
- 1ElasticSearch学习笔记-第四章 ES分片原理以及读写流程详解
- 2【EtherCAT工具】一、ubuntu18.04安装IgH主站_ubuntu igh
- 3[独有源码]java-jsp超市配送系统的设计与实现ee250规划与实现适合自己的毕业设计的策略_java超市配送管理系统
- 4hadoop启动报错: ERROR: Attempting to operate on hdfs namenode as root
- 5协同过滤算法原理介绍_基于用户的协同过滤
- 6基于SpringBoot+Vue+uniapp微信小程序的自助点餐系统的详细设计和实现(源码+lw+部署文档+讲解等)_微信小程序点餐系统开源项目
- 7PreparedStatement防止SQL注入
- 8switchhosts使用详解_switchhosts的用途
- 9pdm 逆向工程 mysql_PowerDesigner16逆向工程生成PDM列注释(My Sql5.0模版)
- 10GitBash: 右键添加 Git Bash Here 菜单
Rust 赋能前端 -- 写一个 File 转 Img 的功能
赞
踩
所有耀眼的成绩,都需要苦熬,熬得过,出众;熬不过,出局
大家好,我是柒八九。一个专注于前端开发技术/Rust及AI应用知识分享的Coder
此篇文章所涉及到的技术有
Rustwasm-bindgen/js-sys/web-sysWeb WorkerWebAssemblyWebpack/Vite配置WebAssemblyOffscreenCanvas- 脚手架生成项目(
npx f_cli_f create xxx)tailwindcss等MuPDF.js/mammoth.js
因为,行文字数所限,有些概念可能会一带而过亦或者提供对应的学习资料。请大家酌情观看。
前言
在前一篇文章写一个类ChatGPT应用,前后端数据交互有哪几种我们介绍了,如果要进行一个类ChatGPT应用的开发,可能会用到的前后端数据交互的方式。同时呢,我们也介绍了最近公司所做的项目,做一款基于文档类问答的AI功能。
而谈到文档相关的应用,从操作文档角度来看,无非就是文件上传,文件解析和文件展示。而我们之前在文件上传 = 拖拽 + 多文件 + 文件夹介绍过更优雅的上传方式。而文件展示如果大家想了解的话,我们可以单独写一篇文章。
而我们今天来聊聊关于文件解析的相关操作。
业务背景
大家肯定用过很多云盘类的应用。在我们对本地文件进行上传后,在展示的时候一般分为两种模式
- 列表模式
- 大图模式

如果大家观察过云盘针对大图模式的文件资源的展示,就会发现每个文件的头图都是用一个<img/>接收了一个从后端返回的固定图片资源。
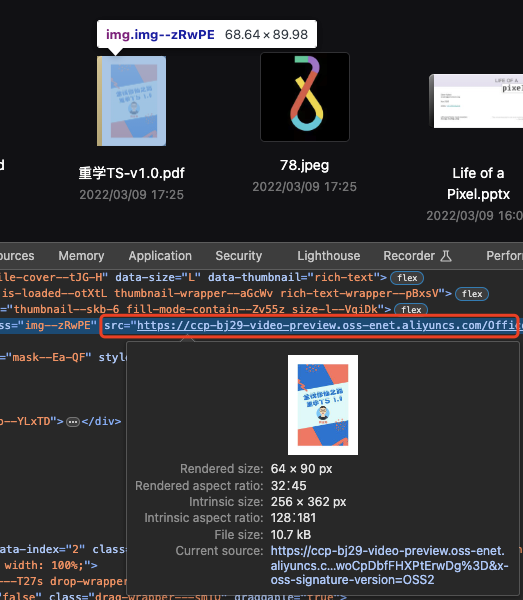
而现在,我们针对大图模式有几点改进
- 要求该图片能显示文件资料的
概要内容(这块可以借助AI对文本进行Summary处理,这个我们后面会单独写一篇文章),而不是单单的把文件的首页信息(pdf/word/pptx)转换成图片(像阿里云盘一样) - 要求前端在上传过程中,就需要显示文件的
概要信息,而不是走接口从服务器获取,也就是这是一个纯前端的事情 - 还需要在图片的标识文件的类型,例如展示
pdf/word/ppt等的图标
为什么做呢,有没有发现我们通过上述的改造和处理,我们直接在大图模式下,通过文件头图信息就能大致知晓文件的内容(概要信息),其次如果展示的资源信息过多,每次从后端获取对应的图片资源也是一件极其耗费带宽的事情。
前端糅合其他语言
讲到这里,大家可能会疑惑,你上面说了那么多,那么这和Rust有啥关系?
关系大着呢,从上面的需求点出发,我们可以看出,其实针对文档解析的处理,都是在前端环境中操作的。同时,针对大体积的文件资源,对其解析处理是一件极其耗时的事情。有时针对特殊文件,可能前端还暂时无法处理。
既然,我们想要在前端执行这些耗时且不易处理的任务,我们就需要请帮手,而在其他语言中有成熟的方案来处理我们遇到的这些问题。(由于种种原因,其他端的小伙伴无瑕处理这种情况)
那么,我们就可以选择一种方式,在前端环境中通过某种方式来糅合其他语言的操作来执行对应的任务。那思来想去,WebAssembly是再合适不过的方式了。如果不了解它,可以看我们之前的文章 - 浏览器第四种语言-WebAssembly。
当然,其他语言(
C/TypeScript)都可以通过编译工具转化成WebAssembly,此片文章中也会涉及,只不过我们是直接使用别人构建好的WebAssembly,而现行阶段,Rust是对WebAssembly最友好的语言。并且,我们也会用Rust手搓一个WebAssembly。这也是为什么这篇文章的主标题叫Rust赋能前端而不是WebAssembly赋能前端(我们在本文的第三部分,Word 解析中详细介绍了用Rust写WebAssembly,如果不想看mupdf的可以直接跳到第三节)
好了,天不早了,干点正事哇。

我们能所学到的知识点
- 服务配置&项目配置
- PDF 解析
- Word 解析
1. 服务配置&项目配置
由于,WebAssembly是一个新兴技术,在一些常规的打包工具(vite/webpack)中使用,我们需要额外处理。
使用WebAssembly从来源大致可以两类
npm包/公司私包(针对如何发私包可以参考之前的如何在gitlab上发布npm包)- 直接在项目目录中使用已经构建好的
wasm
这两种情况我们接下来都会涉及。其实他们的处理方式都是一样的。下面我们就来讲讲Webpack/Vite是如何配置它们的。
Webpack
针对Webpack中使用WebAssembly,我们之前在Rust 编译为 WebAssembly 在前端项目中使用就介绍过。
其实,最关键的点就是需要wasm-pack-plugin
其次,我们还想让WebAssembly模块能够和其他ESM一样,通过import进行方法的导入处理,针对Webapck5我们还可以通过配置experiments的asyncWebAssembly为true来启动该项功能。
最后,为了兼容性,我们处理TextEncoder/TextDecoder。
const path = require('path'); const HtmlWebpackPlugin = require('html-webpack-plugin'); const webpack = require('webpack'); const WasmPackPlugin = require("@wasm-tool/wasm-pack-plugin"); module.exports = { entry: './index.js', output: { path: path.resolve(__dirname, 'dist'), filename: 'index.js', }, plugins: [ new HtmlWebpackPlugin({ template: 'index.html' }), new WasmPackPlugin({ crateDirectory: path.resolve(__dirname, ".") }), // 让这个示例在不包含`TextEncoder`或`TextDecoder`的Edge浏览器中正常工作。 new webpack.ProvidePlugin({ TextDecoder: ['text-encoding', 'TextDecoder'], TextEncoder: ['text-encoding', 'TextEncoder'] }) ], mode: 'development', experiments: { asyncWebAssembly: true } };

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
Vite
从Vite官网看,它只兼容了引入预编译的.wasm,但是对 WebAssembly 的 ES 模块集成提案 尚未支持。而恰巧,我们今天所涉及到的.wasm都是ESM格式的。
按照官网的提示,我们可以借助vite-plugin-wasm的帮助。
配置也很简单,按照下面的处理即可。
import wasm from "vite-plugin-wasm"; import topLevelAwait from "vite-plugin-top-level-await"; export default defineConfig({ plugins: [ wasm(), topLevelAwait() ], worker: { plugins: [ wasm(), topLevelAwait() ] } });
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
项目配置
由于,我们公司的打包工具是Vite,还记得我们之前介绍过的脚手架工具吗。
大家可以在自己电脑中执行,npx f_cli_f create file_to_img来构建一个以Vite为打包工具的前端项目。
然后,我们就可以将上面逻辑写到对应的文件中。
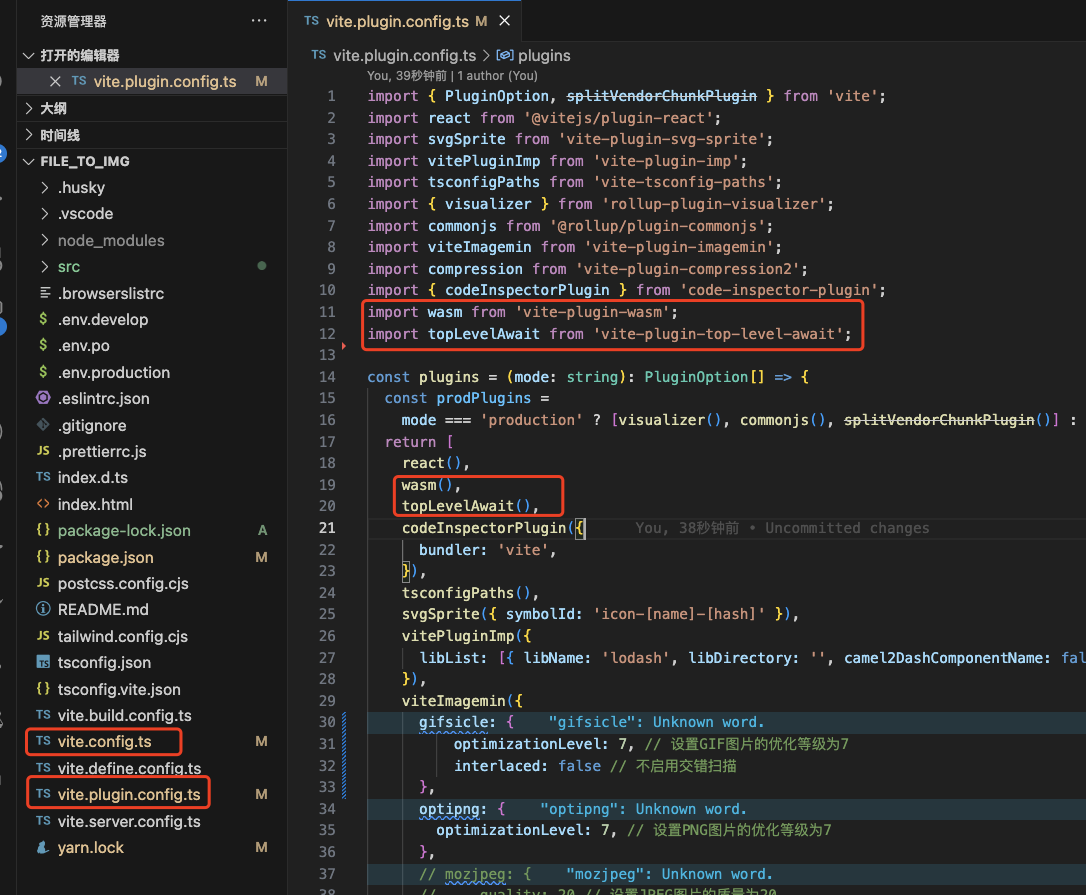
执行到这里,我们的前期的配置工作就算完成了。
如果使用过我们的f_cli_f的人,会知道。我们在项目中内置了很多东西,可以算是开箱即用。
所以,我们保留之前的结构的基础上,在pages中新建一个FileToImg的目录结构,并且将其放置于main路由下。
最后的页面结构如下
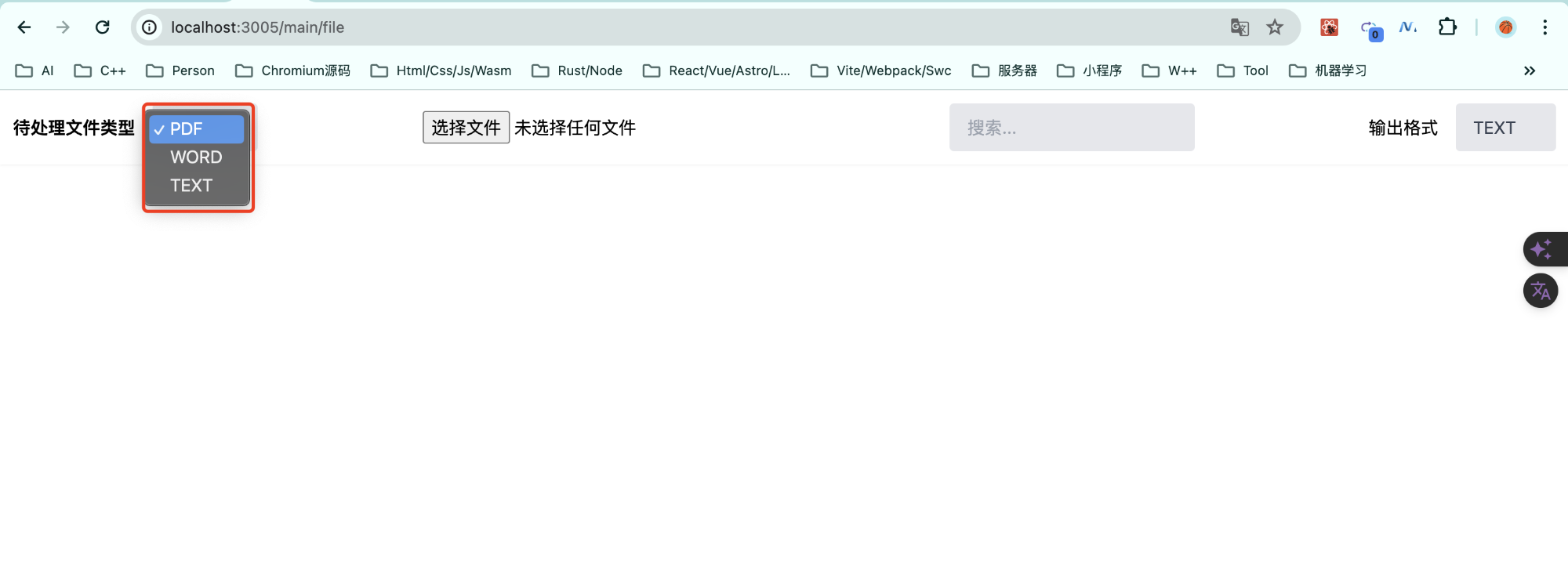
- 左侧的待处理文件类型我们提供了针对
pdf/word/text的常规文件的解析 - 附件上传就是使用最原始的
<input type="file"/> - 搜索区块的话,是针对
PDF的内容检索 - 右侧的格式输出,可以切换文件的输

