
- 1Android_8.1 Log 系统源码分析_liblog.so 源码包
- 2解决办法汇总:You have an error in your SQL syntax; check the manual that corresponds to your MySQL_you have an error in your sql syntax; check the ma
- 3虚拟机安装(VM17pro+linux最小安装版)
- 4Ultrascale selectio 仿真之 IDELAYE3和IDELAYCTRL
- 5【SPIE独立出版,往届均已见刊并完成EI、SCOPUS检索 | 四川省人工智能学会主办】第四届大数据、人工智能与风险管理国际学术会议 (ICBAR 2024)
- 6使用CSDN开发助手_csdn助手
- 7RT-DETR论文解读与代码_rt-detr代码
- 8原生html table固定表头,后台返回一个数组对象有多个值,根据表头需要的字段显
- 9基于微信小程序的餐厅点餐系统(附开题报告)_基于微信小程序的点餐系统
- 10西门子c#(开发实习一面)_c#软件工程师西门子面试
【MySQL复合查询】
赞
踩
一、基本的使用案例
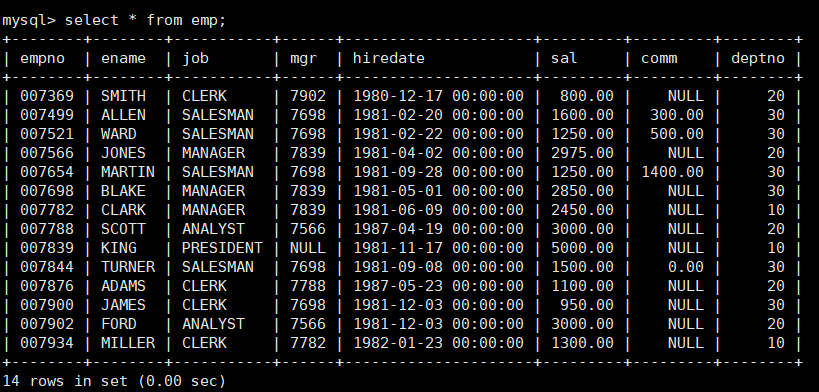
注明:以下案例使用的均为一个scott.sql的资源文件。
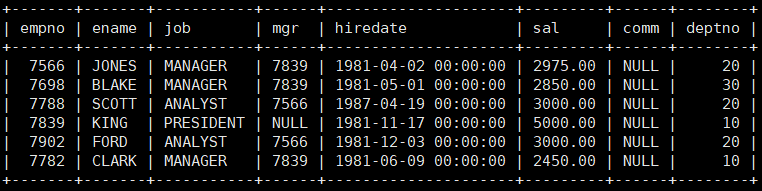
其中一个表的内容如下:
查询工资高于500或岗位为MANAGER的雇员,同时还要满足他们的姓名首字母为大写的J
mysql> select * from emp where (sal>500 or job=‘MANAGER’) and ename like ‘J%’ ;

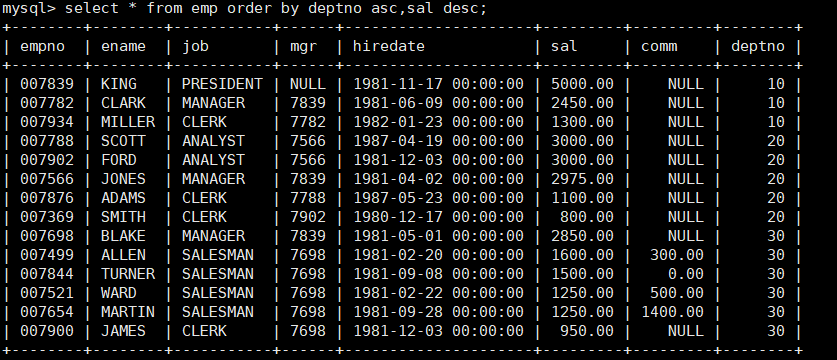
按照部门号升序而雇员的工资降序排序
mysql> select * from emp order by deptno asc,sal desc;
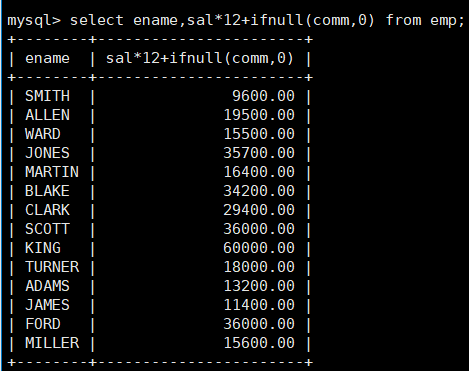
计算每一个人的年薪(年薪 = 月薪*12 + 奖金);
mysql> select ename,sal*12+ifnull(comm,0) from emp;
这里使用了ifnull函数,来判断如果comm为NULL,那就是0,如果不为NULL,那奖金就是comm。(因为在表创建奖金时,comm设置允许为NULL)
而前面讲过,NULL跟谁运算,结果都是NULL。
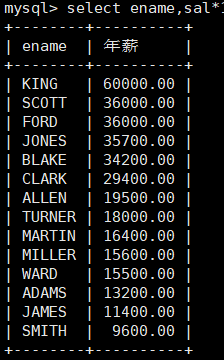
然后按照年薪,进行降序排序。
mysql> select ename,sal*12+ifnull(comm,0) as 年薪 from emp order by 年薪
desc;
子查询的两个经典案例:
显示工资最高的员工的名字和工作岗位
这里分两步走:
1.先查出整个表中最高的薪资是多少。
2.遍历表,将每个员工工资与最高工资比较。
一般情况下就会分两步SQL代码来执行。
mysql> select max(sal) from emp ;
mysql> select ename,job from emp where sal=5000;
但是,这样执行太挫了。
不如这样:
mysql> select ename,job from emp where sal=(select max(sal) from emp);
这样执行的顺序是:先从括号内开始进行查询,最后再向外执行聚合。
显示工资高于平均工资的员工信息
mysql> select * from emp where sal > (select avg(sal) from emp);
计算平均工资的过程,就是把emp表分成一个小的表。
先从括号内进行分组选择,再进行聚合。
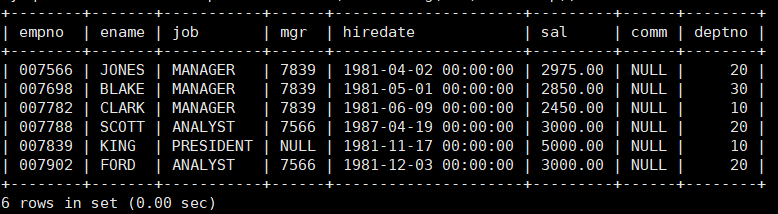
显示每个部门的平均工资和最高工资
分析:这里存在分组。
第一:每个部门,第二:平均工资,第三:最高工资。
其实就是把一个表分成三个表。
先获取部门这一个表,这是分组过程。
再在部门表中,获取平均工资和最高工资,这是聚合过程。
分组聚合是相辅相成的。
mysql> select deptno,format(max(sal),2) 最高工资,format(avg(sal),2) 平均工资
from emp group by deptno;
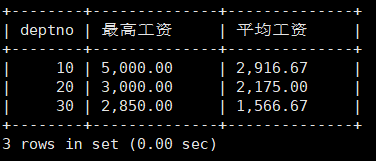
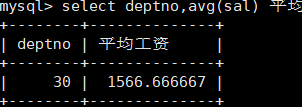
显示平均工资低于2000的部门号和它的平均工资
mysql> select deptno,avg(sal) 平均工资 from emp group by deptno having 平均工资 < 2000;
这里也考察了where和having的用法。
上篇文章说过,where和having区别就是使用时机不同。
where是分组聚合前使用,having是分组聚合后使用。
如果把上面的话变成这样:
显示部门和它的平均工资。
这样的含义就是:先分组,一个部门就是一个组,再在组内聚合计算平均工资。
现在增加了几个字:
显示平均工资低于2000的部门和它的平均工资。
显然,是先在组内聚合计算完平均工资后,再将最终结果与2000比较。
所以就是分组聚合后使用having。
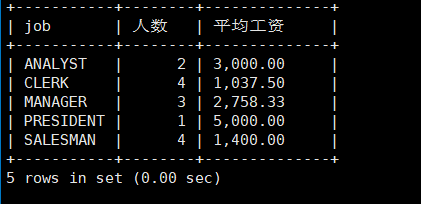
显示每种岗位的雇员总数,平均工资
mysql> select job,count(*) 人数,format(avg(sal),2) 平均工资 from emp group by job;
第一步:可以先计算一共有多少员工
select count(*) from emp;
第二步:按照岗位进行分组,计算每个岗位有多少员工
select count(*) from emp group by job;
第三步:汇总即可。
二、多表查询
案例:
显示雇员名、雇员工资以及所在部门的名字因为上面的数据来自EMP和DEPT表,因此要联合查询。
上面的案例,需要用到两张表的信息,所以需要查询两张表。
select * from emp,dept;
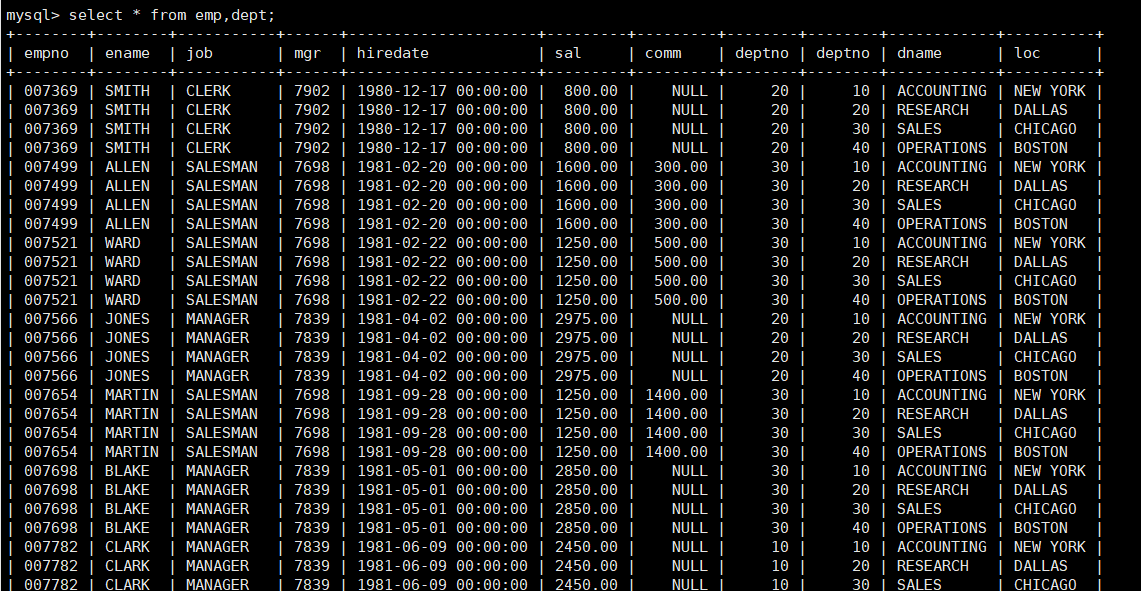
可以看到,查询结果是一张非常大的表格。
联合查询的过程是使用笛卡尔积的方式。
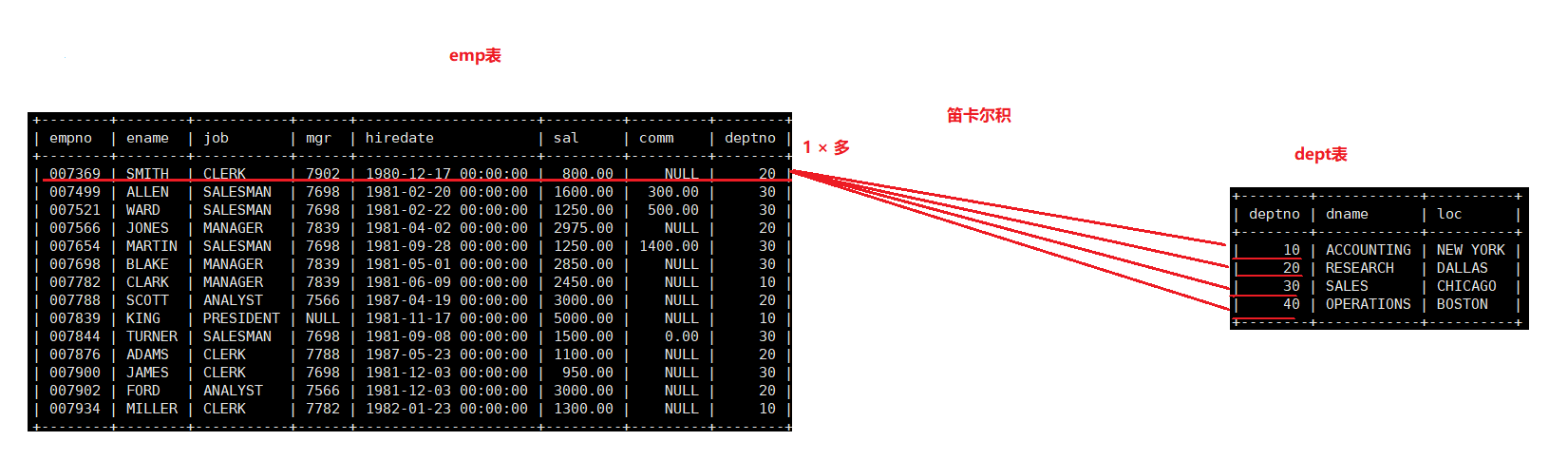
而每条数据都会进行这样的方式。
这就是为什么在联合查询出来的表,会出现多个dpetno,且部门号不同的原因,所以,那些deptno不同的数据是没有意义的。
mysql> select * from emp,dept where emp.deptno = dept.deptno;
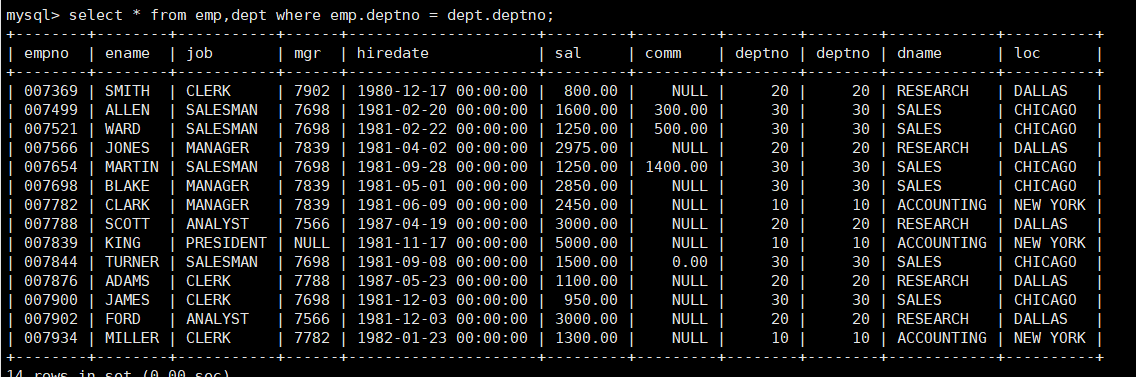
所以才需要进行筛选,过滤掉所有deptno不同的数据。
案例:显示部门号为10的部门名,员工名和工资
显然,这个案例也需要联合查询。
mysql> select dname,ename,job from emp,dept where emp.deptno = dept.deptno and dept.deptno = 10;
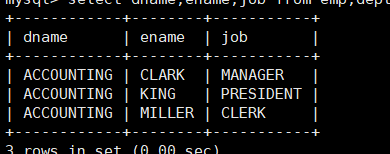
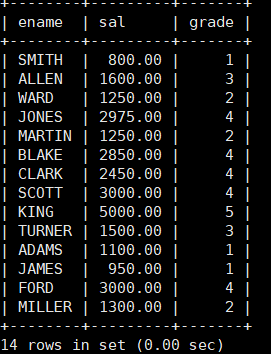
案例:显示各个员工的姓名,工资,及工资级别
mysql> select ename,sal,grade from emp,salgrade where sal between losal and hisal;
三、自连接
自连接是指在同一张表连接查询。
案例:
显示员工FORD的上级领导的编号和姓名(mgr是员工领导的编号–empno)
- 1.先根据员工信息找到领导编号。
- 2.根据领导编号,找到领导的信息。
方法1:
- 使用子查询
mysql> select ename,empno from emp where empno=(select mgr from emp where ename=‘FORD’);

方法2:
- 使用自查询
mysql> select e2.ename, e2.empno from emp e1,emp e2 where e1.ename = ‘FORD’ and e1.mgr = e2.empno;
from是最先被执行的,因为只有先找到表,才能执行接下来的其他所有操作!!!
所以,在select阶段,也可以使用重命名后的表。
注意:e1和e2虽然都是emp表的别名,但是经过笛卡尔积后,两个表不再是同一张表了!!
四、子查询
4.1单行子查询
返回一行记录的子查询。
单行子查询最显著的特征是:查询出来的结果只有一行一列。
案例:显示SMITH同一部门的员工
- 1.先找到SMITH的所在部门号。
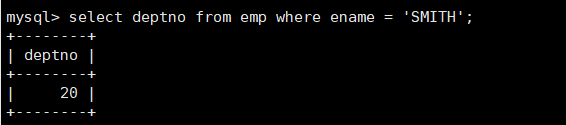
- 2.根据部门号,找到所有在该部门的员工。
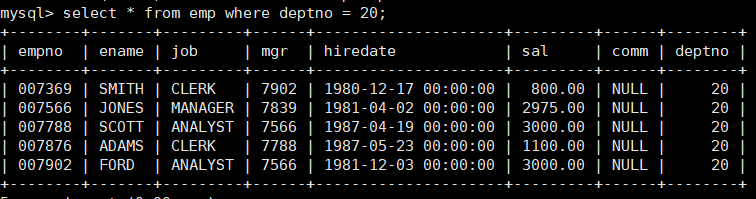
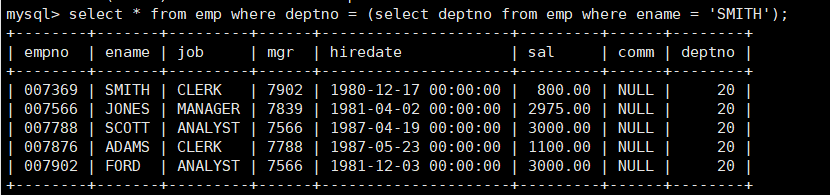
合并的结果就是:
mysql> select * from emp where deptno = (select deptno from emp where ename = ‘SMITH’);
4.2多行子查询
in关键字
案例:查询和10号部门的工作岗位相同的雇员的名字,岗位,工资,部门号,但是不包含10自己的。
mysql> select ename,job,sal,deptno from emp where job in (select job from emp where deptno = 10) and deptno <> 10;


all关键字
all关键字的含义就是比所有值都要怎么怎么样。
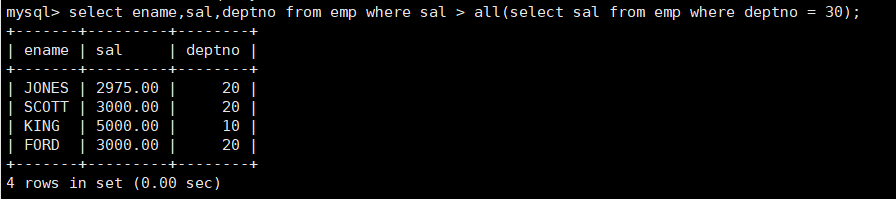
案例:显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号
mysql> select ename,sal,deptno from emp where sal > all(select sal from emp where deptno = 30);
any关键字
any关键字就是比一批人员中的任意一个高就行。
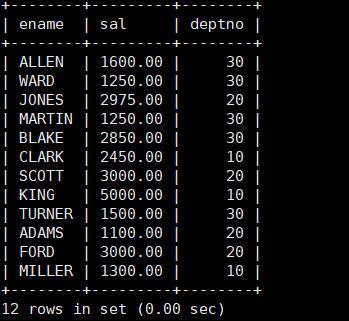
案例:显示工资比部门30的任意员工的工资高的员工的姓名、工资和部门号(包含自己部门的员工)
mysql> select ename,sal,deptno from emp where sal > any (select sal from emp where deptno = 30);
也可以加上一个distinct进行去重。
4.3多列子查询
单行子查询是指子查询只返回单列,单行数据;多行子查询是指返回单列多行数据,都是针对单列而言的,而多列子查询则是指查询返回多个列数据的子查询语句。
案例:查询和SMITH的部门和岗位完全相同的所有雇员,不含SMITH本人
mysql> select * from emp where (job,deptno) = (select job ,deptno from emp where ename = ‘SMITH’);

4.4 在from子句中使用子查询
子查询语句出现在from子句中。这里要用到数据查询的技巧,把一个子查询当做一个临时表使用。
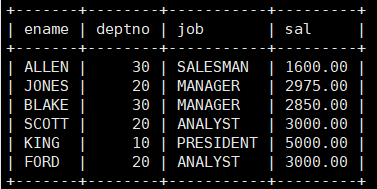
案例:显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资
mysql> select ename,deptno,job,sal from emp , (select deptno dt, avg(sal) avsal from emp group by deptno) tmp where emp.sal > tmp.avsal and emp.deptno = tmp.dt;
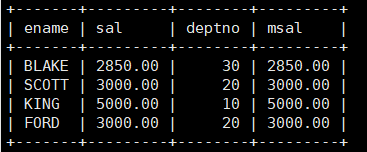
案例:查找每个部门工资最高的人的姓名、工资、部门、最高工资。
mysql> select ename,sal,deptno,msal from emp,(select deptno dt ,max(sal) msal from emp group by deptno) tmp where emp.sal = tmp.msal and emp.deptno = tmp.dt;
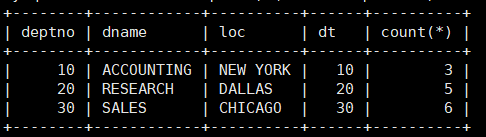
案例:显示每个部门的信息(部门名,编号,地址)和人员数量。
mysql> select * from dept t1, (select deptno dt, count(*) from emp
group by deptno) t2 where t1.deptno = t2.dt;
解决多表问题的本质
解决多表问题的本质:将多表转化成单表,所以MySLQ中,所有的select问题,都可以转化成单表问题。
五、合并查询
1.union
该操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。
案例:将工资大于2500或职位是MANAGER的人找出来
mysql> select * from emp where sal > 2500 union select * from emp where job = ‘MANAGER’;
2.union all
与union的区别就是不去重。

