
- 1海康威视2023薪资曝光,月薪2W年终8W_海康威视年终奖
- 2Git push 时如何避免出现 Merge branch 'master' of xxx
- 3VisionPro的CogRecordDisplay控件显示及保存图片
- 4selenium爬取招聘数据并存入MySQL_selenium获取table的数据插入数据库
- 5Unity 入门笔记 - 07(完) - 菜单&手机端&静态类&生成游戏_unity mobile 开始菜单
- 6建立最简单的repo服务器实例讲解
- 7SpringCloud实用篇6——elasticsearch搜索功能_windows elasticsearch分词搜索集成到springcloud项目中
- 8windows安装hadoop教程_hadoop window下载
- 9Memcache遍历 获取模糊匹配key对应的记录_memcached get 模糊
- 10【python】零基础从入门到精通(四)
动手学深度学习(1)—— 基础知识
赞
踩
一、基本概念
1.1 关键组件
机器学习的组件
- 我们可以学习的数据(data)
- 如何转换数据的模型(model)
- ⼀个⽬标函数(objective function),⽤来量化模型的有效性
- 调整模型参数以优化⽬标函数的算法(algorithm)
数据
每个数据集由⼀个个样本(example, sample)组成,⼤多时候,它们遵循独⽴同分布(independently and identically distributed, )。样本有时也叫做数据点
(data point)或者数据实例(data instance),通常每个样本由⼀组称为特征(features,或协变量(covariates))的属性组成。机器学习模型会根据这些属性进⾏预测。在上⾯的监督学习问题中,要预测的是⼀个特殊的属性,它被称为标签(label,或⽬标(target))
当每个样本的特征类别数量都是相同的时候,其特征向量是固定⻓度的,这个⻓度被称为数据的维数(dimensionality)。
模型
深度学习与经典⽅法的区别主要在于:前者关注的功能强⼤的模型,这些模型由神经⽹络错综复杂的交织在⼀起,包含层层数据转换,因此被称为深度学习(deep learning)。
目标函数
我们需要定义模型的优劣程度的度量,这个度量在⼤多数情况是“可优化”的,我们称之为⽬标函数(objective function)。我们通常定义⼀个⽬标函数,并希望优化它到最低点。因为越低越好,所以这些函数有时被称为损失函数(loss function,或cost function)。
当任务在试图预测数值时,最常⻅的损失函数是平⽅误差(squared error),即预测值与实际值之差的平⽅。当试图解决分类问题时,最常⻅的⽬标函数是最⼩化错误率,即预测与实际情况不符的样本⽐例。
通常,损失函数是根据模型参数定义的,并取决于数据集。在⼀个数据集上,我们通过最⼩化总损失来学习模型参数的最佳值。该数据集由⼀些为训练⽽收集的样本组成,称为训练数据集(training dataset,或称为训练集(training set))。然⽽,在训练数据上表现良好的模型,并不⼀定在“新数据集”上有同样的效能,这⾥的“新数据集”通常称为测试数据集(test dataset,或称为测试集(test set))。
综上所述,我们通常将可⽤数据集分成两部分:训练数据集⽤于拟合模型参数,测试数据集⽤于评估拟合的模型。当⼀个模型在训练集上表现良好,但不能推
⼴到测试集时,我们说这个模型是“过拟合”(overfitting)的。
优化算法
我们接下来就需要⼀种算法,它能够搜索出最佳参数,以最⼩化损失函数。深度学习中,⼤多流⾏的优化算法通常基于⼀种基本⽅法‒梯度下降(gradient descent)。简⽽⾔之,在每个步骤中,梯度下降法都会检查每个参数,看看如果你仅对该参数进⾏少量变动,训练集损失会朝哪个⽅向移动。然后,它在可以减少损失的⽅向上优化参数。
1.2 各种机器学习问题
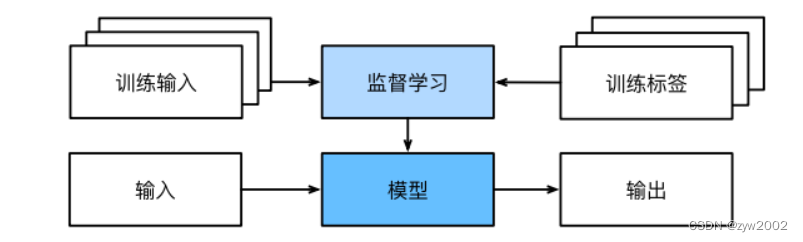
监督学习
监督学习(supervised learning)擅⻓在 “给定输⼊特征” 的情况下预测标签。每个“特征-标签”对都称为⼀个样本(example)。有时,即使标签是未知的,样本也可以指代输⼊特征。我们的⽬标是⽣成⼀个模型,能够将任何输⼊特征映射到标签,即预测。
监督学习之所以发挥作⽤,是因为在训练参数时,我们为模型提供了⼀个数据集,其中每个样本都有真实的标签。
-
回归
标签,是⼀个数值。当标签取任意数值时,我们称之为回归问题。我们的⽬标是⽣成⼀个模型,它的预测⾮常接近实际标签值。
-
分类
在分类问题中,我们希望模型能够预测样本属于哪个类别(category,正式称为类(class))。给定⼀个样本特征,我们的模型为每个可能的类分配⼀个概率。当我们有两个以上的类别时,我们把这个问题称为多元分类(multiclass classification)问题。分类问题的常⻅损失函数被称为交叉熵(cross-entropy)
在回归中,我们训练⼀个回归函数来输出⼀个数值;⽽在分类中,我们训练⼀个分类器,它的输出即为预测的类别。
-
标记问题
学习预测不相互排斥的类别的问题称为多标签分类(multi-label classification)。
-
搜索
搜索结果的排序也⼗分重要,我们的学习算法需要输出有序的元素⼦集。
-
推荐系统
另⼀类与搜索和排名相关的问题是推荐系统(recommender system),它的⽬标是向特定⽤⼾进⾏“个性化”推荐。
-
序列学习
序列学习需要摄取输⼊序列或预测输出序列,或两者兼⽽有之。具体来说,输⼊和输出都是可变⻓度的序列
无监督学习
我们称这类数据中不含有“⽬标”的机器学习问题为⽆监督学习(unsupervised learning)
- 聚类(clustering)问题: 在没有标签的情况下对数据进行分类。
- 主成分分析(principal component analysis)问题:找到少量的参数来准确地捕捉数据的线性相关属性。
- 因果关系(causality)和概率图模型(probabilistic graphical models)问题:我们能否描述观察到的许多数据的根本原因。
- ⽣成对抗性⽹络(generative adversarial networks):为我们提供⼀种合成数据的⽅法,甚⾄像图像和⾳频这样复杂的⾮结构化数据
强化学习
强化学习是指使用机器学习开发与环境交互并采取行动。
在强化学习问题中,agent在⼀系列的时间步骤上与环境交互。在每个特定时间点,agent从环境接收⼀些观察(observation),并且必须选择⼀个动作(action),然后通过某种机制(有时称为执⾏器)将其传输回环境,最后agent从环境中获得奖励(reward)。
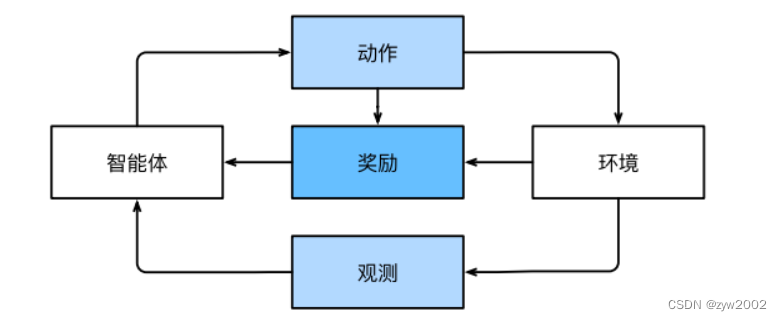
强化学习和环境之间的相互作用
但在强化学习中,我们并不假设环境告诉agent每个观测的最优动作。⼀般来说,agent只是得到⼀些奖励。此外,环境甚⾄可能不会告诉我们是哪些⾏为导致了奖励。
强化学习者必须处理学分分配(credit assignment)问题:决定哪些⾏为是值得奖励的,哪些⾏为是需要惩罚的。
强化学习可能还必须处理部分可观测性问题。也就是说,当前的观察结果可能⽆法阐述有关当前状态的所有信息。
强化学习agent必须不断地做出选择:是应该利⽤当前最好的策略,还是探索新的策略空间(放弃⼀些短期回报来换取知识)。
agent的动作会影响后续的观察,⽽奖励只与所选的动作相对应。环境可以是完整观察到的,也可以是部分观察到的。
当环境可被完全观察到时,我们将强化学习问题称为⻢尔可夫决策过程(markov decision process)。当状态不依赖于之前的操作时,我们称该问题为上下⽂赌博机(contextual bandit problem)。当没有状态,只有⼀组最初未知回报的可⽤动作时,这个问题就是经典的多臂赌博机(multi-armed bandit problem)。
1.3 神经网络的特点
神经网络
- 线性和⾮线性处理单元的交替,通常称为层(layers)。
- 使⽤链式规则(也称为反向传播(backpropagation))⼀次性调整⽹络中的全部参数。
机器学习可以使⽤数据来学习输⼊和输出之间的转换。
深度学习是“深度”的,模型学习了许多“层”的转换,每⼀层提供⼀个层次的表⽰。例如,靠近输⼊的层可以表⽰数据的低级细节,⽽接近分类输出的层可以表⽰⽤于区分的更抽象的概念。
深度学习⽅法中最显著的共同点是使⽤端到端训练。也就是说,与其基于单独调整的组件组装系统,不如构建系统,然后联合调整它们的性能。
二、预备知识
2.1 数据操作
⾸先,我们介绍n维数组,也称为张量(tensor)。深度学习框架⼜⽐Numpy的ndarray多⼀些重要功能:⾸先,GPU很好地⽀持加速计算,⽽NumPy仅⽀持CPU计算;其次,张量类⽀持⾃动微分。这些功能使得张量类更适合深度学习。
入门
⾸先,我们导⼊torch。
import torch
- 1
张量表⽰由⼀个数值组成的数组,这个数组可能有多个维度。具有⼀个轴的张量对应数学上的向量(vector);具有两个轴的张量对应数学上的矩(matrix);具有两个轴以上的张量没有特殊的数学名称。
⾸先,我们可以使⽤ arange 创建⼀个⾏向量 x。这个⾏向量包含以0开始的前12个整数,它们默认创建为整数。也可指定创建类型为浮点数。张量中的每个值都称为张量的 元素(element)。例如,张量 x 中有 12 个元素。除⾮额外指定,新的张量将存储在内存中,并采⽤基于CPU的计算。
x = torch.arange(12)
x
- 1
- 2
tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
- 1
可以通过张量的shape属性来访问张量(沿每个轴的⻓度)的形状。
x.shape
- 1
torch.Size([12])
- 1
如果只想知道张量中元素的总数,即形状的所有元素乘积,可以检查它的⼤⼩(size)
x.numel()
- 1
12
- 1
要想改变⼀个张量的形状⽽不改变元素数量和元素值,可以调⽤reshape函数。
X = x.reshape(3, 4)
X
- 1
- 2
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
- 1
- 2
- 3
我们可以通过-1来调⽤此⾃动计算出维度的功能。即我们可以⽤x.reshape(-1,4)或x.reshape(3,-1)来取代x.reshape(3,4)
有时,我们希望使⽤全0、全1、其他常量,或者从特定分布中随机采样的数字来初始化矩阵。我们可以创建⼀个形状为(2,3,4)的张量,其中所有元素都设置为0。代码如下:
torch.zeros((2, 3, 4))
- 1
tensor([[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]],
[[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]]])
- 1
- 2
- 3
- 4
- 5
- 6
同样,我们可以创建⼀个形状为(2,3,4)的张量,其中所有元素都设置为1。代码如下:
torch.ones((2, 3, 4))
- 1
tensor([[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]],
[[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]]])
- 1
- 2
- 3
- 4
- 5
- 6
以下代码创建⼀个形状为(3,4)的张量。其中的每个元素都从均值为0、标准差为1的标准⾼斯分布(正态分布)中随机采样。
torch.randn(3, 4)
- 1
tensor([[-0.5582, -0.0443, 1.6146, 0.6003],
[-1.7652, 1.3074, 0.5233, 1.4372],
[ 0.2452, 2.2281, 1.3483, 0.1783]])
- 1
- 2
- 3
我们还可以通过提供包含数值的Python列表(或嵌套列表),来为所需张量中的每个元素赋予确定值。在这⾥,最外层的列表对应于轴0,内层的列表对应于轴1。
torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
- 1
tensor([[2, 1, 4, 3],
[1, 2, 3, 4],
[4, 3, 2, 1]])
- 1
- 2
- 3
运算符
对于将两个数组作为输⼊的函数,按元素运算将⼆元运算符应⽤于两个数组中的每对位置对应的元素。对于任意具有相同形状的张量,常⻅的标准算术运算符(+、-、*、/和**)都可以被升级为按元素运算。
x = torch.tensor([1.0, 2, 4, 8])
y = torch.tensor([2, 2, 2, 2])
x + y, x - y, x * y, x / y, x ** y # **运算符是求幂运算
- 1
- 2
- 3
(tensor([ 3., 4., 6., 10.]),
tensor([-1., 0., 2., 6.]),
tensor([ 2., 4., 8., 16.]),
tensor([0.5000, 1.0000, 2.0000, 4.0000]),
tensor([ 1., 4., 16., 64.]))
- 1
- 2
- 3
- 4
- 5
“按元素”⽅式可以应⽤更多的计算,包括像求幂这样的⼀元运算符。
torch.exp(x)
- 1
tensor([2.7183e+00, 7.3891e+00, 5.4598e+01, 2.9810e+03])
- 1
除了按元素计算外,我们还可以执⾏线性代数运算,包括向量点积和矩阵乘法。
我们也可以把多个张量连结(concatenate)在⼀起,把它们端对端地叠起来形成⼀个更⼤的张量。我们只需要提供张量列表,并给出沿哪个轴连结。下⾯的例⼦分别演⽰了当我们沿⾏(轴-0,形状的第⼀个元素)和按列(轴-1,形状的第⼆个元素)连结两个矩阵时,会发⽣什么情况。
X = torch.arange(12, dtype=torch.float32).reshape((3,4))
Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1)
- 1
- 2
- 3
(tensor([[ 0., 1., 2., 3.],
[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.],
[ 2., 1., 4., 3.],
[ 1., 2., 3., 4.],
[ 4., 3., 2., 1.]]),
tensor([[ 0., 1., 2., 3., 2., 1., 4., 3.],
[ 4., 5., 6., 7., 1., 2., 3., 4.],
[ 8., 9., 10., 11., 4., 3., 2., 1.]]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
有时,我们想通过逻辑运算符构建⼆元张量。以X == Y为例:对于每个位置,如果X和Y在该位置相等,则新张量中相应项的值为1。这意味着逻辑语句X == Y在该位置处为真,否则该位置为0。
X == Y
- 1
tensor([[False, True, False, True],
[False, False, False, False],
[False, False, False, False]])
- 1
- 2
- 3
对张量中的所有元素进⾏求和,会产⽣⼀个单元素张量。
X.sum()
- 1
tensor(66.)
- 1
广播机制
在某些情况下,即使形状不同,我们仍然可以通过调⽤ ⼴播机制(broadcasting mechanism)来执⾏按元素操作。
这种机制的⼯作⽅式如下:⾸先,通过适当复制元素来扩展⼀个或两个数组,以便在转换之后,两个张量具有相同的形状。其次,对⽣成的数组执⾏按元素操作。
a = torch.arange(3).reshape((3, 1))
b = torch.arange(2).reshape((1, 2))
a,b
- 1
- 2
- 3
(tensor([[0],
[1],
[2]]),
tensor([[0, 1]]))
- 1
- 2
- 3
- 4
由于a和b分别是3 × 1和1 × 2矩阵,如果让它们相加,它们的形状不匹配。我们将两个矩阵⼴播为⼀个更⼤的3 × 2矩阵,如下所⽰:矩阵a将复制列,矩阵b将复制⾏,然后再按元素相加。
a + b
- 1
tensor([[0, 1],
[1, 2],
[2, 3]])
- 1
- 2
- 3
索引和切片
与任何Python数组⼀样:第⼀个元素的索引是0,最后⼀个元素索引是-1;可以指定范围以包含第⼀个元素和最后⼀个之前的元素。
如下所⽰,我们可以⽤[-1]选择最后⼀个元素,可以⽤[1:3]选择第⼆个和第三个元素:
X[-1], X[1:3]
- 1
(tensor([ 8., 9., 10., 11.]),
tensor([[ 4., 5., 6., 7.],
[ 8., 9., 10., 11.]]))
- 1
- 2
- 3
除读取外,我们还可以通过指定索引来将元素写⼊矩阵。
X[1, 2] = 9
X
- 1
- 2
tensor([[ 0., 1., 2., 3.],
[ 4., 5., 9., 7.],
[ 8., 9., 10., 11.]])
- 1
- 2
- 3
如果我们想为多个元素赋值相同的值,我们只需要索引所有元素,然后为它们赋值。例如,[0:2, :] 访问第1⾏和第2⾏,其中“:”代表沿轴1(列)的所有元素。虽然我们讨论的是矩阵的索引,但这也适⽤于向量和超过2个维度的张量。
X[0:2, :] = 12
X
- 1
- 2
tensor([[12., 12., 12., 12.],
[12., 12., 12., 12.],
[ 8., 9., 10., 11.]])
- 1
- 2
- 3
节省内存
运⾏⼀些操作可能会导致为新结果分配内存。例如,如果我们⽤Y = X + Y,我们将取消引⽤Y指向的张量,⽽是指向新分配的内存处的张量。
在下⾯的例⼦中,我们⽤Python的id()函数演⽰了这⼀点,它给我们提供了内存中引⽤对象的确切地址。运⾏Y = Y + X后,我们会发现id(Y)指向另⼀个位置。这是因为Python⾸先计算Y + X,为结果分配新的内存,然后使Y指向内存中的这个新位置。
before = id(Y)
Y = Y + X
id(Y) == before
- 1
- 2
- 3
False
- 1
我们可以使⽤切⽚表⽰法将操作的结果分配给先前分配的数组,例如Y[:] = <expression>。为了说明这⼀点,我们⾸先创建⼀个新的矩阵Z,其形状与另⼀个Y相同,使⽤zeros_like来分配⼀个全0的块。
Z = torch.zeros_like(Y)
print('id(Z):', id(Z))
Z[:] = X + Y
print('id(Z):', id(Z))
- 1
- 2
- 3
- 4
id(Z): 140316199714544
id(Z): 140316199714544
- 1
- 2
如果在后续计算中没有重复使⽤X,我们也可以使⽤X[:] = X + Y或X += Y来减少操作的内存开销。
before = id(X)
X += Y
id(X) == before
- 1
- 2
- 3
True
- 1
转换为其他python 对象
将深度学习框架定义的张量转换为NumPy张量(ndarray)很容易,反之也同样容易。torch张量和numpy数组将共享它们的底层内存,就地操作更改⼀个张量也会同时更改另⼀个张量。
A = X.numpy()
B = torch.tensor(A)
type(A), type(B)
- 1
- 2
- 3
(numpy.ndarray, torch.Tensor)
- 1
要将⼤⼩为1的张量转换为Python标量,我们可以调⽤item函数或Python的内置函数。
a = torch.tensor([3.5])
a, a.item(), float(a), int(a)
- 1
- 2
(tensor([3.5000]), 3.5, 3.5, 3)
- 1
2.2 数据预处理
读取数据集
举⼀个例⼦,我们⾸先创建⼀个⼈⼯数据集,并存储在CSV(逗号分隔值)⽂件 ../data/house_tiny.csv中。以其他格式存储的数据也可以通过类似的⽅式进⾏处理。下⾯我们将数据集按⾏写⼊CSV⽂件中。
import os
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms,Alley,Price\n') # 列名
f.write('NA,Pave,127500\n') # 每⾏表⽰⼀个数据样本
f.write('2,NA,106000\n')
f.write('4,NA,178100\n')
f.write('NA,NA,140000\n')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
要从创建的CSV⽂件中加载原始数据集,我们导⼊pandas包并调⽤read_csv函数。该数据集有四⾏三列。其中每⾏描述了房间数量(“NumRooms”)、巷⼦类型(“Alley”)和房屋价格(“Price”)。
# 如果没有安装pandas,只需取消对以下⾏的注释来安装pandas
# !pip install pandas
import pandas as pd
data = pd.read_csv(data_file)
print(data)
- 1
- 2
- 3
- 4
- 5
NumRooms Alley Price
0 NaN Pave 127500
1 2.0 NaN 106000
2 4.0 NaN 178100
3 NaN NaN 140000
- 1
- 2
- 3
- 4
- 5
处理缺失的数据
注意,“NaN”项代表缺失值。为了处理缺失的数据,典型的⽅法包括插值法和删除法,其中插值法⽤⼀个替
代值弥补缺失值,⽽删除法则直接忽略缺失值。在这⾥,我们将考虑插值法。
通过位置索引iloc,我们将data分成inputs和outputs,其中前者为data的前两列,⽽后者为data的最后⼀列。对于inputs中缺少的数值,我们⽤同⼀列的均值替换“NaN”项。
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean())
print(inputs)
- 1
- 2
- 3
NumRooms Alley
0 3.0 Pave
1 2.0 NaN
2 4.0 NaN
3 3.0 NaN
- 1
- 2
- 3
- 4
- 5
对于inputs中的类别值或离散值,我们将“NaN”视为⼀个类别。由于“巷⼦类型”(“Alley”)列只接受两种类型的类别值“Pave”和“NaN”,pandas可以⾃动将此列转换为两列“Alley_Pave”和“Alley_nan”。巷⼦类型为“Pave”的⾏会将“Alley_Pave”的值设置为1,“Alley_nan”的值设置为0。缺少巷⼦类型的⾏会将“Alley_Pave”和“Alley_nan”分别设置为0和1。
inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)
- 1
- 2
NumRooms Alley_Pave Alley_nan
0 3.0 1 0
1 2.0 0 1
2 4.0 0 1
3 3.0 0 1
- 1
- 2
- 3
- 4
- 5
现在inputs和outputs中的所有条⽬都是数值类型,它们可以转换为张量格式。
import torch
X, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
X, y
- 1
- 2
- 3
- 4
(tensor([[3., 1., 0.],
[2., 0., 1.],
[4., 0., 1.],
[3., 0., 1.]], dtype=torch.float64),
tensor([127500, 106000, 178100, 140000]))
- 1
- 2
- 3
- 4
- 5
2.3 线性代数
标量
标量由只有一个元素的张量表示。 在下面的代码中,我们实例化两个标量,并执行一些熟悉的算术运算,即加法、乘法、除法和指数。
import torch
x = torch.tensor(3.0)
y = torch.tensor(2.0)
x + y, x * y, x / y, x**y
- 1
- 2
- 3
- 4
- 5
- 6
(tensor(5.), tensor(6.), tensor(1.5000), tensor(9.))
- 1
向量
我们通过一维张量处理向量。
x = torch.arange(4)
x
- 1
- 2
tensor([0, 1, 2, 3])
- 1
在代码中,我们通过张量的索引来访问任一元素。
x[3]
- 1
tensor(3)
- 1
我们可以通过调用Python的内置len()函数来访问张量的长度。
len(x)
- 1
4
- 1
当用张量表示一个向量(只有一个轴)时,我们也可以通过.shape属性访问向量的长度。 形状(shape)是一个元素组,列出了张量沿每个轴的长度(维数)。 对于只有一个轴的张量,形状只有一个元素。
x.shape
- 1
torch.Size([4])
- 1
矩阵
正如向量将标量从零阶推广到一阶,矩阵将向量从一阶推广到二阶。
A = torch.arange(20).reshape(5, 4)
A
- 1
- 2
tensor([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11],
[12, 13, 14, 15],
[16, 17, 18, 19]])
- 1
- 2
- 3
- 4
- 5
现在我们在代码中访问矩阵的转置
A.T
- 1
tensor([[ 0, 4, 8, 12, 16],
[ 1, 5, 9, 13, 17],
[ 2, 6, 10, 14, 18],
[ 3, 7, 11, 15, 19]])
- 1
- 2
- 3
- 4
张量
张量(本小节中的“张量”指代数对象)为我们提供了描述具有任意数量轴的n
维数组的通用方法。
X = torch.arange(24).reshape(2, 3, 4)
X
- 1
- 2
tensor([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]]])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
具体而言, 两个矩阵的按元素乘法称为Hadamard积(Hadamard product)(数学符号 ⊙ \odot ⊙ )。对 于矩阵 B ∈ R m × n \mathbf{B} \in \mathbb{R}^{m \times n} B∈Rm×n 其中第 i i i行和第 j j j列的元素是 b i j b_{i j } bij 。矩阵 A \mathbf{A} A和 B \mathbf{B} B的 Hadamard积为:
A
⊙
B
=
[
a
11
b
11
a
12
b
12
…
a
1
n
b
1
n
a
21
b
21
a
22
b
22
…
a
2
n
b
2
n
⋮
⋮
⋱
⋮
a
m
1
b
m
1
a
m
2
b
m
2
…
a
m
n
b
m
n
]
\mathbf{A} \odot \mathbf{B}=\left[
A * B
- 1
tensor([[ 0., 1., 4., 9.],
[ 16., 25., 36., 49.],
[ 64., 81., 100., 121.],
[144., 169., 196., 225.],
[256., 289., 324., 361.]])
- 1
- 2
- 3
- 4
- 5
将张量乘以或加上一个标量不会改变张量的形状,其中张量的每个元素都将与标量相加或相乘。
默认情况下,调用求和函数会沿所有的轴降低张量的维度,使它变为一个标量。
A.shape, A.sum()
- 1
(torch.Size([5, 4]), tensor(190.))
- 1
我们还可以指定张量沿哪一个轴来通过求和降低维度。 以矩阵为例,为了通过求和所有行的元素来降维(轴0),我们可以在调用函数时指定axis=0
。 由于输入矩阵沿0轴降维以生成输出向量,因此输入轴0的维数在输出形状中消失。
A_sum_axis0 = A.sum(axis=0)
A_sum_axis0, A_sum_axis0.shape
- 1
- 2
(tensor([40., 45., 50., 55.]), torch.Size([4]))
- 1
指定axis=1将通过汇总所有列的元素降维(轴1)。因此,输入轴1的维数在输出形状中消失。
A_sum_axis1 = A.sum(axis=1)
A_sum_axis1, A_sum_axis1.shape
- 1
- 2
(tensor([ 6., 22., 38., 54., 70.]), torch.Size([5]))
- 1
沿着行和列对矩阵求和,等价于对矩阵的所有元素进行求和。
A.sum(axis=[0, 1]) # SameasA.sum()
- 1
tensor(190.)
- 1
我们通过将总和除以元素总数来计算平均值。 在代码中,我们可以调用函数来计算任意形状张量的平均值。
A.mean(), A.sum() / A.numel()
- 1
(tensor(9.5000), tensor(9.5000))
- 1
同样,计算平均值的函数也可以沿指定轴降低张量的维度。
A.mean(axis=0), A.sum(axis=0) / A.shape[0]
- 1
有时在调用函数来计算总和或均值时保持轴数不变会很有用。
sum_A = A.sum(axis=1, keepdims=True)
sum_A
- 1
- 2
由于sum_A在对每行进行求和后仍保持两个轴,我们可以通过广播将A除以sum_A
A / sum_A
- 1
tensor([[0.0000, 0.1667, 0.3333, 0.5000],
[0.1818, 0.2273, 0.2727, 0.3182],
[0.2105, 0.2368, 0.2632, 0.2895],
[0.2222, 0.2407, 0.2593, 0.2778],
[0.2286, 0.2429, 0.2571, 0.2714]])
- 1
- 2
- 3
- 4
- 5
如果我们想沿某个轴计算A元素的累积总和, 比如axis=0(按行计算),我们可以调用cumsum函数。 此函数不会沿任何轴降低输入张量的维度。
A.cumsum(axis=0)
- 1
tensor([[ 0., 1., 2., 3.],
[ 4., 6., 8., 10.],
[12., 15., 18., 21.],
[24., 28., 32., 36.],
[40., 45., 50., 55.]])
- 1
- 2
- 3
- 4
- 5
点积
给定两个向量 x , y ∈ R d \mathbf{x}, \mathbf{y} \in \mathbb{R}^d x,y∈Rd, 它们的点积 (dot product) x ⊤ y \mathbf{x}^{\top} \mathbf{y} x⊤y (或 ⟨ x , y ⟩ \langle\mathbf{x}, \mathbf{y}\rangle ⟨x,y⟩ ) 是相同位置的按元素乘积的和:
x ⊤ y = ∑ i = 1 d x i y i ∘ \mathbf{x}^{\top} \mathbf{y}=\sum_{i=1}^d x_i y_{i \circ} x⊤y=i=1∑dxiyi∘
注意,我们可以通过执行按元素乘法,然后进行求和来表示两个向量的点积:
torch.sum(x * y)
- 1
tensor(6.)
- 1
矩阵-向量积
当我们为矩阵A和向量x调用torch.mv(A, x)时,会执行矩阵-向量积。 注意,A的列维数(沿轴1的长度)必须与x的维数(其长度)相同。
A.shape, x.shape, torch.mv(A, x)
- 1
(torch.Size([5, 4]), torch.Size([4]), tensor([ 14., 38., 62., 86., 110.]))
- 1
矩阵-矩阵乘法
B = torch.ones(4, 3)
torch.mm(A, B)
- 1
- 2
tensor([[ 6., 6., 6.],
[22., 22., 22.],
[38., 38., 38.],
[54., 54., 54.],
[70., 70., 70.]])
- 1
- 2
- 3
- 4
- 5
2.4 微积分
我们可以将拟合模型的任务分解为两个关键问题:
- 优化(optimization):⽤模型拟合观测数据的过程
- 泛化(generalization):数学原理和实践者的智慧,能够指导我们⽣成出有效性超出⽤于训练的数据集本⾝的模型。
在深度学习中,我们通常选择对于模型参数可微的损失函数。
- 导数:
f ′ ( x ) = lim h → 0 f ( x + h ) − f ( x ) h f^{\prime}(x)=\lim _{h \rightarrow 0} \frac{f(x+h)-f(x)}{h} f′(x)=h→0limhf(x+h)−f(x)
- 偏导数:
∂ y ∂ x i = lim h → 0 f ( x 1 , … , x i − 1 , x i + h , x i + 1 , … , x n ) − f ( x 1 , … , x i , … , x n ) h \frac{\partial y}{\partial x_i}=\lim _{h \rightarrow 0} \frac{f\left(x_1, \ldots, x_{i-1}, x_i+h, x_{i+1}, \ldots, x_n\right)-f\left(x_1, \ldots, x_i, \ldots, x_n\right)}{h} ∂xi∂y=h→0limhf(x1,…,xi−1,xi+h,xi+1,…,xn)−f(x1,…,xi,…,xn)
- 梯度
连结⼀个多元函数对其所有变量的偏导数,以得到该函数的梯度(gradient)向量。
∇ x f ( x ) = [ ∂ f ( x ) ∂ x 1 , ∂ f ( x ) ∂ x 2 , … , ∂ f ( x ) ∂ x n ] ⊤ \nabla_{\mathbf{x}} f(\mathbf{x})=\left[\frac{\partial f(\mathbf{x})}{\partial x_1}, \frac{\partial f(\mathbf{x})}{\partial x_2}, \ldots, \frac{\partial f(\mathbf{x})}{\partial x_n}\right]^{\top} ∇xf(x)=[∂x1∂f(x),∂x2∂f(x),…,∂xn∂f(x)]⊤
- 链式法则
d y d x i = d y d u 1 d u 1 d x i + d y d u 2 d u 2 d x i + ⋯ + d y d u m d u m d x i \frac{d y}{d x_i}=\frac{d y}{d u_1} \frac{d u_1}{d x_i}+\frac{d y}{d u_2} \frac{d u_2}{d x_i}+\cdots+\frac{d y}{d u_m} \frac{d u_m}{d x_i} dxidy=du1dydxidu1+du2dydxidu2+⋯+dumdydxidum
2.5 自动微分
深度学习框架通过⾃动计算导数,即⾃动微分(automatic differentiation)来加快求导。实际中,根据我们设计的模型,系统会构建⼀个计算(computational graph),来跟踪计算是哪些数据通过哪些操作组合起来产⽣输出。⾃动微分使系统能够随后反向传播梯度。这⾥,反向传播(backpropagate)意味着跟踪整个计算图,填充关于每个参数的偏导数。
例子
对于函数 y = 2 x ⊤ x y=2 \mathbf{x}^{\top} \mathbf{x} y=2x⊤x 关于列向量 x \mathbf{x} x 求导。⾸先,我们创建变量x并为其分配⼀个初始值。
import torch
x = torch.arange(4.0)
x
- 1
- 2
- 3
tensor([0., 1., 2., 3.])
- 1
在我们计算y关于x的梯度之前,我们需要⼀个地⽅来存储梯度。重要的是,我们不会在每次对⼀个参数求导时都分配新的内存。因为我们经常会成千上万次地更新相同的参数,每次都分配新的内存可能很快就会将内存耗尽。注意,⼀个标量函数关于向量x的梯度是向量,并且与x具有相同的形状。
x.requires_grad_(True) # 等价于x=torch.arange(4.0,requires_grad=True)
x.grad # 默认值是None
- 1
- 2
现在让我们计算y。
y = 2 * torch.dot(x, x)
y
- 1
- 2
tensor(28., grad_fn=<MulBackward0>)
- 1
接下来,我们通过调⽤反向传播函数来⾃动计算y关于x每个分量的梯度,并打印这些梯度。
y.backward()
x.grad
- 1
- 2
tensor([ 0., 4., 8., 12.])
- 1
现在让我们计算x的另⼀个函数。
# 在默认情况下,PyTorch会累积梯度,我们需要清除之前的值
x.grad.zero_()
y = x.sum()
y.backward()
x.grad
- 1
- 2
- 3
- 4
- 5
tensor([1., 1., 1., 1.])
- 1
非标量变量的反向传播
当y不是标量时,向量y关于向量x的导数的最⾃然解释是⼀个矩阵。对于⾼阶和⾼维的y和x,求导的结果可以是⼀个⾼阶张量。
当我们调⽤向量的反向计算时,我们通常会试图计算⼀批训练样本中每个组成部分的损失函数的导数。这⾥,我们的⽬的不是计算微分矩阵,⽽是单独计算批量中每个样本的偏导数之和。
# 对非标量调用backward需要传入一个gradient参数,该参数指定微分函数关于self的梯度。
# 在我们的例子中,我们只想求偏导数的和,所以传递一个1的梯度是合适的
x.grad.zero_()
y = x * x
# 等价于y.backward(torch.ones(len(x)))
y.sum().backward()
x.grad
- 1
- 2
- 3
- 4
- 5
- 6
- 7
tensor([0., 2., 4., 6.])
- 1
分离计算
有时,我们希望将某些计算移动到记录的计算图之外。 例如,假设y是作为x的函数计算的,而z则是作为y和x的函数计算的。 想象一下,我们想计算z关于x的梯度,但由于某种原因,我们希望将y视为一个常数, 并且只考虑到x在y被计算后发挥的作用。
在这里,我们可以分离y来返回一个新变量u,该变量与y具有相同的值, 但丢弃计算图中如何计算y的任何信息。 换句话说,梯度不会向后流经u到x。 因此,下面的反向传播函数计算z=u*x关于x的偏导数,同时将u作为常数处理, 而不是z=x*x*x关于x的偏导数。
x.grad.zero_()
y = x * x
u = y.detach()
z = u * x
z.sum().backward()
x.grad == u
- 1
- 2
- 3
- 4
- 5
- 6
- 7
tensor([True, True, True, True])
- 1
Python 控制流的梯度计算
使用自动微分的一个好处是: 即使构建函数的计算图需要通过Python控制流(例如,条件、循环或任意函数调用),我们仍然可以计算得到的变量的梯度。 在下面的代码中,while循环的迭代次数和if语句的结果都取决于输入a的值。
def f(a):
b = a * 2
while b.norm() < 1000:
b = b * 2
if b.sum() > 0:
c = b
else:
c = 100 * b
return c
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
让我们计算梯度。
a = torch.randn(size=(), requires_grad=True)
d = f(a)
d.backward()
- 1
- 2
- 3
我们现在可以分析上面定义的f函数。 请注意,它在其输入a中是分段线性的。 换言之,对于任何a,存在某个常量标量k,使得f(a)=k*a,其中k
的值取决于输入a。 因此,我们可以用d/a验证梯度是否正确。
a.grad == d / a
- 1
tensor(True)
- 1
2.6 概率
首先,我们导入必要的软件包。
%matplotlib inline
import torch
from torch.distributions import multinomial
from d2l import torch as d2l
- 1
- 2
- 3
- 4
为了抽取一个样本,即掷骰子,我们只需传入一个概率向量。 输出是另一个相同长度的向量:它在索引i处的值是采样结果中i出现的次数。
fair_probs = torch.ones([6]) / 6
# 将结果存储为32位浮点数以进行除法
counts = multinomial.Multinomial(1000, fair_probs).sample()
counts / 1000 # 相对频率作为估计值
- 1
- 2
- 3
- 4
tensor([0.1640, 0.1770, 0.1740, 0.1880, 0.1560, 0.1410])
- 1

