
- 10054期通过AI算法识别不同野生动物-含数据集_动物检测 数据集
- 2网络安全工程师必读的100本书籍,2024年最新一篇文章教你搞定计算机网络面试_成为一名合格的网络安全工程师要看哪些书
- 3【javaSE】String类(2)
- 4PostgreSQL 视图_postgres中视图的作用
- 5[ffmpeg]通过Qt调用ffmpeg命令
- 6国内超大型智能算力中心建设白皮书 2024_智算中心 架构
- 7机器学习在大数据分析中的自然语言处理
- 8Hive UDF UDTF UDAF 自定义函数详解_hive udaf函数编写
- 9一、Docker部署GitLab(详细步骤)_docker gitlab 重新生成配置
- 10YOLOv9改进策略 :小目标 | 新颖的多尺度前馈网络(MSFN) | 2024年4月最新成果_msfn模块
AB实验人群定向HTE模型1 - Causal Tree_实验平台 定向人群实验
赞
踩
背景
论文给出基于决策树估计实验对不同用户的不同影响。并提出Honest,variance Penalty算法旨在改进CART在tree growth过程中的过拟合问题。
我们举个例子:科研人员想衡量一种新的降血压药对病人的效果,发现服药的患者有些血压降低但有些血压升高。于是问题可以抽象成我们希望预测降压药会对哪些病人有效?相似的问题经常出现在经济,政治决策,医疗研究以及当下的互联网AB测试中。
Treatment effect之所以比通常的预测问题要更难解决,因为groud-truth在现实中是无法直接观测到的,一个人在同一时刻要么吃药要不么吃药,所以你永远无法知道吃药的人要是没吃药血压会不会也降低,或者没吃药的人要是吃了药血压会不会降低。
既然个体的treatment effect无法估计,只能退而求其次去估计群体的treatment effect- ATE (Average treatment effect),既全部用户中(服药效果- 未服药效果)。 但是当出现个体效果差异时ATE无法反应局部效果(E.g.样本稀释)。这时我们需要估计相似群体的treatment effect-CATE(Conditional average treatment effect)
用数学抽象一下上述问题:

模型
这里寻找相似用户的方式是通过决策树。树相较线性模型的优点毫无疑问是它对特征类型的兼容,尤其考虑到实际情况中会存在大量离散特征如性别,地域等等。
那究竟怎样grow tree来找到局部用户群, 取决于cost function的定义。一般决策/回归树是对Y的拟合例如RMSE,或者cross-entropy等等。这里作者选择最大化(Y(1)-Y(0))作为cost Function, 既我们通过树划分出的局部人群可以实现局部实验效果最大化(正向或负向)。 cost function 如下:
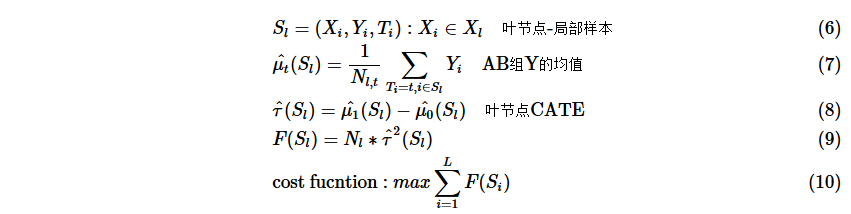
熟悉决策树的朋友也就知道后续split criterion就是去寻找最大化CATE增长的特征和阈值。
模型优化
决策树最大的问题就是过拟合,因为每一次split都一定可以带来Information Gain。这里就涉及到ML里最经典的Bias-variance trade off。树划分的节点越小,对样本的估计偏差(Bias)越小但方差(Variance)越大。
传统决策树一般通过几个方法来解决过拟合的问题:
- cross-validation来确定树深度
- min_leaf, min_split_gain 用叶节点的最小样本量等参数来停止growth
作者在文章中给出另外两种解决过拟合的方法:
- Honest approach
- Variance Penalty
Honest approach是把训练样本分成train和est两部分,用train来训练模型用est来给出每个叶节点的估计 Variance Penaly则是直接把叶节点的方差加到cost function中,最终的cost function如下:
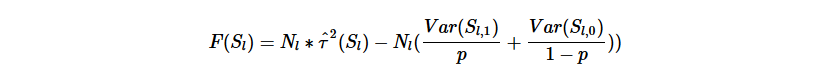
如何系统的去学习大模型LLM ?
作为一名热心肠的互联网老兵,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。
但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的 AI大模型资料 包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

