
- 1我的书签菜单_聚bt网址
- 2SLA(服务等级协议)_服务可用性sla
- 3Baidu Comate——基于AI的智能代码生成让你的编码更快、更好、更简单!_指新用户在ide中安装comate插件,并在问答区有技术类的提问,或者在编码区有采纳行
- 4Java|IDEA 运行和打包报错解决_java: java.lang.nosuchfielderror: class com.sun.to
- 5Github 2024-05-21 开源项目日报 Top10
- 6Android Studio Gradle
- 7Openlayers的交互功能(六)——编辑图斑_openlayer modify
- 8CSDN上传付费资源需要创作者等级Lv3,我的升级之路_csdn 的 综合贡献分
- 9Endnote 保姆级攻略:参考文献插入与删除、Style修改、文档格式转化(转载)_endnote插入引文 参考文献格式
- 10人工智能 ai java_人工智能需要java吗
Kafka Producer 内存池设计源码赏析_new kfkoneproducer[poolsize];
赞
踩
一、开篇引出一个 Full Gc 的问题
在上一篇文章中,我们讲到了 Kafka 发送消息的八个流程,并且着重讲了 Kafka 封装了一个内存结构,把每个分区的消息封装成批次,缓存到内存里。
如下图所示:
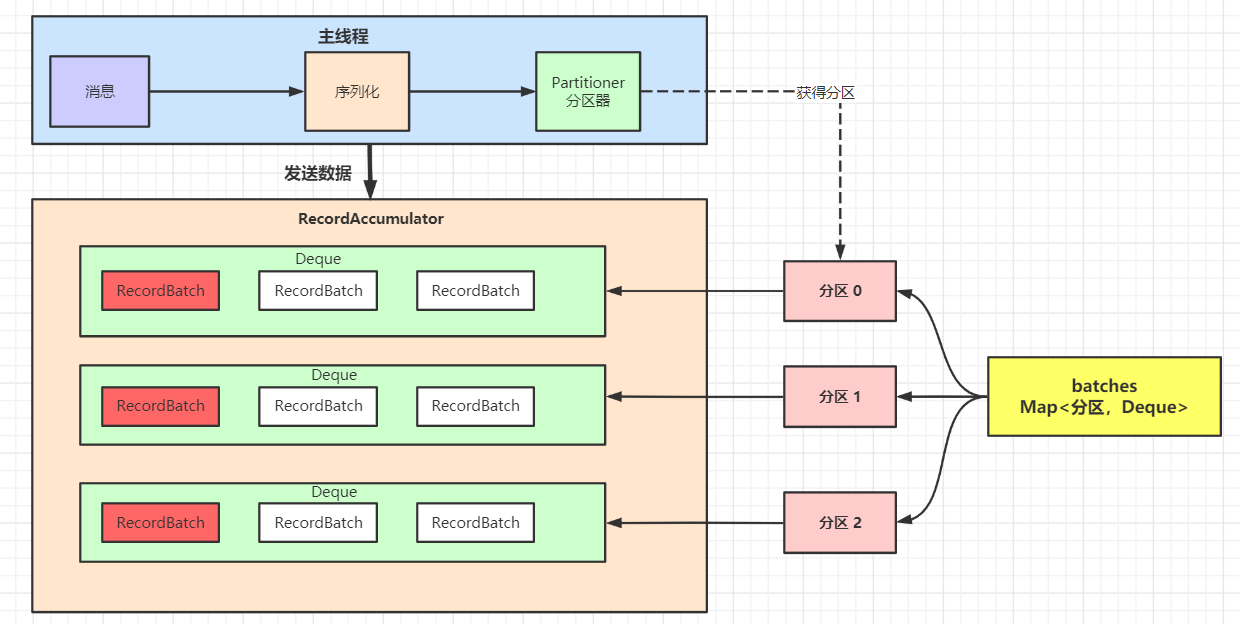
上图中,整体是一个 Map 结构,Map 的 key 是分区,Map 的值是一个队列;队列里有一个个的小批次,里面是很多消息。
这样好处就是可以一次性的把消息发送出去,不至于来一条发送一条,浪费网络资源。
但由此也带来了问题,生产者端消息这么多,一个批次发送完了就不管了去等待 JVM 的垃圾回收的时候,很有可能会触发 full gc。
一次 full gc,整个 Producer 端的所有线程就都停了,所有消息都无法发送了,由此带来的损耗也是不可小觑。
这个严重的问题,当然 Kafka 的开发者也考虑到了这一点,所以作者设计了一个内存池,用来反复利用被发送出去 RecordBatch,以减少 full gc。
二、什么是内存池
可以类比连接池,连接池缓存了很多 jdbc 连接,避免不必要的创建连接的开销;内存池也一样,可以对 RecordBatch 做到反复利用。
那我们看看 Kafka 内存池是怎么设计的:
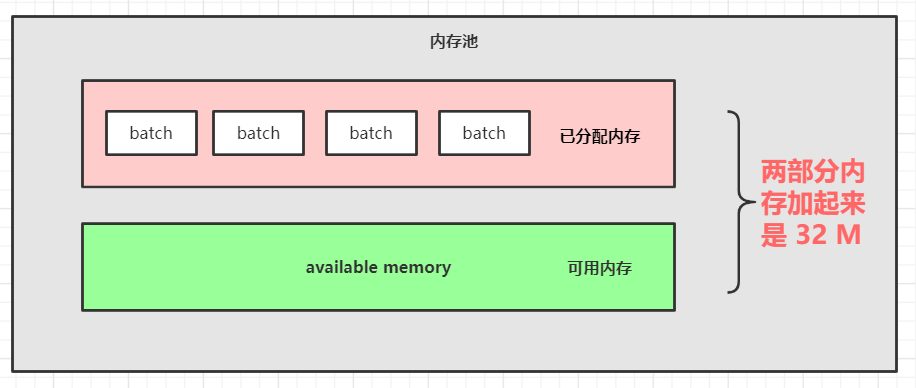
Kafka 内存设计有两部分,下面的绿色的是可用的内存(未分配的内存,初始的时候是 32M),上面红色的是已经被分配了的内存,每个小 batch 是 16K,然后这一个个的 batch 就可以被反复利用,不需要每次都申请内存。
两部分加起来是 32M。
这个 32M 的配置在 ProducerConfig 这个类里面:

三、申请内存的过程
(发送消息的流程在上一篇文章讲过了,可以回去复习下)
我们从发送消息的大流程的第七步开始看(当前位置:KafkaProducer):

进入到 RecordAccumulator 类里,当发现还没有队列的时候,创建了一个队列,然后去申请内存(当前类位置:RecordAccumulator):

本次我们主要看的就是这个 allocate 方法。点到 allocate 里面,到了 BufferPool 类,BufferPool 是对内存池的封装。然后来一行行看这个申请内存的方法。
(1)如果申请的内存大小超过了整个缓存池的大小,则抛错出来

(2)对整个方法加锁:
this.lock.lock();
- 1
(3)如果申请的大小是每个 recordBatch 的大小(16K),并且已分配内存不为空,则直接取出来一个返回。
if (size == poolableSize && !this.free.isEmpty())
return this.free.pollFirst();
- 1
- 2
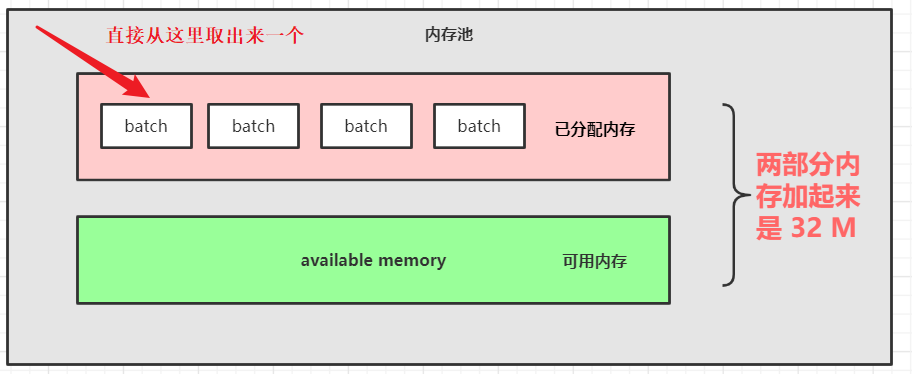
(4)如果要申请的内存大小不是 16K 或者已分配内存没有了的情况。
如果整个内存池大小比要申请的内存大小大 (this.availableMemory + freeListSize >= size),则直接从可用内存(即上图绿色的区域)申请一块内存。
并且可用内存要去掉申请的那一块内存。
int freeListSize = this.free.size() * this.poolableSize;
if (this.availableMemory + freeListSize >= size) {
// we have enough unallocated or pooled memory to immediately
// satisfy the request
freeUp(size);
this.availableMemory -= size;
lock.unlock();
return ByteBuffer.allocate(size);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

(5)下面是 else 分支,表示申请的内存大小不是 16 K,或者已分配内存区域没有,并且所有的内存加起来都不够了。
首先创建一个 Condition。Condition 就是用来替代传统的 Object 的 wait() 和 notify() 方法来实现线程间的协作。Condition 必须在 lock 和 unlock 代码块中间才可使用。
Condition moreMemory = this.lock.newCondition();
- 1
将 Condition 加入到 waiters 里面。为什么会有多个 Condition 呢?因为这里可能很多个线程都在使用生产者发送消息,可能很多个线程都没有足够的内存分配了,都在等待。
this.waiters.addLast(moreMemory);
- 1
然后线程开始睡眠,等待释放资源(唤醒条件有两个,一个是睡眠时间到了,一个是有其他线程释放了内存,被唤醒了):
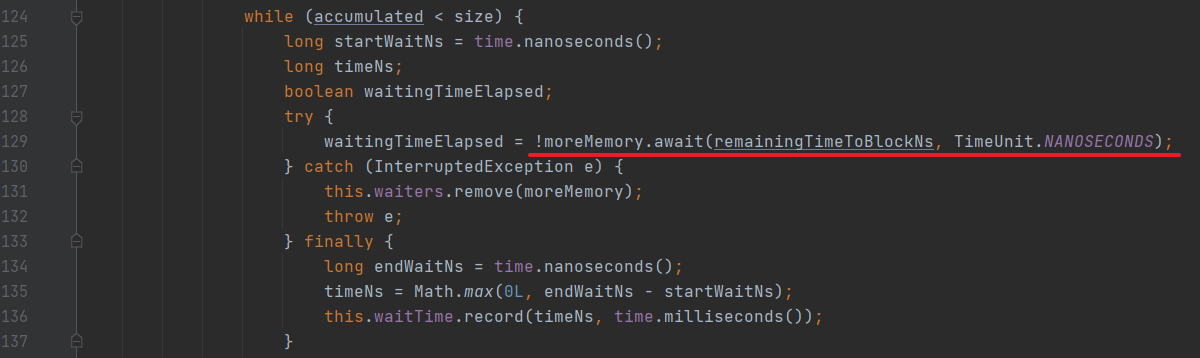
(7)如果等了指定时间(默认配置是 60s - 获取元数据的时间),还没被唤醒,则直接抛一个缓存超时的异常出去
if (waitingTimeElapsed) {
this.waiters.remove(moreMemory);
throw new TimeoutException("Failed to allocate memory within the configured max blocking time " + maxTimeToBlockMs + " ms.");
}
- 1
- 2
- 3
- 4
(8)如果有其他线程释放内存,被唤醒了,从 waiters 列表里面移除自己,然后去看看有没有内存可以用。
这里仍然有两个分支,一个是首先看已分配内存里面有没有内存(16K),如果有的话,直接拿一个 batch 出来
if (accumulated == 0 && size == this.poolableSize && !this.free.isEmpty()) {
// just grab a buffer from the free list
buffer = this.free.pollFirst();
accumulated = size;
}
- 1
- 2
- 3
- 4
- 5
另一个分支是,如果要申请的不是 16K,或者已分配内存空间不是空的
// 从已分配内存取一个出来放到可用内存区域
freeUp(size - accumulated);
// 申请一块,有可能只能申请到2K
int got = (int) Math.min(size - accumulated, this.availableMemory);
// 做扣减
this.availableMemory -= got;
accumulated += got;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
有可能这里只能申请到一部分内存,比如3K,5K,没有达到想申请的那个数量,则会继续走 while 循环。
(9)最后发现内存有富余,则唤醒其他线程
if (this.availableMemory > 0 || !this.free.isEmpty()) {
if (!this.waiters.isEmpty())
this.waiters.peekFirst().signal();
}
- 1
- 2
- 3
- 4
四、释放内存的过程
释放内存的过程很简单了,如果释放的是一个批次的大小(16K),则直接加到已分配内存里面
如果没有,则把内存放到可用内存里面,这部分内存等待虚拟机垃圾回收。
public void deallocate(ByteBuffer buffer, int size) {
lock.lock();
try {
if (size == this.poolableSize && size == buffer.capacity()) {
buffer.clear();
this.free.add(buffer);
} else {
this.availableMemory += size;
}
Condition moreMem = this.waiters.peekFirst();
if (moreMem != null)
moreMem.signal();
} finally {
lock.unlock();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
这里可能会有一个疑问:
为什么释放了一个批次大小(16K)内存的时候,才放到已分配内存里面。我想释放个 1M 的内存,为什么不能往已分配内存里面呢?
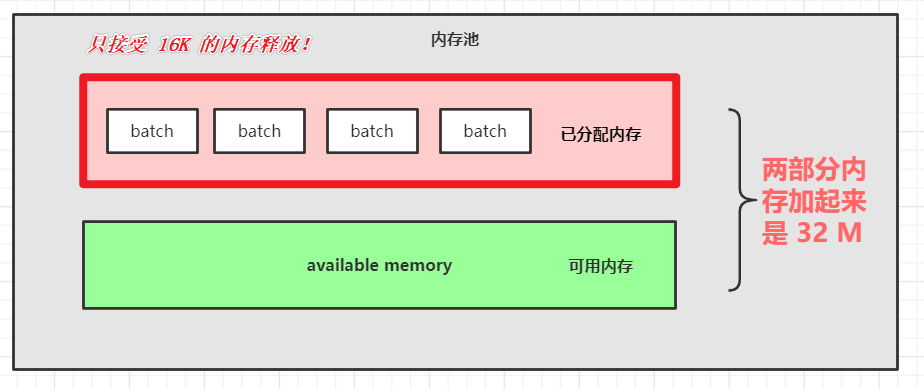
假设我们往已分配内存里释放了个 1M 的批次到内存里。
然后发送消息其实是有条件的,要么是许多消息把批次撑满了发送出去,要么是一个批次累积消息的时间到了,就会立马发出去。
如果是一个 1M 的内存批次,才攒了几条消息,一个批次才用了 几十K,时间到了,就把这个 1M 的内存批次发送出去了。
那么可想而知,内存的使用率是会非常低的。
所以这里控制了,已分配内存必须是 16K 的,每个批次的大小必须一致,这样才能充分利用内存空间。
五、总结
本文我们讨论了 Kafka 生产者端设计了一个内存池的结构,反复利用每一个批次,减少 Java 虚拟机的内存回收。
本文中,还涉及到了一个高并发锁的代码,比如 可重入锁 ReentrantLock,Condition,如果有不明白的地方,可以把这部分复习一下,再看这段代码就很容易明白了。

