
- 1学校规定:一个学生可选修多门课,一门课有若干学生选修;一个教师可讲授多门课,一门课只有一个教师讲授;一个学生选修一门课,仅有个成绩。学生的属性有学号、学生姓名;教师的属性有教师编号,教师姓名_假设教务管理系统规定: ①一个学生可选修多门课,一门课有若干学生选修; ②一个教
- 2刷LeetCode算法题的常见模式套路
- 3java版12306抢票_J12306
- 4Android:设置屏幕亮度的几种方法_android 安卓调屏幕亮度
- 5(详解)钉钉接口,PC端微应用,免登录及获取当前用户信息_从钉钉打开一个网页 获取当前用户信息的方法
- 6Unity面试题总结
- 7IOS Xcode证书配置和ipa打包流程(附详细图文教程)_xcode 15.3打包步骤
- 8最近论文汇总:ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks_channel attention论文名
- 9Oracle表空间管理_ora-25141: ??? extent management ??
- 10长沙EI国际会议 | 计算机视觉与深度学习国际会议(CVDL 2024)_2024 计算机 会议
全链路数据血缘在满帮的实践_neo4j 数据血缘
赞
踩
摘要:全链路数据血缘,指在数据的全生命周期内,数据与数据之间会形成各式各样的关系,贯穿整个数据链路中。
本文分享自华为云社区《全链路数据血缘在满帮的实践》,作者: 你好_TT。
什么是全链路数据血缘
根据维基百科定义,数据血缘(Data Lineage)又叫做数据起源(Data Provenance)或者数据家谱(Data Pedigree)。其通常被定义为一种生命周期,主要包含数据的来源以及数据随时间移动的位置。
数据血缘是数据资产的重要组成部分,用于分析表和字段从数据源到当前表的血缘路径,以及血缘字段之间存在的关系是否满足,并关注数据一致性以及表设计的合理。它描述了数据从收集,生产到服务的全链路的变化和存在形式。
全链路数据血缘,指在数据的全生命周期内,数据与数据之间会形成各式各样的关系,贯穿整个数据链路中,如图1所示。
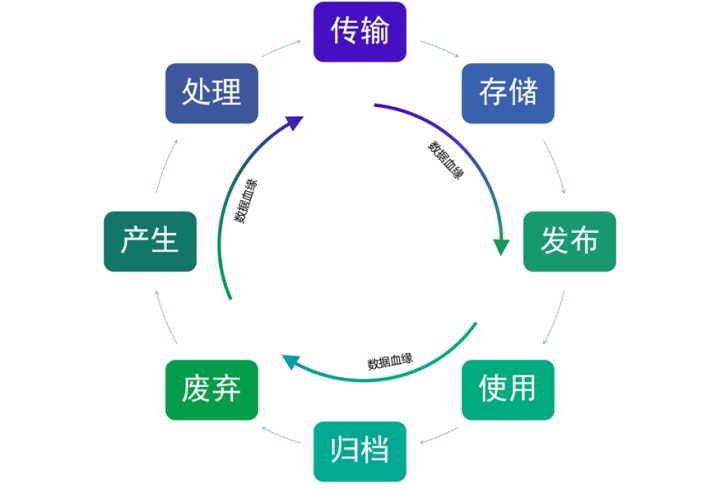
图1 全链路数据血缘
血缘构建方案调研
血缘解析
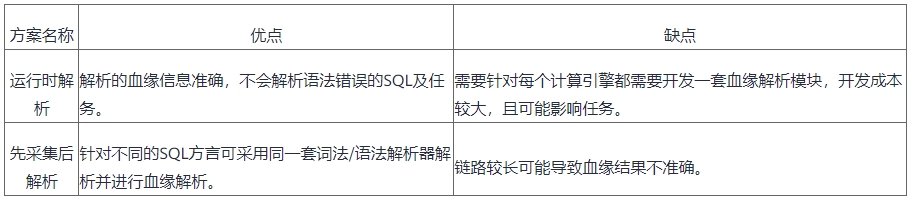
当前,数据血缘大多是对SQL语句进行解析,以发现上下游调用栈等信息。主流方案可分为两种:
- 运行时解析,即在任务运行时通过hook接口或者listener接口对SQL生成的逻辑技术树(AST)进行解析。
- 先采集后解析,即通过采集程序把各个计算引擎的SQL统一采集到mq进行血缘解析。
上述两类方案各有优劣,其对比如表1所示。
表1 数据血缘解析方案
血缘存储
相比传统关系型数据库和ES等工具,图数据库在血缘信息的查询与分析方面具有如下优势:
1、对复杂关系的存储和分析更优
数据血缘刻画了数据的完整生命周期,具有数据链路长的特点。传统关系型数据库和ES等,往往只能反映当前状态或较短路径内的状态,在长链路血缘的检索中存在明显劣势。而图数据库进行了复杂关系的有效组织,通过点边结构将血缘的上下游进行了完美串联,进而可实现更长链路血缘的存储、检索和分析。
2、能够有效利用数据间的关联性达成更精准可靠的决策
图结构特征对业务具有重要的指导意义。例如,图的稠密程度可反映业务数据关联的紧密程度,进而有助于识别高I/O或高吞吐量业务,识别链路瓶颈;图数据间的共现性可反映出血缘中的共生关系,进行辅助进行血缘重要性划分;图可视化有助于帮助业务人员更清晰的了解血缘动态等。
相比开源图数据库Neo4j、Nebula Graph,华为云GES具有如下优势:
- 基于分布式内存计算,性能更高,速度更快,响应时间更短
- 集成30+高性能算法,图分析能力更强
- 对接华为云大数据、AI服务,周边支持更全面,服务对接更便利
- 基于实践自研了查询算子Path-Query,支持复杂过滤查询条件,且具备更优的查询性能
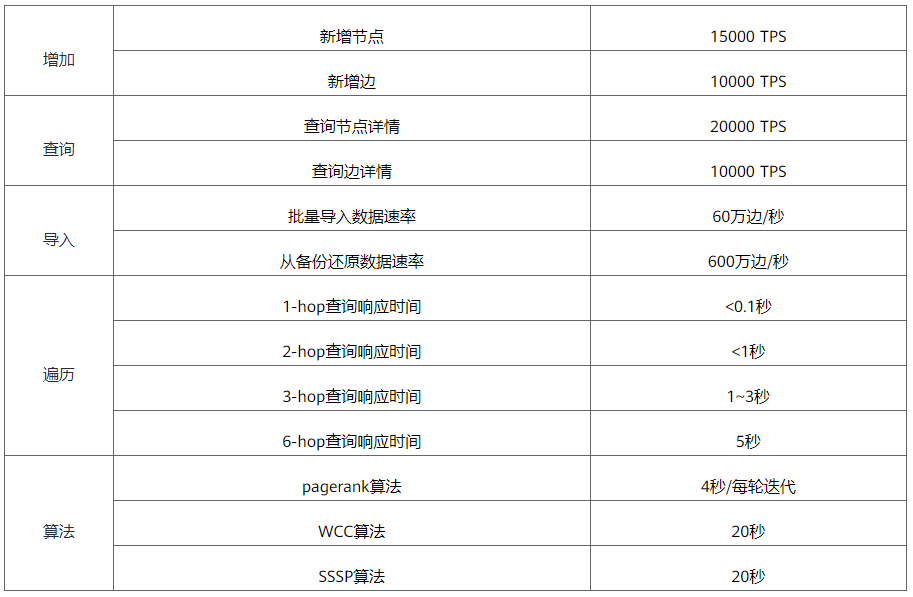
华为云GES的基准测试数据如表2所示。
表2 华为云GES的基准测试数据
满帮数据血缘的实践
满帮数据血缘特点
满帮数据血缘具备如下几个特点:
- 采集覆盖范围广。目前已覆盖满帮离线和实时绝大部分场景,涉及的组件有hive、spark、impala、flink、doris、kafka、clickhouse等。
- 多层次的血缘关系。根据血缘模型和血缘数据,形成了字段与字段、字段与表、表与表、库与库、任务与任务等血缘关系,应用于不同的场景中。
- 丰富的应用场景。目前已应用于数据治理、数据质量、数据安全、应用告警等各个场景。
- 开放的血缘接口。目前基于血缘服务平台,对外提供了丰富的血缘接口,包括基础的血缘信息查询和基于各种算法的血缘路径查询。
数据血缘模型
定义丰富的血缘模型,有助于更真实有效的展示血缘关系。满帮血缘模型主要包括实体和关系,其中,实体主要涵盖了任务、库、表、视图、字段、函数和其他实体。实体和关系的组合显示了从一个表/列到其他表/列的血缘,包含表之间的依赖关系 INSERT INTO\CTAS,字段之间的依赖关系PROJECTION\PREDICATE。
使用完整的数据血缘模型能够展示血缘全貌,但存在以下问题:一是完整的血缘模型往往包含成千上万个实体血缘关系,较难在前端展示;二是过量冗余的信息可能导致问题实体定位困难。为解决上述问题,满帮基于数据血缘模型,开发了多个层次的血缘模型,主要包括完整血缘模型和高阶血缘模型。完整的数据血缘模型是所有其他高级血缘模型的基础,而高级血缘模型通过省略或聚合模型中的某些关系和实体对完整血缘进行了放缩操作。在实际业务中,可使用完整的血缘模型展示SQL查询中数据是如何传输的,而表级数据的流动可通过高级血缘模型进行呈现。
整体架构方案
满帮全链路数据血缘,实现了血缘数据数据采集开始到最终数据服务整个链路的贯穿,有助于高效地实现问题的快速定位以及影响面的快速评估。全链路血缘架构如图2所示,主要包含5层:
- 血缘采集层:负责采集满帮大数据平台各组件的任务血缘信息,将血缘解析为统一格式;
- 血缘处理层:通过消息队列Kafka,通过实时任务将血缘信息统一处理并写入GES和Hive,并提供血缘存储接口和血缘管理功能;
- 血缘存储层:通过GES和Hive分别提供血缘关系信息存储和血缘分析统计功能;
- 血缘接口层:提供血缘信息功能接口,对接血缘应用服务;
- 血缘应用层:提供血缘服务,包括数据资产,数据治理,数据安全等。
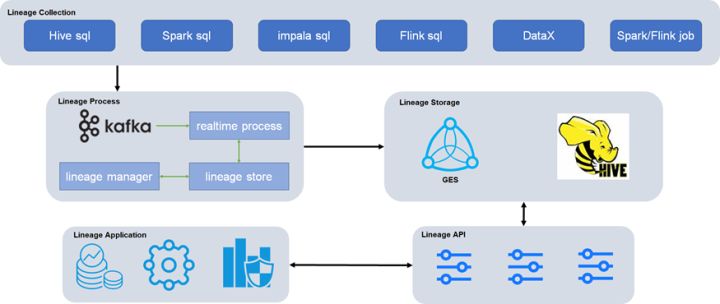
图2 满帮全链路血缘架构
血缘采集层
满帮血缘采集层当前已覆盖了满帮内部撸数、离线调度、实时计算等平台的SQL任务和Spark\Flink任务。血缘关系包含了系统血缘关系、作业血缘关系、库血缘关系、表级血缘关系和字段血缘关系,其指向数据的上游来源,向上游追根溯源。通过血缘关系能清晰展现数据加工处理逻辑脉络,快速定位数据异常字段影响范围,准确圈定最小范围数据回溯,降低了理解数据和解决数据问题的成本。具体为:
- Hive SQL血缘解析主要参考org.apache.hadoop.hive.ql.hooks.LineageLogger通过Hive hook函数解析。
- Spark SQL是通过QueryExecutionListener的onSuccess方法来获取逻辑计划的Output,通过Output解析出字段血缘关系。
- Flink SQL通过Cava cc来获取SQL的逻辑计划树(AST),通过遍历AST来获取执行Input\Output,从而解析出表、字段血缘关系。
- Spark\Flink任务通过分析DAG中关系,找出Input\Output,构建虚拟的输入输出表来构建血缘关系。
- Impala目前采用filebeat采集血缘日志,异步发送血缘信息到Kafak。
为了便于数据血缘的采集和处理,统一了各个组件的血缘格式,主要包含输入输出表、字段等信息。

血缘处理层
血缘处理层主要由血缘实时处理模块、血缘存储接口模块、血缘管理模块组成。
为了满足近实时的血缘查询需求,满帮采用了Flink作为血缘实时处理模块的核心组件,通过实时分析处理上游采集到的血缘信息,快速的写入到图数据库和Hive中。该模块支持批量删除\查询\更新以及模糊删除\查询\更新等功能。
血缘存储接口模块主要开发快速写入图数据库及Hive的相关接口。
血缘管理模块主要用于维护管理及统计分析血缘信息。
血缘存储层
血缘存储层选用了华为云图引擎GES服务作为存储引擎。GES使用华为自研的EYWA内核,是针对以“关系”为基础的“图”结构数据,进行查询、分析的服务。GES目前提供丰富多样的原生接口,包括批量读写点、边以及各个路径查询算法。
在满帮全链路数据血缘场景中,对图数据操作主要包括读和写操作两块。写操作主要是将解析格式化好的血缘数据实时写入图数据库。另一块写操作主要给应用方提供写的请求,如表\字段安全等级打标。读操作主要是来源自满帮内部各个应用场景,主要涵盖了短途、CRM、客服、金融。
血缘接口层及血缘应用层
血缘接口层主要对接血缘应用层各个服务,通过开放血缘RPC接口,给各个应用服务提供丰富的接口选择。
目前,满帮血缘信息主要用于数据资产、数据治理、数据安全、数据质量等各个场景。
1、数据资产
满帮数据资产管理平台提供资产全景、数据地图,数据质量,数据安全等功能,如图4所示。数据地图支持以扇形图及图表的形式进行可视化展示各类数据资产的占比,通过不同层次的图形展现粒度控制,满足业务上不同应用场景的数据查询和辅助分析需要。

图4 满帮数据资产管理平台
数据地图还支持血缘信息的展示,用以分析数据在任务间的流向,如图5所示。目前数据地图支持任务、库、表、字段级血缘关系的展示。

图5 满帮数据地图
2、数据治理
数据治理是指在数据的全生命周期内,对其进行管理的原则性方法,其目标是为了确保数据的安全、及时、准确、可用和易用。满帮数据治理主要围绕“指标清晰,质量规范”“资源合理,厉行节约”原则开展。
如图6所示,满帮数据治理任务通过分析库、表、字段的血缘信息,从价值密度、访问频次、使用方式、时效性等级等维度评估,从而评级出数据热度,热数据、温数据、冷数据和冰数据。通过血缘信息查看离线数仓某个任务链路的上下游任务依赖,可同时分析链路上表的使用冷热程度,优化ods、dwd上相关任务和SQL,裁剪合并低价值表,缩短数据流ETL链路,从而降低维护成本,提升数据价值。

图6 满帮数据治理
3、数据质量
数据质量,旨在实现高效监控每一类作业的运行状态,洞察关键信息,形成事前预判、事中监控、事后跟踪的质量管理闭环流程。在满帮数据质量监管平台建设中,面临如下几个问题:
- 离线实时监控体系不完善,监控有盲点
- 全链路难以保障数据质量,数据不可信
- 数据依赖复杂,链路深,数据产出易延迟
针对上述问题,满帮基于全链路数据血缘,从如下几方面提升数据全生命周期内的数据质量:
- 流量数据owner主动通知,根据血缘关系,通知有调度依赖的任务,提供多层通知选项,以避免过渡干扰。
- 离线ETL链路,若ods\dwd层的某个表的关键字段发生修改变更,通过血缘信息,自动发告警给下游依赖表、任务负责人
- 实时Flink任务,若source端Kafka字段结构发生变更,根据血缘关系,自动通知下游依赖表及任务负责人
4、数据安全
随着国家对数据流通过程中数据的安全越来越重视,若没有有效识别安全级别高的数据,可能产生安全合规风险。因此,满帮上线了资产安全打标平台,支持通过“自动化+手动”打标实现资产安全定级打标,但存在打标覆盖率不高,精准度较低等问题。
基于全链路血缘关系,可根据不同数据安全级别,先利用血缘打标接口对不同表字段进行打标,然后识别出打标字段的上下游血缘关系,进而自动打上安全等级标签。如图7所示,通过血缘打标平台给字段city_name安全打标,定级为L3,根据血缘关系将自动给下游血缘链路的字段进行染色打标,实现自动“染色”。

图7 数据安全
未来展望
经过探索实践,满帮基于图数据库相关技术已基本实现全链路数据血缘建设,取得了一定成效。未来,将在如下方面进行更深层次的探索,实现业务进一步提升:
1、目前,血缘采集主要通过SQL、任务自动解析和人工整理的方式提高血缘覆盖率,目前覆盖率已达到95%以上。未来将探索使用人工智能相关方法,基于数据集之间的依赖关系计算数据相似性,以提升覆盖率。
2、Impala血缘采集方式链路较长,且依赖Filebeat。后续将逐步对接使用SQL语法解析AST的方案,实现解析归一化。
3、目前血缘关系维度还不支持函数级别。
4、开发全链路血缘开放平台,快速对接应用方,为应用方提供血缘服务。
参考
[1] https://en.wikipedia.org/wiki/Data_lineage
[2] https://zhuanlan.zhihu.com/p/408737398
[3] https://www.infoq.cn/article/fov6aewrgnofhd91yvcr

