
ACL'22 | 一文解读复旦黄萱菁、邱锡鹏等老师NLP实验室的12篇长文
赞
踩
每天给你送来NLP技术干货!

来自:FudanNLP
国际计算语言学年会(Annual Meeting of the Association for Computational Linguistics, ACL)是自然语言处理领域的顶级学术会议,由计算语言学协会在世界范围内每年召开一次。
在ACL 2022中,复旦大学自然语言处理实验室FudanNLP共计12篇长文被录用,其中包括7篇主会论文和5篇Findings论文。
ACL 2022 主会
CQG: A Simple and Effective Controlled Generation Framework for Multi-hop Question Generation
作者:费子楚,张奇,桂韬,梁迪,王思睿,武威,黄萱菁
类别:Long Paper
摘要:多跳问题生成侧重于生成需要对输入段落的多条信息进行推理的复杂问题。当前具有最先进性能的模型已经能够生成与答案相对应的正确问题。然而,大多数模型无法保证生成问题的复杂性,因此它们可能会生成无需多跳推理即可回答的浅层问题。为了应对这一挑战,我们提出了CQG,这是一个简单有效的可控生成框架。CQG采用简单的方法生成包含多跳推理链中关键实体的多跳问题,保证了问题的复杂性和质量。此外,我们引入了一种新颖的基于Transformer的可控解码器,以保证关键实体出现在问题中。实验结果表明,我们的模型大大提高了性能,在HotpotQA上也比最先进的模型高出5个BLEU点约25%。
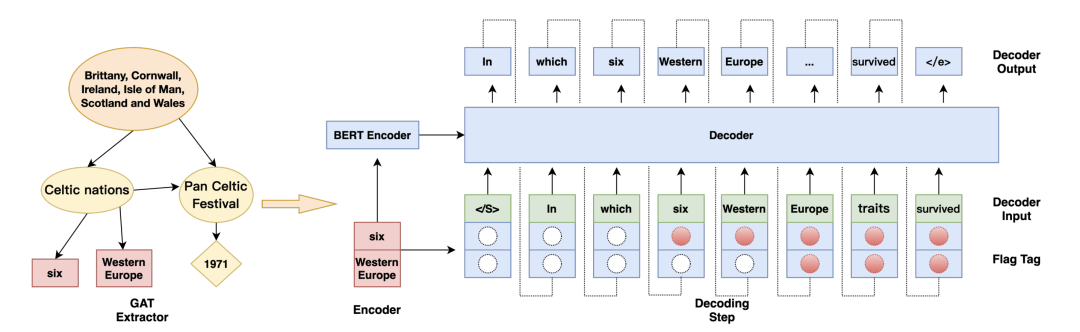
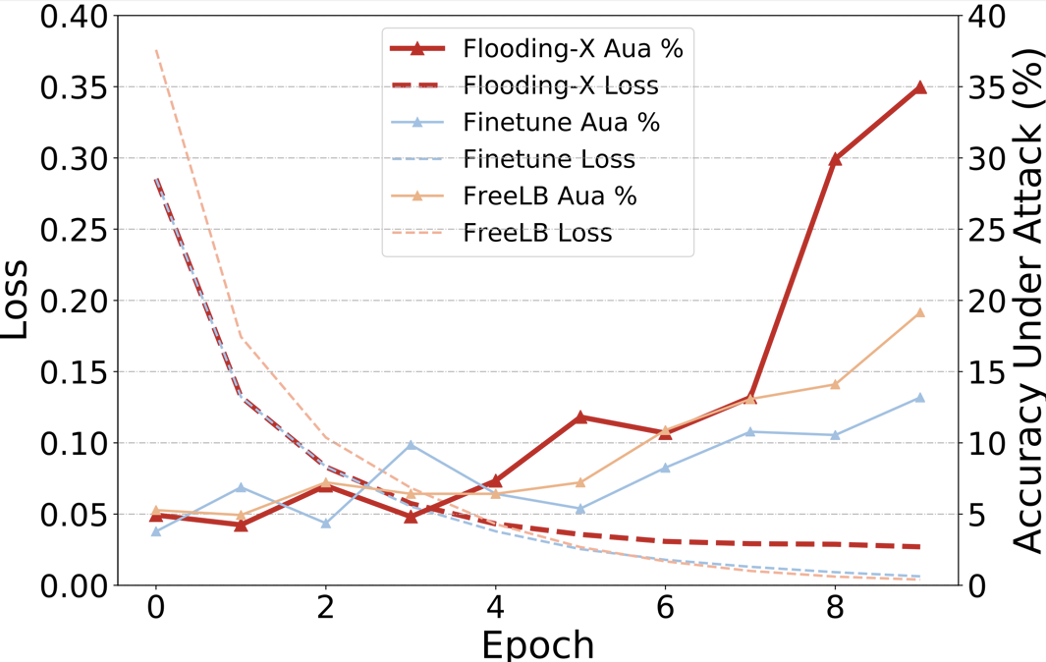
Flooding-X: Improving BERT's Resistance to Adversarial Attacks via Loss-Restricted Fine-Tuning
作者:刘勤,郑锐,包容,刘婧漪,刘志华,程战战,乔梁,桂韬,张奇,黄萱菁
类别:Long Paper
摘要:对抗鲁棒性在学界引起了很多关注,主流的解决方案是对抗训练。通用方法是为每个输入样本生成对抗扰动,这种训练方法的计算复杂性随着对抗样本所需要的梯度计算次数成倍上升。为了解决这个问题,我们采用了Flooding方法作为一种低成本的防御方法。然而,这一方法依赖于参数的选择,于是我们进一步提出一个指标来缩小参数搜索范围。Flooding-X并不需要生成额外的对抗扰动来训练模型,其时间消耗近似于模型微调,比标准对抗训练快2-15倍。实验表明,我们的方法在很大程度上提高了BERT对文本对抗攻击的防御能力,并在各种文本分类和GLUE任务上获得了当前最佳的鲁棒正确率。
MINER: Improving Out-of-Vocabulary Named Entity Recognition from an Information Theoretic Perspective
作者:王枭,窦士涵,熊立茂,邹易澄,张奇,桂韬,乔梁,程战战,黄萱菁
类别:Long Paper
摘要:基于深度学习的命名实体识别模型在许多数据集(如CONLL2003)上取得惊人的可喜成绩,但是,近期很多研究表明过去的方法过度依赖实体词本身的信息,以至于对训练集中未见过的实体词(未登录实体词)上的识别性能很差。现实生活中的实体词往往呈长尾分布,意味着这样的模型在实际应用中很难达到预期的效果。在这个工作中,基于信息论,我们提出一种新的NER学习框架去解决未登录实体词的识别问题。该方法额外包含两个基于互信息的训练目标,1)泛化信息最大化,目标是强化文本表示中的上下文信息和可泛化的实体特征;2)多余信息最小化,防止模型过度关注实体词本身和训练集中的数据偏见。实验结果表明,我们的方法可以有效提升模型在未登陆实体词识别上的泛化性和数据扰动下的鲁棒性。
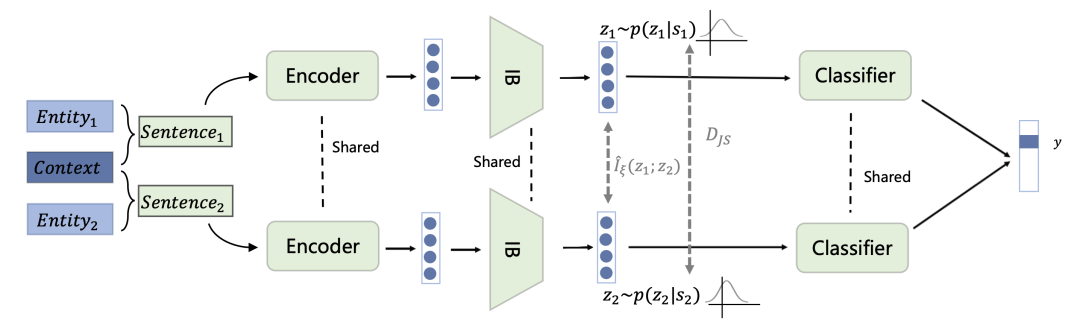
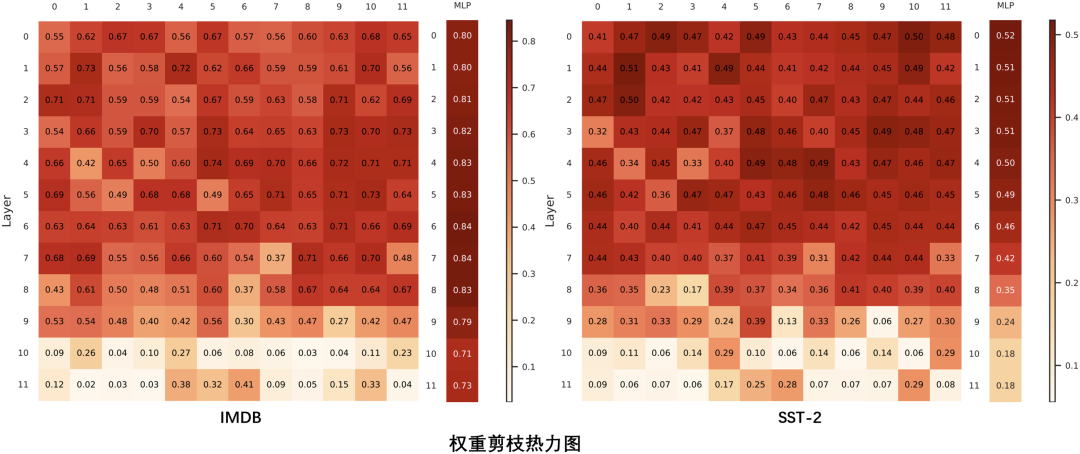
Robust Lottery Tickets for Pre-trained Language Models
作者:郑锐,包容,周钰皓,梁迪,王思睿,武威,桂韬,张奇,黄萱菁
类别:Long Paper
摘要:彩票网络假说(Lottery Ticket Hypothesis)的相关工作表明,预训练模型中存在媲美原始网络性能的子网络,这些子网络也被称为中奖彩票(winning tickets)。然而,中奖彩票在遭受对抗攻击时,表现出了比原始网络更差的鲁棒性。为了缓解上述问题,本文提出了一种基于可学习权重掩码(learnable binary masks for weights)的方法来识别隐藏在原始预训练模型中的鲁棒彩票网络(Robust Tickets)。为了解决二值掩码带来的离散优化问题,本方法使用concrete distribution对掩码进行建模,并使用L0范数的平滑近似来促进掩码的稀疏度。此外,本方法引入对抗损失目标来指引鲁棒彩票网络的搜索过程,确保彩票网络在准确度和鲁棒性上都有很好的表现。实验结果表明,相较之前的工作,本方法在鲁棒性评估上得到显著改善,甚至优于目前最先进的文本对抗防御方法。最后,本文提供了一种新的角度解释预训练语言模型在对抗鲁棒性上的脆弱性:某些预训练权重对准确度没有贡献,但可能会损害模型鲁棒性。
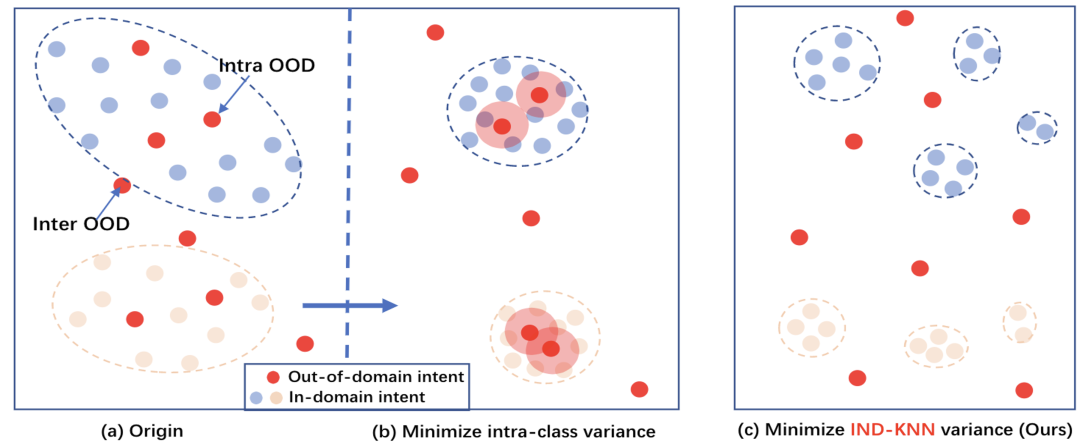
KNN-Contrastive Learning for Out-of-Domain Intent Classification
作者:周云华,刘佩举,邱锡鹏
类别:Long Paper
摘要:未知意图分类对于任务型对话系统是一项基础又具有挑战的任务。现有的方法在学习已知意图的可判别特征(语义)表示时,通常隐性限制已知意图的特征分布区域为“紧致的”或“单连通区域”,即分布区域内部不含未知意图。在下游未知意图检测时,已知意图的特征分布通常又会被限定服从某一特定的分布(最常见为高斯分布),使其应用受限。本文首先探索了未知意图分类问题的本质,借助于Open Space Risk形式化了该问题的优化目标,并提出了一种简单且有效的特征学习方法--k近邻对比学习,即仅利用与样本在特征(语义)空间中相近的k个样本来学习意图的可判别特征表示。进一步,本文尝试从理论层面探索,相比之前方法,该方法能更好优化目标的原因。值得注意的是,本文提出的意图特征学习方式和以密度为基础的异常检测方法天然相适应,从而避免对意图的特征分布做额外限制。在四个文本意图基准数据集上的实验结果表明,该方法能够取得较好的效果。
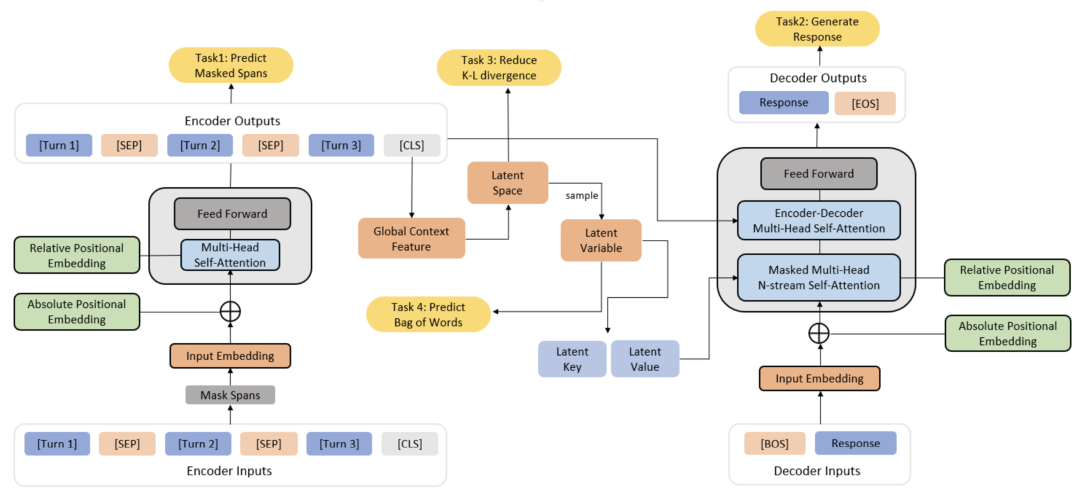
DialogVED: A Pre-trained Latent Variable Encoder-Decoder Model for Dialog Response Generation
作者:陈伟,宫叶云,王松,要博伦,齐炜祯,魏忠钰,胡晓武,周海涛,毛祎,陈伟祝,程骉,段楠
类别:Long Paper
摘要:开放域对话中的响应生成是一个重要的研究课题,其主要挑战是生成相关且多样的响应。本文提出一种新的对话预训练框架DialogVED,它将连续隐变量引入增强的编码器-解码器预训练框架中,以提高响应的相关性和多样性。我们利用语言模型和变分自编码器文献中的4个任务在大型对话语料库Reddit上对模型进行预训练:1) 遮盖语言模型;2) 响应生成;3)词袋预测;4)KL散度减少。我们还添加了额外的参数来建模对话中的轮次结构,以提高预训练模型的性能。我们在PersonaChat、DailyDialog 和 DSTC7-AVSD 基准上进行实验。结果表明,我们的模型在所有这些数据集上都达到了最新的水平。
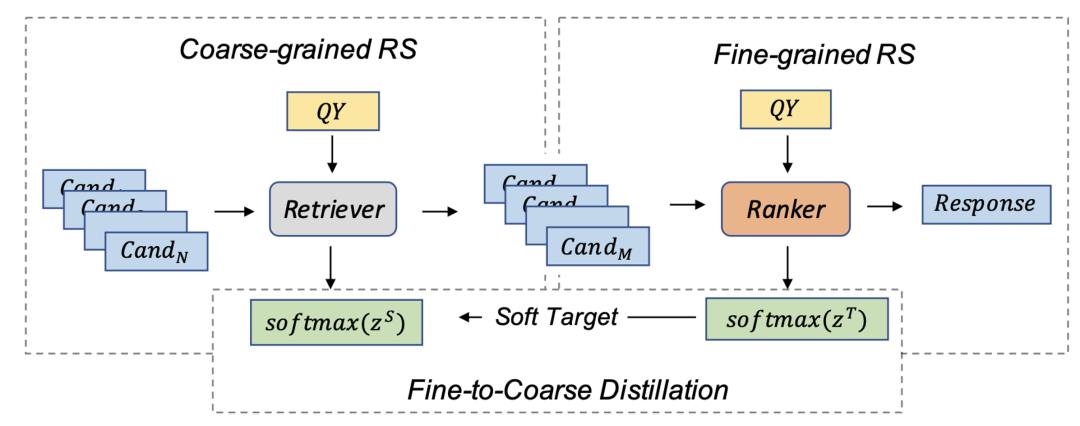
Contextual Fine-to-Coarse Distillation for Coarse-grained Response Selection in Open-Domain Conversations
作者:陈伟,宫叶云,徐粲,胡煌,要博伦,魏忠钰,范智昊,胡晓武,周海涛,姜大昕,程骉,段楠
类别:Long Paper
摘要:我们研究了检索式对话系统中的粗粒度响应选择问题,它与细粒度响应选择同样重要,但在现有文献中的探索较少。本文提出一种基于上下文的细到粗蒸馏模型CFC,用于开放域对话中的粗粒度响应选择。在CFC 模型中,我们基于上下文匹配和多塔架构学习查询、候选上下文和响应的稠密表示,并将单塔架构(细粒度)中学习的知识蒸馏到多塔架构中(粗粒度)以增强检索器的性能。为了评估所提出模型的性能,我们基于 Reddit 评论和 Twitter 语料库构建了两个新数据集。在两个数据集上的大量实验结果表明,与传统的基线方法相比,所提出的方法在所有评估指标上都取得了巨大的进步。
Findings of ACL 2022
A Simple Hash-Based Early Exiting Approach For Language Understanding and Generation
作者:孙天祥,刘向阳,朱威,耿志超,吴玲玲,何义龙,倪渊,谢国彤,黄萱菁,邱锡鹏
类型:Long Paper
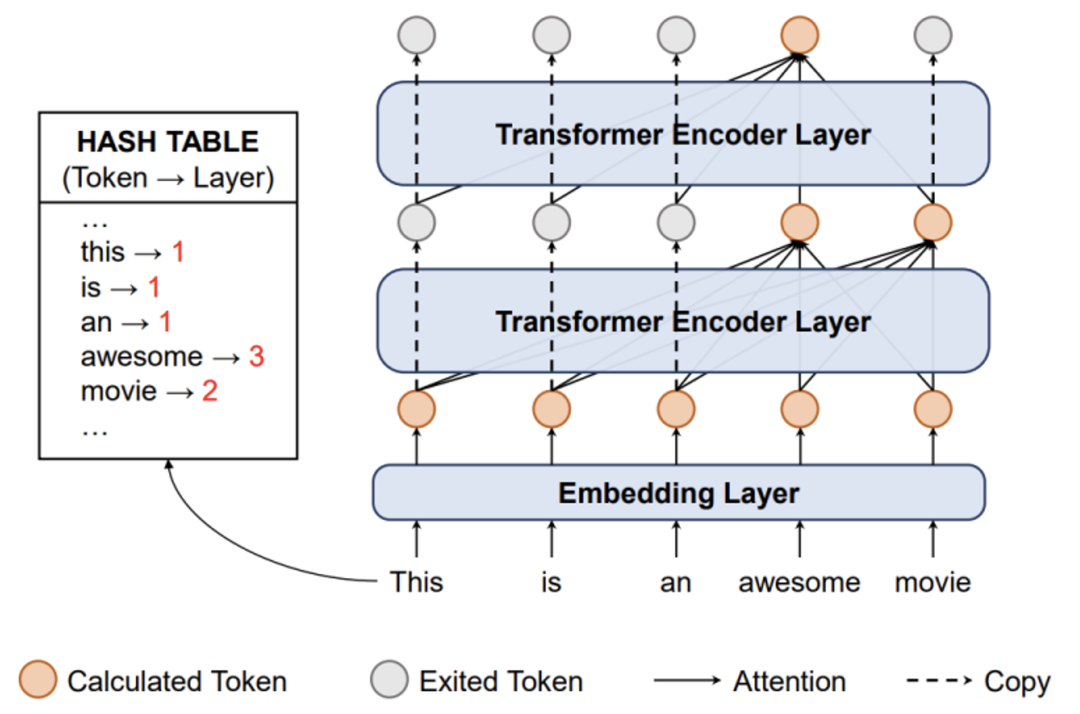
摘要:动态早退是一种提升模型推理效率的技术手段,它通过估计样本难度让不同样本在不同层退出推理过程。过去的工作通常采用某些启发式指标(例如熵)来衡量样本难度,因此需要调节阈值且找到的阈值难以在不同任务间泛化。作为对比,利用神经网络模块去估计样本难度进而学习何时退出的方法更加通用。但是,样本难度究竟能否被学习,以及能够学到什么程度仍旧是未知的。在本文中,我们对样本难度的可学性开展了实验,结果表明现代神经网络在预测样本难度任务上表现很差。基于这一观察,我们提出了一种简单有效的基于哈希的早退方法(HashEE),用简单的哈希函数替换learn-to-exit模块,直接为每个单词分配其退出层。相比过去的方法,HashEE不需要内部分类器或额外参数,因而更加高效。我们在分类、回归、生成任务上的实验结果都表明,HashEE可以用更少的FLOPs和推理时间取得更好的效果。
Towards Adversarially Robust Text Classifiers by Learning to Reweight Clean Examples
作者:徐健涵,张岑湲,郑骁庆,李林阳,Cho-Jui Hsieh,Kai-Wei Chang,黄萱菁
类别:Long Paper
摘要:在文本领域的对抗鲁棒性研究中,现阶段绝大部分的研究关注于对抗数据增强、优化模型结构等方面上,而在分配训练数据训练权重的研究则偏少。本文通过以重新分配原始训练样本权重的方式,尝试不在训练集中添加额外的对抗增强数据,来得到一个鲁棒的文本分类器,并将这种训练方法命名为WETAR。具体地,我们希望通过使用验证集梯度,来引导模型分配训练样本权重。我们采用了Learning to Reweight的框架,通过构建在验证集中加入对抗样本构建鲁棒验证集,并采取了类似元学习的训练方式来计算验证集样本在训练样本上的相对影响力。实验证明,WETAR不仅能够得到一个鲁棒的模型,在三个数据集上要优于之前的大部分对抗训练工作,而且让我们能够知道存在一种权重分配方式,能够使模型在原始样本下训练下得到很好的鲁棒性提升。该工作在复旦大学郑骁庆老师团队与加州大学洛杉矶分校的Cho-Jui Hsieh和Kai-Wei Chang老师指导下完成。
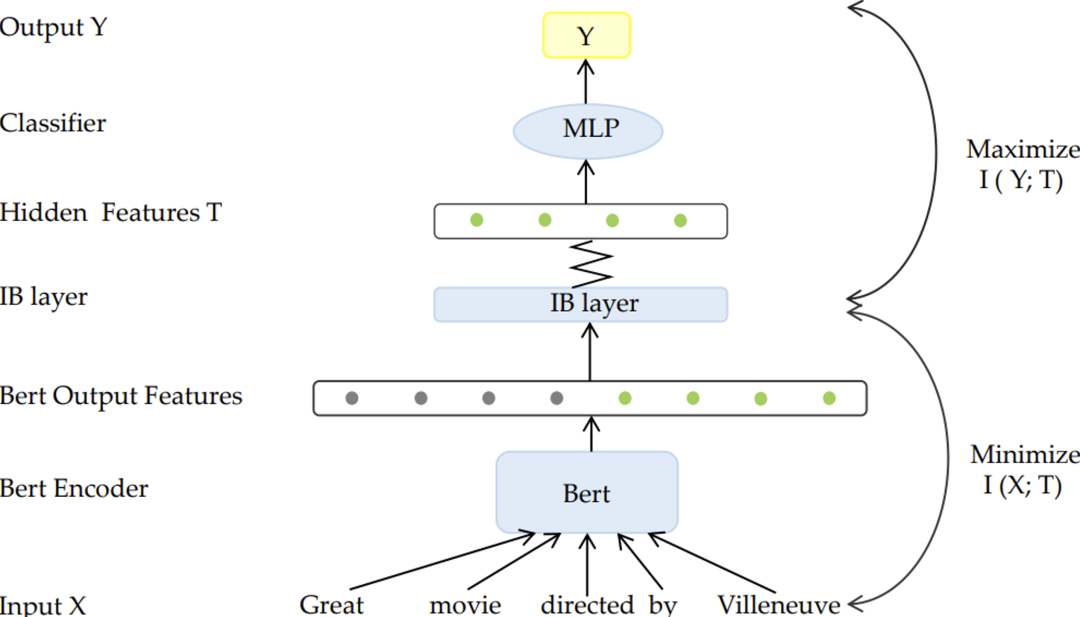
Improving the Adversarial Robustness of NLP Models by Information Bottleneck
作者:张岑湲,周翔,万奕欣,郑骁庆,Kai-Wei Chang,Cho-Jui Hsieh
类别:Long Paper
摘要:现有研究显示,对抗样本的成因与非鲁棒特征有直接联系。非鲁棒特征能够对模型最终的预测结果产生影响,但人类对这种特征并不敏感。因此,非鲁棒特征容易被人为操控,以用来欺骗语言模型、进行对抗攻击。
在本研究中,我们利用了信息瓶颈(information bottleneck)理论,尝试探索在保留任务相关的鲁棒特征的前提下,尽可能的过滤掉非鲁棒特征。我们在SST-2, AGNEWS 和 IMDB三个数据集上进行了实验,实验结果证明: 相较于现有的防御方法, 基于information bottleneck的方法能够在保证模型在干净样本上性能的基础上,令模型的鲁棒性得到显著提升。
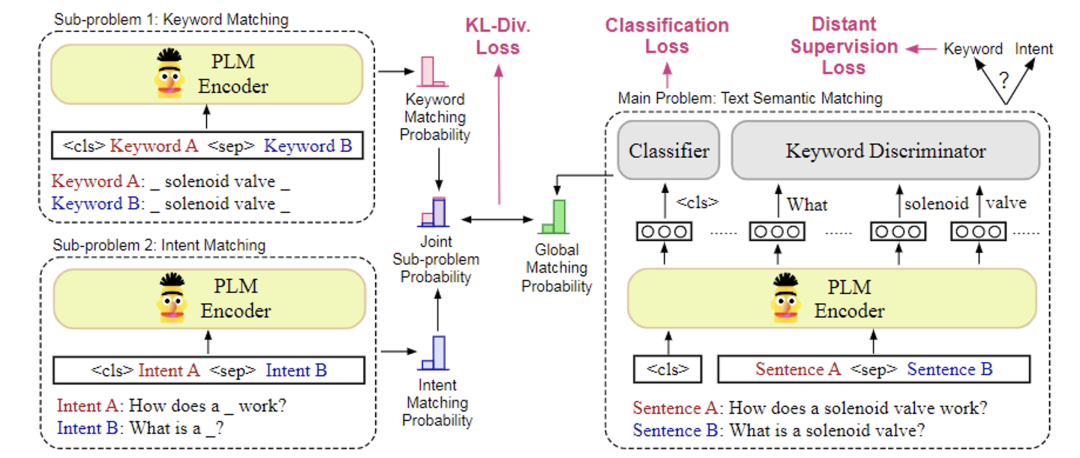
Divide and Conquer: Text Semantic Matching with Disentangled Keywords and Intents
作者:邹易澄,刘宏伟,桂韬,王浚哲,张奇,唐萌,李海翔,Daniel Wang
类别:Long Paper
摘要:文本语义匹配是一项被广泛应用于社区问答、信息检索、推荐系统等多种场景的基础任务。大多数基于预训练语言模型(PLM)的文本匹配方法(如 BERT等)通过统一处理句子中不同的单词来直接进行文本内容的比较。然而,待匹配的句子通常包含不同匹配粒度的内容。我们一般将其分为两类:(1)“关键词”(keyword), 即应当严格匹配的动作、实体和事件等事实信息;(2)“意图”(intent),即可以通过多种表述方式传达的抽象概念。在这项工作中,我们提出了一种简单有效的文本匹配训练策略DC-Match,将关键词与意图分离,并使用分而治之的策略进行匹配。我们假设两个句子是匹配的,当且仅当它们的关键词和意图均匹配。DC-Match可以方便地与PLM相结合,而不影响其推理的效率。我们在三个数据集上进行了实验,结果表明我们的方法在多种 PLM 上均能得到稳定的性能提升。
Logic-Driven Context Extension and Data Augmentation for Logical Reasoning of Text
作者:王思远,钟宛君,唐都钰,魏忠钰,范智昊,姜大昕,周明,段楠
类别:Long Paper
摘要:基于文本的逻辑推理需要识别文本中的逻辑结构并执行逻辑推断,目前的方法主要关注于文本的上下文语义而难以对逻辑推断过程进行明确建模。本文我们提出了一个LReasoner系统,由两个部分组成:逻辑驱动的文本扩充框架和逻辑驱动的样本增强算法。前者通过提取逻辑表达式作为基本推理单元,根据逻辑等价律推断隐式存在的表达式,并扩充给定文本以匹配答案。后者构造字面上相似但逻辑上不同的样本,通过对比学习使得模型更好地捕捉文本中的逻辑信息,尤其是逻辑上的否定和条件关系。我们在数据集ReClor和LogiQA上进行了实验,结果表明了我们提出的推理系统的有效性,甚至在ReClor数据上超过了人类性能。

- 下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套! 后台回复【五件套】
- 下载二:南大模式识别PPT 后台回复【南大模式识别】
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!
