
Windows下安装Spark(亲测成功安装)_windows spark
赞
踩
Windows下安装Spark
Spark简介
Apache Spark是专为大规模数据处理而设计的快速通用的计算引擎 [2] 。现在形成一个高速发展应用广泛的生态系统。
Spark 主要有三个特点
- 首先,高级 API 剥离了对集群本身的关注,Spark 应用开发者可以专注于应用所要做的计算本身。
- 其次,Spark 很快,支持交互式计算和复杂算法。
- 最后,Spark 是一个通用引擎,可用它来完成各种各样的运算,包括 SQL 查询、文本处理、机器学习等,而在 Spark 出现之前,我们一般需要学习各种各样的引擎来分别处理这些需求。
Spark 性能特点
- 更快的速度
内存计算下,Spark 比 Hadoop 快100倍。 - 易用性
Spark 提供了80多个高级运算符。 - 通用性
Spark 提供了大量的库,包括Spark Core、Spark SQL、Spark Streaming、MLlib、GraphX。 开发者可以在同一个应用程序中无缝组合使用这些库。 - 支持多种资源管理器
Spark 支持 Hadoop YARN,Apache Mesos,及其自带的独立集群管理器 - Spark生态系统
- Shark:Shark基本上就是在Spark的框架基础上提供和Hive一样的HiveQL命令接口,为了最大程度的保持和Hive的兼容性,Spark使用了Hive的API来实现query Parsing和 Logic Plan generation,最后的PhysicalPlan execution阶段用Spark代替HadoopMapReduce。通过配置Shark参数,Shark可以自动在内存中缓存特定的RDD,实现数据重用,进而加快特定数据集的检索。同时,Spark通过UDF用户自定义函数实现特定的数据分析学习算法,使得SQL数据查询和运算分析能结合在一起,最大化RDD的重复使用。
- SparkR:SparkR是一个为R提供了轻量级的Spark前端的R包。 SparkR提供了一个分布式的data frame数据结构,解决了 R中的data frame只能在单机中使用的瓶颈,它和R中的data frame 一样支持许多操作,比如select,filter,aggregate等等。(类似dplyr包中的功能)这很好的解决了R的大数据级瓶颈问题。 SparkR也支持分布式的机器学习算法,比如使用MLib机器学习库。 SparkR为Spark引入了R语言社区的活力,吸引了大量的数据科学家开始在Spark平台上直接开始数据分析之旅。
一、Spark安装前提
安装Spark之前,需要安装JDK、Hadoop、Scala。
本次安装版本选择:
JDK:1.8
Hadoop:2.7.2
Scala:2.11.12
Spark:2.4.7
1.1、JDK安装(version:1.8)
1.1.1、JDK官网下载
官网下载地址(需要oracle账号)
https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
1.1.2、JDK网盘下载
或者网盘下载:https://pan.baidu.com/s/1MMkFbzcf8ZYvGwdHreXtUg?pwd=yyds
1.1.3、JDK安装
安装方法就不赘述了。
1.2、Scala安装(version:2.11.12)
1.2.1、Scala官网下载
官网下载地址:https://downloads.lightbend.com/scala/2.11.12/scala-2.11.12.msi
1.2.2、Scala网盘下载
网盘下载地址:https://pan.baidu.com/s/1Qiy1aEndKn_Xs-zSSLaWIA?pwd=yyds
1.2.3、Scala安装
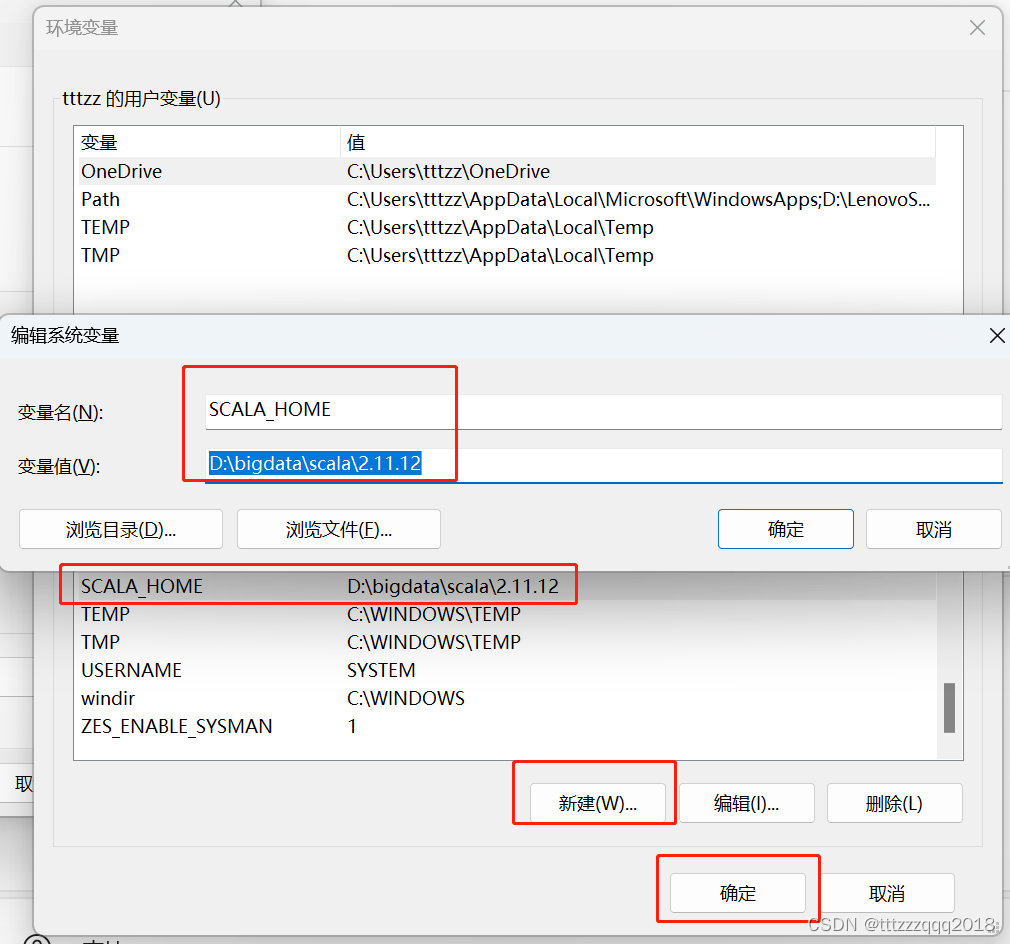
本地点击msi文件安装,安装目录为 D:\bigdata\scala\2.11.12\
设置环境变量 %SCALA_HOME%
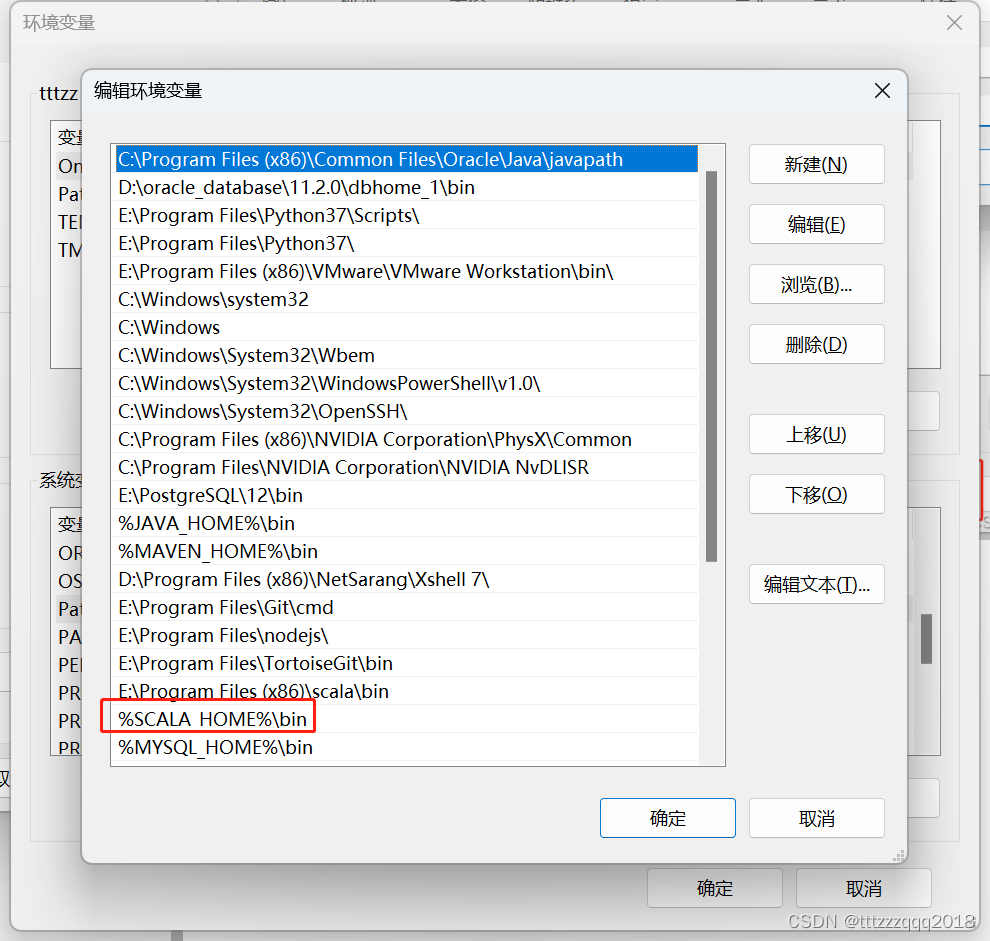
环境变量Path添加条目%SCALA_HOME%\bin
1.2.4、验证Scala是否安装成功
为了验证Scala是否安装成功,开启一个新的cmd窗口。
输入:Scala

可以看到Scala安装成功。
1.3、Hadoop安装(version:2.7.2)
参考博文:Windows下安装Hadoop(手把手包成功安装)
二、安装Spark(version:2.4.7)
2.1、Spark官网下载
官网下载地址:https://archive.apache.org/dist/spark/spark-2.4.7/spark-2.4.7-bin-hadoop2.7.tgz
历史版本仓库:https://archive.apache.org/dist/spark/
2.2、Spark网盘下载
网盘下载地址:https://pan.baidu.com/s/1VyVLwnSvdMzSocj37xlErQ?pwd=yyds
2.3、Spark安装
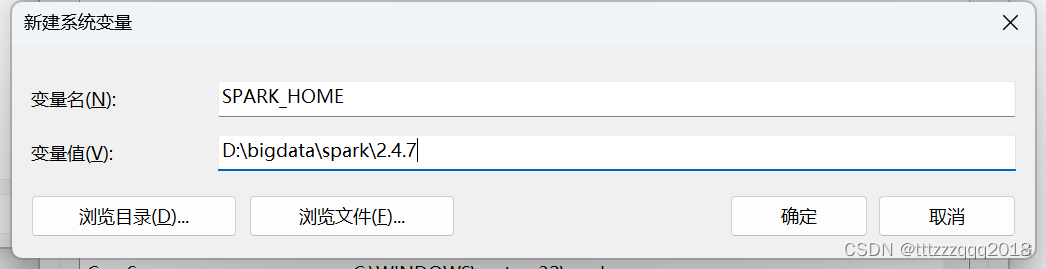
本地解压spark文件,目录为 D:\bigdata\spark\2.4.7\
设置环境变量 %SPARK_HOME%
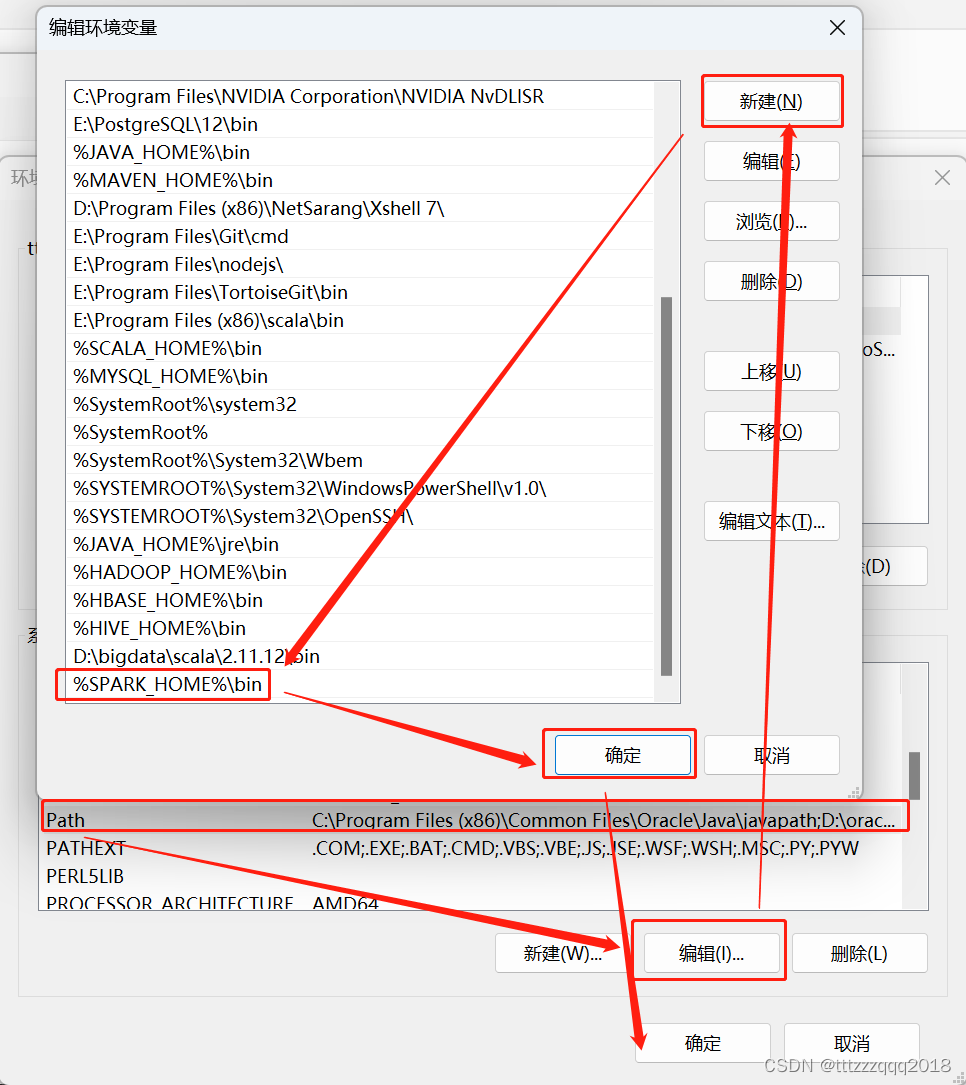
环境变量Path添加条目%SPARK_HOME%\bin
跟上面配置环境变量一样的配置方法。
2.4、验证Spark是否安装成功
为了验证Spark是否安装成功,开启一个新的cmd窗口。
输入:spark-shell

显示上面的正常运行界面,表示本地的spark环境已搭建完成!

