
- 1数据结构 易错题合集(持续更新)_数据结构易错题
- 2跟着医生学kivy:kivy-garden 究竟怎样安装?_kivy garden安装
- 3在 QML 中,ComboBox 是一种常用的用户界面控件,通常用于提供一个下拉式的选择框,允许用户从预定义的选项列表中选择一个值_qml 下拉框
- 4当35岁中年危机码农遇上GPT.....
- 5基于大语言模型的智能问答系统设计与实践_基于大模型的智能问答技术
- 6c++有趣的代码_C++开源项目:十行代码15个BUG,你入坑了吗?
- 7基于SpringBoot面向智慧教育的实习实践系统
- 8在红帽上搭建dm7的主备的一些问题_dm7主备搭建守护进程报错无法绑定端口
- 9openlayers入门添加百度地图绘制点线面_openlayers 添加百度地图
- 10如何用python进行接口测试(详细教程)_python接口测试
视频动作识别调研(Action Recognition)_tsn动作识别
赞
踩
视频动作识别调研(Action Recognition)
本文首发于微信公众号“ StrongerTang”,可打开微信搜一搜,或扫描文末二维码,关注查看更多文章。
原文链接:( https://mp.weixin.qq.com/s?__biz=Mzg3NDEzOTAzMw==&mid=2247483899&idx=1&sn=da9ad193c218c0321b4486d09eac1b70&chksm=ced41d0df9a3941be132629546e870a5bb1ba1860b5c7eadf60e2c1591411634e2c1ed3d7f5b&token=361221201&lang=zh_CN#rd)
1.视频动作识别概述
动作识别(Action Recognition)是视频理解方向很重要的一个问题,至今为止已经研究多年。深度学习出来后,该问题被逐步解决,现在在数据集上已经达到了比较满意的效果。动作识别问题简单的来说就是:对于给定的分割好的视频片段,按照其中的人类动作进行分类。比如打球、跑步、吃饭等。该任务不需要确定视频中行为的开始时间和结束时间。
2. 研究难点
动作识别虽然研究多年,但是至今还是处于实验室数据集测试阶段,没有实现真正的实用化和产业化。由此可见该任务目前还是没有非常鲁棒的解决方案。
2.1 任务特点
动作识别和图像分类其实很相似,图像分类是按照图像中的目标进行软分类,动作识别也类似。起初类似于UCF数据集,都是采用单标签,也就是一段视频只对应一个标签。现在CPVR举办的Activitynet(Kinetics数据集)每段视频中包含多个标签。相比于图像分类,视频多了一个时序维度,而这个问题恰恰是目前计算机领域令人头疼的问题。
2.2 任务难点
动作识别处理的是视频,所以相对于图像分类来说多了一个需要处理的时序维度动作识别还有一个痛点是视频段长度不一,而且开放环境下视频中存在多尺度、多目标、摄像机移动及不同视角等众多的问题。此外,动作的类内差异性和类间相似性也是难点之一。这些问题都是导致动作识别还未能实用化的重要原因。
3 数据集介绍
目前比较常用的数据库主要有3个,UCF101、HMDB51和Kinetics。

4 技术原理
在深度学习出现之前,表现最好的算法是iDT[1][2],之后的工作基本上都是在iDT方法上进行改进。深度学习出来后,陆续出来多种方式来尝试解决这个问题,具体包括:Two-Stream[3][4]、C3D(Convolution 3 Dimension)[6],还有RNN[7]方向等。
4.1 iDT方法
在深度学习之前,iDT(improved Dense Trajectories)方法是最经典的一种方法。虽然目前基于深度学习的方法已经超过iDT,但是iDT的思路依然值得学习,而且与iDT的结果做ensemble后总能获得一些提升。
iDT的思路主要是在《Dense Trajectories and Motion Boundary Descriptors for Action Recognition》和《Action Recognition with Improved Trajectories》两篇文章中体现。这两篇都是Wang H的文章,前者要更早一些,介绍了DT(Dense Trajectories)算法。后者则在前者的基础上进行了改进。DT算法的基本思路为利用光流场来获得视频序列中的一些轨迹,再沿着轨迹提取HOF,HOG,MBH,trajectory 4种特征,其中HOF基于灰度图计算,另外几个均基于dense optical flow计算。最后利用FV(Fisher Vector)方法对特征进行编码,再基于编码结果训练SVM分类器。而iDT改进的地方在于它利用前后两帧视频之间的光流以及SURF关键点进行匹配,从而消除、减弱相机运动带来的影响,改进后的光流图像被成为warp optical flow。
4.2 TWO STREAM方法
Two-Stream方法是深度学习在动作识别方向的一大主流方向。最早是VGG团队在NIPS上提出来的。其实在这之前也有人尝试用深度学习来处理动作识别,例如李飞飞团队通过叠加视频多帧输入到网络中进行学习,但不幸的是这种方法比手动提取特征更加糟糕。当Two-Stream CNN出来后才意味着深度学习在动作识别中迈出了重大的一步。
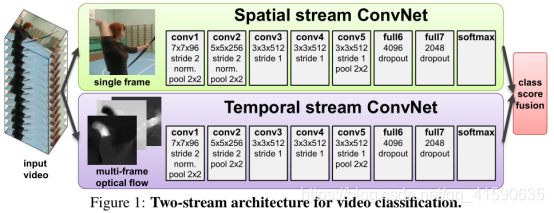
4.2.1 TWO-STREAM CNN
Two-Stream CNN网络顾名思义分为两个部分,一部分处理RGB图像,一部分处理光流图像。最终联合训练,并分类。这篇文章主要有以下三个贡献点。
1)论文提出了two-stream结构的CNN网络,由空间(RGB)和时间(光流)两个维度的网络组成;
2)作者提出了利用网络训练多帧密度光流,以此作为输入能在有限训练数据的情况下取得不错的结果;
3)采用多任务训练的方法将两个动作分类的数据集联合起来,增加训练数据,最终在两个数据集上都取得了更好的效果(作者提到,联合训练也可以去除过拟合的可能)。
网络结构:
因为视频可以分为空间和时间两个部分。空间部分,每一帧代表的是空间信息,比如目标、场景等等。而时间部分是指帧间的运动,包括摄像机的运动或者目标物体的运动信息。所以网络相应的由两个部分组成,分别处理时间和空间两个维度。每个网络都是由CNN和最后的softmax组成,最后的softmax的fusion主要考虑了两种方法:平均,在堆叠的softmax上训练一个SVM。网络的结构图如下所示。
光流栈(Optical flow Stacking):
光流栈,或者叫做光流的简单叠加。简单的来说就是计算每两帧之间的光流,然后简单的stacking。
考虑对一小段视频进行编码,假设起始帧为T,连续L帧(不包含T帧)。计算两帧之间的光流,最终可以得到L张光流场,每张光流场是2通道的(因为每个像素点有x和y方向的移动)。

最后将这些光流场输入,得到相应的特征图。
该方法在UCF-101和HMDB-51上取得了与iDT系列最好的一致效果。在UCF-101上准确度为88.0%,在HMDB上准确度为59.4%。
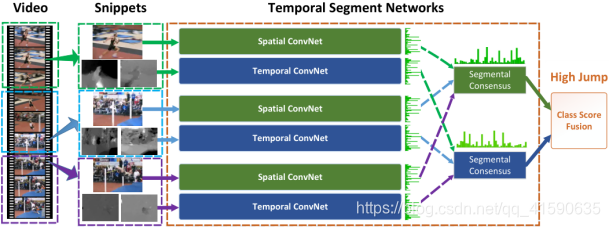
4.2.2 TSN
TSN(Temporal Segments Networks)[5]是在two-Stream CNN基础上改进的网络。目前基于two-stream的方法基本上是由TSN作为骨干网络。
two-stream方法很大的一个弊端就是不能对长时间的视频进行建模,只能对连续的几帧视频提取temporal context。为了解决这个问题,TSN网络提出了一个很有用的方法,先将视频分成K个部分,然后从每个部分中随机的选出一个短的片段,然后对这个片段应用上述的two-stream方法,最后对于多个片段上提取到的特征做一个融合。下图是网络的结构图。
4.3 C3D方法
C3D(3-Dimensional Convolution)[6]是Two-Stream之外的另一大主流方法,但是目前来看C3D的方法得到的效果普遍比Two-Stream方法低好几个百分点。但是C3D仍然是目前研究的热点,因为该方法比Two-Stream方法快很多,而且基本上都是端到端的训练,网络结构更加简洁。该方法思想非常简单,图像是二维,所以使用二维的卷积核。视频是三维信息,那么可以使用三维的卷积核。所以C3D的意思是:用三维的卷积核处理视频。
网络结构:
C3D共有8次卷积操作,5次池化操作。其中卷积核的大小均为333,步长为111。池化核为222,但是为了不过早的缩减在时序上的长度,第一层的池化大小和步长为122。最后网络再经过两次全连接层和softmax层后得到最终的输出结果。网络的输入为316112112,其中3为RGB三通道,16为输入图像的帧数,112112是图像的输入尺寸。

4.4 RNN方法
因为视频除了空间维度外,最大的痛点是时间序列问题。而众所周知,RNN网络在NLP方向取得了傲人的成绩,非常适合处理序列。所以除了上述两大类方法以外,另外还有一大批的研究学者希望使用RNN网络思想来解决动作识别问题。
典型工作有中科院深圳先进院乔宇老师的工作:《RPAN:An End-to-End Recurrent Pose-Attention Network for Action Recognition in Videos》[7]。这篇文章是ICCV2017年的oral文章。但是与传统的Video-level category训练RNN不同,这篇文章还提出了Pose-attention的机制。

这篇文章主要有以下几个贡献点:
1)不同于之前的pose-related action recognition,这篇文章是端到端的RNN,而且是人体姿态的时空演变;
2)不同于独立的学习关节点特征(human-joint features),这篇文章引入的pose-attention机制通过不同语义相关的关节点(semantically-related human joints)分享attention参数,然后将这些通过human-part pooling层联合起来;
3)视频姿态估计,通过文章的方法可以给视频进行粗糙的姿态标记。
此外,RNN方向比较新的研究包括如下:
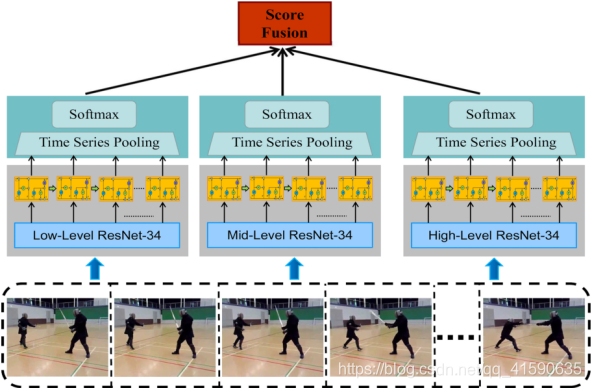
1)2018 Zhenxing ZHENG等人的《Multi-Level Recurrent Residual Networks for Action Recognition》,提出了一种新的多层次循环残差网络(MRRN),它结合了三种识别流。每个流由一个剩余网络(resnet)和一个循环模型组成。该模型通过使用两个可选的网格从静态帧中学习空间表示,并使用叠加简单循环单元(SRU)来建模时间动态,从而捕获时空信息。通过计算SoftMax分数的加权平均值来融合三个独立学习的低、中、高级别表示的不同级别流,以获得视频的互补表示。与以前以时间复杂度和空间复杂度为代价提高性能的模型不同,该模型通过使用快捷连接降低了复杂度,并以更高的效率进行端到端培训。与CNN-RNN框架基线相比,MRRN显示出显著的性能改进,并获得了与最新技术相当的性能,在HMDB-51数据集上达到51.3%,在UCF-101数据集上达到81.9%,尽管没有额外的数据。
2)2019年Lin Sun等人的《Coupled Recurrent Network (CRN)》,提出了一种新的循环结构,称为耦合循环网络(CRN),用于处理多个输入源。在CRN中,RNN的并行流耦合在一起。CRN的关键设计是一个循环解释块(RIB),它支持以循环方式从多个信号中学习互易特征表示。与在每个时间步或最后一个时间步叠加训练损失的RNN不同,也提出了一种有效的CRN训练策略。实验证明了该方法的有效性。特别是,在人类动作识别和多人姿态估计的基准数据集上取得了新的进展。
5 小结
视频动作识别是视频理解的重要内容,也是计算机视觉领域的重要组成部分,在视频信息检索、日常生活安全、公共视频监控、人机交互、科学认知等领域都有广泛的应用前景和社会价值,是值得长期投入的课题。
但动作识别和检测的关系就类似于图像识别和图像检测,可以说识别是检测的一部分或者说是前期准备,因而目前的研究热点主要集中于难度更大的动作检测部分。动作检测将在下一篇文章中予以介绍。
参考文献
[1] Wang H, Schmid C. Action recognition with improved trajectories[C]//Computer Vision (ICCV), 2013 IEEE International Conference on. IEEE, 2013: 3551-3558.
[2] Wang H, Kläser A, Schmid C, et al. Dense trajectories and motion boundary descriptors for action recognition[J]. International journal of computer vision, 2013, 103(1): 60-79.
[3] Simonyan K, Zisserman A. Two-stream convolutional networks for action recognition in videos[C]//Advances in neural information processing systems. 2014: 568-576.
[4] Feichtenhofer C, Pinz A, Zisserman A P. Convolutional two-stream network fusion for video action recognition[J]. 2016.
[5] Wang L, Xiong Y, Wang Z, et al. Temporal segment networks: Towards good practices for deep action recognition[C]//European Conference on Computer Vision. Springer, Cham, 2016: 20-36.
[6] Tran D, Bourdev L, Fergus R, et al. Learning spatiotemporal features with 3d convolutional networks[C]//Computer Vision (ICCV), 2015 IEEE International Conference on. IEEE, 2015: 4489-4497.
[7] Du W, Wang Y, Qiao Y. Rpan: An end-to-end recurrent pose-attention network for action recognition in videos[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2017: 3725-3734.
[8] Karpathy A, Toderici G, Shetty S, et al. Large-scale video classification with convolutional neural networks[C]//Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2014: 1725-1732.
本文参考了众多网络资料及论文原文,在此表示感谢!!
 (关注微信公众号“StrongerTang”,看更多文章,和小汤一起学习,一同进步!)
(关注微信公众号“StrongerTang”,看更多文章,和小汤一起学习,一同进步!)

