
Python数据合并/拼接函数concat、append、merge、join_python concat函数
赞
踩
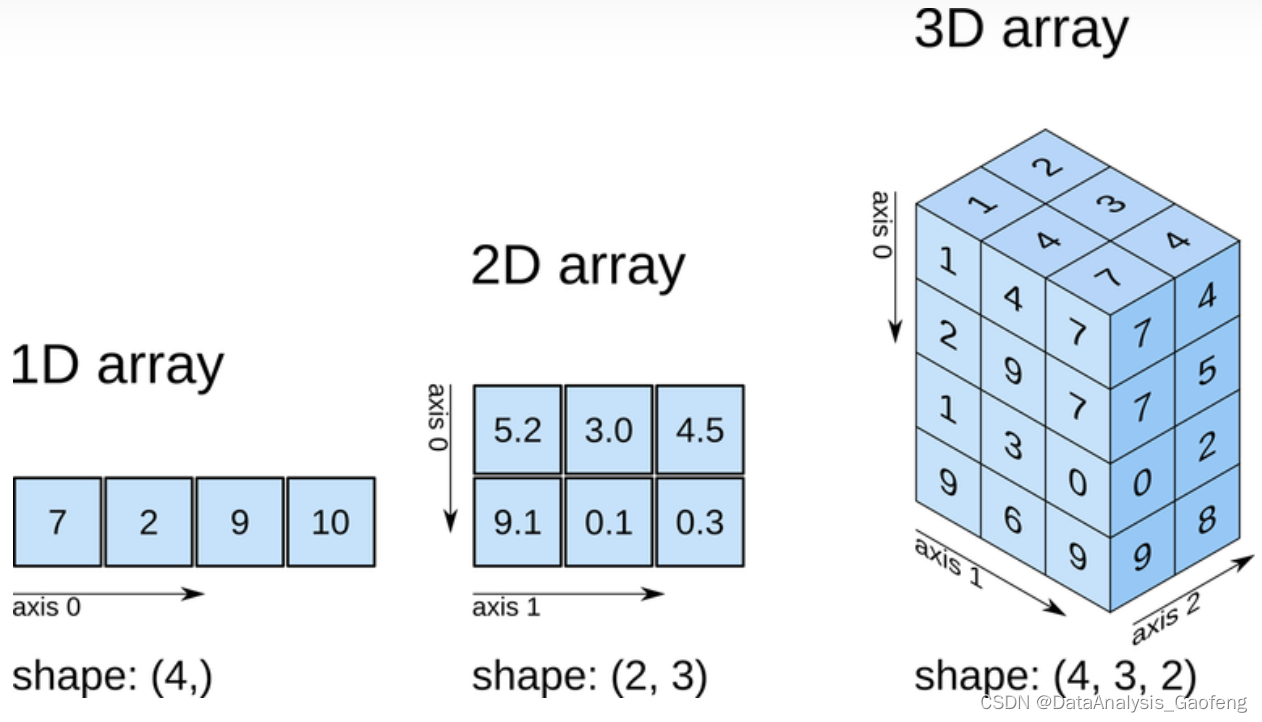
目录
概述
数据分析中经常会遇到补行/列数据 或 数据拼接/合并的问题:
- 数据或表格的左右连接——concat(aixs=1)、merge、join;
- 数据或表格的上下连接——concat(aixs=0)、append。
根据上述问题,本文总结了python中的表格拼接/合并函数的基本用法和使用效果:
- merge : 主要用于表格的左右连接,类似于SQL中的Join操作,根据具体字段来匹配连接
- concat : 既能按轴上下拼接,也能按轴左右拼接,主要取决于参数axis的设定
- append: 追加,只能用于表格的上下连拼,可视作axis=0的简便版concat
- join:主要用于表格的左右连接
数据准备
- #建立数据表
- import numpy as np
- import pandas as pd
-
- df1 = pd.DataFrame({"id": ["01", "02", "03", "04"],
- "name": ["Alice", "Bruce", "Cook", "Daisy"],
- "school": ["AA", "BB", "CC", "AA"],
- "score": [85, 90, 75, 80]})
-
- df2 = pd.DataFrame({"id": ["01", "20"],
- "name": ["Alice", "Jason"],
- "school":["AA", "CC"],
- "score": [85, 88]})
-
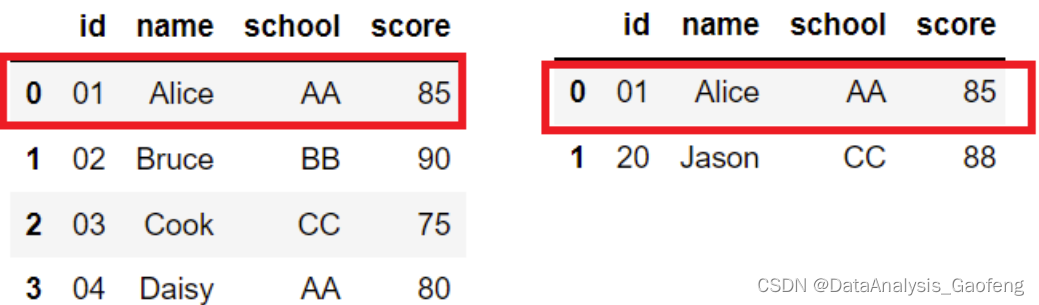
- df1
- df2

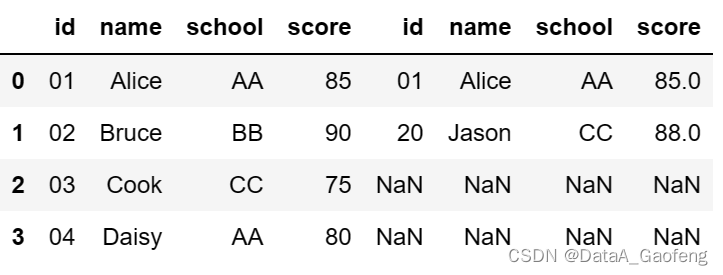
df1和df2 表格的数据呈现如下图,特别注意这2个表格的第1行的数据是相同的
1.merge()
merge与concat不同,merge是根据两个表的具体连接字段来进行匹配合并,而concat是根据轴的具体方向进行合并不会有匹配过程。

1.1 merge()函数基本格式
pd.merge( left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None,)1.2 常用参数的使用与应用
merge(): 主要使用于表格的左右连接(横向合并)
- left,right参数
- how参数
- on参数
- indicator参数
- sort参数
left,rght参数
(参数名可省略不写)
left: 表示拼接后置于左边的表格;
right: 表示拼接后置于右边的表格
- df = pd.merge(left=df1, right=df2) # 或 df = pd.merge(df1,df2)
- df
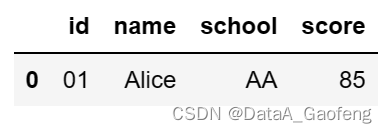
表格连接的结果是返回了两个表格的“交集”,即两个表格中都存在的相同记录!这是因为merge的参数how,它的默认值为"inner"!也即内连接。
how参数
连接的方式,有4中选择:“left”, “right”, “inner”, “outer”, 默认值=”inner"
“inner”: 返回两个表格的交集
“outer”:返回两个表格的并集
① 设置how="inner"
- df = pd.merge(df1, df2, how="inner")
- df
由于how的默认值是"inner", 因此连接的结果与上面的一样!
② 设置how="outer"
- df = pd.merge(=df1, df2, how="outer")
- df
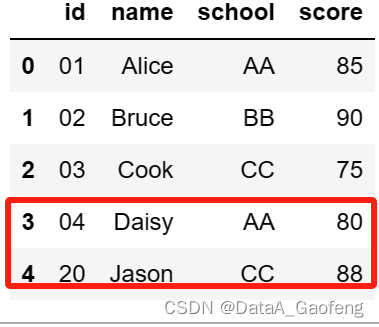
表格连接的结果:将两个表格中所有的数据,相同的数据只显示1次。相当于两个表格合并后去重。
③ 设置how="left" ---- 按照左边的表格进行数据合并
- df = pd.merge(df1, df2, how="left")
- df
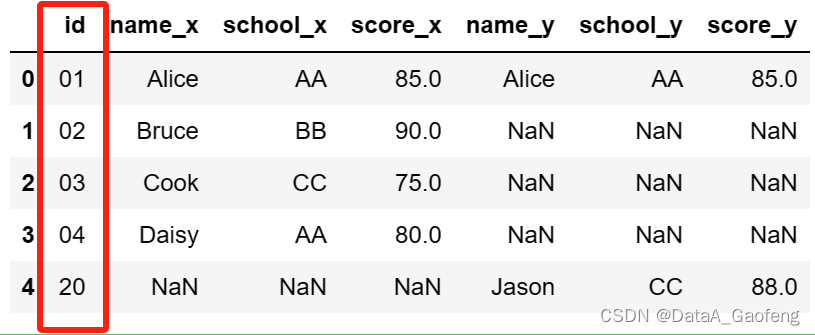
④ 设置how="right" -- 按照右边的表格进行数据合并
- df = pd.merge(df1, df2, how="right")
- df
on参数
以哪一列作为连接列进行匹配连接,该列对应字段必须同时出现在两个dataframe中,如果未传递且left_index和right_index为False,则DataFrame中的列的交集将被推断为连接键。
① 设置on=["id"]
- df = pd.merge(df1, df2, on=["id"], how="outer")
- df
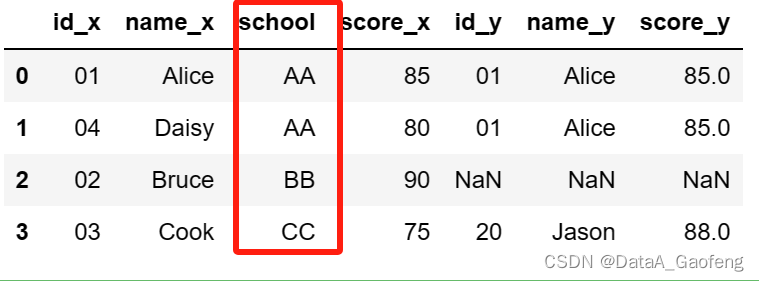
② 设置on=["school"]
- df = pd.merge(df1, df2, on=["school"], how="outer")
- df
indicator参数
指示器,为布尔值,默认为False。
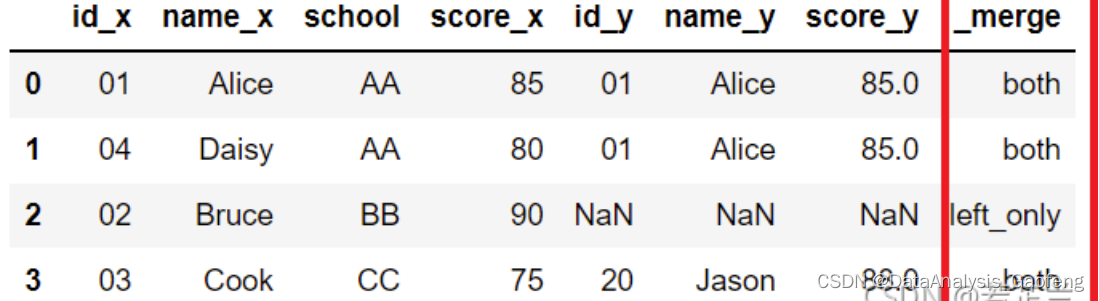
如果indicator为True,则向输出数据帧添加一个名为“_merge”的列,显示根据要求,每行数据在2个表格中匹配的情况,同一行两个表都不为NaN的显示both,同一行左表或右表为NaN的显示left_only或right_only。
① 设置indicator=True
- df = pd.merge(df1, df2, on=["school"], how="outer", indicator=True)
- df
sort参数
排序,根据连接字段进行升序,默认值为False
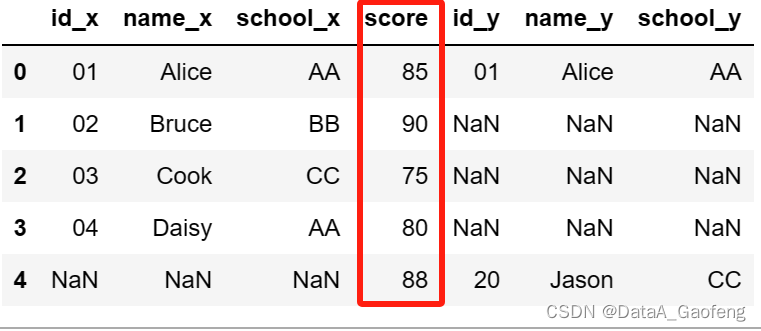
① 设置sort使用默认值 False
- df = pd.merge(df1, df2, on=["score"], how="outer")
- df
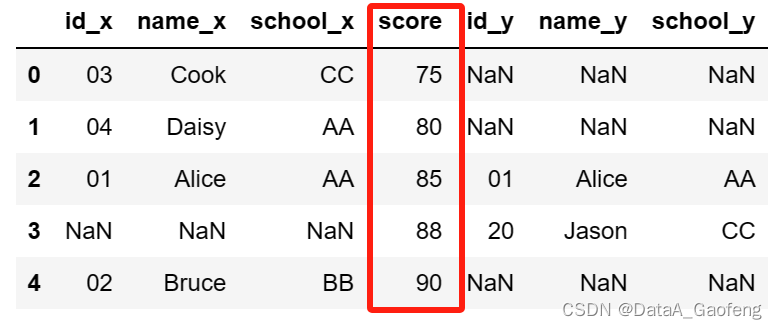
② 设置sort = True
- df = pd.merge(df1, df2, on=["score"], how="outer", sort=True)
- df
2. concat()
concat是”contatenate"的缩写,指的是多表之间的“拼接”。该函数能够沿指定轴执行连接操作,同时对其他轴上的索引(如果有的话,Series 只有一个轴)执行可选的集合运算(并集或交集)
2.1 concat()函数基本格式
pd.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=True,)2.2 常用参数的使用与应用
参数axis=0:数据的向下拼接
重复数据不会去重, 常用于数据(记录)的汇总合并,相当于SQL中的union all
- df = pd.concat([df1, df2], axis=0)
- df
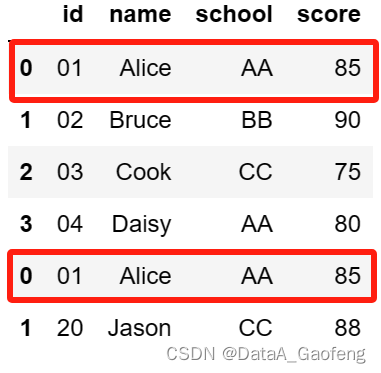
df1和df2是直接进行上下连接 – 常用于数据(记录)的汇总合并,相当于SQL中的union all
参数axis=1:数据的左右拼接
参数 join的默认值=“outer”, 因此下列2行代码的结果是一样的。
- df = pd.concat([df1, df2], axis=1)
- # df = pd.concat([df1, df2], axis=1, join="outer")
- df
小结:
对比结果,pd.concat() 适用于数据表(DataFrame)的上下连接,而对于表格的左右连接,pd.merge() 会更好一些。
3. append()
append是series和dataframe的方法,使用它就是默认沿着列进行拼接,append可以视作axis=0的简便版concat。也就是说,它只支持上下的行拼接,同时比concat简便一些。这里要注意和concat的用法区别。concat是pd的属性,所以调用的时候应该是pd.concat((df1,df2)),而append是对DataFrame的方法,所以调用的时候是DataFrame.append(df2)
只能使用于表格的上下连接,表格的上下位置顺序取决于哪一个表格放在前面。
x=df.append(other, ignore_index=False, verify_integrity=False, sort=None)
- other:要追加的数据,可以是dataframe,series,字典,列表
- gnore_index:两个表的index是否有实际含义,默认为False,若ignore_index=True,表根据列名对齐合并,生成新的index
- verify_integrity:默认为False,若为True,创建具有重复项的索引时引发ValueError
- sort:默认为False,若为True如果’ self ‘和’ other '的列没有对齐,则对列进行排序。
在表格df1后面连接表格df2:
- df = df1.append(df2)
- df
4. join()
DataFrame内置的join方法是一种快速合并的方法,join操作是一个同merge相似的操作。join()默认是两个DataFrame之间进行Index的关联合并,当然也可以指定普通的列column和index之间进行混合合并:join也可以被理解为merge的一个简便并且特殊的方法。join也可以设置参数"how",只不过这里默认值不同。Merge中,how的默认值是”inner“,join中的默认值为”left"。
df=DataFrame.join(obj, on=None, how=’left’, lsuffix=”, rsuffix=”, sort=False,validate="one_to_one")
- obj:要合并的表,DataFrame、或者带有名字的Series、或者DataFrame的list。如果传递的是Series,那么其name属性应当是一个集合,并且该集合将会作为结果DataFrame的列名
- on:合并表时的列名称,连接的列,默认使用索引连接
- how:{‘left’, ‘right’, ‘outer’, ‘inner’}, 默认left连接方式,即左连接。具体连接方式见上文merge参数how
- lsuffix:列名重复时,合并后左表列名使用的后缀,默认’ ’
- rsuffix:列名重复时,合并后右表列名使用的后缀,默认’ ’
- sort:按照字典顺序对结果在连接键上排序。如果为False,连接键的顺序取决于连接类型(关键字)。True时根据合并的索引排列合并结果,False时根据how参数排序,默认False
- validate:设置合并数据类型,支持"one_to_one" or “1:1”、“one_to_many” or “1:m”、“many_to_one” or “m:1”、“many_to_many” or “m:m”
① Index-Index的关联合并
result = left.join(right)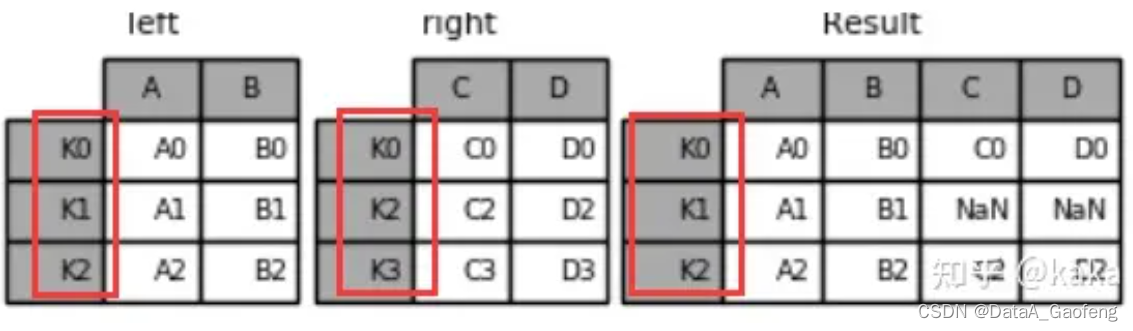
② Column-Index的混合关联合并
result = left.join(right, on='key')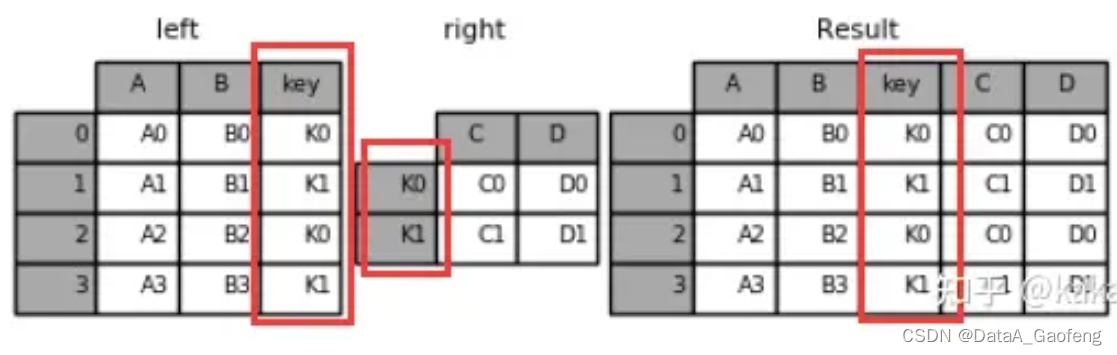
5. 结束语
- concat和append是通过轴向的合并(这个过程类似于SQL中的union all),merge和join主要是通过具体的某一列(键)进行匹配(类似于Excel中的VLOOKUP,SQL中的join),若在合并数据的过程中需要通过某些键进行关联则使用merge和join,若不需要匹配则用concat和append。
- append和join相较于concat和merge来说,参数更少一点,能够实现的功能也相对少一些,可以理解为简化版的concat和merge。

