
- 1postgresql如何查询物化视图脚本内容_pgsql 查看物化视图语句
- 2语义分析基础知识_语义规则
- 3史上最强Excel模板 (680个文档)_680个excel模板
- 4计算机专业春招笔试+面试题(个人总结)_计算机专业应届生招聘技术面试题
- 5大数据技术之Hadoop(HDFS)_大数据hadoop
- 6解决Flask项目无法使用公网IP访问的问题_flask小demo放到阿里云无法访问
- 7VueX_映射的计算属性的名称与 state 的子节点名称相同是怎么样的
- 8Linux(Centos7)下配置Hadoop的环境以及启动其HDFS的详细教程_centos打开hadoop显示什么才是成功
- 9创建Github Pages 仓库
- 10git pull指令报错 error: You have not concluded your merge (MERGE_HEAD exists)._> git pull --tags origin master error: you have no
掌握模型性能:使用 GridSearchCV 调整超参数
赞
踩
使用 GridSearchCV 进行超参数优化的综合指南
超参数调优概述
Hyper参数是在学习机的学习过程之前设置的参数,在模型训练的学习过程中不会直接从数据中学习。与模型参数不同,这些参数不是从数据中学习的,超参数是由数据科学家或机器学习专家根据他们的知识和直觉确定的。
超参数调优对模型性能的意义: 正确选择超参数可以提高机器学习模型的性能。通过调整超参数,您可以确定可提高准确性、精度或其他性能度量的区域,从而提高速度和建模精度。调优良好的模型更加健壮和稳定,因为它们对输入的微小变化和训练集的微小变化不太敏感。
网格搜索简历简介
GridSearchCV(交叉验证)是一种超参数优化技术,用于搜索机器学习模型的超参数值的最佳组合。它是 Python 中 sci-kit-learn 库的一部分,广泛用于超参数优化。
在决策树上使用 GridsearchCV 的示例:
不使用 GridsearchCV:
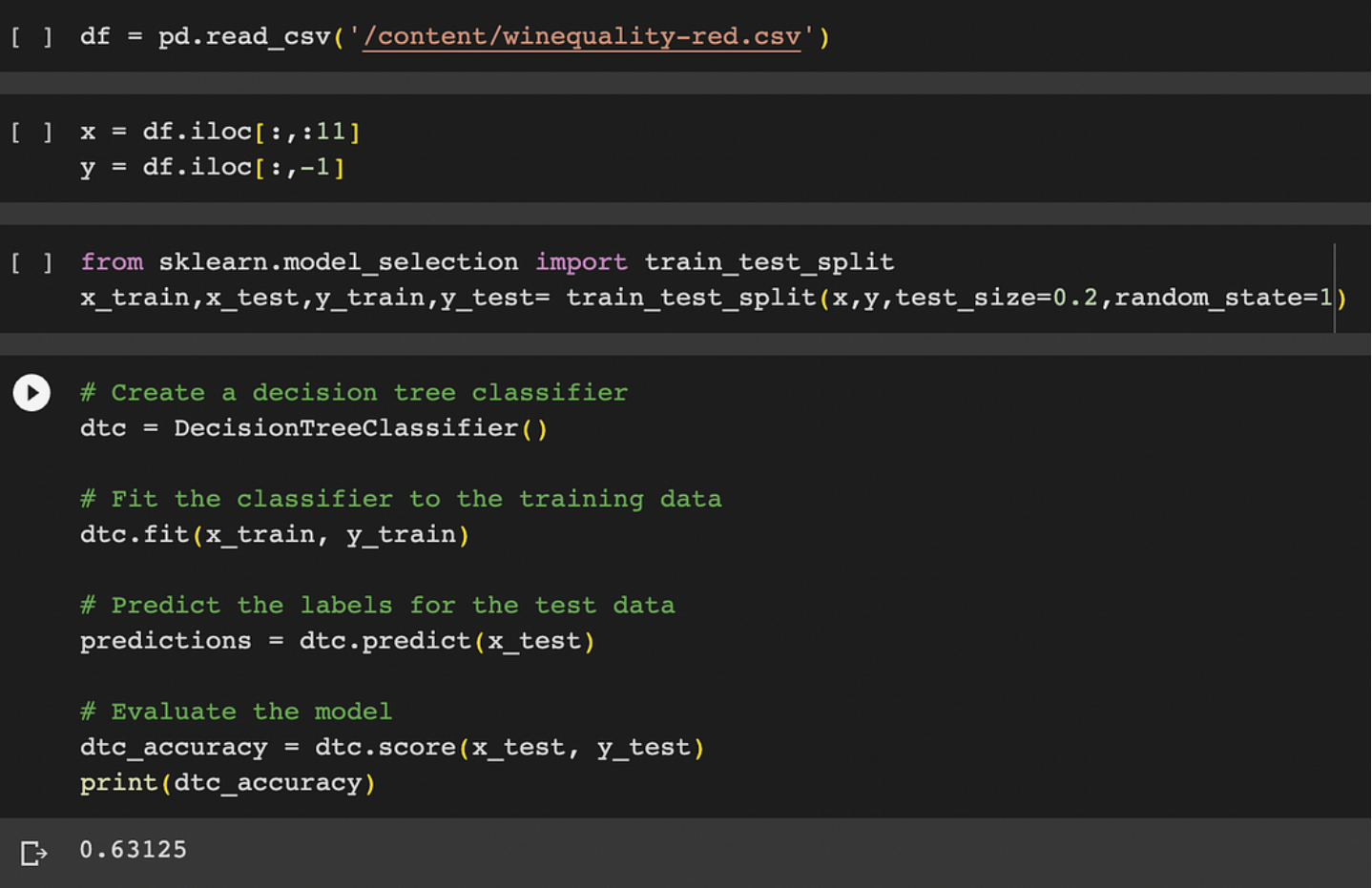
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test= train_test_split(x,y,test_size=0.2,random_state=1)
#decision tree classifier
dtc = DecisionTreeClassifier()
# Fit the classifier to the training data
dtc.fit(x_train, y_train)
# Predict the labels for the test data
predictions = dtc.predict(x_test)
# Evaluate the model
dtc_accuracy = dtc.score(x_test, y_test)
print(dtc_accuracy)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
使用 GridSearchCV 后:
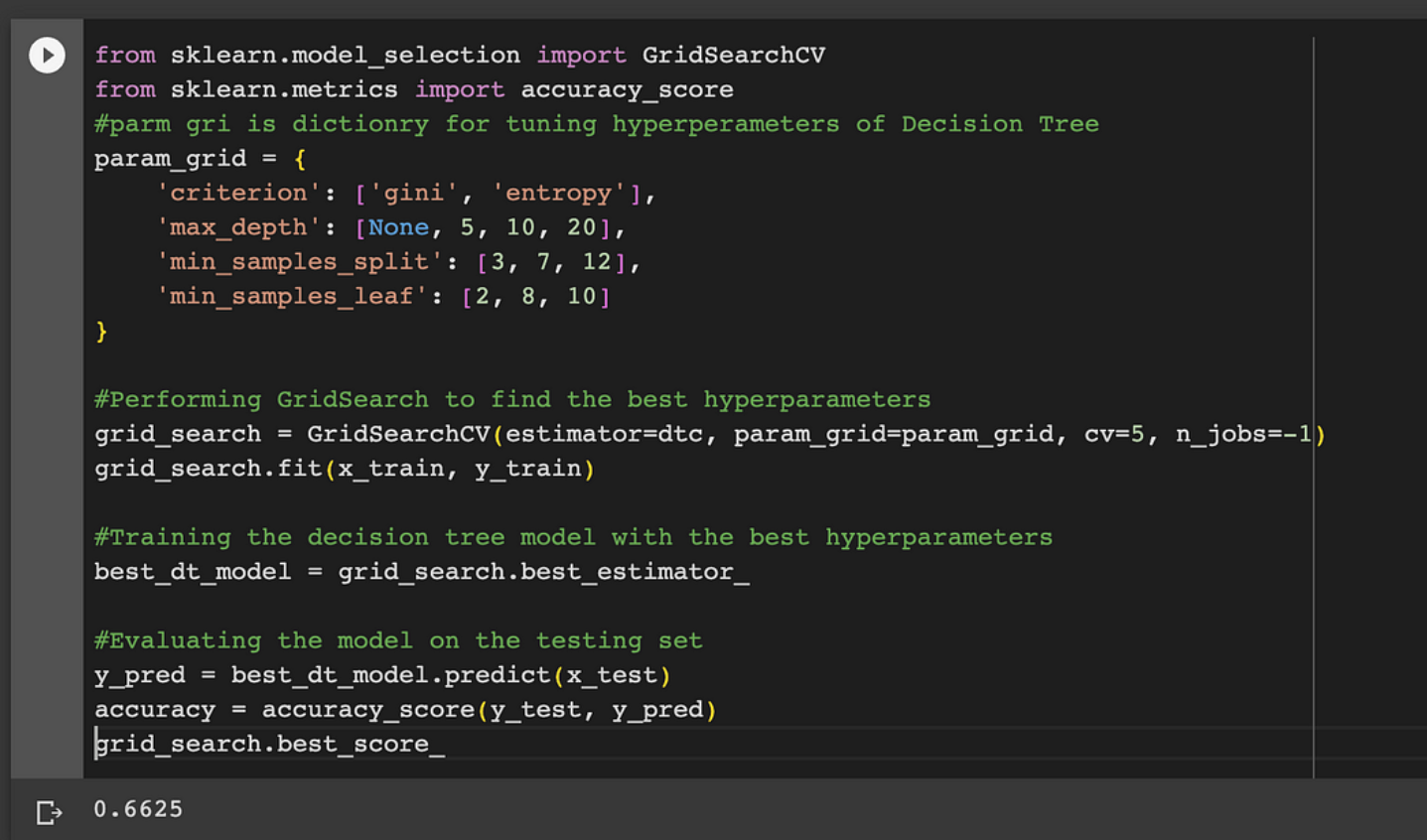
from sklearn.model_selection import GridSearchCV from sklearn.metrics import accuracy_score #parm grid is dictionry for tuning hyperperameters of Decision Tree param_grid = { 'criterion': ['gini', 'entropy'], 'max_depth': [None, 5, 10, 20], 'min_samples_split': [3, 7, 12], 'min_samples_leaf': [2, 8, 10] } #Performing GridSearch to find the best hyperparameters grid_search = GridSearchCV(estimator=dtc, param_grid=param_grid, cv=5, n_jobs=-1) grid_search.fit(x_train, y_train) #Training the decision tree model with the best hyperparameters best_dt_model = grid_search.best_estimator_ #Evaluating the model on the testing set y_pred = best_dt_model.predict(x_test) accuracy = accuracy_score(y_test, y_pred) grid_search.best_score_

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
随机搜索CV:在某些特殊情况下,不适合使用网格searcCV或RandomgridSearcgCV,这些情况是:
当数据被限制为以有效的方式使用网格搜索时,应该有适当数量的数据,因为gridsearchCV使用K折叠交叉验证。在这种情况下,可以使用更高级的技术(如贝叶斯优化)作为有效搜索超参数空间的替代方法。这种情况是: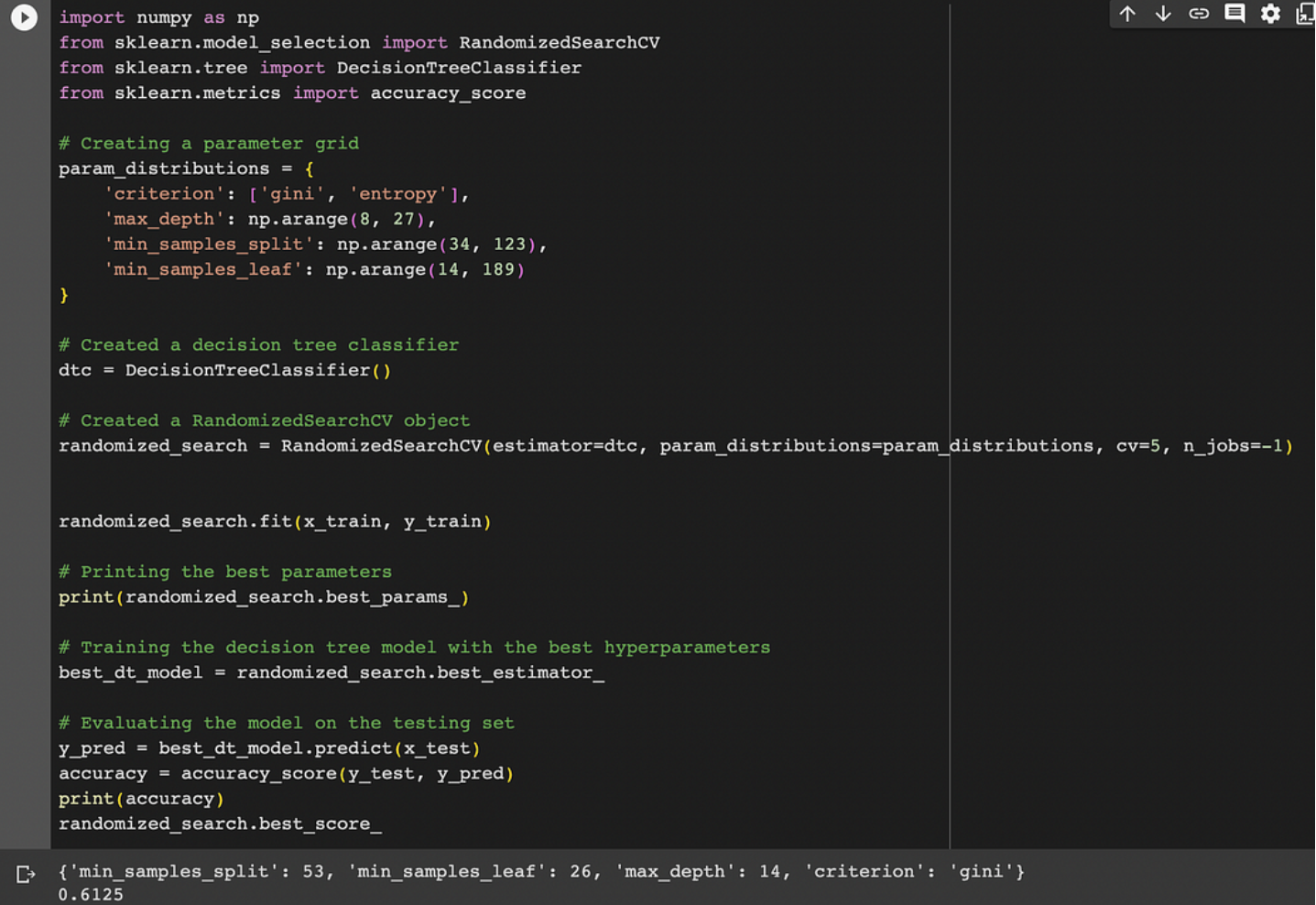
import numpy as np from sklearn.model_selection import RandomizedSearchCV from sklearn.tree import DecisionTreeClassifier from sklearn.metrics import accuracy_score # Creating a parameter grid param_distributions = { 'criterion': ['gini', 'entropy'], 'max_depth': np.arange(8, 27), 'min_samples_split': np.arange(34, 123), 'min_samples_leaf': np.arange(14, 189) } # Created a decision tree classifier dtc = DecisionTreeClassifier() # Created a RandomizedSearchCV object randomized_search = RandomizedSearchCV(estimator=dtc, param_distributions=param_distributions, cv=5, n_jobs=-1) randomized_search.fit(x_train, y_train) # Printing the best parameters print(randomized_search.best_params_) # Training the decision tree model with the best hyperparameters best_dt_model = randomized_search.best_estimator_ # Evaluating the model on the testing set y_pred = best_dt_model.predict(x_test) accuracy = accuracy_score(y_test, y_pred) print(accuracy) randomized_search.best_score_
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
了解网格搜索CV:
使用GridSearchCV()方法,该方法在scikit-learn类model_selection中可用。它可以通过创建 GridSearchCV() 的对象来启动它需要 4 个参数估计器、param_grid、cv 和 n-jobs。这些参数的解释如下: 1. 估计器 — 一个 scikit-learn 模型 2. param_grid -:包含参数名称和参数值列表的字典。 3. 评分:绩效衡量标准。例如,“dtc”表示决策树模型,“precision”表示分类模型。 4. cv :它代表了许多 k 折叠交叉验证。
网格搜索CV的工作:
它通过搜索可能的超参数值网络并评估每个超参数组合的模型函数来有效工作。然后使用超参数训练最终模型,使模型表现良好。
在测试所有可能的超参数对并评估其性能后,GridSearchCV 根据评估标准选择提供最佳性能的超参数组合。
确定最佳超参数,GridSearchCV 将使用整个训练数据集重新训练模型,这次使用最佳超参数。
最后,在看不见的测试数据上测试具有最佳超参数的模型,以预测其在新的、看不见的数据上的性能。
结论:
使用 GridSearchCV 的主要优点是它可以自动执行超参数优化过程,并使您免于手动尝试许多连接。它通过探索超参数空间来提高新数据的性能,从而增加了为模型找到最佳或接近最优超参数的风险。
GridSearchCV 的计算成本可能很高,尤其是在您拥有大型数据集或复杂的多变量模型时。在这种情况下,最好考虑使用 RandomizedSearchCV,它探索不同的超参数域,并在性能和预算之间提供良好的权衡。
然而,在某些情况下,其他超渗透率技术更有用,例如当数据有限时,贝叶斯优化可以用作有效搜索超参数空间的替代方法。

