
- 1【数据库】binlog和redo log的区别_redo log和bin log到底有什么区别?
- 2在本地使用gitbash实现github项目的克隆、创建新分支、修改、合并_git bash克隆代码并命名
- 3NLP数据标注_nlp对话行为识别标注
- 4随笔-我说你真可爱
- 52024年Python爬虫实战 爬取网络中的小说_手机怎么爬虫晋江做txt(1),分享面试流程_爬虫网络小说
- 6基于Android的家庭理财系统的设计与实现.rar(毕业论文设计+程序源码) android studio导入可直接打开_android studio记账管理系统
- 7Micropython——九轴传感器(MPU6050)的使用及算法(三)_mpu6050数据手册
- 8github 双因子认证, app或chrome扩展验证_git 双因子验证
- 9ALLEGRO PCB 文件转 PADS9.5 PCB方法_cadence的pcb怎么导出为pads
- 10Golang Web3钱包开发指南_写web3钱包_web3观察钱包创建源码实例
python爬虫——爬取小说_爬虫爬取小说python代码
赞
踩
一、导入requests和parsel库
requests是一个HTTP请求库,像浏览器一样发送THHP请求来获取网站信息。
parsel是对 HTML 和 XML 进行解析库,
import requests
import parsel
- 1
- 2
- 3
二、获取小说网站内容
通过 url = “https://www.777zw.net/1/1429/” 爬取小说网站内容。
url = "https://www.777zw.net/1/1429/"
response = requests.get(url)
responses = response.text.encode('iso-8859-1').decode('gbk')
print(responses)
- 1
- 2
- 3
- 4
- 5
在爬取小说网站时遇见一个错误爬取中文编译乱码:

之后查找资料发现是由于网页编码用的方式不同 :
解决方法
查看网站所用编码方法,打开想爬取页面开启开发人员工具,在控制台输入document.charse查看文本格式

将常规的 “utf-8” 格式转换成 “gbk”
# utf-8格式
response.encoding = 'utf-8'
# 改成gbk格式
response.text.encode('iso-8859-1').decode('gbk')
- 1
- 2
- 3
- 4
- 5
获取网页内容代码:
url = "https://www.777zw.net/1/1429/"
response = requests.get(url)
responses = response.text.encode('iso-8859-1').decode('gbk')
print(responses)
- 1
- 2
- 3
- 4
- 5
三、获取小说名和获取小说章节
在开发者工具中找到小说名:
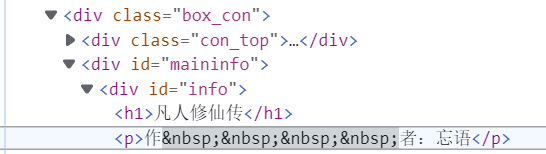
爬取方法
selector = parsel.Selector(responses)
novel_name = selector.css('#info h1::text').get() #小说名
- 1
- 2
- 3
#info 获取 id 是 info,h1 存取小说名,小说名是文本文件所以用text
找到小说章节
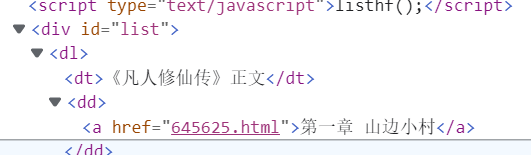
爬取代码
href = selector.css('#list dd a::attr(href)').getall() #小说章节
- 1
- 2
get() 获取一个,getall() 获取所有小说章节
四、获取章节名和小说内容
这一步原理和步骤一样就不多赘述了
五、源代码
import requests import parsel url = "https://www.777zw.net/1/1429/" response = requests.get(url) responses = response.text.encode('iso-8859-1').decode('gbk') print(responses) selector = parsel.Selector(responses) novel_name = selector.css('#info h1::text').get() #小说名 href = selector.css('#list dd a::attr(href)').getall() #小说章节 for link in href: link_url = 'https://www.777zw.net/1/1429/' + link response_1 = requests.get(link_url) responses_1 = response_1.text.encode('iso-8859-1').decode('gbk') selecter_1 = parsel.Selector(responses_1) title_name = selecter_1.css('.bookname h1::text').get() #小说章节 content_list = selecter_1.css('#content::text').getall() #小说内容 content = ' '.join(content_list) break # 保存 with open(novel_name + '.txt',mode = 'a',encoding = 'utf-8') as f: f.write(title_name) f.write(' ') f.write(content) f.write(' ') # print(title_name) print(novel_name) print(content_list)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
六、结果

先自我介绍一下,小编13年上师交大毕业,曾经在小公司待过,去过华为OPPO等大厂,18年进入阿里,直到现在。深知大多数初中级Python工程师,想要升技能,往往是需要自己摸索成长或是报班学习。
Python这个类目无论是功能性、还是上手程度都碾压其他语言,作为最适合零基础入门的编程语言,想要学习自然不能纸上谈兵,还得沉下心来深入的研究和学习。
只告诉大家学什么但是不给予方向的行为无异于耍流氓,这里也是分享我多年收藏的技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你,干货内容包括:

上述这份完整版的Python全套学习资料已经上传CSDN官方,如果需要可以微信扫描下方CSDN官方认证二维码 即可领取
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/792269
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

