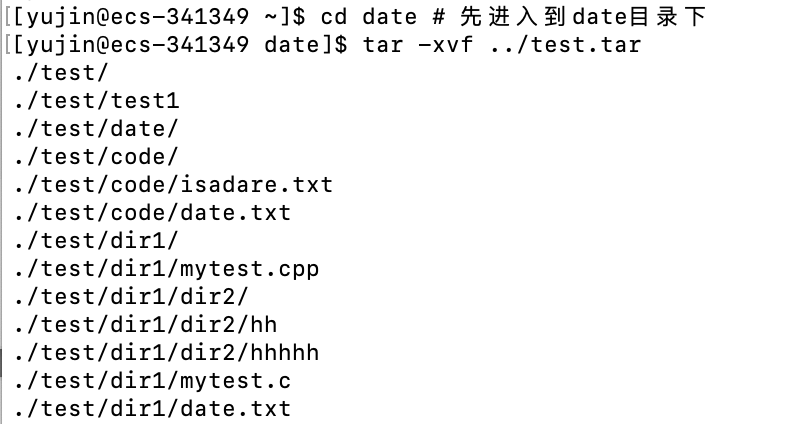
将
test.tar解包到date目录下可以先进入到指定目录,再解压到当前目录
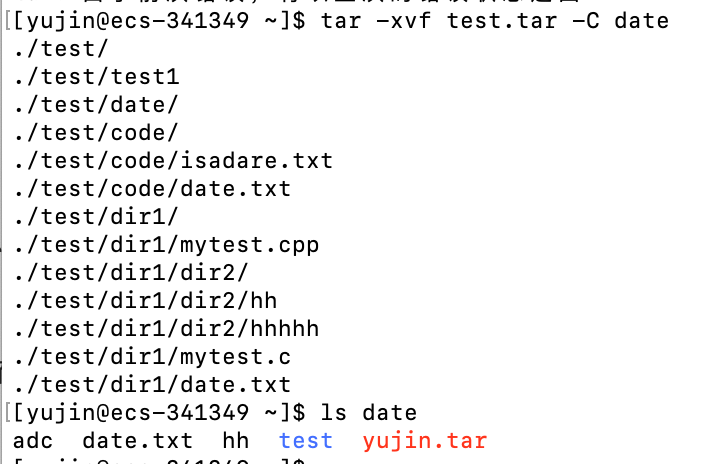
也可以用选项-C直接解压到指定目录
只想将
test.tar.gz中的dir1解开到当前目录
可以看到,解压出的文件是按照原来的层级形成的,解压出test目录下的dir1目录下的mytest.c
将a目录进行打包,并立即在dir1目录下解开它(这就相当于将a目录移动到dir1目录下,跟cp类似)
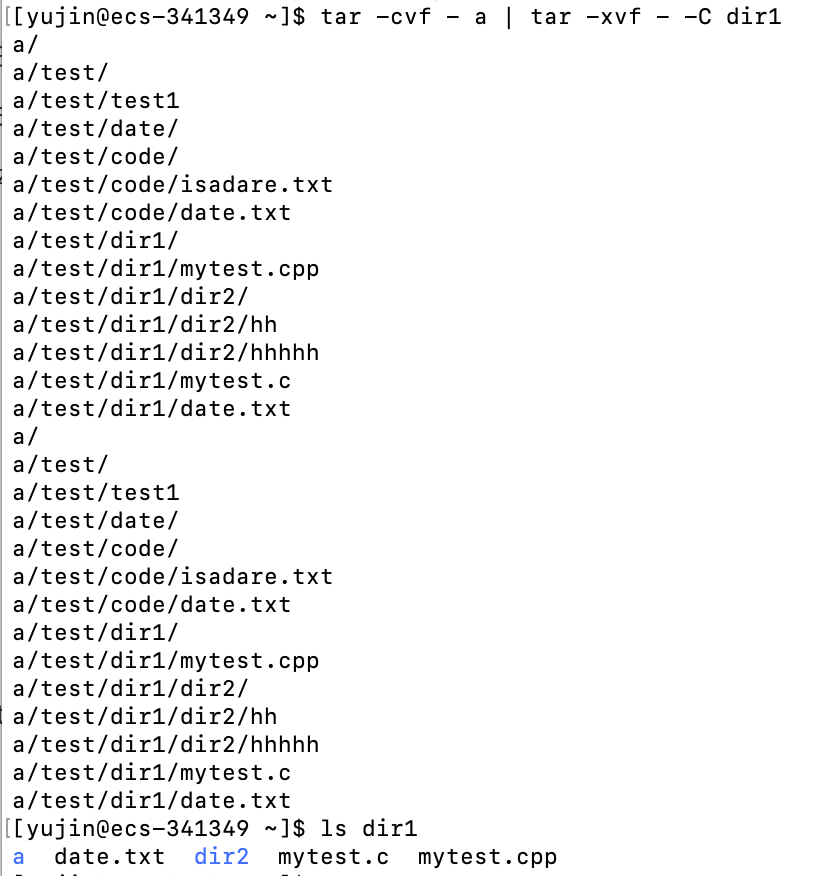
运用了管道,将前一个命令的输出作为后一个命令的输入
这里的单独的
-意思是标准输入输出(standard input , standard output)在前面的命令中,是将a目录进行打包,然后输出到-f 后面的文件中,-f后面跟的是-,也就是标准输出,所以就是将打包好的a目录输出到了标准输出
在后面的命令中,-xvf 后面跟的是 - ,也就是要解压的包是标准输出上的,并解压到dir1
这样就用管道命令和标准输入输出实现了
bc
可以很方便进行浮点运算,用的时候man一下查找用法即可,此处不再赘述
uname
语法:
uname [option]
功能:
显示电脑的操作系统等信息
常用选项:
-a # 输出所有详细信息,依次为内核名称、主机名、内核版本号、内核版本、硬件名、处理器类型、硬件平台信息、操作系统名称
- 1
几个重要的热键
| 按键 | 功能 |
|---|---|
| Tab | 命令补全、档案补齐 |
| ctrl + c | 终止当前进程 |
| ctrl + d | 代表“键盘输入结束(End of file,EOF,End of input)“的意思; 另外,也可以取代exit命令来登出Linux账户 |
更多快捷键请见linuxJournal中的快捷键整理
Linux权限的概念
用户
Linux中有两种用户:超级用户(root)、普通用户
超级用户:可以在Linux系统内做任何事情,不受限制。命令提示符是:#
普通用户:在Linux下做有限的事情。命令提示符是:$
用户切换指令:su
语法:
su [USERNAME]
功能:
切换用户
说明:
当只使用su命令的时候,是切换到root用户,输入root用户的密码
当使用 su USERNAME 的时候,是切换到名称为USERNAME的普通用户,并要输入那个用户的密码;如果是从root切换到别的普通用户,不需要输入密码
sudo
语法:
sudo [option] 指令
功能:
以root身份执行当前指令
说明:
不会切换身份,只是用root身份执行指令,当前用户(使用sudo命令的用户)不变,相当于在执行指令的时候暂时提高了权限
常用选项:
-u USERNAME # 以USERNAME身份执行当前命令
-l # 显示当前用户(使用sudo命令的用户)的权限
- 1
- 2
权限管理
文件访问者的分类:
访问文件的人有三种
文件的所有者:u——User
文件所有者所在组的用户:g——Group
其他用户:o——Others
其中,文件的创建者不一定就是文件的所有者,文件的所有权是可以转让的
Group,在工作中,一般是以团队进行的,文件的所有者是属于某一个团队的,这个团队的人有时就需要访问这个文件,文件所有者可以创建一个Group,指定在Group里的所有人对于这个文件的访问权限。文件所有者本人本身就是一个团队,他可以往团队里加人。
Others就是不属于前两者的人。
文件类型和访问权限(文件属性):
在使用ll命令的时候会展示出文件的详细信息
Linux文件默认是按照名称排序的
文件属性包括文件类型和文件权限,文件类型就是文件的种类,包括普通文件、目录文件等,详细在一开始有讲过在这里可以查看一下
文件权限就是,文件访问者对于文件的访问权限是如何的
读®:Read 对文件而言,具有读取文件内容的权限;对目录来说,具有ls浏览该目录信息的权限
写(w):Write 对文件而言,具有修改文件内容的权限;对目录来说具有创建删除移动目录内文件的权限
执行(x):execute 对文件而言,具有执行文件的权限;对目录来说,具有cd进入目录的权限
"-"表示不具有该项权限
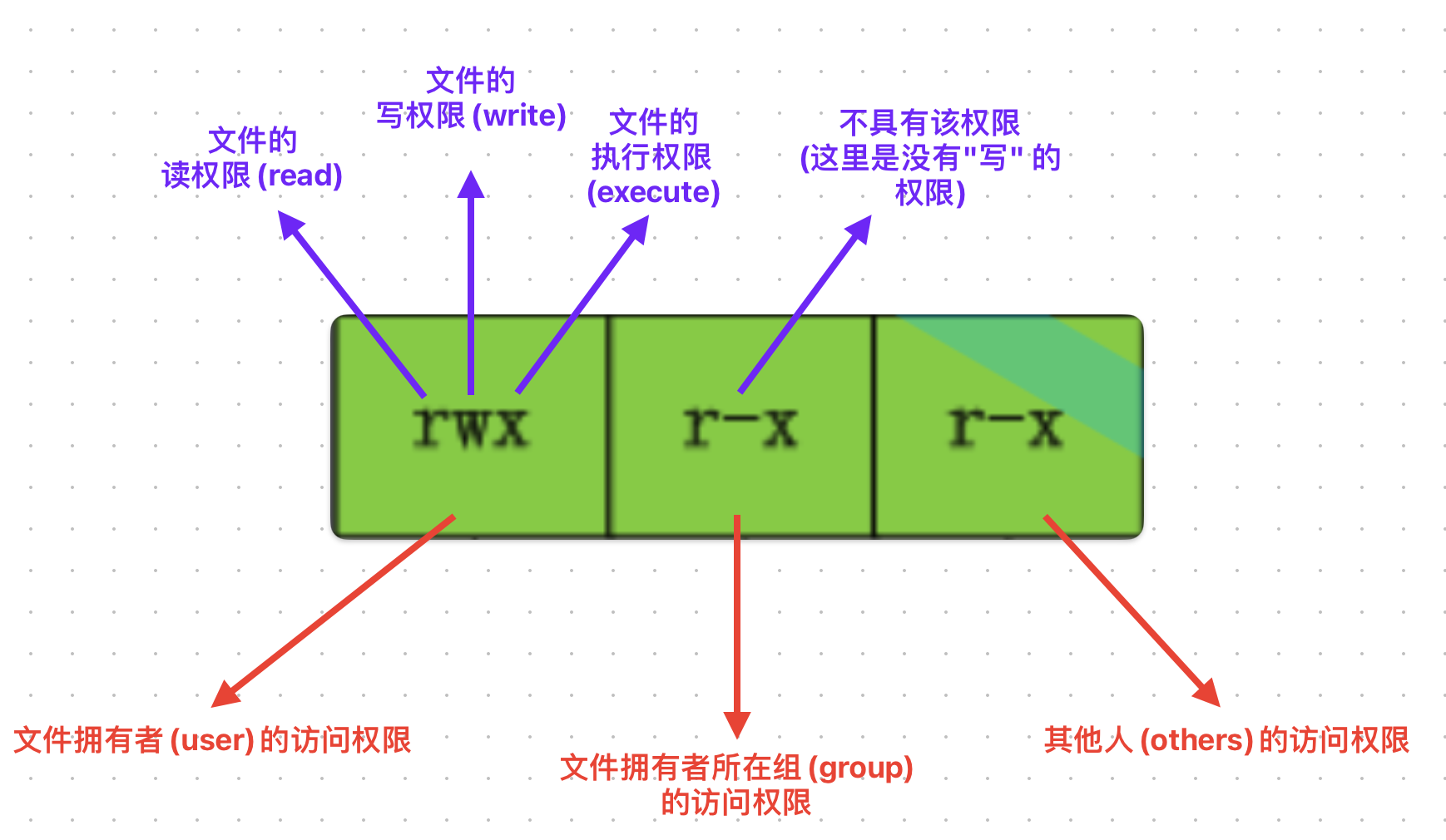
文件权限的表示方法:
-
字符表示方法
Linux字符表示 权限说明 Linux字符表示 权限说明 r– 只读 -w- 仅可写 –x 仅可执行 rw- 可读可写 -wx 可写可执行 r-x 可读可执行 rwx 全部权限 — 无任何权限 -
8进制数值表示方法
对于权限的顺序,可以排列为r、w、x
对于权限的有无,可以用二进制表示,0表示没有这个权限,1表示有这个权限
故r、w、x这三个权限可以用三个二进制数表示,而三个二进制数又能被一个八进制数表示
权限符号 二进制 八进制 — 000 0 r– 100 4 -w- 010 2 –r 001 1 rw- 110 6 r-x 101 5 -wx 011 3 rwx 111 7
文件访问权限的设置方法:
chmod
功能:
设置文件的访问权限
语法:
chmod [option] 权限 文件
说明:
只有文件所有者和root用户才能修改文件访问权限的权限
常用选项:
R # 递归修改目录文件的权限
- 1
权限格式一:
用户表示符 +或-或= 文件权限字符
用户表示符:
- u拥有者
- g同组者
- o其他用户
- a所有用户
+:向用户增加(追加)权限
-:向用户取消(减少)权限
=:向用户赋予权限,也就是用户只有被赋予的权限
向hello.txt的拥有者追加执行权限

向hello.txt的同组者减少可写权限

向hello.txt的其他人只赋予可写权限

可以看到others原来是有rw权限,但是被赋予w权限之后,就只有w权限了
权限格式二:
三个8进制数表示权限 (方便常用)
第一个八进制数表示user的权限
第二个表示group的权限
第三个表示other的权限
跟文件的权限对应
将hello.txt的文件权限设置为rwx rwx rwx

rwx对应的二进制就是111,对应的八进制数就是7
将hello.txt的文件权限设置为555

5对应的权限就是101即r-x
将hello.txt的文件权限设置为754

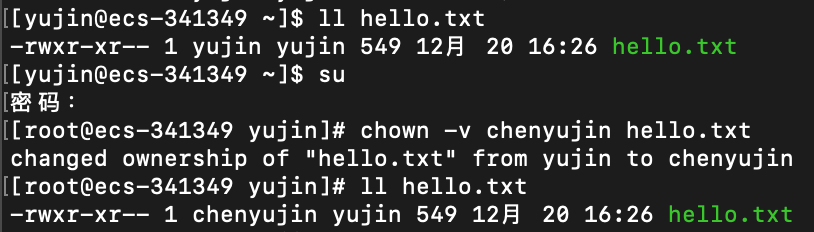
chown
功能:
修改文件的拥有者
语法:
chown [option] 用户名 文件名
注意事项:
只有root用户才有权限使用这个命令
常用选项:
-v # 显示详细过程信息
-R # 递归更改目录的拥有者
-help # 查看用法帮助
-f # 忽略错误信息
- 1
- 2
- 3
- 4
实例:
把hello.txt的所属权从yujin转给chenyujin
chgrp
功能:
修改文件所属组
语法:
chgrp [option] 用户组名 文件名
注意事项:
与chown不同,只要是文件原组里的用户,就可以修改文件的所属组
常用选项:
-v # 显示详细过程信息
-c # 效果类似"-v"参数,但仅显示更改的部分。
-R # 递归更改目录的拥有者
- 1
- 2
- 3
umask
功能:
查看或修改文件权限掩码
语法:
umask 权限掩码值
说明:
将现有的默认权限减去权限掩码,即可产生创建文件时的预设权限
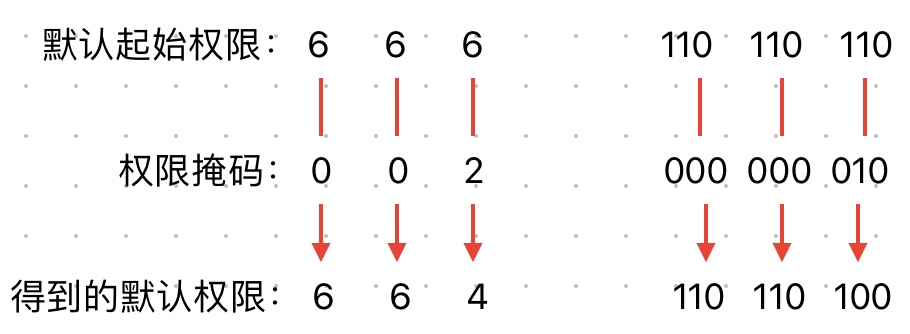
权限掩码(简介)
在创建目录文件的时候,默认权限是775
在创建普通文件的时候,默认权限是664
(不同系统上可能有差别,此处以centOS7为例
但是实际上:
- 普通目录的默认起始预设权限是777,普通文件的默认起始预设权限是666
- 权限掩码umask会在用户创建目录或者文件时拿掉一些默认起始权限,得到的才是创建之后的默认权限
umask # 查看权限掩码
- 1

当前系统下的权限掩码是0002(第一位不用看,代表特殊权限,此处暂不讨论。当然,在写权限的时候是可以带上的,比如0777
系统会拿掉权限掩码对应的权限,002则对应着owner: 0, grouper: 0, other: 2
意味着other会被拿掉2权限(2是八进制数,对应的二进制数是010,也就是w权限)
对于目录,ohter的默认起始权限是7(也就是111,rwx),被拿掉2(也就是010,w)之后就变成了5(也就是101,rx),所以创建出的目录的默认权限就变成了775
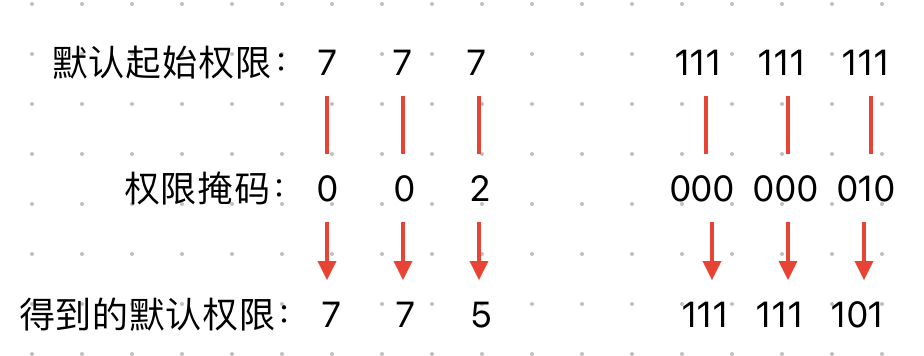
对于文件,other的默认起始权限是6(110,rw),被拿掉2(010,w)之后就变成了4(100,r),所以创建出的文件默认权限就是664
file
功能:
查看文件类型
语法:
file [option] 文件
常用选项:
-c # 显示详细执行过程,便于排错或分析程序执行的情形
-z # 尝试去解读压缩文件的内容
- 1
- 2

粘滞位
让我们回顾一下目录的权限:
读®:Read 对目录来说,具有ls浏览该目录信息的权限
写(w):Write 对目录来说具有创建删除移动目录内文件的权限
执行(x):execute 对目录来说,具有cd进入目录的权限
那这样的话,只要用户具有目录的w权限,就能删除目录中的文件。
那么问题来了,当张三和李四对于一个目录都有w的权限的时候,张三创建了一个文件,结果被李四删除了!我张三创建的文件你李四凭什么给我删除了!?这不科学呀
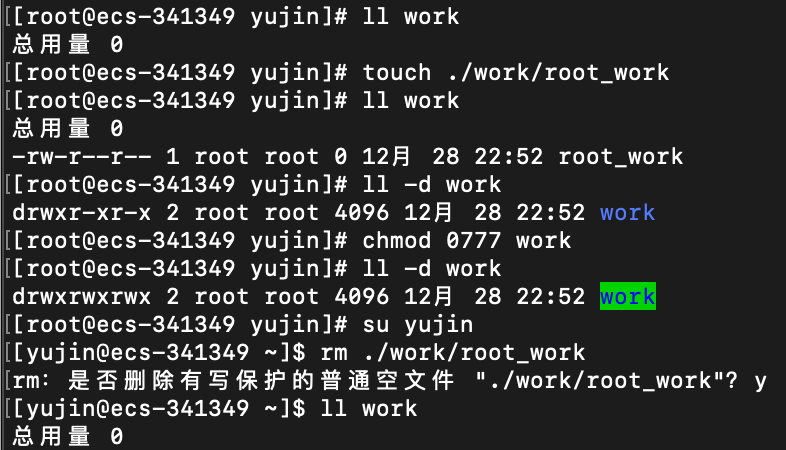
这里yujin具有work目录的w权限(属于others),他将work里root创建的root_work删除了
为了解决这个不科学的问题,就出现了粘滞位
说明&功能&用法:
目录的所有者可以对目录添加粘滞位,加上了粘滞位的目录,具有w权限的用户不能删除目录下别人的文件了,只能删除自己的文件
chmod +t 目录
只有 root 和 目录所有者 才能给目录加上粘滞位
将work目录加上粘滞位之后,yujin就没办法删除root创建的文件root_work2了
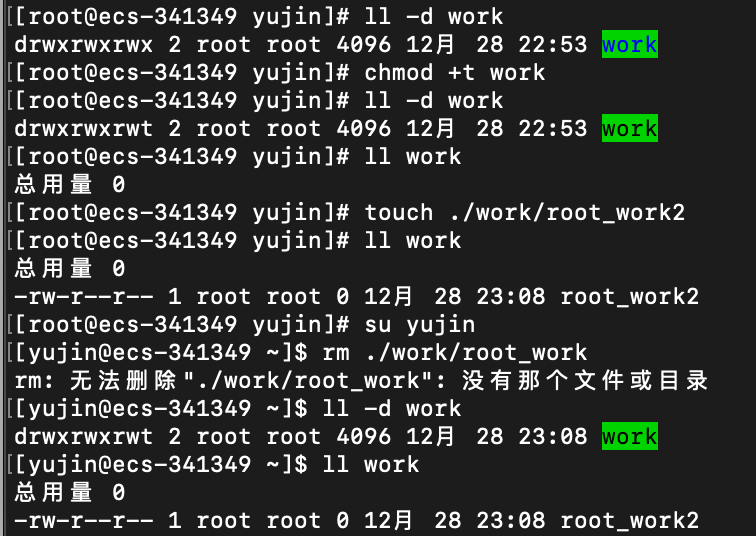
当一个目录被加上粘滞位的时候,该目录下的文件只能由
- root删除
- 该目录的所有者删除
- 该文件的所有者删除
关于权限的总结
- 目录的可执行权限是表示你可否在目录下执行命令
- 如果目录没有-x权限,则无法对目录执行任何命令,甚至无法cd 进入目, 即使目录仍然有-r 读权限(这 个地方很容易犯错,认为有读权限就可以进入目录读取目录下的文件)
- 而如果目录具有-x权限,但没有-r权限,则用户可以执行命令,可以cd进入目录。但由于没有目录的读 权限,所以在目录下,即使可以执行ls命令,但仍然没有权限读出目录下的文档。

