- 1东方通TongWeb结合Spring-Boot使用_tongweb springboot
- 2Centos安装rabbitMQ_package erlang-r16b-03.18.el7.aarch64 requires erl
- 3如何无损放大图片?教你三种方法轻松提高画质_ps怎么无损放大图片
- 4AI绘画揭秘:7种Midjourney后缀参数详解_niji6 variation mode 参数介绍
- 5区块链技术之以太坊ETH白皮书
- 6机器学习模型运用在机器人上
- 7ES底层原理之倒排索引_es倒排索引原理
- 8国内Ubuntu安装 stable-diffusion教程,换成国内镜像
- 9Python 第一个GUI制作 pyqt6+qtdesigner+vscode_pyqt6 vscode
- 10数仓体系与数据治理全集_数据治理 ods
Hadoop生态圈(三十六)- YARN High Availability(HA)高可用集群_yarn ha
赞
踩
1. YARN HA 集群概述
ResourceManager(RM)负责管理群集中的资源和调度应用程序(如 MR、Spark 等)。在Hadoop 2.4之前,YARN集群中的ResourceManager存在SPOF(Single Point of Failure,单点故障)。为了解决 ResourceManager 的单点问题,YARN 设计了一套 Active/Standby 模式的 ResourceManager HA(High Availability,高可用)架构。在运行期间有多个ResourceManager同时存在来增加冗余进而消除这个单点故障,并且只能有一个ResourceManager处于Active状态,其他的则处于Standby状态,当Active节点无法正常工作,其余Standby状态的几点则会通过竞争选举产生新的Active节点。
2. 高可用 HA 架构
ResourceManager 的 HA 通过Active/Standby体系实现,其底层通过ZooKeeper集群来存储RM的状态信息、应用程序的状态。如果 Active 状态的 RM 遇到故障,会通过切换 Standby 状态的 RM 为 Active 来继续为集群提供正常服务。

故障转移机制支持自动故障转移和手动故障转移两种方式实现。在生产环境中,自动故障转移应用更为广泛。
- 第一种:手动故障转移
当没有启用自动故障转移时,管理员必须手动将一个 RM 转换为活动状态。要从一个 RM 到另一个 RM 进行故障转移,需要先把 Active 状态的 RM 转换为 Standby 状态的 RM,然后再将 Standby 状态的 RM 转换为 Active 状态的 RM。这些操作可用 yarn rmadmin 命令来完成。 - 第二种:自定故障转移
RM可以选择嵌入基于Zookeeper的ActiveStandbyElector(org.apache.hadoop.ha.ActiveStandbyElector类)来实现自动故障转移,以确定哪个RM应该是Active。当 Active 状态的 RM 发生故障或无响应时,另一个 RM 被自动选为 Active,然后接管服务。YARN 的故障转移不需要像 HDFS 那样运行单独的 ZKFC 守护程序,因为 ActiveStandbyElector 是一个嵌入在 RM 中充当故障检测器和 Leader 选举的线程,而不是单独的 ZKFC 守护进程。
当有多个 RM 时,Clients 和 NMs 通过读取 yarn-site.xml 配置找到所有 ResourceManager。Clients、AM 和 NM 会轮训所有的 ResourceManager 并进行连接,直到找着 Active 状态的 RM。如果 Active 状态的 RM 也出现故障,它们就会继续查找,直到找着新的 Active 状态的 RM。
3. 故障转移原理
YARN 这个 Active/Standby 模式的 RM HA 架构在运行期间,会有多个RM同时存在,但只能有一个RM处于Active状态,其他的RM则处于Standby状态,当 Active 节点无法正常提供服务,其余 Standby 状态的 RM 则会通过竞争选举产生新的Active节点。以基于 ZooKeeper 这个自动故障切换为例,切换的步骤如下:
- 主备切换,RM 使用基于 ZooKeeper 实现的 ActiveStandbyElector 组件来确定 RM 的状态是 Active 或 Standby。
- 创建锁节点,在 ZooKeeper 上会创建一个叫做
ActiveStandbyElectorLock的锁节点,所有的 RM 在启动的时候,都会去竞争写这个临时的 Lock 节点,而 ZooKeeper 能保证只有一个 RM 创建成功。创建成功的 RM 就切换为 Active 状态,并将信息同步存入到 ActiveBreadCrumb 这个永久节点,那些没有成功的 RM 则切换为 Standby 状态。 - 注册Watcher监听,所有 Standby 状态的 RM 都会向
/yarn-leader-election/cluster1/ActiveStandbyElectorLock节点注册一个节点变更的 Watcher 监听,利用临时节点的特性,能够快速感知到 Active 状态的 RM 的运行情况。 - 准备切换,当 Active 状态的 RM 出现故障(如宕机或网络中断),其在 ZooKeeper 上创建的 Lock 节点随之被删除,这时其它各个 Standby 状态的 RM 都会受到 ZooKeeper 服务端的 Watcher 事件通知,然后开始竞争写 Lock 子节点,创建成功的变为 Active 状态,其他的则是 Standby 状态。
- Fencing(隔离),在分布式环境中,机器经常出现假死的情况(常见的是 GC 耗时过长、网络中断或 CPU 负载过高)而导致无法正常对外进行及时响应。如果有一个处于 Active 状态的 RM 出现假死,其他的 RM 刚选举出来新的 Active 状态的 RM,这时假死的 RM 又恢复正常,还认为自己是 Active 状态,这就是分布式系统的脑裂现象,即存在多个处于 Active 状态的 RM,可以使用隔离机制来解决此类问题。
- YARN的Fencing机制是借助 ZooKeeper 数据节点的 ACL 权限控制来实现不同 RM 之间的隔离。这个地方改进的一点是,创建的根 ZNode 必须携带 ZooKeeper 的 ACL 信息,目的是为了独占该节点,以防止其他 RM 对该 ZNode 进行更新。借助这个机制假死之后的 RM 会试图去更新 ZooKeeper 的相关信息,但发现没有权限去更新节点数据,就把自己切换为 Standby 状态。
4. 高可用集群搭建
4.1 安装Zookeeper集群
YARN HA 高可用依赖于 Zookeeper 集群存储状态数据和自动故障转移,所以要配置安装部署 Zookeepe r集群,具体步骤之前的另一篇博客有些,这里不再重复说了:《Zookeeper3.6.3集群搭建教程(附群起脚本)》
4.2 YARN HA配置
我这里用的环境是之前搭建的 HDFS 高可用集群,在此基础上将 YARN 改为高可用模式,具体从零到一如何搭建高可用集群可看这篇《Hadoop生态圈(九)- HDFS High Availability(HA)高可用集群》,然后根据下面修改 yarn-site.xml 内容即可搭建 YARN 高可用集群。
4.2.1 yarn-site.xml
删除内容
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.68.122</value>
</property>
- 1
- 2
- 3
- 4
添加内容
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>192.168.68.122</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>192.168.68.123</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>192.168.68.122:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>192.168.68.123:8088</value>
</property>
<!-- 启动自动故障转移,默认为false -->
<property>
<name>yarn.resourcemanager.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>hadoop.zk.address</name>
<value>192.168.68.121:2181,192.168.68.122:2181,192.168.68.123:2181</value>
</property>
<!-- 启用RM集群可恢复功能 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 指定RM集群的状态信息存储在zookeepr集群 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
同步配置文件到另外两台机器
scp yarn-site.xml hadoop@192.168.68.122:$PWD
scp yarn-site.xml hadoop@192.168.68.123:$PWD
- 1
- 2
重启YARN集群
stop-yarn.sh
start-yarn.sh
- 1
- 2
4.3 集群测试
当前集群角色分布:
| 服务器 | 服务进程 |
|---|---|
| 192.168.68.121 | DataNode DFSZKFailoverController JournalNode NodeManager NameNode QuorumPeerMain |
| 192.168.68.122 | ResourceManager JournalNode NodeManager DataNode NameNode DFSZKFailoverController QuorumPeerMain |
| 192.168.68.123 | DataNode JournalNode ResourceManager QuorumPeerMain NodeManager |
使用 YARN 提供管理命令,查看 RM 运行状态:

使用 WebUI 查看 RM 状态:


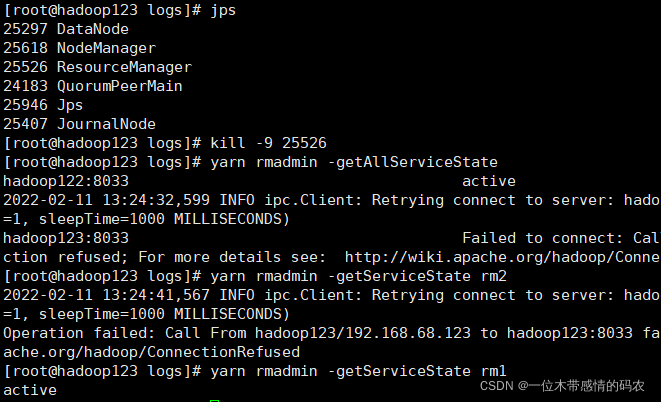
4.4 验证故障切换
- 查看HA状态
当hadoop123节点的 RM 为 Active 状态、hadoop122节点的 RM 为 Standby 状态时,访问http://hadoop122:8088会自动跳转到http://hadoop123:8088中,表示 YARN HA 正确配置。 - 自动故障切换
强制杀死hadoop123节点的 RM,基于 ZooKeeper 的 ActiveStandbyElector 自动故障转移策略将hadoop122节点的 RM 选举为 Active 状态,表示故障转移配置正确。