
- 1深入解析PHP函数
- 2一文彻底搞懂OSI七层模型和TCP/IP四层模型_osi网络协议
- 3优秀的 Verilog/FPGA开源项目介绍(三)- 大厂的项目_opentitan是什么
- 4.net8 blazor auto模式很爽(三)用.net8的Blazor自动模式测试,到底在运行server还是WebAssembly_blazor auto项目刷新后注入的service会失效
- 5RabbitMQ的五种工作模式和使用场景_rabbitmq五种消息模型及应用场景
- 6如何用python画长方形_python怎么画矩形
- 7信息管理系统三级等保的一些要求_三级等保对网站系统有什么要求
- 8通过C语言实现三种版本的快速排序
- 9PyTorch Mobile在端侧可堪大用?能否与TensorFlow Lite一较高下_pytorch lite flutter
- 10python中的 list (列表)append()方法 与extend()方法的用法 和 区别
性能优化实践总结——JAVA_java性能优化实践
赞
踩
1、 衡量程序性能的指标
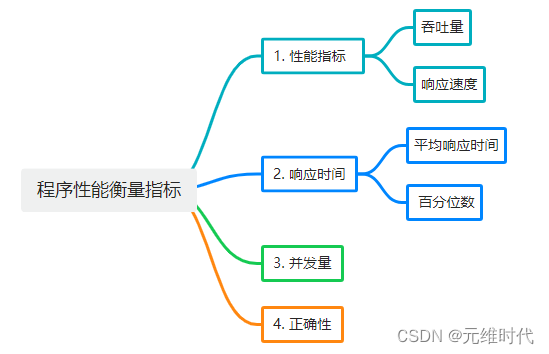
- 并发:同一时间有多少请求访问
- TPS:transaction per second(每秒的事物数)
- QPS:query per second(每秒请求数)
- 耗时:端到端耗时,服务端耗时,应用程序耗时
- 95线:95%的请求落在什么范围内
- 99线:99%的请求落在什么范围内
2、Java 程序性能优化切入点
-
硬件优化:增加 CPU、内存、磁盘等硬件资源,提高程序运行效率。
-
JVM 参数优化:调整 JVM 参数,包括堆大小、垃圾回收机制等,提高 JVM 性能。
-
代码优化:包括算法优化、数据结构优化、避免重复计算、复用优化、结果集优化(JSON)、资源冲突优化等。
-
计算优化:使用多线程技术,变同步为异步;惰性加载(使用设计模式优化业务),提高程序性能。
-
数据库优化:包括索引优化、SQL 语句优化等,提高数据库查询效率。
-
网络优化:包括减少网络传输数据量、使用缓存等,提高网络传输效率。
-
缓存优化:使用缓存技术,减少程序对数据库等资源的访问,提高程序响应速度。
-
日志优化:包括日志级别、日志格式等,减少不必要的日志输出,提高程序性能。
3、获取程序的性能数据
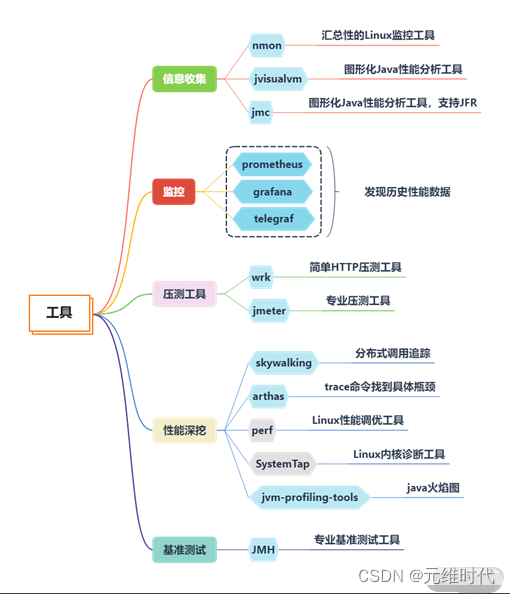
1、nmon:获取系统性能数据
- nmon是一种在 AIX 与各种 Linux 操作系统上广泛使用的监控与分析工具
- 它能在系统运行过程中实时地捕捉系统资源的使用情况,记录的信息比较全面
- 它可将服务器系统资源耗用情况收集起来并输出一个特定的文件,并可利用 excel 分析工具(nmon analyser)进行数据的统计分析
2、jvisualvm:获取JVM性能数据
它提供了一个可视界面,用于查看 Java 虚拟机 (Java Virtual Machine, JVM) 上运行的基于 Java 技术的应用程序(Java 应用程序)的详细信息。
3、jmc:获取Java应用详细性能数据
性能监测图形化,通过jdk自带的JMC工具即可轻松实现。
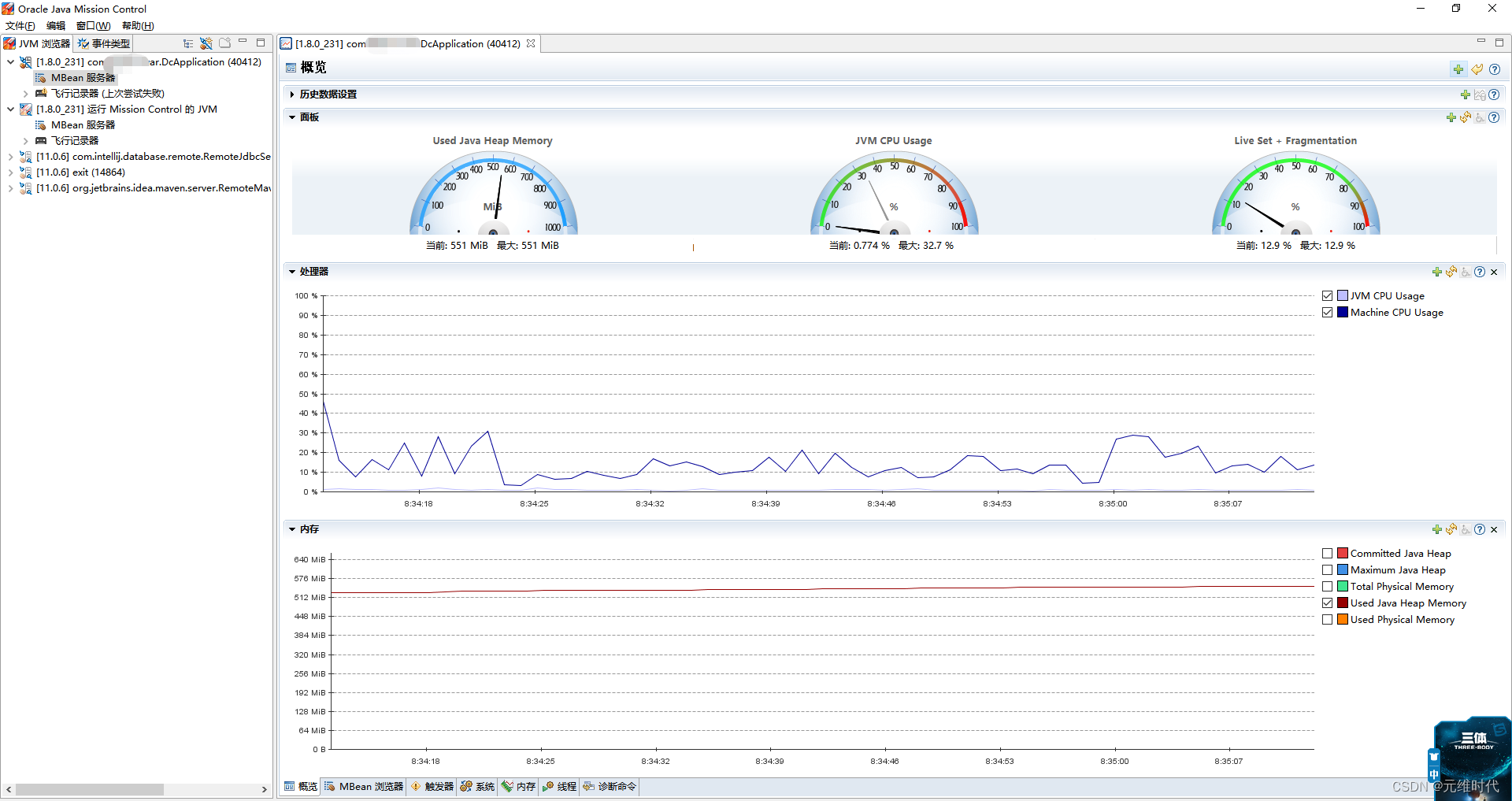
4、arthas:获取单个请求的调用链耗时
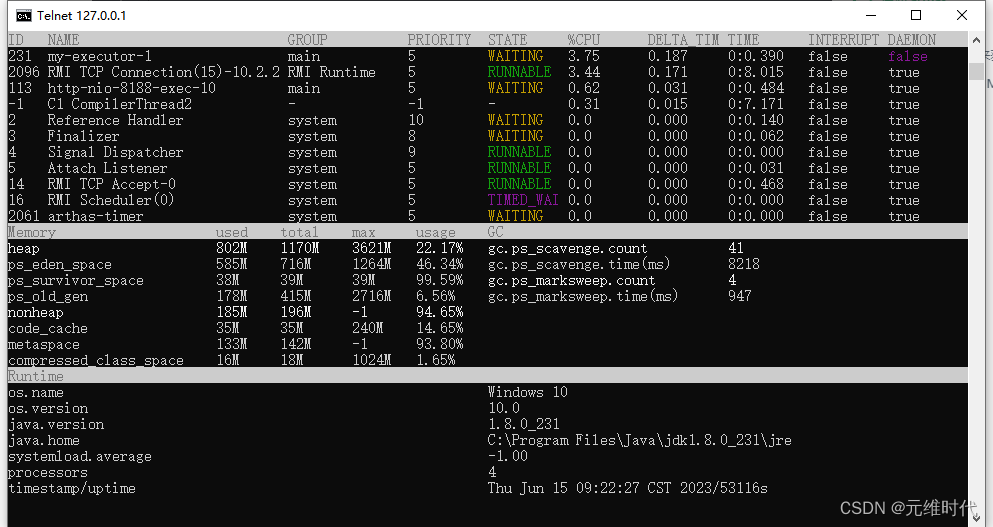
5、wrk获取Web接口的性能数据
HTTP基准测试工具,能够在单个多核CPU上运行时产生大量负载。它结合了多线程设计和可扩展的事件通知系统,如epoll和kqueue,以及使用了redis的’ae’事件循环,可以用很少的线程压出很大的并发量。
wrk压测教程
4、应用程序优化
1、缓冲区
缓冲(Buffer)通过对数据进行暂存,然后批量进行传输或者操作,多采用顺序方式,来缓解不同设备之间次数频繁但速度缓慢的随机读写。
1、优势
- 缓冲双方能各自保持自己的操作节奏,操作处理顺序也不会打乱,可以 one by one 顺序进行;
- 以批量的方式处理,减少网络交互和繁重的 I/O 操作,从而减少性能损耗;
- 优化用户体验,比如常见的音频/视频缓冲加载,通过提前缓冲数据,达到流畅的播放效果。
2、应用
3、常见的使用缓冲区来提升性能的做法:
- StringBuilder 和 StringBuffer,通过将要处理的字符串缓冲起来,最后完成拼接,提高字符串拼接的性能;
- 操作系统在写入磁盘,或者网络 I/O 时,会开启特定的缓冲区,来提升信息流转的效率。通常可使用 flush 函数强制刷新数据,比如通过调整 Socket 的参数 SO_SNDBUF 和 SO_RCVBUF 提高网络传输性能;
- MySQL 的 InnoDB 引擎,通过配置合理的 innodb_buffer_pool_size,减少换页,增加数据库的性能;
- 在一些比较底层的工具中,也会变相地用到缓冲。比如常见的 ID 生成器,使用方通过缓冲一部分 ID 段,就可以避免频繁、耗时的交互。
2、缓存
1、进程内缓存
在 Java 中,进程内缓存,就是我们常说的堆内缓存。Spring 的默认实现里,就包含 Ehcache、JCache、Caffeine、Guava Cache 等。
以Guava 的 LoadingCache为例:
缓存一般是比较昂贵的组件,容量是有限制的,设置得过小,或者过大,都会影响缓存性能:
- 缓存空间过小,就会造成高命中率的元素被频繁移出,失去了缓存的意义。
- 缓存空间过大,不仅浪费宝贵的缓存资源,还会对垃圾回收产生一定的压力。
LoadingCache的常见操作:
(1)缓存初始化
首先,我们可以通过下面的参数设置一下 LC 的大小。一般,我们只需给缓存提供一个上限。
- maximumSize 这个参数用来设置缓存池的最大容量,达到此容量将会清理其他元素;
- initialCapacity 默认值是 16,表示初始化大小;
- concurrencyLevel 默认值是 4,和初始化大小配合使用,表示会将缓存的内存划分成 4 个 segment,用来支持高并发的存取。
(2)缓存操作
那么缓存数据是怎么放进去的呢?有两种模式:
- 使用 put 方法手动处理,比如,我从数据库里查询出一个 User 对象,然后手动调用代码进去;
- 主动触发( 这也是 Loading 这个词的由来),通过提供一个 CacheLoader 的实现,就可以在用到这个对象的时候,进行延迟加载。
public static void main(String[] args) {
LoadingCache<String, String> lc = CacheBuilder
.newBuilder()
.build(new CacheLoader<String, String>() {
@Override
public String load(String key) throws Exception {
return slowMethod(key);
}
});
}
static String slowMethod(String key) throws Exception {
Thread.sleep(1000);
return key + ".result";
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
(3)回收策略
- 第一种回收策略基于容量,这个比较好理解,也就是说如果缓存满了,就会按照 LRU 算法来移除其他元素。
- 第二种回收策略基于时间:一种方式是,通过 expireAfterWrite 方法设置数据写入以后在某个时间失效;另一种是,通过 expireAfterAccess 方法设置最早访问的元素,并优先将其删除。
- 第三种回收策略基于 JVM 的垃圾回收,我们都知道对象的引用有强、软、弱、虚等四个级别,通过 weakKeys 等函数即可设置相应的引用级别。当 JVM 垃圾回收的时候,会主动清理这些数据。
(4)缓存造成内存故障
LC 可以通过 recordStats 函数,对缓存加载和命中率等情况进行监控。
值得注意的是:LC 是基于数据条数而不是基于缓存物理大小的,所以如果你缓存的对象特别大,就会造成不可预料的内存占用。
围绕这点,引出一个由于不正确使用缓存导致的常见内存故障:
大多数堆内缓存,都会将对象的引用设置成弱引用或软引用,这样内存不足时,可以优先释放缓存占用的空间,给其他对象腾出地方。这种做法的初衷是好的,但容易出现问题。
当缓存使用非常频繁,数据量又比较大的情况下,缓存会占用大量内存,如果此时发生了垃圾回收(GC),缓存空间会被释放掉,但又被迅速占满,从而会再次触发垃圾回收。如此往返,GC 线程会耗费大量的 CPU 资源,缓存也就失去了它的意义。
(5)缓存算法
堆内缓存最常用的有 FIFO、LRU、LFU 这三种算法。
- FIFO:这是一种先进先出的模式。如果缓存容量满了,将会移除最先加入的元素。这种缓存实现方式简单,但符合先进先出的队列模式场景的功能不多,应用场景较少。
- LRU:LRU 是最近最少使用的意思,当缓存容量达到上限,它会优先移除那些最久未被使用的数据,LRU是目前最常用的缓存算法,稍后我们会使用 Java 的 API 简单实现一个。
- LFU:LFU 是最近最不常用的意思。相对于 LRU 的时间维度,LFU 增加了访问次数的维度。如果缓存满的时候,将优先移除访问次数最少的元素;而当有多个访问次数相同的元素时,则优先移除最久未被使用的元素。
(6)缓存优化的一般思路
一般,缓存针对的主要是读操作。当你的功能遇到下面的场景时,就可以选择使用缓存组件进行性能优化:
- 存在数据热点,缓存的数据能够被频繁使用;
- 读操作明显比写操作要多;’
- 下游功能存在着比较悬殊的性能差异,下游服务能力有限;
- 加入缓存以后,不会影响程序的正确性,或者引入不可预料的复杂性。
缓存组件和缓冲类似,也是在两个组件速度严重不匹配的时候,引入的一个中间层,但它们服务的目标是不同的:
- 缓冲,数据一般只使用一次,等待缓冲区满了,就执行 flush 操作;
- 缓存,数据被载入之后,可以多次使用,数据将会共享多次。
缓存最重要的指标就是命中率,有以下几个因素会影响命中率。
-
缓存容量:缓存的容量总是有限制的,所以就存在一些冷数据的逐出问题。但缓存也不是越大越好,它不能明显挤占业务的内存。
-
数据集类型:如果缓存的数据是非热点数据,或者是操作几次就不再使用的冷数据,那命中率肯定会低,缓存也会失去了它的作用。
(7)缓存失效策略
推荐使用 Guava Cache 或者 Caffeine 作为堆内缓存解决方案,然后通过它们提供的一系列监控指标,来调整缓存的大小和内容,一般来说: -
缓存命中率达到 50% 以上,作用就开始变得显著;
-
缓存命中率低于 10%,那就需要考虑缓存组件的必要性了;
缓存算法也会影响命中率和性能,目前效率最高的算法是 Caffeine 使用的 W-TinyLFU 算法,它的命中率非常高,内存占用也更小。新版本的 spring-cache,已经默认支持 Caffeine。
2.分布式缓存——Redis
一种集中管理的思想。如果我们的服务有多个节点,堆内缓存在每个节点上都会有一份;而分布式缓存,所有的节点,共用一份缓存,既节约了空间,又减少了管理成本。
在分布式缓存领域,使用最多的就是 Redis。Redis 支持非常丰富的数据类型,包括字符串(string)、列表(list)、集合(set)、有序集合(zset)、哈希表(hash)等常用的数据结构。当然,它也支持一些其他的比如位图(bitmap)一类的数据结构。
(1)SpringBoot 如何使用 Redis
使用 SpringBoot 可以很容易地对 Redis 进行操作(完整代码见仓库)。Java 的 Redis的客户端,常用的有三个:jedis、redisson 和 lettuce,Spring 默认使用的是 lettuce。
lettuce 是使用 netty 开发的,操作是异步的,性能比常用的 jedis 要高;redisson 也是异步的,但它对常用的业务操作进行了封装,适合书写有业务含义的代码。
- 通过坐标引入下面的 jar 包即可方便地使用 Redis。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
- 1
- 2
- 3
- 4
使用 RedisTemplate 这个类,它针对不同的数据类型,抽象了相应的方法组。
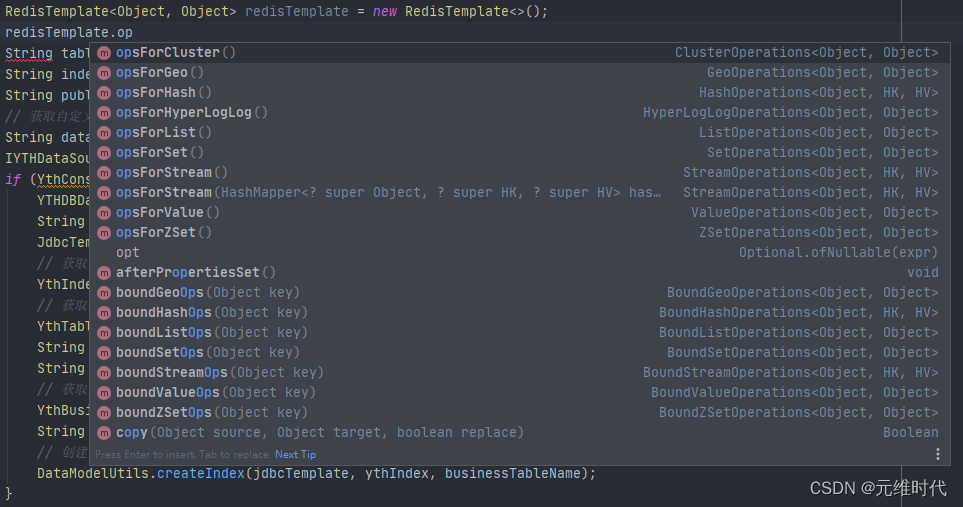
- 另外一种方式,就是使用 Spring 抽象的缓存包 spring-cache。它使用注解,采用 AOP的方式,对 Cache 层进行了抽象,可以在各种堆内缓存框架和分布式框架之间进行切换。这是它的 maven 坐标。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-cache</artifactId>
</dependency>
- 1
- 2
- 3
- 4
使用 spring-cache 有三个步骤:
- 在启动类上加入 @EnableCaching 注解;
- 使用 CacheManager 初始化要使用的缓存框架,使用 @CacheConfig 注解注入要使用的资源;
- 使用 @Cacheable 等注解对资源进行缓存;
针对缓存操作的注解,有三个:
- @Cacheable 表示如果缓存系统里没有这个数值,就将方法的返回值缓存起来;
- @CachePut 表示每次执行该方法,都把返回值缓存起来;
- @CacheEvict 表示执行方法的时候,清除某些缓存值。
我们系统使用的是第二种方式:
应用案例:缓存远程服务数据
(2)缓存穿透、击穿和雪崩
- 缓存穿透:命中率有关。如果命中率很低,那么压力就会集中在数据库持久层。假如能找到相关数据,我们就可以把它缓存起来。但问题是,本次请求,在缓存和持久层都没有命中,这种情况就叫缓存的穿透。例如:在一个登录系统中,有外部攻击,一直尝试使用不存在的用户进行登录,这些用户都是虚拟的,不能有效地被缓存起来,每次都会到数据库中查询一次,最后就会造成服务的性能故障。
解决方案:
第一种就是把空对象缓存起来。不是持久层查不到数据吗?那么我们就可以把本次请求的结果设置为 null,然后放入到缓存中。通过设置合理的过期时间,就可以保证后端数据库的安全。
缓存空对象会占用额外的缓存空间,还会有数据不一致的时间窗口,所以第二种方法就是针对大数据量的、有规律的键值,使用布隆过滤器进行处理。一条记录存在与不存在,是一个 Bool 值,只需要使用 1 比特就可存储。布隆过滤器就可以把这种是、否操作,压缩到一个数据结构中。比如手机号,用户性别这种数据,就非常适合使用布隆过滤器。 - 缓存击穿:指的也是用户请求落在数据库上的情况,大多数情况,是由于缓存时间批量过期引起的。我们一般会对缓存中的数据,设置一个过期时间。如果在某个时刻从数据库获取了大量数据,并设置了同样的过期时间,它们将会在同一时刻失效,造成和缓存的击穿。
解决方案:
对于比较热点的数据,我们就可以设置它不过期;或者在访问的时候,更新它的过期时间;批量入库的缓存项,也尽量分配一个比较平均的过期时间,避免同一时间失效。 - 缓存雪崩:缓存是用来对系统加速的,后端的数据库只是数据的备份,而不是作为高可用的备选方案。当缓存系统出现故障,流量会瞬间转移到后端的数据库。过不了多久,数据库将会被大流量压垮挂掉,这种级联式的服务故障,可以形象地称为雪崩。
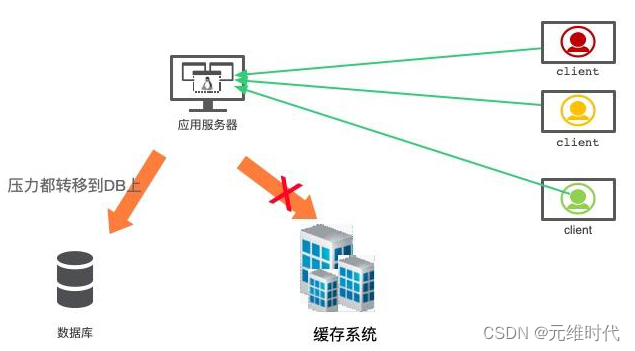
解决方案:Redis 提供了主从和 Cluster 的模式,其中 Cluster 模式使用简单,每个分片也能单独做主从,可以保证极高的可用性。另外,我们对数据库的性能瓶颈有一个大体的评估。如果缓存系统当掉,那么流向数据库的请求,就可以使用限流组件,将请求拦截在外面。
(3)缓存一致性
我们首先来看问题是怎么发生的。对于一个缓存项来说,常用的操作有四个:写入、更新、读取、删除。
- 写入:缓存和数据库是两个不同的组件,只要涉及双写,就存在只有一个写成功的可能性,造成数据不一致。
- 更新:更新的情况类似,需要更新两个不同的组件。
- 读取:读取要保证从缓存中读到的信息是最新的,是和数据库中的是一致的。
- 删除:当删除数据库记录的时候,如何把缓存中的数据也删掉?
由于业务逻辑大多数情况下,是比较复杂的。其中的更新操作,就非常昂贵,比如一个用户的余额,就是通过计算一系列的资产算出来的一个数。如果这些关联的资产,每个地方改动的时候,都去刷新缓存,那代码结构就会非常混乱,以至于无法维护。
推荐使用触发式的缓存一致性方式,使用懒加载的方式,可以让缓存的同步变得非常简单:
- 当读取缓存的时候,如果缓存里没有相关数据,则执行相关的业务逻辑,构造缓存数据存入到缓存系统;
- 当与缓存项相关的资源有变动,则先删除相应的缓存项,然后再对资源进行更新,这个时候,即使是资源更新失败,也是没有问题的。
这种操作,除了编程模型简单,有一个明显的好处。我只有在用到这个缓存的时候,才把它加载到缓存系统中。如果每次修改 都创建、更新资源,那缓存系统中就会存在非常多的冷数据。但这样还是有问题。我们上面提到的缓存删除动作,和数据库的更新动作,明显是不在一个事务里的。如果一个请求删除了缓存,同时有另外一个请求到来,此时发现没有相关的缓存项,就从数据库里加载了一份到缓存系统。接下来,数据库的更新操作也完成了,此时数据库的内容和缓存里的内容,就产生了不一致。
解决方案:可以使用分布式锁来解决这个问题,将缓存操作和数据库删除操作,与其他的缓存读操作,使用锁进行资源隔离即可。一般来说,读操作是不需要加锁的,它会在遇到锁的时候,重试等待,直到超时。
3、池化策略
在我们平常的编码中,通常会将一些对象保存起来,这主要考虑的是对象的创建成本。比如像线程资源、数据库连接资源或者 TCP 连接等,这类对象的初始化通常要花费比较长的时间,如果频繁地申请和销毁,就会耗费大量的系统资源,造成不必要的性能损失。
并且这些对象都有一个显著的特征,就是通过轻量级的重置工作,可以循环、重复地使用。这个时候,我们就可以使用一个虚拟的池子,将这些资源保存起来,当使用的时候,我们就从池子里快速获取一个即可。
在 Java 中,池化技术应用非常广泛,常见的就有数据库连接池、线程池等。
(1)公用池化包 Commons Pool 2.0
GenericObjectPool 是对象池的核心类,通过传入一个对象池的配置和一个对象的工厂,即可快速创建对象池。
public GenericObjectPool(
final PooledObjectFactory<T> factory,
final GenericObjectPoolConfig<T> config)
- 1
- 2
- 3
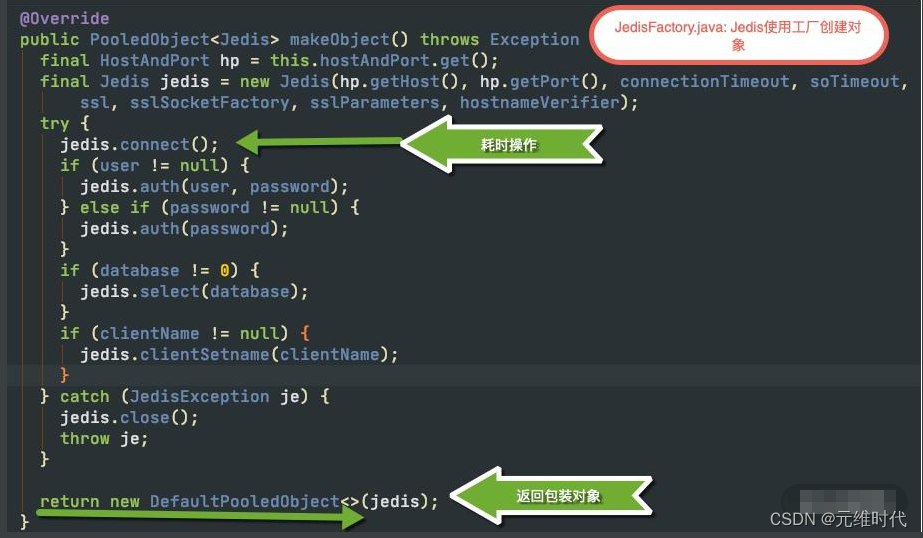
Redis 的常用客户端 Jedis,就是使用 Commons Pool 管理连接池的,可以说是一个最佳实践。下图是 Jedis 使用工厂创建对象的主要代码块。对象工厂类最主要的方法就是makeObject,它的返回值是 PooledObject 类型,可以将对象使用 new DefaultPooledObject<>(obj) 进行简单包装返回。
我们再来介绍一下对象的生成过程,如下图,对象在进行获取时,将首先尝试从对象池里拿出一个,如果对象池中没有空闲的对象,就使用工厂类提供的方法,生成一个新的。
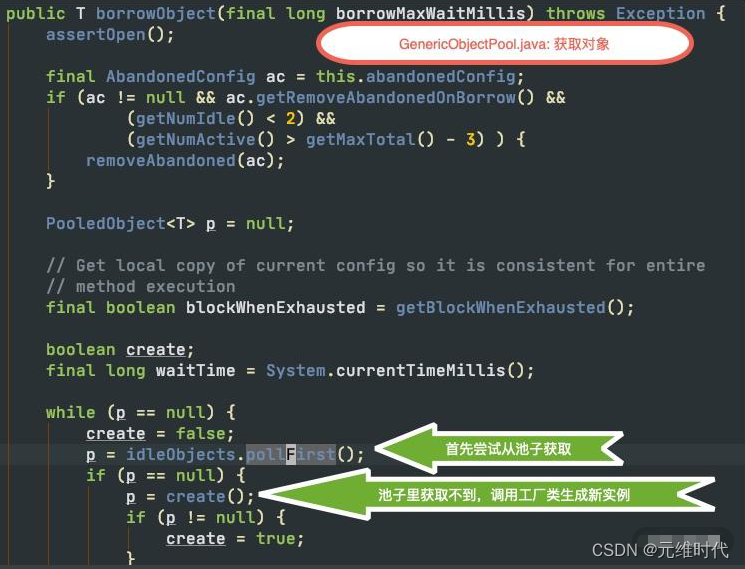
那对象是存在什么地方的呢?这个存储的职责,就是由一个叫作 LinkedBlockingDeque的结构来承担的,它是一个双向的队列。
一个池化对象在整个池子中的生命周期。如下图所示,池子的操作主要有两个:一个是业务线程,一个是检测线程。
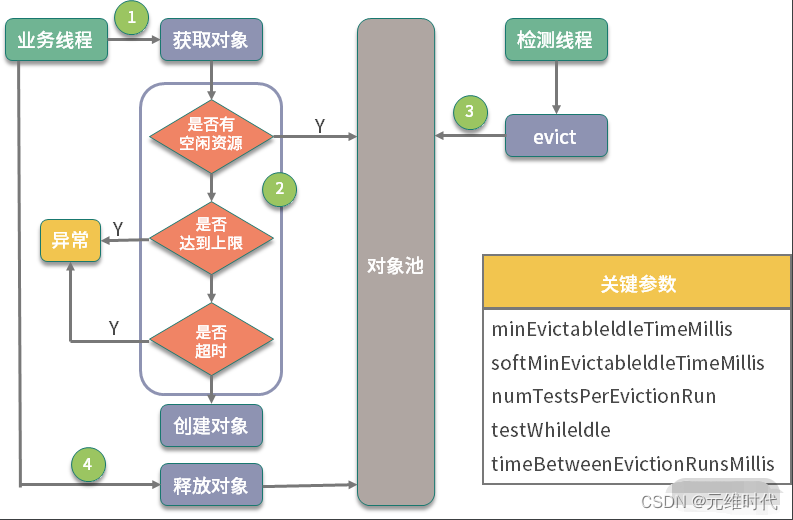
对象池在进行初始化时,要指定三个主要的参数:
- maxTotal 对象池中管理的对象上限
- maxIdle 最大空闲数
- minIdle 最小空闲数
其中 maxTotal 和业务线程有关,当业务线程想要获取对象时,会首先检测是否有空闲的对象。如果有,则返回一个;否则进入创建逻辑。此时,如果池中个数已经达到了最大值,就会创建失败,返回空对象。对象在获取的时候,有一个非常重要的参数,那就是最大等待时间(maxWaitMillis),这个参数对应用方的性能影响是比较大的。该参数默认为 -1,表示永不超时,直到有对象空闲。
如果对象创建非常缓慢或者使用非常繁忙,业务线程会持续阻塞 (blockWhenExhausted 默认为 true),进而导致正常服务也不能运行。
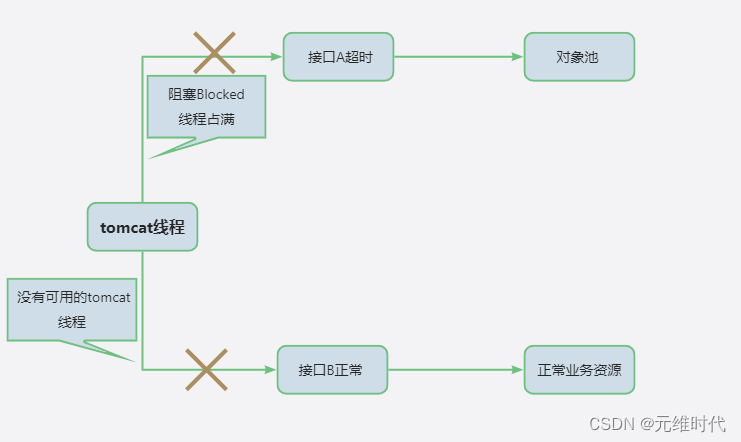
这种情况需要设置最大等待时间,设置成接口可以忍受的最大延迟。比如,一个正常服务响应时间 10ms 左右,达到 1 秒钟就会感觉到卡顿,那么这个参数设置成 500~1000ms 都是可以的。超时之后,会抛出 NoSuchElementException 异常,请求会快速失败,不会影响其他业务线程,这种 Fail Fast 的思想,应用也很广泛。
(2)数据库连接池 HikariCP
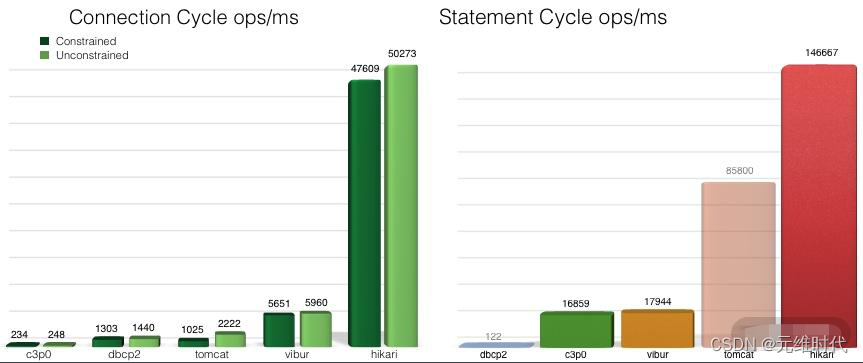
HikariCP 源于日语“光”的意思(和光速一样快),它是 SpringBoot 中默认的数据库连接池。数据库是我们工作中经常使用到的组件,针对数据库设计的客户端连接池是非常多的,它的设计原理也是池化思想,可以有效地减少数据库连接创建、销毁的资源消耗。
同是连接池,它们的性能也是有差别的,下图是 HikariCP 官方的一张测试图,可以看到它优异的性能:
HikariCP 为什么快呢?主要有三个方面:
- 它使用 FastList 替代 ArrayList,通过初始化的默认值,减少了越界检查的操作;
- 优化并精简了字节码,通过使用 Javassist,减少了动态代理的性能损耗,比如使用 invokestatic 指令代替 invokevirtual 指令;
- 实现了无锁的 ConcurrentBag,减少了并发场景下的锁竞争。
(3)考虑使用池化来增加系统性能的场景
- 对象的创建或者销毁,需要耗费较多的系统资源;
- 对象的创建或者销毁,耗时长,需要繁杂的操作和较长时间的等待;
- 对象创建后,通过一些状态重置,可被反复使用。
将对象池化之后,只是开启了第一步优化。要想达到最优性能,就不得不调整池的一些关键参数,合理的池大小加上合理的超时时间,就可以让池发挥更大的价值。和缓存的命中率类似,对池的监控也是非常重要的。
4、用设计模式优化性能
- 代理模式:Java 中实现动态代理主要有两种模式:一种是使用 JDK,另外一种是使用 CGLib。
其中,JDK 方式是面向接口的,主 要的相关类是 InvocationHandler 和 Proxy;
CGLib 可以代理普通类,主要的相关类是 MethodInterceptor 和 Enhancer。 - 单例模式:Spring 在创建组件的时候,可以通过 scope 注解指定它的作用域,用来标示这是一个prototype(多例)还是 singleton(单例)。
- 享元模式:专门针对性能优化的设计模式,它通过共享技术,最大限度地复用对象。
- 原型模式:比较类似于复制粘贴的思想,它可以首先创建一个实例,然后通过这个实例进行新对象的创建。在 Java 中,最典型的就是 Object 类的 clone 方法。
5、大对象处理
这里的“大对象”,是一个泛化概念,它可能存放在 JVM 中,也可能正在网络上传输,也可能存在于数据库中。
1、大对象影响应用性能的原因
- 第一,大对象占用的资源多,垃圾回收器要花一部分精力去对它进行回收;
- 第二,大对象在不同的设备之间交换,会耗费网络流量,以及昂贵的 I/O;
- 第三,对大对象的解析和处理操作是耗时的,对象职责不聚焦,就会承担额外的性能开销。
结合我们前面提到的缓存,以及对象的池化操作,加上对一些中间结果的保存,我们能够对大对象进行初步的提速。
2、集合大对象扩容
对象扩容,在 Java 中是司空见惯的现象,比如 StringBuilder、StringBuffer、HashMap,ArrayList 等。概括来讲,Java 的集合,包括 List、Set、Queue、Map 等,其中的数据都不可控。在容量不足的时候,都会有扩容操作,扩容操作需要重新组织数据,所以都不是线程安全的。
StringBuilder 的扩容代码:
void expandCapacity(int minimumCapacity) {
int newCapacity = value.length * 2 + 2;
if (newCapacity - minimumCapacity < 0)
newCapacity = minimumCapacity;
if (newCapacity < 0) {
if (minimumCapacity < 0) // overflow
throw new OutOfMemoryError();
newCapacity = Integer.MAX_VALUE;
}
value = Arrays.copyOf(value, newCapacity);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
容量不够的时候,会将内存翻倍,并使用 Arrays.copyOf 复制源数据。
下面是 HashMap 的扩容代码,扩容后大小也是翻倍。它的扩容动作就复杂得多,除了有负载因子的影响,它还需要把原来的数据重新进行散列,由于无法使用 native 的 Arrays.copy 方法,速度就会很慢。
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
Entry[] newTable = new Entry[newCapacity];
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
List 的代码大家可自行查看,也是阻塞性的,扩容策略是原长度的 1.5 倍。
由于集合在代码中使用的频率非常高,如果你知道具体的数据项上限,那么不妨设置一个合理的初始化大小。比如,HashMap 需要 1024 个元素,需要 7 次扩容,会影响应用的性能。
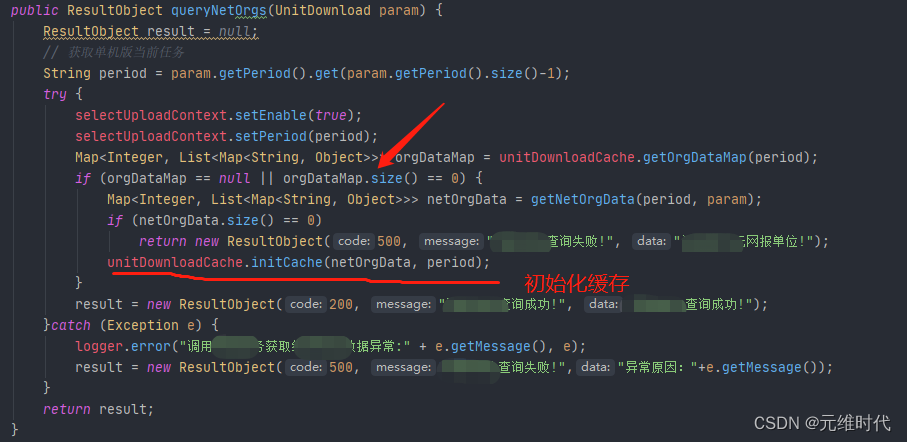
案例:RPC远程获取“任务定义”大对象的部分信息,只获取有效信息即可。
应用背景:数据量达到200W+的时候,一次单位下载就要耗时一个多小时。
//远程调用网报服务
Map<String, String> taskInfoMap = null;
try {
taskInfoMap = unitDownloadFeign.getTaskInfo(taskCode, param.getFormSchemeKey(), param.getToken());
} catch (Exception e) {
logger.error("远程调用网报服务异常:" + e.getMessage(), e);
result = new ResultObject(500, "远程调用网报服务异常:" + e.getMessage(), map);
return result;
}
if (taskInfoMap.size() == 0) {
result = new ResultObject(500, "网报中未匹配到标识一致的任务!", map);
return result;
}
String netEntityId = taskInfoMap.get("entityId");
String netTaskTitle = taskInfoMap.get("taskTitle");
String netOrgName = taskInfoMap.get("orgName");
String netVersionStr = taskInfoMap.get("version");
String hasFmdm = taskInfoMap.get("hasFmdm");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
批量处理数据:每5000条记录存储在一个clob字段中
private void generateDetails(UnitDownloadLog downloadLog, UnitLog unitLog) {
// 日志详情表
Detail detail = new Detail();
detail.setLogId(downloadLog.getKey());
ObjectMapper mapper = new ObjectMapper();
String addUnit;
String updateUnit;
String failUnit;
String failReason;
try {
// 单位数量小于等于5000,一次性写入数据库表中
if (lessFiveThousand(unitLog.getAddUintList()) && lessFiveThousand(unitLog.getUpdateUnitList()) && lessFiveThousand(unitLog.getFailUnitList()) && lessFiveThousand(unitLog.getFailReasonList())) {
detail.setId(UUID.randomUUID().toString());
List<String> addUintList = unitLog.getAddUintList();
addUnit = mapper.writeValueAsString(addUintList);
detail.setAddUnit(addUnit);
unitLog.getAddUintList().removeAll(addUintList);
List<String> updateUnitList = unitLog.getUpdateUnitList();
updateUnit = mapper.writeValueAsString(updateUnitList);
detail.setUpdateUnit(updateUnit);
unitLog.getUpdateUnitList().removeAll(updateUnitList);
List<String> failUnitList = unitLog.getFailUnitList();
failUnit = mapper.writeValueAsString(failUnitList);
detail.setFailUnit(failUnit);
unitLog.getFailUnitList().removeAll(failUnitList);
List<String> failReasonList = unitLog.getFailReasonList();
failReason = mapper.writeValueAsString(failReasonList);
detail.setFailReason(failReason);
unitLog.getFailReasonList().removeAll(failReasonList);
// 入库
detailsDao.insertDetail(detail);
} else {
// 分批次,每次5000条数据,写入数据库表中
detail.setId(UUID.randomUUID().toString());
List<String> addList;
if (!lessFiveThousand(unitLog.getAddUintList())) {
addList = unitLog.getAddUintList().subList(0, DownloadConst.FIVE_THOUSAND);
} else {
addList = unitLog.getAddUintList();
}
detail.setAddUnit(mapper.writeValueAsString(addList));
unitLog.getAddUintList().removeAll(addList);
List<String> updateList;
if (!lessFiveThousand(unitLog.getUpdateUnitList())) {
updateList = unitLog.getUpdateUnitList().subList(0, DownloadConst.FIVE_THOUSAND);
} else {
updateList = unitLog.getUpdateUnitList();
}
detail.setUpdateUnit(mapper.writeValueAsString(updateList));
unitLog.getUpdateUnitList().removeAll(updateList);
List<String> failList;
if (!lessFiveThousand(unitLog.getFailUnitList())) {
failList = unitLog.getFailUnitList().subList(0, DownloadConst.FIVE_THOUSAND);
} else {
failList = unitLog.getFailUnitList();
}
detail.setFailUnit(mapper.writeValueAsString(failList));
unitLog.getFailUnitList().removeAll(failList);
List<String> reasonList;
if (!lessFiveThousand(unitLog.getFailReasonList())) {
reasonList = unitLog.getFailReasonList().subList(0, DownloadConst.FIVE_THOUSAND);
} else {
reasonList = unitLog.getFailReasonList();
}
detail.setFailReason(mapper.writeValueAsString(reasonList));
unitLog.getFailReasonList().removeAll(reasonList);
// 入库
detailsDao.insertDetail(detail);
generateDetails(downloadLog, unitLog);
}
} catch (JsonProcessingException e) {
logger.error("单位下载,生成日志详情异常:" + e.getMessage(), e);
throw new RuntimeException(e);
} catch (DBParaException e) {
throw new RuntimeException(e);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
6、并行计算
(1)并行获取数据
在我们的平常的业务中,有计算密集型任务和 I/O 密集型任务之分。
- I/O 密集型任务
对于我们常见的互联网服务来说,大多数是属于 I/O 密集型的,比如等待数据库的 I/O,等待网络 I/O 等。在这种情况下,当线程数量等于 I/O 任务的数量时,效果是最好的。虽然线程上下文切换会有一定的性能损耗,但相对于缓慢的 I/O 来说,这点损失是可以接受的。 - 计算密集型任务
计算密集型的任务却正好相反,比如一些耗时的算法逻辑。CPU 要想达到最高的利用率,提高吞吐量,最好的方式就是:让它尽量少地在任务之间切换,此时,线程数等于 CPU 数量,是效率最高的。
核心线程数另一种结论:
- CPU密集型:CPU核数+1
- IO密集型:CPU核数*2
动态获取CPU核数方法:
Runtime.getRuntime().availableProcessors()
- 1
生产环境案例:同步8张表的数据
private AtomicInteger syncDataFromDesToRunByAsync () {
AtomicInteger tableCount = new AtomicInteger();
ExecutorService poolExecutor = Executors.newFixedThreadPool(8);
CompletableFuture<Void> versionTask = CompletableFuture.runAsync(() -> {
// 清除运行期数据
DiyDataSourceUtils.execute(jdbcTemplate, String.format("delete from %s", YthConst.TABLE_YTH_VERSION));
// insert into 运行期表 select * from 设计期表:insert into yth_table select * from yth_table_des
DiyDataSourceUtils.execute(jdbcTemplate, String.format("insert into %s select * from %s", YthConst.TABLE_YTH_VERSION, YthConst.TABLE_YTH_VERSION_DES));
tableCount.getAndIncrement();
logger.info("(1).同步[{}]表数据成功", YthConst.TABLE_YTH_VERSION);
}, poolExecutor);
CompletableFuture<Void> tableTask = CompletableFuture.runAsync(() -> {
DiyDataSourceUtils.execute(jdbcTemplate, String.format("delete from %s", YthConst.YTH_TABLE));
DiyDataSourceUtils.execute(jdbcTemplate, String.format("insert into %s select * from %s", YthConst.YTH_TABLE, YthConst.YTH_TABLE_DES));
tableCount.getAndIncrement();
logger.info("(2).同步[{}]表数据成功", YthConst.YTH_TABLE);
},
poolExecutor);
CompletableFuture<Void> fieldTask = CompletableFuture.runAsync(() -> {
DiyDataSourceUtils.execute(jdbcTemplate, String.format("delete from %s", YthConst.TABLE_YTH_FIELD));
DiyDataSourceUtils.execute(jdbcTemplate, String.format("insert into %s select * from %s", YthConst.TABLE_YTH_FIELD, YthConst.TABLE_YTH_FIELD_DES));
tableCount.getAndIncrement();
logger.info("(3).同步[{}]表数据成功", YthConst.TABLE_YTH_FIELD);
},
poolExecutor);
CompletableFuture<Void> indexTask = CompletableFuture.runAsync(() -> {
DiyDataSourceUtils.execute(jdbcTemplate, String.format("delete from %s", YthConst.TABLE_YTH_INDEX));
DiyDataSourceUtils.execute(jdbcTemplate, String.format("insert into %s select * from %s", YthConst.TABLE_YTH_INDEX, YthConst.TABLE_YTH_INDEX_DES));
tableCount.getAndIncrement();
logger.info("(4).同步[{}]表数据成功", YthConst.TABLE_YTH_INDEX);
},
poolExecutor);
CompletableFuture<Void> groupTask = CompletableFuture.runAsync(() -> {
DiyDataSourceUtils.execute(jdbcTemplate, String.format("delete from %s", YthConst.TABLE_YTH_TABLE_GROUP));
DiyDataSourceUtils.execute(jdbcTemplate, String.format("insert into %s select * from %s", YthConst.TABLE_YTH_TABLE_GROUP, YthConst.TABLE_YTH_TABLE_GROUP_DES));
tableCount.getAndIncrement();
logger.info("(5).同步[{}]表数据成功", YthConst.TABLE_YTH_TABLE_GROUP);
},
poolExecutor);
CompletableFuture<Void> rangeTask = CompletableFuture.runAsync(() -> {
DiyDataSourceUtils.execute(jdbcTemplate, String.format("delete from %s", YthConst.TABLE_YTH_RANGE));
DiyDataSourceUtils.execute(jdbcTemplate, String.format("insert into %s select * from %s", YthConst.TABLE_YTH_RANGE, YthConst.TABLE_YTH_RANGE_DES));
tableCount.getAndIncrement();
logger.info("(6).同步[{}]表数据成功", YthConst.TABLE_YTH_RANGE);
},
poolExecutor);
CompletableFuture<Void> codesetTask = CompletableFuture.runAsync(() -> {
DiyDataSourceUtils.execute(jdbcTemplate, String.format("delete from %s", YthConst.TABLE_YTH_CODESET));
DiyDataSourceUtils.execute(jdbcTemplate, String.format("insert into %s select * from %s", YthConst.TABLE_YTH_CODESET, YthConst.TABLE_YTH_CODESET_DES));
tableCount.getAndIncrement();
logger.info("(7).同步[{}]表数据成功", YthConst.TABLE_YTH_CODESET);
},
poolExecutor);
CompletableFuture<Void> codeTask = CompletableFuture.runAsync(() -> {
DiyDataSourceUtils.execute(jdbcTemplate, String.format("delete from %s", YthConst.TABLE_YTH_CODE));
DiyDataSourceUtils.execute(jdbcTemplate, String.format("insert into %s select * from %s", YthConst.TABLE_YTH_CODE, YthConst.TABLE_YTH_CODE_DES));
tableCount.getAndIncrement();
logger.info("(8).同步[{}]表数据成功", YthConst.TABLE_YTH_CODE);
},
poolExecutor);
// allOf : 等待所有任务完成完成,是阻塞式等待,等待上面的异步任务都完成,注意join()方法抛出的是uncheck异常(即RuntimeException),不会强制开发者抛出,
CompletableFuture.allOf(tableTask, versionTask, fieldTask, indexTask, groupTask, rangeTask, codesetTask, codeTask).join();
// 关闭线程池
poolExecutor.shutdown();
return tableCount;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
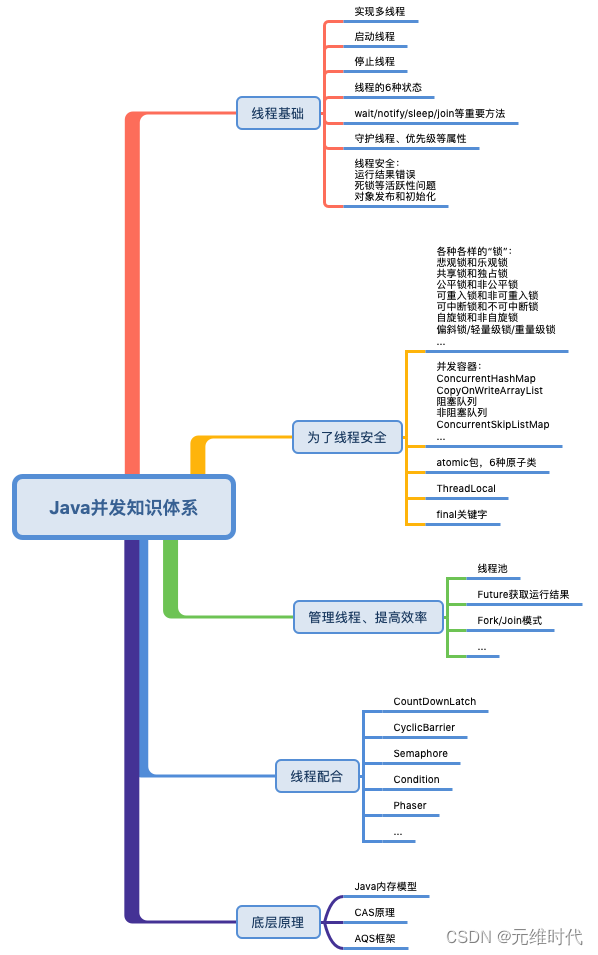
(2)从池化对象原理看线程池
线程的资源也是比较昂贵的,频繁地创建和销毁同样会影响系统性能。
任务的创建过程:
(3)在 SpringBoot 中如何使用异步
需要在启动类上加上 @EnableAsync 注解,然后在需要异步执行的方法上加上 @Async 注解。
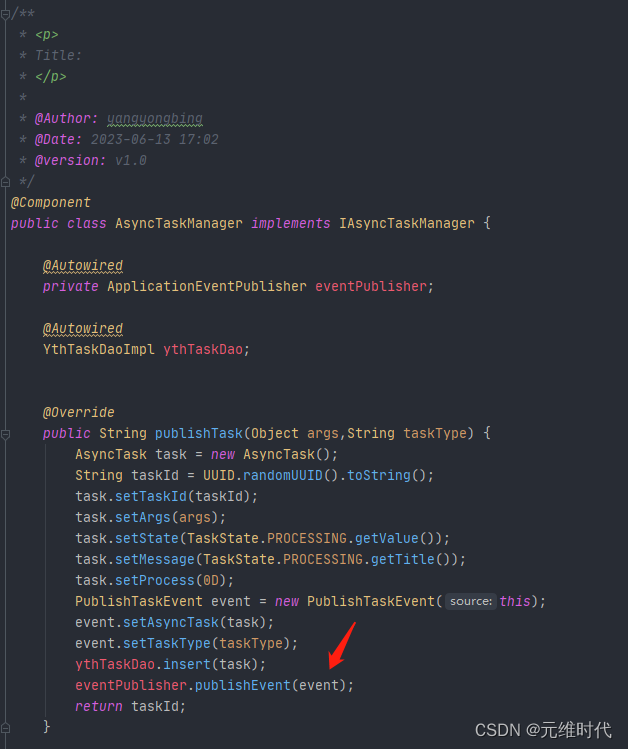
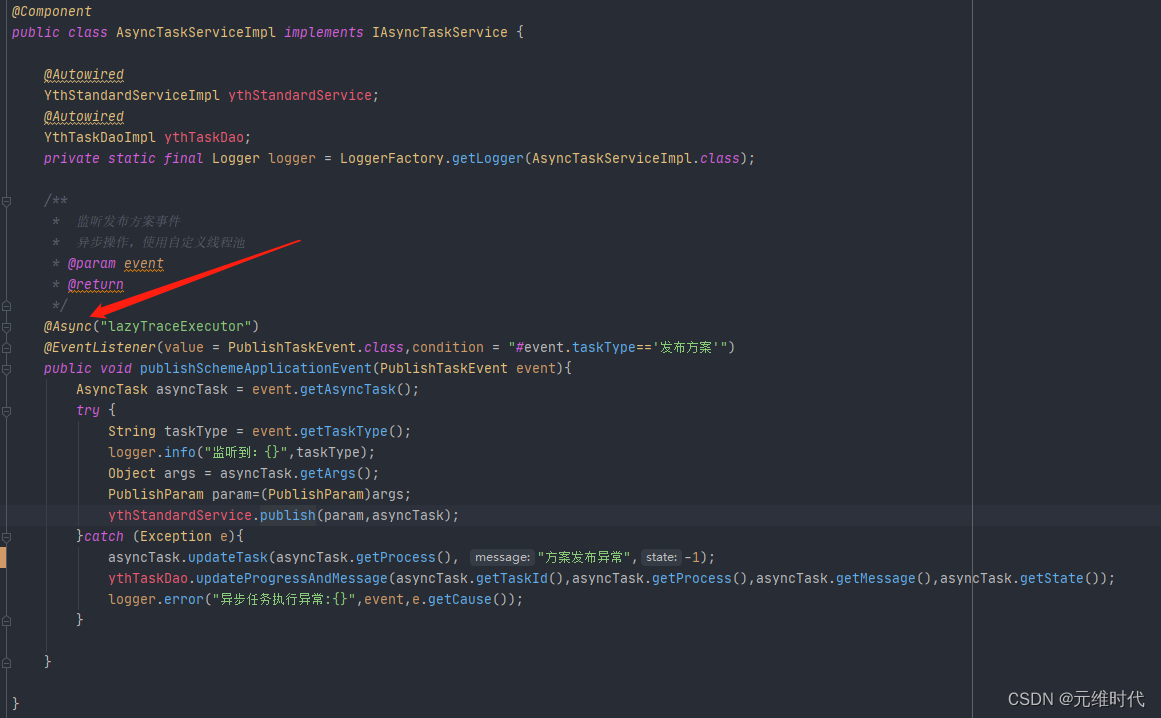
默认情况下,Spring 将启动一个默认的线程池供异步任务使用。这个线程池也是无限大的,资源使用不可控,所以强烈建议你使用代码设置一个适合自己的。
异步是一种编程模型,它通过将耗时的操作转移到后台线程运行,从而减少对主业务的堵塞,所以我们说异步让速度变快了。但如果你的系统资源使用已经到了极限,异步就不能产生任何效果了,它主要优化的是那些阻塞性的等待。
(4)使用多线程注意点
- StringBuilder 对应着 StringBuffer。后者主要是通过 synchronized 关键字实现了线程的同步。值得注意的是,在单个方法区域里,这两者是没有区别的,JIT 的编译优化会去掉 synchronized 关键字的影响。
- HashMap 对应着 ConcurrentHashMap。ConcurrentHashMap 的话题很大,这里提醒一下 JDK1.7 和 1.8 之间的实现已经不一样了。1.8 已经去掉了分段锁的概念(锁分离技术),并且使用 synchronized 来代替了 ReentrantLock。
- ArrayList 对应着 CopyOnWriteList。后者是写时复制的概念,适合读多写少的场景。
- LinkedList 对应着 ArrayBlockingQueue。ArrayBlockingQueue 对默认是不公平锁,可以修改构造参数,将其改成公平阻塞队列,它在 concurrent 包里使用得非常频繁。
- HashSet 对应着 CopyOnWriteArraySet。
(5)线程安全的重要性举例
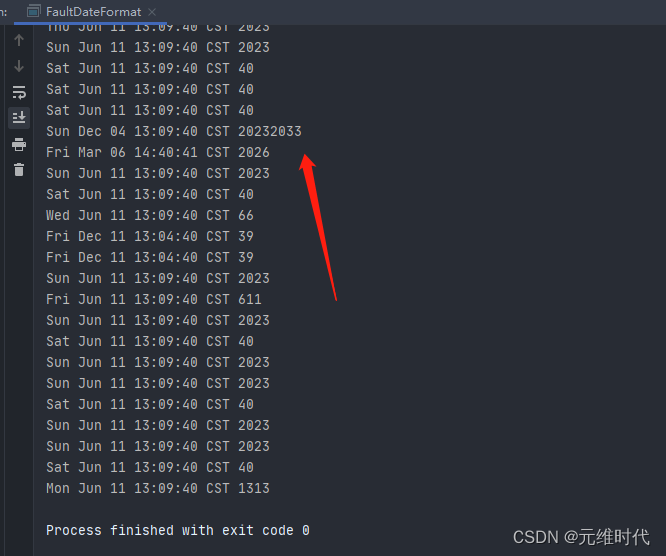
SimpleDateFormat 是我们经常用到的日期处理类,但它本身不是线程安全的,在多线程运行环境下,会产生很多问题。
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* <p>
* Title:
* </p>
*
* @Author: yangyongbing
* @Date: 2023-06-11 13:03
* @version: v1.0
*/
public class FaultDateFormat {
SimpleDateFormat format=new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public static void main(String[] args) {
final FaultDateFormat faultDateFormat=new FaultDateFormat();
ExecutorService executor = Executors.newCachedThreadPool();
for(int i=0;i<1000;i++){
executor.submit(()->{
try {
System.out.println(faultDateFormat.format.parse("2023-06-11 13:09:40"));
} catch (ParseException e) {
e.printStackTrace();
}
});
}
executor.shutdown();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
执行上图的代码,可以看到,时间已经错乱了。
解决方式就是使用 ThreadLocal 局部变量,代码如下图所示,可以有效地解决线程安全问题。
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* <p>
* Title:
* </p>
* * @Author: yangyongbing
* @Date: 2023-06-14 13:12
* @version: v1.0
*/
public class GoodDateFormat {
ThreadLocal<SimpleDateFormat> format= ThreadLocal.withInitial(() -> new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"));
public static void main(String[] args) {
final GoodDateFormat goodDateFormat=new GoodDateFormat();
ExecutorService executor = Executors.newCachedThreadPool();
for(int i=0;i<1000;i++){
executor.submit(()->{
try {
System.out.println(goodDateFormat.format.get().parse("2023-06-11 13:09:40"));
} catch (ParseException e) {
e.printStackTrace();
}
});
}
executor.shutdown();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
(6)线程的同步方式
- 使用 Object 类中的 wait、notify、notifyAll 等函数。由于这种编程模型非常复杂,现在已经很少用了。这里有一个关键点,那就是对于这些函数的调用,必须放在同步代码块里才能正常运行。
- 使用 ThreadLocal 线程局部变量的方式,每个线程一个变量。
- 使用 synchronized 关键字修饰方法或者代码块。这是 Java 中最常见的方式,有锁升级的概念。
- 使用 Concurrent 包里的可重入锁 ReentrantLock。使用 CAS 方式实现的可重入锁。
- 使用 volatile 关键字控制变量的可见性,这个关键字保证了变量的可见性,但不能保证它的原子性。
- 使用线程安全的阻塞队列完成线程同步。比如,使用 LinkedBlockingQueue 实现一个简单的生产者消费者。
- 使用原子变量。Atomic* 系列方法,也是使用 CAS 实现的。
- 使用 Thread 类的 join 方法,可以让多线程按照指定的顺序执行。
7、锁的优化
(1)加锁示例
来避免 SimpleDateFormat 在并发环境下引起的时间错乱问题。其实还有一种解决方式,就是通过对parse 方法进行加锁,也能保证日期处理类的正确运行
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* <p>
* Title:
* </p>
* * @Author: yangyongbing
* @Date: 2023-06-11 13:32
* @version: v1.0
*/
public class ThreadSafeDateFormat {
SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
public static void main(String[] args) {
final ThreadSafeDateFormat threadSafeDateFormat = new ThreadSafeDateFormat();
ExecutorService executor = Executors.newCachedThreadPool();
for (int i = 0; i < 1000; i++) {
executor.submit(() -> {
try {
synchronized (threadSafeDateFormat) {
System.out.println(threadSafeDateFormat.format.parse("2023-06-11 13:09:40"));
}
} catch (ParseException e) {
e.printStackTrace();
}
});
}
executor.shutdown();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
锁对性能的影响,是非常大的。因为对资源加锁以后,资源就被加锁的线程独占,其他的线程就只能排队等待这个锁,此时程序由并行执行,变相地成了顺序执行,执行速度自然就降低了。
(2)加锁的方式
Java 中有两种加锁的方式:一种就是常见的synchronized 关键字,另外一种,就是使用 concurrent 包里面的 Lock。针对这两种锁,JDK 自身做了很多的优化,它们的实现方式也是不同的。
第一种:synchronied关键字
synchronized 关键字给代码或者方法上锁时,都有显示或者隐藏的上锁对象。当一个线程试图访问同步代码块时,它首先必须得到锁,而退出或抛出异常时必须释放锁。
- 给普通方法加锁时,上锁的对象是 this;
- 给静态方法加锁时,锁的是 class 对象;
- 给代码块加锁,可以指定一个具体的对象作为锁;
分级锁:
在 JDK 1.8 中,synchronized 的速度已经有了显著的提升,它都做了哪些优化呢?答案就是分级锁。JVM 会根据使用情况,对 synchronized 的锁,进行升级,它大体可以按照下面的路径进行升级:偏向锁 — 轻量级锁 — 重量级锁。
锁只能升级,不能降级,所以一旦升级为重量级锁,就只能依靠操作系统进行调度。
第二种:Lock
1.主要方法
Lock 是基于 AQS(AbstractQueuedSynchronizer)实现的,而 AQS 是基于 volitale 和 CAS 实现的。
Lock 与 synchronized 的使用方法不同,它需要手动加锁,然后在 finally 中解锁。Lock 接口比 synchronized 灵活性要高,我们来看一下几个关键方法。
- Lock: Lock 方法和 synchronized 没什么区别,如果获取不到锁,都会被阻塞;
- tryLock: 此方法会尝试获取锁,不管能不能获取到锁,都会立即返回,不会阻塞,它是有返回值的,获取到锁就会返回 true;
- tryLock(long time, TimeUnit unit): 与 tryLock 类似,但它在拿不到锁的情况下,会等待一段时间,直到超时;
- LockInterruptibly: 与 Lock 类似,但是可以锁等待,可以被中断,中断后返回 InterruptedException;
一般情况下,使用 Lock 方法就可以;但如果业务请求要求响应及时,那使用带超时时间的tryLock是更好的选择:我们的业务可以直接返回失败,而不用进行阻塞等待。
tryLock 这种优化手段,采用降低请求成功率的方式,来保证服务的可用性,在高并发场景下常被高频采用。
2.读写锁
但对于有些业务来说,使用 Lock 这种粗粒度的锁还是太慢了。比如,对于一个HashMap 来说,某个业务是读多写少的场景,这个时候,如果给读操作,也加上和写操作一样的锁的话,效率就会很慢。
ReentrantReadWriteLock 是一种读写分离的锁,它允许多个读线程同时进行,但读和写、写和写是互斥的。
第三种:Redis 分布式锁
Redis分布式锁原理
(3)锁的优化技巧
1.死锁示例
public class DeadLockDemo {
public static void main(String[] args) {
Object object1 = new Object();
Object object2 = new Object();
Thread t1 = new Thread(() -> {
synchronized (object1) {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (object2) {
}
}
}, "deadlock-demo-1");
t1.start();
Thread t2 = new Thread(() -> {
synchronized (object2) {
try {
Thread.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
synchronized (object1) {
}
}
}, "deadlock-demo-2");
t2.start();
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
代码创建了两把对象锁,线程1 首先拿到了 object1 的对象锁,200ms 后尝试获取 object2 的对象锁。但这个时候,object2 的对象锁已经被线程2 获取了。这两个线程进入了相互等待的状态,产生了死锁。
使用我们上面提到的,带超时时间的 tryLock 方法,有一方超时让步,可以一定程度上避免死锁。
2、优化技巧
锁的优化理论其实很简单,那就是减少锁的冲突。无论是锁的读写分离,还是分段锁,本质上都是为了避免多个线程同时获取同一把锁。
所以我们可以总结一下优化的一般思路:减少锁的粒度、减少锁持有的时间、锁分级、锁分离 、锁消除、乐观锁、无锁等。
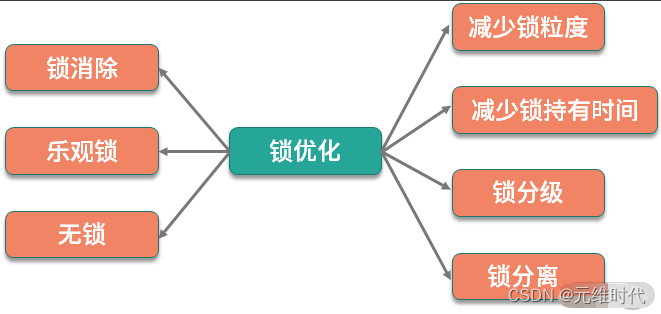
- 减小锁粒度:通过减小锁的粒度,可以将冲突分散,减少冲突的可能,从而提高并发量。简单来说,就是把资源进行抽象,针对每类资源使用单独的锁进行保护。
- 减少锁持有时间:通过让锁资源尽快地释放,减少锁持有的时间,其他线程可更迅速地获取锁资源,进行其他业务的处理。
- 锁分级: Synchronied 锁的锁升级,属于 JVM 的内部优化,它从偏向锁开始,逐渐升级为轻量级锁、重量级锁,这个过程是不可逆的。
- 锁分离:读写锁,就是锁分离技术。这是因为,读操作一般是不会对资源产生影响的,可以并发执行;写操作和其他操作是互斥的,只能排队执行。所以读写锁适合读多写少的场景。
- 锁消除:通过 JIT 编译器,JVM 可以消除某些对象的加锁操作。举个例子,大家都知道StringBuffer 和 StringBuilder 都是做字符串拼接的,而且前者是线程安全的。 但其实,如果这两个字符串拼接对象用在函数内,JVM 通过逃逸分析这个对象的作用范围就是在本函数中,就会把锁的影响给消除掉。
比如下面这段代码,它和 StringBuilder 的效果是一样的。
String m1(){
StringBuffer sb = new StringBuffer();
sb.append("");
return sb.toString();
}
- 1
- 2
- 3
- 4
- 5
(4)Synchronized和Lock对比

Lock 的功能是比 Synchronized 多的,能够对线程行为进行更细粒度的控制。
但如果只是用最简单的锁互斥功能,建议直接使用 Synchronized,有两个原因:
- Synchronized 的编程模型更加简单,更易于使用。
- Synchronized 引入了偏向锁,轻量级锁等功能,能够从 JVM 层进行优化,同时JIT 编译器也会对它执行一些锁消除动作。
8、Java代码优化技巧
1.使用局部变量可避免在堆上分配
由于堆资源是多线程共享的,是垃圾回收器工作的主要区域,过多的对象会造成 GC 压力。可以通过局部变量的方式,将变量在栈上分配。这种方式变量会随着方法执行的完毕而销毁,能够减轻 GC 的压力。
2.减少变量的作用范围
注意变量的作用范围,尽量减少对象的创建。如下面的代码,变量 a 每次进入方法都会创建,可以将它移动到 if 语句内部。
public void test1(String str) {
final int a = 100;
if (!StringUtils.isEmpty(str)) {
int b = a * a;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
3.访问静态变量直接使用类名
有的同学习惯使用对象访问静态变量,这种方式多了一步寻址操作,需要先找到变量对应的类,再找到类对应的变量,如下面的代码:
public class StaticCall {
public static final int A = 1;
void test() {
System.out.println(this.A);
System.out.println(StaticCall.A);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
对应的字节码为:
void test();
descriptor: ()V
flags:
Code:
stack=2, locals=1, args_size=1
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
3: aload_0
4: pop
5: iconst_1
6: invokevirtual #3 // Method java/io/PrintStream.println:(I)V
9: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
12: iconst_1
13: invokevirtual #3 // Method java/io/PrintStream.println:(I)V
16: return
LineNumberTable:
line 5: 0
line 6: 9
line 7: 16
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
4.字符串拼接使用 StringBuilder
字符串拼接,使用 StringBuilder 或者 StringBuffer,不要使用 + 号。比如下面这段代码,在循环中拼接了字符串。
public String test() {
String str = "-1";
for (int i = 0; i < 10; i++) {
str += i;
}
return str;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
从下面对应的字节码内容可以看出,它在每个循环里都创建了一个 StringBuilder 对象。所以,我们在平常的编码中,显式地创建一次即可。
5: iload_2
6: bipush 10
8: if_icmpge 36
11: new #3 // class java/lang/StringBuilder
14: dup
15: invokespecial #4 // Method java/lang/StringBuilder."<init>":()V
18: aload_1
19: invokevirtual #5 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder;
22: iload_2
23: invokevirtual #6 // Method java/lang/StringBuilder.append:(I)Ljava/lang/StringBuilder;
26: invokevirtual #7 // Method java/lang/StringBuilder.toString:()Ljava/lang/String;
29: astore_1
30: iinc 2, 1
33: goto 5
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
5.重写对象的 HashCode,不要简单地返回固定值
重写 HashCode 和 Equals 方法时,会把 HashCode 的值返回固定的 0,而这样做是不恰当的。
当这些对象存入 HashMap 时,性能就会非常低,因为 HashMap 是通过 HashCode 定位到 Hash 槽,有冲突的时候,才会使用链表或者红黑树组织节点。固定地返回 0,相当于把 Hash 寻址功能给废除了。
6.HashMap 等集合初始化的时候,指定初始值大小
通过指定初始值大小可减少扩容造成的性能损耗。
7.遍历 Map 的时候,使用 EntrySet 方法
使用 EntrySet 方法,可以直接返回 set 对象,直接拿来用即可;而使用 KeySet 方法,获得的是key 的集合,需要再进行一次 get 操作,多了一个操作步骤。所以更推荐使用 EntrySet 方式遍历 Map。
8.不要在多线程下使用同一个 Random
Random 类的 seed 会在并发访问的情况下发生竞争,造成性能降低,建议在多线程环境下使用 ThreadLocalRandom 类。
在 Linux 上,通过加入 JVM 配置 -Djava.security.egd=file:/dev/./urandom,使用 urandom 随机生成器,在进行随机数获取时,速度会更快。
9.自增推荐使用 LongAddr
自增运算可以通过 synchronized 和 volatile 的组合,或者也可以使用原子类(比如 AtomicLong)。
后者的速度比前者要高一些,AtomicLong 使用 CAS 进行比较替换,在线程多的情况下会造成过多无效自旋,所以可以使用 LongAdder 替换 AtomicLong 进行进一步的性能提升。
10.不要使用异常控制程序流程
异常,是用来了解并解决程序中遇到的各种不正常的情况,它的实现方式比较昂贵,比平常的条件判断语句效率要低很多。这是因为异常在字节码层面,需要生成一个如下所示的异常表(Exception table),多了很多判断步骤。
Exception table:
from to target type
7 17 20 any
20 23 20 any
- 1
- 2
- 3
- 4
所以,尽量不要使用异常控制程序流程。
11.不要捕捉 RuntimeException
Java 异常分为两种,一种是可以通过预检查机制避免的 RuntimeException;另外一种就是普通异常。其中,RuntimeException 不应该通过 catch 语句去捕捉,而应该使用编码手段进行规避。
如下面的代码,list 可能会出现数组越界异常。是否越界是可以通过代码提前判断的,而不是等到发生异常时去捕捉。提前判断这种方式,代码会更优雅,效率也更高。
//BAD
public String test1(List<String> list, int index) {
try {
return list.get(index);
} catch (IndexOutOfBoundsException ex) {
return null;
}
}
//GOOD
public String test2(List<String> list, int index) {
if (index >= list.size() || index < 0) {
return null;
}
return list.get(index);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
12.合理使用 PreparedStatement
PreparedStatement 使用预编译对 SQL 的执行进行提速,大多数数据库都会努力对这些能够复用的查询语句进行预编译优化,并能够将这些编译结果缓存起来。这样等到下次用到的时候,就可以很快进行执行,也就少了一步对 SQL 的解析动作。
PreparedStatement 还能提高程序的安全性,能够有效防止 SQL 注入。
但如果你的程序每次 SQL 都会变化,不得不手工拼接一些数据,那么 PreparedStatement 就失去了它的作用,反而使用普通的 Statement 速度会更快一些。
13、日志优化
- 同步日志/异步日志
- 日志归档时间
- 日志大小拆分
我们平常会使用 debug 输出一些调试信息,然后在线上关掉它。如下代码:
logger.debug("xjjdog:"+ topic + " is awesome" );
- 1
程序每次运行到这里,都会构造一个字符串,不管你是否把日志级别调试到 INFO 还是 WARN,这样效率就会很低。
可以在每次打印之前都使用 isDebugEnabled 方法判断一下日志级别,代码如下:
if(logger.isDebugEnabled()) {
logger.debug("xjjdog:"+ topic + " is awesome" );
}
- 1
- 2
- 3
使用占位符的方式,也可以达到相同的效果,就不用手动添加 isDebugEnabled 方法了,代码也优雅得多。
logger.debug("xjjdog:{} is awesome" ,topic);
- 1
对于业务系统来说,日志对系统的性能影响非常大,不需要的日志,尽量不要打印,避免占用 I/O 资源。
14.减少事务的作用范围
如果的程序使用了事务,那一定要注意事务的作用范围,尽量以最快的速度完成事务操作。这是因为,事务的隔离性是使用锁实现的。
@Transactional
public void test(String id){
String value = rpc.getValue(id); //高耗时
testDao.update(sql,value);
}
- 1
- 2
- 3
- 4
- 5
如上面的代码,由于 rpc 服务耗时高且不稳定,就应该把它移出到事务之外,改造如下:
public void test(String id){
String value = rpc.getValue(id); //高耗时
testDao(value);
}
@Transactional
public void testDao(String value){
testDao.update(value);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
这里有一点需要注意的地方,由于 SpringAOP 的原因,@Transactional 注解只能用到 public 方法上,如果用到 private 方法上,将会被忽略。
15.使用位移操作替代乘除法
计算机是使用二进制表示的,位移操作会极大地提高性能。
16.不要打印大集合或者使用大集合的 toString 方法
将集合作为字符串输出到日志文件中,这个习惯是非常不好的。拿 ArrayList 来说,它需要遍历所有的元素来迭代生成字符串。在集合中元素非常多的情况下,这不仅会占用大量的内存空间,执行效率也非常慢。
17.程序中减少用反射
反射的功能很强大,但它是通过解析字节码实现的,性能就不是很理想。
现实中有很多对反射的优化方法,比如把反射执行的过程(比如 Method)缓存起来,复用来加快反射速度。
Java 7.0 之后,加入了新的包 java.lang.invoke,同时加入了新的 JVM 字节码指令 invokedynamic,用来支持从 JVM 层面,直接通过字符串对目标方法进行调用。
如果你对性能有非常苛刻的要求,则使用 invoke 包下的 MethodHandle 对代码进行着重优化,但它的编程不如反射方便,在平常的编码中,反射依然是首选。
18.正则表达式可以预先编译,加快速度
Java 的正则表达式需要先编译再使用。典型代码如下:
Pattern pattern = Pattern.compile({pattern});
Matcher pattern = pattern.matcher({content});
- 1
- 2
Pattern 编译非常耗时,它的 Matcher 方法是线程安全的,每次调用方法这个方法都会生成一个新的 Matcher 对象。所以,一般 Pattern 初始化一次即可,可以作为类的静态成员变量。
5、提高数据库读写性能
1、单机数据库
(1) 查询优化
主键查询:千万条记录 1-10ms
唯一索引:千万条记录 10-100ms
非唯一索引:千万条记录 100-1000ms
无索引:百万条记录 1000ms+
(2)批量写优化
for each{insert into table values(1)},性能极差
Exeute once insert into table values (1),(2),(3),(4)…;
批量写优势:
Sql编译N次=>1次的时间与空间复杂度有很大的性能差异
网络消耗的时间复杂度大幅降低
磁盘寻址的复杂度大幅降低
(3)索引优化
索引优化详解
(4) innodb相关优化

慢查询优化案列
2、分布式部署
1、读写分离
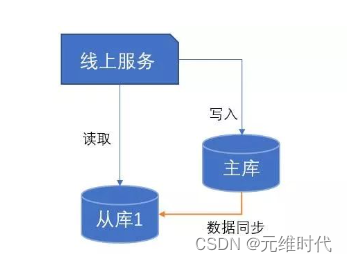
读写分离就是将数据库分为主库和从库,一个主库专用于写入数据,一个或多个从库用于读数据。主库和从库通过某种机制进行数据的同步。
- 一主多从
- 多主多从
- 读库延迟处理
- 主从切换处理
通过一主多从的方式,我们可以将查询请求均匀地分散到多个从数据节点上,来提升系统的查询能力(这里有个小技巧,从数据节点太多的话,可以从主数据节点先同步到一个从数据节点,再从这个从数据节点同步到其他的从数据节点)。
2、分库分表
微服务架构单一数据库设计存在的问题:
- 微服务提供多个类型服务,但单一数据库的传统设计会产生紧密耦合,无法做为独立部署服务。
- 使用单一数据库,对提高应用程序性能成为挑战。当使用单一共享数据库,在一段时间过后,我们最终会有着一个数据庞大的表,让数据检索变得很困难,我们必须连接多个大表格,方能获取所需的数据。
- 随着业务量的加大,数据库访问终将成为性能瓶颈,这个时候多个服务共享一个数据库基本不可行。
从维度来说分成两种,一种是垂直,一种是水平。
-
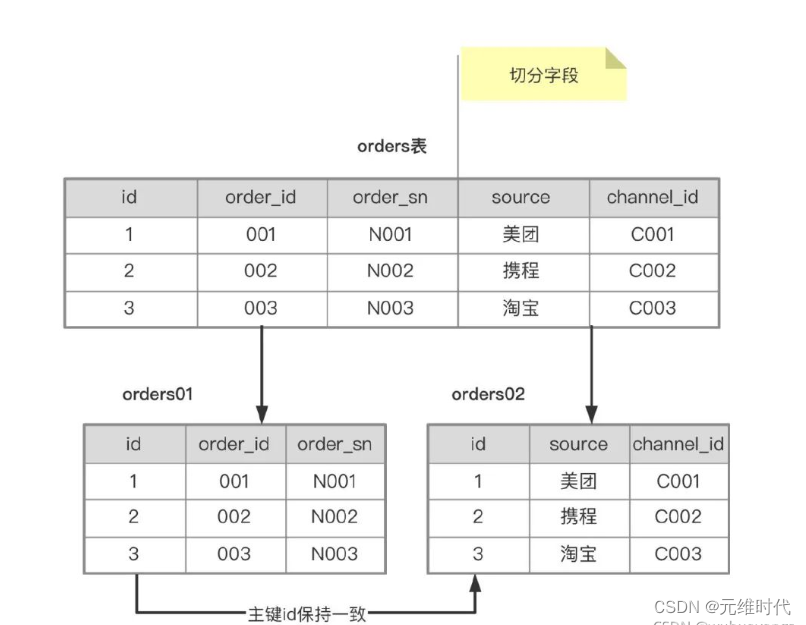
垂直拆分:基于表或字段划分,表结构不同。我们有单库的分表,也有多库的分库。
-
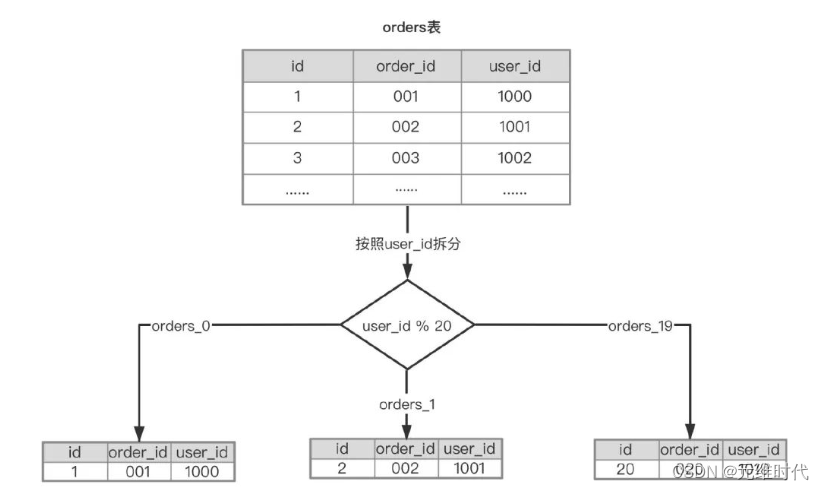
水平拆分:基于数据划分,表结构相同,数据不同,也有同库的水平切分和多库的切分。
6、JVM性能调优
1、 JVM 内存模型
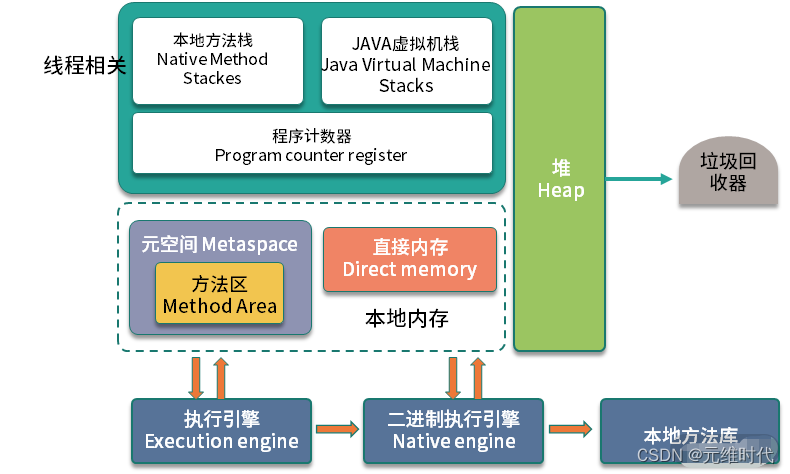
- 堆:如 JVM 内存区域划分图所示,JVM 中占用内存最大的区域,就是堆(Heap),我们平常编码创建的对象,大多数是在这上面分配的,也是垃圾回收器回收的主要目标区域。
- Java 虚拟机栈
JVM 的解释过程是基于栈的,程序的执行过程也就是入栈出栈的过程,这也是 Java 虚拟机栈这个名称的由来。
Java 虚拟机栈是和线程相关的。当你启动一个新的线程,Java 就会为它分配一个虚拟机栈,之后所有这个线程的运行,都会在栈里进行。
Java 虚拟机栈,从方法入栈到具体的字节码执行,其实是一个双层的栈结构,也就是栈里面还包含栈。
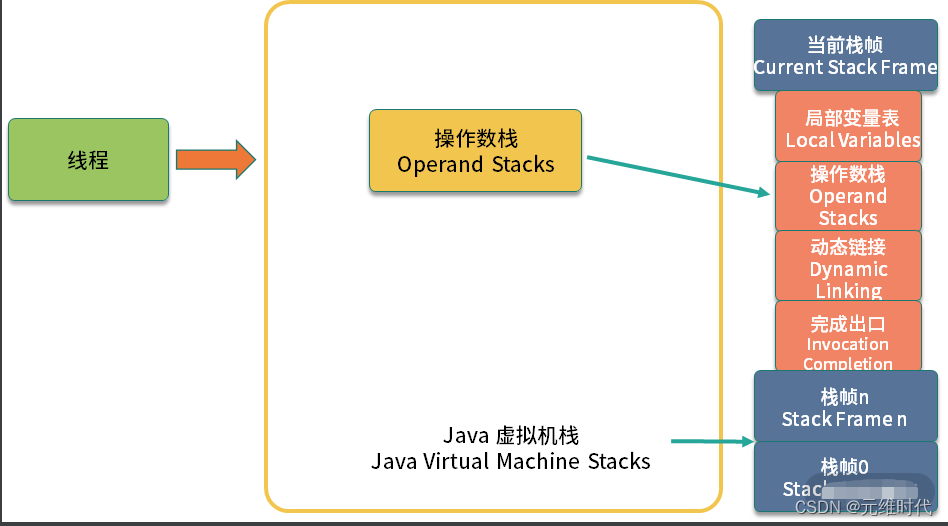 如上图,Java 虚拟机栈里的每一个元素,叫作栈帧。每一个栈帧,包含四个区域: 局部变量表 、操作数栈、动态连接和返回地址。
如上图,Java 虚拟机栈里的每一个元素,叫作栈帧。每一个栈帧,包含四个区域: 局部变量表 、操作数栈、动态连接和返回地址。
其中,操作数栈就是具体的字节码指令所操作的栈区域,考虑到下面这段代码:
public void test(){
int a = 1;
a++;
}
- 1
- 2
- 3
- 4
JVM 将会为 test 方法生成一个栈帧,然后入栈,等 test 方法执行完毕,就会将对应的栈帧弹出。在对变量 a 进行加一操作的时候,就会对栈帧中的操作数栈运用相关的字节码指令。
-
程序计数器
既然是线程,就要接受操作系统的调度,但总有时候,某些线程是获取不到 CPU 时间片的,那么当这个线程恢复执行的时候,它是如何确保找到切换之前执行的位置呢?这就是程序计数器的功能。和 Java 虚拟机栈一样,它也是线程私有的。程序计数器只需要记录一个执行位置就可以,所以不需要太大的空间。事实上,程序计数器是 JVM 规范中唯一没有规定 OutOfMemoryError 情况的区域。 -
本地方法栈
与 Java 虚拟机栈类似,本地方法栈,是针对 native 方法的。我们常用的 HotSpot,将 Java 虚拟机栈和本地方法栈合二为一,其实就是一个本地方法栈,大家注意规范里的这些差别就可以了。
2、内存大小的取舍
(1)扩大内存可以降低触发GC的次数
(2)内存太大触发GC时的停顿时间也会太长
因此要根据实际的业务场景设置成一个“合适”的值,并配合压测和线上环境的实际情况不断的调优,建议:吞吐量=花费在非GC停顿上的工作时间/总时间>95%。
控制内存大小的核心JVM参数:
-
-Xms:启动JVM时堆内存的大小
-
-Xmx:堆内存最大限制
建议:两者需要设置的一样防止扩缩容 -
-XX:NewSize 年轻代大小
-
-XX:MaxNewSize 最大年轻代大小
建议:两者需要设置的一样防止扩缩容 -
-XX:SurvivorRation Eden与Survivor 占比,默认为8
建议:Eden需要必Survivor尽可能的大(至少是一倍),防止多次触发young gc导致年龄快速增长到可以进入老年代的case -
-XX:MetaspaceSize 元空间初始空间大小
-
-XX:MaxMetaspaceSize=512 元空间最大空间,默认是没有限制的。
3、GC优化策略
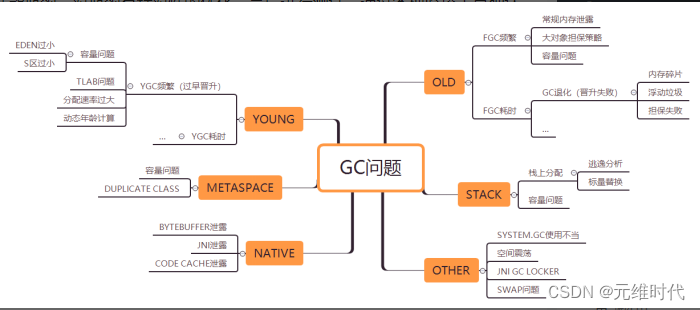
- 将进入老年代的对象减少到最低
- young gc: 40ms内
- major gc:(老年代): stop the world时间总和控制在100ms内
- full gc: 尽可能少,且时间在1s内
除了cms和g1这两种GC收集器外,其余的major gc=full gc
GC策略开启参数
JVM调优标志,除了少数例外,JVM接收两种标志:
布尔标志和附带参数的标志。布尔标志使用的语法是:
-XX:+FlagName表示开启,-XX:-FlagName表示关闭。
附带参数的标志使用的语法是:-XX:FlagName=something,表示设置FlagName的值为something。其中,something指表示任意值的符号。例如,-XX:NewRatio=N表示NewRatio标志可以设成任意值N(N的含义将是讨论的重点)。
4.、优化详细方案
1、优化总体方案
根据性能跟踪、分析,进行JVM调优。优化方案需要根据压测结果对比最终进行调整。
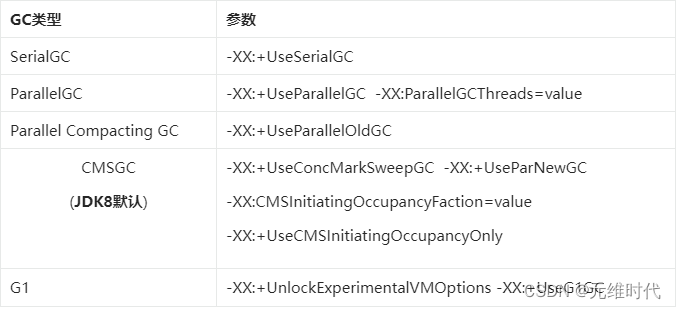
2、选择合适垃圾收集器
可参考:堆内存4G以下可以用parallel,4-8G可以用ParNew + CMS。
JDK8默认采用parallel。
3、堆内初始值设置
jvm参数的初始值和最大值设置一样,避免扩容时消耗性能。
-Xms4096m –Xmx4096m
4、元空间设置
元空间的大小参数必须要设置,默认是21M,但是它会自动扩容,元空间满了也会触发fullGC,所以一开始就设置好,避免扩容和触发FullGC。
-XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M
5、年轻代、老年代占比
默认年轻代:老年代是1:2,可以调整为1:1。
尽可能让对象都在新生代里分配和回收,尽可能别让太多对象频繁进入老年代,避免频繁对老年代进行垃圾回收,同时给系统充足的内存大小,避免新生代频繁进行垃圾回收。
扩大年轻代的空间,避免触发对象动态年龄判定机制,尽量避免对象进入老年代,触发FullGC,也可以减少minorGC的频率。
如果用parallel,则需要显式的指定比例,parallel默认会动态调整。
-XX:-UseAdaptiveSizePolicy -XX:NewRatio=2
6、Eden、S0、S1占比
eden区和s0、s1默认是8:1:1,可以调整为6:1:1
尽量让每次Young GC后的存活对象小于Survivor区域的50%,都留在年轻代中,避免对象动态年龄判定的触发。尽量别让对象进入老年代,减少FullGC频率,避免频繁fullGC对性能影响。(FullGC时间长,会STW)。
如果用parallel,则需要显式的指定比例,parallel默认会动态调整。
-XX:-UseAdaptiveSizePolicy -XX:SurvivorRatio=6
7、晋升老年代的最大年龄阈
-XX:MaxTenuringThreshold=15
8、开启GC日志
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintHeapAtGC
-XX:+PrintTenuringDistribution
9、调优参数
需要对下列参数进行调优:
-Xms2048m -Xmx2048m
-XX:-UseAdaptiveSizePolicy -XX:NewRatio=1 -XX:SurvivorRatio=6
-XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M
-XX:+PrintGCDetails -XX:
+PrintGCDateStamps
-XX:+PrintHeapAtGC
-XX:+PrintTenuringDistribution
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
-XX:+PrintHeapAtGC
-XX:+PrintTenuringDistribution
10、参考参数
4核8G,JDK1.8参数参考,具体要以实际项目及调优结果进行设置:
-Xms4096m
-Xmx4096m
-Xmn3072m
-XX:MetaspaceSize=256m
-XX:MaxMetaspaceSize=256m
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:CMSInitiatingOccupancyFraction=92
-XX:+UseCMSCompactAtFullCollection
-XX:CMSFullGCsBeforeCompaction=0
-XX:+CMSParallelInitialMarkEnabled
-XX:+CMSScavengeBeforeRemark
-XX:+DisableExplicitGC
-XX:+PrintGCDateStamps
-XX:+PrintGCDetails
-Xloggc:gc.log
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/usr/local/dumdir
5、调优目标
1.GC的时间足够的短
2.GC的次数足够的少
3.发生Full GC的周期足够的长
7、推荐文章、书籍
1、常见性能优化策略的总结
2、性能优化模式
3、深入理解Java虚拟机

4、Java性能权威指南

5、收获,不止Oracle



