
- 1一个简易的QQ魔法卡片炼卡消耗计算器_魔法卡片计算器
- 2黑马redis学习笔记_黑马redis原理篇笔记
- 3万亿国债消防救援——北斗应急通讯设备类目推荐
- 4【论文笔记】机器遗忘:错误标签方法_扰动标签的方法,该方法在每一次迭代过程中,将部分标签随机替换为错误标签
- 5jquery实现app开发闹钟功能_智能闹钟APP方案开发, 自己设定有趣铃声, 舒适唤醒效果!...
- 6无缝迁移!数亿MySQL数据顺利迁移到MongoDB_mysql 转mongofb
- 7基于Python爬虫的豆瓣电影影评数据可视化分析_电影影评分析及可视化
- 8网易Java面试必问:月薪20k+的Java面试都问些什么_java面试20k
- 9回忆自己的大学四年得与失_大学的得与失
- 10【深度学习】资源:最全的 Pytorch 资源大全_pytorch pt模型大全
分布式计算浅谈_分布式操作系统集中式算法和分布式算法
赞
踩
一、集中计算和分布式计算
对于究竟如何处理大数据,业界内其实一直有集中式计算和分布式计算两大方向,虽然大数据技术包含了数据采集、存储、计算、分析等一系列流程,但分布式计算其实一直是其中的核心。
20世纪60年代,大型主机自被发明出来以后,凭借其超强的计算和I/O处理能力及在稳定性、安全性方面的卓越表现,在很长一段时间内引领了计算机行业以及商业计算领域的发展。与此同时,集中式计算机系统架构也成为了主流,而分布式系统由于理论复杂、技术实现困难并未被推广。
所谓集中式计算就是指由一台或多台主计算机组成中心节点,数据集中存储在这个中心节点中,并且整个系统的所有业务单元都集中部署在这个中心节点上,系统的所有功能均能由其进行集中处理,其最大的特点就是部署结构简单。
而分布式计算主要研究如何应用分布式系统进行计算,即把一组计算机通过网络相互连接组成分散系统,然后将需要处理的数据分散成多个部分,交由分散在系统内的计算机组同时计算再将结果最终合并得到最终结果。
然而随着计算机系统逐渐向微型化、网络化发展,传统的集中式处理不仅会导致成本攀升,也存在着较大的单点故障风险。为了规避风险、降低成本,互联网公司把研究方向转向了分布式计算。
二、何为分布式计算
2.1 分布式计算
这里我引用知乎上的介绍:“分布式计算( Distributed computing )是一种把需要进行大量计算的工程数据分割成小块,由多台计算机分别计算,在上传运算结果后,将结果统一合并得出数据结论的科学。”
2.2 分布式计算优缺点
优点:
1.超大规模
2.虚拟化
3.高可靠性
4.通用性
5.高伸缩性
6.按需服务
7.极其低廉
8.容错性
缺点:
1.多点故障
2.安全性低
2.3 应用点
工业互联网络、云计算、物联网、大数据、并行计算、人工智能。
三、分布式技术术语
典型分布式计算技术有中间件技术、移动Agent技术、网格、Web Service技术、P2P技术等。
中间件(Middleware)技术:属于可复用软件的范畴,处于操作系统软件与用户应用软件中间。中间件在操作系统、网络和数据库之上、应用软件之下,其作用是为处于上层的应用软件提供运行与开发的环境,帮助用户灵活、高效地开发和集成复杂的应用软件。
移动Agent技术:是一个能在异构网络中自主地从一台主机迁移到另一台主机、并可与其他agent或资源交互的程序,具有自治性、移动性、智能性。
网格(Grid):网格技术在动态的一组个体、机构和资源的虚拟组织中实行灵活、可靠、可调整的资源共享环境。在此环境中,网格所需解决的问题包括:唯一性认证、资源访问、资源发现的方式等。
Web Service技术:是一种部署在Web上的对象/组件。Web Service结合了以组件为基础的开发模式以 及 Web 的出色性能,一方面具有黑 匣子的功能,可以在不关心功能如何实现的情况下重用;同时,Web Service可以把不同平台开发的不同类型的功能块集成在一起,提供相互之间的互操作。
P2P技术:P2P 系统由若干互联协作的计算机构成,是Internet上实施分布式计算的新模式。它把C/S与B/S系统中的角色一体化, 引导网络计算模式从集中式向分布式偏移,也就是说网络应用的核心从中央服务器向网络边缘的终端设备扩散,通过服务器与服务器、服务器与PC机、PC机与PC机、PC机与WAP 手机等两者之间的直接交换而达成计算机资源与信息共享。
四、 分布式计算的实现思想
4.1 三大引擎
讲到分布式计算,大多数人第一时间想到的,就是“Hadoop”,它的诞生就是为了解决海量数据的计算问题。Hadoop以谷歌三大论文为蓝本,Google FS、MapReduce、BigTable,这三篇论文奠定了大数据算法的基础。但这些论文毕竟是2003年就发表了,当时也只能应对离线数据的处理,因此后来衍生出了一些其他的方式,比如流失计算、流水线模式,以应对技术发展的需要,为实时计算、机器学习提供了更强有力的保障。
如果问起MapReduce、Spark、Tensorflow的区别,很多人会认为这是属于不同领域的引擎,但它们都有共同的一部分,即“分布式计算”。也就是说,这三个框架,都是定义了一种计算数据的方法,通过这种方法,来设计它的分布式计算能力,并解决一些特定的问题。
4.2 三种实现思想
包含三种思想:分治思想、流思想、接下来我们就分别讲一下,这三种引擎对应的三种设计思想。
1) map-redius分治思想
批处理:分而治之的思想
MapReduce的代表思想是“分而治之”,如何理解?其实很简单,根据名字就可以看出来,分而治之就是将一个复杂的大问题,拆解成规模较小的子问题,然后通过对子问题的求解,来合并成对大问题的求解。
第一个阶段称为Map阶段,负责将大的任务拆分为多个并行的子任务,相较于原始任务而言,子任务所执行的内容与父任务是相同的,但子任务的数据规模及需要计算的数据量都会小很多。第二个阶段称之为Reduce阶段,将各个拆分子任务的结果进行汇总,并得到最终的计算结果。整个过程如下图所示:
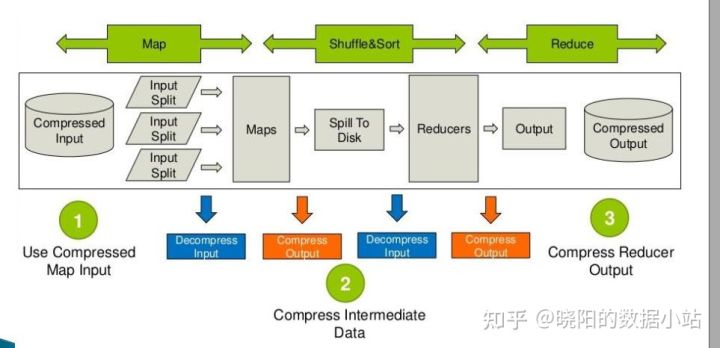
MapReduce的调优是一个复杂的过程,是一种长期积累的经验总结。主要包括以下四个部分:
- 硬件调优:内存、磁盘io以及网络等;
- 参数调优:缓冲区、磁盘读写、增加JVM内存、增加运行个数等;
- 代码调优:编写Combiner、重新设计Key、合并小文件、数据压缩等;
- 作业调优:合理规划运行依赖、调整作业优先级等。
2)流处理--实时计算的基础
MapReduce实时性不好,实时任务通常是针对“数据流”进行处理,需要常驻的进行,数据到了之后,即时进行处理。在分布式领域,我们把这种方式称之为“流处理”,英文是Stream,如最近比较火的直播电商,就需要实时处理直播产生的流数据。
目前流式计算框架相对成熟,以Flink、Spark Streaming、Storm为代表的开源组件也被广泛应用。流式数据处理,简单来讲,就是系统每产生一条数据,都会被立刻采集并发送到流式任务中心进行处理,不需要额外的定时调度来执行任务。
通常来讲,流式计算与离线计算的区别在于以下四点:
- 数据像水流一样,持续的进行计算;
- 数据的规模通常很大,至少TB级以上;
- 对实时性的要求高,但旧数据的重要性会持续下降;
- 数据到达的顺序无法保证,因此需要窗口计算。
以Flink为例,流式数据处理过程如下图所示:

3) 流水线:深度学习的助手
流水线作业,这里主要谈tensorflow的框架。(特点是业务处理点很多)
批处理和流式计算,能够解决绝大多数的业务场景,即便是复杂的业务场景,应用“流批一体”的技术,也能够设计出较好的方案。但有一种模式还是例外的,那就是“流水线”模式,这种模式通常与制造业相关。
例如生产一瓶饮料,首先需要在瓶子里灌装饮料,然后需要瓶盖封口,再包上相应的包装纸。这种向工厂一样的作业,即上一个任务结束后,再开始下一个任务,这种模式我们称之为“流水线”模式。
这种模式最早应用于CPU的设计,后来推广到机器学习等领域,广泛应用于模型训练之中,典型的框架就是Tensorflow,示意图如下:
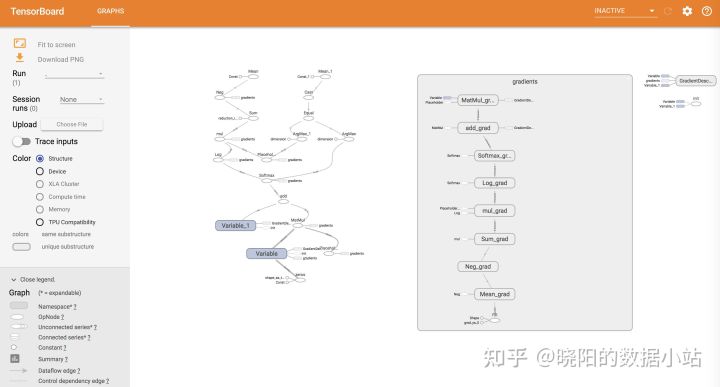
TensorFlow的ETL流程如下:
- 提取(Extract):通过多种途径读取数据,比如内存、本地的 HDD 或 SSD、远程的 HDFS、GCS 等。数据的种类也有很多,比如图像数据、文本数据、视频数据等;
- 转换(Transform):使用 CPU 处理器对输入的数据进行解析以及预处理操作,包括混合重排(shuffling)、批处理(batching), 以及一些特定的转换。比如图像解压缩和扩充、文本矢量化、视频时序采样等;
- 加载(Load):将转换后的数据加载到执行机器学习模型的加速器设备上,比如 GPU 或 TPU。
- 流水线模式对于一些加速模型训练还是很重要的,如果你的CPU处理数据能力跟不上GPU的处理速度,此时CPU预处理数据就成为了训练模型的瓶颈环节。
综上,分布式计算技术,相较于分布式的其他领域,理解起来比较容易,实际应用也非常广泛,因此勤加学习,相信您很快可以掌握其中的精髓。
五、结论
读者至少应该掌握:
- 分布式计算不仅仅是一种方式。
- 当前可用分布式至少有三种框架:分治框架、流框架、流水线框架。
- 应用范围: 工业互联网络、云计算、物联网、大数据、并行计算、人工智能。

