
- 1每日一题:C语言经典例题之韩信点兵_c语言韩信点兵问题
- 2golang办公流程引擎初体验js-ojus/flow——系列四_flowprovider golang demoflow
- 3Zookeeper是什么
- 4K8S彻底卸载教程_卸载kubelet
- 5Window环境下mysql读写分离以及主从配置(不错可以的)_window mysql如何读写分离教程
- 6链表C++详解(知识点+相关LeetCode题目)_c++链表
- 7推荐一个在线stable-diffusion-webui,通过文字生成动画视频的网站-Ai白日梦_stablediffusion在线生成
- 8Qwen-14B Ai新手部署开源模型安装到本地_qwen本地部署
- 9静态IP代理哪个好用?_哪家的静态ip好
- 10大型语言模型 (LLM) 的系统消息框架和模板建议_llm下的智能客服的系统架构
爆火的ChatTTS试用体验(附完整安装步骤和体验地址)_chattts-ui-0.84
赞
踩
近日,一个名为 ChatTTS 文本转语音项目爆火出圈。突破了开源语音天花板,才开源3天斩获9k的Star量。 该模型真是强大,又要火爆一波,是最接近真人的语音特征,包括笑声、停顿和插入词等,让人感觉不到竟是语音合成的效果。
ChatTTS介绍
非常自然的文本转语音(Text To Speech)TTS,支持中英文混读,还可以穿插笑声,听起来很真实自然。项目地址:https://github.com/2noise/ChatTTS/tree/main
专门为对话场景设计的文本转语音模型。它支持英文和中文两种语言。最大的模型使用了10万小时以上的中英文数据进行训练。在HuggingFace中开源的版本为4万小时训练且未SFT的版本。
作者本人也在 x 上表示,ChatTTS 突破了开源天花板。不过,目前开源的只是底模,没有经过 SFT 监督微调。
ChatTTS 不仅能说中文,英文也能 hold 住,还支持一些细粒度控制,它允许你加入笑声、说话间的停顿,还有语气词,可玩性很强。
音频体验效果,音频来自 B 站:
https://www.bilibili.com/video/BV1zn4y1o7iV/?share_source=copy_web&vd_source=983ec32a3036bb1cf2699e4fdbce3c28
- 1
开源地址
https://github.com/2noise/ChatTTS
安装步骤
0.使用Anaconda环境
关于Anaconda安装,不再说明,可参见我的博客:
让照片人物开口说话,SadTalker 安装及使用(避坑指南)-CSDN博客
1.使用conda 创建虚拟环境
-
conda create -n ChatTTS python=3.9
# 创建新的虚拟环境
-
conda activate ChatTTS
# 激活新建的虚拟环境
- 1
2.下载源码并安装依赖
-
//
clone源码
-
git
clone https://gitcode.com/2noise/ChatTTS.git
-
// 进入源码目录
-
cd ChatTTS
-
// 安装依赖
-
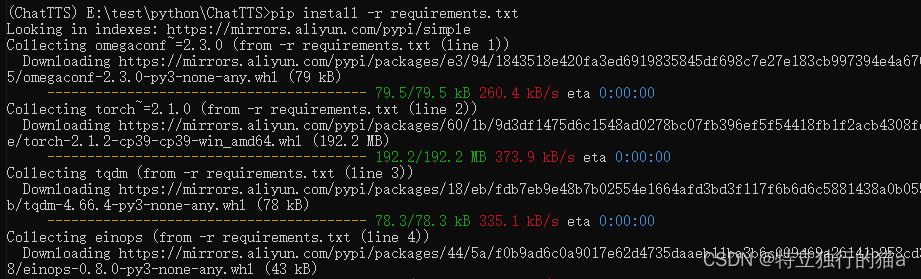
pip install -r requirements.txt
#安装项目需要的库
- 1
模型下载地址
下载地址一
https://huggingface.co/2Noise/ChatTTS
下载地址二
https://www.modelscope.cn/models/pzc163/chatTTS/files
如何使用
在项目ChatTTS目录下新建个test.py,内容如下:
-
import ChatTTS
-
from wave import Wave_write
-
import numpy as np
-
-
base_path = r
'E:\test\python\chat-mode\chatTTS'
-
chat = ChatTTS.Chat()
-
chat.load_models(
source=
'local',local_path=base_path)
-
-
# 输入文本
-
inputs =
""
"大家好,我是猫哥。专注于python、机器学习及人工智能等相关技术分享,感谢大家的点赞关注"
""
-
-
# 笑声、停顿等按需要添加的输入文本中具体位置
-
params_refine_text = {
-
'prompt':
'[oral_2][laugh_0][break_4]'
-
}
-
wavs = chat.infer(inputs, params_refine_text=params_refine_text)[0]
-
-
sample_rate = 24000
-
# 转换数据类型并调整到合适的范围
-
# audio_data_rescaled = (wavs * 32767).astype(np.int16).flatten()
-
audio_data_rescaled = (wavs * 28000).astype(np.int16).flatten()
-
-
# 创建并打开一个wav文件用于写入
-
with Wave_write(
'test4.wav') as wave_file:
-
wave_file.setparams((
1,
2, sample_rate, len(audio_data_rescaled), 'NONE', 'not compressed'))
-
wave_file.writeframes(audio_data_rescaled.tobytes())
- 1
运行报错解决
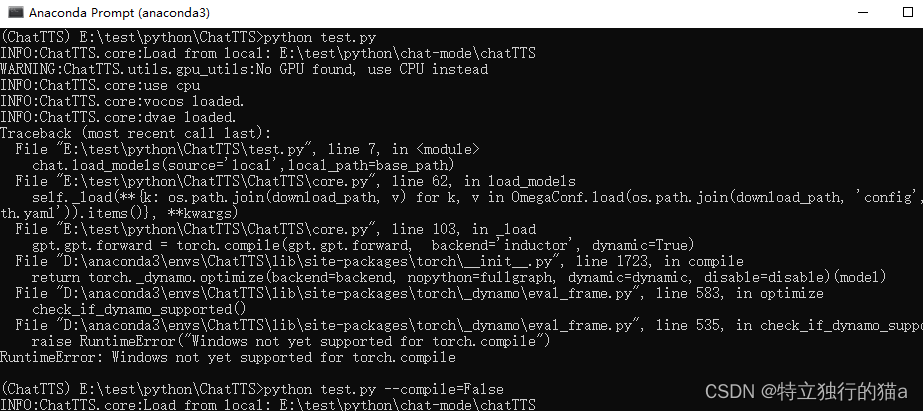
原因是 torch.compile是Pytorch2.0以后新增加的特性,用来加速Pytorch代码的方法,通过JIT 将 PyTorch 代码编译成优化的内核。但目前的windows不支持它。
windows会报错,RuntimeError: Windows not yet supported for torch.compile。
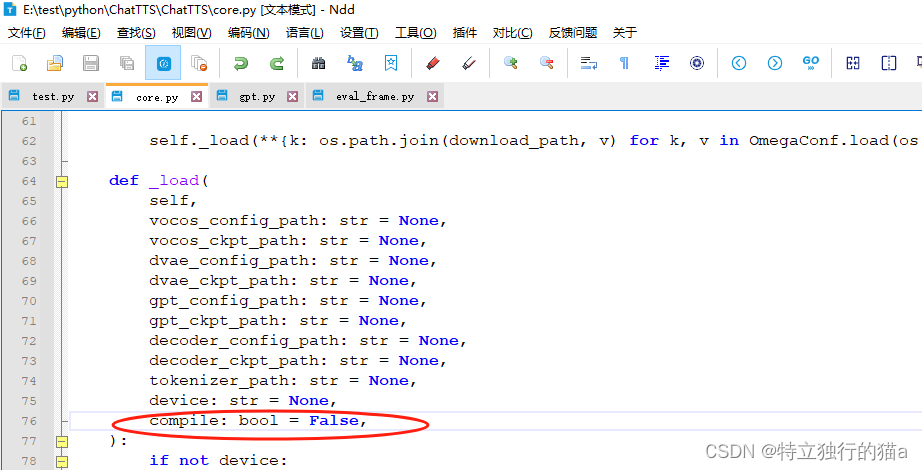
需要改ChatTTS/core.py,第75行,把原来的True改为False。
再次报错:
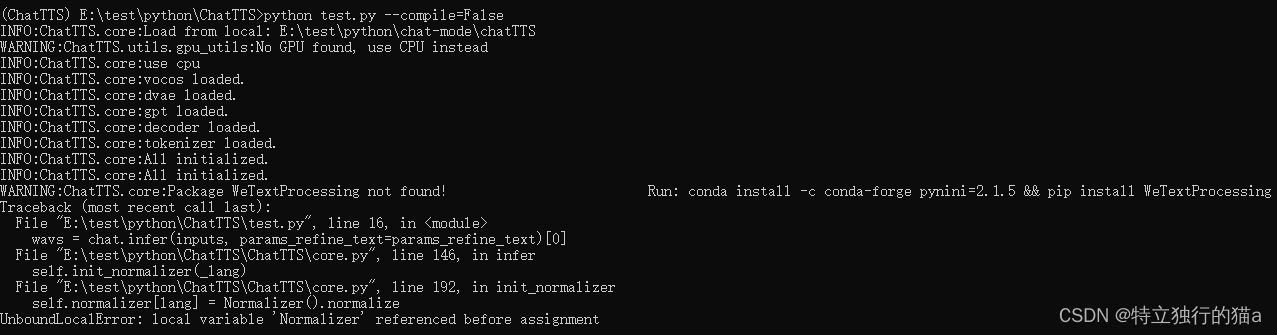
conda install -c conda-forge pynini=2.1.5 && pip install WeTextProcessing
- 1
如何快速体验
如果不想像上面的步骤自己本机安装,可以在线快速体验。
Hugging Face 上有部署好的项目,我们可以直接去试用。
体验地址
- 1
其他资源
https://gitcode.com/2noise/ChatTTS/overview
https://blog.51cto.com/yunyaniu/5935335
【手把手教学】最新ChatTTS语音合成项目使用指南【附所有源码与模型】-CSDN博客

