
- 1Sql server 2008忘记sa登录密码重置_sqlserver2008忘记sa密码
- 2flink的面试题和答案_flink 面试题
- 335岁程序员还能找到工作吗?60%选择转岗项目经理!
- 4C语言经典题目:求0-10000之间的水仙花数,并将这个数输出,打印_一万以内的水仙花数
- 5MySQL基础之触发器,函数,存储过程_mysql触发器调用存储过程
- 6xcode 出现Verify that your build process has compiled binaries and copied in bundled resources.的问题记录一下
- 7关于Web前端渗透-ZAP的基本介绍_zed attack proxy
- 8神器!
- 9hw技战法整理参考
- 10深入解析力扣157题:用Read4高效读取N个字符(多种解法与详细图解)_力扣文件读取题
ODPS SQL优化总结
赞
踩

ODPS(Open Data Processing Service)是一个海量数据处理平台,基于阿里巴巴自主研发的分布式操作系统(飞天)开发,是公司云计算整体解决方案中最核心的主力产品之一。本文结合作者多年的数仓开发经验,结合ODPS平台分享数据仓库中的SQL优化经验。
背景
数据仓库,是一个面向主题、集成的、随时间变化的、信息本身相对稳定的数据集合。数据仓库从Oracle(单机、RAC),到MPP(Green plum),到Hadoop(Hive、Tez、Sprak),再到批流一体Flink/Blink、数据湖等,SQL都是其主流的数据处理工具。海量数据下的高效数据流转,是数据同学必须直面的一个挑战。本文结合阿里自研的ODPS平台,从自身工作出发,总结SQL的一些优化技巧。
基础知识
▐ Hive SQL的执行过程
Hive SQL的编译到执行,可以参考《Hive SQL的编译过程》,里面详细介绍了神奇的SQL如何在大数据平台编译与执行的过程。
《Hive SQL的编译过程》地址:https://tech.meituan.com/2014/02/12/hive-sql-to-mapreduce.html
▐ SQL的基础语法
大佬们写过很多SQL基础入门的文章,也可以参考Hive SQL的官方文档。
Hive SQL的官方文档地址:https://cwiki.apache.org/confluence/display/Hive//GettingStarted#GettingStarted-SQLOperations
经验总结与沉淀
▐ SQL的一些使用技巧
null
我们在进行=/<>/in/not in等判断时,null会不包含在这些判断条件中,所以在对null的处理时可以使用nvl或者coalesce函数对null进行默认转换。
select *
在数据开发或者线上任务时,尽可能提前对列进行剪裁,即使是全表字段都需要,也尽可能的把字段都写出来(如果实在觉得麻烦,可以使用数据地图的生成select功能),一是减少了数据运算中不必要的数据读取,二是避免后期因为原表或者目标表字段增加,导致的任务报错。
multi insert
读取同一张表,但是因为粒度不同,需要插入多张表时,可以考虑使用 from () tab insert overwrite A insert overwrite B 的方式,减少资源的浪费。当然,有些团队的数仓开发规范中会规定一个任务不能有两个目标表,具体情况可以视情况尽可能复用公共数据,如通过临时表的方式临时存储这部分逻辑。
分区限定
ODPS表大部分都是分区表,分区表又会根据业务规则分为增量表、全量表、快照表等。所以在做简单查询,或者数据探查时,一定要养成习惯先限定分区ds。经常会在jobhistory中看到很多好资源的任务都是因为分区限定不合理或者没有限定分区导致的。
limit的使用
临时查询或者数据探查时,养成习惯加上limit,会快速的查询出你想要的数据,且消耗更少的资源。
UDF函数的使用
尽可能把UDF的使用下沉到第一层子查询中,效率会有很大的提升。
行转列、列转行
collect_set 、lateral view函数可以实现行转列或者列转行的功能,好多大佬也都写过类似的ATA,可以参考。
窗口函数的使用
可以通过 row_number()/rank() over(partition by order by )的方式实现数据按照某个字段分组的排序,也可以通过 max(struct())的方式实现。
关联
左关联、内关联、右关联、left anti join 、left semi join等,可以实现不同情况下的多表关联。关联字段要确保字段类型的一致。
笛卡尔积的应用
有时会存在把一行数据翻N倍的诉求,这时候可以考虑自己创建一个维表,通过笛卡尔积操作;同时也可以通过LATERAL VIEW POSEXPLODE(split(REGEXP_REPLACE(space(end_num -start_num+1),' ','1,'),',')) t AS pos ,val的方式。
▐ 数据倾斜问题
大表关联小表
大表关联小表出现倾斜时,可以使用mapjoin的hint(/*+mapjoin(b)*/)。
同时可适当调整mapjoin中小表的内存大小:
set odps.sql.mapjoin.memory.max=512;默认512,单位M,[128,2048]之间调整。
大表关联大表
一种情况,大表中存在热点key:可以考虑对大表进行拆分,根据join的key,把热点的数据拆出来走mapjoin,其余的考虑普通join即可。当然也有skewjoin的hint可以参考使用。
另一种情况,大表中不存在热点key:可以考虑在分区的基础上加上桶,对关联字段进行分桶,减少shuffle的数据量。
count distinct
常见的数据倾斜还有一种情况是因为使用了count distinct,这种情况可以考虑使用group by先进行数据去重,再count。
odps新特性
可以关注MaxCompute(ODPS2.0)重装上阵系列文章,很多心得特性对于我们的性能优化有很大的帮助。
▐ 常用的参数设置
常用的调整无外乎调整map、join、reduce的个数,map、join、reduce的内存大小。本文以ODPS的参数设置为例,参数可能因版本不同而略有差异。
Map设置
set odps.sql.mapper.cpu=100
作用:设置处理Map Task每个Instance的CPU数目,默认为100,在[50,800]之间调整。
场景:某些任务如果特别耗计算资源的话,可以适当调整Cpu数目。对于大多数Sql任务来说,一般不需要调整Cpu个数的。
set odps.sql.mapper.memory=1024
作用:设定Map Task每个Instance的Memory大小,单位M,默认1024M,在[256,12288]之间调整。
场景:当Map阶段的Instance有Writer Dumps时,可以适当的增加内存大小,减少Dumps所花的时间。
set odps.sql.mapper.merge.limit.size=64
作用:设定控制文件被合并的最大阈值,单位M,默认64M,在[0,Integer.MAX_VALUE]之间调整。
场景:当Map端每个Instance读入的数据量不均匀时,可以通过设置这个变量值进行小文件的合并,使得每个Instance的读入文件均匀。一般会和odps.sql.mapper.split.size这个参数结合使用。
set odps.sql.mapper.split.size=256
作用:设定一个Map的最大数据输入量,可以通过设置这个变量达到对Map端输入的控制,单位M,默认256M,在[1,Integer.MAX_VALUE]之间调整。
场景:当每个Map Instance处理的数据量比较大,时间比较长,并且没有发生长尾时,可以适当调小这个参数。如果有发生长尾,则结合odps.sql.mapper.merge.limit.size这个参数设置每个Map的输入数量。
Join设置
set odps.sql.joiner.instances=-1
作用: 设定Join Task的Instance数量,默认为-1,在[0,2000]之间调整。不走HBO优化时,ODPS能够自动设定的最大值为1111,手动设定的最大值为2000,走HBO时可以超过2000。
场景:每个Join Instance处理的数据量比较大,耗时较长,没有发生长尾,可以考虑增大使用这个参数。
set odps.sql.joiner.cpu=100
作用: 设定Join Task每个Instance的CPU数目,默认为100,在[50,800]之间调整。
场景:某些任务如果特别耗计算资源的话,可以适当调整CPU数目。对于大多数SQL任务来说,一般不需要调整CPU。
set odps.sql.joiner.memory=1024
作用:设定Join Task每个Instance的Memory大小,单位为M,默认为1024M,在[256,12288]之间调整。
场景:当Join阶段的Instance有Writer Dumps时,可以适当的增加内存大小,减少Dumps所花的时间。
作业跑完后,可以在 summary 中搜索 writer dumps 字样来判断是否产生 Writer Dumps。
Reduce设置
set odps.sql.reducer.instances=-1
作用: 设定Reduce Task的Instance数量,手动设置区间在[1,99999]之间调整。不走HBO优化时,ODPS能够自动设定的最大值为1111,手动设定的最大值为99999,走HBO优化时可以超过99999。
场景:每个Join Instance处理的数据量比较大,耗时较长,没有发生长尾,可以考虑增大使用这个参数。
set odps.sql.reducer.cpu=100
作用:设定处理Reduce Task每个Instance的Cpu数目,默认为100,在[50,800]之间调整。
场景:某些任务如果特别耗计算资源的话,可以适当调整Cpu数目。对于大多数Sql任务来说,一般不需要调整Cpu。
set odps.sql.reducer.memory=1024
作用:设定Reduce Task每个Instance的Memory大小,单位M,默认1024M,在[256,12288]之间调整。
场景:当Reduce阶段的Instance有Writer Dumps时,可以适当的增加内存的大小,减少Dumps所花的时间。
上面这些参数虽然好用,但是也过于简单暴力,可能会对集群产生一定的压力。特别是在集群整体资源紧张的情况下,增加资源的方法可能得不到应有的效果,随着资源的增大,等待资源的时间变长的风险也随之增加,导致效果不好!因此请合理的使用资源参数!
小文件合并参数
set odps.merge.cross.paths=true|false
作用:设置是否跨路径合并,对于表下面有多个分区的情况,合并过程会将多个分区生成独立的Merge Action进行合并,所以对于odps.merge.cross.paths设置为true,并不会改变路径个数,只是分别去合并每个路径下的小文件。
set odps.merge.smallfile.filesize.threshold = 64
作用:设置合并文件的小文件大小阀值,文件大小超过该阀值,则不进行合并,单位为M,可以不设,不设时,则使用全局变量odps_g_merge_filesize_threshold,该值默认为32M,设置时必须大于32M。
set odps.merge.maxmerged.filesize.threshold = 256
作用:设置合并输出文件量的大小,输出文件大于该阀值,则创建新的输出文件,单位为M,可以不设,不设时,则使用全局变odps_g_max_merged_filesize_threshold,该值默认为256M,设置时必须大于256M。
set odps.merge.max.filenumber.per.instance = 10000
作用:设置合并Fuxi Job的单个Instance允许合并的小文件个数,控制合并并行的Fuxi Instance数,可以不设,不设时,则使用全局变量odps_g_merge_files_per_instance,该值默认为100,在一个Merge任务中,需要的Fuxi Instance个数至少为该目录下面的总文件个数除以该限制。
set odps.merge.max.filenumber.per.job = 10000
作用:设置合并最大的小文件个数,小文件数量超过该限制,则超过限制部分的文件忽略,不进行合并,可以不设,不设时,则使用全局变量odps_g_max_merge_files,该值默认为10000。
UDF相关参数
set odps.sql.udf.jvm.memory=1024
作用: 设定UDF JVM Heap使用的最大内存,单位M,默认1024M,在[256,12288]之间调整。
场景:某些UDF在内存计算、排序的数据量比较大时,会报内存溢出错误,这时候可以调大该参数,不过这个方法只能暂时缓解,还是需要从业务上去优化。
set odps.sql.udf.timeout=1800
作用:设置UDF超时时间,默认为1800秒,单位秒。[0,3600]之间调整。
set odps.sql.udf.python.memory=256
作用:设定UDF python 使用的最大内存,单位M,默认256M。[64,3072]之间调整。
set odps.sql.udf.optimize.reuse=true/false
作用:开启后,相同的UDF函数表达式,只计算一次,可以提高性能,默认为True。
set odps.sql.udf.strict.mode=false/true
作用:True为金融模式,False为淘宝模式,控制有些函数在遇到脏数据时是返回NULL还是抛异常,True是抛出异常,False是返回null。
Mapjoin设置
set odps.sql.mapjoin.memory.max=512
作用:设置Mapjoin时小表的最大内存,默认512,单位M,[128,2048]之间调整。
动态分区设置
set odps.sql.reshuffle.dynamicpt=true/false
作用:默认true,用于避免拆分动态分区时产生过多小文件。如果生成的动态分区个数只会是很少几个,设为false避免数据倾斜。
数据倾斜设置
set odps.sql.groupby.skewindata=true/false
作用:开启Group By优化。
set odps.sql.skewjoin=true/false
作用:开启Join优化,必须设置odps.sql.skewinfo 才有效。
SQL优化案例一:关联与数据倾斜
▐ 背景
常规的一段SQL逻辑,近90天淘宝天猫订单表作为主表,左关联商品属性表,左关联SKU属性表。
第一阶段:业务诉求里只需要取40个叶子类目的订单数据,常规开发上线运行两个月,暂时没有发现任何运行缓慢的问题。
第二阶段:业务诉求叶子类目扩展到所有实物类目,开发上线后发现JOIN节点出现了运行缓慢的问题,运行时长到达了4个小时。

▐ 解决步骤
skewjoin
看到JOIN节点运行缓慢,第一反应是数据倾斜,通过对淘宝天猫订单表按照商品维度汇总统计也可以印证存在热销商品的情况。于是毫不犹豫使用了ODPS的skewjoin hint。然而经过几次测试,JOIN节点运行缓慢的问题有所缓解,但是运行时长还是2个多小时,明显没有达到优化的预期。

传统的热点数据分离
skewjoin时效有所提升,但是还不是很理想,想尝试下传统的热点数据拆分:淘宝天猫订单表中热卖TOP50W商品写入临时表,TOP50W商品订单明细与对应的商品属性表、SKU属性表MAPJOIN,非TOP50W商品订单明细与对应的商品属性表、SKU属性表普通JOIN。但是运行时效还是不太理想,也要2个多小时。
执行计划详细分析
隐式转换
实在是不知道哪里出现了问题,尝试通过执行计划,看下具体的执行细节,在这里猛然发现了一个很大的问题:关联的时候,item_id和SKU_ID都先转换成了DOUBLE再进行关联。
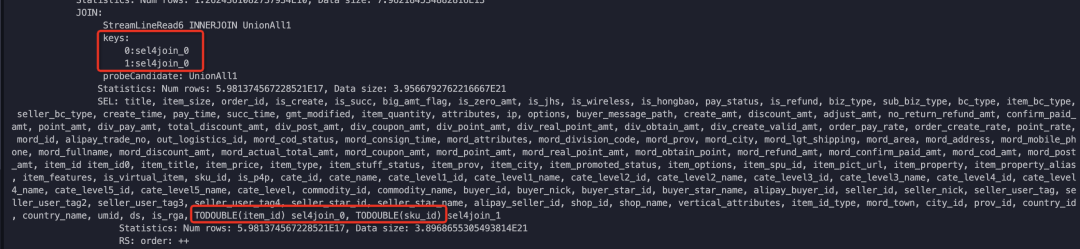
通过一个简单SQL测试也印证了这个问题,bm_dw.dim_itm_prop_dtl_di表中item_id存储的是string,查询时item_id输入为bigint,但是执行结果明显错误,原因就是默认把int的数据转换成了double再去匹配。
但是也尝试用比较常规长度的item_id查询,貌似数据又是正确的,猜想大概是超过15-16位后精度就不准确导致。
数据字段类型检查
检查字段发现订单表中item_id是bigint,但是sku属性和商品属性中的item_id存储成了string。
最终尝试关联的时候都强制转换成string再观察,发现在资源充足的情况40分钟即可完成任务的计算。

▐ 优化总结
skewjoin或者传统拆分冷热数据可以解决常规的数据倾斜。
关联时要确保左右数据类型一致,如不一致建议强制转换成string再进行关联。
商品id竟然存在18位的情况,后续使用过程中建议还是统一存储成string,查询时最好也使用string类型,避免各种查询、分析带来的麻烦。
SQL优化案例二:分桶解决大表与大表的关联
▐ 背景
DWS层存储了淘宝天猫用户天增量粒度的用户与商品交互行为轻度汇总数据(浏览、收藏、加购、下单、交易等等),基于明细数据需要汇总用户N天内的行为汇总数据,分析数据发现无明显的数据分布不均匀情况,但执行效率明显不高。
- SELECT cate_id
- ,shop_type
- ,user_id
- ,SUM(itm_sty_tme) AS itm_sty_tme
- ,SUM(itm_vst_cnt) AS itm_vst_cnt
- ,SUM(liv_sty_tme) AS liv_sty_tme
- ,SUM(liv_vst_cnt) AS liv_vst_cnt
- ,SUM(vdo_sty_tme) AS vdo_sty_tme
- ,SUM(vdo_vst_cnt) AS vdo_vst_cnt
- ,SUM(img_txt_sty_tme) AS img_txt_sty_tme
- ,SUM(img_txt_vst_cnt) AS img_txt_vst_cnt
- ,SUM(col_cnt_ufm) AS col_cnt_ufm
- ,SUM(crt_cnt_ufm) AS crt_cnt_ufm
- ,SUM(sch_cnt_ufm) AS sch_cnt_ufm
- ,SUM(mkt_iat_cnt) AS mkt_iat_cnt
- ,SUM(fan_flw_cnt) AS fan_flw_cnt
- ,SUM(fst_itm_sty_tme) AS fst_itm_sty_tme
- ,SUM(fst_itm_vst_cnt) AS fst_itm_vst_cnt
- ,SUM(col_cnt_fm) AS col_cnt_fm
- ,SUM(crt_cnt_fm) AS crt_cnt_fm
- ,SUM(sch_cnt_fm) AS sch_cnt_fm
- ,SUM(shr_cnt) AS shr_cnt
- ,SUM(cmt_cnt) AS cmt_cnt
- ,SUM(pvt_iat_cnt) AS pvt_iat_cnt
- FROM dws_tm_brd_pwr_deep_usr_cat_1d
- WHERE ds = TO_CHAR(DATEADD(TO_DATE('${bizdate}', 'yyyymmdd'), -89, 'dd'), 'yyyymmdd')
- AND cate_flag = '1'
- GROUP BY cate_id
- ,shop_type
- ,user_id

▐ 解决步骤
参数调优:增加map、reduce个数,执行效率没有明显的提升。
分桶:测试使用hash clustering解决group/join缓慢的问题。
- 1、创建测试表
- create table tmp_zhangtao_test_hash_range like dws_tm_brd_pwr_deep_brd_usr_cat_1d LIFECYCLE 2;
- 2、查看测试表结构
- desc mkt.tmp_zhangtao_test_hash_range;
- 3、修改测试表支持桶;测试时发现user_id倾斜情况不太严重
- ALTER TABLE tmp_zhangtao_test_hash_range CLUSTERED BY (user_id)
- SORTED by ( user_id) INTO 1024 BUCKETS;
- 4、插入数据,这里发现多了一个1024个任务的reduce。
- insert OVERWRITE table mkt.tmp_zhangtao_test_hash_range partition(ds,cate_flag)
- SELECT
- brand_id,
- cate_id,
- user_id,
- shop_type,
- deep_score,
- brd_ord_amt,
- discovery_score,
- engagement_score,
- enthusiasm_score,
- itm_sty_tme,
- itm_vst_cnt,
- liv_sty_tme,
- liv_vst_cnt,
- vdo_sty_tme,
- vdo_vst_cnt,
- img_txt_sty_tme,
- img_txt_vst_cnt,
- col_cnt_ufm,
- crt_cnt_ufm,
- sch_cnt_ufm,
- mkt_iat_cnt,
- fan_flw_cnt,
- fst_itm_sty_tme,
- fst_itm_vst_cnt,
- col_cnt_fm,
- crt_cnt_fm,
- sch_cnt_fm,
- shr_cnt,
- cmt_cnt,
- pvt_iat_cnt,
- ds,
- cate_flag
- FROM dws_tm_brd_pwr_deep_brd_usr_cat_1d
- WHERE ds = TO_CHAR(DATEADD(TO_DATE('${bizdate}', 'yyyymmdd'), -89, 'dd'), 'yyyymmdd');
-
-
- 5、查询数据性能比对
-
-
-
-
- SELECT cate_id
- ,shop_type
- ,user_id
- ,SUM(deep_score) AS deep_score
- ,SUM(brd_ord_amt) AS brd_ord_amt
- ,SUM(discovery_score) AS discovery_score
- ,SUM(engagement_score) AS engagement_score
- ,SUM(enthusiasm_score) AS enthusiasm_score
- ,SUM(itm_sty_tme) AS itm_sty_tme
- ,SUM(itm_vst_cnt) AS itm_vst_cnt
- ,SUM(liv_sty_tme) AS liv_sty_tme
- ,SUM(liv_vst_cnt) AS liv_vst_cnt
- ,SUM(vdo_sty_tme) AS vdo_sty_tme
- ,SUM(vdo_vst_cnt) AS vdo_vst_cnt
- ,SUM(img_txt_sty_tme) AS img_txt_sty_tme
- ,SUM(img_txt_vst_cnt) AS img_txt_vst_cnt
- ,SUM(col_cnt_ufm) AS col_cnt_ufm
- ,SUM(crt_cnt_ufm) AS crt_cnt_ufm
- ,SUM(sch_cnt_ufm) AS sch_cnt_ufm
- ,SUM(mkt_iat_cnt) AS mkt_iat_cnt
- ,SUM(fan_flw_cnt) AS fan_flw_cnt
- ,SUM(fst_itm_sty_tme) AS fst_itm_sty_tme
- ,SUM(fst_itm_vst_cnt) AS fst_itm_vst_cnt
- ,SUM(col_cnt_fm) AS col_cnt_fm
- ,SUM(crt_cnt_fm) AS crt_cnt_fm
- ,SUM(sch_cnt_fm) AS sch_cnt_fm
- ,SUM(shr_cnt) AS shr_cnt
- ,SUM(cmt_cnt) AS cmt_cnt
- ,SUM(pvt_iat_cnt) AS pvt_iat_cnt
- FROM dws_tm_brd_pwr_deep_usr_cat_1d/tmp_zhangtao_test_hash_range
- WHERE ds = TO_CHAR(DATEADD(TO_DATE('${bizdate}', 'yyyymmdd'), -89, 'dd'), 'yyyymmdd')
- AND cate_flag = '1'
- GROUP BY cate_id
- ,shop_type
- ,user_id
查询结果:
使用hash clustering ,map数和桶个数相同。
Summary: resource cost: cpu 0.34 Core * Min, memory 0.61 GB * Min
不使用hash clustering:
resource cost: cpu 175.85 Core * Min, memory 324.24 GB * Min
▐ 优化总结
通过CREATE TABLE或者ALTER TABLE语句,指定一个或者多个Cluster列,通过哈希方法,把数据存储分散到若干个桶里面,类似于这样:
CREATE TABLE T (C1 string, C2 string, C3 int) CLUSTERED BY (C3) SORTED by (C3) INTO 1024 BUCKETS;
这样做有几个好处:
对于C3列的等值条件查询,可以利用Hash算法,直接定位到对应的哈希桶,如果桶内数据排序存储,还可以进一步利用索引定位,从而大大减少数据扫描量,提高查询效率。
如果有表T2希望和T1在C3上做Join,那么对于T1表因为C3已经Hash分布,可以省掉Shuffle的步骤,进而大大节省计算资源。
Hash Clustering也有一些局限性:
使用Hash算法分桶,有可能产生Data Skew的问题。和Join Skew一样,这是Hash算法本身固有的局限性,输入数据存在某些特定的数据分布时,可能造成倾斜,进而导致各个哈希桶之间数据量差异较大。因为Hash Clustering之后,我们的并发处理单位往往是一个桶,如果哈希桶数据量不一致,在线上往往容易造成长尾现象。
Bucket Pruning只支持等值查询。因为使用哈希分桶方法,对于区间查询,比如上例中使用C3 > 0这样的条件,我们无法在哈希桶级别定位,只能把查询下发到所有桶内进行。
对于多个CLUSTER KEY的组合查询,只有所有CLUSTER KEY都出现并且都为等值条件,才能达到优化效果
SQL优化案例三:结合业务具体场景给出合理的SQL优化方案
▐ 背景
还是上面案例二的例子,DWS层存储了淘宝天猫用户天增量粒度的用户与商品交互行为轻度汇总数据(浏览、收藏、加购、下单、交易等等),基于明细数据需要汇总用户30天内的行为汇总数据。
▐ 解决步骤
基于月+日的计算方式
使用bigint类型的行为作为判断依据,>0的保存。采用double的判断>0存在数据精度问题导致的数据偏差。
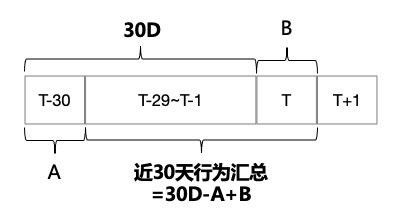
优化后:
可以发现map阶段读取原始数据map减少,计算时间缩短40分钟。
一次读取多次插入
后续需求中衍生出需要用户+一级类目的行为汇总数据,采用from insert1 insert2的方式,实现一次读取多次写入,减少资源消耗。
▐ 优化总结
基于hash cluster的方式进行优化,需要对上游的数据表进行表结构变更。如果上游表不在本团队,且适用范围较广,变更表结构的方式可操作性不高。在维持原表结构不变的情况下,优化自身SQL逻辑可能往往是一个最优的解决方案。
写在最后
SQL的语法是固定的,业务的诉求是变化的,SQL只是业务逻辑转换为物理逻辑的一个工具;在繁杂的业务诉求背景下,通过高效的SQL逻辑,覆盖/冗余更多的业务场景,是数据同学不变的追求。服务业务与降本提效有时可能会产生冲突,SQL的优化是在理解业务诉求的前。
团队介绍
我们是大聚划算数据科学团队。
使命:让货品和心智运营变得高效且有确定性!
愿景:与运营、产品合力,打造最具价格优惠心智的购物入口,最具爆发性的营销矩阵。
职责:负责支持聚划算、百亿补贴、天天特卖等业务。我们聚焦优惠和选购体验,通过数据洞察,挖掘数据价值,建立面向营销场、服务供需两端的消费者运营和供给运营解决方案。
✿ 拓展阅读


作者|张韬(伯略)
编辑|橙子君


